SpringCloud Alibaba AI整合DeepSeek智能客服系统
Service// 退订意图所需的关键信息字段(至少需满足一个)// 1. 识别意图:判断是否为"退订"if (!return new IntentResult("inquiry", "未识别到退订意图");// 2. 提取用户输入中的订单信息(通过NLP工具)// 示例:userMessage="退订101徐庶" → extractedInfo={"orderId":"101", "name":
目录:
1、前置准备工作
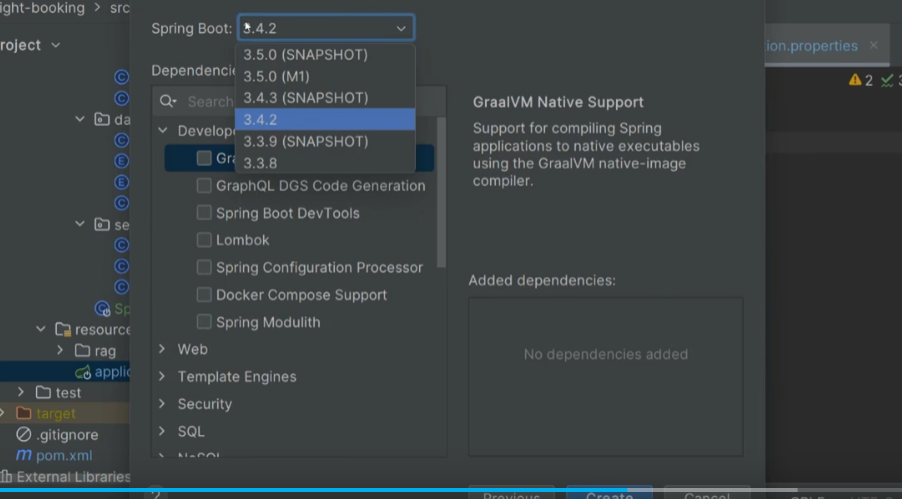
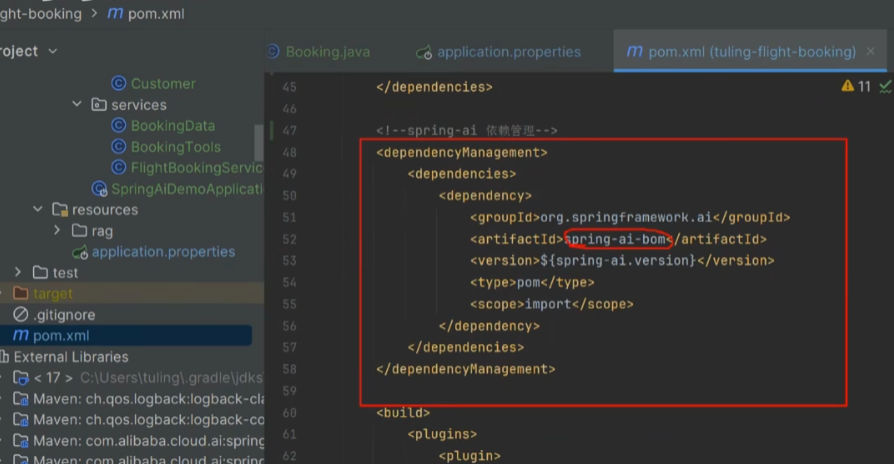
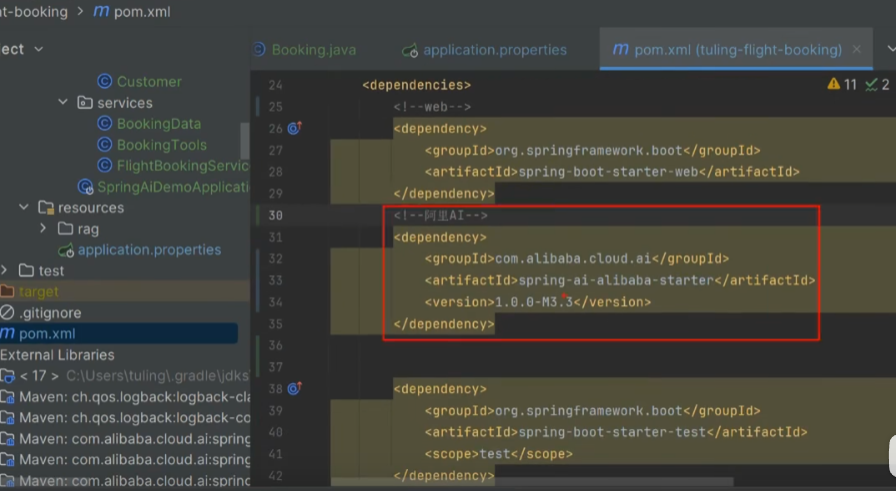
springboot3.x以上的版本才包含AI的相关依赖。
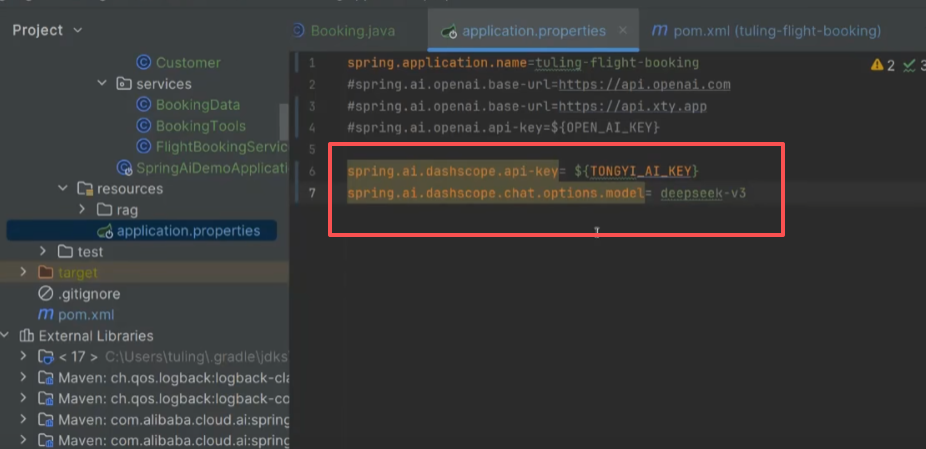
deepseek-r1适用于纯对话功能的场景;deepseek-v3包含向量等功能适用于更复杂的场景。
2、扩展deepseek本地部署
下载Ollama后再去执行安装deepseek大模型
上面一是使用官方的阿里巴巴直接封装好的deepseek,如果是本地部署的,就不需要apikey,调用本地deepseek即可。
3、调用示例
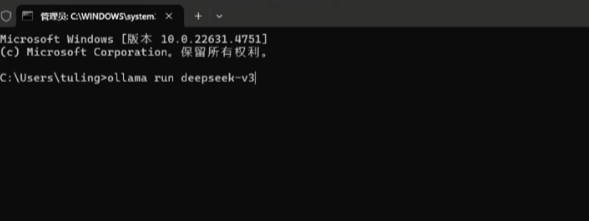
ollama run deepseek-v3
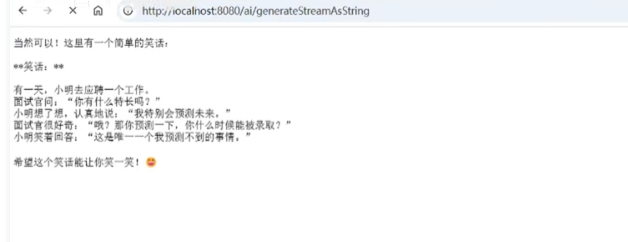
流式响应: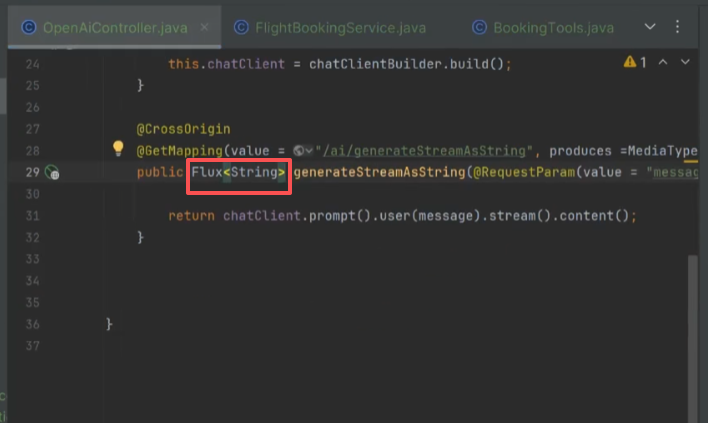
4、日志拦截
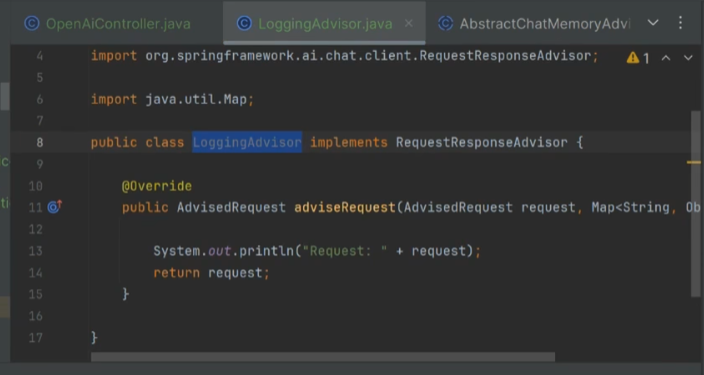
可以用来记录对话信息。
