论文阅读:Emergent abilities of large language models
Wei J, Tay Y, Bommasani R, et al. Emergent abilities of large language models[J]. arXiv preprint arXiv:2206.07682, 2022.
主要探讨了随着模型规模的扩大,语言模型如何突然展现出小模型所不具备的能力
引言
众所周知,增加语言模型的规模(如增加训练计算量、模型参数量等)通常能带来更好的性能和样本效率,且在许多情况下,规模对性能的影响在方法论上是可以预测的(如交叉熵损失),这意味着,通常我们可以通过小模型的表现来推断大模型的性能。
然而,文章指出了一个与之相对的、反直觉的现象,即某些下游任务的性能并不会随着规模增加而持续、平滑地改善, 这种现象是不可预测的,即不能提前通过小模型预知大模型是否会具备某种能力。本文将这种现象称为“大型语言模型的涌现能力”。具体而言, 涌现是指系统中的量变导致了行为上的质变,具体到模型规模,文章将“涌现能力”定义为:在小规模模型中不存在,但在大规模模型中存在的能力。
涌现能力的定义
涌现能力在数据可视化上的特征,也是识别涌现的关键具体表现为——在达到某个临界阈值之前,模型的性能基本上接近随机;一旦突破这个阈值,性能会急剧提升,显著超越随机水平。这种剧烈的变化也被称为“相变”,即整体行为发生了戏剧性的改变,这是通过观察小规模系统无法预见的。【关于“规模”的定义:主要通过训练计算量和模型参数量对规模进行定义(因为使用更多计算量训练的模型通常也拥有更多参数)】
具体而言,涌现可以看作是许多相关变量的函数; 此外能力首次涌现的规模并不是固定不变的。如果使用更高质量的数据或更好的训练方法,涌现可能会在更小的计算量或更少的参数下发生。
