1.1 大模型基础知识
这是我再学习AI大模型过程中做的笔记,分享我觉得是重点的东西,减轻记忆负担,想了解更多可以借助AI工具.
·
本节目标
- 了解大模型发展的几个重要阶段
- 知道什么是语言模型
- 掌握语言模型的评估指标
- 了解国内外主流大模型的差异
- 熟悉通用大语言模型的评估任务
一、什么是语言模型
-
核心目标:用于计算一个词序列(句子、段落)出现概率的模型。
-
通俗理解:判断一句话“是不是人话”——即计算一个句子出现的概率 P(s) 。
- 例:
- “中国的首都是北京” → 高概率
- “中国的首都是深圳” → 低概率
- 例:
-
两种视角:
- 计算整个句子的概率;
- 预测下一个词(Next Token Prediction)。
二、语言模型的发展历程(四个阶段)

1. 统计语言模型(N-gram)
用前N个词来预测下一个词
- 基于马尔可夫假设:当前词只依赖前 N−1个词。
- 常见类型:
- 1-gram(Unigram):词独立,忽略上下文 ( 不常用 )
- 2-gram(Bigram):依赖前1个词
- 3-gram(Trigram):依赖前2个词 ( 实践中常用 )
- 缺点:
- 参数空间爆炸(组合太多)
- 数据稀疏(很多词对未在语料中出现 → 概率为0)
2. 神经语言模型(Neural LM)