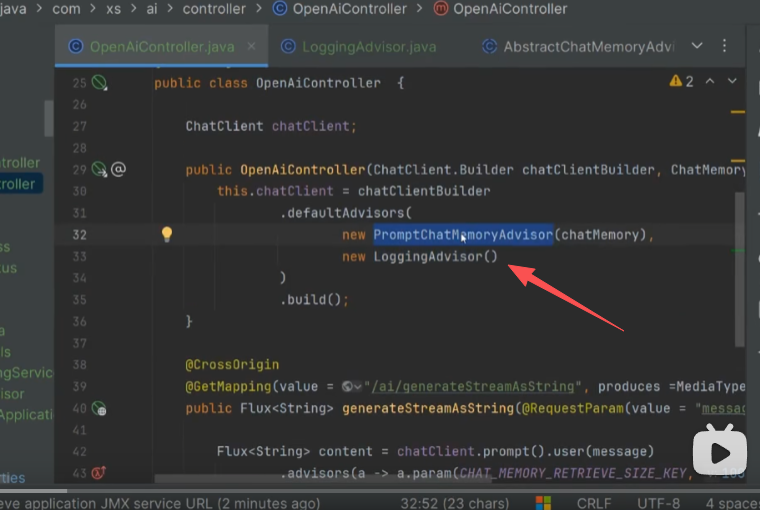
5、实现对话记忆
public OpenAiController(ChatClient.Builder chatClientBuilder, ChatMemory chatMemory) {
this.chatClient = chatClientBuilder
.defaultAdvisors( // 注册 AOP 拦截器(顾问)
new PromptChatMemoryAdvisor(chatMemory), // 记忆拦截器(核心)
new LoggingAdvisor() // 日志拦截器(辅助)
)
.build();
}
- 关键作用:通过 defaultAdvisors 为 ChatClient 注册拦截器,其中 PromptChatMemoryAdvisor
负责对话记忆管理。
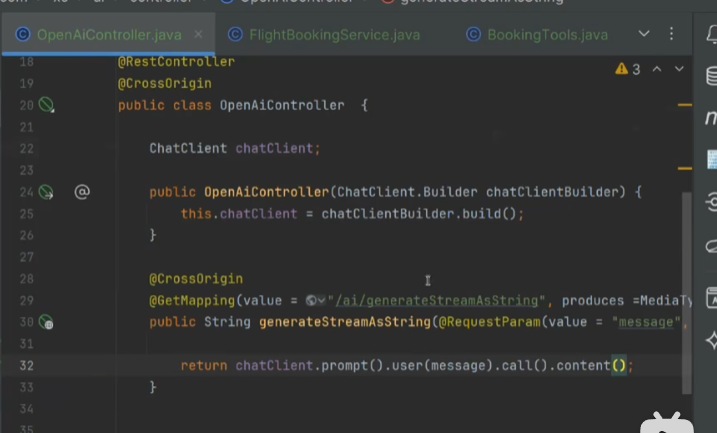
@GetMapping("/ai/generateStreamAsString")
public Flux<String> generateStreamAsString(
@RequestParam("message") String message,
@RequestParam("sessionId") String sessionId // 会话ID(必填)
) {
return chatClient.prompt()
.user(message)
.param(CHAT_MEMORY_SESSION_ID_KEY, sessionId) // 传递会话ID到拦截器
.stream()
.content();
}
// 第42-43行:为当前请求动态配置记忆检索参数
Flux<String> content = chatClient.prompt().user(message)
