也说边缘计算
智能设备是它的身份。边缘计算是它的站位(离用户近)。边缘AI是它的技能。
·
这是一个非常大的话题,更是一个大环境
整体框图
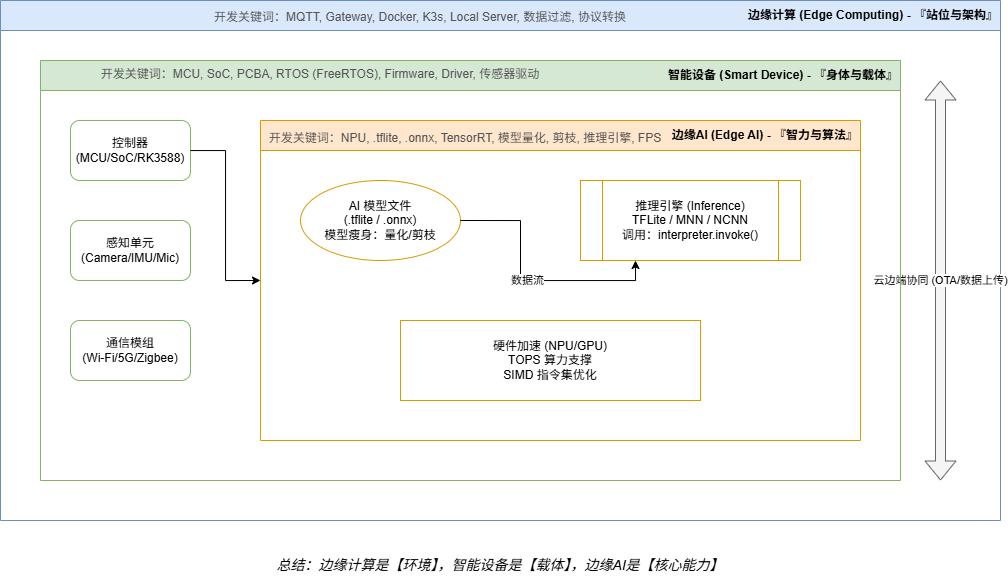
多维度解析
1. 架构类概念:定义的“边界”在哪里?
- 云边端协同 (Cloud-Edge-Device Collaboration): 这是目前的标准架构。云端负责大规模训练和管理,边缘负责局部处理,终端负责执行和采集。
- 雾计算 (Fog Computing): 介于云和边缘之间的一个层级,通常指局域网内的服务器集群,比边缘节点算力强,比云端延迟低。
- MEC (多接入边缘计算 / Multi-access Edge Computing): 深度绑定5G的概念。将计算能力直接部署在电信运营商的基站侧,实现极低延迟。
- 数字孪生 (Digital Twin): 在数字世界里为物理设备建立一个实时同步的“镜像”,常用于工业边缘侧的状态监测和寿命预测。
2. 硬件与芯片类:AI的“体力”来源
- NPU / TPU / ASIC:
- NPU (神经网络处理器):专门为加速AI计算设计的硬件。
- TPU (张量处理器):由Google研发的专为机器学习定制的加速器,擅长处理大规模张量运算。
- ASIC (专用集成电路):为特定算法定制的芯片,效率最高。
- SoC (System on Chip): 片上系统。现在的智能设备芯片(如手机芯片、安防芯片)通常集成了CPU、GPU和NPU。
- RISC-V: 一种开源指令集架构,因其低功耗和可定制性,在边缘AI和物联网芯片中越来越火。
- FPGA (现场可编程逻辑门阵列): 可以通过编程改变硬件逻辑的芯片,常用于算法迭代飞快的原型开发阶段。
3. 算法部署与优化:如何把“大象”装进“冰箱”
由于边缘设备资源有限,必须对AI模型进行“瘦身”:
- TinyML: 极小型机器学习。特指在极低功耗(毫瓦级)的单片机上运行AI模型的技术。
- 模型量化 (Quantization): 将模型中高精度的浮点数(如Float32)转换为低精度(如INT8),大幅减小模型体积并提速。
- 模型剪枝 (Pruning): 删掉神经网络中对结果影响不大的“冗余神经元”,就像修剪树枝一样。
- 知识蒸馏 (Knowledge Distillation): 用一个复杂的“教师模型”训练出一个轻量化的“学生模型”,让小模型具备大模型的能力。
- 推理引擎 (Inference Engine): 专门在硬件上运行AI模型的软件框架,如英伟达的 TensorRT、华为的 MindSpore Lite、谷歌的 TFLite。
4. 通信与连接类:设备的“语言”
- OTA (Over-the-Air): 空中下载技术。智能设备必须具备的功能,用于远程升级固件或更新AI模型。
