教你部署一个自己的舆情分析系统!BettaFish部署教程
在信息爆炸的时代,高效、精准地洞察网络舆情对企业决策和市场研究至关重要。BettaFish(又称“微舆”)是一款基于多智能体(Multi-Agent)技术的开源舆情分析系统,它能够自动分析国内外主流社交媒体平台的海量数据,并通过模拟“论坛辩论”的协作机制生成深度报告。对于许多初学者而言,在服务器上部署此类综合项目可能令人望而生畏。本教程旨在提供一份真正从零开始的详细指南,摒弃晦涩难懂的理论,专注于
前言
在信息爆炸的时代,高效、精准地洞察网络舆情对企业决策和市场研究至关重要。BettaFish(又称“微舆”)是一款基于多智能体(Multi-Agent)技术的开源舆情分析系统,它能够自动分析国内外主流社交媒体平台的海量数据,并通过模拟“论坛辩论”的协作机制生成深度报告。对于许多初学者而言,在服务器上部署此类综合项目可能令人望而生畏。本教程旨在提供一份真正从零开始的详细指南,摒弃晦涩难懂的理论,专注于可操作的步骤和清晰的解释,帮助你成功搭建属于自己的舆情分析平台。
第一部分:部署前准备
在开始安装之前,充分的准备工作是成功的关键。这部分将帮助你配置好服务器基础环境。
1.1 准备工作:
准备一台具备公网IP的云服务器(推荐使用雨云)
优惠注册地址:雨云 - 新一代云服务提供商_
使用优惠码:sn
注: 使用优惠码注册后绑定微信可领取5折优惠券
服务器选购步骤:
- 注册后,在"总览"页面找到"云服务器"入口,进入后点击"购买云服务器"
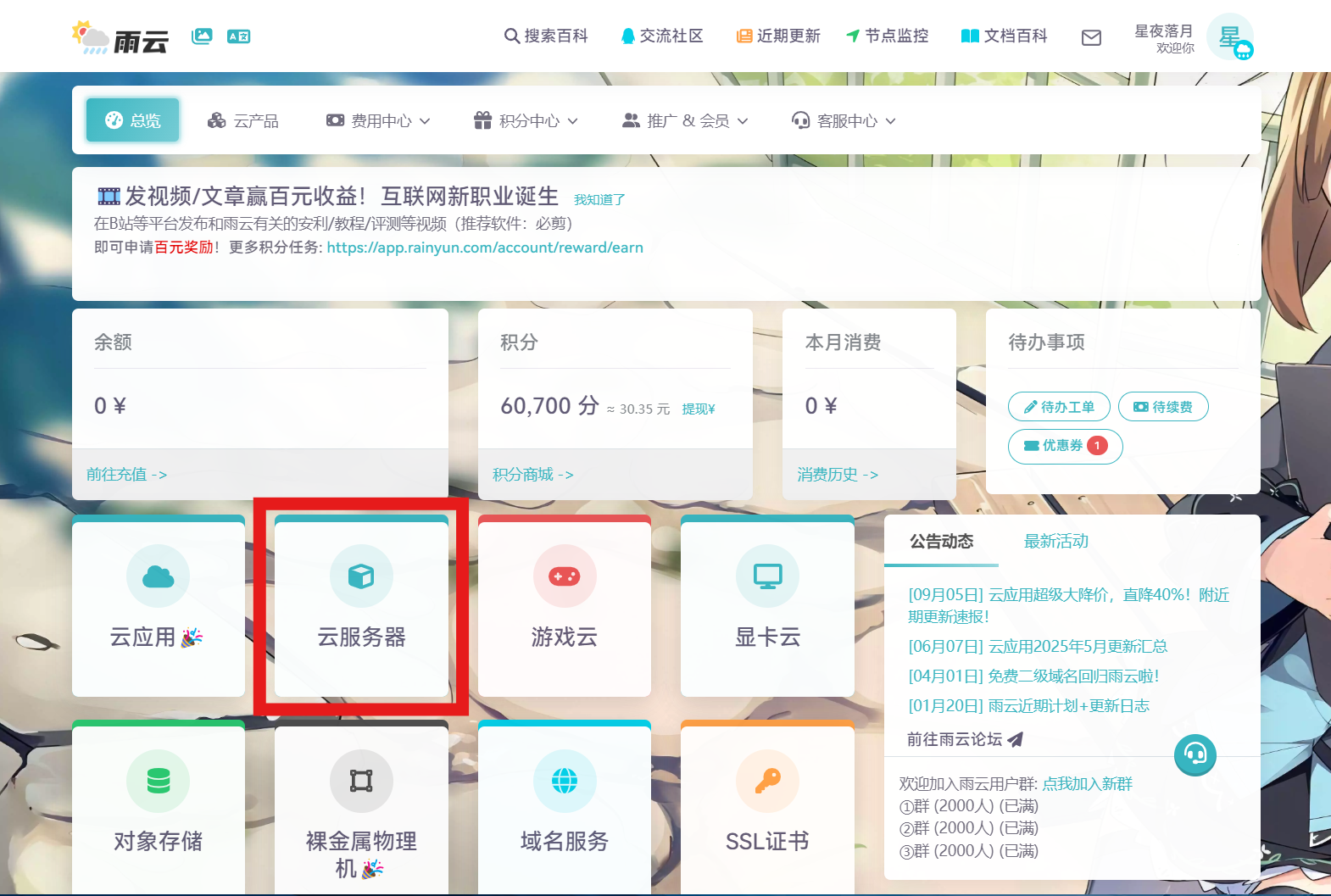
![]()
2.根据需求选择合适的配置,建议选择国内的服务器,访问更快,选好后点击立即购买即可
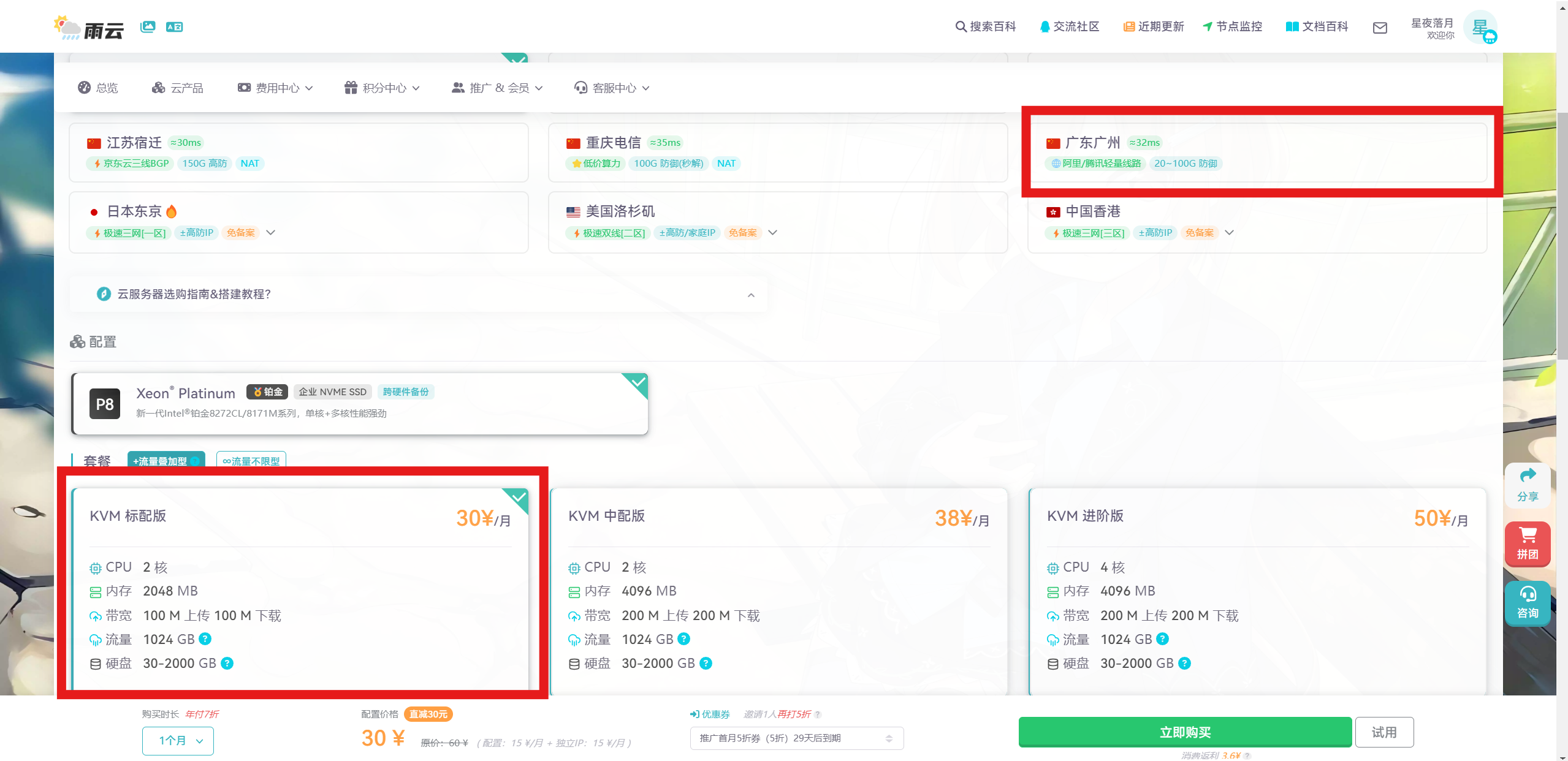
![]()
3.选好后进入控制台,使用SSH客户端远程连接服务器即可,SSH客户端建议选择FinalShell
1.2 获取项目源代码
请逐一核对并完成下表中的基本环境配置
| 检查项 | 命令 | 预期结果/操作 |
|---|---|---|
| 系统更新 | sudo apt update && sudo apt upgrade -y (Ubuntu) |
更新软件包列表并升级现有包。 |
sudo dnf update -y (CentOS) |
||
| Python版本 | python3 --version |
确认版本为3.8或以上,BettaFish推荐3.11。 |
| 安装pip | sudo apt install python3-pip -y (Ubuntu) |