.advisors(a -> a.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, ...)) // 动态设置记忆检索数量
.stream()
.content();
这段代码的核心作用是 通过 ChatClient 的拦截器(Advisor)动态配置对话记忆的检索数量,具体是 设置每次从历史对话中提取的消息条数(控制记忆长度)。
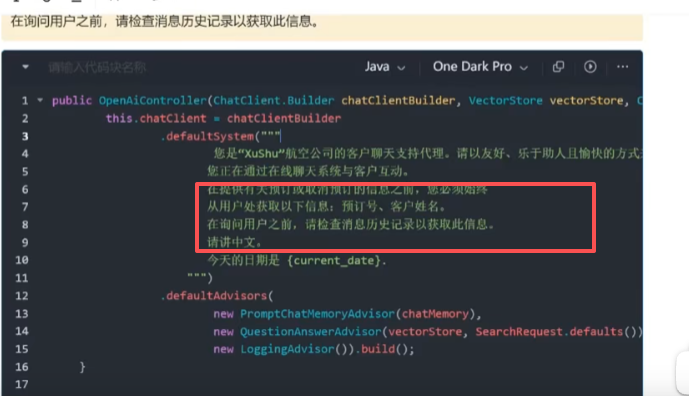
6、设定用户的场景角色
在创建 ChatClient 时,通过 defaultSystemMessage 设定全局角色,所有对话都会使用该角色:
// OpenAiController 构造函数中配置
public OpenAiController(ChatClient.Builder chatClientBuilder, ChatMemory chatMemory) {
this.chatClient = chatClientBuilder
.defaultAdvisors(
new PromptChatMemoryAdvisor(chatMemory), // 记忆拦截器(之前的记忆功能)
new LoggingAdvisor()
)
// === 全局角色设定:系统提示词 ===
.defaultSystem("你是一名专业的网约车客服助手,只回答与订单、司机、路线相关的问题,语气亲切。")
.build();
}
7、设置日期到回答模版
chatClient.prompt()
.user(message)
// 动态生成 System Prompt,注入当前日期
.system(s -> s.param("current_date", LocalDate.now()).toString())
.advisors(...)