少样本提示任务
详细探讨了大型语言模型在“少样本提示”模式下表现出的涌现能力(即在模型的输入上下文中提供少量“输入-输出”的示例作为前言,然后让模型为未见过的例子完成任务)。在各个任务中,当模型规模较小时,性能处于随机水平;直到达到某个临界规模后,性能突然提升至远超随机水平。具体包括BIG-Bench 基准测试(算数能力及其它任务)、TruthfulQA(回答的真实性)、接地概念映射(方位映射到文本网格中)、多任务语言理解、 上下文单词理解,各个参数量级的模型具体表现如下图所示:
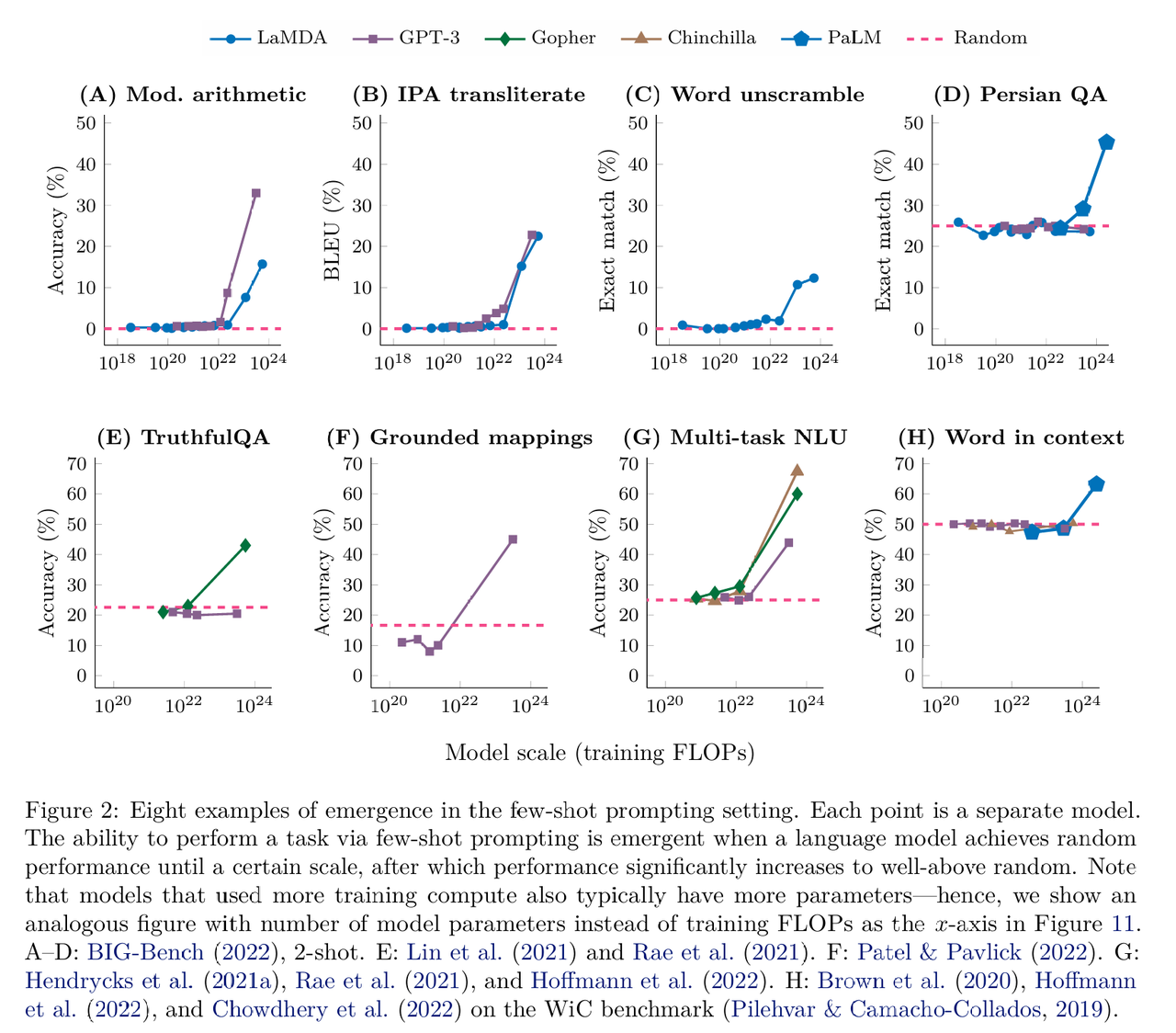
增强提示策略
如果一种技术在小规模模型上没有提升甚至是有害的,但在大规模模型上却能显著提升性能,那么这种利用技术的能力也被视为一种涌现能力。具体在包括多步推理(利用思维链提示)、指令遵循(基于指令微调)、程序执行(微调模型以在算数等任务中引入中间输出)、模型校准(先输出再评估自己答案是不是准确的)。这一部分的核心观点是,许多高级的提示和微调技术并非对所有模型都有效,它们往往存在一个“规模门槛”,只有越过这个门槛,这些技术才能解锁模型的潜力。
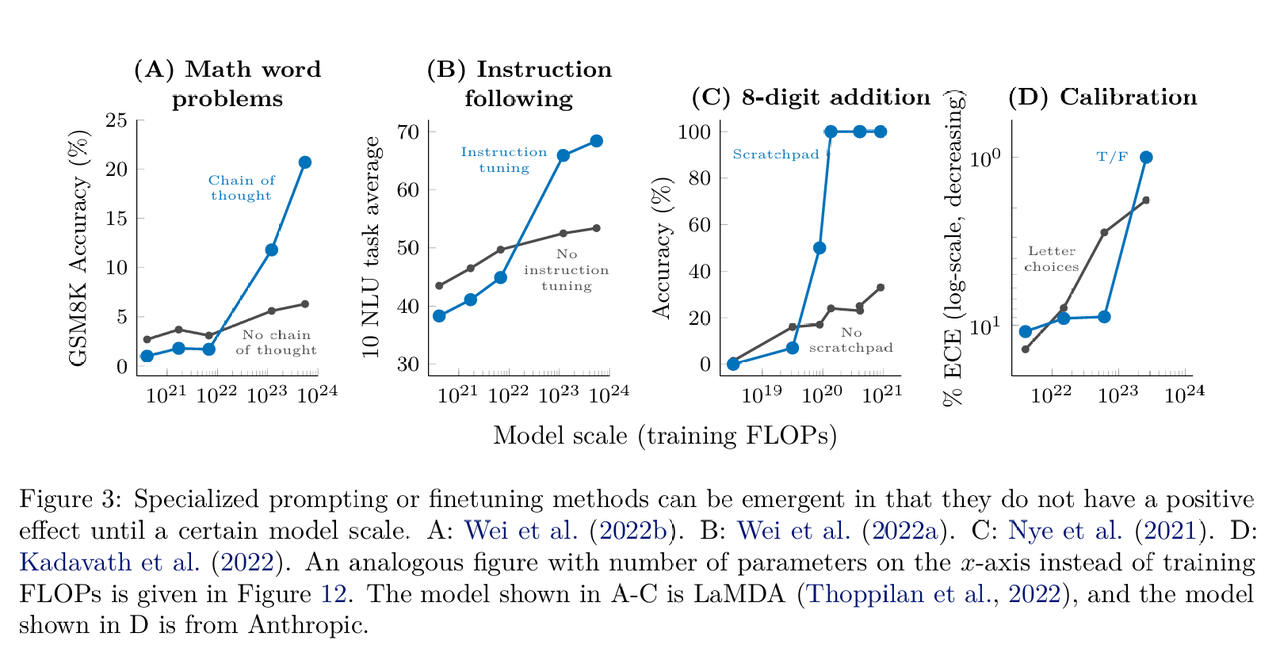
讨论
作者首先重申,涌现能力意味着我们不能简单地通过小模型来推断大模型的能力。许多能力没有显式包含在预训练中。一个重要的案例是“上下文单词理解”任务,之前的研究(如 GPT-3)即使扩展到很大规模也无法在该任务上超越随机水平,这导致研究者认为这是模型架构(如缺乏双向注意力)的问题,但当使用单纯的解码器模型 PaLM 并将其扩展到 540B 参数时,该能力突然涌现了。这证明了某些被认为需要架构改进的问题,可能仅仅通过扩大规模就能解决。