安装Python包管理工具。 |
sudo dnf install python3-pip -y (CentOS) |
||
| 安装Git | sudo apt install git -y (Ubuntu) |
安装版本控制工具,用于拉取项目代码。 |
sudo dnf install git -y (CentOS) |
||
| 防火墙设置 | sudo ufw allow 5000 (Ubuntu) |
开放BettaFish默认的Web服务端口。 |
在准备好的目录下,克隆BettaFish项目的主仓库。
# 进入用户主目录或你选择的工作目录
cd ~
# 克隆项目代码
git clone https://github.com/666ghj/BettaFish.git
# 进入项目文件夹
cd BettaFish第二部分:选择与实施部署方案
BettaFish提供了两种主流的部署方式:手动部署和Docker容器化部署。Docker方式能极大简化环境依赖问题,是零基础用户的首选。
2.1 方案一:Docker部署(推荐)
这种方式通过容器技术将应用及其所有依赖打包,实现一键启动,避开了复杂的本地环境配置。
步骤1:安装Docker与Docker Compose 如果你的系统没有安装Docker,请执行以下命令:
# 安装Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
# 将当前用户加入docker组,避免每次使用sudo
sudo usermod -aG docker $USER
# 安装Docker Compose插件
sudo apt install docker-compose-plugin -y # Ubuntu
# 或 sudo dnf install docker-compose-plugin -y # CentOS安装完成后,需要退出SSH并重新登录,以便用户组更改生效。之后运行 docker --version 和 docker compose version 验证安装。
步骤2:配置环境变量文件 BettaFish通过 .env 文件管理所有配置。请基于示例文件创建你自己的配置。
# 复制环境变量示例文件
cp .env.example .env
# 使用nano或vim编辑该文件
nano .env你需要重点关注并修改以下几类配置,特别是数据库和各大模型的API密钥:
| 配置类别 | 关键变量示例 | 说明与获取指引 |
|---|---|---|
| 数据库 | DB_HOST=db, DB_DIALECT=postgresql |
