大模型新架构STEM:静态稀疏化提升效率与稳定性,代码示例全解析【收藏必看】
STEM:一种高效稳定的稀疏大模型架构 STEM是由CMU与Meta联合开发的新型大模型稀疏架构,通过将FFN层的上投影矩阵替换为基于token ID的静态查找表,有效解决了MoE架构的动态路由问题。该架构具有三大优势:1)计算效率提升,减少1/3计算量;2)训练稳定性增强,避免了MoE常见的负载不均衡问题;3)知识可编辑性强,支持精确的知识修改。实验表明,STEM在保持模型性能的同时,展现出优异
STEM是由CMU与Meta开发的新型大模型稀疏架构,将FFN层的上投影矩阵替换为基于token ID的静态查找表,避免了MoE的动态路由问题。这种方法提升了计算效率(减少1/3计算量)、训练稳定性和知识可编辑性,同时具备"测试时容量扩展"特性,在长文本处理中表现优异。实验表明,STEM在保持甚至提升模型性能的同时,解决了MoE训练不稳定、负载不均衡等问题,为构建更高效可控的大模型提供了新思路。
大模型稀疏性的文章最近层出不穷,前几天我们刚介绍过 DeepSeek 的 Engram([DeepSeek 从「计算」转向「记忆」: Engram技术深度解读]),今天再来看一篇 CMU 和 Meta 合作的文章,和 Engram 有某种思路上的共鸣。
作者把这种方法叫做 STEM,简而言之,是一种静态的、词元索引(Token-indexed)的稀疏化架构,想要克服 MoE 的系统性局限,同时提供更高的效率、稳定性、知识容量和可解释性。
我们尝试给出一个深入浅出的讲解。
一、背景:MoE 有哪些局限?
Scaling Laws(缩放定律)告诉我们:模型越大(参数越多),通常越聪明。但是,参数变多不是没有代价:
- 计算量爆炸:训练和推理都变慢了。
- 显存不够:通俗地说就是,GPU 放不下。
所以,引入「稀疏性」是一个很自然的思路。目前的业界主流方案首推 MoE(混合专家模型),比如当前 DeepSeek 最强的 V3 系列基础模型就是这种架构。
MoE 的思路是:「我有很多个专家(子神经网络),但对每个 token,我只激活其中少数几个」。这样参数量虽然大了,但计算量没变大。
虽然 MoE 很强,但它很难训练。它需要一个「路由器(Router)」来决定把 token 发给哪个专家。
- 训练不稳定:路由器可能犯傻,导致 loss 突然暴涨。
- 负载不均衡:可能所有 token 都挤到某几个热门专家那里,其他专家在「摸鱼」。
- 通信开销:在多 GPU 训练时,把 token 发来发去很费时间。
所以,STEM 的出发点是:能不能有一种方法,既能像 MoE 一样拥有巨大的参数量(稀疏性),又不需要那个麻烦的「路由器」,还能比原来的模型计算更少?
二、解剖:FFN 层发生了什么?
为了理解 STEM 做了什么,我们需要先回顾一下标准 Transformer 中最占参数的部件:Feed-Forward Network (FFN) ,特别是现在流行的 SwiGLU 结构。
1. 标准的 FFN (SwiGLU)
在一个 FFN 层里,输入向量 会经过三个矩阵的操作。公式如下:
这里有三个大矩阵:
- :门控投影(决定让多少信息通过)。
- :上投影(将维度放大,提取特征)。
- :下投影(将维度缩回,输出结果)。
2. STEM 的灵感
STEM 的全称是 Scaling Transformers with Embedding Modules。我们就来看看这个 Embedding Modules 是什么。
「FFN 是 KV memory」这个视角是早前研究的一个重要发现(参见下文拓展阅读部分),在此基础之上,作者指出, 这一步其实是在为 token 寻找一个「特征向量」 。在标准模型里,这个向量是通过矩阵乘法「算」出来的。
那既然如此,我们为什么要算?直接查表行不行?
