【NeurIPS 2024】MDAgents:用于医疗决策的自适应大型语言模型协作
参考论文:MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making医疗决策(MDM) 是一个复杂且多维度的过程,需要解读复杂的多模态数据,包括影响,电子健康记录(EHR),生理信息和遗传信息,同时还要快速将新的医学研究整合到临床实践中。已知LLM能够处理和综合大量医学文献与临床信息,并支持概率与因果推理,但是它们
文章目录
概要
项目地址:https://github.com/mitmedialab/MDAgents
参考论文:MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making
医疗决策(MDM) 是一个复杂且多维度的过程,需要解读复杂的多模态数据,包括影响,电子健康记录(EHR),生理信息和遗传信息,同时还要快速将新的医学研究整合到临床实践中。
已知LLM能够处理和综合大量医学文献与临床信息,并支持概率与因果推理,但是它们在医疗应用中的评估却十分有限。LLM的“通用型”设计未能有效整合现实世界中系统性的医疗决策流程,而这种流程需要一种自适应,协作且分层的方法。
急诊科会根据患者病情的严重程度与复杂度进行分流:表现为典型、无并发症的急性病症,或病情稳定的慢性病患者,可由初级保健医生处理,属于低复杂度病例;而涉及多器官损伤、有副作用的慢性病,或重叠病症的患者,通常需要专科医生之间的多学科协作(MDT)或序贯会诊(ICT),属于高复杂度病例 。
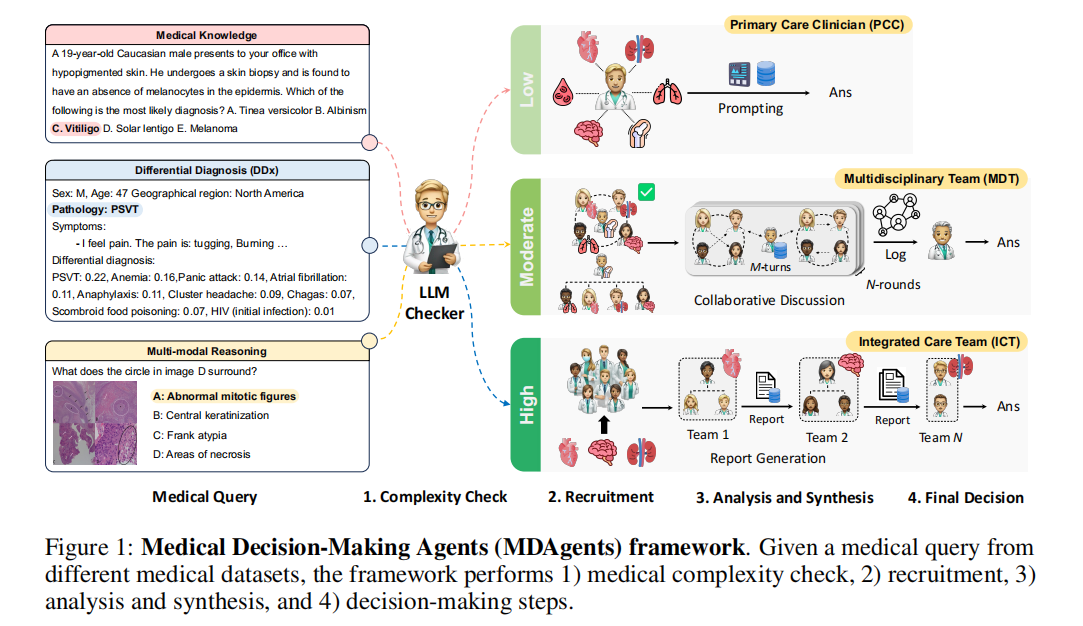
输入来自不同医疗数据集的医学查询(Medical Query),包括医学知识(如 “19 岁白人男性皮肤色素脱失,最可能的诊断是什么?” 这类纯知识题),鉴别诊断(如 “47 岁男性胸痛,给出鉴别诊断及概率” 这类临床推理题),多模态推理(如 “图像 D 中圆圈内是什么?” 这类需要结合医学影像的题)。 --------- 由LLM checker(LLM检查器)来分析问题,定义复杂度。
- 低复杂度仅调用一个初级保健医生(PCC)角色的LLM,通过简单提示直接生成答案,无需复杂协作。
- 中复杂度设计不同专科视角的问题,如胸痛可能涉及心内科,呼吸科等。需要组建一个多学科团队(MDT),包含多个不同专科的LLM agent。 agent之间进行多轮的协作讨论,并记录对话日志,最终形成答案。
- 高复杂度涉及多团队深度协作的问题,需要组建多个专业子团队,每个子团队负责一个子任务。各子团队独立分析生成报告,再由更高层的agent综合所有报告,最终形成答案。
受临床医生实际决策方式的启发,提出医疗决策智能体(MDAagents),一种自适应医疗决策框架,利用LLM模拟从个体临床医生到协作临床团队的分层诊断流程(图1)。
MDAgents的工作流程分为三步:
- Medical complexity check
- Recruitment based medical complexity
- analysis and synthesis and final decision-making to return the answer
贡献:根据任务复杂度动态调整AI agent之间的协作。在基准任务上的准确率优于以往单人与团队方法,通过调整agent数量,实现了性能与效率之间的有效权衡。在消融实验中验证了MDAgents能够为每个医疗决策实例找到合适的复杂度级别。
背景概念
为提升LLM的能力,有两种主要途径:
- 领域特定数据训练
- 推理时技术:如提示工程和检索增强生成
推理时技术 ---- 不需要重新训练模型,而是在模型做推理(回答问题,生成内容)的环节上进行优化。
提示工程 ---- 通过设计提问方式(思维链 CoT,少样本 Few-shot),引导模型输出更准确且符合要求的结果。
早期研究只要集中在使用医学知识进行预训练与微调,通用LLM的兴起催生了无需训练的方法(利用模型潜在的医学知识)。通用模型的潜力激发了Medprompt和集成优化等技术,以改进LLM的推理能力,以及RAG工具以利用外部资源提升LLM响应的真实性与完整性。 — 像MEDIQ和UoT这样的框架,通过自适应提问和不确定性降低来提升临床环境下LLM的可靠性,支持更贴合现实的诊断流程。
Medprompt ,集成优化:这类技术属于提示工程,通过优化提示词的设计,来激发LLM更好的推理能力。
