AI服务器供电革命:为何交错并联Buck成为算力时代的必然选择
摘要:随着AI算力需求爆发式增长,服务器供电系统面临严峻挑战。本文深入分析交错并联Buck技术在AI服务器电源中的核心价值:通过多相纹波抵消实现亚毫伏级噪声控制,分散热源提升功率密度,以及优化动态响应满足AI芯片瞬态需求。文章构建了包含四象限分析、MECE原则和SMART目标的系统设计框架,并以NVIDIA DGX系统为例,展示了从12相交错设计到自适应相位管理的演进路径。最后探讨了3D集成供电和
引言:当算力需求撞上物理学的墙
数据中心机房的低鸣,如今已演变为AI算力洪流的咆哮。根据Synergy Research Group的数据,2023年全球超大规模数据中心数量已突破900座,其中用于AI训练的算力集群正以每年超过50%的复合增长率膨胀。一个更具冲击力的事实是:单颗NVIDIA H100 GPU的峰值功耗已突破700瓦,而一个满载8颗H100的DGX服务器节点,瞬时功率需求可达6千瓦以上。这不仅仅是一个数字,它意味着供电网络必须在微秒级别内,稳定、高效地应对高达数千安培的电流瞬态变化。
传统的单相或简单多相Buck变换器在此等严苛需求面前已捉襟见肘。工程师们发现,即便使用最先进的功率MOSFET和控制器,纹波噪声干扰导致的计算错误、因局部过热引发的系统降频、以及为了散热而付出的巨大空间与能耗代价,正成为榨取AI芯片极限算力的主要瓶颈。
核心论点:
- 纹波抑制的物理极限:交错并联技术通过精确的相位延时,从根源上实现了输入/输出纹波的主动抵消,这是满足AI芯片亚毫伏级电源噪声容限的唯一高效途径。
- 热管理的系统重构:它将集中发热分散为多个可管理的“热源”,结合热-电协同设计,直接决定了系统的功率密度与长期可靠性。
- 动态响应的架构优势:多相交错等同于将一个大电感“等效分割”,大幅提升了环路带宽,使电源能够像“迅捷的仆从”一样,跟上AI芯片负载瞬息万变的步伐。
本文将带您穿透“交错并联”这一技术名词的表面,从物理学、控制论和系统工程的交叉视角,深度剖析其成为AI服务器电源“心脏”的必然逻辑。您将不仅理解“为什么”,更将掌握一套基于四象限分析法、MECE原则和SMART目标的系统级设计评估框架,并透过头部厂商的真实案例,看清未来高密度供电的技术演进路径。
第一章:理论基石——交错并联的物理学与优化数学
1.1 纹波抵消:从时间域到频率域的优雅舞蹈
任何开关电源的电流纹波都源于功率器件的周期性开关动作。对于占空比为D的单相Buck变换器,其电感电流纹波峰峰值公式为:
其中,(f_{sw})为开关频率,L为电感感量。其输出纹波电压直接与此电流纹波相关。
交错并联(Interleaving)的核心思想,是将N个相同的Buck变换器并联,但使它们的控制时钟(开关信号)依次错开 (360^\circ / N) 的相位。这一操作的妙处,体现在叠加原理上。
以两相交错为例:
- 单个相位的电感电流纹波波形峰值为 (\Delta I_L),形状为三角波。
- 当两相相位差180°时,一相电流上升时另一相电流下降。它们在输出电容处汇总。
- 总输出电流是两相电流之和。通过数学推导(基于傅里叶分析),总输出电流的纹波频率加倍(变为 (2 \times f_{sw})),而纹波幅值显著降低。
其纹波抵消系数 (k_r(N)) 可以表示为:
在理想占空比D=0.5时,两相交错(N=2)的纹波理论值可降至单相的 25%,四相交错(N=4)则可降至约 6%。
这不仅仅是量的减少,更是质的飞跃:
- 频域提升:纹波基频移至N倍开关频率,更易被高频特性更好的陶瓷电容滤除。
- 电容应力减小:所需承纹波电流的电容容量和体积可以大幅缩减,这对高密度设计至关重要。