Docker部署中,db指向Compose文件内定义的数据库容器。必须使用PostgreSQL。 |
| 大模型API | INSIGHT_ENGINE_API_KEY |
这是系统的核心。你需要从各大模型平台(如DeepSeek、Kimi、SiliconFlow等)申请API密钥。每个Agent可配置不同模型。 |
INSIGHT_ENGINE_BASE_URL |
填写对应API平台的地址,例如 https://api.siliconflow.cn/v1。 |
|
| 搜索工具API | TAVILY_API_KEY |
用于网络搜索,需在Tavily官网注册获取。 |
BOCHA_WEB_SEARCH_API_KEY |
用于多模态搜索,需在Bocha AI注册并领取免费资源包。 |
步骤3:启动Docker容器 配置完成后,使用一条命令启动所有服务(包括BettaFish应用和PostgreSQL数据库)。
# 在项目根目录(docker-compose.yml所在目录)执行
docker compose up -d-d 参数表示在后台运行。首次执行会从网络拉取镜像,时间可能较长。如果拉取官方镜像速度慢,可以编辑 docker-compose.yml 文件,尝试使用国内镜像源(如 ghcr.nju.edu.cn/666ghj/bettafish:latest)。
启动后,使用 docker compose ps 查看容器状态,显示为“Up”即表示运行正常。
2.2 方案二:手动部署
此方式适合希望深入了解项目依赖或进行二次开发的用户。你需要手动安装Python依赖和数据库。
步骤1:创建并激活Python虚拟环境
# 安装虚拟环境工具
sudo pip3 install virtualenv
# 创建虚拟环境
python3 -m virtualenv venv
# 激活虚拟环境
source venv/bin/activate
# 激活后,命令行提示符前通常会出现 (venv)步骤2:安装Python依赖 在激活的虚拟环境中,安装项目所需的所有包。
pip install -r requirements.txt这是最关键的步骤之一。如果遇到某些包(如早期教程中提到的Pillow、PyTorch)编译安装失败,可以尝试搜索对应平台的预编译轮子(wheel)文件,或使用 conda 安装。
步骤3:安装并配置PostgreSQL数据库
-
安装数据库:
