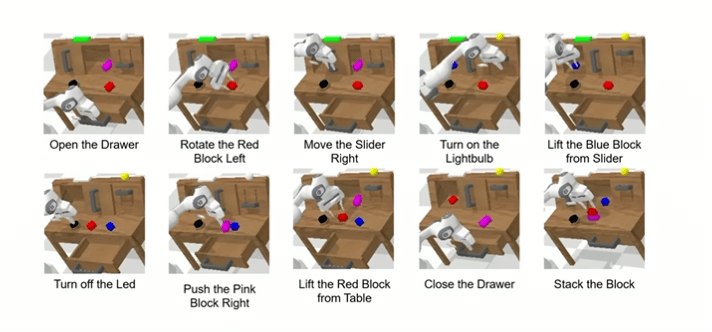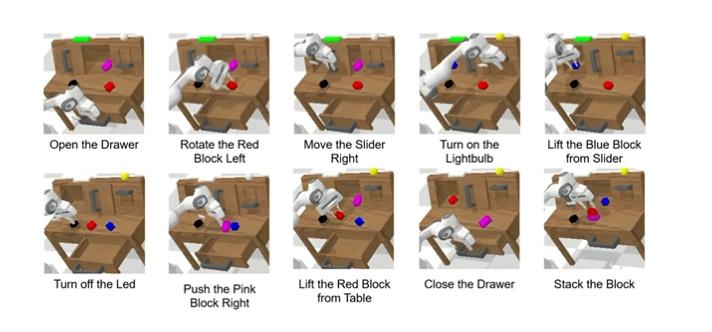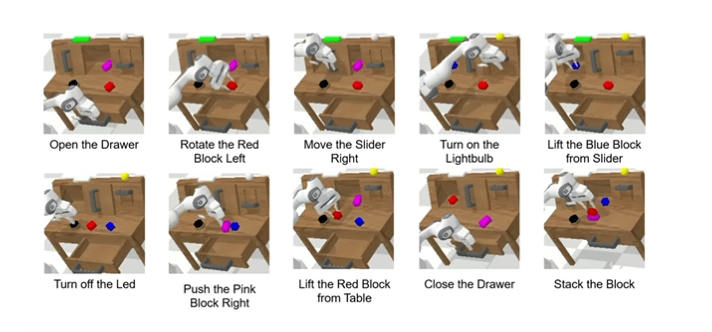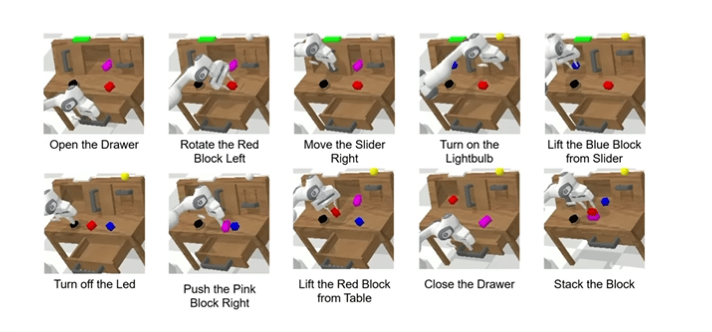
AAAI 2026 最佳论文出炉:港科广 ReconVLA 打破 VLA 模型注意力困局
未来,VLA模型的竞争可能会聚焦在“如何更高效地引导注意力”和“如何用更少的数据实现泛化”——ReconVLA给出了一个可行的方向,但要完全解决复杂场景的问题,还需要融合动态目标检测、物理先验知识等更多技术。重建任务的核心是一个轻量扩散Transformer(Diffusion Denoiser),它的作用不是生成高清图像,而是从加了噪音的特征中,还原凝视区域的“细粒度特征”视觉接地能力薄弱,导致

10 万轨迹 + 200 万样本,首创“重建式”VLA
——Outstanding Paper Award
目录
扩散Transformer:从噪音里“抠细节”,逼着模型学精
今天上午,AAAI 2026现场,港科大(广州)、西湖大学等团队联合发布的ReconVLA斩获最佳论文!
