强化学习基本概念 & 贝尔曼方程 Bellman Equation
学的这个课程
配套的书比讲义要详细,可以同步看书
建议直接去看书,本篇整理内容出处为讲义&书
state: the status of the agent with respect to the environment
state space: the set of all states, agent can have many states
action: possible actions for each state, different states can have different sets of actions
action space of a state: the set of all possible actions of a state
state transition: when taking an action, the agent may move from one state to another. It can be deterministic or stochastic.
tabular representation: we can use a table to describe the state transition, but can only represent deterministic cases
policy tells the agent what actions to take at a state. It can be deterministic or stochastic (all possible actions)
tabular representation of a policy can represent either deterministic or stochastic cases.
reward: a real number we get after taking an action, can represent encouragement or punishment; positive can mean punishment. In fact, it is the relative reward values instead of the absolute values that determine encouragement or discouragement.reward can be interpreted as a human-machine interface, with which we can guide the agent to behave as what we expect.
a trajectory is a state-action-reward chain, it can be infinite. Therefore, we can introduce a discount rate, then the sum becomes finite and it can balance the far and near future rewards.
the return of this trajectory is the sum of all the rewards collected along the trajectory, return could be used to evaluate whether a policy is good or not
episode: when interacting with the environmnet following a policy, the agent may stop at some terminal states. The resulting trajectory is called an episode.
