AI 论文周报丨Transformer前沿研究专题导读,解析结构稀疏化、记忆机制与推理组织的最新进展
北京大学与 DeepSeek-AI 的研究者提出 Engram,一种具有 O(1) 查找复杂度的可扩展条件记忆模块,通过将静态知识检索 Transformer 的早期层中剥离出来并与 MoE 形成互补,从而释放早期层用于更深层的推理计算,并在推理任务(BBH +5.0,ARC-Challenge +3.7)、代码与数学任务(HumanEval +3.0,MATH +2.4)以及长上下文任务(Mul
过去八年,Transformer 几乎重塑了整个人工智能研究版图。自 2017 年 Google 在「Attention Is All You Need」中提出这一架构以来,「注意力机制」逐渐从一种工程技巧演变为深度学习的通用范式——从自然语言处理到计算机视觉,从语音、多模态到科学计算,Transformer 正在成为事实上的基础模型骨架。
以 Google、OpenAI、Meta、Microsoft 为代表的工业界不断推动其规模化与工程化极限,而斯坦福、MIT、伯克利等高校则在理论分析、结构改进与新范式探索上持续输出关键成果。在模型规模、训练范式与应用边界不断被拓展的同时,Transformer 领域的研究也呈现出高度分化与快速演进的趋势——这使得系统性梳理与精选代表性论文,变得尤为必要。
为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI超神经官网(hyper.ai)现已上线「最新论文」板块,每天都会更新 AI 前沿研究论文。
* 最新 AI 论文:https://go.hyper.ai/hzChC