这一成果直击传统视觉-语言-动作(VLA)模型的核心痛点——
视觉接地能力薄弱,导致机器人在杂乱环境或长时程任务中注意力“跑偏”,要么分散于无关区域,要么紧盯错误目标,最终引发操作失败。
ReconVLA以“重建引导注意力”的隐式接地范式实现突破,无需额外输入与冗余输出,仅通过轻量扩散Transformer重建目标区域,就能迫使模型聚焦核心特征,在仿真与真实世界中同步达成“精准操纵”与“强泛化”。
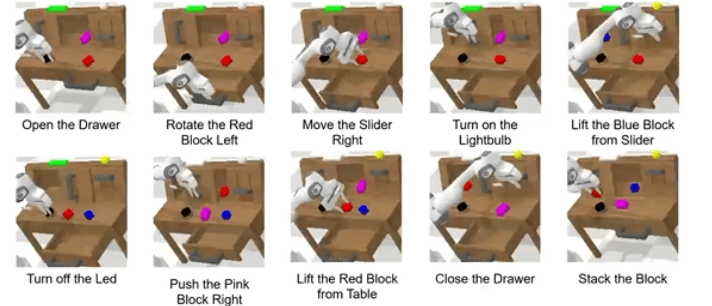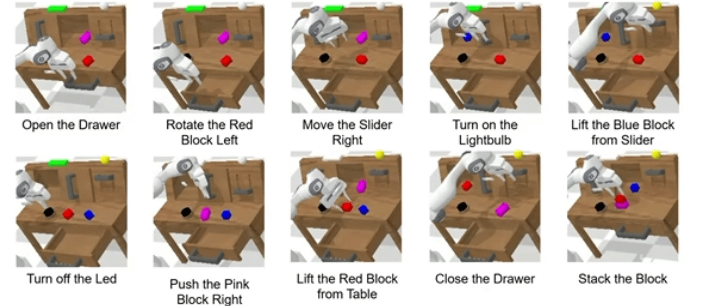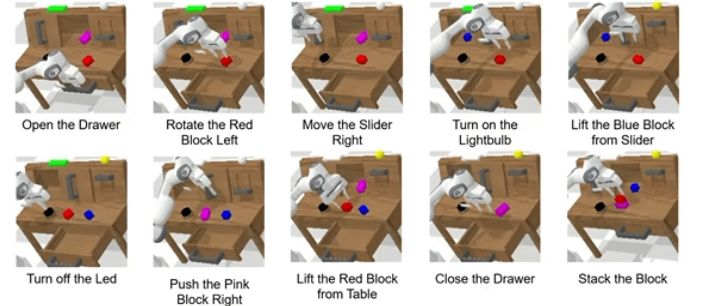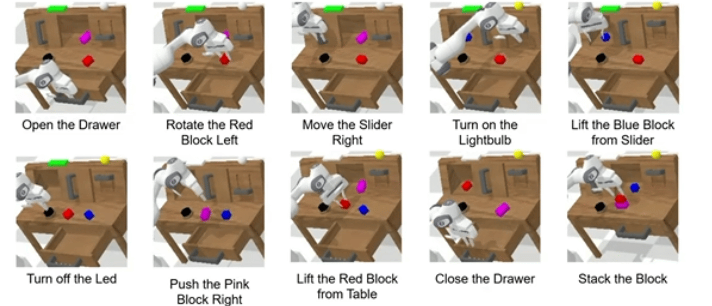
下面我们详细拆解,为什么ReconVLA能获得Outstanding Paper Award,以及它还存在哪些未解决的难点。
01 用“重建”逼模型专注目标
ReconVLA的核心思路特别直接:既然模型不会主动盯目标,那就设计一个“辅助任务”逼着它盯——
从噪音中重建目标区域(也就是“凝视区域”)
这个过程就像让模型“默写”目标的细节,为了写对,它必须主动记住目标的特征,注意力自然就聚焦了。
隐式接地:不增输入,不添输出,悄悄搞定注意力
ReconVLA提出的“隐式接地范式”,和传统方法最大的区别就是“无侵入性”:
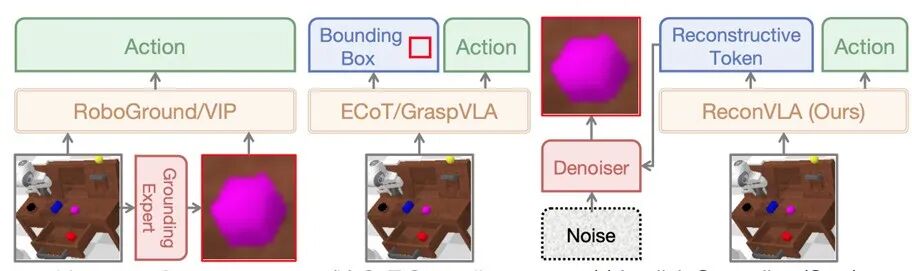
▲三种视觉接地范式(显式、思维链、隐式)的概念对比图