episodic/continuing tasks can be treated in a unified mathematical way by converting episodic tasks to continuing tasks.
Markov decision process:
1) Markov property: memoryless property of a stochastic process.
Mathematically, it means that
Equation indicates that the next state or reward depends merely on the current state and action and is independent of the previous ones.
2) policy: in state s, the probability to choose action a is ..It holds that
for any
.
3) state/action/ reward/ state transition probability/ reward probability
state transition probability: In state , when taking action
, the probability of transitioning to state
is
, it holds that
for any
reward probability: In state , when taking action
, the probability of obtaining reward
is
. it holds that
for any
.
4) Markov decision process becomes Markov process once the policy is given
model or dynamics: and
for all
. The model can be either stationary or nonstationary. A stationary model does not change over time, a nonstationary model may vary over time.
I. a specific example
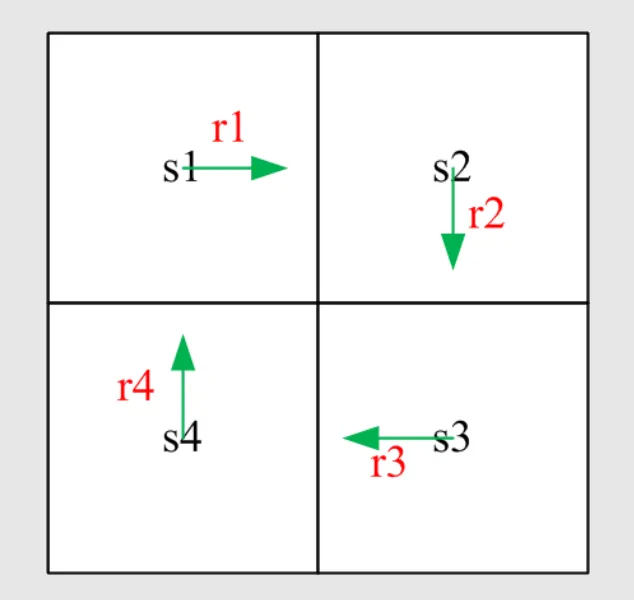
v1=r1+γv2
v2=r2+γv3
v3=r3+γv4
v4=r4+γv1
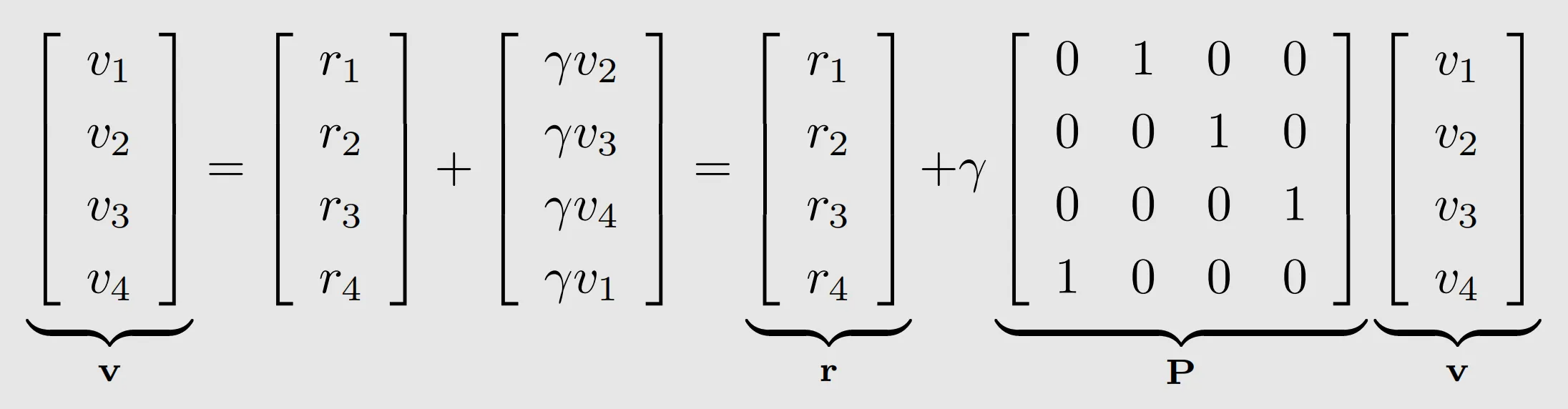
which can be written compactly as
v=r+γPv
Though simple, the Bellman equation demonstrates the core idea:
the value of one state relies on the values of other states.
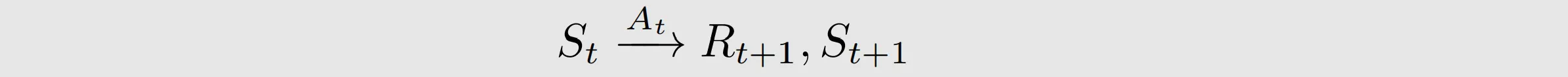
policy tells the agent what actions to take at a state. It can be deterministic or stochastic
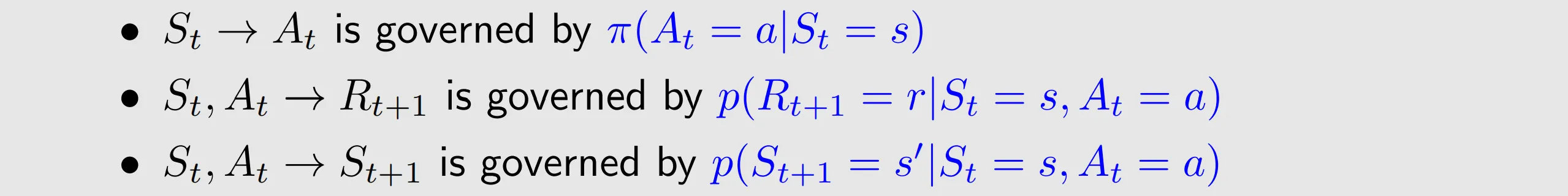
this means even if St and At are known, Rt+1 and St+1 still are random variables.
