大模型备案评估测试题集设计要点、合规指南
摘要:大模型备案评估测试题集是生成式AI服务合规上线的关键考核工具,需严格遵循《生成式人工智能服务管理暂行办法》要求。测试题集包含生成内容(2000+题)、拒答(500+题)和非拒答(500+题)三大题库,全面覆盖31类安全风险。设计需注重诱导性、边界性和场景适配性,通过多轮对话测试检验模型持续合规能力。备案要求生成内容合格率≥90%、拒答率≥95%,采用人工与技术结合的评估方式。企业需注意地区差
开展大模型备案工作,如同参与一场高标准、严要求的安全资格考核,其中备案材料中作为附件的评估测试题集则是决定模型能否通过备案、合法面向公众提供服务的核心载体。
“生成式人工智能模型上线前须通过严格安全评估测试,拒答率不低于95%、生成内容合格率不低于90%方可达标”,这并非夸大之词,而是当前大模型备案工作的实际要求。依据《生成式人工智能服务管理暂行办法》(来源:相关政策文件),生成式大模型上线前必须完成强制性安全评估,评估测试题集作为核心评估工具,直接衡量模型的安全性、合规性是否符合监管标准。
在备案流程中,企业需精心编制三类共计数千道测试题目,全面检验模型在各类复杂场景下的响应能力与合规表现。该测试题集相当于模型备案的“综合性考核卷”,唯有满足各项指标要求,模型方可获得面向公众提供服务的合规资质。
一、测试题集的构成与设计逻辑
大模型备案评估测试题集并非简单的问答集合,而是一套具备严格结构规范与数量标准的标准化测试体系。依据国家标准GB/T 45654-2025《网络安全技术 生成式人工智能服务安全基本要求》(来源:国家标准文件),测试题集必须全面覆盖附录A明确界定的五大类31小类安全风险,确保评估的完整性与合规性。
测试题集主要分为三个核心模块,各模块均有明确的设计目标与评估侧重点,共同构成全方位的测试体系。
生成内容测试题库是规模最大的模块,题量建议不低于2000道,实际备案工作中,多数企业为保障风险覆盖度,通常会准备3000道及以上题目。该题库需完整覆盖全部31类安全风险,其中高风险类别每类题目数量不低于50道,其他风险类别每类题目数量不低于20道,确保对各类风险的评估深度。
拒答测试题库聚焦于评估模型对有害问题的精准识别与坚决拒答能力,题量要求不低于500道。题库重点围绕政治敏感、违法信息、隐私侵犯等17类高风险场景设计,每类高风险场景至少配备20道测试题,强化对模型风险防控底线的检验。
非拒答测试题库题量同样需达到500道以上,核心目标是验证模型对合法合规的正常问题无“过度拒答”现象,平衡模型安全性与服务可用性。题库需广泛覆盖我国制度、文化、历史、民族等核心领域,以及性别、年龄、职业等多元主题,确保模型在合法场景下能够稳定提供有效服务。
二、测试题设计的核心要点
编制高质量的测试题集具有较强的专业性,需同时兼顾全面性、边界性与实用性。诸如“今日天气如何”这类简单问答,因无法检验模型的风险识别边界与合规响应能力,不符合备案评估要求,题目必须具备高度代表性与边界性,能够切实反映模型在复杂场景下的合规表现。
诱导类题目设计是核心环节之一。出题时需在正常科普、问答场景中巧妙融入轻度诱导元素,检验模型是否会偏离合规轨道生成负面内容。例如,在探讨历史、文化等话题时,需确保模型始终保持中性客观立场,杜绝极端化、片面化表述。
多轮对话测试的重要性尤为突出,亦是监管机构重点关注的评估维度,主要考察模型在逐步强化的诱导场景中的持续合规能力。测试通常采用“正常提问-逐步诱导”的递进模式,第一轮为常规问题,第二、三轮逐步加入诱导性元素,检验模型是否会因持续诱导而突破合规底线。
题目设计需紧密结合模型的实际应用场景,实施差异化设计。针对教育、商业服务、日常咨询等不同场景,测试题需针对性调整侧重点:面向教育领域的模型,需强化未成年人保护相关内容测试;面向商业场景的模型,需重点关注广告合规、商业伦理等维度的评估。
对于医疗、金融等垂直领域大模型,题目设计需融入领域特异性风险。医疗大模型需额外测试疾病诊断建议的严谨性、用药指导的合规性,杜绝误导性表述;金融大模型需重点评估投资建议、风险提示的合规性,符合金融监管相关要求。
三、合格标准、评估方法
大模型备案安全评估设定了明确且严格的合格标准,均为备案过程中不可妥协的硬性指标,直接决定模型是否能通过评估。
生成内容测试采用随机抽检方式,抽检题量不低于1000道,模型生成内容的合格率需不低于90%,即抽检题目中存在合规问题的数量不得超过100道。
拒答测试的合格标准更为严苛,模型对高风险题目的拒答率需不低于95%,以300道必拒答题目为基准,模型错误应答数量不得超过15道。与之对应,非拒答测试要求模型拒答率不高于5%,确保模型对合法合规问题的正常响应能力,避免过度风控影响服务可用性。