.stream()
.content();
核心逻辑:
- system(…) 方法:用于设置 系统提示词(System Prompt),定义 AI 模型的角色和行为。
- s -> s.param(“current_date”, LocalDate.now()):
- s 是 PromptTemplate 对象,支持通过 param(key, value) 动态注入参数。
- 这里注入了名为 current_date 的参数,值为 LocalDate.now()(当前日期,如 2025-10-18)。
- .toString():将填充参数后的 PromptTemplate 转换为最终的字符串提示词。
效果: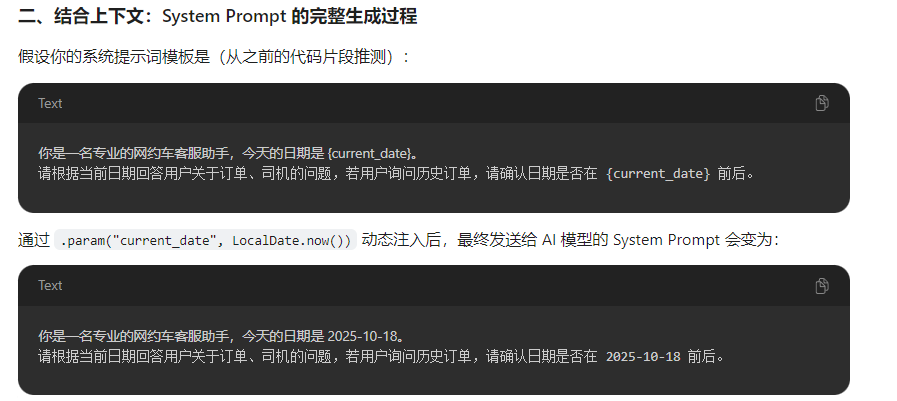
8、通过对话实现取消和确定订单功能
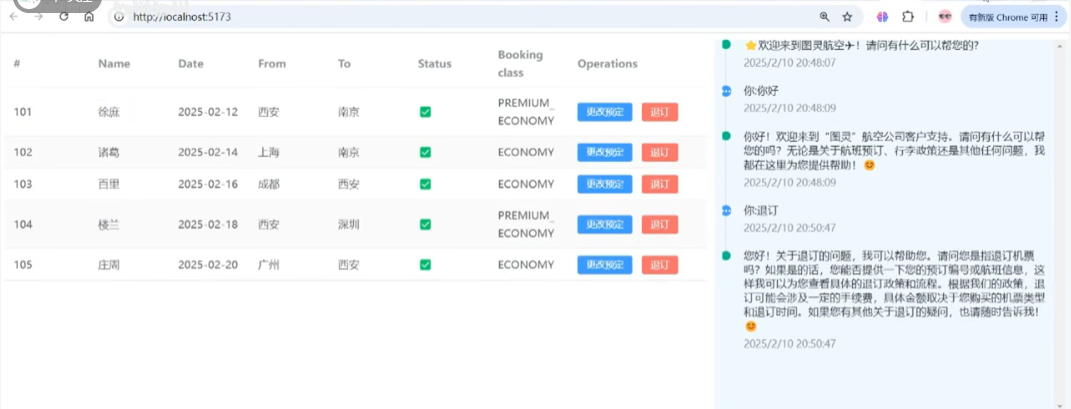
当前场景的核心是 通过大模型的Function-Call(工具调用)能力,实现对话交互与订单系统的自动化集成,即让AI直接调用后端API完成订单取消/确认操作,无需人工介入。
一、核心逻辑:Function-Call实现订单操作自动化

二、关键技术点:Function-Call实现步骤
- 定义Function-Call接口规范
首先需告诉大模型“有哪些工具可用”(即订单操作API的参数和格式),例如“取消订单”接口的定义:
{
"name": "cancel_order",
"description": "取消用户的航空订单",
"parameters": {
"type": "object",
"properties": {
"orderId": {
"type": "string",
"description": "订单ID(必须从用户消息或订单列表中提取)"
},
"userId": {
"type": "string",
"description": "用户ID(当前登录用户)"
}
},
"required": ["orderId", "userId"]
}
}
json数据的定义需要遵循大模型官方文档去定义,比如你是单组还是多组命令,需要分别对应的接口参数去定义。
deepseek官方定义: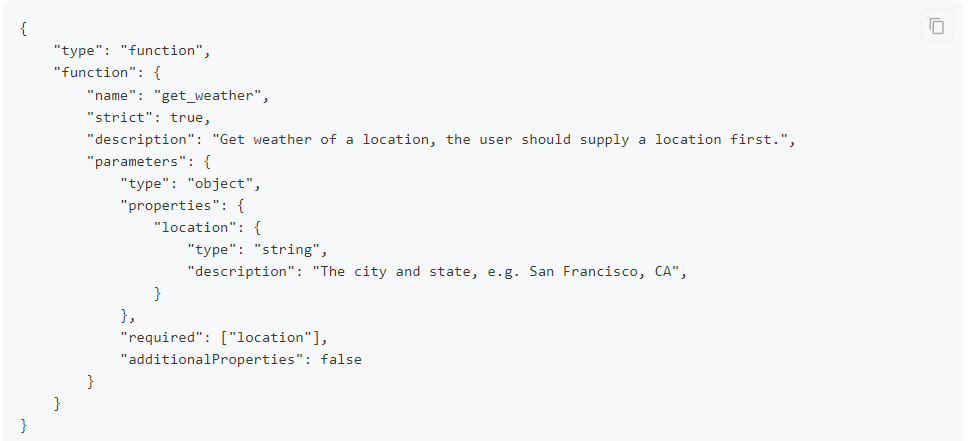
以下以通义千问来展示其他的json接口对比:
# 定义工具列表
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "当你想查询指定城市的天气时非常有用。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市或县区,比如北京市、杭州市、余杭区等。",
}
},
"required": ["location"],
},
},
},
]
- 前端:传递订单列表作为Function-Call上下文
与传统方式类似,前端需将当前订单列表数据(如订单ID、用户ID、状态)传递给大模型,但需额外标记为“可用于工具调用的上下文”:
// 前端发送消息时,携带订单上下文和Function-Call配置
const sendMessage = async (userInput) => {
const response = await fetch('/api/ai/process', {
method: 'POST',
body: JSON.stringify({
message: userInput,
// 1. 订单列表上下文(供AI提取orderId)
orderContext: currentOrders,
// 2. 告知大模型可调用的工具(Function-Call定义)
functions: [cancelOrderFunctionDef, confirmOrderFunctionDef]
})
});
const result = await response.json();
addMessageToChat('assistant', result.content);
if (result.refresh) refreshOrderList(); // 操作成功后刷新列表
};
- 后端:大模型调用Function-Call执行订单操作
以Spring AI(或OpenAI SDK)为例,后端需处理大模型的工具调用请求,解析参数后调用订单系统API,再将结果返回给大模型:
步骤1:大模型返回Function-Call指令(工具调用请求)