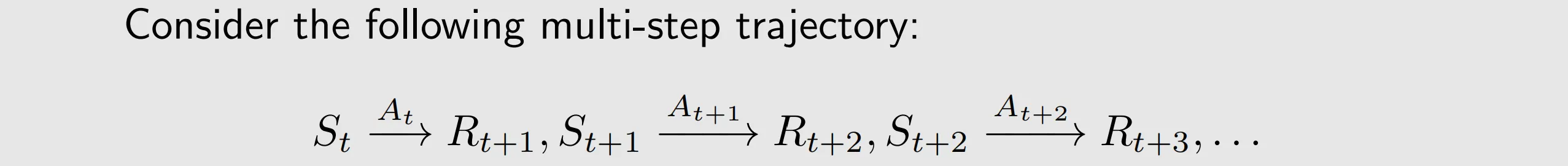
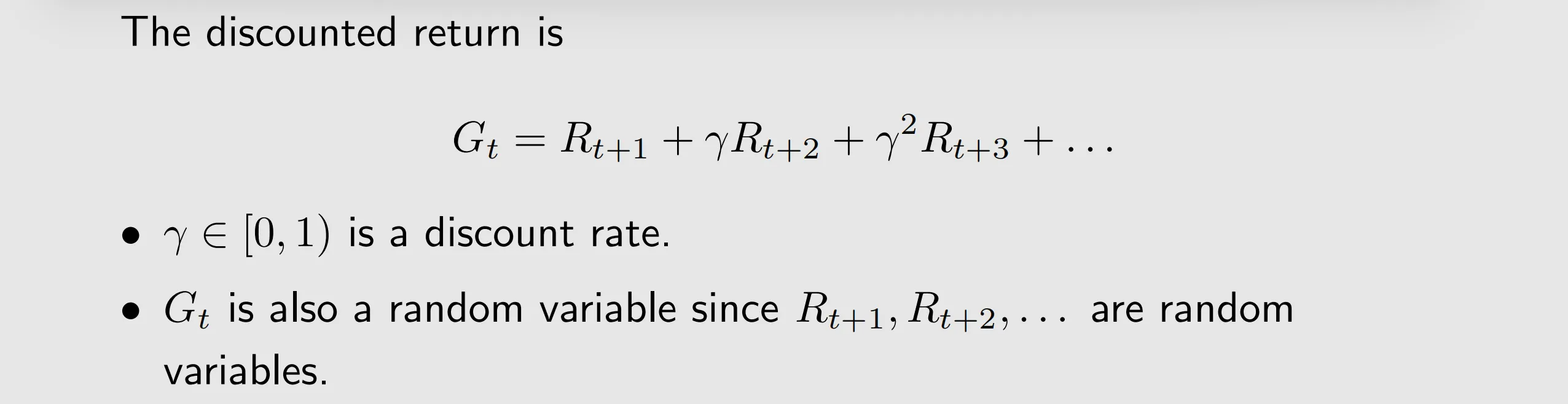
state value:
- introduce some notations
Consider a sequence of time steps t=0,1,2,... At time t, the agent is in state , and the action taken following a policy
is
. The next state is
, and the immediate reward obtained is
. This process can be expressed concisely as
Note that these are all random variables.
Moreover, and
- By definition, the discounted return along the trajectory is
- Since
is a random variable, we can calculate its expected value:

it depends on s. It is a conditional expectation with the condition that the state starts from s.
It depends on . For a different policy, the state value can be different
It does not depend on t.
It represents the value of a state. If the state value is greater, then the policy is better because greater cumulative rewards can be obtained. if both the policy and the system model are deterministic, return can be used to evaluate policies. By contrast, when either the policy or the system model is stochastic, starting from the same state may generate different trajectories and the state value can be used to evaluate policies.
The state value is the expected return starting from that state and following policy thereafter
II. Bellman equation: Derivation
the Bellman equation can be used to calculate state value
the Bellman equation describes the relationship among the values of all states.


the first term is the expectation of the immediate rewards.