- MQTT / CoAP: 物联网中最常用的轻量级通信协议。
- TSN (时间敏感网络): 工业边缘计算的关键,确保数据传输延迟是确定的(比如必须在0.1毫秒内到达)。
- Matter: 目前全球最热门的智能家居标准,旨在让不同品牌的智能设备能够互相协作。
5. 前沿与进阶概念:未来的方向
- 联邦学习 (Federated Learning): “数据不动模型动”。多个边缘设备各自在本地训练模型,只交换参数不交换原始数据,极大地保护了隐私。
- 端侧学习 (On-device Learning): 目前大部分边缘AI只是“推理(使用)”,端侧学习是指设备能在使用过程中根据用户习惯,在本地直接更新和进化模型。
- 边缘大模型 (Edge LLM): 将简化版的类ChatGPT大语言模型部署在手机或车机本地,实现不联网的自然语言对话。
- 视觉边缘分析 (IVA / Video Analytics): 边缘AI最成熟的领域,涉及目标检测、人脸识别、行为分析等。
专家视角总结:
如果你要进入这个领域,建议的学习路径是:
- 基础: 嵌入式开发 (C/C++, RTOS/Linux)。
- 核心: 了解一两个主流推理框架 (如 TFLite 或 ONNX Runtime)。
- 进阶: 掌握模型量化与性能调优(这是目前最值钱的技能,因为买芯片容易,让模型在便宜芯片上跑得快很难)。
开发是都在做什么?
1. “智能设备”在开发时做什么?
当你真正动手做一个智能设备时,你看到的词汇是:
- 硬件层面: MCU(单片机)、SoC(系统级芯片)、PCBA(电路板)、传感器(如IMU、温湿度计)、执行器(继电器、电机)。
- 软件层面: Firmware(固件)、RTOS(实时操作系统,如FreeRTOS)、Peripheral(外设)、Driver(驱动程序)。
- 交互层面: HMI(人机交互)、OTA(远程升级)。
- 为什么看不到: 因为“智能”是对功能的结果描述,开发时关注的是如何让硬件通电、联网、稳定运行。
2. “边缘计算”在开发时做什么?
在代码或系统架构中,你不会看到 import edge_computing,你会看到:
- 协议类: MQTT Broker、Gateway(网关)、Local Server。
- 数据处理: Data Filtering(数据过滤)、Stream Processing(流处理)、Downsampling(降采样)。
- 部署类: Docker/K3s(容器化部署在边缘节点)、Microservices(微服务)。
- 缓存类: Local Storage、Offline Buffer(离线缓存)。
- 为什么看不到: 因为边缘计算是一种**“位置”**选择。当你决定把原本在云端跑的代码放到本地网关上跑时,这个动作本身就是边缘计算,但代码里只体现为具体的业务逻辑。
3. “边缘AI”在开发时做什么?