本周,我们为大家精心挑选了 5 篇有关 Transformer 的热门论文,涵盖北大、DeepSeek、字节跳动 Seed、Meta AI 等团队,一起来学习吧!⬇️
本周论文推荐
1
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
北京大学与 DeepSeek-AI 的研究者提出 Engram,一种具有 O(1) 查找复杂度的可扩展条件记忆模块,通过将静态知识检索 Transformer 的早期层中剥离出来并与 MoE 形成互补,从而释放早期层用于更深层的推理计算,并在推理任务(BBH +5.0,ARC-Challenge +3.7)、代码与数学任务(HumanEval +3.0,MATH +2.4)以及长上下文任务(Multi-Query NIAH:84.2 → 97.0)上取得显著提升,同时保持等参数量与等 FLOPs 的效率。
论文及详细解读:https://go.hyper.ai/SlcId
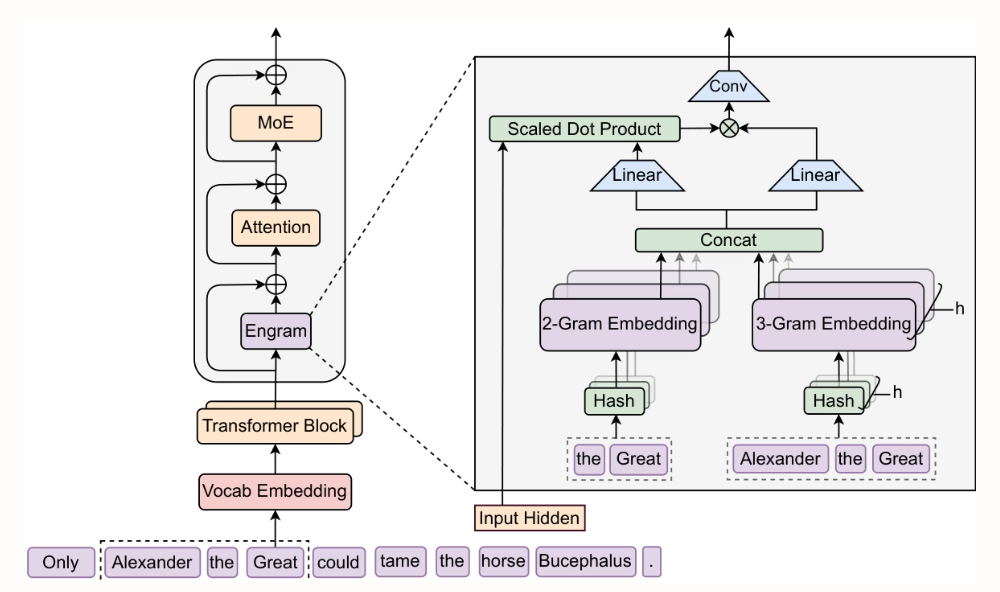
Engram 模型结构示例
2
STEM: Scaling Transformers with Embedding Modules
卡内基梅隆大学与 Meta AI 的研究人员联合提出一种静态的、基于标记索引的稀疏架构——STEM。用层内嵌入查找替代 FFN 的上投影,实现稳定训练,将每标记的 FLOPs 和参数访问量减少约三分之一,并通过可扩展的参数激活提升长上下文性能。通过将容量与计算和通信解耦,STEM 支持异步预取的 CPU 卸载,利用具有大角度分布的嵌入实现更高的知识存储容量,同时无需修改输入文本即可实现可解释、可编辑的知识注入,在知识和推理基准测试中,相比密集基线性能提升高达约 3–4%。
论文及详细解读:https://go.hyper.ai/NPuoj