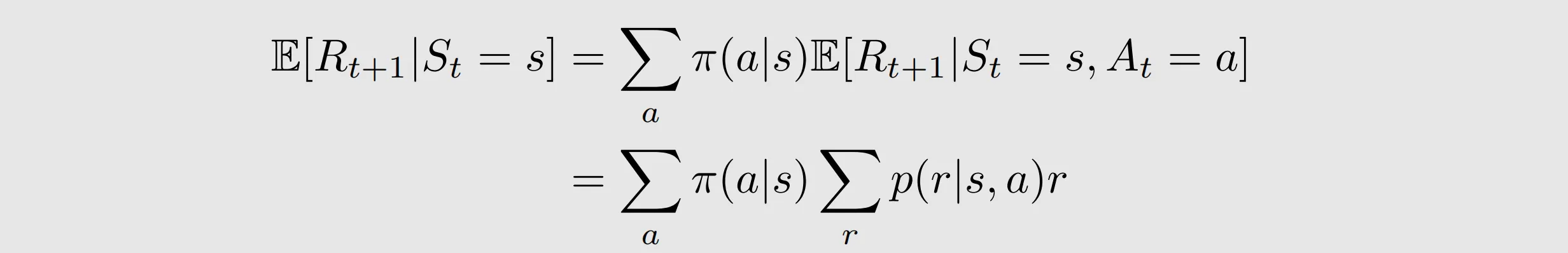
r depends on s,a and s', however, since s' also depends on s and a, we can equivalently write r as a function of s and a.
the second term
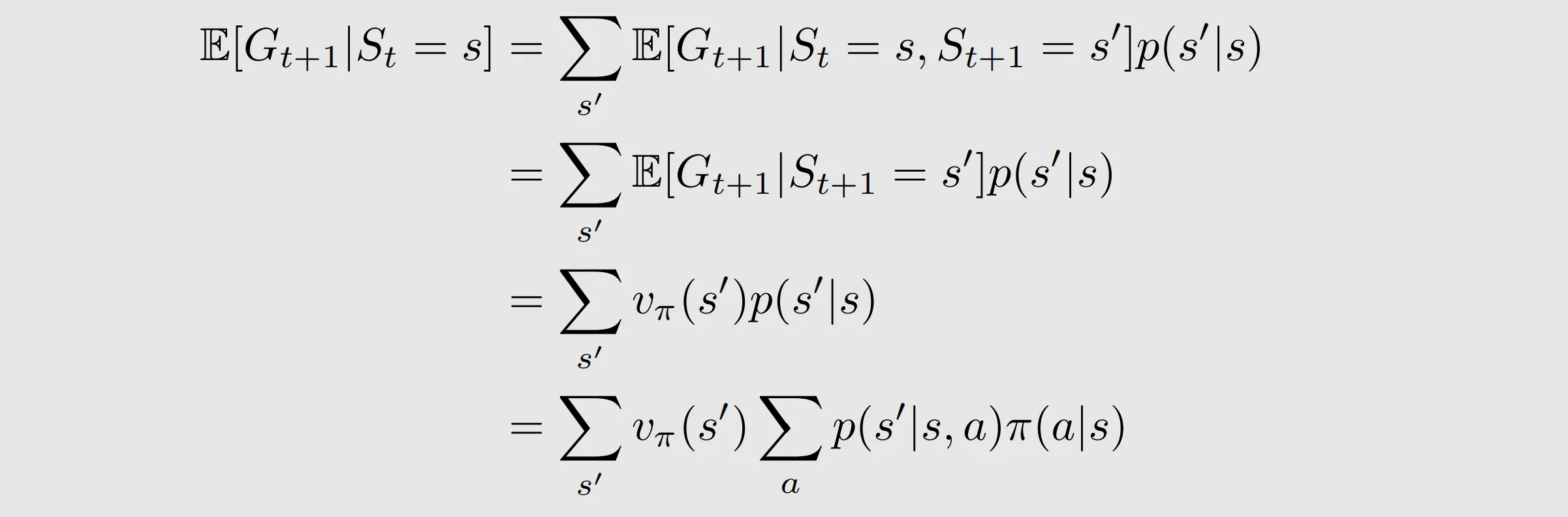
=
![]()
these two formulas are the same because of the interchangeability of double summation
the first formula: given every possible s', calculate its return vΠ(s') multiply by total transition probability( s-->s')
