InstructGPT 2022详细解读
摘要: InstructGPT通过三阶段训练实现语言模型与人类偏好对齐:1)监督微调(SFT)使模型初步遵循指令;2)奖励模型(RM)学习人类偏好排序;3)强化学习(RLHF)结合PPO算法优化输出,通过KL散度约束平衡创新与稳定性。该方法解决了模型幻觉问题,奠定ChatGPT等技术基础,并推动DPO等后续优化方案的发展。核心创新在于“生成-评价-优化”闭环,首次系统性融合人类反馈,成为大模型对齐
InstructGPT 2022 decoder only
InstructGPT是大语言模型对齐人类意识的里程碑工作,解决模型幻觉等问题,更能理解符合人类的期望。
核心思想:通过人类反馈feedback微调模型,使其输出更听话、更安全、更有用helpful, honest, harmless。
InstructGPT 训练分为三阶段: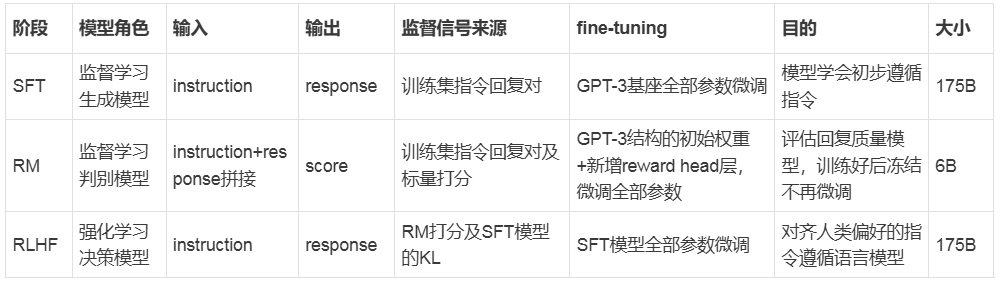
三阶段训练流程:
SFT 模型 = 学生(回答题)
RM 模型 = 老师(打分)
RL 阶段 = 学生根据老师打分不断改进答题方式
1.监督微调supervised fine-tuning,SFT,标准的语言建模目标,自回归生成的回复 token 序列(response) 纯文本指令(instruction)
(1)13k条指令-回复对(instruction,response)在GPT-3基座模型上标准监督学习,全部参数full fine-tuning微调
(2)模型初步学会按指令办事,而不是输出无关内容,得到初步具备指令遵循能力的SFT模型
SFT 模型 = 原始 GPT-3 架构 + 所有参数被更新过一次。
SFT模型作用:
a. 用于生成 RM阶段所需的多个候选回复;
b. 在 RL 阶段冻结作为参考策略(reference policy) 计算 KL 散度,初始化参数成为可训练的策略网络policy;
2.奖励模型训练reward modeling,RM,本质二分类排序任务
基于GPT-3结构的独立打分模型,初始化GPT-3权重不同于其网络,新增一个线性层linear head作为reward head,量化打分。全部参数训练,训练完后不再微调,冻结model。
量化同个指令不同回答哪个更好,主观性打分,RM 必须能处理 (instruction + response) 的总长度(可能比 SFT 更长)。
(1)上一阶段SFT模型同一指令生成多个(通常4~9个)不同回复
(2)按照偏好排序标注(A>B>C…)
(3)训练模型,输入为instruction+response拼接,标签/输出为标量分数r,偏好越大,分值越高,使用pairwise ranking loss优化,损失函数:Bradley-Terry pairwise loss
(4)得到自动评估回复质量的reward model
RM = GPT-3 backbone(初始化) + 新增 reward head(随机初始化) → 端到端微调。
3.强化学习微调reinforcement learning from human feedback,RLHF,本质强化学习任务
使用近端策略优化PPO(Proximal Policy Optimization)算法微调策略网络Policy Network(SFT网络)π,符合人类偏好对齐指令遵循模型。 全部参数full fine-tuning微调
策略网络,强化学习中专业名词。
(1)阶段1的SFT冻结模型生成回复
(2)阶段2的RM冻结模型对回复打分
(3)copy SFT模型为策略网络,生成回复文本,参数可调
(4)loss来自外部,而不是生成模型loss,包含两项:奖励项和KL penalty项,最大化奖励(RM 打分),而不是最小化交叉熵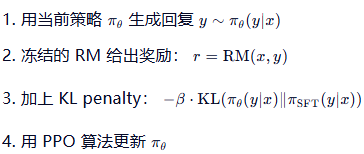
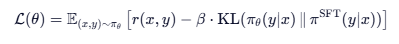
loss加入KL penalty惩罚项,比较当前策略和 SFT 策略的 log-prob,防止模型偏离原始SFT模型(reference policy)太远(避免过度优化或胡言乱语或多样性丧失)
KL penalty 相当于一个“正则化锚点”,让模型在 遵循人类偏好 和 保持语言建模能力 之间取得平衡。
RLHF 的 loss 来自 RM 打分 + KL 约束,没有 ground-truth 文本监督!SFT 的 loss 来自 真实回复的 token。
(5)目的得到经过人类偏好对齐的指令遵循语言模型InstructGPT
RLHF 微调 = SFT 模型的所有参数 + PPO 更新 + KL 正则化约束。
4.影响
首次系统性地将人类偏好融入 LLM 训练,形成“生成→评价→优化”闭环,RLHF 成为 LLM 对齐的标准范式
RLHF 范式确立,为后续 ChatGPT、Claude、Gemini 等所有主流对话模型奠定技术基础
ChatGPT = InstructGPT + 更大数据 + 更强基座 + 工程优化
引发大量改进工作:DPO(直接偏好优化)、KTO、RAHF 等(试图绕过 RL 的复杂性)
Tokenization:三个阶段使用相同的 tokenizer(如 GPT 的 BPE),确保格式一致。
推理时:只有 RLHF 最终模型被部署,RM 和 SFT 模型都不参与线上服务。
后续:DPO 2023新的替代方案,更简单稳定。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)