机器学习————支持向量机
一、核心概念
支持向量机核心目标:在特征空间中找到一个最优的超平面,将不同类别的样本分开,并且让这个超平面到各类样本的 “间隔” 最大化。
概念解读
1.超平面:在二维空间是一条直线,三维空间是一个平面,高维空间就是超平面,是 SVM 的分类边界。
2.支持向量:距离超平面最近的那些样本点,这些点决定了超平面的位置,是 SVM 的核心,移除其他样本不影响超平面。
3.间隔:超平面到最近样本点的垂直距离的 2 倍,SVM 追求 “最大间隔”,这让模型泛化能力更强。
4.核函数:解决非线性可分问题的核心——把低维空间中线性不可分的数据,映射到高维空间使其线性可分。
常见核函数:
- 线性核(Linear):
,用于线性可分数据。
- 高斯核(RBF / 径向基):
,最常用,适用于绝大多数非线性场景。
- 多项式核:
;
使用原因:在不实际把低维数据映射到高维空间的前提下,直接计算高维空间中样本之间的内积,既解决了低维数据线性不可分的问题,又避免了高维映射带来的 “维度灾难”。
二、数学原理
SVM 的数学原理核心围绕 “找最优超平面”展开,从线性可分的理想情况(硬间隔),到允许少量噪声的现实情况(软间隔),再到处理非线性数据(核函数),层层递进,所有推导都基于 “最大化间隔” 这个核心目标。
计算前提:
- 样本标签:统一用
表示,而非 0/1,是为了数学推导中方便判断样本在超平面哪一侧;
- 超平面公式:特征空间中分类边界的通用表达式为
,其中w 是法向量,决定超平面方向;b 是截距,决定超平面位置;x 是样本特征向量;
- 点到超平面的距离:样本点
到超平面
,其中
是w的L2 范数,即
,n 是特征维度),这个距离是 SVM “间隔” 的基础。
1. 线性可分 SVM(硬间隔)—— 理想无噪声场景
目标:找到能完美分开两类样本、且间隔最大的超平面。
- 约束条件:所有样本分类正确,即
,标准化处理,让支持向量满足
;
- 优化目标:最大化间隔
,等价于最小化
;
- 求解技巧:通过拉格朗日乘数法转化为对偶问题,把高维 w 的优化,变成低维样本乘子
的优化;
- 关键结论:最优超平面仅由支持向量决定,非支持向量的
,不影响超平面位置。
2.线性不可分 SVM(软间隔)—— 现实含噪声场景
目标:允许少量样本违反间隔约束,平衡间隔与错分惩罚。
- 引入松弛变量
:表示样本违反约束的程度,ξi=0 合规,ξi≥1 错分;
- 优化目标:
,其中C是惩罚系数;
- 参数 C 作用:C 越大,对误分类惩罚越重,但容易过拟合;C 越小,越追求大间隔,但易欠拟合;
- 对偶问题:与硬间隔几乎一致,仅新增
约束。
3.非线性 SVM—— 核函数解决非线性分布
目标:隐式映射低维数据到高维,转化为线性可分问题。
因为直接映射高维会导致维度灾难,所以无需显式映射,直接用低维样本计算高维内积。
即:,
其中是低→高维映射。
三、代码实现
模块一:导入必要的库
import numpy as np # 数值计算基础库
import matplotlib.pyplot as plt # 可视化库
from sklearn import datasets # 内置数据集
from sklearn.model_selection import train_test_split # 划分训练集/测试集
from sklearn.svm import SVC # SVM分类器
from sklearn.metrics import accuracy_score # 计算分类准确率模块二:加载并预处理数据
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 简化为二分类:取前两个特征(方便可视化)+ 前两类样本(setosa和versicolor)
X = iris.data[:100, :2] # 特征:萼片长度、萼片宽度(前100个样本,前2个特征)
y = iris.target[:100] # 标签:0=setosa,1=versicolor
# 划分训练集(80%)和测试集(20%),random_state固定随机种子保证结果可复现
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)模块三: 定义并训练SVM模型