-
输入是原来的“图像+语言指令+机器人本体感受”(比如夹具状态),不用额外加抠图、坐标;
-
输出还是直接的动作指令,不用多输出边界框;
关键在于中间多了一个“重建监督”:模型在生成动作的同时,还要输出“重建tokens”,引导扩散Transformer从噪音中还原凝视区域的特征。
这个过程就像人类做事:你要把书放进书包,眼睛会自然盯着书(凝视区域),大脑会自动忽略周围的水杯、笔记本(干扰物)。
ReconVLA就是让模型模拟这种“主动凝视”,通过重建任务,把“盯目标”变成一种内在能力,而不是靠外部指令。
凝视区域:不止是“目标”,更是“任务导航”
很多人会觉得“凝视区域不就是目标物体吗?”
其实不然——它是“当前任务最该关注的区域”,在长时程任务中还会动态切换:
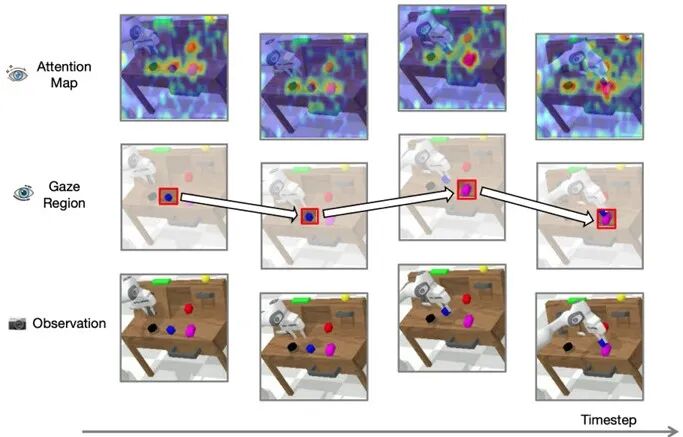
▲长时程 “堆叠方块” 任务中观察、凝视区域与注意力图的可视化
比如“堆叠方块”任务
-
第一步要抓蓝色方块,凝视区域就是蓝色方块;
-
第二步要放在粉色方块上,凝视区域就变成粉色方块的顶面。
这种动态切换让模型自然学会“分步骤做事”,不用额外设计子任务规划模块,这也是ReconVLA在长时程任务中表现突出的关键。
扩散Transformer:从噪音里“抠细节”,逼着模型学精
重建任务的核心是一个轻量扩散Transformer(Diffusion Denoiser),它的作用不是生成高清图像,而是从加了噪音的特征中,还原凝视区域的“细粒度特征”(比如方块的颜色、碗的边缘)。
为什么用扩散模型?