// 伪代码:两相交错Buck PWM生成逻辑 (基于定时器中断)
#define PHASE_NUM 2
uint16_t phase_shift_degree[PHASE_NUM] = {0, 180}; // 相位差定义
void PWM_Init() {
Timer_Config master_timer(FREQ_SW); // 主开关频率
for (int i = 0; i < PHASE_NUM; i++) {
PWM_Channel_Config channel_i;
channel_i.base_timer = &master_timer;
channel_i.phase_offset = (master_timer.period * phase_shift_degree[i]) / 360; // 计算相位偏移计数
channel_i.duty_cycle = calculate_duty(Vin, Vout); // 统一占空比
enable_channel(channel_i); // 使能PWM通道
}
}1.2 热力学与功率密度:分散的艺术
焦耳定律清楚地表明,导通损耗与电流的平方成正比。在单相大电流方案中,所有损耗集中在一个或少数几个功率回路上,导致局部热流密度极高,形成“热点”(Hot Spot)。
交错并联通过 “分流” 实现了 “分热”。假设总电流为 (I_{total}),采用N相交错,每相平均电流为 (I_{total}/N)。那么,单相导通损耗变为:
总导通损耗为单相的 (1/N)。更重要的是,发热源从1个变为N个,均匀分布在PCB上,散热面积有效增加,极大降低了散热设计的难度和风冷需求的功耗。这是实现功率密度(W/in³)突破的关键。
为了系统评估热设计挑战,我们可以引入 四象限分析法 进行问题诊断:
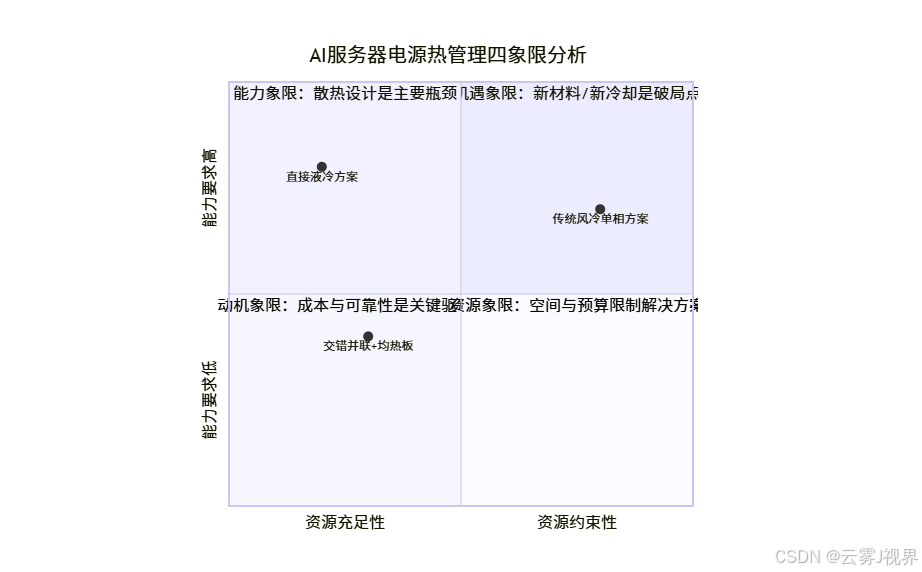
如图所示,传统方案深陷“能力-资源”双重困境,而交错并联通过架构优化,将问题移向“资源-动机”象限,成为更具可行性的高效解决方案。
第二章:实战解码——从实验室到数据中心的系统权衡
我们选择以 NVIDIA 的 DGX 系统 作为贯穿案例。作为AI服务器的标杆,其供电架构的演进极具代表性。
2.1 案例深度研究:从DGX A100到DGX H100的供电架构演进
背景与挑战:
- 核心矛盾:如何在1U/2U的有限空间内,为TDP持续飙升的GPU提供“零妥协”的供电质量,同时确保系统在满负荷下的长期可靠运行。
- 量化数据(DGX A100):单颗A100 GPU TDP为400W,8颗GPU峰值需求超3.2kW。实测其核心电源(VDD)负载阶跃(Load Step)速率高达500A/μs,电流瞬态峰值超600A。纹波噪声若控制不当,将直接导致GPU内部数以万计的计算核心(CUDA Core)发生时序错误或计算精度下降。
解决方案(以VDD电源为例):
[步骤一:MECE架构分解] 设计团队首先运用 MECE原则 拆解供电需求。VDD供电被“相互独立,完全穷尽”地分解为:稳态高效率区、瞬态大电流响应、高频纹波抑制、低频负载调整、故障隔离与均流 五个子问题。
- 单一拓扑无法MECE地解决所有问题。结论是:需要一个 “高频多相交错Buck + 紧随其后的线性稳压器(LDO)” 的复合架构。高频多相Buck负责处理大电流和主要效率,后级LDO(或称为“负载点开关电容转换器”)提供最终的纹波“剃除”。
[步骤二:拓扑选择与相位优化] 对于前级Buck,团队选择了 12相交错并联拓扑。相位数的确定基于SMART原则:
- 具体 (S):目标是将PCB平面上的电感电流纹波峰值降低至单相的1%以内,并将有效纹波频率推至2MHz以上。
- 可衡量 (M):通过仿真和原型测试,测量开关节点噪声和输出纹波。
- 可实现 (A):使用当时成熟的、支持12相的数字多相控制器(如Infineon XDPE或MPS HR-1000系列)和功率级。
- 相关 (R):直接关联GPU的计算稳定性与超频潜力。
- 有时限 (T):在芯片设计周期内完成验证。
[步骤三:热-电协同设计] 12个功率电感与MOSFET被严格按对称网格布局,下方对应巨大的散热均热板(Vapor Chamber)。热仿真与电气同步进行,确保无局部热点。
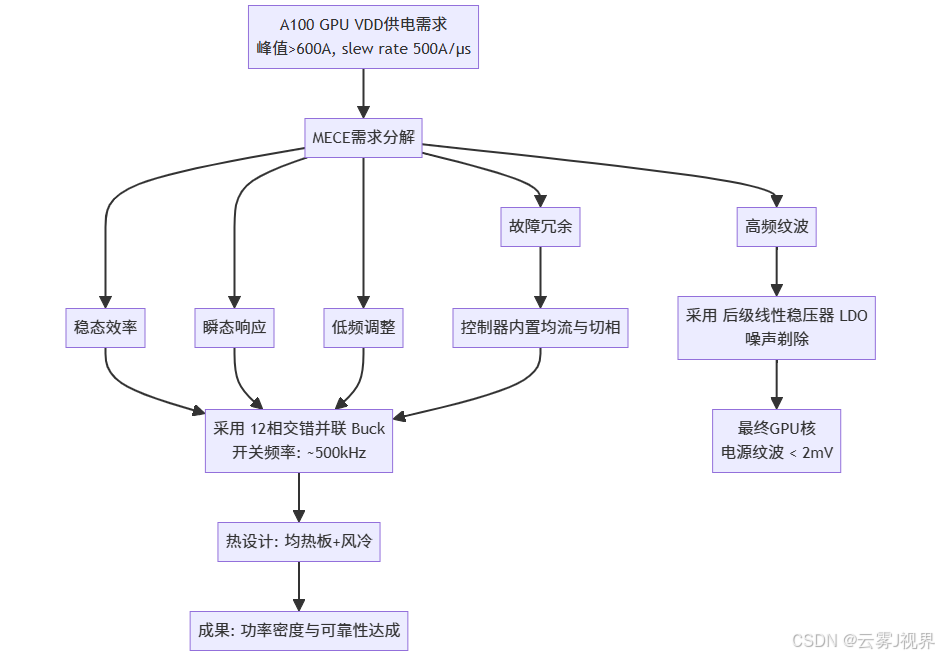
实施成果:
- 直接效果:DGX A100的GPU供电网络实现了>95%的峰值效率,核心电压纹波被控制在±2mV以内,完全满足GPU苛刻的电源噪声要求。相对于前代非交错优化的设计,在相同电流下,电感温升降低了超过25°C。
- 长期价值:这套供电架构奠定了NVIDIA高端计算平台的基础,其高可靠性(MTBF大幅提升)使得超大规模数据中心能够放心地部署成千上万个节点进行7x24小时训练,直接支撑了ChatGPT等大模型的诞生。
演进至H100:当H100 GPU TDP跃升至700W,其供电需求更为恐怖。NVIDIA的解决方案是 进一步增加交错相位数(如16相或更多)并提升开关频率,同时引入了更精细的 自适应相位管理(Adaptive Phase Shedding)。
- 轻载时,主动关闭部分相位,将剩余相位的工作点移至更高效率区间。
- 重载瞬态时,所有相位以纳秒级延迟同时响应,提供最大电流能力。
- 这种动态重构能力,是传统固定相位架构无法实现的,它完美体现了交错并联在 “效率”与“性能” 之间的弹性优势。
2.2 系统级权衡框架:效率、密度与成本的铁三角
没有免费的午餐。交错并联带来了性能飞跃,也引入了新的权衡点。一个专业的电源架构师必须运用系统思维进行评估。
1)效率 (Efficiency) vs. 成本/复杂性 (Cost/Complexity):
- 更多相位意味着更多的功率级(MOSFET、电感、驱动),BOM成本上升。
- 解决方案:采用 集成化功率级 (Power Stage) 或 DrMOS,将驱动器和MOSFET封装一体,节省面积,优化寄生参数,有时反而能在系统层面降低成本。
2)功率密度 (Power Density) vs. 散热能力 (Thermal):
- 相位越多,理论上热分布越好,但所需的总PCB面积也越大。
- 解决方案:采用 耦合电感技术。将两相或多相电感绕制在同一个磁芯上,既能保持纹波抵消效果,又能大幅减小磁件体积和损耗。但这会增加磁设计复杂度,并可能影响瞬态响应(电感耦合系数带来的权衡)。
3)动态响应 (Transient Response) vs. 稳定性 (Stability):
- 交错并联等效减小了输出电感,提升了带宽,但也使环路更容易受到高频噪声干扰。
- 解决方案:采用 先进数字控制(如基于PID或状态空间的数字补偿器),并引入输入电压前馈(Feedforward),在保持快速响应的同时,精确控制稳定性裕度。
// 简化数字PID控制代码示例(用于单电压环)
typedef struct {
float Kp, Ki, Kd; // PID参数
float integral_sum;
float prev_error;
} PID_Controller;
float PID_Update(PID_Controller* pid, float setpoint, float feedback, float dt) {
