具身智能资源汇总:机器人学习数据集,在线体验世界建模模型,英伟达/字节/小米等最新研究论文
本文系统整理了一批具身智能相关的高质量数据集、在线教程、论文,为进一步学习和研究提供参考,欢迎前往 hyper.ai 探索更多优质资源!
如果说过去十年人工智能的主战场在「看懂世界」和「生成内容」,那么下一阶段的核心问题正在转向一个更具挑战性的命题:AI 如何真正进入物理世界,并在其中行动、学习与进化。在与此相关的研究与讨论声中,具身智能一词频繁出现。
顾名思义,具身智能并非传统的机器人,而是强调 Agent 与环境交互在感知—决策—行动的闭环中形成智能。在这一视角下,智能不再只存在于模型参数或推理能力中,而是深度嵌入到传感器、执行器、环境反馈与长期学习之中。机器人、自动驾驶、Agent 乃至通用人工智能(AGI)的讨论,都被纳入这一框架。
正因如此,具身智能成为近两年全球科技巨头与顶级研究机构高度关注的方向。特斯拉 CEO 埃隆·马斯克多次强调,人形机器人 Optimus 的意义不亚于自动驾驶;英伟达创始人黄仁勋将 Physical AI 视为继生成式 AI 之后的下一波浪潮,并持续加码机器人仿真与训练平台;李飞飞、Yann LeCun 等围绕空间智能、世界模型等细分领域持续产出高质量的前沿分析与成果;OpenAI、Google DeepMind、Meta 也在基于多模态模型、强化学习等技术探索智能体在真实或近真实环境中的学习能力。
在此背景下,具身智能不再只是单一模型或算法的问题,而逐渐演化为一个由数据集、仿真环境、基准任务与系统性方法共同构成的研究生态。为了帮助更多读者快速理解这一领域的关键脉络,本文将系统整理并推荐一批具身智能相关的高质量数据集、在线教程、论文,为进一步学习和研究提供参考。
数据集推荐
1
BC-Z 机器人学习数据集
预估大小:32.28 GB
下载地址:https://go.hyper.ai/vkRel

这是一个由谷歌、 Everyday Robots 、加州大学伯克利分校和斯坦福大学共同开发的大规模机器人学习数据集,包含了超过 25,877 个不同的操作任务场景,涵盖了 100 种多样化的操作任务。这些任务通过专家级的远程操作和共享自主过程来收集,涉及 12 个机器人和 7 名不同的操作员,累计了 125 小时的机器人操作时间。数据集支持训练一个 7 自由度的多任务策略,该策略可以根据任务的语言描述或人类操作视频来调整,以执行特定的操作任务。
2
DexGraspVLA 机器人抓握数据集
预估大小:7.29 GB
下载地址:https://go.hyper.ai/G37zQ

该数据集由 Psi-Robot 团队创建,包含 51 个人类演示数据样本,用于了解数据和格式,以及运行代码体验训练过程。其研究背景源于灵巧抓取在杂乱场景下的高成功率需求,特别是在未见过的物体、光照及背景组合下实现超过 90% 的成功率,此框架采用预训练的视觉-语言模型作为高层任务规划器,并学习基于扩散的策略作为低层行动控制器,其创新之处在于利用基础模型实现强大的泛化能力,并使用基于扩散的模仿学习获取灵巧行动。