当用户输入“取消2月14日上海到南京的订单”,大模型会识别意图并返回工具调用格式(而非自然语言):
{
"function_call": {
"name": "cancel_order",
"parameters": {
"orderId": "102", // 从orderContext中提取的订单ID
"userId": "user_123" // 当前登录用户ID
}
}
}
步骤2:后端解析并执行API调用
@Service
public class AiFunctionService {
@Autowired
private RestTemplate restTemplate; // 用于调用订单系统API
// 处理大模型的Function-Call请求
public String processFunctionCall(String functionName, Map<String, Object> params) {
// 1. 根据函数名路由到具体操作
if ("cancel_order".equals(functionName)) {
return cancelOrder(
params.get("orderId").toString(),
params.get("userId").toString()
);
} else if ("confirm_order".equals(functionName)) {
return confirmOrder(params.get("orderId").toString());
}
return "未知函数调用";
}
// 调用订单系统的取消订单API
private String cancelOrder(String orderId, String userId) {
try {
// 调用后端订单服务(如http://order-system/api/cancel)
ResponseEntity<String> response = restTemplate.postForEntity(
"http://order-system/api/orders/" + orderId + "/cancel",
new HttpEntity<>(userId),
String.class
);
return response.getBody(); // 返回"订单已取消"或错误信息
} catch (Exception e) {
return "取消失败:" + e.getMessage();
}
}
}
步骤3:将API结果返回给大模型,生成自然语言回复
后端执行API后,将结果(如“订单已取消”)返回给大模型,大模型再用自然语言整理后回复用户:
// 大模型处理流程(伪代码)
String userMessage = "取消2月14日上海到南京的订单";
String orderContext = "..."; // 前端传递的订单列表
List<FunctionDef> functions = Arrays.asList(cancelOrderDef);
// 1. 第一次调用大模型:获取Function-Call指令
FunctionCall call = aiClient.generateFunctionCall(userMessage, orderContext, functions);
// 2. 执行函数调用
String apiResult = functionService.processFunctionCall(call.getName(), call.getParams());
// 3. 第二次调用大模型:将API结果转换为自然语言
String aiReply = aiClient.generateResponse(apiResult, userMessage);
// 最终回复用户:"您2月14日上海到南京的订单(订单号102)已取消,退款将在24小时内到账。"
- 前端:自动刷新订单列表
大模型返回操作结果后,前端无需用户交互,直接刷新订单列表(如将订单102的状态从“已预订”更新为“已取消”):
// 接收后端返回的结果,判断是否需要刷新列表
const handleAiResponse = (result) => {
addMessageToChat('assistant', result.content);
if (result.functionCall?.name === 'cancel_order' && result.success) {
refreshOrderList(); // 自动刷新列表