the second formula: calculate the expectation of the return of the next state given a specific policy, then multiply it by action selection
St=s can be deleted because of the memoryless Markov property. Given St+1=s', St=s provides no additional information
Therefore, we have
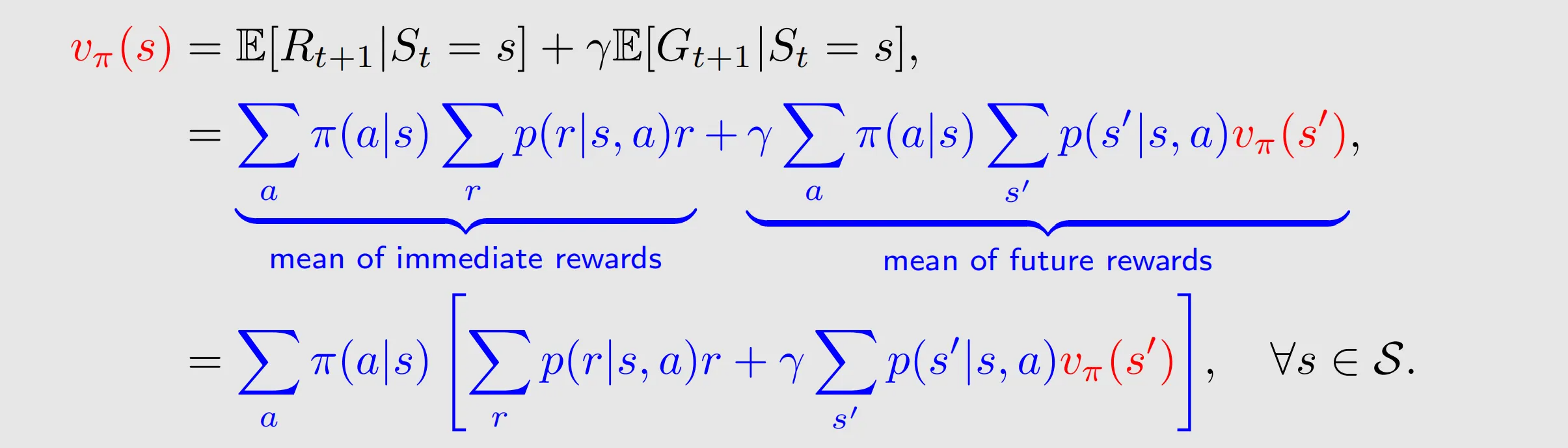
Bellman equation: characterizes the relationship among the state-value functions of different states.
It consists of two terms, the immediate reward term and the future reward term.
III. Bellman equation: Matrix-vector form