本文方法借鉴了这些技术和通用模型的能力,同时认识到单个LLM可能无法完全覆盖现实世界医疗决策的协作与多学科本质。 ---- 为了更准确的解决复杂医疗任务,需要联合多个专业LLM进行有效协作。
多agent协作:
已有大量研究探索了多智能体LLM之间的有效协同框架,以超越单个LLM的能力。
- 角色扮演:每个agent扮演特定角色,任务被分解为多个子步骤并协作解决。
- 多智能体辩论:每个agent独立解决任务,通过其他agent的答案迭代答成共识。这种方法可以提升多智能体解决方案的真实性,数学能力和推理能力。
尽管这些框架在各自任务上表现出改进,但它们依赖于预先确定的agent数量和交互设置。当应用于更广泛的任务时,这种静态架构可能导致次优的多智能体配置,从而对性能产生负面影响。
此外多智能体方法存在计算效率低下或部署成本高昂的风险,需要通过显著的性能提升来证明其成本合理性。
基于上面的问题,本文提出的框架能够根据查询的复杂度在推理时分配最优协作策略。
MDAgents:医疗决策智能体
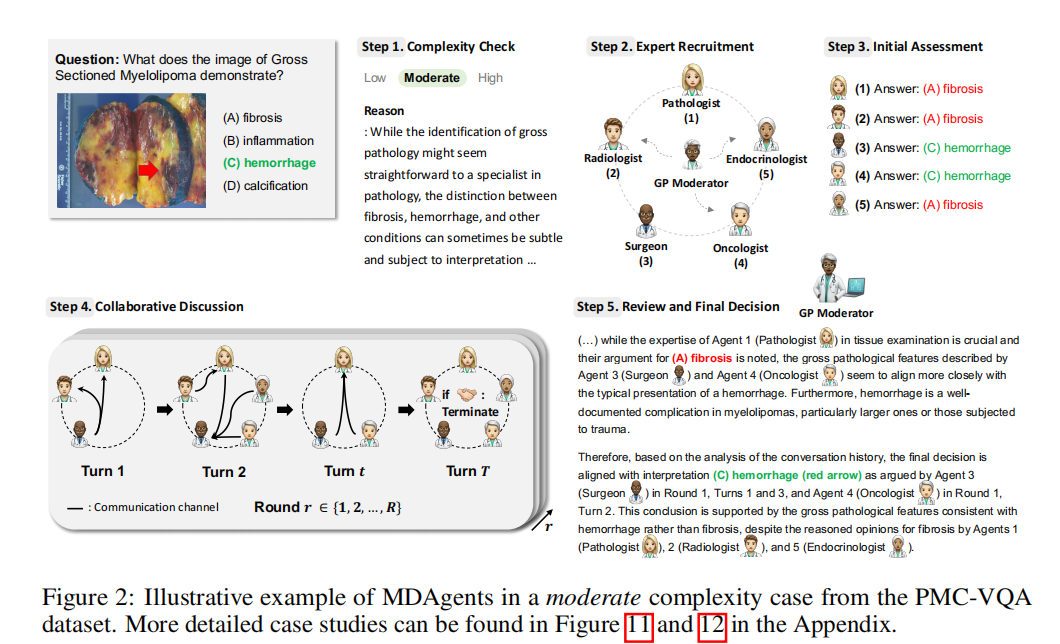
上图以 中等复杂度病例 为例,用一个来自PMC-VQA数据集的具体兵力展示多学科团队(MDT)模型的运作细节。
- 问题:大体切片骨髓瘤(Gross Sectioned Myelolipoma)的图像显示了什么?A. 纤维化(fibrosis) B. 炎症(inflammation) C. 出血(hemorrhage) D. 钙化(calcification)
- 复杂度检查:纤维化、出血等情况的区分有时很微妙,需要多学科视角来确认。
- 专家招募:根据问题的病理、影像、临床背景,组建一个多学科团队,包括 病理学家(Pathologist),放射科医生(Radiologist),全科协调医生(GP Moderator),外科医生(Surgeon),内分泌科医生(Endocrinologist),肿瘤学家(Oncologist)
- 初始评估:每个专家给出初始答案
- 协作讨论:专家进行多轮协作讨论,通过沟通渠道交换观点,相互说服。
- 审核与最终决策:虽然病理学家和放射科医生的意见很有道理,但外科医生和肿瘤学家提出的出血特征更具说服力。
MDAgents的设计(图1,图2)包括四个阶段:
- medical complexity check : 系统评估医疗查询,根据临床决策技术将其分类为低,中,高三个复杂度级别。
- expert recruitment : 基于复杂度,框架为低复杂度问题激活单个初级保健医生(PCP)agent,为中高复杂度问题激活多学科团队(MDT)或整合医疗团队(ICT)。
- analysis and synthesis : 单人查询使用思维链(CoT)和self-consistency(SC)等提示技术;多学科团队由多个LLM agent组成以达成共识; 整合医疗团队则为最复杂病例综合信息。
- decision_making :最终阶段综合所有输入,为医疗查询提供充分依据的答案。
agent roles
- 协调者(moderator):作为全科医生或急诊科医生,负责对医疗查询进行分流。该智能体评估问题的复杂度,决定应由单个智能体、多学科团队还是整合医疗团队处理。协调者确保根据查询复杂度选择合适的路径,并监督整个决策过程。
- 招募者(Recruiter):负责根据协调者的复杂度评估,组建合适的专家团队。招募者可为低复杂度病例分配单个初级保健医生智能体,为中高复杂度病例组建相关专业的多学科团队或整合医疗团队。
- 全科医生 / 专科医生(General Doctor/Specialist):这些是由招募者招募的领域特定或全科医生智能体。根据病例复杂度,他们可以独立工作或作为团队的一部分。全科医生处理低复杂度、常规病例,而专科医生则在更复杂的场景中凭借其特定专业知识被招募。这些智能体参与协作决策过程,贡献专业知识以达成共识,并为高复杂度病例提供详细报告。

medical complexity classification (Line 1 of Algorithm 1,Appendix C.2)
MDAgents 框架的第一步是由作为全科医生(GP)的协调者大语言模型确定给定医疗查询q的复杂度。协调者作为分类器返回查询的复杂度级别,它被提供了医疗复杂度的定义信息,并被指示将查询分为三个不同的复杂度级别:
- 低复杂度:简单、定义明确的医学问题,可由单个初级保健医生智能体解决。这些通常包括常见、急性疾病或稳定的慢性病,其医疗需求可预测,且只需极少的跨学科协调。