}
};
9、问题总结
1、如何通过提示词,来让模型通过对话帮你或者用户信息,航班信息等。
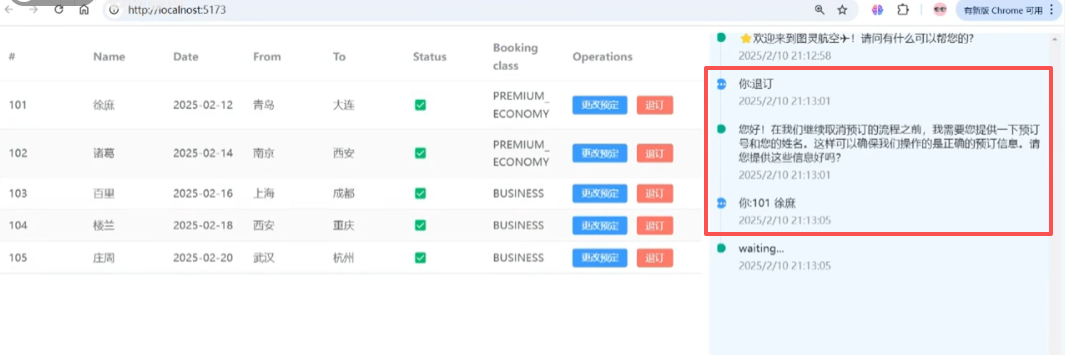
2、客户输入信息不完整,如何实现客户提示信息用户确认信息
@Service
public class IntentService {
// 退订意图所需的关键信息字段(至少需满足一个)
private static final List<String> REQUIRED_FIELDS = Arrays.asList("orderId", "name", "date");
public IntentResult detectRefundIntent(String userMessage, List<Order> userOrders) {
// 1. 识别意图:判断是否为"退订"
String intent = aiClient.classifyIntent(userMessage, Arrays.asList("refund", "inquiry", "other"));
if (!"refund".equals(intent)) {
return new IntentResult("inquiry", "未识别到退订意图");
}
// 2. 提取用户输入中的订单信息(通过NLP工具)
Map<String, String> extractedInfo = nlpTool.extractOrderInfo(userMessage);
// 示例:userMessage="退订101徐庶" → extractedInfo={"orderId":"101", "name":"徐庶"}
// 3. 检测信息缺失:判断是否满足退订所需字段
List<String> missingFields = REQUIRED_FIELDS.stream()
.filter(field -> !extractedInfo.containsKey(field))
.collect(Collectors.toList());
if (!missingFields.isEmpty()) {
// 信息缺失:生成追问话术(如"请提供姓名或订单号")
String prompt = generatePrompt(missingFields);
return new IntentResult("refund", prompt, false); // isComplete=false
} else {
// 信息完整:匹配用户订单列表中的唯一订单
Order matchedOrder = matchOrder(extractedInfo, userOrders);
if (matchedOrder == null) {
return new IntentResult("refund", "未找到匹配订单,请确认信息", false);
}
return new IntentResult("refund", "确认退订订单吗?", true, matchedOrder.getId());
}
}
// 生成追问话术(如缺失"name"和"orderId",则提示"请提供订单号或姓名")
private String generatePrompt(List<String> missingFields) {
if (missingFields.contains("orderId") && missingFields.contains("name")) {
return "请提供预订号或姓名,以便确认订单";
} else if (missingFields.contains("date")) {
return "请提供订单日期,避免操作错误";
}
return "请补充订单信息";
}
}
实现代码如上,让ai通过对话提取信息,如果提取不到信息,则ai回复用户请提供预订号或姓名,以便确认订单这个询问,用户回答后,提取到订单信息后才触发取消订单的方法去取消订单。
10、利用RAG技术增强行业知识支持
1、使用背景
比如客户询问,各种舱取消订单需要多少费用?这个是ai无法回答的,需要通过RAG检索文档来获取答案让ai再回答给客户更精准的回答。
2、实现流程

3、RAG核心实现步骤
1. 文档预处理(构建知识库)

预处理代码(Python/Java):
// 文档分割工具(使用LangChain或Spring AI的DocumentSplitter)