当你开发边缘AI应用时,你面对的是这些冷冰冰的技术名词:
- 模型文件:
.tflite(TensorFlow Lite)、.onnx、.nb(PaddleLite)、.weights。 - 推理框架: Inference Engine、MNN、NCNN、TensorRT。
- 硬件指令: NPU Acceleration、INT8 Quantization(量化)、SIMD(单指令多数据流)。
- 性能指标: FPS(每秒帧数)、Latency(延迟)、TOPS(算力单位)。
- 为什么看不到: 因为AI在边缘侧表现为一段**“推理过程”**。你的代码通常是在调用一个“推理引擎”去加载一个“模型文件”,然后输入数据,得到结果。
举个例子:一个“边缘AI智能摄像头”的真实面目
如果你看它的宣传单,上面写着:
“这是一款集成了边缘计算能力的边缘AI智能设备。”
但如果你看它的工程目录和代码,你会看到:
- 硬件层: 使用了 Rockchip RK3588 (SoC),带 6TOPS 的 NPU。
- 边缘计算层: 代码里有一个
mqtt_publisher.py,负责把识别结果发给本地服务器;还有一个data_cleaner.cpp,负责把重复的画面删掉。 - 边缘AI层: 文件夹里放着一个
yolov5s_quant_int8.tflite模型文件,代码里调用了interpreter.invoke()来做物体识别。
总结
- 智能设备是它的身份。
- 边缘计算是它的站位(离用户近)。
- 边缘AI是它的技能。
应用示例
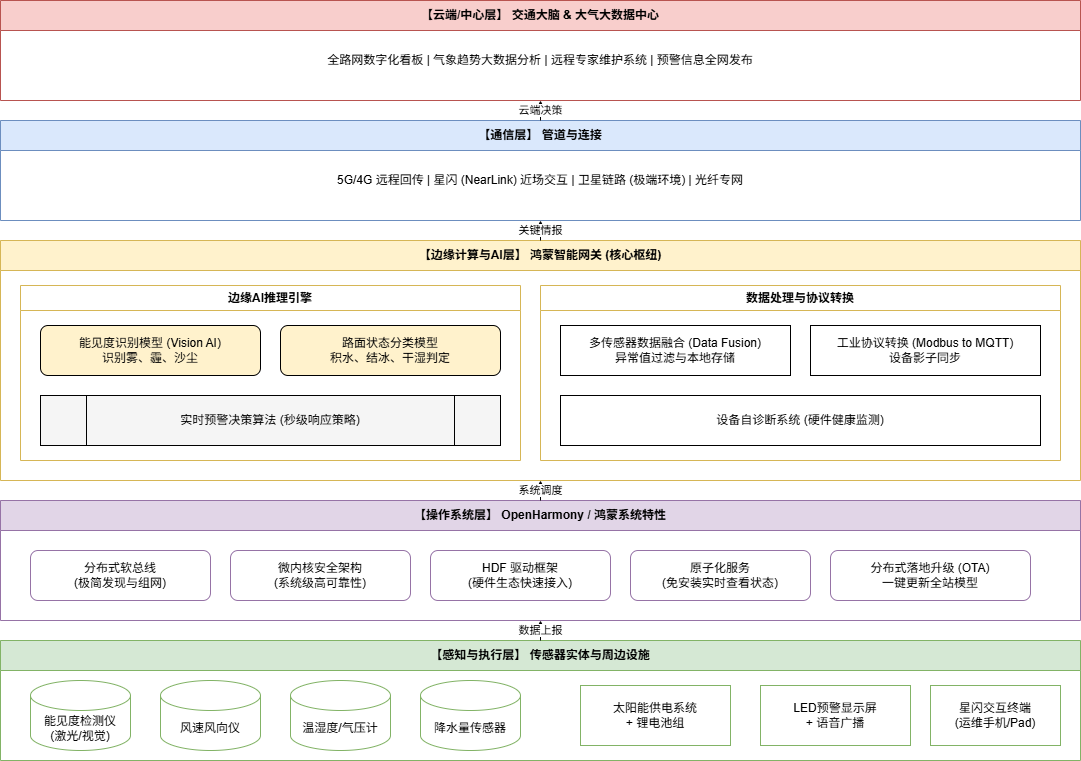
核心技术点深度解析(图解补充)
为了让你更透彻地理解,我将图中几个最关键、最华为的技术细节拎出来解释:
A. 鸿蒙分布式软总线(关键中的关键)
- 传统做法:传感器连接网关需要物理接线或手动配置IP。
- 鸿蒙做法:传感器通电后,通过软总线协议自动被网关“发现”。开发者只需调用鸿蒙的标准API,就像调用本地设备一样读取风速。这就是为什么报道中说能“快速部署、即插即用”。
B. 星闪(NearLink)交互
- 技术背景:这是华为推出的新一代无线通信技术。
- 应用场景:高速路边的气象站通常在高处,维修极难。有了星闪,运维人员拿着鸿蒙手机在路边,通过**“原子化服务”**(卡片)就能瞬间连上设备,看到实时波形图。这比Wi-Fi更稳、比蓝牙更远更快。
C. 边缘AI推理(视觉AI + 时序模型)
- 识别“看不见”的危险:传统的能见度仪是点式的。华为的边缘AI网关可以接入摄像头,运行深度学习模型(如YOLO)。它不仅监测一个点,而是通过图像分析整个路段的“团雾”。
- 本地化决策:当模型识别到“团雾”时,网关直接给路边的LED屏下达“减速”指令。整个过程不需要上传云端。
D. HDF(硬件驱动框架)
- 解决碎片化:气象传感器厂家极多,接口各异。华为通过 HDF (Hardware Driver Foundation) 实现了驱动程序的标准化。这意味着,只要符合鸿蒙HDF标准的传感器,换一个品牌,网关代码一行都不用改。
总结
华为这个技术栈的精髓在于:用“操作系统”的底层能力(鸿蒙)解决了设备的连接问题,用“边缘算力”解决了预警的响应速度问题。
这就是一个典型的 AIoT(人工智能+物联网) 闭环应用。
你觉得我总结如何,请告诉我!
设备选型
华为边缘计算设备选型矩阵图 (2025-2026 版)