# 3. 定义并训练SVM模型(对比线性核和RBF核)
# 3.1 线性核SVM
# C=1.0:惩罚系数(默认值),C越大对误分类惩罚越重;kernel='linear'指定线性核
svm_linear = SVC(kernel='linear', C=1.0, random_state=42)
svm_linear.fit(X_train, y_train) # 用训练数据训练模型
# 3.2 RBF核SVM(处理非线性场景)
# gamma='scale':gamma是RBF核的参数,scale表示gamma=1/(n_features * X.var())
# gamma越大,模型越容易过拟合;gamma越小,模型越平滑
svm_rbf = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
svm_rbf.fit(X_train, y_train)模块四:模型预测与评估
# 对测试集进行预测
y_pred_linear = svm_linear.predict(X_test)
y_pred_rbf = svm_rbf.predict(X_test)
# 计算准确率(正确预测数/总样本数)
acc_linear = accuracy_score(y_test, y_pred_linear)
acc_rbf = accuracy_score(y_test, y_pred_rbf)
# 打印评估结果
print(f"线性核SVM测试集准确率:{acc_linear:.2f}")
print(f"RBF核SVM测试集准确率:{acc_rbf:.2f}")模块五: 可视化分类边界
def plot_svm_decision_boundary(model, X, y, title):
# 定义网格范围(覆盖所有样本的x、y轴范围)
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
# 生成网格点(步长0.02),用于绘制决策边界
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 预测网格中每个点的类别(ravel展平为一维,c_拼接为二维)
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape) # 重塑为网格形状
# 绘制决策边界(等高线图)
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Spectral)
# 绘制样本点(不同类别用不同颜色/标记)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Spectral)
# 添加标题和坐标轴标签
plt.title(title, fontsize=12)
plt.xlabel('萼片长度 (cm)', fontsize=10)
plt.ylabel('萼片宽度 (cm)', fontsize=10)
plt.show()
# 绘制线性核SVM的决策边界
plot_svm_decision_boundary(svm_linear, X, y, "线性核SVM分类边界(鸢尾花二分类)")
# 绘制RBF核SVM的决策边界
plot_svm_decision_boundary(svm_rbf, X, y, "RBF核SVM分类边界(鸢尾花二分类)")运行结果
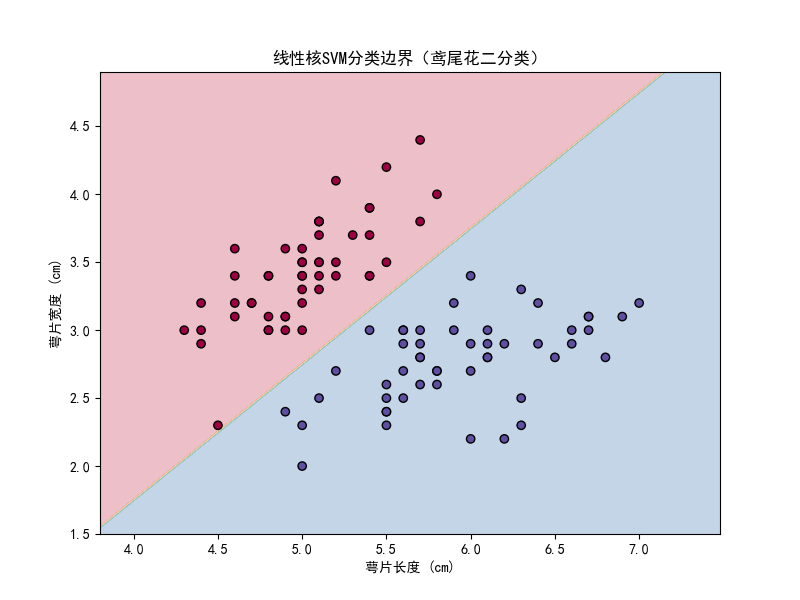
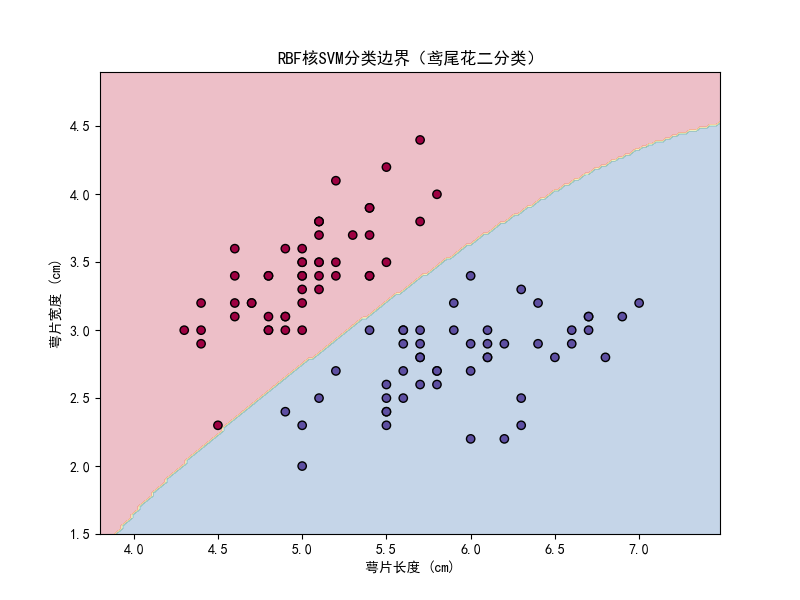
图片解读:两种核函数效果几乎一样,但 RBF 核保留了应对非线性情况的潜力。
线性核SVM测试集准确率:1.00
RBF核SVM测试集准确率:1.00
四、结语
大家可以选择性的阅读,有些部分写的比较粗糙,请大家多多见谅。感谢大家的观看!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)