从MELT到语义治理:深度解析多智能体协作下的新一代数据治理
1月21日,博睿数据数智能力中心AI能力开发部负责人丁锐,以《2026趋势预测:多智能体协作下的新一代数据治理》为主题展开深度分享。他围绕多智能体协作的核心技术原理与架构演进,深度拆解该模式下新一代数据治理的核心逻辑,精准传递前瞻趋势与行业洞察。
2026年博睿数据重磅推出【前瞻2026:可观测技术风向与趋势洞察】专题直播,聚焦可观测领域核心技术演进、未来趋势预判与产品体系化升级,为从业者传递前沿技术理念与核心洞见。
1月21日,博睿数据数智能力中心AI能力开发部负责人丁锐,以《2026趋势预测:多智能体协作下的新一代数据治理》为主题展开深度分享。他围绕多智能体协作的核心技术原理与架构演进,深度拆解该模式下新一代数据治理的核心逻辑,精准传递前瞻趋势与行业洞察。我们同步发布技术长文,在直播分享基础上进一步深化技术细节、梳理方法论框架,为企业前瞻布局新一代数据治理提供清晰指引。
以下为原文,精彩直播回放及演讲资料文末领取。
引 言
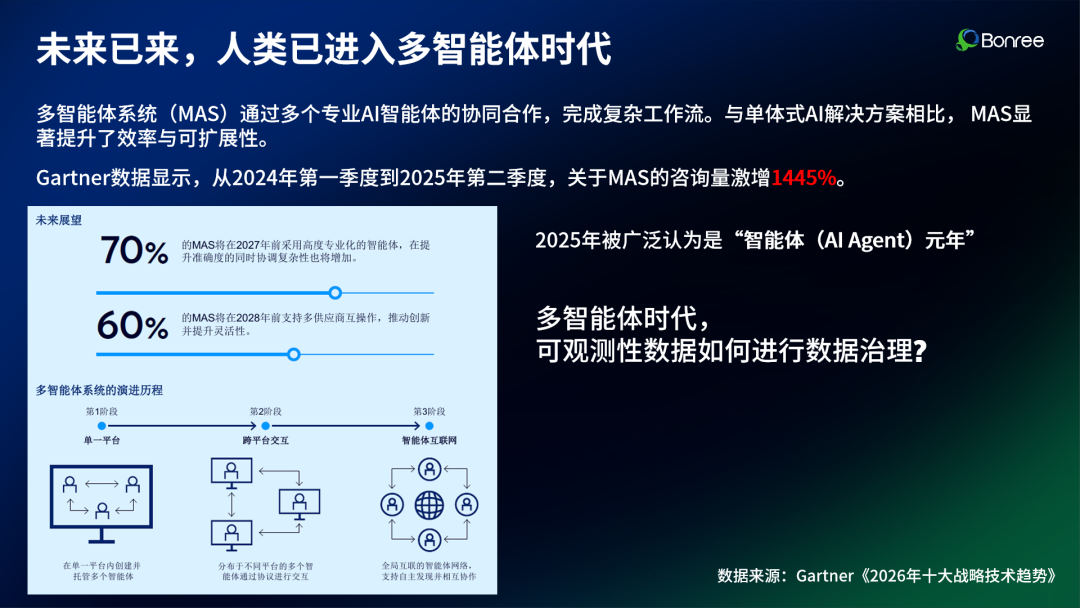
未来已来,人类已进入多智能体时代。多智能体系统(MAS)通过多个专业AI智能体的协同合作,完成复杂工作流。与单体式AI解决方案相比,MAS显著提升了效率与可扩展性。Gartner数据显示,从2024年第一季度到2025年第二季度,关于MAS的咨询量激增1445%。
这一爆发式增长背后,暴露出一个关键挑战:当多个AI智能体开始协同工作,传统的可观测性数据治理框架已经捉襟见肘。如何让这些智能体"听懂人话、说人话"?如何监督它们的"思考过程"?如何确保协作高效且成本可控?多智能体时代,可观测性数据如何进行数据治理?
