电科研一|那个 0.006 的误差,是我给 Self-Attention 交的“税”
《从软件温室到硬件战场:一个FPGA工程师的自我救赎》记录了将SAM模型Self-Attention模块移植到FPGA的艰难历程。文章揭示了理论认知与实践落地的巨大鸿沟:Python中优雅的Softmax在FPGA中变成了吞噬DSP资源的黑洞,0.006的精度误差成为横亘在理想与现实间的鸿沟。通过"通用废品"到"专用原型"的进化,作者经历了从盲目跟随AI生成
01. The Hook:认知的刺点
教科书告诉你,Softmax 是一个优雅的概率分布函数。 Vivado 告诉你,Softmax 是一个吞噬 DSP 的黑洞,是 Mismatch 报错的罪魁祸首。 当你习惯了 Python 里 torch.softmax 的丝般顺滑,FPGA 会用那个该死的 0.006 误差,刺破你的软件温室气泡。
02. The Evolution:物种进化
续上回。在上一篇笔记里,为了摆脱“提线木偶”的恐惧,我按下了暂停键。而现在,我必须重新启动 Google Antigravity,去打一场真正的硬仗——把 SAM 的真正的心脏(Self-Attention)塞进芯片。
但这不再是盲目的狂飙。这次,我可以坐在副驾上了。我见证了代码在 Antigravity 手下从“通用废品”到“专用原型”的物种进化。
Gen 0: 通用废品 (The Generic Waste) 起初,为了让 AI 推进度,我让它直接生成代码。直到我把代码发回给 Gemini 做检查时,才发现这个版本充满了通用计算的傲慢。如果不加干预,这就是我作为“木偶”会产出的东西:
-
特征:
TILE_SIZE = 32(通用参数),无 Softmax (功能缺失)。 -
本质:不可用 (Not Production Ready)。 用 32 的核去算 SAM 模型的 14x14 特征图,意味着大量的 Padding 和超过 80% 的算力浪费。 没有 Softmax 的 Attention 只是一个蹩脚的通用矩阵乘法器,算出来的全是数值爆炸的垃圾数据。
-
状态:能跑,但全是错的。这是一堆电子垃圾。
Gen 1: 专用原型 (The Specialized Prototype) 这次进化并非源于我的顿悟,而是源于 AI 的自省。Gemini 在检查代码时,冷冷地指出了 Gen 0 的荒谬,并直接抛出了修正方案。 我没有争辩,也没有思考,只是像一个听话的执行者一样,全盘接受了它的修改建议:
-
特征:
TILE_SIZE = 14(适配 ViT-B),含 Softmax (功能闭环)。 -
本质:MVP (Minimum Viable Product)。 这是一个真正能被系统集成的工业级零件。它不再是通用的代码,它是为 SAM 量身定做的硬件器官。
-
状态:逻辑成立,但撞上了 0.006 的误差墙。
03. The Crash:撞墙
Co-simulation 跑到一半,控制台吐出了一串刺眼的红字。系统判定:FAIL。 我的目光锁定在那个罪证上:
-
Software (CPU reference):
0.0641178 -
Hardware (RTL output):
0.0705046 -
Diff:
0.006
说实话,我当时更多的是一种麻木的困惑。我就像一个被 Google Antigravity 裹挟的乘客,车突然撞停了,我完全不知道是哪里出了问题。是代码逻辑错了?还是 HLS 软件甚至 AI 本身在“发癫”?我依然处于那种随波逐流的状态,只觉得屏幕上的红字既刺眼又荒谬。
04. Brute Force:暴力突围
面对报错,传统老手会去查代码逻辑或 Testbench。而我则是直接把 Error 截图和 Console 日志一把甩给了 AI。 Gemini 的判断比我更冷酷:‘这是浮点转定点的精度问题,建议放宽阈值先看波形。’