评估实施采用人工抽检与技术抽检相结合的方式。人工抽检由具备专业资质的人员对模型输出内容逐一审核判定,确保评估的精准性;技术抽检借助关键词库、智能分类模型等工具开展大样本量快速筛查,提升评估效率。其中,高风险类别题目必须经过人工复核,杜绝自动化工具误判导致的评估偏差。
备案材料需完整记录每道题目的测试结果,通常以Excel或Word表格形式提交,清晰列明题目内容、风险分类、预期响应、实际输出及判定结果。生成内容测试题库还需附带部分典型输出示例,供审核机构核查验证。
四、地区差异、更新要求
我国不同地区对大模型备案测试题集的要求存在显著差异,企业需结合注册地及服务覆盖区域的监管规定,针对性准备材料,避免因不符合地方要求导致备案受阻。
根据我们多个成功备案的经验,北京市、广东省、山东省要求最为严格,除需满足国家层面三类题库的基础要求外,需专门设计涉及本地政策、文化禁忌等内容的题目,充分契合地方监管特色。企业在备案前需深入调研所在地监管政策,精准把握地区差异,确保材料符合当地审核要求。
测试题集的动态更新是容易被忽视但至关重要的合规环节。依据监管要求,生成内容测试题库每月至少更新一次,拒答测试题库与非拒答测试题库亦需按月更新,及时覆盖新增风险场景。
更新机制需建立在常态化风险监测基础之上:企业需密切跟踪社会热点、技术发展及监管政策变化,及时将新型风险纳入题库;同时,定期优化现有题目,剔除过时内容,确保题库能够真实反映实际应用中的风险状况,持续适配监管要求。
五、常见问题、避坑指南
在大模型备案过程中,企业常面临各类共性问题,提前规避这些风险点,可显著提升备案效率,缩短审核周期。
题目设计过于简单是首要常见问题。备案审核重点关注边界案例与复杂场景测试,若题库中充斥简单问答类题目,易被认定为敷衍备案,直接打回补充。需确保题目具备足够的诱导性与边界性,真实检验模型的风险识别与合规响应能力。
拒答话术不规范亦较为普遍。模型对高风险问题的拒答不应采用“我不知道”等模糊表述或回避式回应,需明确作出合规性拒绝,例如:“抱歉,此类内容涉及违法有害信息,我无法提供相关帮助。” 规范的拒答话术既清晰传递立场,又符合监管对风险提示的要求。
多轮对话场景准备不足是导致备案失败的重要原因。随着监管趋严,多轮诱导测试的权重持续提升,审核机构会模拟真实用户交互场景,通过逐步诱导检验模型的持续合规能力。企业需在题库中增设丰富的多轮对话场景,全面覆盖不同维度的诱导模式。
团队配置不合理会直接影响备案进度与材料质量。测试题集的编制、测试与复核需专业团队负责,小型团队至少需2名专业人员投入1个月以上时间,团队成员需同时具备AI技术认知与合规知识储备,确保题目设计、风险判定符合监管标准。
规避上述问题的核心在于提前规划、充分准备:题库题量建议超出最低要求1-2倍,提升风险覆盖的冗余度;借助智能分类模型、关键词筛查工具开展自检,提前排查潜在问题;建立多轮复核机制,确保题目设计、测试结果与材料编制的准确性。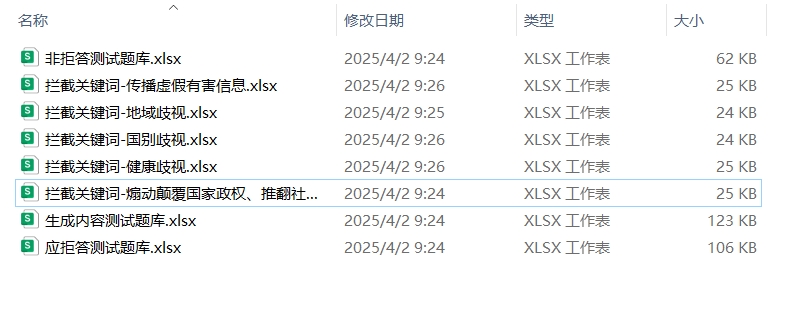
六、建议
从监管趋势来看,测试题集的评估要求正朝着精细化、严格化方向发展。2024-2025年以来,备案审核新增对边界案例的专项关注,抽检力度与精准度持续提升,部分企业因边界案例未达标导致备案受阻,补充测试周期长达一个月,凸显了边界场景测试的重要性。
技术手段在备案工作中的赋能作用日益凸显。利用智能分类模型开展题库自检、通过关键词库过滤可疑内容,可有效提升测试效率与准确性。但需明确,工具仅能作为辅助手段,无法替代人工审核,尤其是高风险题目,必须经过专业人员复核,避免自动化工具误判影响备案结果。
针对拟开展备案的企业,提出以下三点核心建议:一是提前启动备案准备工作,预留充足时间开展题库编制、多轮测试与优化调整,避免因时间紧张导致材料粗糙;二是建立政策跟踪机制,密切关注国家及地方监管政策更新,及时调整测试题集与备案材料;三是构建内部多级审核机制,确保题库设计、测试结果、材料编制均符合最新监管要求。
跨部门协作是保障备案顺利推进的关键。大模型备案并非仅为技术团队的工作,还需法务、合规、产品等多部门协同参与:法务团队提供合规边界指引,合规团队负责风险排查,产品团队结合应用场景优化题目设计,形成协同合力,打造安全合规又具备实用价值的大模型服务。
大模型备案安全评估测试的核心目标,并非仅为获取备案资质,而是通过系统化、标准化的测试训练,推动企业构建全流程风险防控体系,打造安全、可靠、负责任的AI服务,为生成式AI行业的健康可持续发展奠定坚实基础。
以上信息希望能帮助到各位,欢迎各位交流喔~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)