3
EgoThink 第一人称视角下
视觉问答基准数据集
预估大小:865.29 MB
下载地址:https://go.hyper.ai/5PsDP

该数据集是由清华大学提出的一个基于第一人称视角的视觉问答基准数据集,包含 700 张图像,涵盖了 6 个核心能力,细分为 12 个维度。其图像来源于 Ego4D 第一人称视频数据集的采样图片,为了确保数据的多样性,每个视频最多只采样 2 张图片。在数据集构建过程中,只选择了质量较高且能够清晰展现第一人称视角思维的图片。EgoThink 的应用领域广泛,特别是在评估和提升 VLMs 在第一人称视角任务中的性能,为未来的具身人工智能和机器人研究提供了宝贵的资源。
4
EQA 问答数据集
预估大小:839.6 KB
下载地址:https://go.hyper.ai/8Uv1o
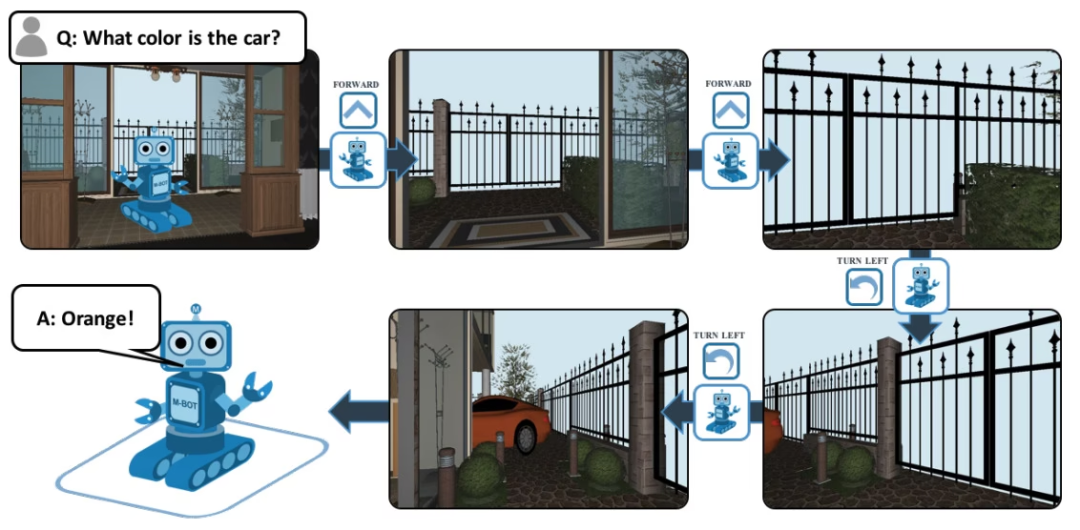
EQA 全称 Embodied Question Answering,是一个基于 House3D 的视觉问答数据集。在环境中任意位置的 agent 在得到一个问题后,能够自己在环境中寻找有用的信息并对该问题作出回答。比如:Q: 汽车是什么颜色的?为了回答这个问题,agent 必须首先通过智能导航来探索环境,从第一人称视角收集必要的视觉信息,然后回答问题:橙色。
5
OmniRetarget 全域机器人
运动重映射数据集
预估大小:349.61 MB
下载地址:https://go.hyper.ai/IloBI

这是由亚马逊联合麻省理工学院、加利福尼亚大学伯克利分校等机构发布的一个用于类人机器人全身运动重映射的高质量轨迹数据集,包含 G1 仿人机器人与物体及复杂地形交互时的运动轨迹,涵盖机器人携物运动、地形行走及物体 – 地形混合交互三类场景。由于许可限制,公开的数据集中不包含 LAFAN1 的重映射版本,分为三个子集,总计约 4 小时运动轨迹数据,具体构成如下:
* robot-object:机器人携带物体的运动轨迹,源自 OMOMO 3.0 数据;
* robot-terrain:机器人在复杂地形上的运动轨迹,由内部 MoCap 采集生成,时长约 0.5 小时;
* robot-object-terrain:同时涉及物体与地形交互的运动轨迹,时长约 0.5 小时。
此外,该数据集另含 models 目录,提供 URDF 、 SDF 与 OBJ 格式的可视化模型文件,用于展示而非训练。
查看更多高质量数据集:https://hyper.ai/datasets
教程推荐
具身智能(Embodied AI)的研究确实往往涉及多个模型和模块的组合,以实现对物理世界的感知、理解、规划和行动。其中便包含世界模型、推理模型,本文主要推荐以下两个最新开源的模型。
查看更多优质教程:https://hyper.ai/notebooks
1
HY-World 1.5:
交互式世界建模系统框架