List<Document> splitDocuments() {
// 1. 读取文档内容
String content = FileUtils.readFileToString(new File("terms-of-service.txt"), StandardCharsets.UTF_8);
// 2. 按段落/标题分割为小文档(避免长文本检索精度低)
RecursiveCharacterTextSplitter splitter = new RecursiveCharacterTextSplitter(
300, // 每个片段最大字符数
50 // 片段重叠字符数(保持上下文连贯)
);
return splitter.splitText(content).stream()
.map(text -> new Document(text, Map.of("source", "terms-of-service.txt"))) // 添加元数据
.collect(Collectors.toList());
}
// 向量化存储(使用Embedding模型+向量数据库)
void initVectorStore() {
List<Document> documents = splitDocuments();
// 1. 将文档片段向量化(如使用OpenAI Embedding或华为云Embedding)
List<Embedding> embeddings = embeddingClient.embedAll(documents.stream()
.map(Document::getContent)
.collect(Collectors.toList()));
// 2. 存入向量数据库(如Redis/ Pinecone/ 华为云GeminiDB)
for (int i = 0; i < documents.size(); i++) {
vectorStore.add(
documents.get(i).getContent(),
embeddings.get(i).getVector(),
documents.get(i).getMetadata()
);
}
}
2. 检索相关条款(用户提问时触发)
当用户提问时,先将问题向量化,然后从向量数据库中 检索最相似的文档片段(如前3条)。
检索代码示例:
@Service
public class RAGService {
@Autowired
private VectorStore vectorStore; // 向量数据库
@Autowired
private EmbeddingClient embeddingClient; // Embedding模型客户端
// 检索与用户问题相关的条款
public List<Document> retrieveRelevantTerms(String userQuestion) {
// 1. 将用户问题向量化
Embedding questionEmbedding = embeddingClient.embed(userQuestion);
// 2. 向量数据库相似度检索(返回Top 3最相关片段)
return vectorStore.similaritySearch(
questionEmbedding.getVector(),
3, // 检索数量
Map.of("source", "terms-of-service.txt") // 仅检索条款文档
);
}
}

3. 生成回答(结合检索结果)
将用户问题、检索到的条款片段拼接为 带上下文的Prompt,送入大模型生成回答,确保回答引用条款内容。
大模型调用代码(Spring AI):
@Service
public class AiService {
@Autowired
private ChatClient chatClient;
@Autowired
private RAGService ragService;
public String generateAnswerWithRAG(String userQuestion) {
// 1. 检索相关条款
List<Document> relevantTerms = ragService.retrieveRelevantTerms(userQuestion);
String context = relevantTerms.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n")); // 拼接条款片段