- 中复杂度:涉及多个相互作用因素的医学问题,需要多学科团队的协作方法。这些场景需要整合不同医学知识领域,并需要专科医生之间的协商以制定有效的护理策略。
- 高复杂度:需要广泛协调和来自整合医疗团队的综合专业知识的复杂医学场景。这些病例通常涉及多种慢性病、复杂的外科或创伤病例,以及需要来自不同医疗部门的专家整合的决策。
expert recruitment (Line 3,7,17 of Algorithm)
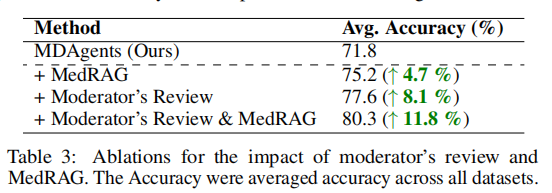
给定医疗查询,招募者大语言模型的目标是根据协调者大语言模型确定的复杂度级别,以个人、团队或多团队的形式招募领域专家。为多个大语言模型分配医学专业知识和角色,指示它们要么独立处理医学病例,要么作为团队与其他医学专家协作。在附录图 9 中,为每个基准提供了常见招募的智能体作为参考。
medical collaboration and refinement
具体的优化方法:
- 低复杂度 (简单病例) :对于分类为低复杂度的查询,其特征是明确的临床决策路径,部署单个初级保健医生智能体。由招募者大语言模型招募的领域专家大语言模型应用少样本提示。输出答案直接从智能体对 Q Q Q 的响应中获得,无需迭代优化,形式化为:
a n s = Agent ( Q ) ans = \operatorname{Agent}\left( Q\right) ans=Agent(Q)其中Agent表示参与的初级保健医生智能体。 - 中复杂度(中等病例):框架通过结构化、分层的协作方法专门解决中等复杂度的查询。由招募者LLM招募的多学科团队启动迭代讨论过程,旨在最多经过 R R R 轮(第 10-12 行)达成共识。对于每一轮 r ∈ R r \in R r∈R ,智能体 A i , i = 1 , … , N {A}_{i},i = 1,\ldots ,N Ai,i=1,…,N 表明参与意愿并选择偏好的对话者。系统促进消息交换 T T T 轮。如果未达成共识且智能体同意继续,则开始新一轮并可访问之前的对话。对于每一轮,多学科团队内的共识通过解析和比较他们的意见来确定。若出现分歧,协调者智能体会审查多学科团队的讨论并为每个智能体制定反馈。
- 高复杂度(复杂病例):这一过程的关键组成部分是提示中描述的报告生成过程,每个团队在首席临床医生的带领下,协作生成一份综合报告。因为每个团队都在之前团队奠定的基础上继续工作,确保对复杂病例进行细致且完善的检查。在整合医疗团队过程中生成的最终报告不仅反映了全面的医疗评估,还体现了系统性和分层分析,这在管理复杂健康场景时至关重要。
diecison-making
在我们框架的最终阶段,决策智能体综合整个决策过程中产生的各种输入,以得出医疗查询 q q q 的有充分依据的最
终答案。这种综合根据查询的复杂度级别涉及多个组成部分:
- 低复杂度:直接利用主要决策智能体的初始响应。
- 中复杂度:纳入所招募智能体之间的对话历史(交互),以理解其响应中的细微差别与分歧。
- 高复杂度:考虑智能体生成的详细报告(报告),其中包括对其诊断建议的全面分析和理由。
决策过程形式化为 a n s = A g e n t ( ⋅ ) a{ns} = \mathrm{{Agent}}\left( \cdot \right) ans=Agent(⋅) ,其中最终答案 a n s a{ns} ans 通过基于医疗复杂度综合分析与综合的输出来确定。这种整合采用集成技术来确保决策的鲁棒性,并在适用时反映模型之间的共识。
集成技术指综合多个agent的输出,来提升最终结果的稳定性和准确性。比如多数投票:统计多个专家的以间,以多数结果为准。加权融合:给不同可信度的专家意见赋予不同的权重,在综合计算。
实验部分
为验证框架的有效性在10个数据集上与基线方法进行全面实验。每个数据集测试了50个样本,每个复杂度级别的推理时间平均为:低复杂度14.7秒,中复杂度95.5秒,高复杂度226秒。 在定量实验中,比较了三种设置:
- 单人(solo):在决策过程中使用单个LLM agent。
- 团队(Group):在决策过程中实现多智能体协作。
- 自适应(Adaptive):本文提出的MDAgents方法,根据查询复杂度动态构建从初级保健医生到多学科团队和整合医疗团队的推理结构。
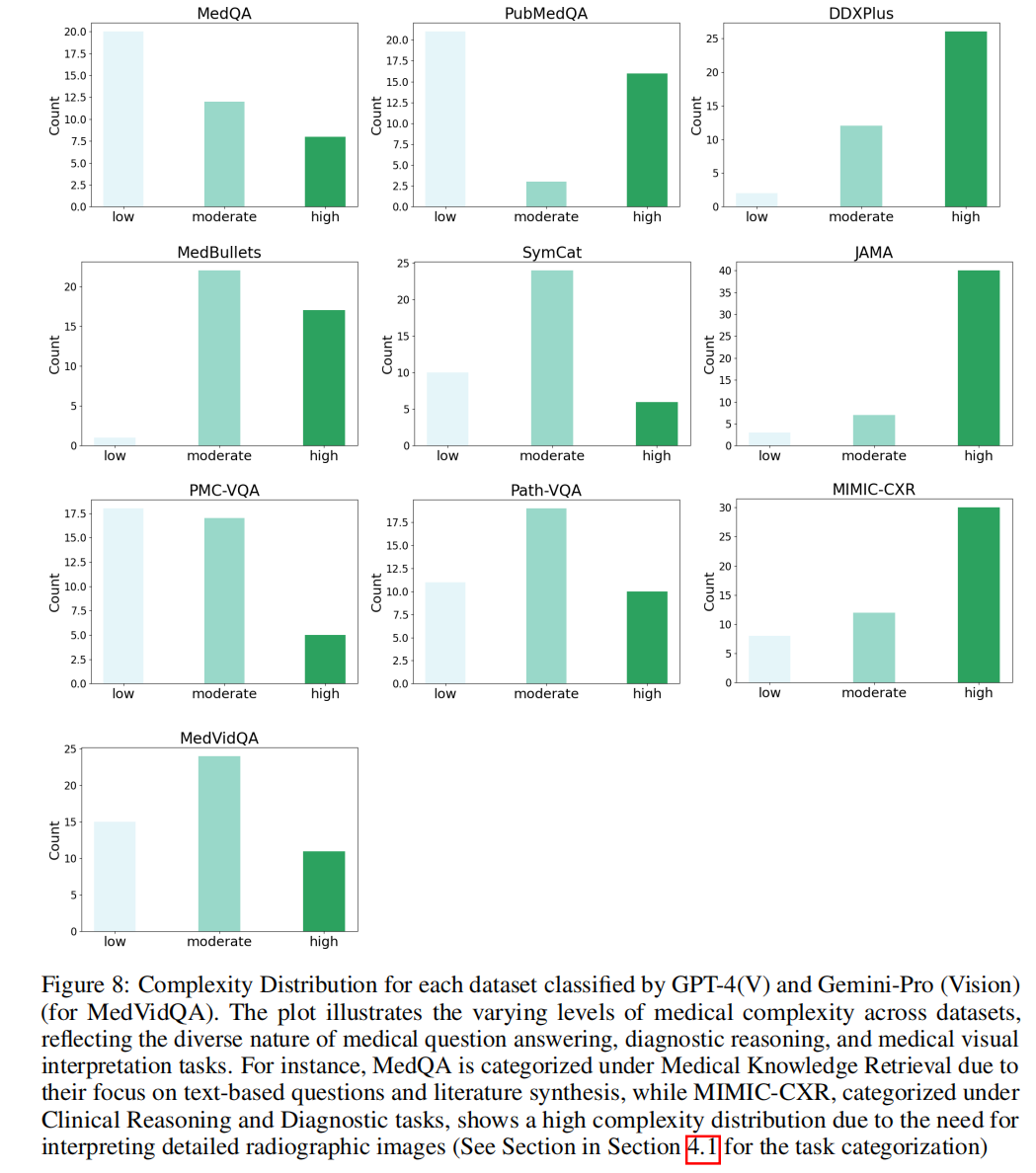