float error = setpoint - feedback;
pid->integral_sum += error * dt;
float derivative = (error - pid->prev_error) / dt;
pid->prev_error = error;
return (pid->Kp * error) + (pid->Ki * pid->integral_sum) + (pid->Kd * derivative);
}
// 多相控制器会为每相分配一个这样的计算实例,并汇总结果进行PWM调制。第三章:超越拓扑——未来AI供电系统的前沿瞭望
交错并联Buck是当下的王者,但技术的进化永不停止。AI算力的“摩尔定律”正倒逼供电网络进行更激进的革新。
3.1 三维集成供电(3D Power Delivery):最后的毫米
当芯片封装从2.5D(CoWoS)走向真正的3D堆叠,供电也必须从PCB层面“爬上”芯片,进入封装内(In-Package) 甚至 芯片背面(Back-Side)。
- 硅基电容(Silicon Capacitor):利用半导体工艺在硅中介层或芯片背面制作深沟槽电容,其寄生电感极低(<10pH),是应对>1000A/μs电流变化率的终极武器。此时,供电拓扑可能演变为超多相(如32相、64相)的微型Buck转换器,直接集成在封装内,通过硅通孔(TSV) 向计算裸片供电。
- 挑战:集成转换器的效率、散热以及设计与制造复杂度将呈指数级上升。
3.2 智能化能源管理(AI for Power)
未来的供电系统将不再是简单的“跟随者”,而是具备预测能力的“协作者”。
- 基于机器学习的负载预测:AI工作负载具有特定的周期性和模式。电源管理系统可以通过学习历史数据,提前几十至几百微秒预测到CPU/GPU的负载跃变,并提前调整相位开关状态或输出电压,实现 “零跌落”瞬态响应。
- 动态健康管理与故障预测:实时监测每相MOSFET的导通电阻、电感温度等参数,利用AI模型预测器件寿命衰减,在故障发生前进行告警或系统重构,实现最高等级的可用性。
结语:从组件思维到系统思维的跃迁
回顾全文,我们可以清晰地看到一条技术演化的主线:
- 核心必然性:交错并联Buck并非凭空出现的“黑科技”,而是AI服务器对 “极高电流、极快瞬态、极低噪声、极严散热” 四大物理约束的必然回应。它用分布式架构化解了集中式设计的根本矛盾。
- 权衡的艺术:优秀的设计不在于追求某个指标的极致,而在于精通 效率、密度、成本、可靠性 这个“铁三角”的系统级权衡。四象限分析法、MECE原则和SMART目标是我们进行理性决策的罗盘。
- 未来的起点:我们正站在供电网络从“板级”向“芯片级”跃迁的前夜。三维集成供电和智能化管理,将是延续算力增长曲线的下一个关键。
三个开放式问题,留给您与我一同思考:
- 当开关频率借助GaN器件提升至10MHz以上,寄生参数成为主导,那时的“最佳相位数量”模型会发生哪些根本性变化?
- 如果未来计算芯片采用光互连,其供电网络是会被彻底颠覆,还是与当前架构融合演化?
- 面向可能到来的量子计算时代,其对供电系统的核心要求(如超低噪声、极低温环境)是否会催生一个完全不同于开关电源的全新物理体系?
供电,这场在方寸之间进行的、关乎能量流动与控制的精密艺术,正以前所未有的深度,定义着AI算力的天花板。而我们,正是这场革命的塑造者。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献129条内容
已为社区贡献129条内容

所有评论(0)