sudo apt install postgresql postgresql-contrib -y # Ubuntu sudo dnf install postgresql-server postgresql-contrib -y # CentOS sudo postgresql-setup --initdb # CentOS初始化 sudo systemctl start postgresql sudo systemctl enable postgresql -
创建数据库和用户:
# 切换到postgres系统用户 sudo -u postgres psql # 在psql命令行中执行 CREATE DATABASE bettafish; CREATE USER bettafish WITH PASSWORD 'your_strong_password'; GRANT ALL PRIVILEGES ON DATABASE bettafish TO bettafish; \q # 退出 -
修改
.env文件:将数据库连接信息修改为本地配置(DB_HOST=localhost,DB_PASSWORD=your_strong_password等)。
第三部分:启动系统与验证
无论采用哪种部署方式,启动后的访问和验证流程是相似的。
3.1 启动并访问Web界面
-
Docker部署:容器启动后,服务即自动运行。
-
手动部署:在项目根目录下,激活虚拟环境后运行:
python app.py # 或使用 UTF-8 编码启动以避免潜在编码错误 # python -X utf8 app.py
启动成功后,在本地电脑的浏览器中访问:http://你的云服务器公网IP:5000。
3.2 初始化配置
首次访问Web界面,系统可能会引导你进行初始化配置:
- 数据库连接测试:确保
.env中的数据库配置正确。 - 填写大模型API密钥:将你在
.env文件中配置的各个Agent的API Key、Base URL和模型名称,在Web界面的对应位置填写并保存。务必确保所有BASE_URL都已正确填写,否则系统可能会错误地调用默认的OpenAI接口导致失败。
3.3 运行首个分析任务
配置完成后,你可以在首页的搜索框输入一个你想分析的舆情主题,例如“近期新能源汽车市场反馈”,然后点击搜索。系统会调动背后的多个AI Agent进行数据收集、分析和辩论,最终生成一份详细的报告。这个过程可能需要几分钟,请耐心等待。
结语
恭喜你!如果你按照以上步骤完成了部署并成功运行了第一个分析任务,那么你已经成功在Linux云服务器上搭建了一个功能强大的AI舆情分析系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)