告别数据量焦虑:大模型微调的工程思维与8B模型垂直Agent训练全解析
文章探讨大模型微调的工程思维,强调数据质量重于数量。SFT用于私域语义锚定,需确保知识点全覆盖和多样性;DPO用于工具调用行为对齐。微调不能突破模型通用推理上限,但可通过工具封装和任务拆解,使小模型成为稳定可控的垂直Agent。实例展示了从问题分析到解决方案的完整迭代过程,体现了"扬长避短"的工程化思维。
文章探讨大模型微调的工程思维,强调数据质量重于数量。SFT用于私域语义锚定,需确保知识点全覆盖和多样性;DPO用于工具调用行为对齐。微调不能突破模型通用推理上限,但可通过工具封装和任务拆解,使小模型成为稳定可控的垂直Agent。实例展示了从问题分析到解决方案的完整迭代过程,体现了"扬长避短"的工程化思维。
这就像有人问:“从回龙观开到天安门,具体需要踩多少脚油门、多少脚刹车?”
这显然不是一个可以预设“标准答案”的问题。与其纠结具体的数字,不如聊聊数据整理背后的工程思维。
今天,我把最近的一些实战思考整理出来,重点谈三个问题:
- 数据哲学: 授人以渔的数据整理思路。
- 认知陷阱: 微调不是魔法,不要试图让小模型做它做不到的事。
- 实战复盘: 一个具体而微的实例, 麻雀虽小五脏俱全(含迭代过程)。
01
训练数据:不要先问“要多少条”,先问“要覆盖什么模式”
1)SFT:用“知识卡”做私域语义锚定(Domain Anchoring)
我通常把私域知识拆成最小单位:知识点,然后为每个知识点准备多张知识卡。
以“知识点”为锚:
- 一张知识卡 = 一个高质量问答对(最好带一点业务上下文)
- 目标不是让模型背答案,而是让它在你的业务语境里“原生认识”实体和概念(像认识“苹果/香蕉”一样认识“USS”)
组织 SFT 知识卡时,重点看三件事:
a. 全覆盖原则:
- 知识点要覆盖“知识盲区”而不是重复常识。
- 哪些是通用模型根本不知道的:内部系统名、字段含义、风险等级口径、业务流程角色、内部产品/岗位/动作定义
- 注意概念依赖:如果私域概念 A 的解释里包含概念 B,那么 B 也必须有独立的解释数据,不能假设模型能自动推理出子概念,否则模型容易“半懂不懂”导致推理漂移。
b. 同一知识点要有“多样性”,否则必然过拟合(关键!)
真实例子(非常典型):
- “问:USS 评估结果 level>50,是否安全?答:不安全”
- “问:USS 查询返回 Not found,是否安全?答:安全”
如果只有这两条,模型很容易学歪,就像赵本山小品里说的“都学会抢答了!”:
- 看到“USS 评估”就直接抢答“不安全”
- 看到“USS 查询”就直接抢答“安全” 而且自信满满——这是最危险的“伪泛化”。
后果:模型会偷懒,看到“评估”就背诵“不安全”,看到“查询”就背诵“安全”。它学会了过拟合(Overfitting),而不是理解。数据必须在此处增加变体,打断这种简单的映射关系。
多样性怎么做?同一知识点至少要覆盖:输入表达变体、边界值、反例、噪声、不同上下文位置(多轮中第 1 轮/第 8 轮出现)等。
c. 训练早期先做“单知识点注入实验”,再扩规模
不要一上来就搞几万条。建议先选 1~3 个最关键私域概念做注入实验,回答下面两个问题:
- 你的模型/模板/超参组合下,一个知识点最小有效注入量大概是多少张知识卡?
- 注入后是否引入“副作用”(输出异常、对话能力损伤、think 标签破损、重复等)?
