如何用Y-Trainer三招解决复读、过拟合和失忆问题
本文针对垂直领域SFT训练中的三大痛点——模型基础能力退化、生成内容单一化和格式不稳定,提出基于Y-Trainer的NLIRG算法解决方案。该算法通过动态调整token级梯度分配,实现训练信号的精准控制:对低loss token削减梯度防止过拟合,中等loss token增强学习效率,高loss token隔离噪声影响。相比传统数据侧优化方法,Y-Trainer在单卡环境下即可构建可复现的训练流程
本文从实战角度解析垂直领域SFT训练中的三大难题,并详解如何通过Y-Trainer的NLIRG算法构建一套可复现、可对照的训练流程。文末附完整代码示例与效果验证方法,助你告别"调参民工"身份,重获模型训练掌控权。
一、为什么我的模型越来越傻?——垂直SFT的三大无声杀手
作为AI工程师,你是否经历过这样的崩溃时刻:
-
专业问题答得精准,却连"你好"都不会说了:模型在垂直任务上表现优异,但在基础对话、常识问答上全面退化
-
上线后变成复读机:训练时loss一路下降,上线后却反复使用相同句式,生成内容缺乏多样性
-
格式时好时坏:训练数据中结构化输出很稳定,但实际使用中格式校验错误率飙升
最令人沮丧的是:这些症状往往同时出现,且难以通过简单调参解决。降低学习率?增加通用语料?调整训练轮次?我们陷入无限试错的泥潭。

今天,我想和大家聊聊一个可能被忽视的方向:训练信号的精细分配。不是所有token都值得同等对待,而Y-Trainer的NLIRG算法正是解决这一问题的利器。
二、传统SFT为何总在"翻车边缘"?梯度分配不合理是元凶
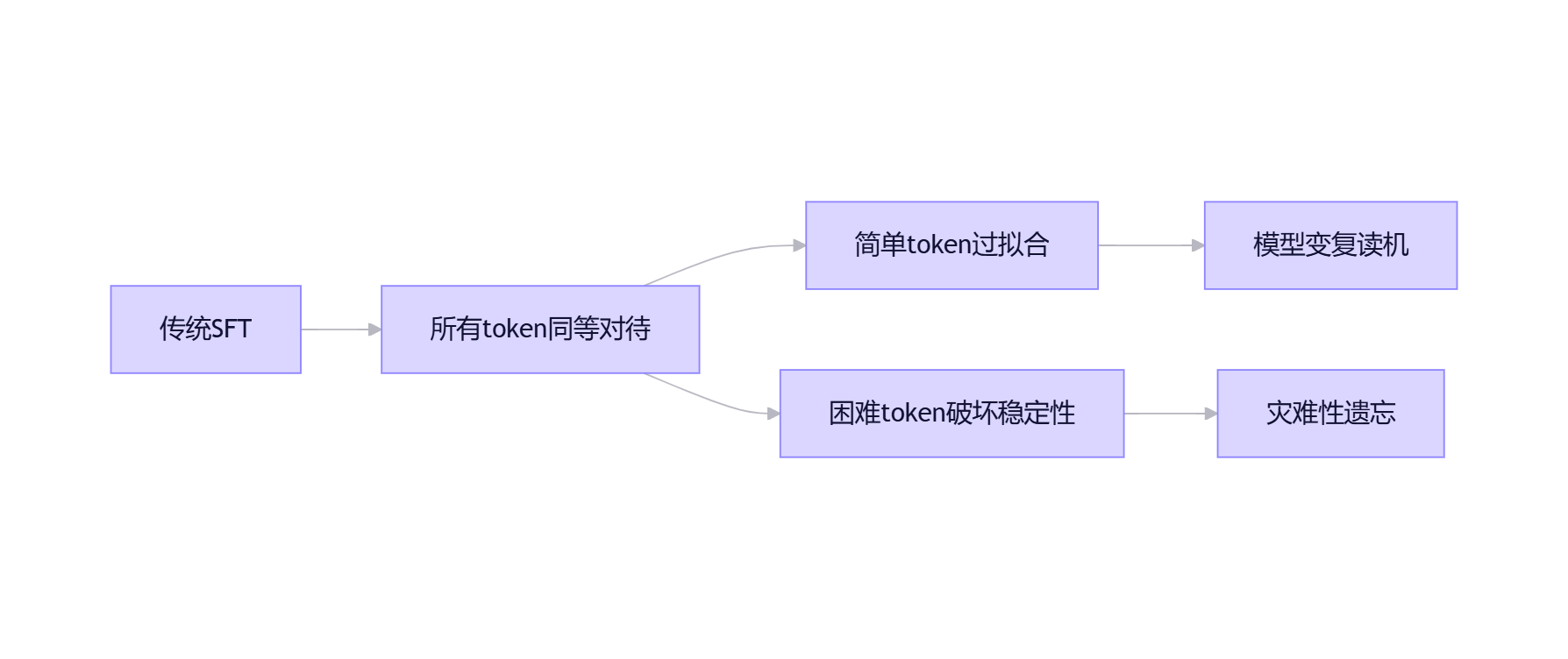
2.1 被忽视的核心事实:SFT的梯度来源是token,不是样本
在指令微调中,真正驱动模型学习的不是整个样本,而是每个token产生的梯度。一个样本中哪些token贡献大、哪些梯度更激进,决定了"模型在这一轮训练中到底学了什么"。
2.2 两大极端现象如何联手毁掉你的模型
现象1:大量低loss token反复出现 垂直数据往往存在强模板:固定开头、字段名、礼貌用语、格式符号等。这些token很快进入低loss区间。但如果继续以相同强度训练它们,模型会在"表面模式"上过拟合,导致:
-
生成内容模板化、缺乏多样性
-
同义改写、字段顺序变化等小改动导致输出漂移
-
信息密度下降,回答变长但内容空洞
现象2:少量高loss token触发过强更新 垂直数据中常有困难样本、长尾表达、噪声标注等。它们对应高loss token,产生更大梯度,迫使模型用大代价拟合少量异常信号,导致:
-
原有通用能力被挤压
-
训练过程不稳定
-
模型变得"偏科",失去基础对话能力
正如Y-Trainer官方文档指出:"灾难性遗忘通常是由过难语料导致,通过识别这些token,进行动态调整,可有效避免。过拟合是由相似语料或者模型已经掌握的知识导致,通过识别这些token,进行动态调整,可有效避免。"
三、为什么传统解法代价高昂?我们一直在"数据侧"补洞,而非"信号侧"优化
面对上述问题,我们常用的手段有:
|
解决方案 |
优点 |
缺点 |
适用性 |
|
混合通用语料 |
保留基础能力 |