上图展示了GPT-4和Gemini-pro 对10个数据集按照复杂度级别进行分类后的数量分布,反映不同医疗任务的难易差异。 ----- 这张图量化了不同医疗任务的难度分布,也从数据上验证了MDAgents框架 按复杂度动态分配资源 的涉设计是合理且有必要的。它解释了为什么一个自适应的多智能体系统,在处理不同类型的医疗问题时,比单一模型或静态团队更具优势。
在所有设置中,对低复杂度病例使用 3-shot 提示,对中高复杂度病例使用 zero-shot 提示。
3-shot 提示:在提问时,给模型提供三个类似问题和正确答案作为示例,引导学习解题模式。
zero-shot 提示:不给任何示例,基于自身知识进行推理和回答。 中高复杂度病例往往是开放性,非标准化的,设计多模态信息,多学科协作,没有固定的解题模式。
- 医疗问答:在 MedQA [35]、PubMedQA [30]、MedBullets [9] 和 JAMA [9] 上,我们专注于通过文本进行问答,涉及基于文献和概念的医学知识问题。具体而言,PubMedQA 要求模型使用 PubMed 摘要回答问题,需要综合生物医学信息。 MedQA 测试模型理解和回答源自医学教育材料与考试的多项选择题的能力。 MedBullets 提供 USMLE Step 2/3 类型的问题,需要应用医学知识与临床推理。 JAMA 临床挑战提出具有挑战性的真实世界临床病例,包含诊断或治疗决策问题,测试模型的临床推理能力(附录图 8 展示了每个数据集的复杂度分布)。
- 诊断推理:DDXPlus [73] 和 SymCat [2] 涉及临床病例,需要鉴别诊断,密切模拟医生的诊断过程。这些任务测试模型通过症状和临床数据推理以提出可能的医学状况的能力,评估 AI 的诊断推理能力,类似于临床环境。SymCat [2] 使用从公共疾病 - 症状源构建的合成患者记录,并通过 NLICE 方法增强了额外的上下文信息。
- 医学视觉解读:Path-VQA [80]、PMC-VQA [95]、MedVidQA [29] 和 MIMIC-CXR [89] 挑战模型解读医学影像与视频,需要整合视觉数据与临床知识。 Path-VQA 专注于回答基于病理图像的问题。 PMC-VQA 评估模型从科学出版物中的文本和图像中推导答案的能力。 MedVidQA 扩展到基于视频的内容,AI 模型需要处理医学操作视频中的信息。 MIMIC-CXR-VQA 专门针对胸部 X 光片,利用多样化且大规模的数据集设计用于医学领域的视觉问答任务。
基线方法
单人:单人设置考虑的基线方法包括:
- Zero-shot [41]:直接使用提示促进推理。
- Few-shot [83]:使用少量示例。
- Few-shot CoT:在推导答案之前整合推理过程。
- Few-shot CoT-SC [82]:在 Few-shot CoT 的基础上,通过采样多条链以产生多数投票结果。
- 集成优化(ER) [67]:一种提示策略,通过多条推理路径调节模型响应,以增强大语言模型的推理能力。
- Medprompt [59]:多种提示策略的组合,可提升大语言模型在多个基准数据集(包括医疗与非医疗数据集)上的性能,并实现最先进的结果。
团队:我们测试了五种团队决策方法:
投票 [82]、MedAgents [72]、ReConcile [10]、AutoGen [86] 和 DyLAN [51]。AutoGen 基于四个智能体(用户、临床医生、医学专家、协调者),每个智能体一个响应 [86]。DyLAN 设置遵循四个智能体的基础实现,无特定角色,最多交互四轮 [51]。尽管这些方法支持多模型,但所有智能体均使用 GPT-4。
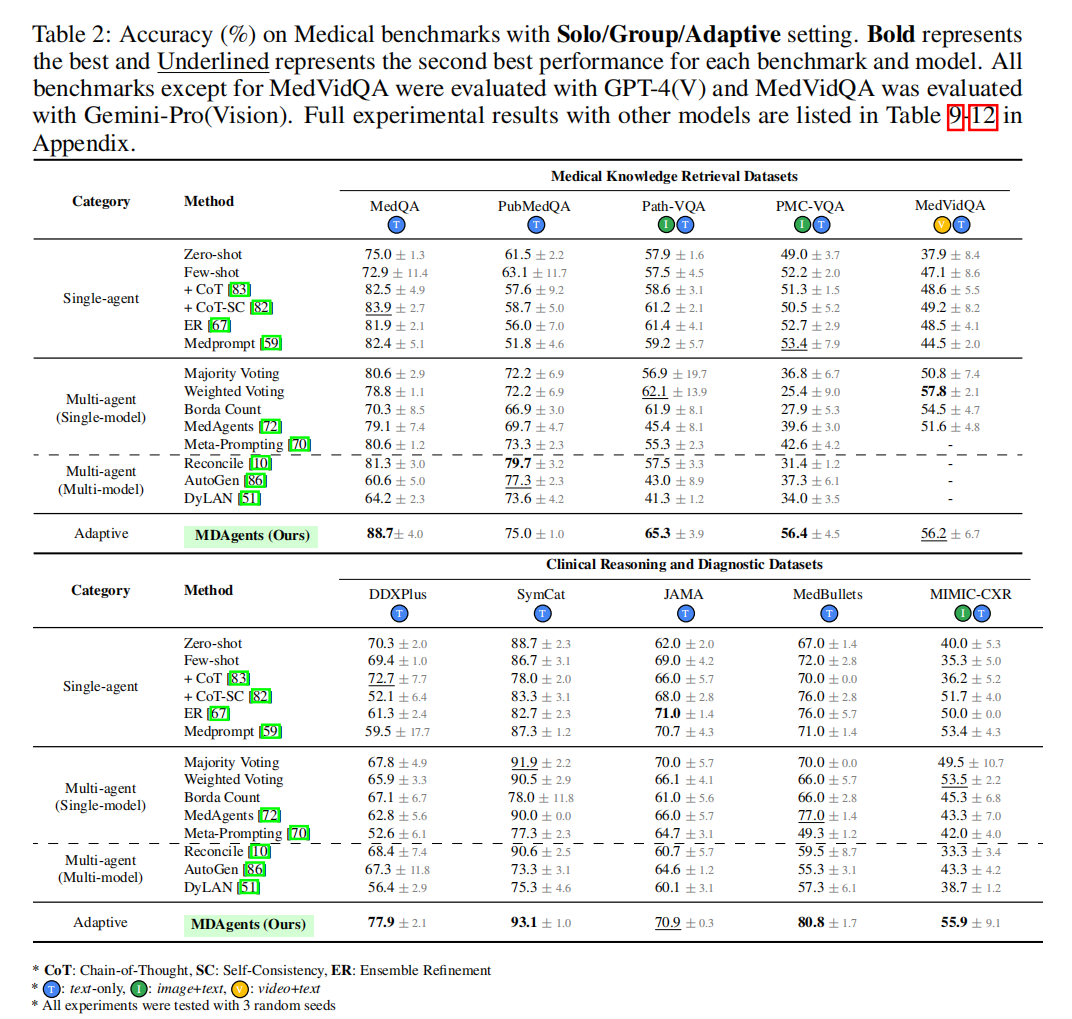
在 表2 中报告了不同数据集上的分类准确率。将本文自适应的方法与单人及团队设置下的多个基线进行了比较。
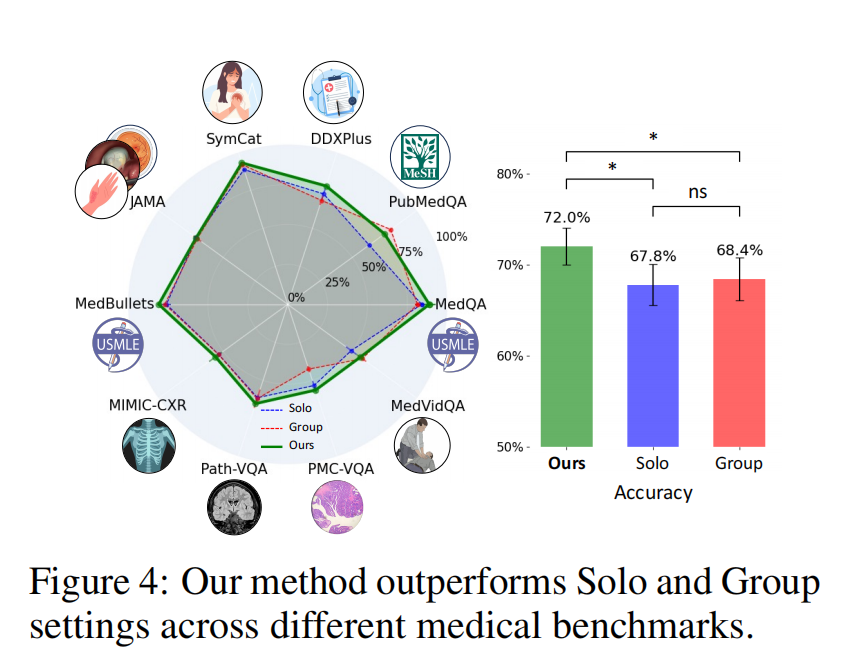
自适应方法优于单人及团队设置
如图 4 和表 2 所示,MDAgents 显著优于(p < 0.05)所有单人及团队设置方法,在测试的 10 个医疗基准任务中有 7 个取得了最佳性能。这揭示了我们系统中集成的自适应策略的有效性,特别是在处理纯文本(如 DDXPlus,本文的方法比单人方法的最佳性能高 5.2%,比团队方法高 9.5%)和文本 - 图像数据集(如 Path-VQA、PMC-VQA 和 MIMIC-CXR)时。本文的方法不仅能以高精度理解文本信息,还能熟练地综合视觉数据,这是医学诊断评估中的一项关键能力。
为什么自适应决策框架表现优异?