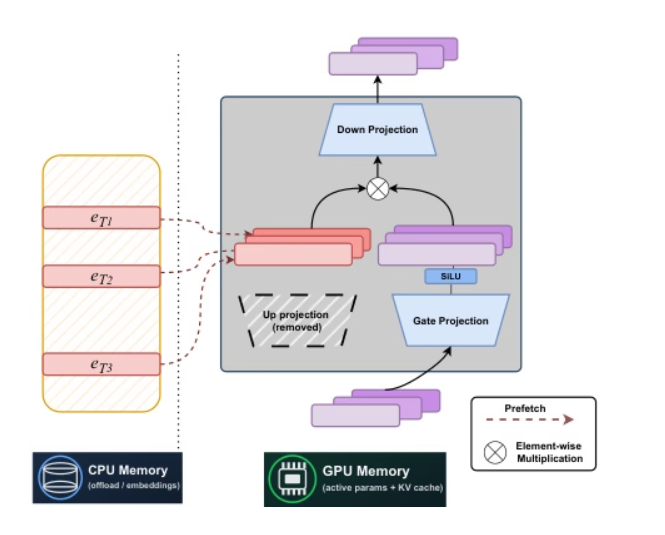
STEM 系统架构示例
数据集由多个来源组成:OLMo-MIX-1124(3.9T标记),为 DCLM 与 Dolma1.7 的混合;NEMOTRON-CC-MATH-v1(数学导向);以及NEMOTRON-PRETRAINING-CODE-v1(代码导向)。
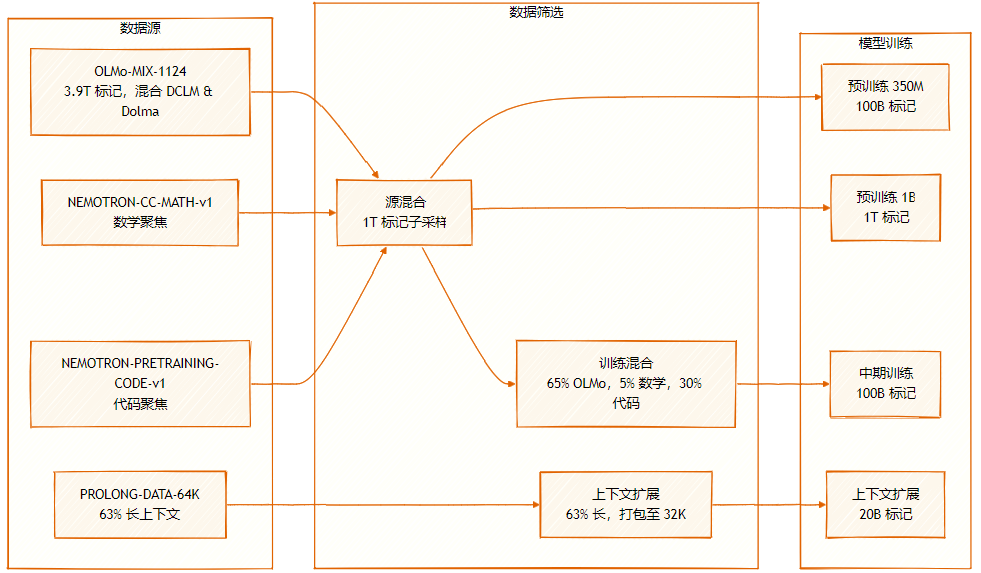
数据集
3
SeedFold: Scaling Biomolecular Structure Prediction
字节跳动 Seed 团队提出 SeedFold,一种可扩展的生物分子结构预测模型,通过扩大 Pairformer 的宽度提升模型容量,采用线性三角注意力机制降低计算复杂度,并利用包含 2650 万样本的蒸馏数据集,在 FoldBench 上达到最先进性能,且在蛋白质相关任务上超越 AlphaFold3。
论文及详细解读:https://go.hyper.ai/9zAID
新型线性三角注意力模块示例
SeedFold 的数据集包含 2650 万样本,通过从两个主要来源进行大规模数据蒸馏扩展:实验数据集(0.18M)和源自 AFDB 与 MGnify 的蒸馏数据集。
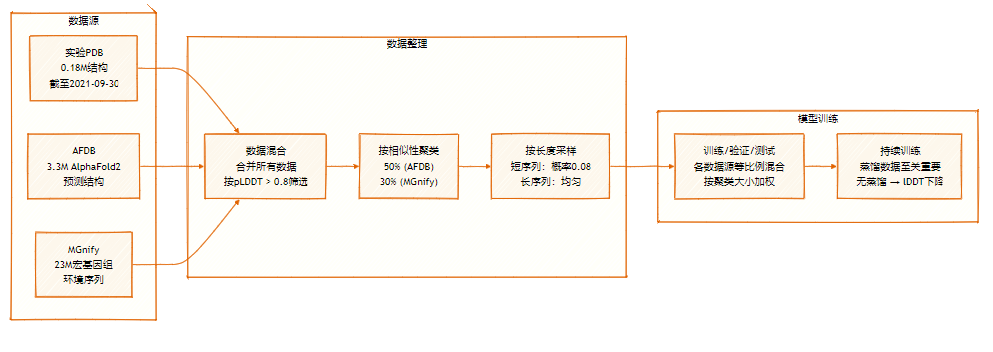
数据集
4
Are Transformers Effective for
Time Series Forecasting?
本文发现,尽管 Transformer 在时序预测领域迅速流行,其自注意力机制的排列不变性会损失关键时间信息。通过对比实验,简单的单层线性模型在多个真实数据集上显著超越了复杂的 Transformer 模型。这一发现挑战了现有研究方向,并呼吁重新评估 Transformer 在时序任务中的有效性。
