DataFlow Agent——NL2Pipeline 让用户意图轻松转换为数据准备流水线
本文介绍了DataFlow-Agent框架中的NL2Pipeline功能,它能够将自然语言描述的数据处理需求自动转化为可执行的DataFlow Pipeline。NL2Pipeline通过多轮对话理解用户意图,拆解任务并映射到现有算子,生成推荐流程并支持自动调试。文章详细展示了两种使用方式:自定义手动编排和Agent自动推荐模式,包括环境部署、参数配置和Pipeline执行全过程。该系统旨在帮助工
在日常的数据处理工作中,你可能已经习惯了 DataFlow 提供的自由编排能力:通过组合算子构建 Pipeline,用于清洗、治理或者为大模型训练准备数据。Pipeline 本身是可靠的,但每次面对新需求时,总有些重复的思考和手动调整。
比如,你可能会遇到这样的需求:
“我希望从网页和 PDF 中抽取文本,清理无效内容,去重并按主题切分,最终得到可直接用于向量化的数据。”
对于有经验的工程师,这并不是全新的任务。你知道大致需要哪些算子,也明白 Pipeline 应该长什么样。但把想法迅速、准确地变成一条可执行流程,仍然需要花一些时间去拆解、组合和调试。
这时候,如果有一个工具能够理解你的自然语言描述,并辅助生成推荐 Pipeline,同时保留你对算子和流程的控制,就会大大加快工作效率。
这正是 Agent-NL2Pipeline 的设计初衷:它让你用自然语言表达“想要什么数据”,系统就可以自动规划 Pipeline,推荐可执行流程,并支持自动调试。
NL2Pipeline:从自然语言到 DataFlow Pipeline
之前的文章已经介绍过 DataFlow-Agent 是围绕数据任务生命周期的智能 Agent 框架层,提供用于 Pipeline 构建、算子编写、交互式问答以及数据采集等 agent,共同形成从用户意图到可执行流程的闭环。如果工程师已经在很熟练的使用 DataFlow,那他本身就有能力去定义算子、编排流程,并构建可复用的数据处理 Pipeline。NL2Pipeline 并不会改变这一点。
在 DataFlow-Agent 中,NL2Pipeline 扮演的是一个“Pipeline 构建助手”的角色。它负责理解用户意图、拆解任务,并将这些信息映射到 DataFlow 已有的算子与执行模型上。
换句话说,Agent-NL2Pipeline 解决的并不是“如何写 Pipeline”,而是当用户用自然语言描述“想要什么样的数据或完成怎样的数据任务是”时,如何更快地把数据目标变成一条合理的 Pipeline,帮助用户更快地进入执行和验证阶段。
NL2Pipeline 的工作流程
在实际使用中,Agent-NL2Pipeline 并不是一次性将自然语言直接转化为 Pipeline,而是通过多轮对话逐步澄清需求,判断是否需要为当前任务推荐或生成数据处理管线,并将用户意图收敛为可执行的流程。
其核心流程可以概括为以下五个步骤:
-
用户意图解析
Agent 通过多轮对话逐步理解用户的真实意图,包括数据治理任务、来源及约束条件,并判断是否需要进一步推荐数据治理或处理 Pipeline。解析结果以结构化的任务意图形式输出,作为后续 Pipeline 规划的统一输入。 -
子意图拆解与算子编排
将整体任务拆解为一组子意图,并映射到已有的 DataFlow 算子与执行步骤。基于现有算子体系,自动检索并编排算子,保证生成流程的可控性与一致性。 -
Pipeline 生成与推荐
基于算子编排结果,生成一条或多条推荐 Pipeline,并以结构化形式输出。同时提供步骤级别的意图解释,便于工程师理解与校验。 -
自动执行与调试
在 Pipeline 推荐完成后,用户可以选择是否自动执行生成的流程。执行过程中,Agent 支持对 Pipeline 的自动调试 debug,并在出现执行错误时尝试自动修复后重新运行,确保推荐的 Pipeline 可运行。 -
Pipeline 输出与复用
最终输出为完整、可复用、可部署的数据处理 Pipeline。该 Pipeline 可脱离 Agent 独立运行,并作为后续数据工程任务的基础流程。
如何使用 NL2Pipeline
我们将通过本章展示完整的代码实操,介绍如何在 DataFlow-Agent 中使用 NL2Pipeline 构建数据处理 Pipeline。整体流程分为三个部分:环境部署、自定义 Pipeline 构建,以及 Agent 自动编排 Pipeline。
获取代码并创建环境
首先 Clone DataFlow-Agent 仓库,并创建独立的 Python 运行环境:
# 克隆仓库
git clone https://github.com/your-org/DataFlow-Agent.git
cd DataFlow-Agent
conda create -n myenv python=3.11
conda activate myenv
# 安装依赖(其中包含Dataflow和Dataflow-agent的依赖)
pip install -r requirements-data.txt
pip install -e .
