AI模型部署指南:硬件选型与性能优化
摘要:本文分析了不同规模AI模型(2B-70B参数)在CPU/GPU上的部署需求,重点介绍了4bit量化后显存占用情况(如7B模型需8-12GB显存)。针对不同场景给出硬件建议:个人开发推荐7B+8-12GB显卡;小团队建议13B+24GB显卡;SaaS服务需多张A100。文章提供了并发估算公式(24GB显卡约支持6-10个短对话并发),并建议根据显存、并发需求选择模型规模或云端API方案。核心结
一、先搞清三个关键维度
模型大小(参数量)
常见档:2B、7B、13B、34B、70B ……(B=十亿参数)
模型越大:显存需求越高、单次推理越慢、但能力通常更强。
部署方式
CPU 推理:不需要显卡,但速度慢很多,只适合小模型、低并发。
GPU 推理:主流做法,显存够的话既快又能多并发。
并发 & 上下文长度
并发=同一时刻有多少请求在跑。
上下文长度=一次对话里总 token 数(系统提示+历史+当前问题+输出)。
同样机器上,context 越长,可支持的并发越低。
二、不同规模模型对 CPU / GPU 的典型要求
1. GPU 需求(按 4bit 量化后估算)
一般实际部署都会做 4bit/8bit 量化,否则显存吃不消。下面是按 4bit 量化 的大致参考:
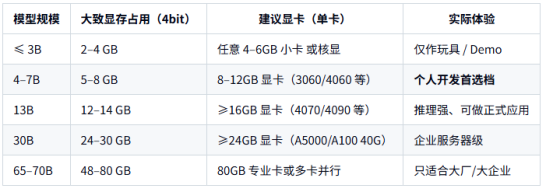
粗略记忆法:
家用 8–12GB 卡:上限就是 7B 4bit;
16GB 卡:13B 4bit 没问题;
想玩 30B/70B → 基本得上 专业卡或多卡集群。
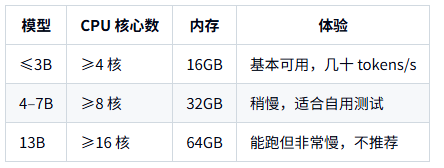
2. CPU 需求
CPU 主要两类用法:
CPU-only 跑模型(没有 GPU,只用 CPU):
只能勉强跑 ≤7B 的 4bit 量化模型,且 速度会明显比 GPU 慢 5–20 倍。
建议配置(只做参考):
CPU + GPU 协作(生产最常见):
CPU 负责:请求调度、tokenize、业务逻辑;
GPU 负责:矩阵乘法/注意力计算。
一般服务器会配:16–32 核 CPU + 1–8 张 GPU,保证 CPU 不成为瓶颈。
三、按场景给「模型 + 硬件」组合建议
场景 A:个人开发 / 本地玩 / 提高学习与编程效率
典型电脑:
CPU:6–8 核(i5/Ryzen 5)
GPU:RTX 3060/4060 8–12GB
内存:16–32GB
推荐模型与框架:
模型(选一个就能用得很爽):
通用聊天:Llama3‑8B、Qwen‑7B、Mistral‑7B、DeepSeek‑7B 的 4bit 量化版
偏代码:Qwen-Coder‑7B、Code‑Llama‑7B 等
部署方式:
完全不想折腾:装一个 Ollama,命令行直接 ollama run llama3。
想做点自己接口:用 llama.cpp / text-generation-webui 跑一个 7B 4bit,对外开 HTTP。
能跑多少并发?