| 核心类别 | 典型设备 (形态) | 核心定位 | 算力等级 (AI/通用) | 物理接口 | 二次开发支持 | 核心开发工具 (工具链) | 典型应用场景 |
|---|---|---|---|---|---|---|---|
| 1. 昇腾AI边缘 (Atlas) | Atlas 200 / 500 (模组/边缘小站) | 深度学习强推理:视觉识别与深度预测 | 极高 (20-88 TOPS INT8) | 千兆网口、HDMI、USB 3.0、GPIO、MIPI (摄像头) | 高度支持 (C++/Python) | MindStudio / CANN (异构计算架构) | 智慧安防、工业质检、无人机/机器人、自动驾驶辅助 |
| 2. 工业物联网关 (AR) | AR502H (导轨式工业级机箱) | 协议转换与连接:工业协议解析与轻量计算 | 低/中 (多核ARM处理器) | RS485/232、DI/DO、CAN、PLC、5G/4G、网口 | 支持 (容器化开发) | Docker / eSlink SDK / Python | 智能电网、智慧路灯杆、充电桩管理、环境监测 |
| 3. 鸿蒙协同网关 (Harmony) | 鸿蒙智能网关 (嵌入式盒子/板卡) | 跨设备协同:分布式组网与多设备联邦控制 | 中 (支持轻量AI加速) | 100M/1000M网口、WiFi、星闪(NearLink)、Zigbee | 高度支持 (JS/ArkTS/C++) | DevEco Studio / HDF (驱动框架) | 交通气象站协同、智慧矿山、智能工地、全屋智能 |
| 4. 重型边缘/MEC (MEC) | 5G MEC 服务器 (1U/2U 标准机架式) | 大流量处理:5G网络下沉与极低延迟计算 | 极高 (CPU+GPU/NPU扩展) | 10G/25G SFP+光口、PCIe 扩展插槽 | 支持 (云原生开发) | IEF (智能边缘平台) / K8s / Linux | 远程矿山操控、超视距自动驾驶、VR/AR云渲染、智慧港口 |
ST 边缘计算与 AI 硬件全景观测表
| 核心类别 | 典型芯片/系列 (形态) | 核心定位 | 算力等级 (通用/AI) | 物理接口 | 二次开发支持 | 核心开发工具 (工具链) | 典型应用场景 |
|---|---|---|---|---|---|---|---|
| 1. 神经网络专用MCU (NEW) | STM32N6 (集成 NPU 的芯片) | 边缘AI新标杆:首款集成硬件 NPU 的微控制器 | 中/高 (可达数 TOPS) | CSI (摄像头)、DSI (显示)、PCIe、CAN-FD | 深度支持 (裸机/RTOS) | STM32Cube.AI / NanoEdge AI | 高性能视觉识别、实时工业控制、高端穿戴设备 |
| 2. 高性能通用MCU | STM32H7 / F7 (Cortex-M7 内核) | 平衡型计算:兼顾复杂控制与 AI 推理 | 中 (400-550 MHz / 无专用NPU) | 双网口、USB HS、FSMC (外扩内存) | 深度支持 (C/C++) | STM32Cube.AI / X-CUBE-AI | 变频器预测性维护、手写识别、语音唤醒 |
| 3. 嵌入式微处理器 (MPU) | STM32MP1 / MP2 (Cortex-A内核) | 边缘网关:运行 Linux 系统的复杂任务 | 中/高 (集成 GPU/NPU 加速) | 千兆网口、多路 CAN-FD、USB 3.0 | 深度支持 (Linux/Yocto) | OpenSTLinux / TensorFlow Lite | 工业 HMI 界面、智能支付终端、能源管理网关 |