说明:
-
DataFlow-Agent 基于 DataFlow Pipeline 执行引擎
-
Python 3.11 为推荐版本,用于保证算子与依赖的兼容性
项目如图所示:
环境安装完成,可以在终端输入如下指令启动前端:
python 你的路径/DataFlow-Agent/gradio_app/app.py
代码成功运行后,在浏览器输入http://localhost:7860 即可启动前端服务。
自定义编排 Pipeline
自定义模式适用于 Pipeline 结构已明确的场景,需要由用户手动配置算子与执行顺序。
基础参数配置
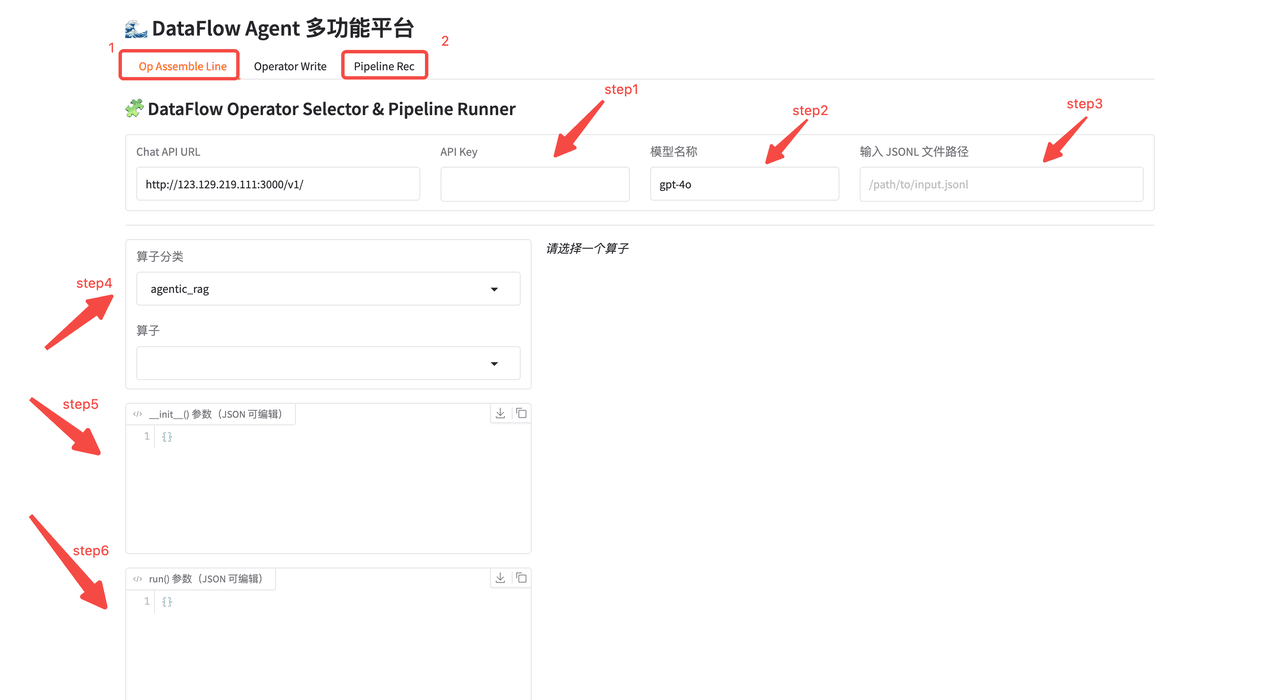
在前端界面中依次填写:
-
API Key
-
模型服务 URL 与模型名称
-
待处理的
jsonl文件路径
这些参数用于配置底层 LLM 服务和数据输入源。
算子配置与数据流约束
在算子配置区域中:
-