// 2. 构建带RAG上下文的Prompt
String prompt = String.format("""
你是航空客服助手,请根据以下条款回答用户问题。
条款内容:
%s
用户问题:%s
回答必须引用条款中的具体内容,如"根据条款X:..."。
""", context, userQuestion);
// 3. 调用大模型生成回答
return chatClient.prompt()
.system("严格按照条款内容回答,不编造信息。")
.user(prompt)
.call()
.getResult()
.getOutput()
.getContent();
}
}
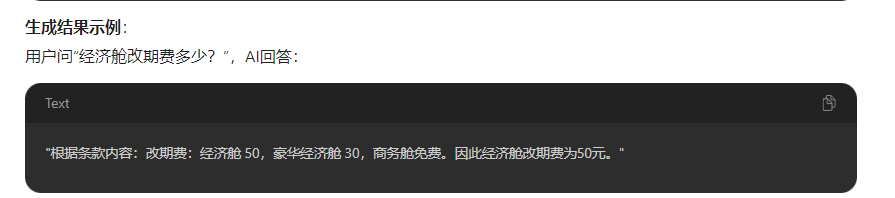
完整调用: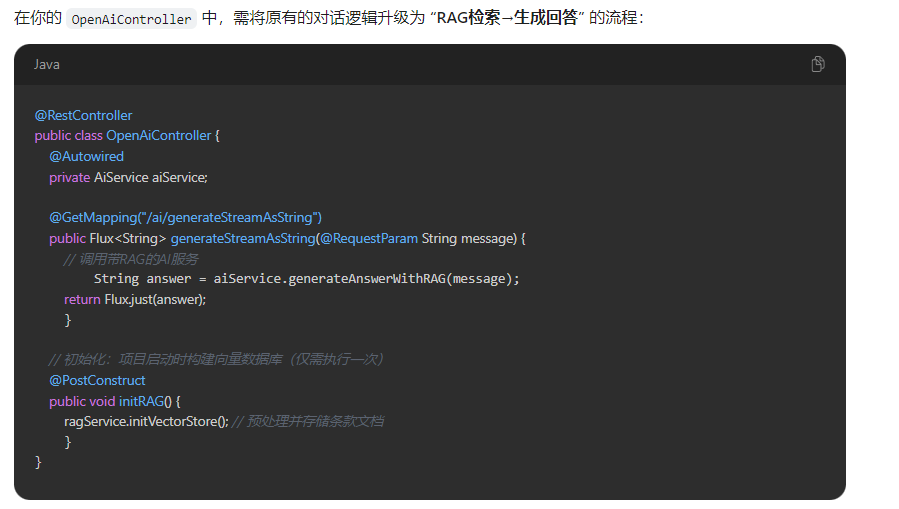
问题扩展:
如果用户回答的很模糊,没有指定什么舱位,那这个就可以根据上面提到过的,信息缺失的话,可以通过两种方式处理:
- 1、ai引导客户回答,提示您指的是什么舱位?经济舱还是豪华舱?
- 2、检索上下文,通过对话提取客户的订单信息,来判断用户的舱位信息
11、项目整体流程解析
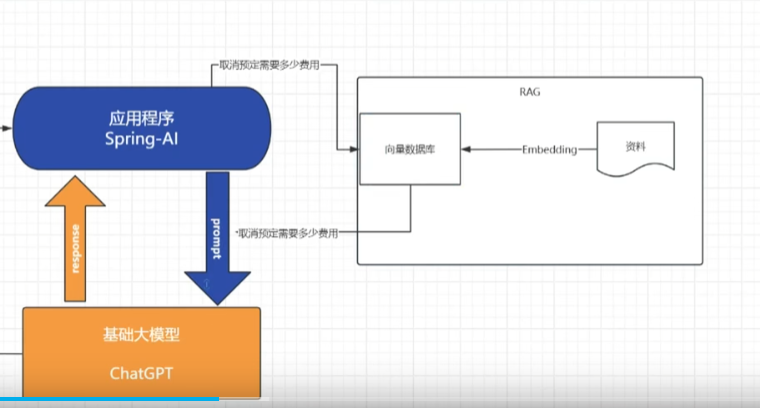
用户问题→Spring-AI应用→RAG检索资料→拼接Prompt→大模型生成回答→返回用户。
其中,RAG模块(资料→Embedding→向量数据库→检索) 是“知识增强”的关键,确保AI回答“有据可查”,尤其适用于规则密集型场景(如航空客服、金融咨询、法律问答等)。你的项目正是通过这个流程实现了“AI客服精准回答改期/取消费用”的功能。
Embedding→向量数据库:
// 向量化存储(使用Embedding模型+向量数据库)
void initVectorStore() {
List<Document> documents = splitDocuments();
// 1. 文档向量化(Embedding)
List<Embedding> embeddings = embeddingClient.embedAll(documents.stream()
.map(Document::getContent)
.collect(Collectors.toList()));
// 2. 存入向量数据库(vectorStore是向量数据库的抽象)
for (int i = 0; i < documents.size(); i++) {
vectorStore.add(
documents.get(i).getContent(),
embeddings.get(i).getVector(),
documents.get(i).getMetadata()
);
}
}
// 检索相关条款(向量数据库相似度搜索)
public List<Document> retrieveRelevantTerms(String userQuestion) {
// 1. 问题向量化
Embedding questionEmbedding = embeddingClient.embed(userQuestion);
// 2. 向量数据库检索(返回Top 3相似片段)
return vectorStore.similaritySearch(
questionEmbedding.getVector(),
3,
Map.of("source", "terms-of-service.txt")
);
}
向量数据库:
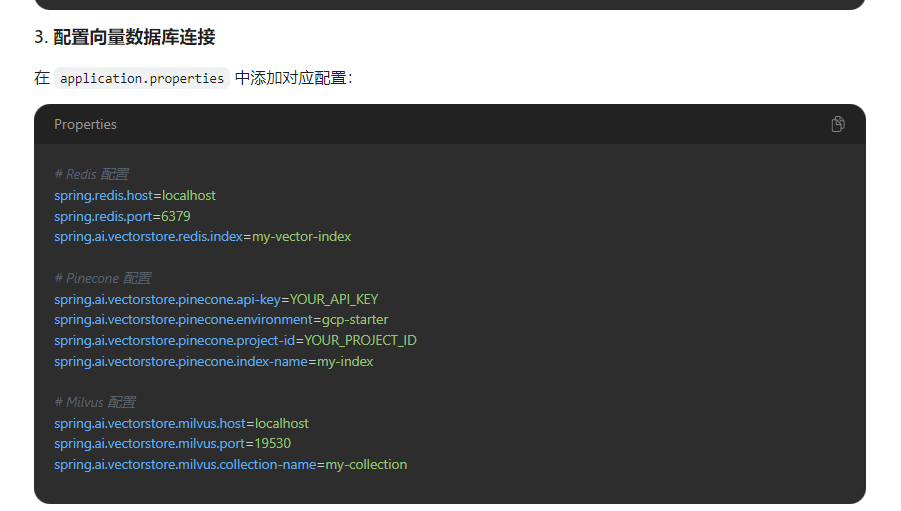
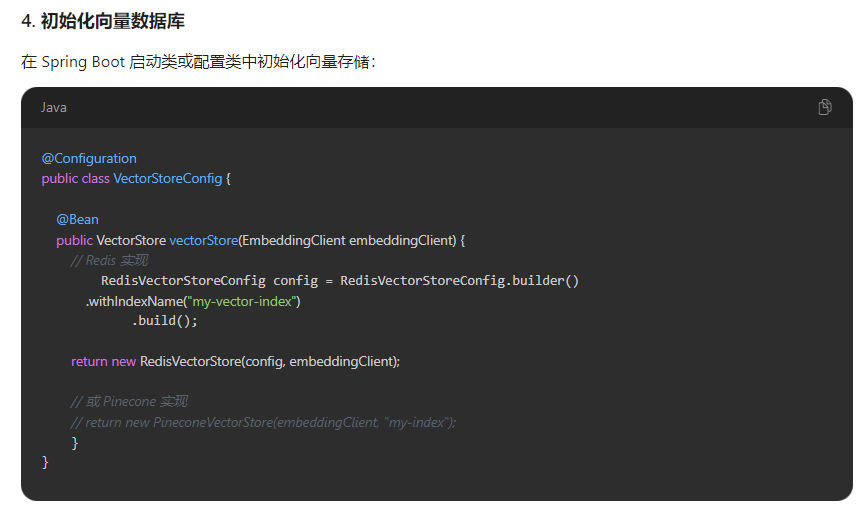
- 构建RedisVectorStoreConfig配置对象
- 设置向量索引名称为"my-vector-index"
- 使用RedisVectorStore作为向量存储实现
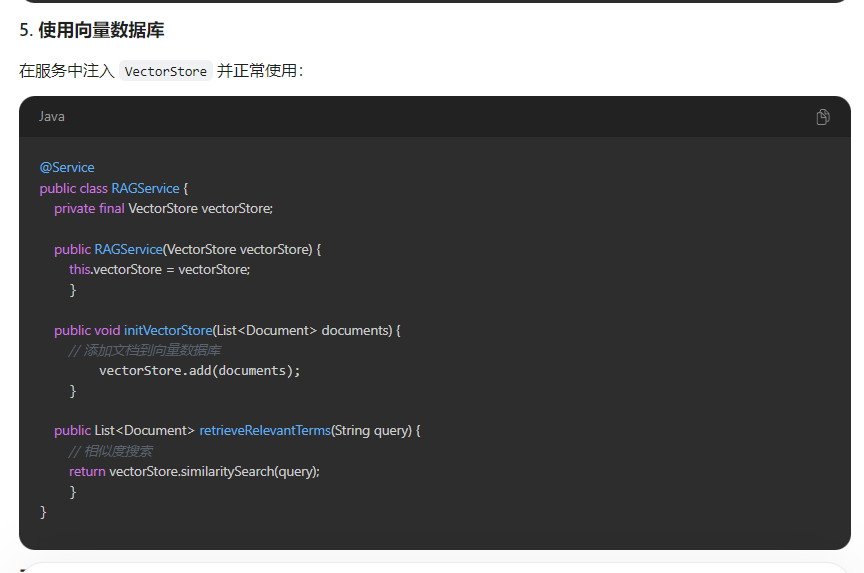

阿里百炼官方文档:
https://help.aliyun.com/zh/model-studio/what-is-model-studio?spm=a2c4g.11174283.0.i0
DeepSeek官方文档:
https://api-docs.deepseek.com/zh-cn/guides/function_calling

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)