看着这一行建议,我犹豫了。 出于本能的完美主义和科研洁癖,修改 Testbench 的判决标准(Epsilon)让我感到一种强烈的“生理性不适”。 把 0.001 改成 0.01?这听起来像是在造假,像是在掩耳盗铃。
但 Gemini 极其冷静地提醒了我一个工程常识:“在现阶段,精度是枝叶,跑通是主干。”这句话瞬间击穿了我的完美主义。我意识到,我不是在写一篇数学论文,我是在造一台原型机。如果因为纠结这 0.006 的枝叶,而让整台机器卡死在 FAIL 的红字里,连波形都看一眼的资格都没有,那才是真正的“学术迂腐”。
“这不是造假,这是工程妥协(Trade-off)。” 我修改了代码。这是一种“必要的暴力”。 再次运行。 PASS。 绿色的文字亮起。
我立刻打开 Vivado Simulator。那一刻,原本抽象的数学公式变成了具有物理实感的电流: 这不再是代码,这是冯·诺依曼架构的心跳: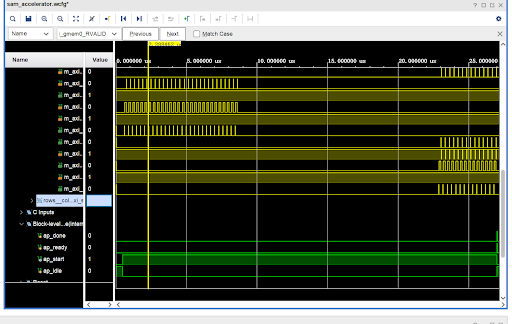
起搏 (The Trigger): 最底部的绿色线条 ap_start 猛然拉高,那是 CPU 下达的“开始”指令。整个硬件瞬间苏醒,进入战备状态。
吞吐 (The Burst Read): 左上角,黄色的波形密集地爆发。那是 AXI 总线在疯狂搬运数据。 它们是成块出现的,这证明 Burst Read 策略生效了!硬件没有傻乎乎地一个一个读,而是像卡车进货一样,一次性把 Q 和 K 矩阵批量拉进了片上缓存(BRAM)。
思考 (The Computation Gap): 紧接着,是一段大约 15us 的“静默期”。波形消失了,只有时间在流逝。 是死机了吗?不,这才是最精彩的地方。 这 15us 的静默,是那 80 个 DSP 在疯狂进行矩阵乘法和 Softmax 指数运算的时间。 *(数学验证:15us = 1500 个时钟周期,完美吻合 HLS 报告的 Latency)*。 Total silence implies maximum efficiency. 总线之所以沉默,是因为计算引擎正在以 100% 的利用率在硅片内部咆哮。
结果 (The Write Back): 右上角黄色波形再次亮起,紧接着底部的 ap_done 脉冲拉高。 计算完成。硬件把 Attention Score 批量写回内存,然后冷冷地告诉 CPU:“我搞定了”。
那一刻我没有狂喜,也没有羞愧,只有一种“如释重负的通透”。我知道,对于一个 MVP(最小可行性产品)来说,这个误差是无伤大雅的。我终于学会了像一个真正的工程师那样思考:在充满噪声的物理世界里,能跑起来的缺陷远比停滞不前的完美有价值得多。
随着 Co-sim 通过,我一鼓作气点击了 Export RTL 和 Implementation。几十分钟后,Bitstream 生成成功。我的发动机原型机,成了。
05. White-Boxing:认知的白盒化
拿到 Bitstream 并不是结束,而是“白盒化” (White-Boxing) 的开始。
为了搞懂这个误差,我让 ChatGPT 用费曼技巧 (Feynman Technique) 带我重新推导了 Self-Attention 的全过程。在彻底理解了 的逻辑后,我把那个精密的“图书检索”模型整理成了详尽的知识文档,并归档进了我的 NotebookLM。在那个纯粹的数学世界里,每一个 Attention Score 都是完美的。
但当我带着满脑子的完美公式回到 Vivado 时,我看到了现实的残酷。 Attention 的核心是 Softmax,而 Softmax 的核心是指数函数 。
在 CPU 的数学理想国(米其林主厨): CPU 是那位拥有精湛刀工的主厨。当算法要求“计算 Q 与 K 的相关性概率”时,他可以用双精度浮点数和泰勒级数,把 切分到小数点后 10 位。 结果:0.0641178。这是数学的极致,是“时间”雕琢的艺术。