选择算子类别
-
配置
init参数 -
配置
run参数
关键约束:
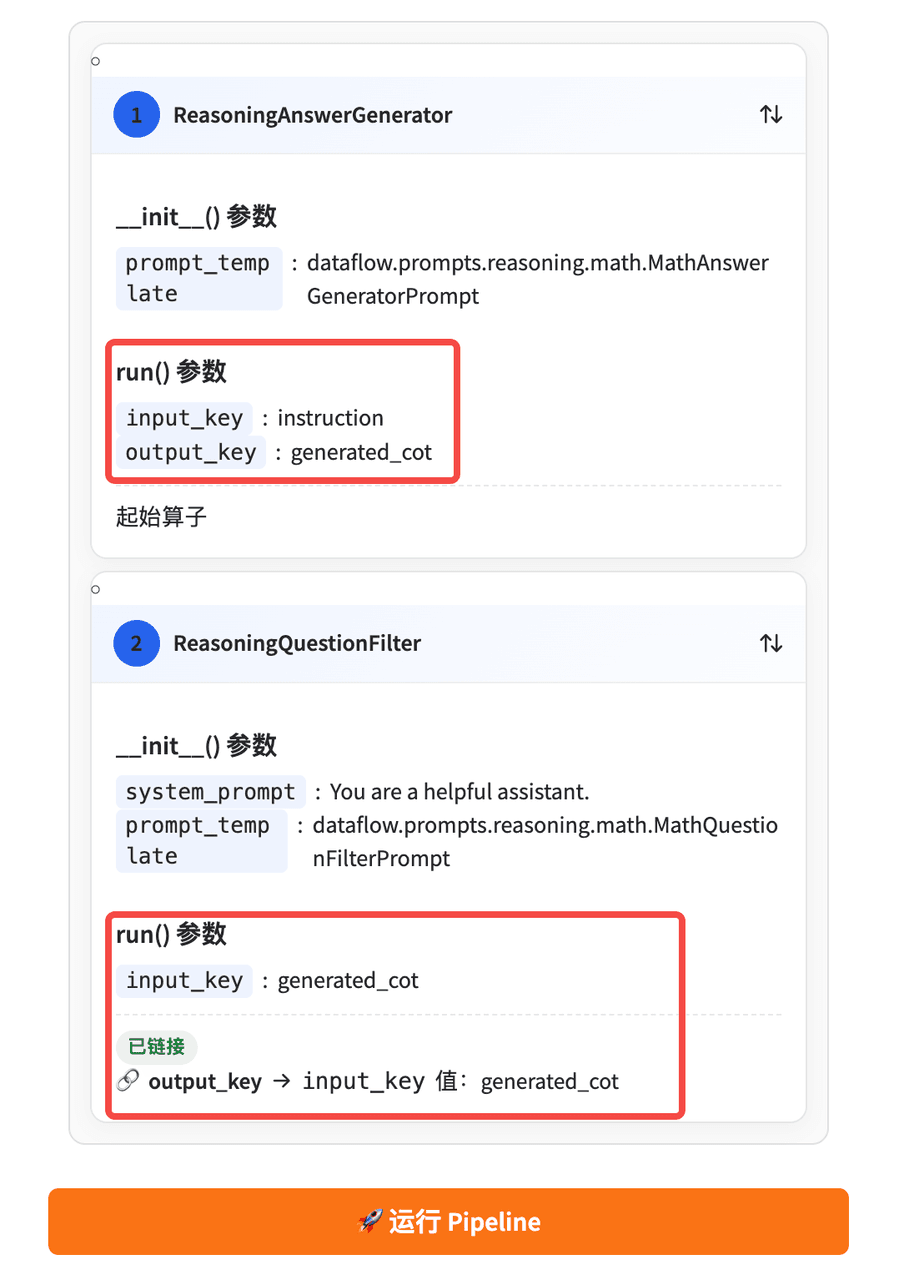
- 第一个算子的
input_key必须来自jsonl文件中的原始字段,然后即可添加第一个算子到 Pipeline。
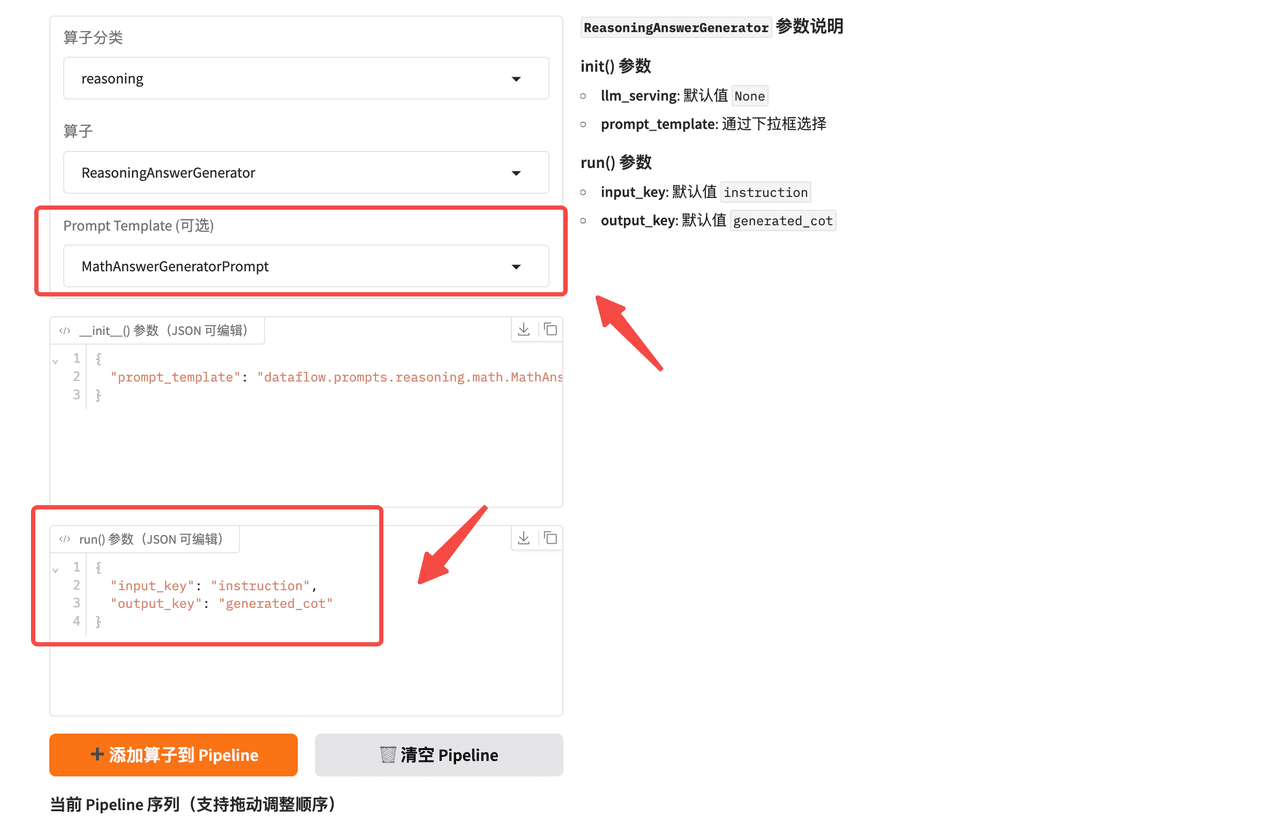
- 后续算子的
input_key必须与前一个算子的output_key一致