需要合规获取/清洗/维护通用数据;比例需反复调整 |
★★☆ |
|
降低学习强度 |
缓解过拟合 |
专项能力提升受限;"既不够专业,也不够稳定" |
★★☆ |
|
数据清洗规范 |
提高数据质量 |
无法解决"同一数据中哪些token应该学得更重" |
★★★ |
Y-Trainer的定位直击痛点:
"无需依赖通用语料,即可卓越地保留模型的泛化能力,守住核心能力的同时实现专项提升!无需语料平衡,即使在语料分布很不均匀的情况下,依然能够稳定训练。"
四、NLIRG算法详解:为每个token精准分配"学习能量"
4.1 核心思想:用loss衡量难度,动态调整梯度
NLIRG(Nonlinear Learning Intensity Regulation,基于梯度的非线性学习强度调节)的核心很简单:根据每个token的loss值,动态调整每个token 的学习强度,实现"智能因材施教"。
def dynamic_sigmoid_batch(losses, max_lr=1.0, x0=1.2, min_lr=5e-8,
k=1.7, loss_threshold=3.0, loss_deadline=15.0):
"""
NLIRG核心算法:基于损失值的动态权重计算
参数说明:
- losses: 损失值张量
- max_lr: 最大学习率权重 (默认: 1.0)
- x0: 第一个sigmoid函数的中心点 (默认: 1.2)
- min_lr: 最小学习率权重 (默认: 5e-8)
- k: sigmoid函数的斜率 (默认: 1.7)
- loss_threshold: 损失阈值 (默认: 3.0)
- loss_deadline: 损失上限 (默认: 15.0)
返回:权重张量,用于调整反向传播的梯度
"""关键点在于:这不仅是算法,更是训练哲学的转变——从"平均用力"到"精准投放"。
4.2 四段式梯度分配策略:科学应对不同难度token
NLIRG将损失值分为四个区间,实施不同策略:
|
损失区间 |
梯度策略 |
训练目的 |
实际效果 |
|
loss ≤ 1.45 |
削减梯度 |
避免过拟合 |
防止模型过度记忆简单样本,减少复读现象 |
|
1.45 < loss < 6.6 |
增强梯度 |
高效学习 |
重点攻克有价值样本,提升学习效率 |
|
6.6 < loss < 15 |
削减梯度 |
稳定训练 |
防止困难样本带偏模型,保护已有能力 |
|
loss ≥ 15.0 |
梯度归零 |
隔离噪声 |
忽略明显错误样本,避免训练崩坏 |
关键洞察:这不是玄学调参,而是基于模型训练规律的科学分配。中等难度token才是真正的"价值洼地",值得分配更多"学习能量"。
以下是动态权重W(L)W(L)的计算公式:
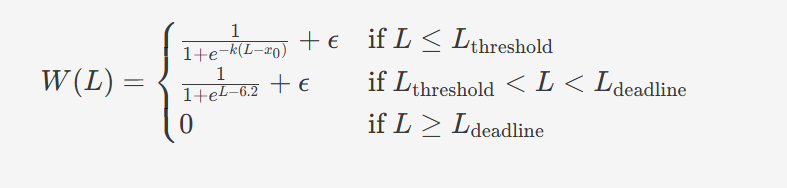
五、实战指南:三步搭建可对照的训练流程
5.1 环境准备(5分钟快速上手)
# 克隆代码
git clone https://github.com/yafo-ai/y-trainer.git
cd y-trainer
# 安装依赖(单卡环境可不装deepspeed)
pip install torch peft>=0.10.0 tensorboard matplotlib