| 4. 智能传感器 (Sensor AI) | MEMS + MLC / ISPU (如 LSM6DSV16X) | 感算一体:在传感器内部直接跑 AI | 极低 (针对振动/姿态算法优化) | I2C / SPI / I3C | 支持 (配置寄存器/微码) | Unicleo-GUI / MLC 决策树工具 | 手机抬腕亮屏、运动监测、机器振动监控、防盗报警 |
ST 与 华为 选型对比总结
| 维度 | 华为 (Huawei) | 意法半导体 (ST) |
|---|---|---|
| 颗粒度 | 系统/盒子级 (买了就能直接用) | 芯片/板卡级 (需要自己设计电路) |
| 功耗 | 瓦级 (W) (5W - 20W+) | 毫瓦级 (mW) (几毫瓦到几百毫瓦) |
| 擅长数据 | 视频流、大规模音频、复杂预测 | 振动、压力、温度、简单图像、低频声音 |
| 开发门槛 | 主要是软件工程、算法部署 | 电子工程、嵌入式 C 语言、寄存器调试 |
| 应用领域 | 智慧城市、交通、服务器、矿山 | 智能手表、白色家电、工业传感器、玩具 |
ST 边缘 AI 的核心竞争力解析
1. 开发工具链:从“数学题”变成“选择题”
ST 成功的一大半归功于它的工具链,这与华为的 MindStudio 逻辑不同:
- STM32Cube.AI:它可以将你训练好的 AI 模型(Keras, TensorFlow Lite, ONNX)一键转换成高度优化的 C 代码,直接在单片机上跑。它能告诉你这个模型需要占用多少 Flash 和 RAM。
- NanoEdge AI Studio:这是 ST 针对工程师研发的 “自动机器学习 (AutoML)” 工具。你不需要懂算法,只要把传感器的正常数据和异常数据喂给它,它会自动为你生成一个最适合该芯片的 AI 模型。
2. “边缘中的边缘”:传感器的智能化
ST 提出了一个概念叫 MLC (Machine Learning Core)。
- 华为的做法:传感器数据给 NPU,NPU 计算。
- ST 的做法:在加速度计内部集成一个微小的逻辑单元。当手机放在桌上没动时,主芯片(CPU)完全休眠以省电,只有传感器内部的微小电路在运行 AI。一旦它识别出“被拿起”的动作,才唤醒 CPU。这使得设备的续航时间可以大幅延长。
3. STM32N6:ST 的核武器
在 2024-2025 年,ST 推出了 STM32N6。这是 ST 第一款真正内置 NPU(神经网络处理单元) 的 MCU。它打破了 MCU 跑不动复杂视觉算法的瓶颈,使得在极低功耗下运行 YOLO 目标检测成为可能。
边缘AI与边缘计算开发设备全景对比表
| 厂商 | 代表系列/型号 | 算力等级 (AI推理) | 核心架构 | 操作系统/开发工具 | 边缘计算适配性 (连接/工业) | 功耗 (典型值) | 推荐场景 |
|---|---|---|---|---|---|---|---|
| 【重型层】 | |||||||
| 华为 | Atlas 500 | 22 - 88T (INT8) | 昇腾NPU | EulerOS / MindStudio | 极强:内置4G/5G, 支持IEF云边协同 | 25W - 40W | 智慧路口、工业质检、算力下沉网关 |
