开源还是商用?大模型选型终极指南与实战搭配
本文深入解析了开源与商用大模型的根本差异,并为您提供了清晰的选型路线图。开源模型(如Llama、Qwen)权重开放、可私有部署、成本可控,但需自行维护;商用模型(如GPT-4、Claude)开箱即用、性能顶尖,但需按量付费且数据需出境。
一、开源大模型 vs 商用大模型:该怎么选?
1. 概念和许可证上的差异
开源 / 开放权重大模型
模型权重(weights)公开,可下载、本地部署、二次训练。
多数采用 Apache 2.0、MIT 等宽松开源许可(如 Mistral 7B、Mixtral、Gemma、Falcon 等都是 Apache 2.0 或相近许可)。
也有“开放但非真正开源”的,如 Llama 3 / Llama 2:权重可下载,但许可证不是 OSI 认可的开源协议,商业使用有附加条款,需要阅读 Meta 的 Llama License。
商用大模型(闭源)
模型结构、权重不公开,仅通过 API 使用。典型代表:OpenAI GPT-4o/5.x、Anthropic Claude 4.x、Google Gemini 2.x/3、DeepSeek API 商用版、Qwen 云端商业版等。
使用的是商业条款(Terms of Use),通常允许商用,但需要按量付费且受服务条款约束。
实际选择时,真正要看的是许可证能不能满足你的商业/合规要求。
比如:想闭源商用、做二次分发,优先选 Apache 2.0 / MIT 的模型(Mistral、Gemma、Falcon、Qwen 部分模型等)。
2. 性能与体验
顶级 商用模型(GPT-5.x、Claude 4.5、Gemini 3 Pro 等)在综合推理、工具调用、多模态方面仍整体领先。
但在很多常见任务上,最新一代开源模型(Llama 3、Mixtral、Qwen 3、GLM-4.7 等)已经接近甚至追平中高档商用模型,尤其是:
代码生成与理解
中文、多语言问答
长上下文总结与检索增强生成(RAG)
所以现在常见策略是:
“80% 场景用开源(自建或托管),20% 极限场景用顶级商用 API 兜底”。
3. 成本对比(按 1M tokens 级别)
典型商用模型(文本输入)的大致价格区间:
OpenAI GPT-4o:约 $2.50 / 1M 输入 tokens,$10 / 1M 输出 tokens
Claude Sonnet 4.5:约 $3 / 1M 输入,$15 / 1M 输出
Gemini 1.5 Flash:约 $0.075–0.15 / 1M 输入,$0.30–0.60 / 1M 输出
高性价比“半商用/开放权重”模型:
DeepSeek V3.2:
缓存命中:$0.028 / 1M 输入 tokens
缓存未命中:$0.28 / 1M 输入,输出 $0.42 / 1M
Qwen3‑8B:第三方提供最低约 $0.035 / 1M 输入,$0.138 / 1M 输出
Mistral Small 3.1:约 $0.10 / 1M 输入,$0.30 / 1M 输出
完全自建开源模型(本地 GPU 或云 GPU):
不按 token 收费,成本来自 显卡 + 机器 + 电费。
对高并发、长周期项目来说,平均下来 往往比持续调用商用 API 更省钱。
4. 隐私、安全与合规
开源 / 自建:
可完全在内网部署,数据不出企业;
对医疗、金融、政府等强隐私场景更容易过安全审计。
商用 API:
需评估数据是否会被用于训练/日志;
国际数据传输、跨境合规、行业监管都要考虑。
5. 维护与上手门槛
开源模型:
好处:可深度定制(微调、裁剪、多模型路由等)。
代价:需要懂一定的算力规划、部署、监控(可用 vLLM、Ollama 等降低难度)。
商用模型:
“调 API 就能用”,运维压力小。
升级由服务商负责,但你对“模型版本变化”可控性较弱。
一句话总结:
追求极致性能/省事 → 先看商用大模型(GPT‑4o/5.x、Claude、Gemini)。
有成本压力 / 隐私要求 / 希望强定制 → 以开源大模型为主,必要时接入少量商用兜底。
二、常用的开源大模型平台 / 网站
1. Hugging Face Hub(国际最主流)
特点:
全球最大的开源模型库,上面有 Llama 3、Mistral、Mixtral、Gemma、Falcon、StarCoder、Qwen、GLM-4.7 等几乎所有你听过的开源权重。
提供 Open LLM Leaderboard,可以查看开源模型在多种基准测试上的得分。
支持 GGUF、safetensors 等格式,方便本地部署。
有 Spaces(在线 Demo),不写代码也能直接在浏览器试用模型。
适合:想找/对比模型、快速试用、多语言/多任务实验。
2. ModelScope(魔搭社区,阿里云)
特点:
聚合国内外大量模型,尤其是 Qwen 系列、Llama 系列中文适配版本等。
面向中文开发者友好:文档、示例、Notebook 多为中文。
支持在线推理、训练、部署一站式体验。
适合:
国内云上项目;
希望结合阿里云生态(OSS、ECS、容器服务)的团队。
3. 开源 LLM 托管 / 推理平台(免自己运维 GPU)
这些平台帮你把开源模型“托管成 API”,你只需要调接口:
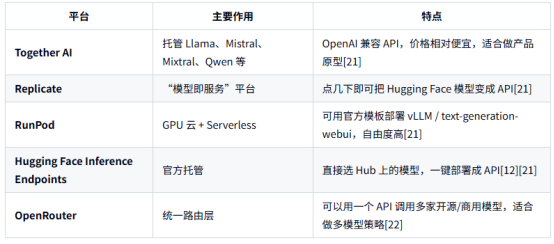
适合:
没有/不想维护自己的 GPU 集群;
需要快速上线 Demo 或中小规模生产系统。
4. 本地/私有化推理引擎
vLLM:
高吞吐、显存利用率高的开源推理与服务引擎,原生支持 Hugging Face 模型。
适合企业把 Llama、Mistral、Qwen 等模型部署为高并发的 HTTP/GRPC 服务。
Ollama:
面向桌面/小型服务器的“一键拉模型运行”工具,支持 Llama 3、Mistral、Gemma、Qwen 等多种量化模型。
安装后 ollama run llama3 就能在本机启动聊天,非常适合个人开发者和 PoC。
适合:
想把开源模型真正落地到 内网服务 / 自有机房 / 边缘设备 上。
三、实际推荐:按场景怎么搭配“开源 vs 商用”?