把这一步跑通,再扩展知识点数量,会少走很多弯路。
粗量级建议(仅供起步):很多场景下,一个知识点 5~30 张“多样性知识卡”就能明显看到锚定提升;但差异巨大,最好以你的注入实验为准。
2)DPO:围绕“错误行为”对齐工具调用偏好(Tool Behavior Alignment)
DPO 的核心不是“教知识”,而是纠正行为偏好:该不该调用、调用哪个函数、参数怎么填、返回怎么解读、何时停止/继续。
我的做法是:针对模型当前的工具调用错误行为与漂移多发场景,构造 chosen / rejected:
- chosen:你期望的正确行为链(正确 tool call + 正确参数 + 正确解读)
- rejected:典型错误行为(不调用、乱调用、参数错、编造返回、解读漂移、跳步等)
需要注意三点:
a. 对齐优先级:先场景与函数名,再参数
很多系统失败是“函数选错/该调用不调用”。参数精度固然重要,但通常是第二阶段;否则你会在错误函数上把参数对齐到极致,仍然是错。
b. 可以按“工具接口”为单位估算量级,而不是按总条数
不用迷信精确数字。更实用的方式是:
- 每个接口至少覆盖:常见输入、边界输入、噪声输入、以及最常见的 3~5 类错误模式
- 通过评估集观察哪个接口最顽固,就优先加数据覆盖它
c. 顽固接口:必要时回到 SFT 追加“字段语义/返回结构”知识点
如果模型连字段含义都不理解(例如 threat_level/confidence/severity 混用),你用 DPO 只是在“对齐它的误解”。这时要回到 SFT 做语义注入,再用 DPO 固化行为。
实用技巧:如果你有评估/线上日志,DPO 数据往往可以“从错误中长出来”,比纯人工凭空造数据快得多、也贴近真实分布。
3)怎么判断“私域微调有效”?建议用 3 类指标做闭环
这也是被问最多的问题。我的判断标准非常工程化:
语义锚定(实体识别)是否稳定:
- 私域系统名/字段名/流程名是否被模型“原生识别”
- 多轮对话里是否漂移到别的解释
行为可控(工具调用)是否稳定:
- 是否该调用就调用
- 函数名与参数是否稳定正确
- 是否出现“编造 tool result / 跳过调用”的坏习惯