关于“涌现”现象出现的原因: 某些任务可能本质上需要一定的复杂度。例如,多步推理可能需要模型达到一定的深度(层数),或者世界知识的任务需要足够的参数来记忆知识。此外,虽然模型训练在下游指标(如准确率)上表现为突变,但在cross-entropy loss上模型的改进通常是平滑的,这意味着模型一直在学,只是在达到临界点前,这些微小的进步无法转化为最终答案的正确率。
此外作者指出,规模并非解锁能力的唯一因素。更好的架构、数据或训练方法可以让能力在更小的规模下涌现。比如PaLM 62B 模型在许多任务上表现出了涌现能力(可能归功于 PaLM 更高质量的训练数据);此外通过指令微调,可以在更小的模型上解锁指令遵循能力。
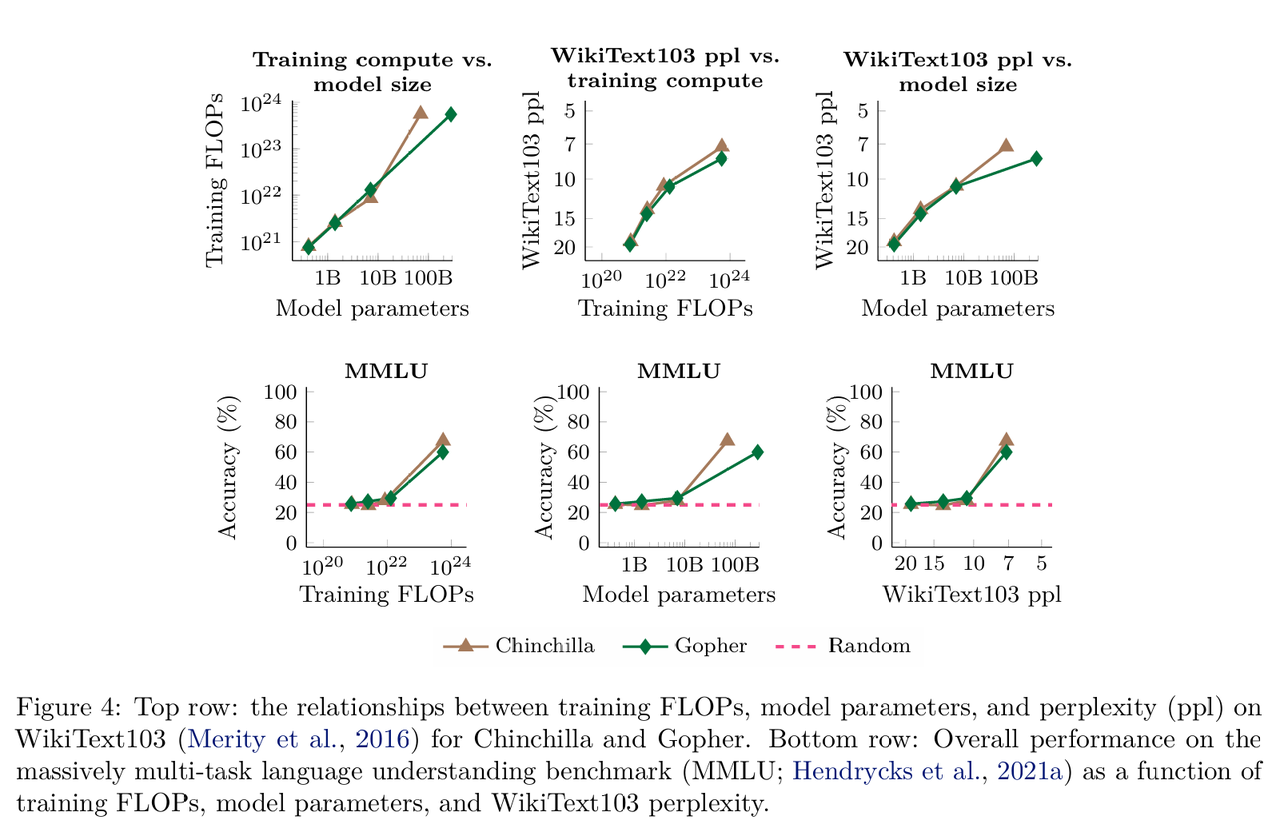
还可以从模型的通用文本困惑度来看待涌现能力,涌现能力与困惑度的改善高度相关。此外除了能力,风险也可能随规模涌现,随着模型变大,它们可能更倾向于模仿人类的谬误,其他的风险包括偏见增强、毒性内容生成以及对训练数据的过度记忆。
这部分的题外话
perplexity一般是这么计算的——困惑度指标实际上是指数化后的交叉熵损失(这个指标是针对tokens序列进行计算的),令,PPL 定义为该序列概率的倒数的几何平均,
,为了数值稳定性,通常在对数域对这个指标进行计算:
,实际上括号里面的就是cross entropy loss
PPL指标可以直观理解为加权分支因子,即“模型对下一个词预测的信心”,在评估长文本的 PPL 时,通常使用滑动窗口策略以避免每一段开头的 token 会因为缺乏上下文而导致的整体PPL偏高。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)