本文将系统解读面向2026年的新一代数据治理方案,揭示从传统MELT框架到"以语义为中心"的五层治理架构的演进路径。
一、传统数据治理:MELT框架的坚守阵地
1.1 MELT治理体系概览
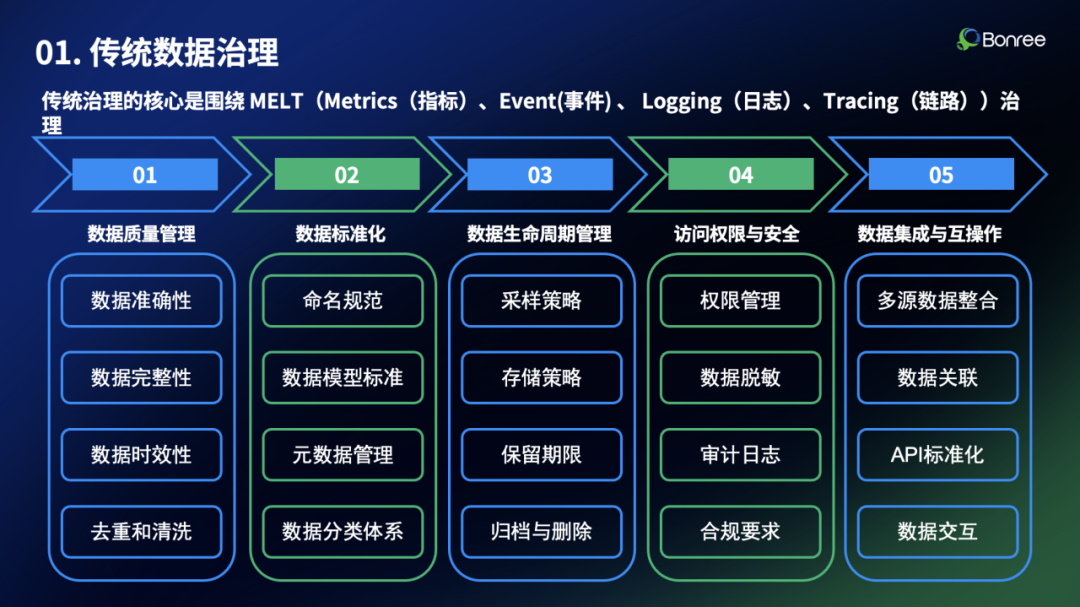
传统可观测性数据治理的核心是MELT体系——Metrics(指标)、Event(事件)、Logging(日志)、Tracing(链路)。这套框架主要聚焦于系统运行状态的监控与优化,解决数据的合规性、成本与一致性问题。
1.2 五大核心治理领域
-
数据质量管理是基础保障。系统需要确保指标、日志、链路数据的准确性和一致性,防止数据丢失,管理采样策略,监控数据延迟,并实施有效的数据去重与清洗机制。
-
数据标准化建立统一规范。通过制定指标、标签、日志格式的命名约定,采用OpenTelemetry等标准协议,管理描述数据来源和关系的元数据,并按业务、系统、层级建立分类体系。
-
数据生命周期管理优化存储成本。包括设计采集策略(采样率、过滤规则),实施分层存储(热数据、冷数据),制定基于合规和成本的保留政策,以及建立安全的归档与删除机制。
-
访问控制与安全保护数据资产。实施基于角色的访问控制(RBAC),对敏感信息进行脱敏处理,记录数据访问和操作的审计日志,满足GDPR、SOC2等合规要求。
-
数据集成与互操作打破信息孤岛。整合不同监控工具的数据,建立指标、日志、链路的关联分析能力,提供统一的数据查询接口。
1.3 局限性分析
MELT框架在监控系统性能、可用性、资源使用方面表现出色,但面对AI智能体的协作场景,它存在明显短板:无法理解智能体的"语义意图",无法追踪"思维推理"过程,无法评估协作质量,也无法应对AI特有的安全风险如幻觉、偏见、越狱攻击。
二、新型五层数据治理范式:
以语义为中心的治理体系
多智能体协作催生了全新的治理需求。我们需要从传统的"系统状态监控"转向以语义为中心(Semantic-Centric)的治理体系,构建包含五个核心层面的立体化治理架构。
2.1 语义治理层:理解引擎
语义层是新体系的核心,关注内容质量与意图准确性。它不仅仅追求数据质量,更关注意图一致性、信息保真与逻辑闭环,确保智能体能够"听懂人话、说人话"。
意图识别准确性是首要目标。系统需要评估对用户真实意图的理解程度,建立多维度的输出质量评估体系(事实性、相关性、流畅性、安全性),实时识别模型生成的幻觉内容,确保多轮对话的语义连贯性,并验证领域知识的专业准确性。
知识库治理保障检索质量。通过优化向量检索的召回率和精度,建立知识更新机制确保新鲜度,追溯知识来源验证可靠性,评估embedding质量,分析知识覆盖度以识别盲区。
2.2 认知治理层:思考引擎
认知层穿透智能体的行为表象,治理其理解、推理与决策过程,让AI的"思考"可监督、可解释、可优化。
智能体行为治理实现决策可追溯。记录从输入到输出的完整推理链,识别智能体的常见决策模式和潜在问题,建立行为基线以检测异常(如循环推理、决策停滞),量化智能体的学习能力和自我改进效果。
提示词治理标准化工程实践。建立企业级提示词模板库,实现版本管理支持快速回滚,通过A/B测试量化不同提示策略的效果,监控上下文窗口使用效率,检测并拦截恶意提示注入攻击。
工具调用链治理确保执行透明。评估智能体选择工具的准确性,完整记录工具调用序列形成可视化执行图,监控外部工具的可用性和响应质量,分析调用模式识别优化机会。
2.3 协作治理层:协调者
协作层设计智能体间的交互协议与责任链路,实现任务分流、信任传递与协同纠错。
协作模式治理优化集体智能。分析智能体间的依赖关系和通信模式识别瓶颈,评估任务分解和分配策略确保负载均衡,建立决策冲突的检测和解决机制,识别可并行执行的任务以提升吞吐量。
反馈闭环治理驱动持续改进。系统化收集和分析用户反馈,建立多维度的输出质量评分机制,管理失败案例形成可学习的经验库,支持不同策略的对比实验,有效整合人类专家反馈(RLHF)提升智能水平。
2.4 成本治理层:效率守门员
成本层实施token级别的精细化成本管理,让协作成本可视、可调、可优化。
