浏览器AI自由:再见,API 账单
Transformer.js 不仅仅是一个库,它代表了一种“以用户为中心”的算力哲学:技术应该是创意的延伸,而非昂贵 API 的束缚。
如还在把所有的 AI 推理请求往后端塞?那可能真的要落伍了。
随着 WebGPU 在主流浏览器(Chrome, Edge, Safari)中的全面爆发,端侧 AI(Edge AI) 已经从“实验室玩具”变成了真正的“生产力工具”。
今天,我们深入聊聊这个领域的头号玩家——Transformer.js v3,并为你拆解如何从零开始配置并转换一个属于你自己的本地模型。
01 为什么是 Transformer.js v3?
在 v3 版本之后,Transformer.js 正式并入了 Hugging Face 的官方版图(包名也从 @xenova/transformers 迁移到了 @huggingface/transformers)。它最大的杀手锏是对 WebGPU 的原生支持。
以往我们在浏览器跑模型,走的是 WebAssembly (WASM) 或者 WebGL,性能勉强够做个简单的分类。但现在,借助 WebGPU 直接调用显卡底层算力,在浏览器里跑 Llama 3.2 或者 Whisper 已经能达到接近原生的速度。
02 深度配置:让 AI 听你指挥
要让 Transformer.js 跑得稳、跑得快,光调个 pipeline 是不够的。你需要通过 env 对象进行全局配置。
核心配置代码:

dtype(数据类型)的设置是性能的关键。在浏览器端,我们通常推荐使用 fp16 或者量化后的 q4、q8,这能在几乎不损失精度的前提下,减少 50%-75% 的内存占用。
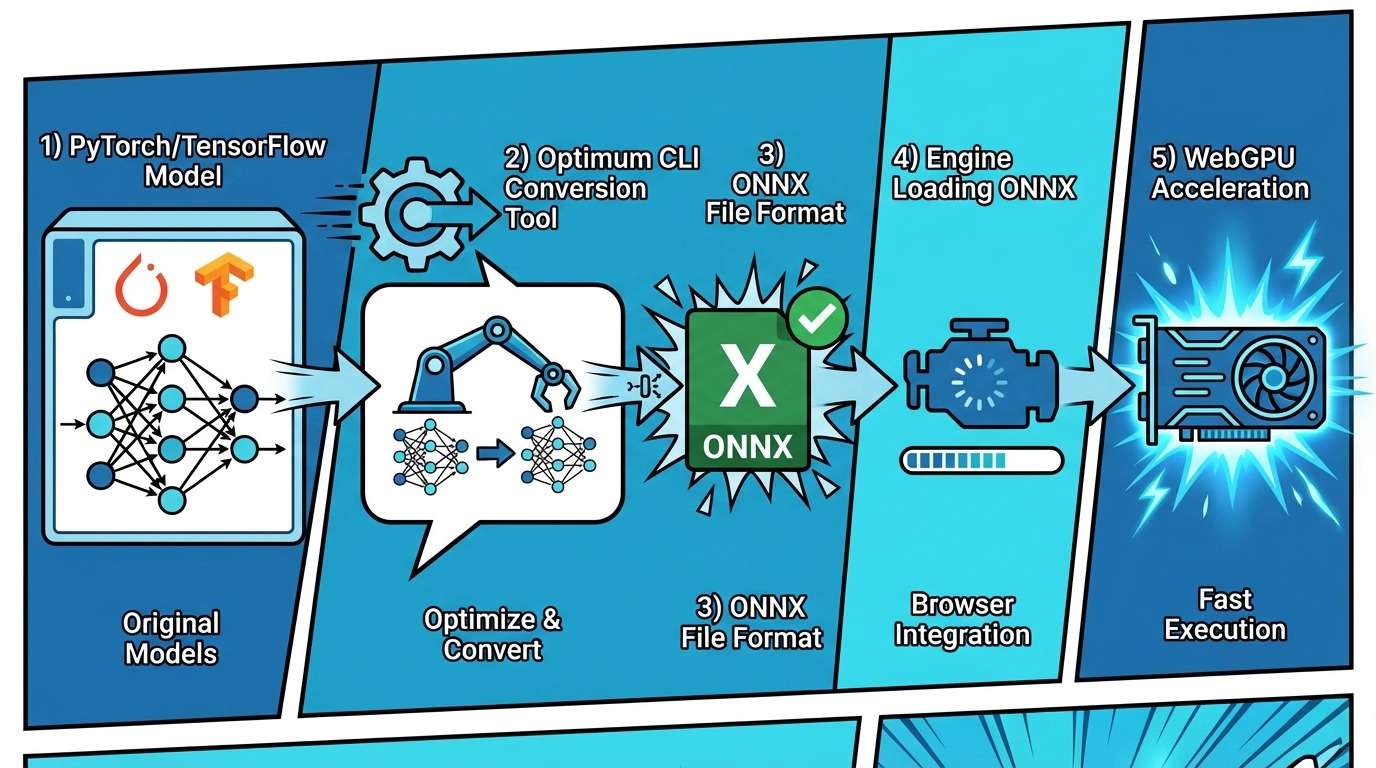
03 实战:如何把 Hugging Face 模型“搬”进浏览器?
并不是所有的模型都能直接被浏览器识别。Transformer.js 依赖的是 ONNX (Open Neural Network Exchange) 格式。如果你的业务需要一个特定的微调模型,你需要自己动手“转译”。
第一步:准备环境
你需要安装 Hugging Face 出品的 Optimum 工具链。
 第二步:一键转换
第二步:一键转换
假设你想转换一个用于中文情感分析的模型 shibing624/bert-base-chinese-sentiment。