于是,STEM 去掉了 这个矩阵,取而代之的是一个巨大的查找表(Embedding Table),这个表是根据 Token ID 索引的。
STEM 的公式变成了:
这里的 就是直接根据当前输入的词(比如 Apple),去一个巨大的表里把属于 Apple 的那个专用向量拿出来。
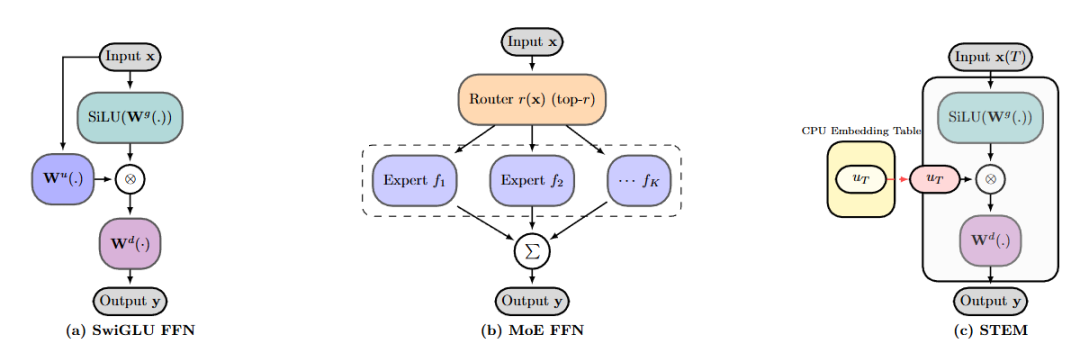
图注:左边是传统的 SwiGLU,中间是复杂的 MoE,右边是清爽的 STEM。注意红色箭头指向的部分,STEM 直接用查表取代了庞大的上投影矩阵,彻底抛弃了复杂的路由机制。
三、优势:为什么这是个好主意?
这看似只是把矩阵乘法换成了查表,但其实改变了整个模型的性质。
1. 效率提升
- 计算量减少:标准的 FFN 需要做 3 次矩阵乘法(Gate, Up, Down)。STEM 只需要做 2 次(Gate, Down)。这直接砍掉了 FFN 层 1/3 的计算量。
- 通信减少:因为不用算 ,训练时的梯度计算和参数加载也变快了。
2. 稳定性
MoE 需要动态路由(Router 决定你去哪),这很不稳定。STEM 是静态的——如果你是 token Cat,你就永远去查表里的 Cat 对应的那行。不需要路由器,缓解了负载不均衡的问题。
这使得 STEM 即使在参数量极大的情况下,训练曲线也非常平滑,不像 MoE 那样容易炸。
3. 可解释性与「脑科手术」
这是这篇论文最有趣的地方。在标准 LLM 里, 里的参数混在一起,你很难说哪个神经元负责「国家」,哪个负责「首都」。
但在 STEM 里,每个 Token 都有自己独立的向量。
举个栗子(知识编辑):假设你问模型:西班牙的首都是哪里? 模型回答:马德里。
现在,我们想给模型做个「手术」。我们在不改变输入文本的情况下,偷偷把 Spain 这个 token 对应的 STEM 向量,换成 Germany 的向量。
输入文本依然是:西班牙的首都是哪里? 但模型内部查表时,拿到的是德国的特征。
结果模型会回答:柏林。
这意味着我们可以精准地定位和修改模型的知识,这在以前的黑盒模型里是很难做到的。
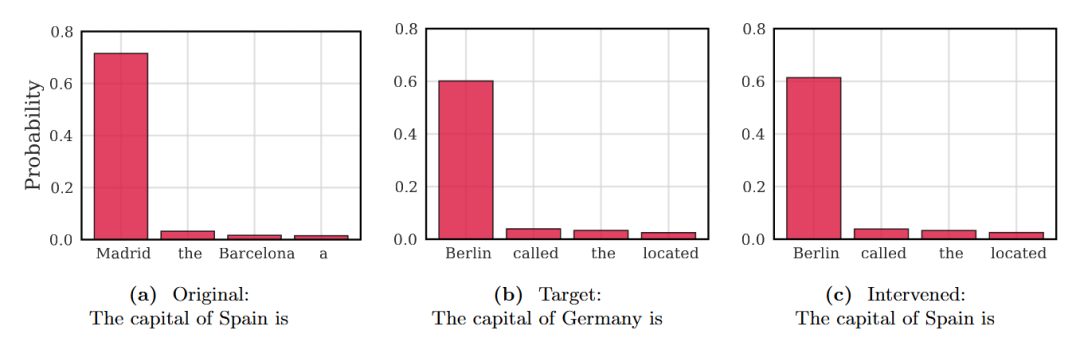
图注:仅仅替换了 Token 的 Embedding,在不改变输入文本的情况下,模型预测「马德里」的概率瞬间消失,转而高置信度地预测「柏林」。这是传统黑盒模型难以做到的。
四、实验:核心结论
- 稳定性:STEM 没有像细粒度 MoE 那样频繁出现训练尖峰(loss spike)
- 效果:在 350M / 1B 上,平均准确率提升可到约 ,尤其知识/推理任务(ARC-C, OBQA, GSM8K, MMLU)提升明显