以 7B 4bit + 12GB 显卡 为例:
自己一个人用:感觉就是「接近 GPT‑3.5 的流畅度」。
真要多人共用:
不流式(整段返回):2–3 个并发 尚可;
流式输出:1–2 个比较稳妥。
对你这种个人/小团队开发者:7B 4bit + 8–12GB 显卡 = 最推荐起步档。
场景 B:小团队做内部工具 or 小型线上产品
目标:公司内部几十人用,或面向外部用户的 MVP 产品;并发在 个位数到十几。
硬件建议(单机):
CPU:16 核(Xeon / EPYC / Ryzen 9)
GPU:
性价比:RTX 4090 24GB
又想稳定又想 NV 驱动省事:A5000 24GB / A6000 48GB
内存:64GB
模型组合:
主力小模型:7B 4bit(响应快,用于大部分请求)
较强模型:13B 4bit(处理复杂问题或需要更强推理时使用)
可以做一个 「小模型优先,大模型兜底」 的策略路由:
用户普通问答 / 常规代码 → 走 7B(省显存、省时间)。
检测到长上下文、高难度(如复杂多步推理) → 走 13B。
大致并发能力(以 24GB 显卡 + vLLM 为例):
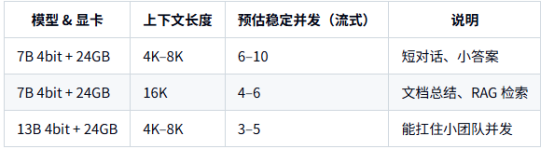
如果希望更稳(考虑高峰波动),就按照「表里数字减半」来规划并发预算。
场景 C:有一定用户规模的 SaaS / 企业内部统一服务
特点:
并发需求从几十到上百;
对稳定性、延迟、监控都有要求。
典型硬件形态:
若在云上:用 1–2 台 A100 40G / L40S / A10G 24G 实例 起步。
若自建机房:
服务器:双路 Xeon/EPYC + 128–256GB 内存
GPU:2–4 张 A100 40G / H100 80G
部署方式:
用 vLLM 部署 7B/13B 4bit 模型若干个实例(可按模型类型拆多个服务)。
前面挂 API 网关(Nginx/Envoy)+ 负载均衡,做流量分发、限流。
并发大致感受:
单卡 A100 40GB + 7B 4bit:
只跑短上下文,吞吐可到 100+ 个请求/分钟,总 tokens 可上万每秒级。
实际应用,一般预留一半给峰值,跑个 20–30 稳定并发 是常见做法。
双卡 A100 40GB + 13B 4bit:
能扛住 20 左右并发的中长对话场景(8K–16K 上下文)。
这一级别很多团队会:
80% 请求走开源自建模型(成本几乎只有显卡钱);
20% 特殊请求走 GPT‑4o / DeepSeek V3.2 这类云 API 兜底。
场景 D:完全不想管硬件,只想「用得起」但也别太贵
那就不需要再纠结 CPU / GPU 了,直接选 云端模型 API:
追求极致性价比:
DeepSeek 系列:带缓存时输入可到 $0.028 / 1M tokens,目前几乎是云端里最便宜的一档。[1]
Qwen3‑8B 等低价档:输入价格约 $0.035 / 1M tokens。[2]
追求效果(不在乎贵一点):
GPT‑4o / GPT‑5、Claude 4.x、Gemini 2.x 等。
这时候你只关心:
每天大概多少请求 × 每次大概多少 tokens
粗算一下:
假设一请求 2000 tokens,1M tokens 约等于 500 次请求;
以 DeepSeek $0.028 / 1M tokens 来算:
500 次请求 ≈ $0.028
1 万次请求 ≈ $0.56
在调用量不大的情况下,直接走 API 往往比自己买卡还省钱。
四、并发估算:给你一个可自己算的「土公式」
假设你用的是 7B 4bit + vLLM + 24GB 显卡:
7B 4bit 模型占用:约 7GB
预留系统 & 缓存开销:约 3–4GB
余下大概 13–14GB 可用于同时服务多个会话的 KV 缓存
非常粗略的估算思路:
对于 短上下文(4K 内) 的请求,每个会话大致吃 1–2GB 显存;
对于 长上下文(16K) 的请求,每个会话吃 2–3GB 显存。
于是你可以估个数量级:
24GB 卡:
短对话:13GB / 1–2GB ≈ 6–10 个并发
长对话:13GB / 2–3GB ≈ 4–6 个并发
如果你有 40GB 显卡,可以近似看成:
40GB ≈ 24GB × 1.6
并发能力在同场景下大约 翻 1.5–1.8 倍。
真要精算,就需要实测(压测工具 + 实际模型),但上面这个数量级足够做早期规划。
五、如何根据你自己的情况快速决策?
你可以按下面这个「选择题」来走:
有没有独显?
没有 / 显存 ≤4GB → 只玩 <=3B 小模型 or 直接用云 API
有 6–12GB → 直接选 7B 4bit 本地跑
有 16–24GB → 上 13B 4bit + 7B 组合,能扛小团队并发
有 40GB+ or 多卡 → 可以考虑 30B/70B,自建企业级服务
日常有多少并发?
仅自己 + 一两个同事 → 一张 8–12GB 卡 + 7B 即够
团队内部 10 人以内,偶尔并发 3–5 → 24GB 卡 + 7B/13B 4bit
对外产品,几十并发 → 至少单卡 A100 40GB 或多卡
能不能接受上云 / 用别人家的接口?
能接受 → 先用 DeepSeek/Qwen/GLM 等便宜 API,后面量大再考虑自建
不接受(强隐私 / 监管) → 必须自建开源模型,按上面的 GPU 等级规划
六、总结
模型越大 → 显存要越多 → 单次响应越慢 → 支持并发数越少(在同一张卡上)。
对大多数个人/小团队来说:
7B 4bit + 8–12GB 显卡 是最合理起点;
想更稳,就上 13B 4bit + 16–24GB 显卡。
想要高并发 / 高稳定,又不想折腾硬件:深度考虑用 DeepSeek / Qwen 这类便宜云 API,本地显卡主要做开发和 PoC。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 36
36 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)