第三步:量化(让模型“瘦身”)
原始 ONNX 模型通常很大,直接发给用户会造成巨大的带宽压力。我们需要进行 Quantization(量化)。

转换完成后,你会得到一个包含 .onnx 文件、tokenizer.json 和 config.json 的文件夹。将这些文件部署到你的 Web 服务器或 CDN 上,前端就可以直接调用了。
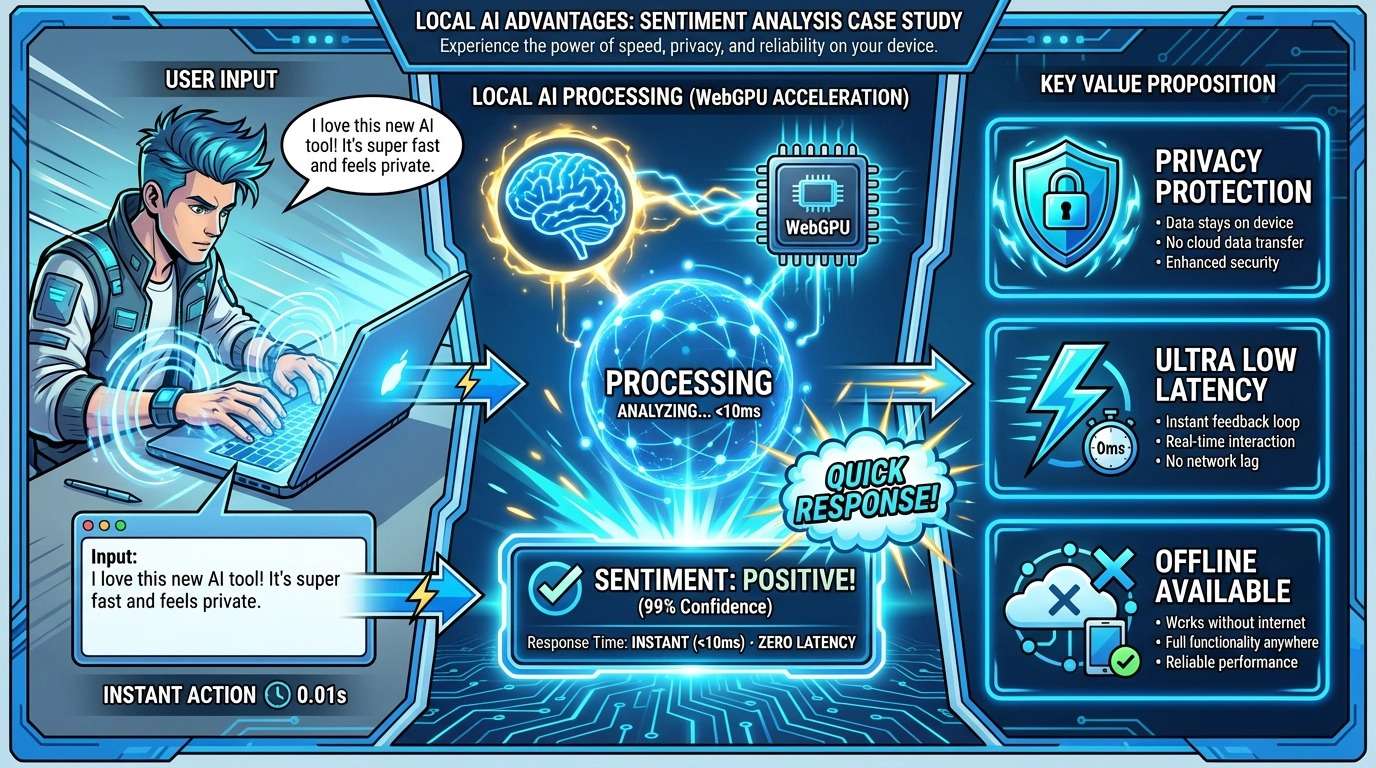
04 落地案例:30 行代码实现本地图片实时描述
下面是一个结合了 WebGPU 和本地模型的完整示例。它能识别用户上传的图片,并用文字描述出来——全过程不经过任何服务器。

作为开发者,我们不能再把浏览器仅仅当成一个“渲染器”。算力去中心化,利用用户闲置的 GPU 算力,是未来低成本扩展 AI 服务的最优解。随着数据安全法更趋严格,能够“在用户本地闭环”处理数据的架构,将拥有极高的竞争门槛。
Transformer.js 不仅仅是一个库,它代表了一种“以用户为中心”的算力哲学:技术应该是创意的延伸,而非昂贵 API 的束缚。
看完这篇文章,你准备好在你的下一个项目里部署本地 AI 了吗? 如果你在模型转换或 WebGPU 适配中遇到了奇怪的报错(比如 GPU device lost),欢迎在评论区留言,我会为你提供更针对性的排障建议。
微信公众号:Next Tech研究局
站在前端与 AI 的交叉口,分享最好用的工具与最前沿的跨端实践。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)