- 效率:每 token FLOPs 更少,并且能把大表放 CPU、异步搬运,减少 GPU 显存压力与跨卡通信
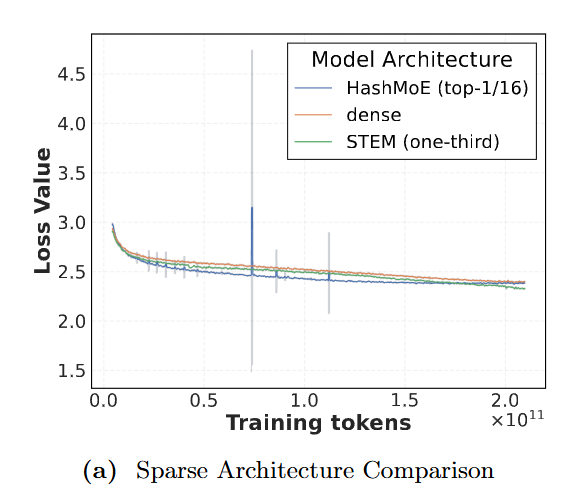
图注:MoE 虽好,但训练由于路由机制常常出现 Loss 尖峰(蓝色曲线)。而 STEM(绿色曲线)凭借其静态稀疏性,展现了如稠密模型般丝滑的训练稳定性。
五、洞见:深入理解
1. 新的稀疏化原语
你可以把 LLM 的 FFN 层想象成一个巨大的键值对数据库。
- 标准 Transformer:像是一个复杂的哈希函数。不管输入是什么,都要经过复杂的计算(矩阵乘法)来算出它的存储地址,然后取值。
- MoE:稀疏发生在「选哪个子网络计算」(动态路由)。像是一个有分诊台的医院。来了一个病人(token),护士(Router)看一眼,把你指派给某个科室(Expert)。
- STEM:稀疏发生在「查哪一行向量参与 FFN」(静态索引)。像是一个巨大的字典。如果你输入的词是「苹果」,我就直接翻到「苹果」这一页,把上面的笔记(Embedding)拿给你,然后再结合上下文(Gate)决定怎么处理。
2. 为什么只替换 Up 投影,而不是 Gate?
论文做了消融实验:替换 Gate 会变差,替换 Up 会变好。
用直觉解释:
- Gate 分支的职责,是根据当前上下文 决定哪些通道要被激活。它必须是 上下文相关的。如果你把 Gate 也换成 token-id 查表,那么 Gate 就几乎不看上下文了。这会破坏「同一个词在不同语境下表现不同」的能力,所以下降明显。
- 而 Up 分支更像是提供「被调制的内容基底/地址向量」,用 token-specific 的向量来替换,反而能让模型把更多知识更「局部化」地存起来,再通过 Gate 进行上下文调制。
3. 为什么 STEM 适合长文本?
随着你输入的文章越来越长,出现的不重复单词(Unique Tokens)越来越多。
在 STEM 中,每一个新出现的单词都会激活表中不同的一行参数。这意味着:上下文越长,模型调用的有效参数量就越大。这被称为「测试时容量扩展(Test-time capacity scaling)」。这对于处理长文档非常有利。
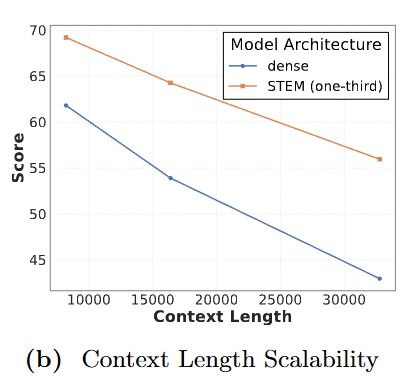
图注:在大海捞针测试中:随着上下文长度(X 轴)增加,STEM(橙色)与基线(蓝色)的差距越拉越大。这证实了 STEM 的「测试时容量扩展」特性在长文本场景下具有天然优势。
4. 查表这种「死记硬背」行为是否会削弱推理能力?