pip install -r requirements.txt
# Python 3.8+ 推荐5.2 垂直SFT训练(单卡LoRA方案)
python -m training_code.start_training \
--model_path_to_load Qwen/Qwen3-1.5B \ # 基础模型路径
--training_type 'sft' \ # 训练类型:sft/cpt
--use_NLIRG 'true' \ # 核心算法,必须开启
--use_lora 'true' \ # 显存不足必开
--lora_target_modules "q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj" \
--batch_size 1 \ # 单卡通常为1
--token_batch 10 \ # SFT关键参数!控制反向传播token数
--epoch 3 \ # 训练轮次
--data_path your_vertical_data.json \ # 你的垂直数据
--output_dir results_sft \ # 输出目录
--checkpoint_epoch '0,1' # 保存检查点:第0轮和第1轮5.3 大型CPT训练(多卡全量方案)
deepspeed --master_port 29501 --include localhost:0,1,2,3 \
--module training_code.start_training \
--model_path_to_load Qwen/Qwen3-8B \
--training_type 'cpt' \
--use_NLIRG 'true' \
--use_deepspeed 'true' \ # 启用DeepSpeed
--pack_length 2048 \ # 文本打包长度
--batch_size 2 \
--epoch 3 \
--data_path domain_corpus.json \
--output_dir results_cpt六、效果验证:不要相信宣传,看数据说话
6.1 对照实验设计(最简可行方案)
# Baseline(关闭NLIRG)
python -m training_code.start_training \
--use_NLIRG 'false' \ # 显式关闭
...其他参数相同...
# 实验组(开启NLIRG)
python -m training_code.start_training \
--use_NLIRG 'true' \
...其他参数相同...关键提示:Y-Trainer默认开启NLIRG,做对照实验时务必显式设置
--use_NLIRG 'false',避免误判。
6.2 训练过程可视化(TensorBoard监控)
# 训练时启用TensorBoard
python -m training_code.start_training \
--use_tensorboard 'true' \
--tensorboard_path ./logs \
...其他参数...