在 FPGA 的物理工地(疯狂装修队): FPGA 是那支要在 10 纳秒内端出 100 盘菜的装修队。面对 这种精细的“分子料理”需求,包工头(DSP)崩溃了:“老子只有泥瓦刀,切不出分子级!” 为了不让整条流水线停摆,装修队拿出了“查表法 (Look-up Table)”——这就像是一张贴在墙上的“作弊小抄”。 “大概是 0.07 吧,别管那么细了,后面的车等着装货呢!” 结果:0.0705046。这是物理的妥协,是“空间”换来的速度。
结论: 这个报错背后的本质是:我们在用“有限的物理资源”去逼近“无限的数学精度”。 那个 0.006 的误差,就是我们在物理世界中为了速度 (Speed) 和 面积 (Area) 所缴纳的“税”。
我真正弄懂 Self-Attention,不是在我推导公式的那一刻,而是在我接受这个误差的那一刻。 我理解了那一点“肮脏”的必要性——如果你想跑得快,你就不能带显微镜上路。
06. The Asset:阶段性复盘
客观评估,目前我正处于 FPGA 开发全流程(Design Flow)的 “算子级 RTL 验证与白盒化” 阶段。
1. 工程进度坐标 (Engineering Coordinate) 我完成了 HLS IP 的设计与仿真。
- 已完成 (Done):
-
算法-硬件映射: 将抽象的 SAM Attention 算法映射为了具体的硬件参数(14x14 Tiling)和计算逻辑(Softmax 近似)。
-
功能验证: 通过 C/RTL Co-simulation 证明了逻辑闭环。虽然存在精度损失,但数据通路畅通。
-
RTL 导出: 生成了 IP 核(.zip)和比特流(.bit)。
-
- 未完成 (Todo):
-
软硬协同验证: 驱动缺失 (Driver Missing)。硬件上的“路”修通了,但 PS 端(CPU)的“车”还没有造好。
-
上板实测: 尚未在物理芯片上用真实数据跑通。
-
2. 资产状态 (Asset Status) 我手里的东西从“通用废品”变成了“专用原型”,并且有了配套的“说明书”。
- 硬资产 (The Hardware):
-
Gen 1: 14x14 SAM 专用 Attention 加速器(Demo 版)。状态:MVP。
-
- 软资产 (The IP Matrix) —— 我个人整理的实战 Review 及知识文档:
-
📄 Docs: 《Attention——从图书馆隐喻到矩阵真相》
包含了从 “图书管理员” 的费曼直观隐喻,到 的全链路手算流程。 -
📄 Docs: 《FPGA 架构哲学与分层解析》
揭示了软件是菜谱(时间),硬件是装修图纸(空间)的本体论差异。 -
📄 Docs: 《定义 FPGA 架构的三大核心约束》
一份关于 ROI 的计算书。记录了为了把无限算法塞进有限芯片所签订的三份契约:空间妥协、逻辑妥协、时间优化。 -
📄 Docs: 《复盘计划:逆向工程协议与费曼问答》
实战验收指南。采用“倒叙复盘法”,验证对底层逻辑的绝对掌控。
-
3. 认知状态 (Cognitive Status) 我完成了对特定算子的 **逆向白盒化 (Reverse White-boxing)**。我不再是 Antigravity 的“生物运行环境”,而是该代码的“审计员”。
Next Step: The Awakening (唤醒时刻) 我手里的这个 .bit 文件,意味着“硬件移植手术”已经完成。 但这颗心脏(IP 核)虽然接通了血管(AXI),却还是一具“植物人”。 下一步,我要做的是比手术更凶险的“电击唤醒” (System Bring-up)。 我要面对的不再是波形的逻辑错误,而是真实的排异反应:驱动的崩溃、总线的死锁。 等我去实验室拿到 FPGA 开发板就开干!
(To my fellow engineers: 能够在浮躁的时代读到这里的你,值得这份深度。致敬。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)