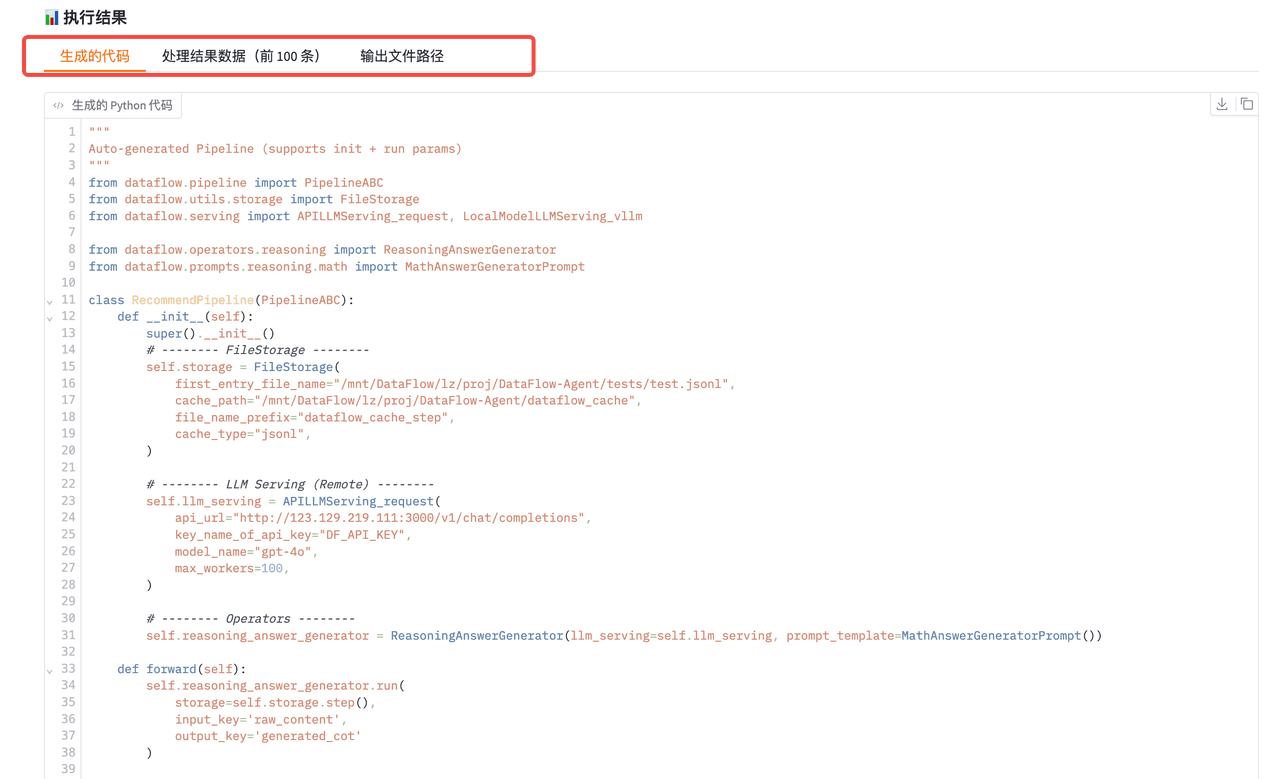
Pipeline 执行结果
运行 Pipeline 后,系统将输出:
-
一份可直接运行的 DataFlow Pipeline 源代码
-
若干处理结果示例
-
处理完成后的
jsonl文件保存路径
生成的 Pipeline 代码可以直接保存,用于复用或生产部署。
NL2Pipeline 自动推荐 Pipeline(Agent 模式)
