【AI应用开发工程师】-带你弄懂Skills如何省 Token?
摘要: Skill技术通过"懒加载"机制优化AI编程的Token消耗,采用三层架构(元数据/指令/资源)实现按需加载。与传统Prompt一次性加载所有规则不同,Skill仅在任务匹配时激活相关模块,实测可节省90%以上Token。类比智能点餐系统,Metadata层快速筛选技能,触发后才加载具体指令和资源,既提升效率又降低成本。该设计类似编程中的懒加载模式,适合多技能复杂场景,
Skill:AI编程的"懒加载"神器,省Token就像省电费!
嘿,程序员朋友,你是不是经常觉得AI模型像个"话痨",一说就停不下来?Token烧得比双十一购物车还快!别急,今天我来揭秘一个省Token的"黑科技"——Skill。它就像给你的AI项目请了个智能管家,只在你需要时递工具,绝不多废话。
📑 目录导航(点击直接跳转)
1. 引言:为什么你的Token在"泄漏"?
专业解释:传统prompt-engineering存在严重的"Token泄漏"问题。每次用户输入时,模型都要带着全部system prompt进入上下文,无论这些规则是否与当前任务相关。
大白话:这就像去餐厅吃饭,服务员每次都把整本菜单从头念到尾,不管你点不点,时间都浪费了!
幽默点:你的Token就像手机流量,传统方式是在4G时代看蓝光视频,而Skill就像是开启了"流量节省模式"!
核心问题:
- ❌ 规则越多,prompt越肥胖
- ❌ 所有Token都算钱,哪怕根本没用上
- ❌ 上下文快速膨胀,直接影响成本和效果
2. 什么是Skill?AI编程的"智能管家"
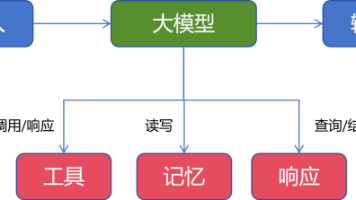
核心理念:Skill不是把所有规则硬塞给模型,而是实现渐进式披露(Progressive Disclosure)——按需、分层、逐步加载。
专业解释:Skill是一种模块化机制,将AI能力封装成独立单元,只在任务匹配时才加载相关内容。
大白话:想象一个智能管家。你要切菜,他不会把整个厨房搬来,只递给你刀和砧板;你要煮咖啡,他才去拿咖啡机。
生活案例:
- 🍳 传统方式:妈妈教你做饭,一次性说完所有菜谱
- 🤖 Skill方式:智能厨房只展示当前需要的步骤
3. 三层懒加载架构:省Token的核心秘诀
第一层:Metadata(元数据)—— 轻量级"名片"
name: pdf-processing
description: 从PDF提取文本和表格
专业解释:包含技能名和描述,每个Skill仅消耗几十到100 tokens,启动时统一加载。
大白话:就像微信好友列表——知道谁在线,但不用看聊天记录。
Token消耗:n个Skill × ~100 tokens,即使有上百个Skill也远低于一次性加载所有说明。
第二层:Instructions(指令主体)—— 触发才加载
专业解释:当模型判断任务需要某个Skill时,才读取SKILL.md文件内容,包含工作流程、步骤指导等。
大白话:点外卖时,只有选中菜品后,才看做法详情。
节省原理:100个Skill可能只触发2-4个,省下90%+ Token。
第三层:Resources(资源)—— 极致按需加载
专业解释:模板文件、参考材料等仅在需要时通过命令读取结果,不加载全文。
大白话:查字典时只抄词义,不复印整本书。
生活类比:医生开药,只写药名,不附上全部医学论文。
4. 传统Prompt vs Skill:一场"省Token大PK"
| 对比维度 | 传统Prompt 🐘 | Skill方式 🐆 |
|---|---|---|
| 加载逻辑 | 一次性全加载,像背登山包 | 分层按需加载,像用智能行李箱 |
| Token消耗 | 所有规则都算钱,容易爆仓 | 只算用到的部分,轻松控制 |
| 扩展性 | 规则越多越臃肿 | 技能越多越智能 |
| 幽默比喻 | "过度准备"的学霸,带全书考试 | "精准狙击"的学神,只带重点笔记 |
专业点:Skill不是缩短prompt,而是通过分层逻辑避免无效负载,类似于编程中的"懒加载"设计模式。
5. 真实节省效果:从"烧豪宅"到"省电费"
让我们用数据说话,看看省Token效果有多震撼!
灾难场景:传统方式
# 传统Prompt的Token灾难
100个Skill × 每个5000 tokens = 500,000 tokens
❌ 远超模型上下文限制,根本无法运行!
智能场景:Skill方式
# Skill的智能节省
Metadata:100 × 100 tokens = 10,000 tokens
触发3个主体:3 × 5000 = 15,000 tokens
资源忽略不计
✅ 总量约25,000 tokens,节省90%以上!
6. 生活案例:Skill就像智能点餐系统
传统Prompt场景(低效烧钱)
🍽️ 场景:你去高级餐厅
💁 服务员:“欢迎光临!现在为您介绍我们128道菜品:第一道是佛跳墙,用料包括…(30分钟后)…最后一道是甜品提拉米苏…”
😴 你:睡着了,钱花了,菜还没点
Skill智能场景(高效省钱)
🍽️ 场景:智能餐厅体验
- Metadata层:服务员问:“先生,想吃中餐还是西餐?”
- Instructions层:你选中餐,才看川菜菜单
- Resources层:点水煮鱼,只上菜不学做法
⏱️ 结果:10分钟吃上饭,省时省力省Token!
7. 总结与互动
🎯 核心要点回顾
Skill省Token的秘诀就一句话:按需加载,绝不多逼逼。通过三层懒加载机制,实现精准高效的AI编程:
- 先用极轻量Metadata进行意图匹配
- 只在任务相关时加载主体Instructions
- 真正需要数据时才按需加载资源
💬 互动环节
📣 评论区嗨起来!
你有没有被Token"烧钱"折磨过?分享你的"血泪史"!
试试Skill后省了多少Token?来晒战绩!
你还有什么省Token的独门秘籍?
🎁 福利: 点赞最高的评论,送"瑞幸咖啡"☕鼓励!3天内有效~
📄 转载声明
转载请注明出处,知识共享需要尊重原创哦~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)