模型调用治理实现精细核算。追踪token级别的成本并准确归因到具体业务,在响应质量和成本间找到最优平衡,分解延迟识别瓶颈,降低因错误重试产生的额外成本,根据任务复杂度智能选择模型规格。
资源优化治理提升投资回报。在多模型混合场景下实现透明的成本归因,最大化相似查询的缓存命中,识别可批量处理的请求,基于业务价值动态分配资源配额,利用峰谷时段成本差异优化调度,量化AI系统的业务价值评估ROI。
2.5 安全治理层:守护者
安全层直面幻觉、偏见、越狱等AI原生风险,构建覆盖从输入到输出的语义安全防线。
安全与合规治理建立全面防护。实时检测和拦截有害内容的生成和传播,识别和防御越狱攻击、提示注入等威胁,确保用户敏感数据流转时的安全性,满足AI监管要求确保可解释性和公平性,追踪数据来源确保知识产权合规,检测模型输出中的偏见。
主动防御体系实现快速响应。建立安全异常的快速发现和处置机制,系统化开展安全测试主动发现脆弱性,积累安全威胁情报和防御经验,建立风险预测模型提前识别潜在问题。
2.6 五层协同架构
这五个层面并非孤立存在,而是形成协同治理体系:认知层+语义层共同决定输出质量,协作层通过智能体编排提升整体效能,成本层约束资源使用追求最优性价比,安全层贯穿所有层面提供基础保障。

三、新型数据治理技术方案:从架构到落地
3.1 语义治理层技术实现
语义级治理,需要在原有的数据结构中植入一个“语义层(Semantic Layer)”

指标语义提取
将时间序列指标转换为易于理解的语义表达,主要包括:
-
语义标签添加:为每个指标添加业务含义、影响范围、关联组件等标签。
-
异常模式识别:使用时序分析方法识别异常模式。
-
模式知识库构建:建立模式知识库,支持相似模式匹配。
-
因果依赖图构建:建立指标间的因果关系图,便于根因分析。
事件语义链接
为离散事件建立统一的语义模型,实现事件间的关联与分析:
-
语义模型构建:为事件建立统一的语义描述。
-
因果关系建立:明确事件间的因果关系链。
-
复杂事件处理(CEP):支持语义查询与事件流处理。
-
影响评估:评估事件对系统与业务的影响范围,关联受影响的用户、订单、服务等。
-
事件序列识别:识别事件发生的序列模式。
日志语义解析
从非结构化日志中提取结构化语义信息,包括:
-
日志模板提取:使用 Drain/Spell 等算法提取日志模板。
-
语义聚类:对语义相似的日志进行聚类。
-
语义标签分配:为每个模板分配错误类型、严重级别、业务影响等标签。
-
实体关系提取:提取调用关系、依赖关系等实体间的关联。
调用链语义关联
将分布式追踪数据转化为业务语义流,实现调用链的语义化分析:
-
业务操作标签:为每个 Span 添加业务操作标签(如“用户登录”、“订单支付”等)。
-
关键路径识别:识别关键业务路径与非关键路径。
-
故障传播图生成:生成语义化的故障传播图,便于定位问题。
-
业务与代码关联:将调用链关联到具体的业务操作和代码位置。
幻觉检测与控制方案
部署SelfCheckGPT进行自我一致性检查,利用SAFE(搜索增强事实性评估器)进行外部验证,采用Monte Carlo Dropout等方法进行不确定性量化,使用FEVER等工具进行事实验证。检测到幻觉时,系统自动触发质量阈值告警并进行修正。
知识库与向量治理技术
使用BGE、E5、OpenAI embeddings等先进模型生成高质量向量,采用Pinecone、Weaviate、Qdrant等向量数据库实现高效检索,通过Cohere Rerank、Cross-encoder等重排序模型提升精度。混合检索结合密集向量(Dense)和稀疏表示(BM25、SPLADE)以获得最佳效果。
知识新鲜度管理使用DVC(数据版本控制)、Apache Iceberg等工具追踪版本变化,通过Kafka实现流式增量更新,利用Apache Atlas、DataHub管理元数据和数据血缘关系。
3.2 认知治理层技术实现

智能体行为治理技术