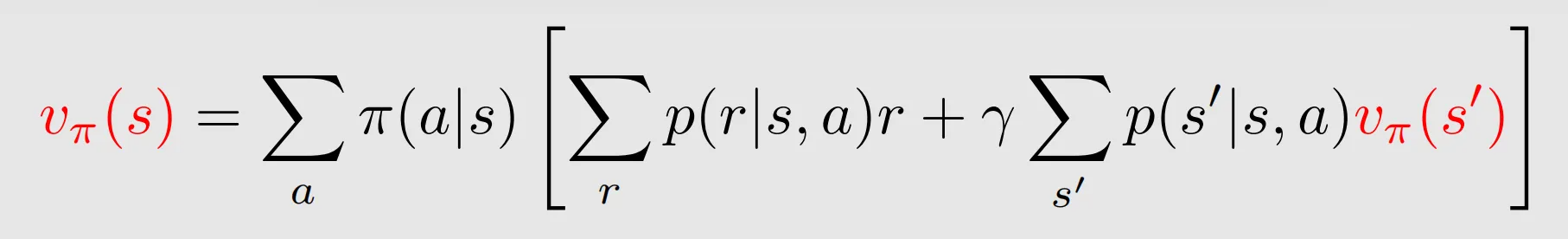
The above elementwise form is valid for every state. That means there are S equations like this
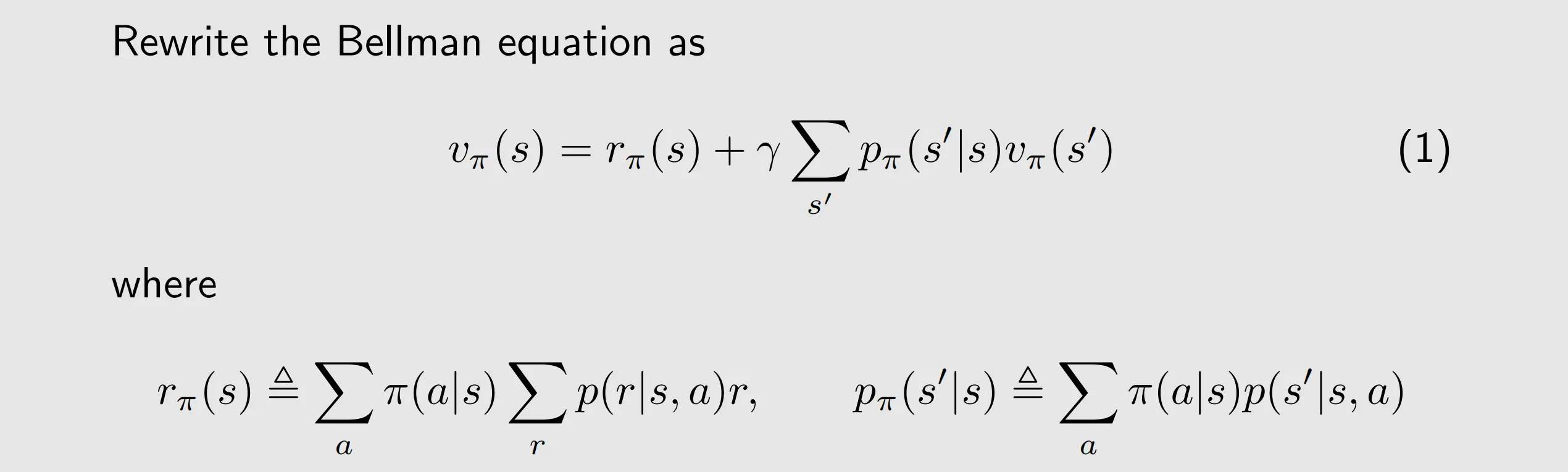
denotes the mean of the immediate rewards
is the probability of transitioning from s to s' under policy
suppose that the states are indexed as si with i=1,…,n, where . For state si, (1) can be written as
let , and
with
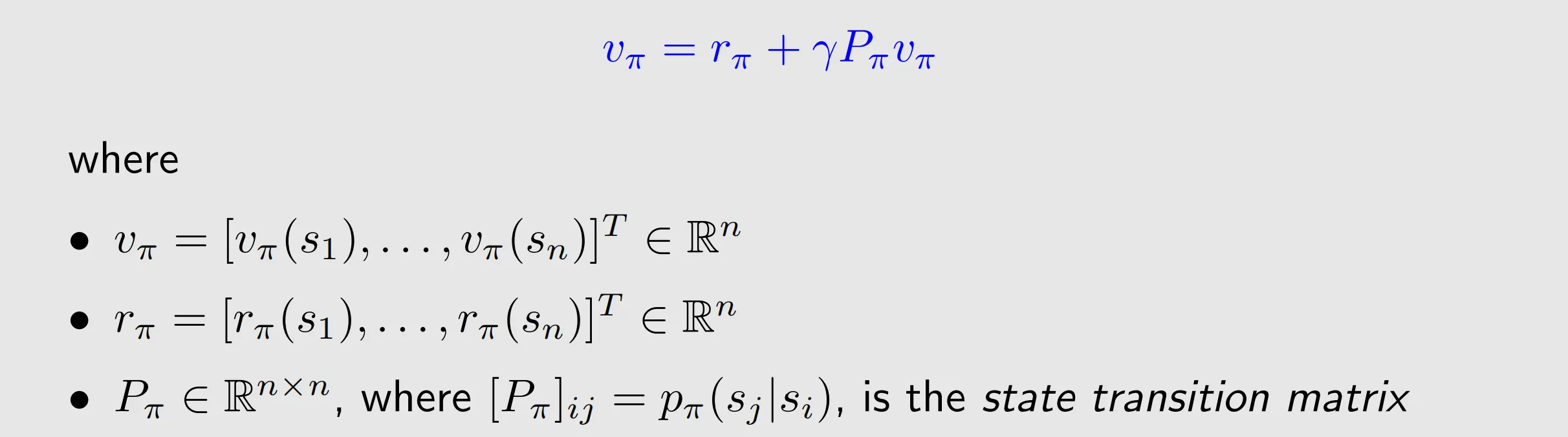
where is the unknown to be solved, and
are known.