核心问题在于大语言模型能否对医学问题的难度进行适当分类。如果大语言模型对难度级别的分类不准确,选择的解决方案可能不合适,从而可能导致错误的决策。因此,理解什么构成适当的难度级别至关重要。
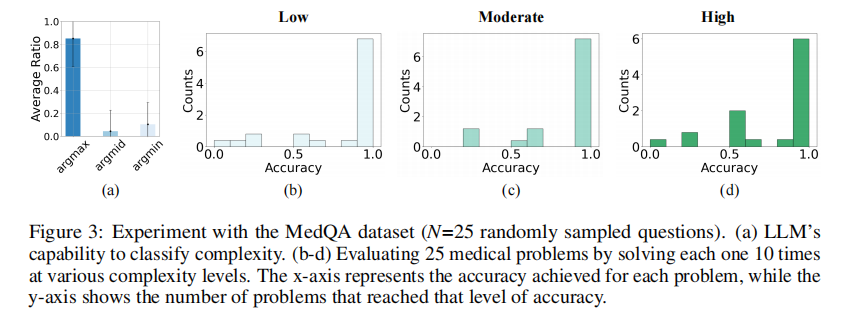
结论:LLM本身就具备相当准确的难度分类能力,这使得MDAgents能为每个医疗问题匹配合适的复杂度级别,从而选择最优的解决方案。 ----- 在不同复杂度设置下,每个问题重复求解10次,以评估LLM的复杂度分类和对应设置下的准确率。
我们假设,作为分类器的大语言模型将为每个医疗决策问题选择最优复杂度级别。图 3 支持了这一假设,该图显示模型能为给定问题适当匹配低、中、高复杂度级别。
为确定这一点,评估了不同难度级别下解决方案的准确率。具体而言,通过在每个难度级别上重复每个问题 10 次来评估 25 个医学问题的准确率。通过测量成功率,旨在确定能产生最高准确率的难度级别。这种方法确保大语言模型的复杂度分类与最有效、最准确的医学解决方案保持一致,从而优化每个问题的专业知识应用。
形式上,对于任意给定问题 P P P ,我们用 p complexity-level ( P ) {p}_{\text{complexity-level}}\left( P\right) pcomplexity-level(P) 表示在特定复杂度级别上可以解决正确答案的概率,其中complexity-level ∈ { \in \{ ∈{ low,moderate,high } \} } 。 arg max ( P ) ∈ { \arg \max \left( P\right) \in \{ argmax(P)∈{ low,moderate,high } \} } 表示具有最高概率的复杂度级别,即 arg max ( P ) = arg max { p l o w ( P ) , p m o d e r a t e ( P ) , p h i g h ( P ) } \arg \max \left( P\right) = \arg \max \{ {p}_{\mathrm{{low}}}\left( P\right) ,{p}_{\mathrm{{moderate}}}\left( P\right) ,{p}_{\mathrm{{high}}}\left( P\right) \} argmax(P)=argmax{plow(P),pmoderate(P),phigh(P)} 。类似地, arg min ( P ) \arg \min \left( P\right) argmin(P) 是概率最低的复杂度级别, arg m i d ( P ) \arg \mathrm{{mid}}\left( P\right) argmid(P) 是概率居中的复杂度级别。我们用 a , b , c a,b,c a,b,c 分别表示大语言模型选择对应 arg max , arg mid , arg min \arg \max ,\arg \operatorname{mid},\arg \min argmax,argmid,argmin 的复杂度级别的概率。那么,我们系统对问题 P P P 的准确率可以描述为:
a ⋅ p arg max ( P ) + b ⋅ p arg mid ( P ) + c ⋅ p arg min ( P ) a \cdot {p}_{\arg \max }\left( P\right) + b \cdot {p}_{\arg \operatorname{mid}}\left( P\right) + c \cdot {p}_{\arg \min }\left( P\right) a⋅pargmax(P)+b⋅pargmid(P)+c⋅pargmin(P)
总体准确率为:
E P [ a ⋅ p arg max ( P ) + b ⋅ p arg mid ( P ) + c ⋅ p arg min ( P ) ] {\mathbb{E}}_{P}\left\lbrack {a \cdot {p}_{\text{arg max }}\left( P\right) + b \cdot {p}_{\text{arg mid }}\left( P\right) + c \cdot {p}_{\text{arg min }}\left( P\right) }\right\rbrack EP[a⋅parg max (P)+b⋅parg mid (P)+c⋅parg min (P)]
a , b , c a,b,c a,b,c 的估计值为 a = 0.81 ± 0.29 a = {0.81} \pm {0.29} a=0.81±0.29 , b = 0.11 ± 0.28 b = {0.11} \pm {0.28} b=0.11±0.28 , c = 0.08 ± 0.16 c = {0.08} \pm {0.16} c=0.08±0.16 ,这表明大语言模型能以至少 80%的概率提供最优复杂度级别。
这些发现表明,作为分类器的大语言模型可以隐式模拟各种复杂度级别,并能最优地适应每个医学问题所需的复杂度,如图 3 所示。这种动态调整复杂度的能力被证明对于在医疗决策环境中有效应用大语言模型至关重要,正如我们自适应方法的竞争力所展现的那样。
医疗决策中的单人 vs. 团队设置
实验结果揭示了单人及团队设置在各种医疗基准上的不同性能模式。在像 MedQA 这样的简单数据集中,单人方法(利用 Few-shot CoT 和 CoT-SC)达到了 83.9% 的准确率,而团队方法仅为 81.3%。相反,在像 SymCat 这样更复杂的数据集中,团队设置表现更好,SymCat 在团队设置中的准确率为 91.9%,而在单人设置中为 88.7%。
值得注意的是,在多模态数据集(如 Path-VQA(图像 + 文本)、MedVidQA(视频 + 文本)和 MIMIC-CXR(图像 + 文本))中,团队设置(如加权投票、ReConcile)表现更好,突出了在复杂任务中协作策略的优势。这一结果与 [4] 的发现一致,该发现表明,医生群体的汇总诊断显著优于个体医生,且准确率随群体规模的增加而提高。
总体而言,单人设置在 4 个基准上优于团队设置,而团队设置在 6 个基准上优于单人设置。这些结果表明,虽然单人方法在简单任务中表现出色,但团队设置在需要多样化专业知识的复杂、多维度任务中提供了更好的性能。
消融实验
复杂度选择的影响
我们通过消融实验(图 5)评估了复杂度评估与自适应过程的重要性。我们的自适应方法在不同模态基准上显著优于静态复杂度分配。对于纯文本查询,自适应方法的准确率为 81.2%,显著高于低复杂度(64.2%)、中复杂度(71.6%)和高复杂度(65.8%)设置。有趣的是,64% 的纯文本查询被分类为高复杂度,表明许多基于文本的查询需要不同专业知识的深入分析。
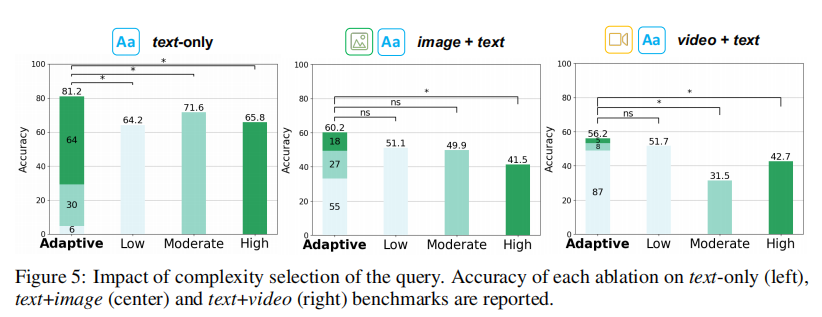
在图像 + 文本模态中,自适应方法将 55% 的查询分类为低复杂度,表明视觉信息通常提供清晰直接的线索,简化了决策过程。最后,对于视频 + 文本查询,87% 的查询被分类为低复杂度,反映出动态视觉数据与文本结合通常可以直接解读。然而,如 MedVidQA(相对较少的复杂医学知识)所示,需要对更具挑战性的视频医学数据集进行进一步评估。
协调者审核与 RAG 的影响
表 3 探讨了将外部医学知识和协调者审核纳入 MDAgents 框架对准确率的影响。MedRAG [89] 是一个系统的检索增强生成(RAG)工具包,利用各种语料库(生物医学、临床和普通医学)提供全面的知识。MDAgents 的基线准确率为 71.8%。整合 MedRAG 将准确率提高到 75.2%(提升 4.7%),而协调者审核进一步将准确率提高到 77.6%(提升 8.1%)。两种方法的结合达到了最高准确率 80.3%(提升 11.8%)。
结果表明,MedRAG 和协调者审核都能提高性能,它们的组合效应具有协同性。这凸显了利用最新外部知识和结构化反馈机制对于完善和达成准确医疗决策的重要性。这种改进强调了混合策略的重要性,与现实世界中持续学习和专家咨询以优化医疗应用性能的实践保持一致。
团队设置中智能体数量的影响
我们在协作团队设置中对不同数量的智能体进行了实验,结果表明,智能体数量的增加并不一定会带来更好的性能。相反,我们的自适应方法通过智能地校准协作智能体的数量,用更少的智能体(N=3,峰值准确率 83.5%)实现了最优性能。这不仅表明了决策中的效率,还带来了计算和经济效益,因为与单人及团队设置相比,API 调用次数减少了。
关于计算效率,单人设置(5-shot CoT-SC)导致 6.0 次 API 调用,而团队设置(MedAgents,N=5)导致 20.3 次 API 调用,计算成本高但准确率没有相应提高。另一方面,我们的自适应方法展现了更经济的资源使用,API 调用次数更少(N=3 时为 9.3 次),同时保持了高准确率,这是部署可扩展且具有成本效益的医疗 AI 解决方案的关键因素。