利用LangChain Callbacks、LangSmith自动捕获模型推理过程,使用OpenTelemetry标准进行分布式追踪,通过Jaeger、Zipkin存储和可视化追踪数据。推理链以结构化格式(JSON)存储,形成完整的思维链路图谱。
行为模式识别使用Prophet、LSTM等时序分析工具,通过Isolation Forest、LOF等算法进行异常检测,利用Sentence-BERT对行为进行向量编码后进行模式挖掘。
提示词数据治理技术
采用Jinja2、Mustache等模板引擎实现参数化管理,使用Git+DVC进行版本控制支持快速回滚,利用DSPy实现声明式提示工程,通过MLflow追踪提示词实验效果。
效果评估建立自动化pipeline,使用G-Eval等基于GPT的评估方法,部署Eppo、Statsig等A/B测试平台进行对比实验,使用SciPy、Statsmodels进行统计显著性检验。
上下文优化使用tiktoken进行token计数,采用LLMLingua、AutoCompressor等技术进行上下文压缩,通过Cohere Rerank、BGE Reranker进行语义排序。
安全注入检测部署Rebuff、LLM Guard等专用检测工具,使用DistilBERT、RoBERTa微调分类器识别恶意模式,参考OWASP LLM Top 10建立威胁情报库。
工具调用链治理技术
使用OpenTelemetry进行端到端追踪,通过Jaeger实现调用链可视化,利用NetworkX、Neo4j构建调用DAG图谱。采用tenacity、resilience4j等库实现智能重试,使用pybreaker、Hystrix等熔断器保障依赖可靠性,通过Prometheus监控工具性能和SLA。
调用优化使用asyncio、Ray等实现并行执行,采用Apache Airflow、Prefect等DAG引擎进行编排,利用Redis、GPTCache实现语义缓存减少重复调用。
3.3 协作治理层技术实现
协作拓扑与任务分配技术
使用NetworkX、Neo4j进行图分析和关系建模,通过Louvain、Leiden等算法进行社区检测识别协作模式,利用Plotly、D3.js、Cytoscape.js进行可视化展示。实时追踪使用Kafka、Redis Streams捕获协作事件。
任务调度采用Celery分布式任务队列,使用Ray进行分布式计算,利用Kubernetes Job Scheduler进行容器化任务管理。负载均衡使用NGINX、HAProxy、Envoy Proxy,通过Sentence-BERT进行能力语义匹配,使用XGBoost、LSTM预测任务性能。
协作编排与冲突解决技术
工作流编排使用Apache Airflow、Prefect、Temporal等成熟引擎,支持DAG定义和并行执行。消息通信采用Kafka、RabbitMQ、NATS等高性能消息队列,使用Protocol Buffers、gRPC优化序列化和传输效率。
冲突解决实施Raft、Paxos等共识算法,使用DeBERTa-MNLI等NLI模型检测矛盾,通过加权投票、二次投票等机制达成共识,采用LLM作为仲裁器处理复杂冲突。
反馈闭环与RLHF技术
反馈收集使用PostHog、Amplitude等产品分析平台,A/B测试采用GrowthBook、Statsig等工具,利用SciPy、PyMC进行统计分析。实验管理使用MLflow、Weights & Biases追踪效果。
RLHF实现使用TRL、trlX等框架,通过Label Studio、Prodigy等平台收集人类反馈,使用Transformers训练奖励模型,采用Stable Baselines3、RLlib实现PPO(近端策略优化)算法。
3.4 成本治理层技术实现

Token级追踪方案与性能成本平衡
使用OpenTelemetry在每个请求中注入成本属性(token数、模型调用次数),通过Prometheus收集成本指标,在Grafana中构建成本仪表板实现多维度归因分析(按业务、用户、任务)。
实施基于任务复杂度的动态模型选择策略,简单任务使用轻量模型(Haiku),复杂任务使用强大模型(Opus),通过路由算法自动匹配。