在该模式下,Pipeline 的规划和生成由 NL2Pipeline 自动完成。
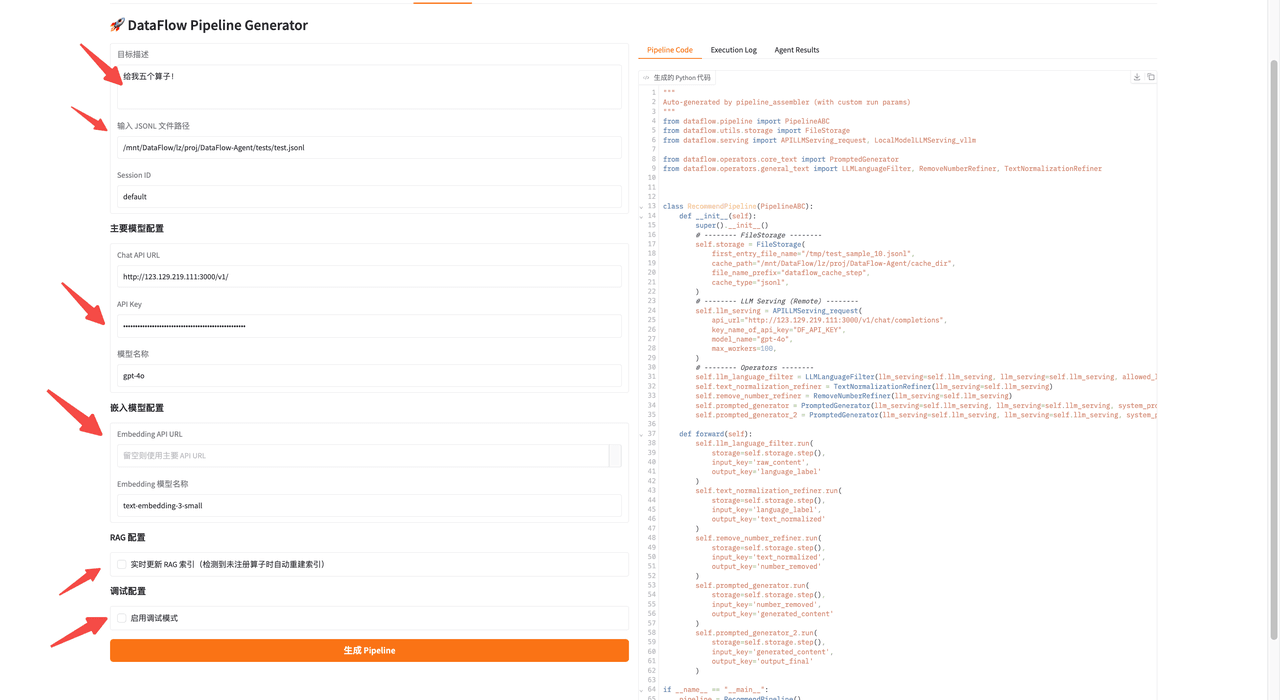
Pipeline 目标与运行参数
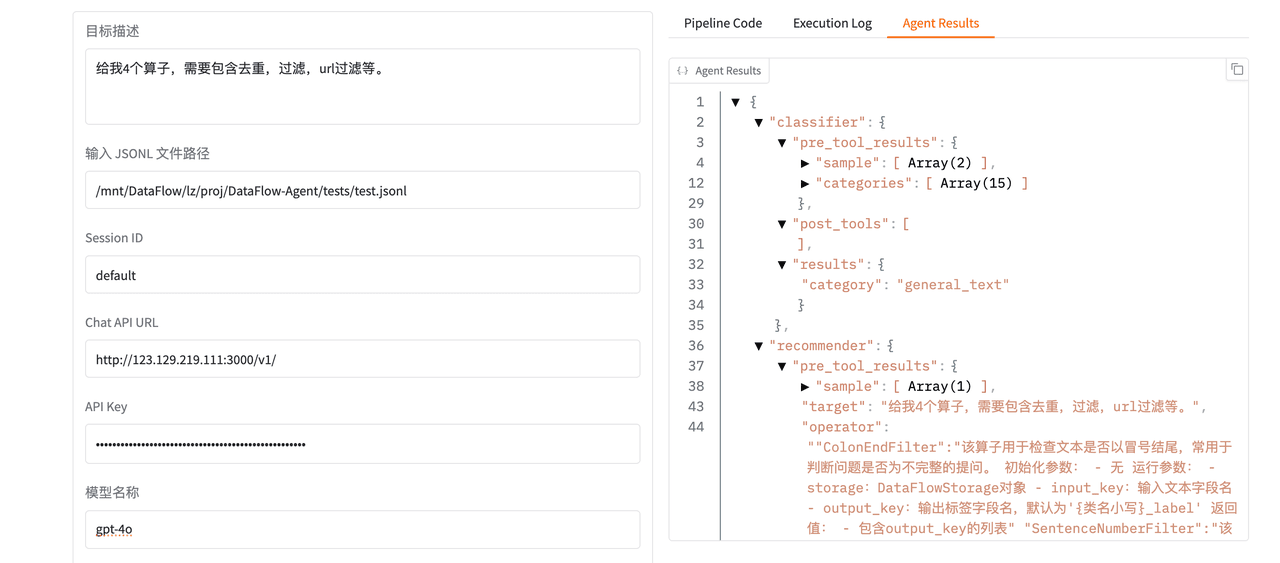
在 Pipeline 推荐页面中输入:
- 处理目标(自然语言)
- “我想要 4 个算子,完成去重、过滤等任务!”