因为扩散过程是“逐步去噪”,能逼着模型捕捉目标最本质的特征——不是简单模仿像素,而是记住“这个目标长什么样、有什么关键细节”。
比如抓碗时,模型会记住碗口的圆形特征,而不是桌面的纹理。
这样就算环境变了(比如桌面颜色换了),也能精准找到目标。
02 ReconVLA的设计拆解
ReconVLA的落地靠三个关键设计,既保证了效果,又兼顾了部署可行性:
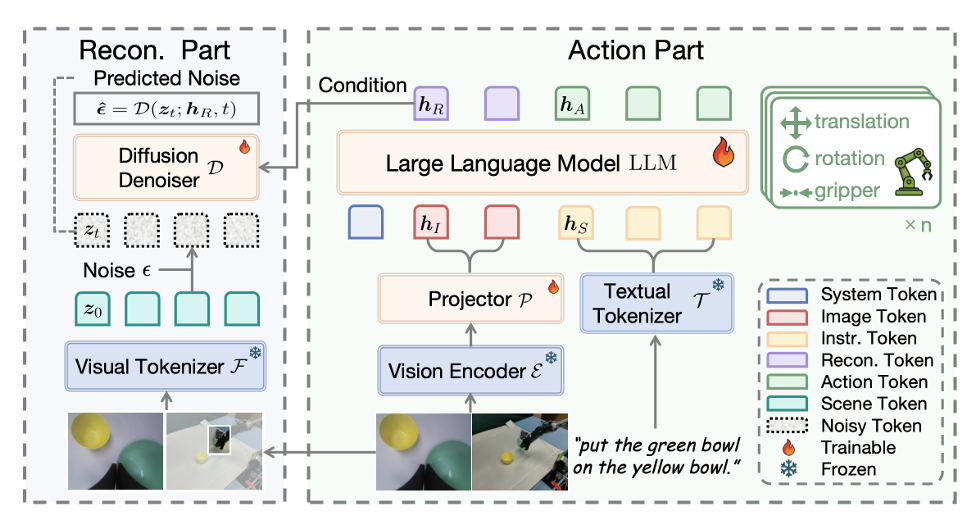
▲ReconVLA 模型整体架构图
模型架构:动作与重建“双轨并行”
ReconVLA的架构特别简洁,基于LLaVA-7b(Qwen2-7b为LLM backbone,siglip-so400mpatch14-384为视觉编码器)。
主要分两部分:
-
动作部分:
和传统VLA一样,把图像转成图像tokens,指令转成文本tokens,输入LLM生成动作tokens,再解码成机器人能执行的动作(比如夹具开合、机械臂位姿)。
-
重建部分:
LLM同时输出“重建tokens”,作为扩散Transformer的条件;
视觉Tokenizer(用VAE)把凝视区域转成 latent tokens(压缩后的特征),并加入噪音;
扩散Transformer根据重建tokens,从噪音中还原出原始latent tokens。
这两部分共享视觉-语言编码器,训练时一起优化,不会增加太多额外计算成本。
大规模预训练:200万样本“打底”
传统VLA模型的重建能力很弱,因为它们的 backbone(VLM)主要训练“看图说话”,没学过“还原图像”。
为了解决这个问题,ReconVLA进行了重新构建数据集并制定预训练策略:
-
数据集构建:
整合BridgeData V2、LIBERO、CALVIN三个开源数据集,用Grounding DINO(一个强开源目标检测器)自动分割“原图-凝视区域”图像对。
最终得到10万+轨迹、200万+样本的预训练数据集——
这是目前VLA领域少有的专门用于视觉重建的大规模数据。
-
预训练策略:
训练时同时优化动作损失和重建损失,让模型先学会“不管什么场景,都能还原目标特征”,再微调具体任务。

▲重建可视化
03 实验验证
研究在仿真(CALVIN基准)和真实世界中做了全面测试,在“精准度”和“泛化性”上,均具有明显优势:
仿真实验:CALVIN基准的“长时程王者”
CALVIN基准包含34个任务、4个环境,长时程挑战需要完成5个连续子任务。
-
范式对比
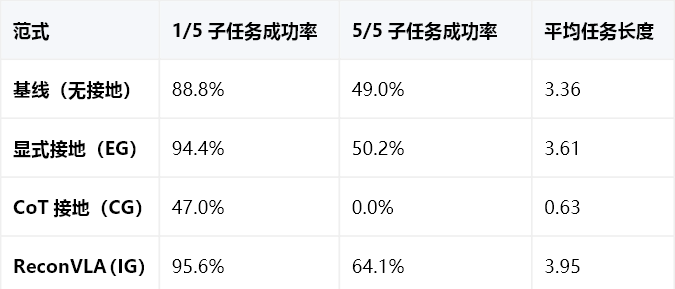
数据能看出:
显式接地比基线好一点,但5个子任务成功率只提升1.2%,冗余信息的弊端很明显;
CoT接地直接“翻车”,5个子任务成功率为0,说明坐标引导完全不适合操纵任务;
ReconVLA不仅首任务成功率最高(95.6%),5个子任务成功率更是比基线高15.1%,平均能完成3.95个任务,接近“全通关”。
-
SOTA对比
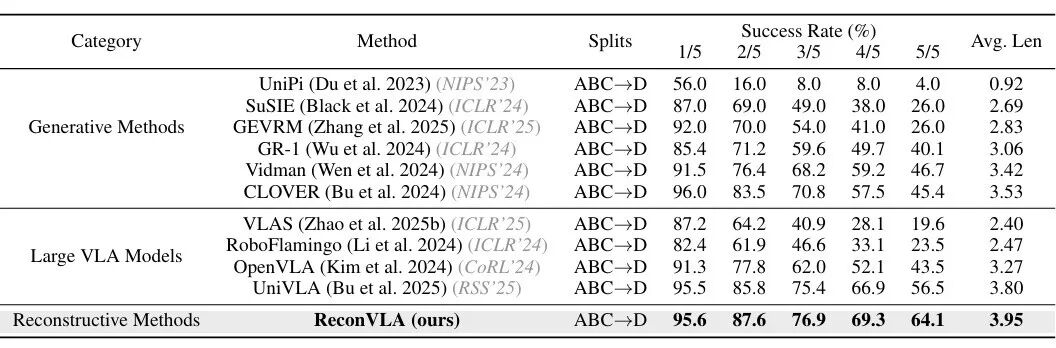
▲ReconVLA 与主流 VLA 模型的性能对标表
在CALVIN的ABC→D( unseen 背景)和ABCD→D(复杂场景)任务中,ReconVLA对阵OpenVLA、UniVLA、3D-VLA等主流模型,结果如下:
ABC→D任务:5/5子任务成功率64.1%,比OpenVLA(43.5%)高20.6%,比UniVLA(56.5%)高7.6%;
ABCD→D任务:首任务成功率98.0%,平均完成4.23个任务,比GR-1(生成式模型代表)高近20%。
即使是“堆叠方块”这个最难任务——基线成功率只有59.3%,ReconVLA为79.5%,提升20.2%,证明其精准操纵能力。
真实世界实验:unseen任务也能“零样本上手”
研究用6自由度AgileX PiPer机械臂,测试了4个实用任务(放水果入碗、堆叠碗、翻杯、清理桌面),还加入了“unseen任务”(替换没训练过的目标物体):

▲真实世界四项代表性操纵任务的实验设置图
-
已知任务:
ReconVLA在“放水果入碗”“堆叠碗”任务中成功率接近90%,远超OpenVLA和PD-VLA。
-
unseen任务:
OpenVLA和PD-VLA的成功率几乎为0,而ReconVLA凭借大规模预训练的泛化能力,能精准找到新目标并完成动作。
注意力可视化:从“撒胡椒面”到“精准锁靶”
最直观的对比:
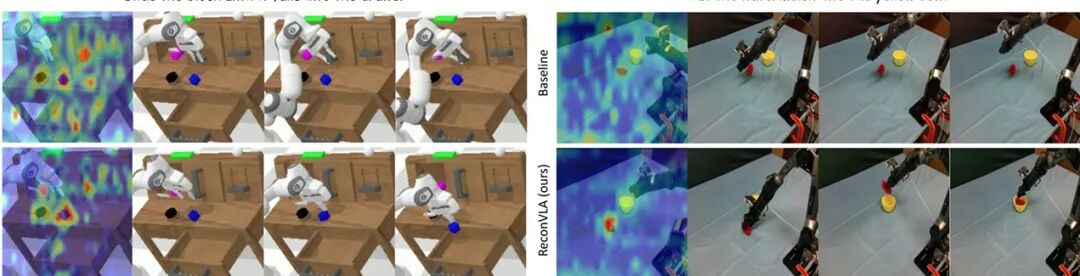
▲CALVIN 仿真与真实世界中基线模型与 ReconVLA 的注意力图定性对比 ——ReconVLA 聚焦目标区域助力精准任务完成
基线模型的注意力分散在整个图像,甚至盯着背景;
ReconVLA的注意力几乎全集中在凝视区域(比如西瓜、碗口、方块),即使是在有其他干扰物的情况下(比如桌面其他杂物)。
这种“主动聚焦”的能力,正是ReconVLA精准操纵的核心——只有盯得准,才能做得对。
04 ReconVLA的落地潜力与局限
ReconVLA也不是完美的,背后的trade-off同样值得探讨:
实际落地价值:简化部署,提升泛化
-
不用依赖外部分割模型:
显式接地需要YOLOv11、LISA等额外模型,部署时要处理多个模型的协同、 latency,而ReconVLA是端到端的,一个模型搞定“看+懂+做”,降低了硬件和工程成本。
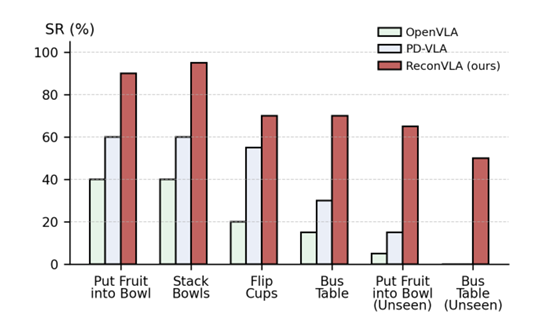
▲真实世界多任务与未见过目标任务的成功率对比图
-
泛化能力适配真实场景:
真实世界中,物体的位置、背景、形态千变万化,unseen任务是常态。ReconVLA的大规模预训练和凝视区域重建,让它能应对这种不确定性,不用每次换场景都微调。
-
长时程任务能力适配复杂需求:
不管是工业装配(多步骤组装),还是家庭服务(叠衣服→放衣柜),长时程任务都是刚需。ReconVLA的动态凝视区域切换,天然适合这类任务,不用额外设计规划模块。
不可忽视的局限
推理速度有提升空间:扩散重建虽然轻量,但还是会增加一点推理时间。论文没明确给出实时性数据,在高速操纵场景(比如流水线抓取),可能需要进一步优化。
凝视区域分割依赖Grounding DINO:预训练数据的凝视区域是靠Grounding DINO分割的,如果分割不准(比如物体遮挡严重),会影响模型训练效果——相当于“源头数据有误差,后续模型难纠正”。
复杂动态场景未验证:目前实验的场景相对静态,没有动态干扰(比如有人突然移动目标物体)。这种情况下,凝视区域的动态调整是否还能精准,还有待测试。
隐式接地可能成为VLA的主流范式
传统显式接地和CoT接地的问题,本质是“用外部信息强行引导注意力”,而ReconVLA的核心是“让模型自己学会聚焦”——
这更符合机器人自主学习的逻辑。
虽然扩散重建增加了一点复杂度,但换来的是“端到端部署”和“强泛化”,这种trade-off在落地场景中是值得的。
而且随着硬件算力的提升,推理速度的问题可以通过模型压缩、量化等方式解决。
未来,VLA模型的竞争可能会聚焦在“如何更高效地引导注意力”和“如何用更少的数据实现泛化”——ReconVLA给出了一个可行的方向,但要完全解决复杂场景的问题,还需要融合动态目标检测、物理先验知识等更多技术。
Ref
论文标题:ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
论文作者:Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, Haoang Li
项目地址:https://github.com/OpenHelix-Team/ReconVLA
论文地址:https://arxiv.org/pdf/2508.10333

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)