构建从租户-应用-会话-请求每级节点的成本,支持多维成本查询。
建立不同模型在各类任务上的质量得分和成本分布表,同时基于分类模型评估任务复杂度,针对简单任务使用快速低成本模型。
缓存与批处理优化技术
使用Redis、Memcached构建多级缓存系统,采用GPTCache实现语义缓存(基于embedding相似度),对相似查询直接返回缓存结果。批处理使用Ray、Apache Beam等框架,识别可批量处理的请求以提高吞吐量和资源利用率。
动态配额管理基于业务价值和优先级分配资源,使用Kubernetes资源配额(Resource Quota)进行限制,通过峰谷调度优化非实时任务的执行时段。
使用TTL动态调整,高频访问延长TTL,低频访问提前过期。
使用批处理技术可以显著提升效率:比如,请求聚合窗口,在某个滑动窗口内收集同类请求,根据GPU利用率和队列深度调整批次等。
3.5 安全治理层技术实现
内容安全与攻击防御技术
部署NeMo Guardrails、LLM Guard等护栏系统在输入输出端进行实时检测,使用OpenAI Moderation API、Perspective API检测有害内容,利用DeBERTa-v3等小模型识别提示注入和越狱攻击。
检测到安全风险时,系统自动拦截请求并生成Security Event,将相关Trace标记为status=security_risk,触发告警和处置流程。
隐私保护与合规技术
在OpenTelemetry Collector中集成Presidio等PII检测引擎,对日志和链路中的敏感信息(手机号、身份证、银行卡)进行实时脱敏处理。实施数据最小化原则,仅记录必要的元数据,对原始载荷进行加密存储或限期删除。
可解释性增强要求在每个Trace的属性中包含知识来源ID、模型版本、推理路径等信息,根据EU AI Act要求为高风险任务打上合规标签,关联审计日志。
攻击防御与红队测试技术
建立自动化红队测试系统,定期从安全知识库提取最新的攻击模版(提示注入、越狱尝试),对Agent端点发起模拟攻击。成功的攻击用例自动转化为Security Metric,触发修复工单。
基于UEBA(用户实体行为分析)建立风险预警模型,监控Token使用量激增、输出毒性得分上升等异常模式,自动触发熔断策略。将安全告警直接关联到异常Trace链路,实现分钟级定位和响应。
四、数据治理效果评估指标:量化治理成效
4.1 语义层评估指标
意图与质量指标
意图识别准确率(Intent Accuracy):评估系统理解用户真实意图的准确程度
-
幻觉发生率(Hallucination Rate):监控模型生成虚假信息的频率
-
事实性验证得分(Factuality Score):量化输出内容的事实准确性
-
语义一致性指数(Semantic Consistency Index):衡量多轮对话的连贯性
-
领域知识准确率(Domain Knowledge Accuracy):评估专业领域的准确性
知识库质量指标
-
检索召回率与精确率(Recall & Precision):评估向量检索的有效性
-
知识新鲜度指数(Freshness Index):追踪知识库的更新及时性
-
知识覆盖率(Knowledge Coverage):识别业务场景的知识盲区
-
检索相关性得分(Relevance Score):量化检索结果与查询的匹配度
4.2 认知层评估指标
行为与决策指标
-
决策链完整性(Coverage Rate):评估推理链记录的完整程度
-
平均推理步骤数(Reasoning Depth):衡量智能体的思考深度
-
决策自洽性得分(Consistency Score):检测推理逻辑的一致性
-
反思触发频率与质量:评估自我改进机制的有效性
提示词效能指标
-
提示词有效性得分(Effectiveness Score):量化提示词的性能表现
-
上下文利用率(Context Utilization):监控token使用效率
-
提示注入检测率(Injection Detection Rate):评估安全防护能力