-
待处理
jsonl文件路径 -
本次任务的唯一 ID(中间结果保存至
dataflow_agent/tmps) -
API Key 与模型名称
可选配置:
-
是否启用 RAG 更新
当算子检索失败时,可以通过RAG重新加载算子 Embedding(http://123.129.219.111:3000/v1/embeddings) -
是否启用 Debug 模式
用于自动修复 Pipeline 中的参数或结构错误,但受到模型、debug次数,以及 pipeline 复杂度影响,无法保证每次成功
Agent 自动生成的完整 Pipeline 代码
下面是 NL2Pipeline 自动生成的完整 Pipeline 源代码:
"""
Auto-generated by pipeline_assembler (with custom run params)
"""
from dataflow.pipeline import PipelineABC
from dataflow.utils.storage import FileStorage
from dataflow.serving import APILLMServing_request, LocalModelLLMServing_vllm
from dataflow.operators.core_text import PromptedGenerator
from dataflow.operators.general_text import LLMLanguageFilter, RemoveNumberRefiner, TextNormalizationRefiner
class RecommendPipeline(PipelineABC):
def __init__(self):
super().__init__()
# -------- FileStorage --------
self.storage = FileStorage(
first_entry_file_name="/tmp/test_sample_10.jsonl",
cache_path="/mnt/DataFlow/lz/proj/DataFlow-Agent/cache_dir",
file_name_prefix="dataflow_cache_step",
cache_type="jsonl",
)
# -------- LLM Serving (Remote) --------
self.llm_serving = APILLMServing_request(
api_url="http://123.129.219.111:3000/v1/chat/completions",
key_name_of_api_key="DF_API_KEY",
model_name="gpt-4o",
max_workers=100,
)
# -------- Operators --------
self.llm_language_filter = LLMLanguageFilter(llm_serving=self.llm_serving, llm_serving=self.llm_serving, allowed_languages=['en'])
self.text_normalization_refiner = TextNormalizationRefiner(llm_serving=self.llm_serving)
self.remove_number_refiner = RemoveNumberRefiner(llm_serving=self.llm_serving)
self.prompted_generator = PromptedGenerator(llm_serving=self.llm_serving, llm_serving=self.llm_serving, system_prompt='Generate a creative and engaging travel story based on the given content, focusing on the emotional and cultural experiences of traveling.', json_schema=None)
self.prompted_generator_2 = PromptedGenerator(llm_serving=self.llm_serving, llm_serving=self.llm_serving, system_prompt='Create a list of five unique travel destinations inspired by the provided content, highlighting their cultural significance and appeal.', json_schema=None)
def forward(self):
self.llm_language_filter.run(
storage=self.storage.step(),
input_key='raw_content',
output_key='language_label'
)
self.text_normalization_refiner.run(
storage=self.storage.step(),
input_key='language_label',
output_key='text_normalized'
)
self.remove_number_refiner.run(
storage=self.storage.step(),
input_key='text_normalized',
output_key='number_removed'
)
self.prompted_generator.run(
storage=self.storage.step(),
input_key='number_removed',
output_key='generated_content'
)
self.prompted_generator_2.run(
storage=self.storage.step(),
input_key='generated_content',
output_key='output_final'
)
if __name__ == "__main__":
pipeline = RecommendPipeline()
pipeline.compile()
pipeline.forward()
我们得到了agent 推荐的完整的 pipeline 代码后,可以直接复制用于二次修改复用;
代码结构说明
该 Pipeline 由 NL2Pipeline 自动生成,但在工程结构上完全符合 DataFlow Pipeline 规范:
-
FileStorage
管理数据输入、中间缓存与输出结果 -
LLM Serving
封装远程模型调用配置 -
Operators
每个算子负责一个独立的数据处理或生成步骤 -
forward 方法
明确规定算子执行顺序和数据流转关系
生成的 Pipeline 可:
-
直接运行
-
拷贝后二次修改
-
纳入版本管理作为长期数据处理流程
结语
通过前面的介绍和实操示例,我们完整展示了 NL2Pipeline Agent 从自然语言需求到可执行 Pipeline 的全过程,并说明了它在 DataFlow-Agent 框架下的作用。
Agent-NL2Pipeline 利用多轮对话逐步理解用户的真实意图,将任务拆解为子步骤,并基于 DataFlow 的算子与执行体系生成可执行的 Pipeline。它支持自动调试和修复,让工程师可以快速得到可靠的流程,而无需重复手动搭建或验证。
作为 DataFlow-Agent 的核心能力,Agent-NL2Pipeline 与现有的 DataFlow Pipeline 紧密协作:它不替代 Pipeline,而是提供一种高效的入口,将自然语言需求转化为工程化流程,使 Pipeline 构建和迭代更加直接、可控。最终生成的 Pipeline 可复用、可部署,适用于数据治理、清洗、特征生成以及 RAG 数据构建。
通过将自然语言、智能调度和工程化执行结合起来,Agent-NL2Pipeline 提高了数据处理效率,也为大模型训练提供了稳定、高质量的数据基础,使数据工程过程更可解释、更贴近业务目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)