不同参数下的鲁棒性
我们的自适应方法对温度变化(低温度 T=0.3 和高温度 T=1.2)表现出鲁棒性,在较高温度下性能有所提升。这表明我们的模型可以利用较高温度下产生的创造性和多样化输出来增强决策能力,这一特性在单人及团队设置中并不显著。这种鲁棒性在具有高度不确定性和数据集模糊性的现实世界医疗领域中尤为宝贵 [15]。此外,研究表明,创造性的诊断方法可以提高诊断准确性 [88]。
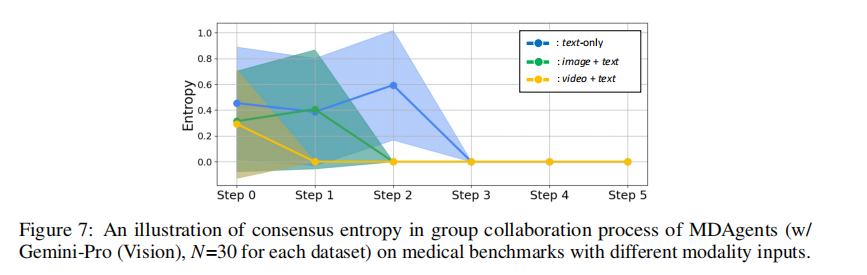
共识动态中的收敛趋势
在 MDAgents 中,跨多种数据模态存在明显的共识收敛趋势(图 7)。文本 + 视频模态的收敛速度最快,这反映了智能体对文本与视觉信息的联合处理能力。相比之下,文本 + 图像和纯文本模态的熵值下降更为平缓,表明智能体的解释多样性在逐步收窄。尽管收敛速度和初始条件不同,但所有模态下的智能体意见都会随着时间推移趋于一致。这种达成共识的一致性凸显了 MDAgents 整合和调和信息的能力。熵值的计算细节请参见附录 B。
无论输入模态如何,agent最终都能通过协作讨论,最终达成高度一致的共识。
结论
本文提出了MDAgents框架,旨在通过动态构建有效的协作模型,提升大语言模型(LLMs)在复杂医疗决策中的实用性。为了模拟临床场景中细致的会诊流程,MDAgents 会根据任务复杂度,自适应地将大语言模型分配为独立工作或团队协作的角色。
这种对现实世界医疗决策过程的模拟已得到全面评估:在 10 个医疗基准任务中,MDAgents 在 7 个任务上的表现均优于以往的单人和团队方法。案例研究展示了该框架的实际效能和协作动态,揭示了不同专家意见如何被综合以达成更准确的诊断。这一点得到了以下事实的印证:尽管初始观点存在分歧,我们的智能体仍能收敛于正确的诊断结论。
消融实验进一步阐明了系统内各智能体和策略的独特贡献,揭示了驱动框架成功的关键组件与交互机制。通过利用多模态推理的优势,并在大语言模型智能体之间促进协作过程,我们的框架为增强大语言模型辅助的医疗诊断系统开辟了新的可能性,推动了自动化临床推理的边界。
代码分析
- utils.py
按医疗问题复杂度动态适配协作模式。
| 论文核心概念 | 代码实现模块 | 核心函数 / 类 |
|---|---|---|
| 智能体(Agent) | Agent 类 | chat()/temp_responses() |
| 多学科团队(MDT) | Group 类 | interact() |
| 复杂度判断 | 工具函数 | determine_difficulty() |
| 基础复杂度(Basic) | 单智能体流程 | process_basic_query() |
| 中级复杂度(Intermediate) | 多专家协作讨论 | process_intermediate_query() |
| 高级复杂度(Advanced) | 多团队分层协作 | process_advanced_query() |
| 模型适配(GPT/Gemini) | Agent 类初始化 + setup_model() | init()/setup_model() |
函数库:
- openai/google.generativeai:调用 GPT/Gemini API 的核心库;
- prettytable:可视化智能体交互日志(输出表格);
- pptree:可视化多智能体协作层级(如 “A> B > C”);
agent类:初始化绑定角色,模型,示例
def __init__(self, instruction, role, examplers=None, model_info='gpt-4o-mini', img_path=None):
self.instruction = instruction # 智能体角色指令(如“你是心内科医生”)
self.role = role # 专家角色(如Cardiologist)
self.model_info = model_info # 模型类型(gpt-4o-mini/gemini-pro)
self.img_path = img_path # 多模态输入(图片路径,暂未使用)
# 分支1:Gemini-Pro初始化
if self.model_info == 'gemini-pro':
self.model = genai.GenerativeModel('gemini-pro')
self._chat = self.model.start_chat(history=[]) # 开启对话历史
# 分支2:GPT系列初始化
elif self.model_info in ['gpt-3.5', 'gpt-4', 'gpt-4o', 'gpt-4o-mini']:
self.client = OpenAI(api_key=os.environ['openai_api_key']) # 读环境变量API Key
self.messages = [{"role": "system", "content": instruction}] # 系统角色
# 少样本提示:加载示例(问题+答案+理由)
if examplers is not None:
for exampler in examplers:
self.messages.append({"role": "user", "content": exampler['question']})
self.messages.append({"role": "assistant", "content": exampler['answer'] + "\n\n" + exampler['reason']})
统一封装GPT/Gemini 对外提供统一接口,底层模型可无缝切换。初始化直接加载示例,无需外部拼接prompt。
chat方法:核心交互函数
def chat(self, message, img_path=None, chat_mode=True):
# Gemini-Pro分支:支持流式响应(重试10次容错)
if self.model_info == 'gemini-pro':
for _ in range(10): # 重试机制:解决API临时报错
try:
response = self._chat.send_message(message, stream=True)
responses = ""
for chunk in response:
responses += chunk.text + "\n"
return responses
except:
continue
return "Error: Failed to get response from Gemini."
# GPT分支:标准chat.completions调用
elif self.model_info in ['gpt-3.5', 'gpt-4', 'gpt-4o', 'gpt-4o-mini']:
self.messages.append({"role": "user", "content": message}) # 追加用户消息
# 模型名映射(兼容GPT-3.5/4o)
if self.model_info == 'gpt-3.5':
model_name = "gpt-3.5-turbo"
else:
model_name = "gpt-4o-mini"
# 调用API
response = self.client.chat.completions.create(
model=model_name,
messages=self.messages
)
# 追加助手回复到对话历史
self.messages.append({"role": "assistant", "content": response.choices[0].message.content})
return response.choices[0].message.content
重试10次,解决网络波动问题。支持流式拼接。自动追加消息到self.messages,模拟连续对话。
Group类:多学科团队(MDT)封装
class Group:
def __init__(self, goal, members, question, examplers=None):
self.goal = goal # 团队目标(如Initial Assessment Team)
self.members = [] # 团队成员(Agent实例列表)
# 初始化团队成员:为每个成员创建Agent实例
for member_info in members:
# 拼接成员指令:"You are a {角色} who {专长}."
_agent = Agent(
'You are a {} who {}.'.format(member_info['role'], member_info['expertise_description'].lower()),
role=member_info['role'],
model_info='gpt-4o-mini'
)
# 初始化角色(发送空指令,让模型记住角色)
_agent.chat('You are a {} who {}.'.format(member_info['role'], member_info['expertise_description'].lower()))
self.members.append(_agent)
self.question = question # 待解决的医疗问题
self.examplers = examplers # 少样本示例
def interact(self, comm_type, message=None, img_path=None):
if comm_type == 'internal': # 仅实现内部协作,external预留
# 步骤1:选领队(Lead)和助理成员
lead_member = None
assist_members = []
for member in self.members:
member_role = member.role
if 'lead' in member_role.lower(): # 含lead的角色为领队
lead_member = member
else:
assist_members.append(member)
# 兜底:无领队时选第一个助理成员
if lead_member is None:
lead_member = assist_members[0]
# 步骤2:领队分配调研任务
delivery_prompt = f'''You are the lead of the medical group which aims to {self.goal}. You have the following assistant clinicians who work for you:'''
for a_mem in assist_members:
delivery_prompt += "\n{}".format(a_mem.role)
delivery_prompt += "\n\nNow, given the medical query, provide a short answer to what kind investigations are needed from each assistant clinicians.\nQuestion: {}".format(self.question)
# 调用领队生成调研任务(容错:失败则用第一个助理)
try:
delivery = lead_member.chat(delivery_prompt)
except:
delivery = assist_members[0].chat(delivery_prompt)
# 步骤3:各成员完成调研任务
investigations = []
for a_mem in assist_members:
investigation = a_mem.chat(
"You are in a medical group where the goal is to {}. Your group lead is asking for the following investigations:\n{}\n\nPlease remind your expertise and return your investigation summary that contains the core information.".format(self.goal, delivery)
)
investigations.append([a_mem.role, investigation])
# 步骤4:汇总调研结果
gathered_investigation = ""
for investigation in investigations:
gathered_investigation += "[{}]\n{}\n".format(investigation[0], investigation[1])
# 步骤5:领队基于汇总结果生成最终回答(支持少样本)
if self.examplers is not None:
investigation_prompt = f"""The gathered investigation from your asssitant clinicians is as follows:\n{gathered_investigation}.\n\nNow, after reviewing the following example cases, return your answer to the medical query among the option provided:\n\n{self.examplers}\nQuestion: {self.question}"""
else:
investigation_prompt = f"""The gathered investigation from your asssitant clinicians is as follows:\n{gathered_investigation}.\n\nNow, return your answer to the medical query among the option provided.\n\nQuestion: {self.question}"""
response = lead_member.chat(investigation_prompt)
return response
elif comm_type == 'external': # 预留外部协作接口
return
模拟真实MDT团队协作流程:选leader,leader向各成员下达调研指令,各成员基于自身专长完成调研,leader汇总所有调研结果,生成最终回答。 ------ 调研结果按照 [角色]\n内容 格式拼接,便于模型解析。
复杂度判断: determine_difficulty():
def determine_difficulty(question, difficulty):
# 非自适应模式:直接返回指定难度
if difficulty != 'adaptive':
return difficulty
# 自适应模式:调用GPT-3.5判断难度
difficulty_prompt = f"""Now, given the medical query as below, you need to decide the difficulty/complexity of it:\n{question}.\n\nPlease indicate the difficulty/complexity of the medical query among below options:\n1) basic: a single medical agent can output an answer.\n2) intermediate: number of medical experts with different expertise should dicuss and make final decision.\n3) advanced: multiple teams of clinicians from different departments need to collaborate with each other to make final decision."""
# 初始化难度判断智能体
medical_agent = Agent(
instruction='You are a medical expert who conducts initial assessment and your job is to decide the difficulty/complexity of the medical query.',
role='medical expert',
model_info='gpt-3.5'
)
medical_agent.chat('You are a medical expert who conducts initial assessment and your job is to decide the difficulty/complexity of the medical query.')
response = medical_agent.chat(difficulty_prompt)
# 解析返回结果(兼容文本/数字)
if 'basic' in response.lower() or '1)' in response.lower():
return 'basic'
elif 'intermediate' in response.lower() or '2)' in response.lower():
return 'intermediate'
elif 'advanced' in response.lower() or '3)' in response.lower():
return 'advanced'
调用GPT-3.5 分析问题,返回 basic/intermediate/advanced,实现自适应。
按复杂度分流:
- process_basic_query(): 基础复杂度(单智能体)
def process_basic_query(question, examplers, model, args):
# 步骤1:初始化辅助智能体(生成示例理由)
medical_agent = Agent(instruction='You are a helpful medical agent.', role='medical expert', model_info=model)
new_examplers = []
# 仅处理MedQA数据集:生成少样本示例(问题+答案+理由)
if args.dataset == 'medqa':
random.shuffle(examplers)
for ie, exampler in enumerate(examplers[:5]): # 选前5个示例
tmp_exampler = {}
exampler_question = exampler['question']
# 随机打乱选项(模拟真实场景)
choices = [f"({k}) {v}" for k, v in exampler['options'].items()]
random.shuffle(choices)
exampler_question += " " + ' '.join(choices)
exampler_answer = f"Answer: ({exampler['answer_idx']}) {exampler['answer']}\n\n"
# 让模型生成答案理由(增强少样本效果)
exampler_reason = medical_agent.chat(f"You are a helpful medical agent. Below is an example of medical knowledge question and answer. After reviewing the below medical question and answering, can you provide 1-2 sentences of reason that support the answer as you didn't know the answer ahead?\n\nQuestion: {exampler_question}\n\nAnswer: {exampler_answer}")
tmp_exampler['question'] = exampler_question
tmp_exampler['reason'] = exampler_reason
tmp_exampler['answer'] = exampler_answer
new_examplers.append(tmp_exampler)
# 步骤2:初始化单智能体(加载示例)
single_agent = Agent(
instruction='You are a helpful assistant that answers multiple choice questions about medical knowledge.',
role='medical expert',
examplers=new_examplers,
model_info=model
)
single_agent.chat('You are a helpful assistant that answers multiple choice questions about medical knowledge.')
# 步骤3:生成最终回答(温度0.0)
final_decision = single_agent.temp_responses(
f'''The following are multiple choice questions (with answers) about medical knowledge. Let's think step by step.\n\n**Question:** {question}\nAnswer: ''',
img_path=None
)
return final_decision
- process_intermediate_query():中级复杂度(多专家协作)
实现专家招募,层级可视化,多轮辩论,共识决策的流程。
def process_intermediate_query(question, examplers, model, args):
# 步骤1:专家招募(调用GPT-3.5生成5个专家)
cprint("[INFO] Step 1. Expert Recruitment", 'yellow', attrs=['blink'])
recruit_prompt = f"""You are an experienced medical expert who recruits a group of experts with diverse identity and ask them to discuss and solve the given medical query."""
tmp_agent = Agent(instruction=recruit_prompt, role='recruiter', model_info='gpt-3.5')
tmp_agent.chat(recruit_prompt)
num_agents = 5 # 固定招募5个专家(可配置)
# 让模型生成专家列表+协作层级
recruited = tmp_agent.chat(f"Question: {question}\nYou can recruit {num_agents} experts in different medical expertise...(省略prompt)")
# 解析专家信息(角色+层级)
agents_info = [agent_info.split(" - Hierarchy: ") for agent_info in recruited.split('\n') if agent_info]
agents_data = [(info[0], info[1]) if len(info) > 1 else (info[0], None) for info in agents_info]
# 随机分配emoji(可视化)
agent_emoji = ['\U0001F468\u200D\u2695\uFE0F', ...] # 省略emoji列表
random.shuffle(agent_emoji)
# 解析协作层级并可视化
hierarchy_agents = parse_hierarchy(agents_data, agent_emoji)
# ...(省略专家列表拼接、Agent实例创建)
# 步骤2:生成少样本示例(同basic流程)
fewshot_examplers = ""
# ...(省略示例生成逻辑)
# 步骤3:多轮辩论(最多5轮,每轮最多5次交互)
cprint("[INFO] Step 2. Collaborative Decision Making", 'yellow', attrs=['blink'])
num_rounds = 5
num_turns = 5
num_agents = len(medical_agents)
# 初始化交互日志(记录每轮/每轮次/智能体间的对话)
interaction_log = {f'Round {round_num}': {f'Turn {turn_num}': {f'Agent {source_agent_num}': {f'Agent {target_agent_num}': None for target_agent_num in range(1, num_agents + 1)} for source_agent_num in range(1, num_agents + 1)} for turn_num in range(1, num_turns + 1)} for round_num in range(1, num_rounds + 1)}
# 初始化第一轮观点
round_opinions = {n: {} for n in range(1, num_rounds+1)}
initial_report = ""
for k, v in agent_dict.items():
opinion = v.chat(f'''Given the examplers, please return your answer to the medical query among the option provided...''')
initial_report += f"({k.lower()}): {opinion}\n"
round_opinions[1][k.lower()] = opinion
# 多轮辩论循环
final_answer = None
for n in range(1, num_rounds+1):
print(f"== Round {n} ==")
# 步骤3.1:汇总当前轮观点,生成分析报告
agent_rs = Agent(instruction="You are a medical assistant who excels at summarizing...", role="medical assistant", model_info=model)
assessment = "".join(f"({k.lower()}): {v}\n" for k, v in round_opinions[n].items())
report = agent_rs.chat(f'''Here are some reports from different medical domain experts...''')