| NVIDIA | Jetson AGX Orin | 200 - 275T (INT8) | Ampere GPU | Ubuntu / CUDA / TensorRT | 强:双千兆网口, 丰富的PCIe扩展 | 15W - 60W | 自动驾驶、配送机器人、医疗影像 |
| Intel | Xeon-D + OpenVINO | 依赖扩展 (CPU/GPU) | x86 CPU | Windows/Linux / OpenVINO | 极强:标准服务器接口, 虚拟化支持 | 45W - 100W+ | 边缘中心机房、内容分发网(CDN) |
| 【中型层】 | |||||||
| 华为 | Atlas 200I DK | 8 - 22T (INT8) | 昇腾NPU | EulerOS / CANN | 中:支持千兆网、USB 3.0 | 10W - 20W | 开发者原型、智能无人机、边缘节点 |
| 瑞芯微 | RK3588 | 6T (INT8) | ARM + NPU | Android/Linux / RKNN | 强:多路HDMI/CSI/网口, 极其全能 | 5W - 12W | 智能座舱、多路监控、国产化边缘盒子 |
| 地平线 | 旭日 3M / 3E | 5T (INT8) | BPU 架构 | Linux / TogetheROS | 中:侧重视觉接口, 低延迟处理 | 2.5W - 5W | 扫地机器人、智能摄像头、智能穿戴 |
| NXP | i.MX 8M Plus | 2.3T (INT8) | ARM + NPU | Linux / eIQ 工具链 | 极强:双CAN-FD, 工业级TSN支持 | 2W - 5W | 工业控制、车载仪表、自动化生产线 |
| Coral TPU | 4T (INT8) | Edge TPU | Linux/Windows / TFLite | 弱:通常作为USB/M.2插件使用 | 2W | 快速AI功能验证、智能办公设备 | |
| Hailo | Hailo-8 | 26T (INT8) | 自研数据流架构 | Linux / HailoRT | 中:作为M.2加速卡接入主机 | 2.5W | 高能效比监控、紧凑型边缘主机 |
| 【轻量层】 | |||||||
| ST | STM32N6 / MP2 | ~1T (加速级别) | ARM + NPU | RTOS/Linux / Cube.AI | 强:丰富工业外设 (SPI,I2C,ADC) | < 1W | 智能家电、手势识别、震动预测维护 |
| 乐鑫 | ESP32-S3 | 指令加速 (无NPU) | Xtensa + 向量指令 | FreeRTOS / ESP-DL | 极强:内置WiFi/蓝牙, 成本极低 | < 0.5W | 语音唤醒开关、智能插座、低功耗IoT |
| 嘉楠 | K510 | 2T (INT8) | RISC-V + KPU | Linux / C++ | 中:支持双摄、极低成本AI视觉 | 1W - 3W | 教育机器人、智能门锁、考勤机 |
| ST (传感器) | LSM6DSV16X | 极低 (微码级别) | MEMS + MLC | 寄存器配置 / Unicleo-GUI | 专精:直接集成在运动传感器内 | 微瓦级 | 计步器、防跌倒报警、手机抬腕唤醒 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)