端到端确定性(E2E)是否提升:
- 同一输入多次运行结果是否一致
- 是否需要大量人工复查才能敢上线
02
常见陷阱:很多失败不是“数据不够”,而是“问题性质判断错了”
1)“微调后模型一定更聪明”——这是误解
模型“聪明”主要受规模与预训练决定。微调的价值是:
- 让模型懂你的私域实体
- 让模型在你的私域场景里走对概率路径
而不是让它在通用推理、规划、约束复查上超越更大的通用模型。
2)如果问题本质是“通用推理上限”,小模型怎么微调也救不了
如果一个任务的困难点在于:复杂规划、长链推理、强数学/强逻辑、跨域常识组合,那么大模型都做不到,小模型微调通常也做不到。
微调前先判断瓶颈属于哪一类:
- 私域语义缺失?(可用 SFT 注入)
- 工具调用行为不稳?(可用 DPO 对齐)
- 通用推理不足?(考虑更大模型/外部工具/拆解任务)
3)“凑够 N 条数据,回车,开始训练,一个月后奇迹发生”——这是集体幻觉
微调更像开车出门。你知道踩油门刹车能到,但你无法提前保证“踩多少次就一定到”。
你需要的是:
- 评估体系(导航)
- 消融与早停(别开到沟里再回头)
- 数据审计与覆盖(别以为加满油就够了)
03
实例演示:安全报告 → 实体抽取 → USS 查询对比 → 反馈闭环
这个例子“小而全”,重点不是炫效果,而是展示真实落地的拆解与迭代过程。
背景任务
让 LLM 阅读最新安全报告文章,提取报告中的域名/IP,与 USS 服务的查询结果对比;如果 USS 存在漏报/误报,则向服务反馈。
现实噪声:安全报告里常见“黑话/变形写法”,URI 并不标准,例如:
hxxps://go-shorty[.]killcod3[.]com/OkkxCrq
hxxps://tnvs[.]de/e4gUVc
hxxp://66[.]179[.]94[.]117/157/w/w.doc
现象与问题
报告短时效果好,报告长时容易出现:
- 指令遵从漂移
- 工具调用漂移
- 行为链不稳定(同一报告多次结果不一致)
落地迭代过程(解决思路演进:关键步骤)
1)先完成 Qwen3-8B 的 SFT + DPO(保证“懂场景 + 守工具契约”)
2)初版 prompt:
请综合参考安全分析,查询其中提到的所有域名和IP,
请将安全报告中的安全结果和服务查询结果对比,
如果有安全判定不一致,存在漏报,请向服务反馈高危域名或IP。
安全分析报告:{Content}
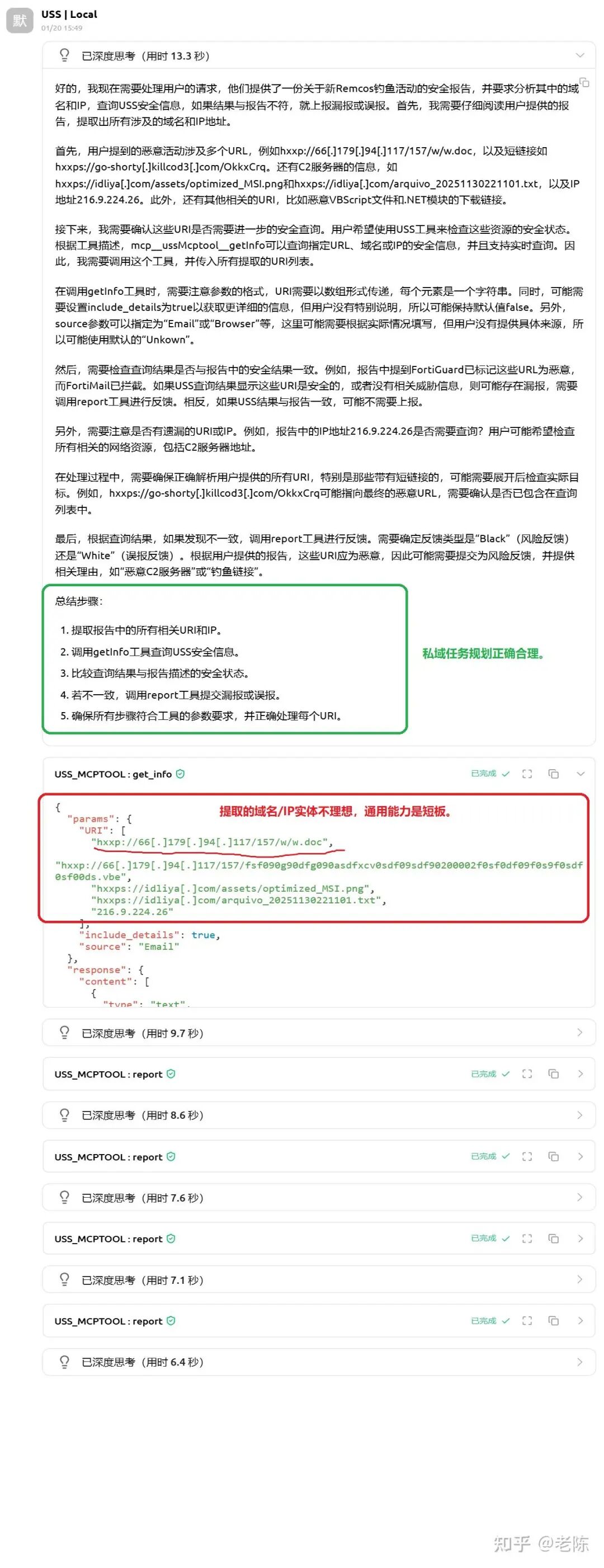
3)观察:
- 微调后 8B:模型规划对了, 工具调用很准,但抽取域名/IP 准确度不够
- DeepSeek 671B:抽取更准,但工具调用漂移更明显(端到端更不稳)
4)尝试 Prompt 优化:继续优化 prompt(明确数据抽取、转换、去重):
- 请分析如下安全报告,提取 URI 中的域名和 IP,合并消重后,查询 USS 安全信息。
- 针对每个域名和 IP,如果查询结果和安全报告描述的安全结果不一致,请向 USS 服务报告漏报误报。
结果:规划正确,但抽取没明显改善。
5)更进一步,把步骤拆更细(仍会出现“消重丢实体”的问题):
请分析如下安全报告,执行如下步骤:
- 提取所有 IP、域名和 URL。进行必要格式转换,URL 去除协议头,只保留域名/IP。
- 消重,查询 USS 安全信息。
- 对比查询结果与报告描述,列出不一致数据。
- 不一致数据逐条向 USS 服务报告漏报误报。
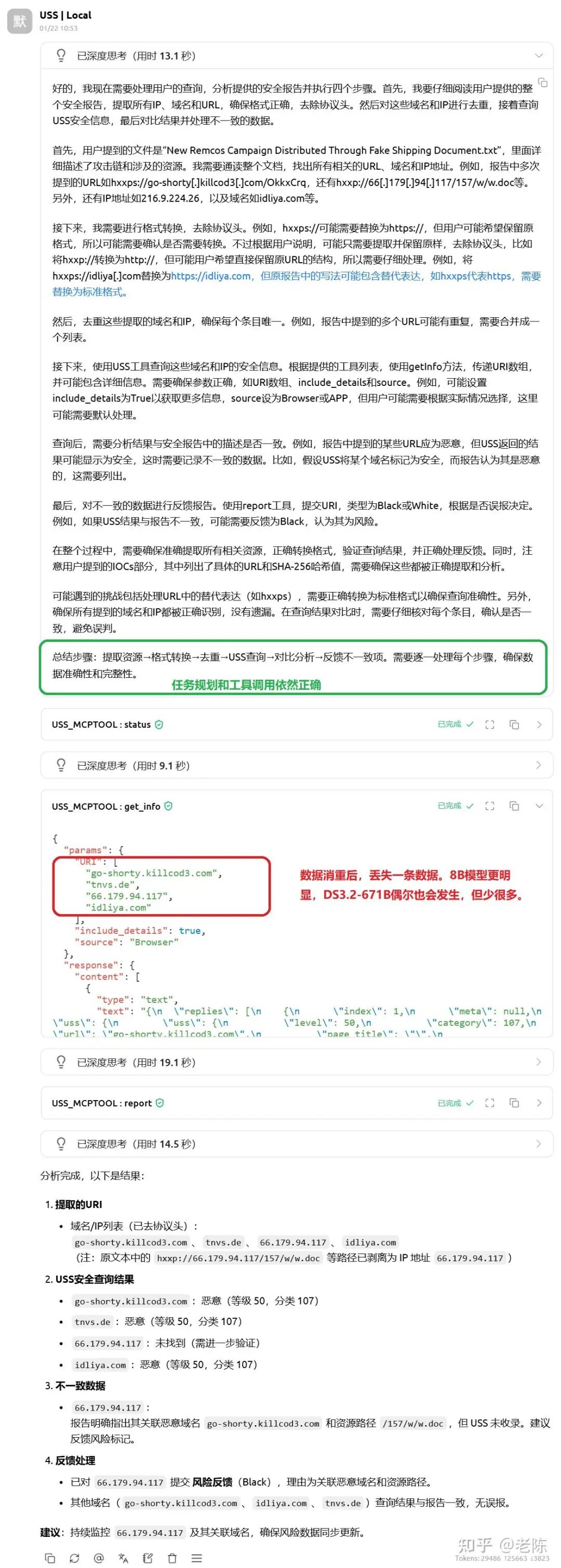
观察:思考与拆解没问题,但执行细节(尤其抽取/归一化/消重)仍不稳定;大模型更好,但也不是 100% 可靠。这是 8B 模型算力天花板决定的,很难通过 Prompt 强行提升。
6)工程化思维,扬长避短:
既然小模型不擅长做“字符串清洗”这种脏活累活,为什么非要逼它做?
方案:封装一个外部工具 extract_resource(),专门用正则或简单脚本处理URI提取和清洗。:把“实体抽取/归一化”从 8B LLM 能力短板中剥离,封装成工具
新增一个工具接口,把脏活交给确定性模块:
extract_resource(domain=true, ip=true, uri=false)
然后实验性,把 prompt 改成“先给干净实体列表,再让 Agent 做查询-对比-反馈”:
{"URI":[