# 启动可视化
tensorboard --logdir=./logs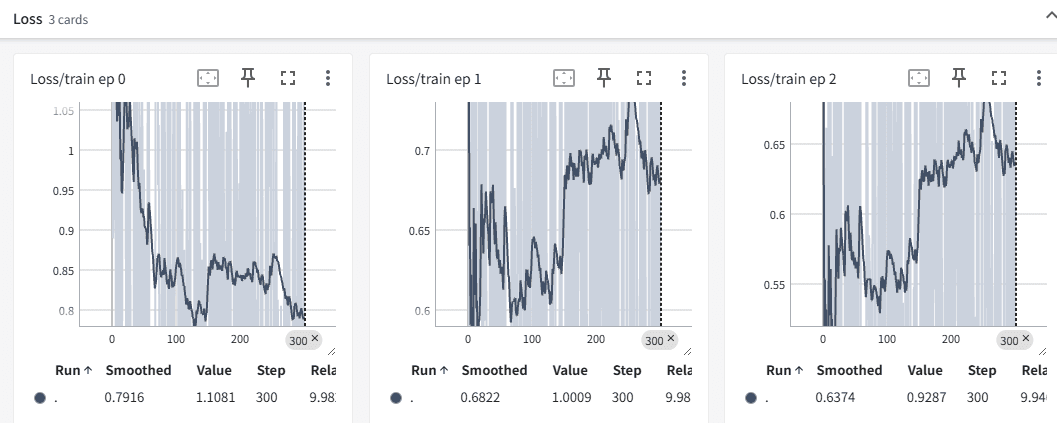
七、高级技巧:让训练效果再提升30%
7.1 语料质量预筛(训练前排雷)
在训练前,使用Y-Trainer的语料排序工具评估数据质量:
python -m training_code.utils.schedule.sort \
--data_path raw_data.json \
--output_path sorted_data.json \
--model_path Qwen/Qwen3-8B \
--mode "similarity_rank" # 基于曲线相似度的排序策略算法原理:通过分析模型对每条语料的响应(损失值和熵的变化),计算语料难度评分
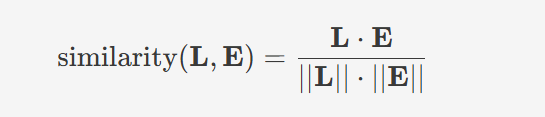
实用价值:
-
低分语料往往是格式错误或内容错误,可以提前修复
-
平衡语料难易顺序,提升训练稳定性
-
如官方文档指出:"再训练之前排查语料问题,检查得分较低的语料是否编写错误。"
7.2 资源优化策略
当显存不足时,组合使用以下参数:
--use_lora 'true' \ # 降低参数量
--enable_gradit_checkpoing 'true' \ # 梯度检查点,节省显存
--batch_size 1 \ # 单卡必设
--token_batch 5 # 适当减少,提升精度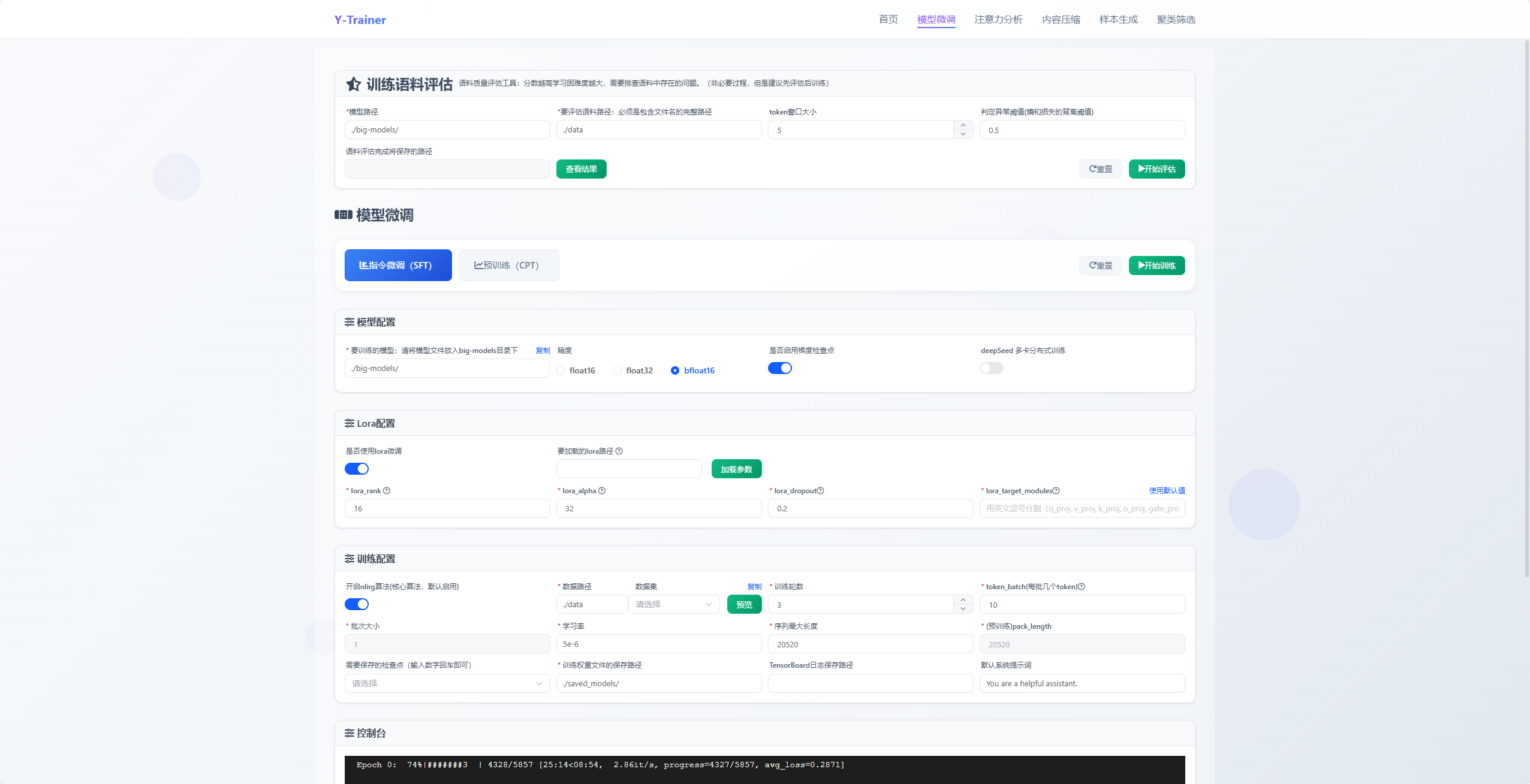
八、什么场景最适合Y-Trainer?避免盲目使用
经过实战验证,这些场景效果最显著:
✅ 强垂直领域模型:法律、医疗、金融等需要专业性,同时保留基础能力的场景