properties of : 1.
2.
is a stochastic matrix, meaning that the sum of the values in every row is equal to one.
IV. Bellman equation: solve the state values(policy evaluation)
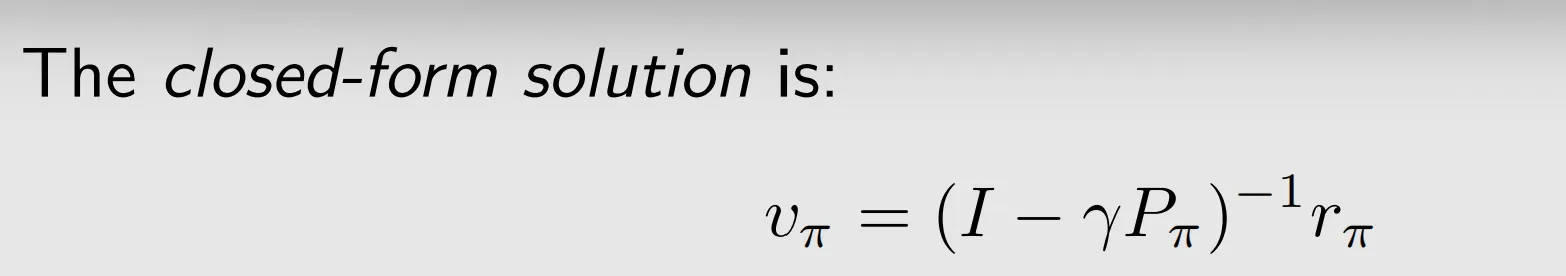
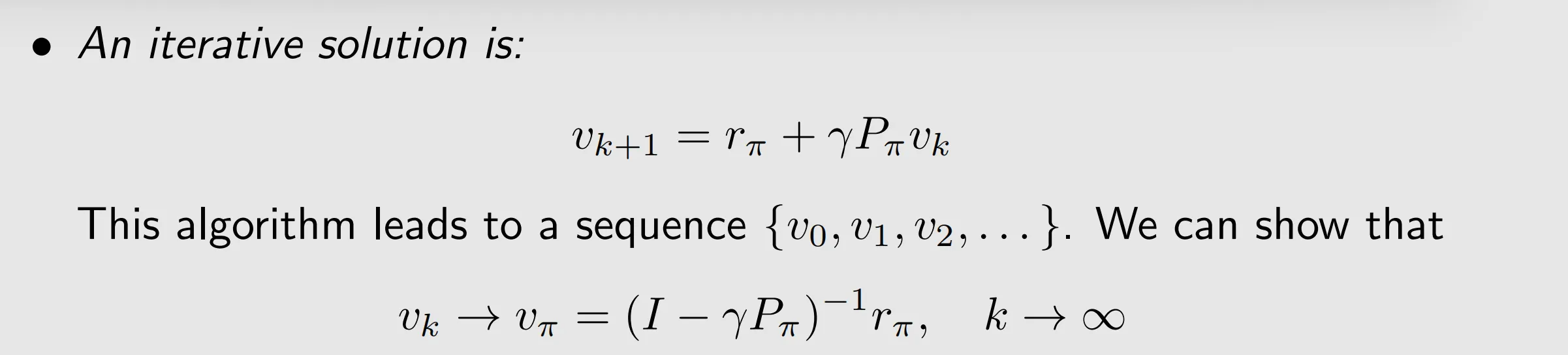

V. Action value
state value: the average return the agent can get starting from a state
action value: the average return the agent can get starting from a state and taking an action
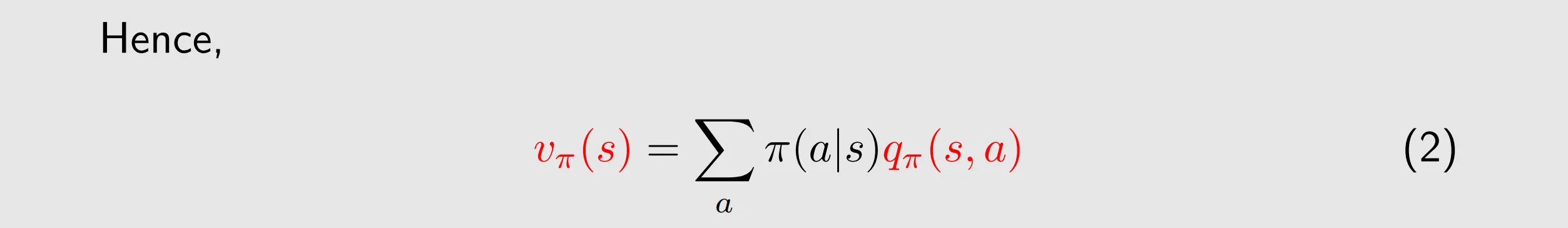
(2) shows how to obtain state values from action values
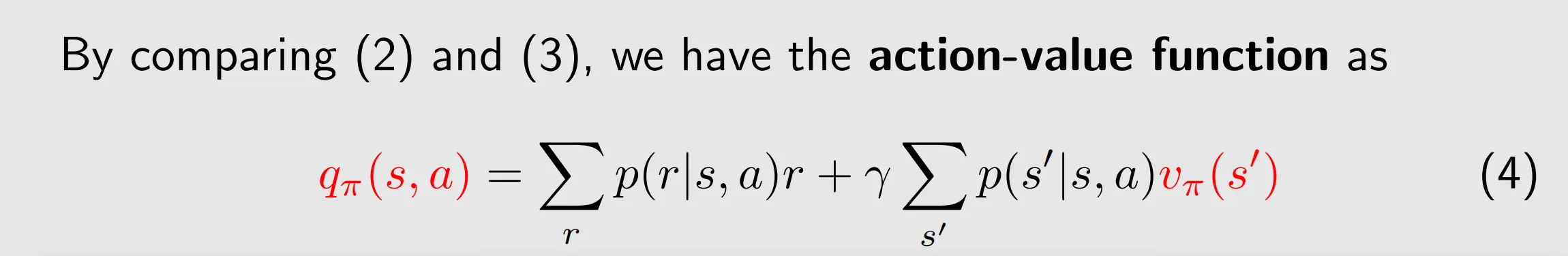
an action value relies on the values of the next states that the agent may transition to after taking the action.
(4)shows how to obtain action values from state values
The Bellman equation in terms of action values
substituting (2) into (4) yields
tips:
-
state value is the function of state and policy
-
action value is relevant to action, state and policy
-
even if an action would not be selected by a policy, it still has an action value, since the pur-pose of reinforcement learning is to find optimal policies, we must keep exploring all actions to determine better actions for each state.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)