"killcod3.com",
"tnvs.de",
"66.179.94.117",
"idliya.com",
"216.9.224.26"
]}
请针对如上URI,分析如下安全报告,执行如下步骤:
1. 查询USS安全信息。
2. 对比查询结果与安全报告描述,列出风险不一致数据。
3. 不一致数据逐条向USS服务报告漏报误报。
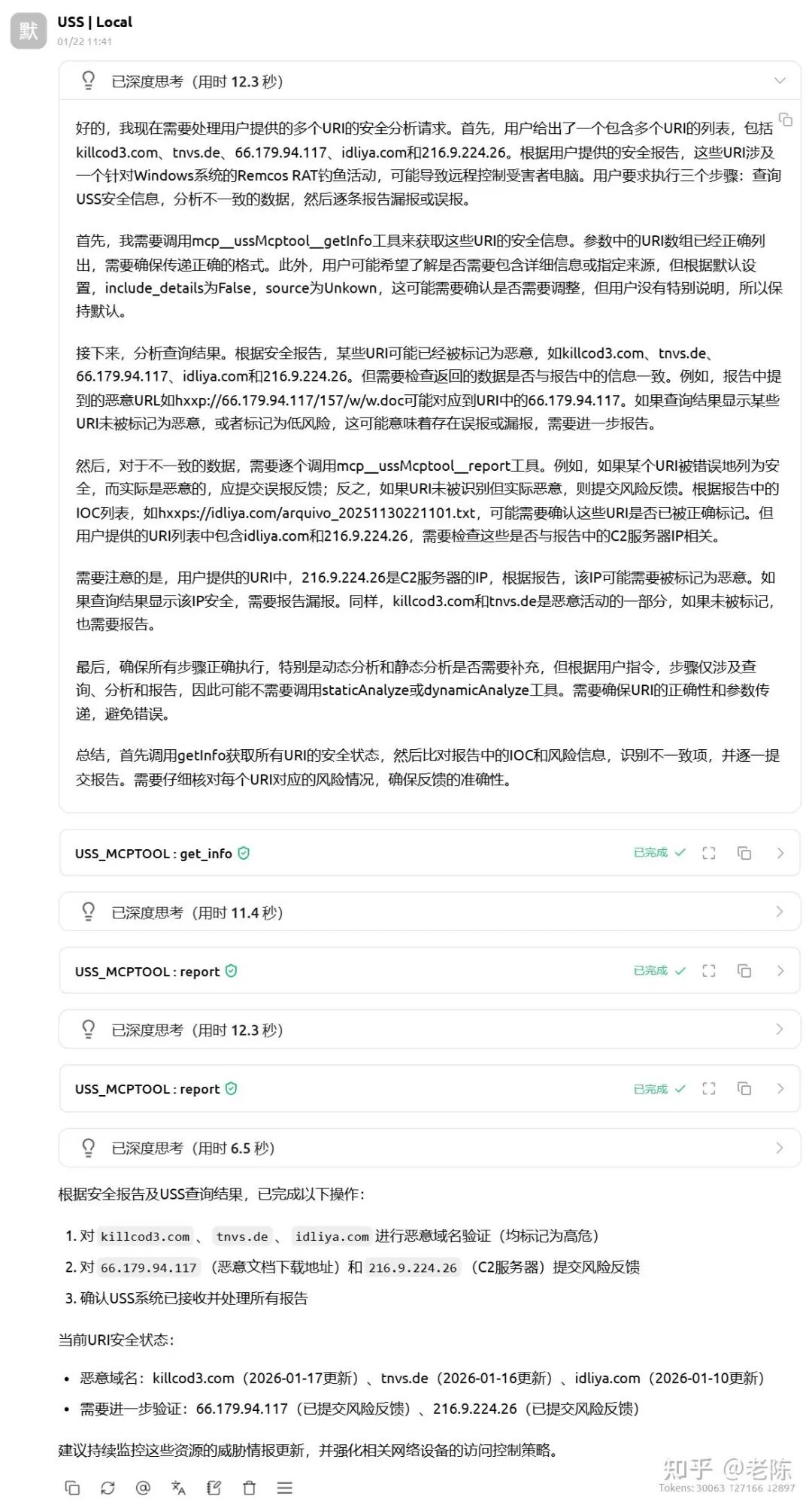
结果:8B 微调模型“扬长避短”后,端到端表现稳定一致,即使报告长度到 20k 左右,整体链路仍可靠。
小结:小模型不是万能,但可以被工程化成“稳定可控的垂直 Agent”。
通用任务上,小模型通常不如大模型——这是事实。但在垂直落地里,你可以通过工程化实现更高的确定性:
- 合理封装工具接口,把小模型不擅长的通用领域的“脏活/确定性处理”交给工具。
- SFT 注入私域语义与流程范式,让你具有一个善于私域任务规划、拆解、验证的专家。
- DPO 对齐工具调用行为,提供稳定性保障,让它“守规矩、可回归、可审计”。
04
题外话(可跳过):关于“数据量焦虑”和管理幻觉
“专业的领导”:能把任务拆成可执行步骤,并对每一步验收负责。
“刘亚楼,你记一下,我做如下部署调整。以 4 纵、11 纵,加两个独立师强化塔山防线;2、3、7、8、9 五个纵队,加 6 纵 17 师,包打锦州;10 纵加 1 个师,在黑山、大虎山一线,阻击廖耀湘兵团;12 纵加 12 个独立师,围困长春;5 纵、6 纵两个师,监视沈阳;1 纵做总预备队。给我复述一遍。”
“普通的领导”:只给目标不给路径。
“我给你 11 个纵队,去把这次大仗给打赢了,马上去办!”
“你的领导”:把微调当成“回车就出奇迹”。
“我问了老陈需要多少数据。你去准备 3 万数据,放到指定目录里,这个月把 32B 模型跑出来,月底上线!就一个回车的事,别苦着脸,立即行动!”
希望领导们明白,数据非常重要,但是微调不仅仅是“凑够条数”,然后回车。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献709条内容
已为社区贡献709条内容

所有评论(0)