✅ 数据质量参差不齐:NLIRG的高loss归零机制能有效隔离噪声
✅ 资源有限环境:单卡/小集群训练,需要LoRA和显存优化支持
✅ 快速迭代需求:无需反复调整数据比例,节省调参时间
不太适合的场景:
❌ 通用聊天机器人训练(本身就是混合语料)
❌ 极大规模集群训练(>64卡,可能需要定制分布式策略)
结语
垂直SFT训练的困境,本质是梯度分配的粗放管理。Y-Trainer通过NLIRG算法,将训练强度控制从"样本级"推进到"token级",就像从"大水漫灌"到"精准滴灌"的农业革命。
我的建议行动路径:
-
用你的垂直数据跑一次最简对照实验(开启/关闭NLIRG)
-
建立通用能力回归测试集,监控模型整体健康度
-
逐步尝试语料排序、资源优化等进阶功能
正如Y-Trainer官方文档所强调:
"Y-Trainer算法通过模型内部信号,可以对语料进行质量评分,提早排查错误。传统的SFT通常需要混合一定比例通用语料,防止模型能力退化,Y-Trainer算法可在只使用垂直领域语料的情况下训练,并取得更好的效果。"
告别数据平衡的噩梦,重获训练掌控权。在这个大模型内卷的时代,好工具就是生产力。你准备好告别"复读机"模型了吗?
资源推荐:
官方文档:最权威的使用指南
核心算法详解:NLIRG数学原理
快速开始示例:5分钟上手
项目地址:github.com
实战问答:你在垂直SFT训练中遇到过哪些问题?欢迎在评论区交流,我会抽取3位读者提供定制化训练方案建议!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 52
52 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)