论文及详细解读:https://go.hyper.ai/Hk05h
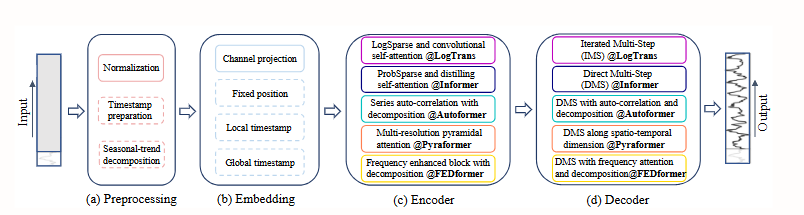
现有基于 Transformer 的时间序列预测方案的流程示例
相关 benchmarks 如下:
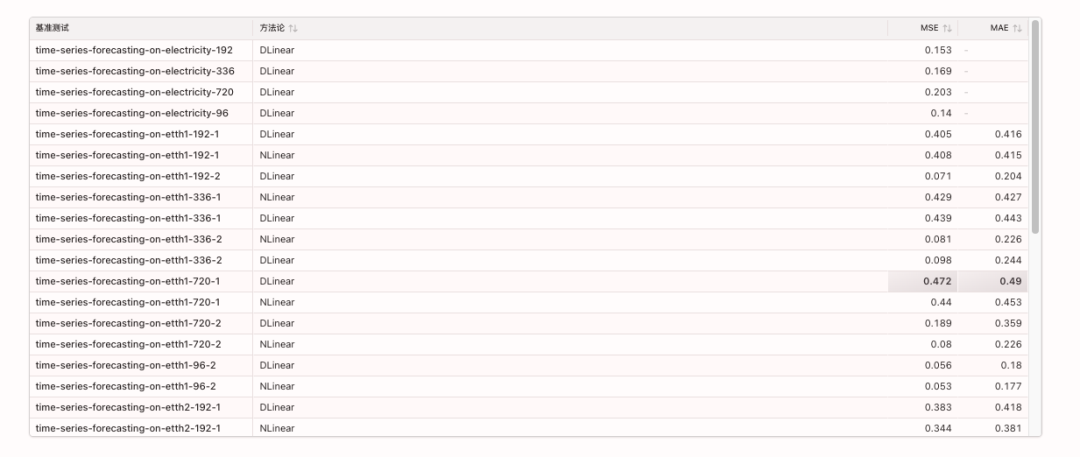
5
Reasoning Models Generate
Societies of Thought
谷歌、芝加哥大学与圣塔菲研究所的研究人员提出,像 DeepSeek-R1 和 QwQ-32B 这样的先进推理模型之所以表现卓越,并非仅仅因为更长的思维链,而是通过隐式模拟一种「思想社会」——即模型内部具有不同人格与专长的多样化视角之间类似多智能体的对话。通过机制可解释性与受控强化学习,他们证明了对话行为(如提问、冲突、调和)以及视角多样性与准确率之间存在因果关系,其中对「惊讶」的话语标记进行引导可使推理性能翻倍。这种思想的社会化组织使得对解空间的系统性探索成为可能,表明集体智能原则——多样性、辩论与角色协调——是有效人工推理的核心基础。
论文及详细解读:https://go.hyper.ai/0oXCC
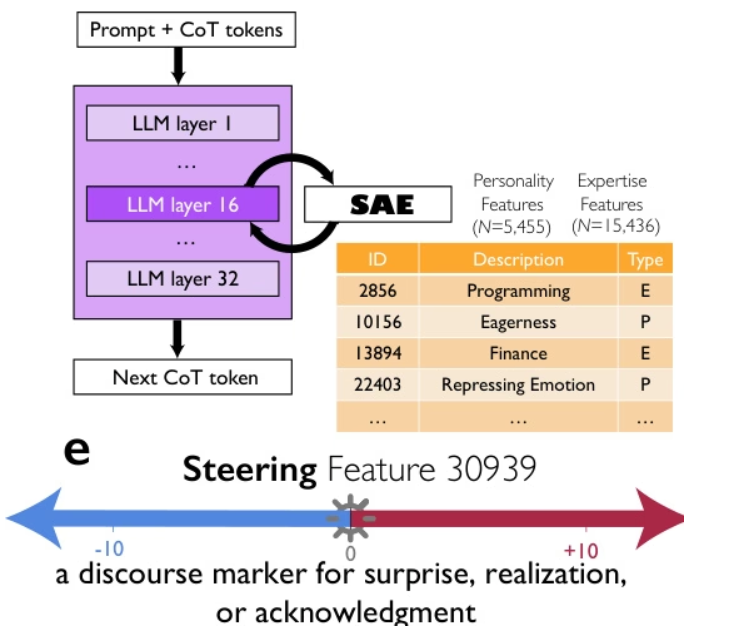
多维度框架示例
数据集包含 8,262 个来自多个领域的推理问题,涵盖符号逻辑、数学求解、科学推理、指令遵循及多智能体推理,支持多视角推理,用于训练与评估模型。
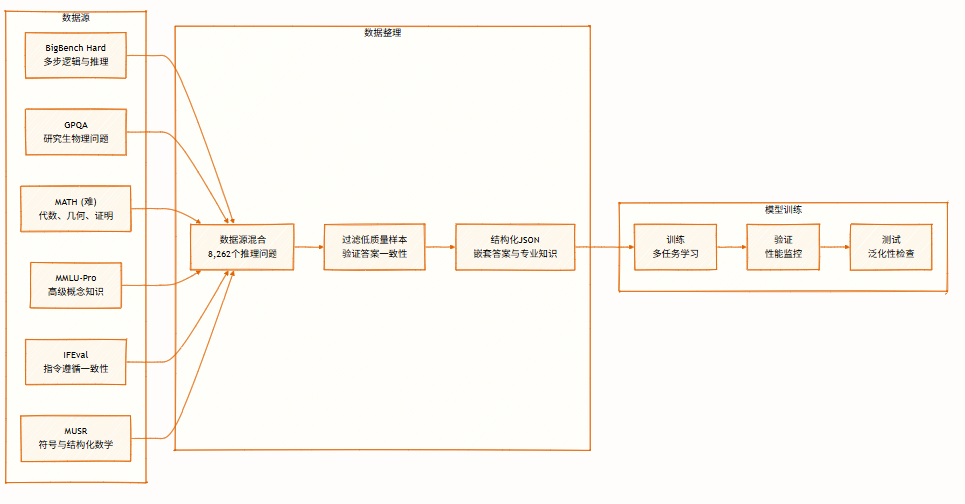
数据集
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)