# 步骤3.2:每轮次交互(专家间沟通)
for turn_num in range(num_turns):
turn_name = f"Turn {turn_num + 1}"
print(f"|_{turn_name}")
num_yes = 0
for idx, v in enumerate(medical_agents):
# 询问当前专家是否要沟通
participate = v.chat("Given the opinions from other medical experts in your team, please indicate whether you want to talk to any expert (yes/no)...")
if 'yes' in participate.lower().strip():
# 选择要沟通的专家
chosen_expert = v.chat(f"Enter the number of the expert you want to talk to...")
chosen_experts = [int(ce) for ce in chosen_expert.replace('.', ',').split(',') if ce.strip().isdigit()]
# 发送观点给选中的专家
for ce in chosen_experts:
specific_question = v.chat(f"Please remind your medical expertise and then leave your opinion to an expert you chose...")
print(f" Agent {idx+1} ({agent_emoji[idx]} {medical_agents[idx].role}) -> Agent {ce} ({agent_emoji[ce-1]} {medical_agents[ce-1].role}) : {specific_question}")
interaction_log[round_name][turn_name][f'Agent {idx+1}'][f'Agent {ce}'] = specific_question
num_yes += 1
else:
print(f" Agent {idx+1} ({agent_emoji[idx]} {v.role}): \U0001f910")
# 无专家愿意沟通,提前结束本轮
if num_yes == 0:
break
# 无交互,提前结束所有轮次
if num_yes == 0:
break
# 步骤3.3:更新本轮最终观点
tmp_final_answer = {}
for i, agent in enumerate(medical_agents):
response = agent.chat(f"Now that you've interacted with other medical experts...")
tmp_final_answer[agent.role] = response
final_answer = tmp_final_answer
# 步骤4:可视化交互日志(表格)
print('\nInteraction Log')
myTable = PrettyTable([''] + [f"Agent {i+1} ({agent_emoji[i]})" for i in range(len(medical_agents))])
# ...(省略表格生成逻辑)
print(myTable)
# 步骤5:主持人多数投票决策
cprint("\n[INFO] Step 3. Final Decision", 'yellow', attrs=['blink'])
moderator = Agent("You are a final medical decision maker who reviews all opinions...", "Moderator", model_info=model)
moderator.chat('You are a final medical decision maker who reviews all opinions...')
_decision = moderator.temp_responses(f"Given each agent's final answer, please review each agent's opinion and make the final answer to the question by taking majority vote...")
final_decision = {'majority': _decision}
print(f"{'\U0001F468\u200D\u2696\uFE0F'} moderator's final decision (by majority vote):", _decision)
return final_decision
根据问题自动生成适配的专家列表,而非固定专家;专家可主动选择沟通对象,模拟真实会诊;汇总所有专家观点,按多数票决策。
- process_advanced_query():高级复杂度(多团队分层协作)
招募多学科团队,各团队独立调研,最终决策团队汇总。
def process_advanced_query(question, model, args):
print("[STEP 1] Recruitment")
group_instances = []
# 步骤1:招募多学科团队(MDT)
recruit_prompt = f"""You are an experienced medical expert. Given the complex medical query, you need to organize Multidisciplinary Teams (MDTs) and the members in MDT to make accurate and robust answer."""
tmp_agent = Agent(instruction=recruit_prompt, role='recruiter', model_info='gpt-4o-mini')
tmp_agent.chat(recruit_prompt)
num_teams = 3 # 3个团队(可配置)
num_agents = 3 # 每队3人(可配置)
# 让模型生成团队列表(必须包含IAT和FRDT)
recruited = tmp_agent.chat(f"Question: {question}\n\nYou should organize {num_teams} MDTs...(省略prompt)")
# 解析团队信息并创建Group实例
groups = [group.strip() for group in recruited.split("Group") if group.strip()]
group_strings = ["Group " + group for group in groups]
for i1, gs in enumerate(group_strings):
res_gs = parse_group_info(gs)
# ...(省略团队信息打印)
group_instance = Group(res_gs['group_goal'], res_gs['members'], question)
group_instances.append(group_instance)
# 步骤2:各团队独立调研
# 2.1 初始评估团队(IAT)调研
initial_assessments = []
for group_instance in group_instances:
if 'initial' in group_instance.goal.lower() or 'iap' in group_instance.goal.lower():
init_assessment = group_instance.interact(comm_type='internal')
initial_assessments.append([group_instance.goal, init_assessment])
# 2.2 其他团队调研
assessments = []
for group_instance in group_instances:
if 'initial' not in group_instance.goal.lower() and 'iap' not in group_instance.goal.lower():
assessment = group_instance.interact(comm_type='internal')
assessments.append([group_instance.goal, assessment])
# 2.3 最终决策团队(FRDT)调研
final_decisions = []
for group_instance in group_instances:
if 'review' in group_instance.goal.lower() or 'decision' in group_instance.goal.lower() or 'frdt' in group_instance.goal.lower():
decision = group_instance.interact(comm_type='internal')
final_decisions.append([group_instance.goal, decision])
# 步骤3:汇总所有团队结果,生成最终决策
decision_prompt = f"""You are an experienced medical expert. Now, given the investigations from multidisciplinary teams (MDT), please review them very carefully and return your final decision to the medical query."""
tmp_agent = Agent(instruction=decision_prompt, role='decision maker', model_info=model)
tmp_agent.chat(decision_prompt)
final_decision = tmp_agent.temp_responses(f"""Investigation:\n{initial_assessment_report}\n\nQuestion: {question}""", img_path=None)
return final_decision
IAT(初始评估)-> 专项团队 -> FRDT(最终决策),模拟医院真实MDT流程。各团队独立完成任务,最终由决策团队汇总,避免信息干扰。
main.py 框架主执行脚本
把之前拆解的所有模块串联起来,实现 批量处理医疗问题,按复杂度决策,保存结果。
- 接收命令行参数(数据集、模型、复杂度模式、样本数);
- 初始化模型(GPT/Gemini)、加载医疗数据集(MedQA);
- 批量处理指定数量的医疗问题:
– 先判断问题复杂度(basic/intermediate/advanced);
– 按复杂度调用对应处理函数(单智能体 / 多专家 / 多团队); - 记录每道题的问题、标签、模型回答、复杂度等信息;
- 将结果保存为 JSON 文件,便于后续分析 / 评估。
命令行参数配置:
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', type=str, default='medqa') # 数据集名称,默认MedQA
parser.add_argument('--model', type=str, default='gpt-4o-mini') # 模型类型,默认gpt-4o-mini
parser.add_argument('--difficulty', type=str, default='adaptive') # 复杂度模式,默认自适应
parser.add_argument('--num_samples', type=int, default=100) # 处理样本数,默认100
args = parser.parse_args()
初始化模型与加载数据:
# 初始化模型(根据--model参数配置GPT/Gemini的API客户端)
model, client = setup_model(args.model)
# 加载数据集:test.jsonl(测试集,待处理问题)、train.jsonl(训练集,用于少样本示例)
test_qa, examplers = load_data(args.dataset)
批量处理医疗问题:
results = [] # 存储所有样本的处理结果
for no, sample in enumerate(tqdm(test_qa)): # tqdm显示进度条
# 达到指定样本数,终止循环
if no == args.num_samples:
break
# 打印当前处理的样本编号(便于调试)
print(f"\n[INFO] no: {no}")
total_api_calls = 0 # 记录当前样本的API调用次数(预留字段,未实际使用)
# 步骤1:格式化问题(针对MedQA拼接选项并随机打乱)
question, img_path = create_question(sample, args.dataset)
# 步骤2:判断问题复杂度(核心)
difficulty = determine_difficulty(question, args.difficulty)
print(f"difficulty: {difficulty}") # 打印当前问题的复杂度
# 步骤3:按复杂度调用对应处理函数
if difficulty == 'basic':
final_decision = process_basic_query(question, examplers, args.model, args)
elif difficulty == 'intermediate':
final_decision = process_intermediate_query(question, examplers, args.model, args)
elif difficulty == 'advanced':
final_decision = process_advanced_query(question, args.model, args)
# 步骤4:记录结果(仅处理MedQA数据集)
if args.dataset == 'medqa':
results.append({
'question': question, # 格式化后的问题(含选项)
'label': sample['answer_idx'], # 标准答案索引(如A/B/C)
'answer': sample['answer'], # 标准答案文本
'options': sample['options'], # 原始选项
'response': final_decision, # 模型最终回答
'difficulty': difficulty # 问题复杂度
})

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)