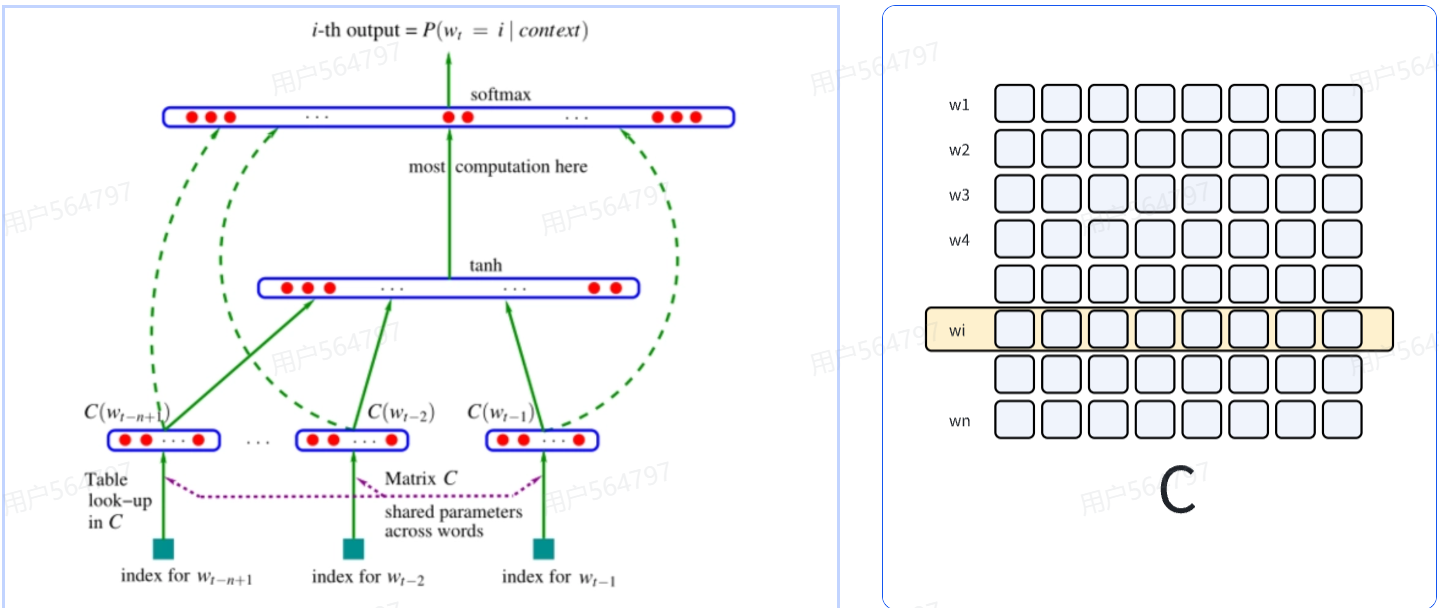
- 使用浅层神经网络(如前馈网络)建模。
- 输入:将前 n−1个词(输入层)通过词表转化的词向量拼接,
经过一个tanh引入非线性(隐藏层)
输出:经过一个全连接层映射到词表上,输出每个词的 softmax 概率(输出层)
- 优点:
- 词向量带来泛化能力,缓解数据稀疏
- 缺点:
- 固定窗口长度,无法处理长距离依赖
- 梯度消失,训练不稳定
3. 预训练语言模型(Pre-trained LM)
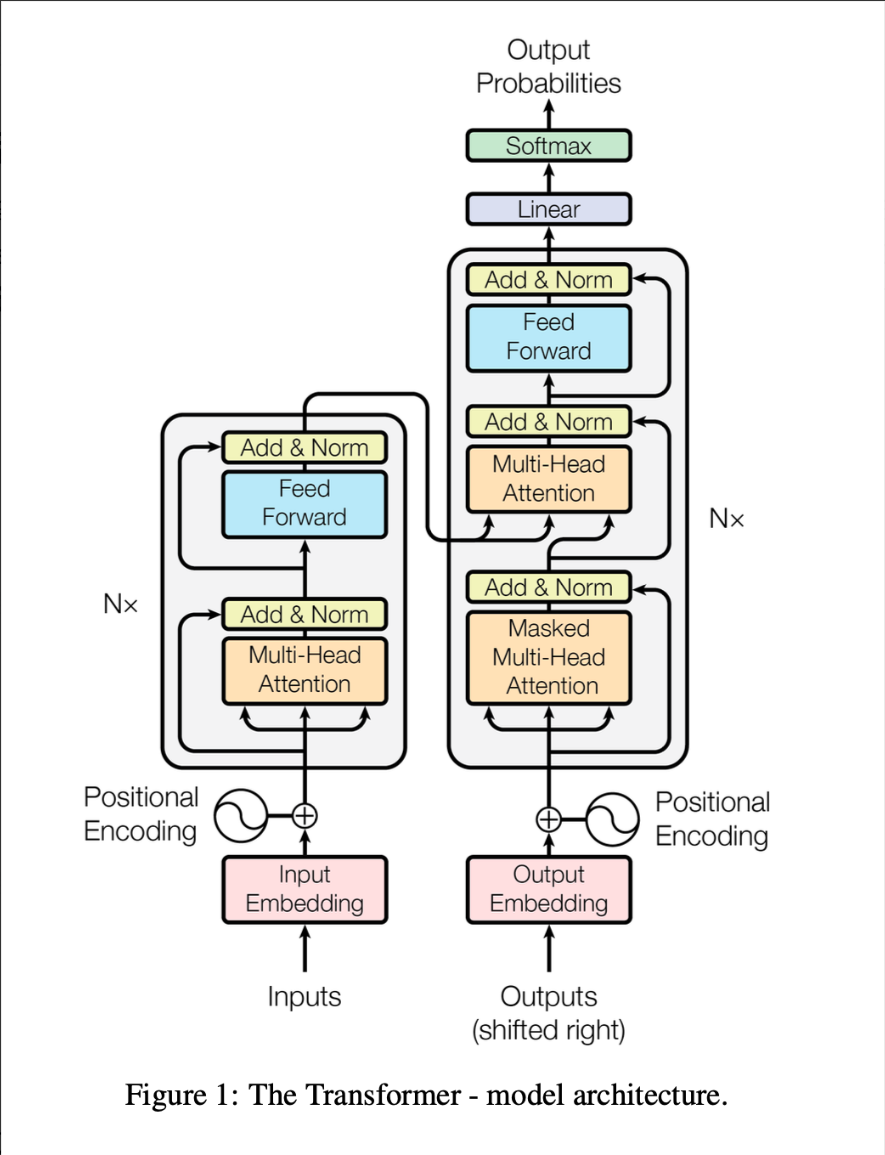
- 核心架构:Transformer
- 代表模型:BERT(Encode-only)、GPT(Decode-only)、T5(Encode-Decode)
- 两阶段范式:
- 预训练:在海量无标注文本上训练(无监督)
- 微调(Fine-tuning):下游任务中使用预训练好的模型进行迁移学习
- 优点:
- 强大的语义表示能力
- 泛化好,减少过拟合
- 缺点:
- 计算资源消耗大
- 可解释性差
4. 大语言模型(Large Language Model, LLM)
- 特征:超大规模参数 + 海量数据 + 扩展法则(Scaling Law)
- 例:GPT-3(1750亿参数) vs GPT-2(17亿)
- 关键突破:
- 涌现能力(Emergent Abilities):小模型不具备的能力(如上下文学习 ICL)
- Few-shot / Zero-shot 能力
- 优点:
- 强大生成能力(文本、多模态)
- 具备推理、工具调用潜力
- 挑战:
- 算力要求极高
- 可能生成有害/偏见内容
三、语言模型的评估指标
1. BLEU
- BLEU(Bilingual Evaluation Understudy)
- 用途:机器翻译、文本生成质量评估
- 原理:衡量生成文本(candidate)与参考文本(reference)的 n-gram 精确率
- 公式要点:
- BLEU-N:基于 N-gram 匹配
- 加权平均(通常 BLEU-1~4 各占 25%)
- 引入**长度惩罚(BP)**防止过短输出
- 注意:偏向精确率(Precision),可能高估重复内容
2. ROUGE
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
- 用途:自动摘要、问答生成
- 原理:基于 召回率(Recall),看生成内容覆盖了多少参考内容
- ROUGE-N:N-gram 召回率
- ROUGE-L:最长公共子序列(LCS)
- 与 BLEU 对比:
- BLEU → 精确率导向(生成内容有多少是对的)
- ROUGE → 召回率导向(参考内容有多少被覆盖了)
3. PPL
- PPL(Perplexity,困惑度)
- 定义:度量一个概率分布或概率模型在预测样本的好坏程度
- 公式:$ PPL(S)=P(w_1,…,w_n)^{−1/n} $
- 解读:
- PPL 越小 → 模型越好(对真实句子赋予更高概率)
- 常用于模型训练过程中的验证指标
四、通用大模型评估任务

五、国内外大模型的差异
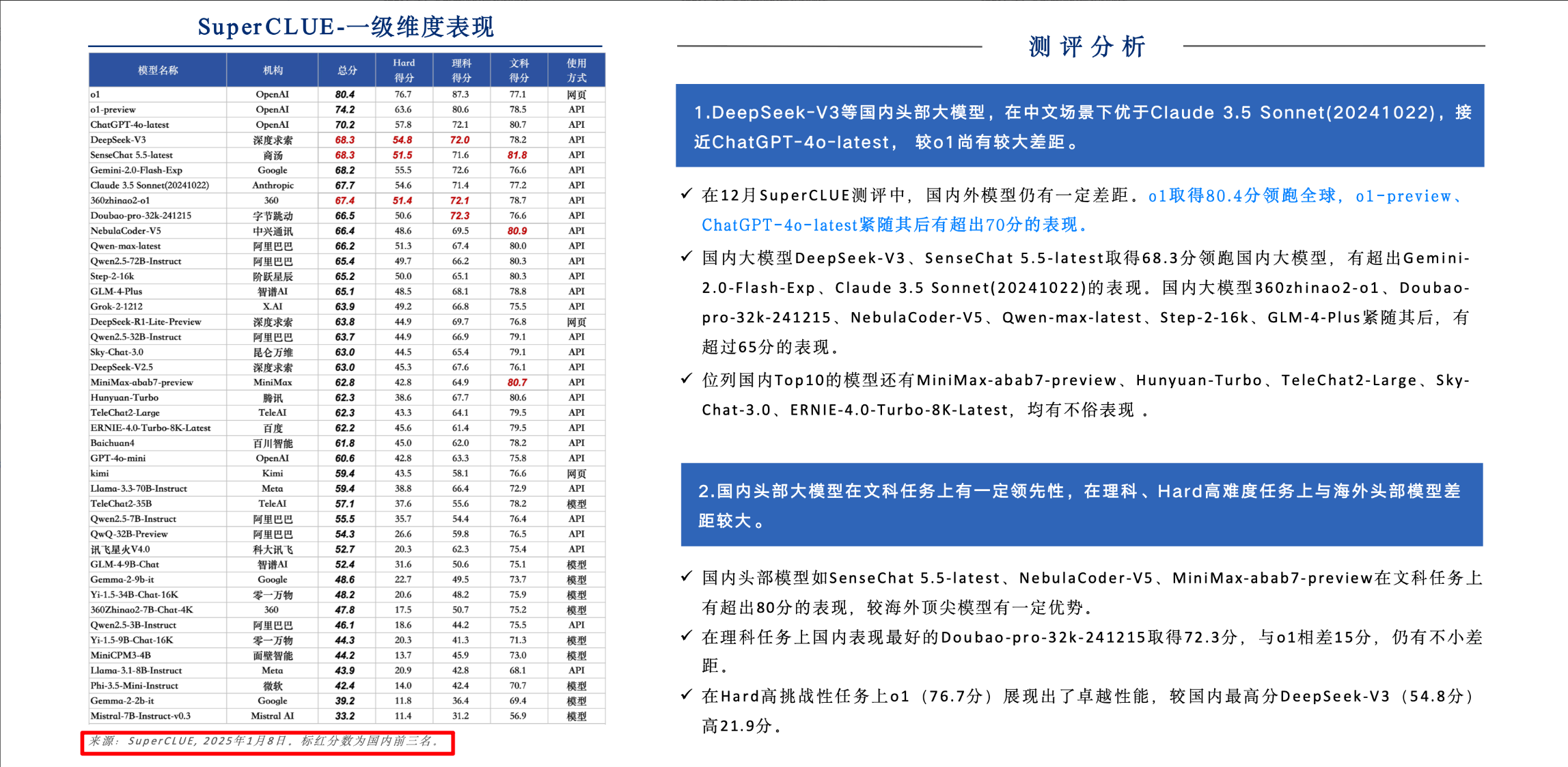
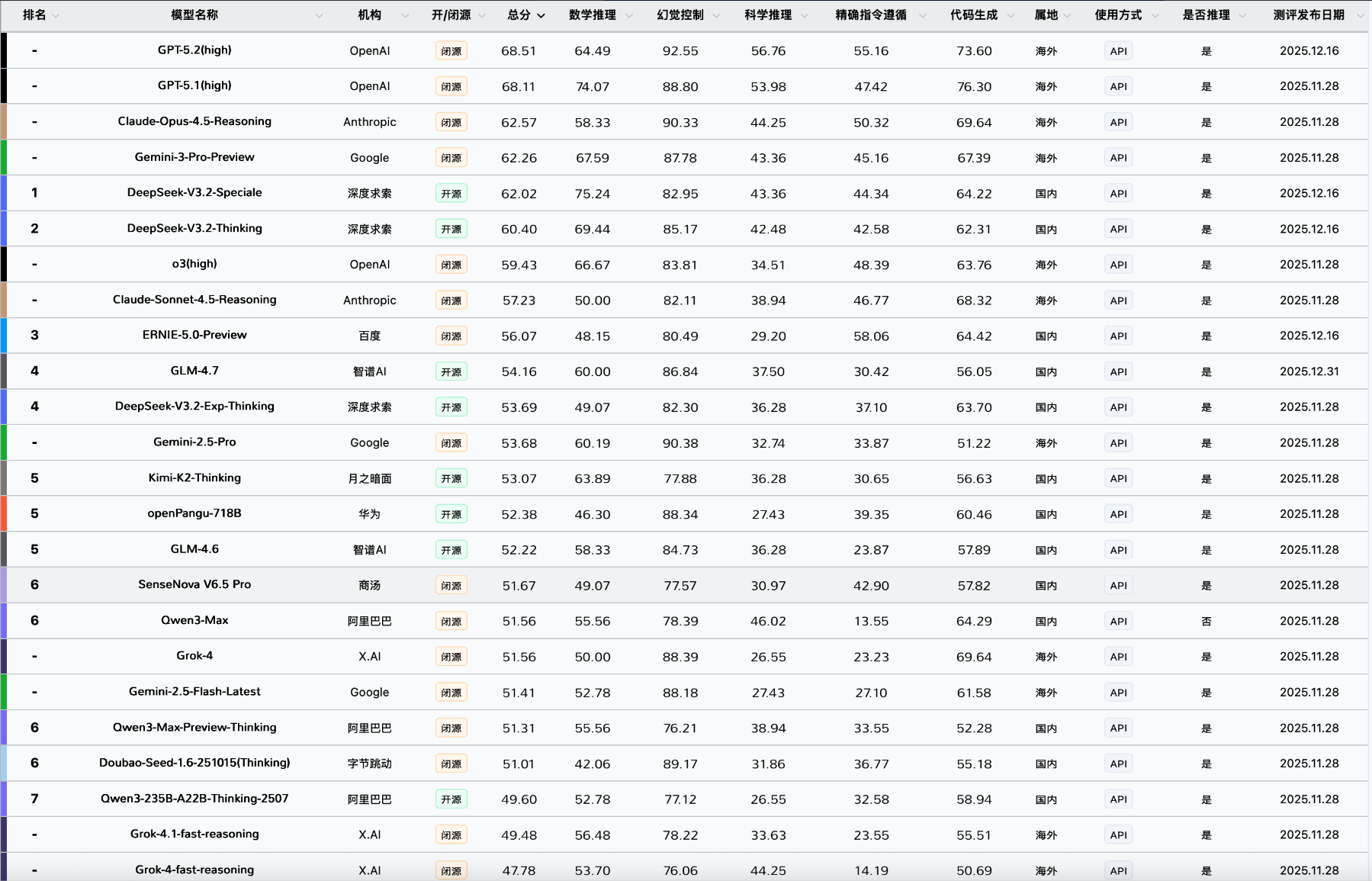
六、本小节面试可能会出现的问题
Q1:什么是语言模型?
A:语言模型建模一个词序列出现的概率,核心任务是预测下一个词或判断句子是否合理。
Q2:N-gram 有什么缺点?
A:数据稀疏(很多组合未出现)、无法处理长距离依赖、参数爆炸。
Q3:BLEU 和 ROUGE 的区别?
A:BLEU 基于精确率(生成内容有多少匹配参考),ROUGE 基于召回率(参考内容有多少被覆盖)。
Q4:PPL(困惑度)越低越好吗?
A:是的,PPL 越低说明模型对真实文本的预测概率越高,性能越好。
Q5:MMLU 评测什么能力?
A:评测模型在 57 个学科上的跨领域知识和理解能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)