工具调用指标
-
工具选择准确率(Tool Selection Accuracy):评估工具选择的合理性
-
工具调用成功率(Call Success Rate):监控执行可靠性
-
平均调用链长度(Chain Length):优化执行路径
-
工具响应时延分布:识别性能瓶颈

4.3 协作层评估指标
协作效率指标
-
任务完成时间缩短率(Task Completion Time):衡量协作效率
-
智能体平均利用率(Agent Utilization):评估资源使用均衡性
-
协作并行度提升(Parallelism Degree):量化并行执行能力
-
决策冲突率与解决时间:监控协作顺畅程度
-
通信开销比例:优化协作成本
反馈改进指标
-
用户满意度得分(User Satisfaction Score):直接反映业务价值
-
反馈收集覆盖率(Feedback Coverage):评估反馈系统的全面性
-
改进迭代周期(Improvement Cycle Time):衡量响应速度
-
A/B测试效果差异(Effect Size):量化优化成果
-
异常案例解决率:追踪问题闭环能力
4.4 成本层评估指标
成本效益指标
-
单次请求成本降幅(Cost per Request):实现精细化成本核算
-
Token使用效率(Token Efficiency):优化资源消耗
-
端到端响应时延(E2E Latency):平衡性能与成本
-
调用失败率与重试成本:减少浪费
-
成本-质量比(Cost-Quality Ratio):评估投入产出
优化成效指标
-
整体成本节约率(Cost Saving Rate):量化优化效果
-
缓存命中率(Cache Hit Rate):衡量缓存策略有效性
-
批处理吞吐量提升:评估并行化收益
-
资源利用率(Resource Utilization):监控资源使用效率
-
业务价值-成本比(Value/Cost Ratio):计算ROI
4.5 安全层评估指标
安全防护指标
-
有害内容拦截率(Harmful Content Block Rate):评估内容安全防护
-
攻击检测准确率(Attack Detection Accuracy):衡量威胁识别能力
-
隐私泄露事件数(Privacy Breach Count):监控数据安全
-
合规审计通过率(Compliance Pass Rate):确保合规性
-
偏见检测得分(Bias Detection Score):评估公平性
-
可解释性覆盖率(Explainability Coverage):满足透明度要求
响应能力指标
-
安全事件响应时间(MTTR):衡量应急响应速度
-
红队测试发现问题数:评估主动防御效果
-
已知漏洞修复率:追踪安全改进
-
风险预警准确率:验证预测模型有效性
结 语
2026年,多智能体协作已成为AI应用的主流范式。这场变革不仅改变了AI系统的工作方式,更重新定义了数据治理的边界。从传统的MELT框架到以语义为中心的五层治理架构,从关注"系统状态"到洞察"智能体思维",从被动监控到主动优化——新一代数据治理正在重塑可观测性的未来。
这套治理体系不是纸上谈兵,而是基于成熟技术栈的可落地方案。从OpenTelemetry的标准化追踪,到LangSmith的LLM专用监控;从BGE的高质量向量化,到RAGAS的RAG评估;从Apache Airflow的工作流编排,到TRL的RLHF实现——每个治理层面都有完善的技术支撑。
展望未来,多智能体数据治理将持续演进:更智能的自动化治理、更精准的语义理解、更高效的协作优化、更经济的成本控制、更坚固的安全防线。企业需要尽早布局,从核心的语义质量评估和检索优化开始,逐步构建完整的五层治理体系。
在这个多智能体的新时代,谁能率先掌握新一代数据治理能力,谁就能在AI竞赛中占据先机。未来已来,治理先行。
点击下方图片或扫描图片中二维码即刻领取演讲资料。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)