场景 A:个人开发者 / 学生(低成本 + 易上手)
目标:写代码、问问题、做一点实验,不想烧钱。
模型选择
优先开源权重:
通用聊天:Llama 3‑8B、Mistral 7B、Qwen 3‑7B[1][2][3][6]
写代码:StarCoder 2、Code Llama、Qwen‑Coder、GLM‑4.7(代码向)
使用方式
想“零运维”:
用 Hugging Face Spaces 直接在浏览器试用;
或用 Together/Replicate 调 API,按量付一点点钱。
想“本地白嫖”:
安装 Ollama,拉 llama3:8b、qwen:7b、mistral:7b 等模型即可本机对话。
是否需要商用模型?
可以注册 OpenAI / Claude / Gemini 免费额度,偶尔在“难题”上用一下 GPT-4o/Claude 兜底即可。
场景 B:小团队 / 初创公司(做产品 MVP)
目标:快速上线产品(SaaS、小工具),预算有限但要求稳定。
优先策略:开源为主 + 商用兜底
主力模型:
中文/多语言应用:Qwen-3-8B 或 GLM-4.7-Flash,用 Together 或 RunPod 托管。
英文/全球用户:Mixtral 8x7B 或 Mistral Small 3.1。
架构建议:
用 vLLM 或 Hugging Face Inference Endpoints 把这些模型托管为自己的 API;
同时集成一个顶级商用(如 GPT-4o 或 Claude Sonnet)通道:
低价值请求 → 走开源模型;
高价值、疑难请求 → 走 GPT-4o / Claude,成本可控。
何时考虑完全用商用大模型?
团队缺乏运维/模型工程能力;
用户量不大(调用量低),API 账单可以接受;
上市时间(Time to Market)极其重要。
场景 C:中大型企业 / 强隐私场景(金融、医疗、政府)
目标:数据绝不能出内网,且有合规模型需求。
模型与许可证优先级
优先选 真正开源许可(Apache 2.0 / MIT) 模型,例如:
Mistral 7B / Mixtral 8x7B(Apache 2.0)
Gemma 2.x / 3.x(Apache 2.0)
Falcon 系列(开放权重)
Qwen 系列中 Apache 2.0 的版本
对 Llama 3 / Llama 2 / Code Llama 这类带自定义许可证的模型,需要法务评估是否符合你的商业和合规要求。
部署方式
在自有 GPU 集群或云上专有 VPC 中:
用 vLLM 部署核心模型为统一推理服务;
使用 GGUF 量化 模型降低显存需求;
通过 API Gateway + 鉴权系统对内/对外提供服务。
是否接入商用模型?
可以在严格匿名化/脱敏后的数据上,
让某些“非敏感功能”走 GPT‑4o / Claude / Gemini,以提升产品体验;
关键业务与敏感数据仍然只走自建开源模型服务。
四、决策建议
如果你只是想了解 / 体验
→ 直接去 Hugging Face 或 ModelScope 找 Llama 3 / Mistral / Qwen 试一圈,再决定需不需要 GPT‑4o / Claude 等商用。
如果你要做实际产品且预算有限
→ 以 开源模型(Mistral、Qwen、GLM-4.7、DeepSeek)+ vLLM/Ollama/RunPod/Together AI 为主,
再接一个 商用 API 作为高难度请求的兜底,做到成本和效果平衡。
如果你在大企业、对数据/合规要求极高
→ 必须建立 私有化开源 LLM 平台(vLLM/ModelScope + Apache/MIT 许可的模型),
商用大模型只在合规范围内、少量使用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)