通常人们认为,Transformer 的参数(矩阵乘法)负责「计算/推理」,而 Embedding 负责「记忆/表征」。STEM 把一层计算换成了查表,理论上推理能力可能会下降。
但作者做了一些实验来反驳了这一点,他们在 BIG-Bench Hard (BBH) 和 MuSR 等高难度推理数据集上进行了测试:
- BBH:包含多步推理任务。
- MuSR:软推理,要求模型在长叙述中跟踪实体和约束条件。
- LongBench Code:代码理解(这通常需要极强的逻辑抽象能力)。
结果 STEM 不仅没有变差,反而全面超越了稠密(Dense)基线模型。特别是在代码理解(LongBench Code)上,STEM 优势明显。
这说明 STEM 的 Embedding 不仅仅是存储了「知识片段」,它更像是存储了预计算好的推理中间状态。这种机制并没有损害模型处理复杂逻辑(如代码、多跳推理)的能力。
5. STEM 为什么可能「更能存知识」?
论文观察到:训练后 这些向量之间的余弦相似度更接近 0,即「角度分布更分散(large angular spread)」。
直观理解:
- 如果很多 token 的地址向量很相似,它们会在下游 中「争用」相似的通道,知识容易互相干扰(类似「写在同一块记忆里」)
- STEM 学到的地址更「正交/分散」,就像给每个 token 更独立的「存储槽位」
- gate 再根据上下文选择性放大/抑制,使得「同一 token 在不同语境下仍可不同」
6. 显存占用会不会增大?
那个查找表 可能非常大。
作者的解法是:CPU Offloading。因为查表是很简单的操作,我们可以把这个巨大的表放在内存(RAM)里,而不是显存(VRAM)里。GPU 计算这一层之前,CPU 提前把需要的向量取出来传过去(Prefetching)。
PS:回忆一下之前讲过的 Engram,其实也有这个问题,DeepSeek 用的是一个更「系统工程」的方案,设计了一套类似操作系统的层级存储。
7. 能不能「既要又要」?
既然 (上投影矩阵)能提取特征,(查表)能提供精确记忆,那我把它们加起来行不行?
于是作者设计了 STEM† 变体,公式如下:
保留原矩阵加上查表
这相当于给模型既穿了「腰带」(矩阵),又戴了「背带」(查表)。
结果,参数量和计算量增加了,效果却没有变好,甚至不如纯粹的 STEM。
如何理解这种现象呢?
- 门控(Gate)才是上下文的关键:作者认为,FFN 中负责「理解上下文」的核心组件是 Gate 投影()。STEM 完整保留了 Gate,因此模型已经具备了根据上下文动态筛选信息的能力。
- 上投影(Up)只需提供「地址」:Up 投影()的作用在作者看来只是提供「记忆槽位」或「特征地址」。实验证明,这个地址用静态的查表(Embedding)来提供已经足够丰富和精确了,不需要再通过矩阵计算生成。
- 单纯的「无效堆砌」:在 Gate 已经有效工作的前提下,额外的矩阵计算并没有提供查表无法涵盖的有效信息,属于低效的冗余。
一句话总结:作者认为「Gate 负责动态脑补,Embedding 负责静态记忆」的分工已经是最优解,强行加回矩阵计算属于「由于边际效应递减导致的资源浪费」。
总结
你可以把 STEM 理解为:一种更高效、更可控、更稳定的「查字典」式 Transformer 架构升级。
- 做减法:有时候去掉一个矩阵乘法,换成简单的查表,效果反而更好。
- 粒度:MoE 是粗粒度的(几个专家),STEM 是极致细粒度的(相当于每个 Token 都是一个专家)。
- 可解释性:让参数和 Token ID 绑定,让我们有了控制模型输出的新手段。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献701条内容
已为社区贡献701条内容

所有评论(0)