HY-World 1.5(WorldPlay)是腾讯混元团队发布的首个具有长期几何一致性的开源实时交互世界模型。该模型通过流式视频扩散技术实现实时交互世界建模,解决了当前方法中速度与内存之间的权衡问题。
在线运行:https://go.hyper.ai/qsJVe
2
vLLM+Open WebUI 部署
Nemotron-3 Nano
Nemotron-3-Nano-30B-A3B-BF16 是由 NVIDIA 从零开始训练的一款大型语言模型(LLM),旨在作为一个同时适用于推理与非推理任务的统一模型,主要用于构建 AI 智能体系统、聊天机器人、RAG(检索增强生成)系统 以及其他各类 AI 应用。
在线运行:https://go.hyper.ai/6SK6n
论文推荐
1
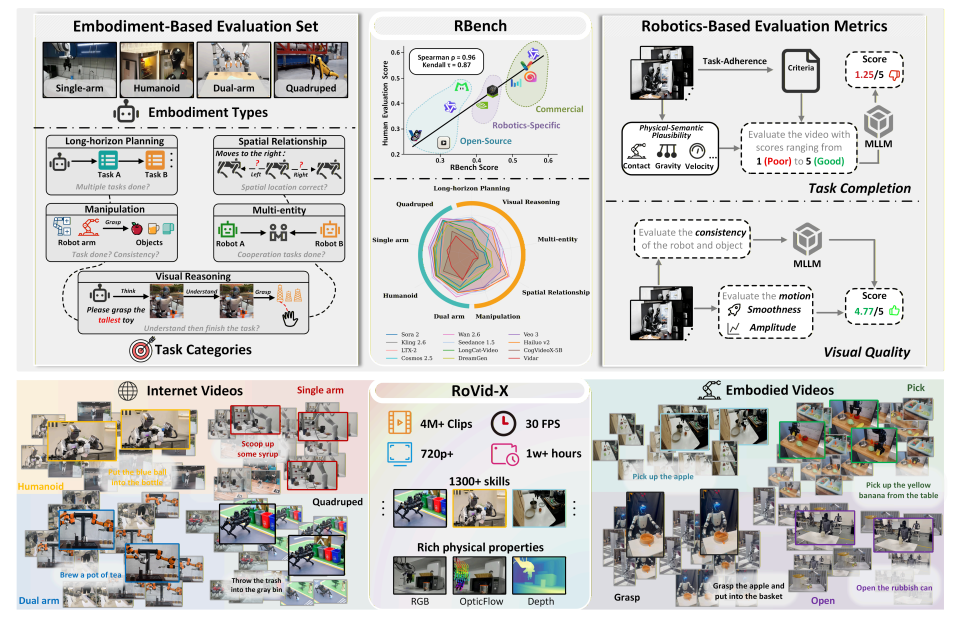
RBench
论文题目:Rethinking Video Generation Model for the Embodied World
研究团队:北京大学、字节跳动 Seed
查看论文:https://go.hyper.ai/k1oMT
研究简介:
该团队提出了一个全面的机器人视频生成评测基准 RBench,覆盖 5 类任务领域 和 4 种不同机器人形态,并通过一系列可复现的子指标,从任务层面的正确性和视觉保真度两个维度进行评估,具体包括结构一致性、物理合理性以及动作完整性等方面。对 25 个具有代表性的视频生成模型的评测结果显示,当前方法在生成符合物理真实感的机器人行为方面仍存在显著不足。此外,RBench 与人工评估之间的 Spearman 相关系数达到 0.96,验证了该基准在衡量模型质量方面的有效性。
此外,该研究还构建了 RoVid-X——目前规模最大的开源机器人视频生成数据集,包含 400 万条标注视频片段,覆盖数千种任务,并辅以全面的物理属性标注。
2
Being-H0.5
论文题目:Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
研究团队:BeingBeyond
查看论文:https://go.hyper.ai/pW24B
研究简介:
该团队提出了一个基础级的视觉-语言-动作(Vision-Language-Action,VLA)模型 Being-H0.5,旨在实现跨多种机器人平台的强泛化具身能力。现有的 VLA 模型往往受限于机器人形态差异大、可用数据稀缺等问题。针对这一挑战,其提出了一种以人为中心的学习范式,将人类交互轨迹视为物理交互领域的通用「母语」。
同时,该团队还发布了 UniHand-2.0,这是目前规模最大的具身预训练方案之一,涵盖 30 种不同机器人形态、超过 35,000 小时的多模态数据。在方法层面,其提出了一个统一动作空间(Unified Action Space),将不同机器人的异构控制方式映射到语义对齐的动作槽位中,使低资源机器人能够从人类数据以及高资源平台中快速迁移和习得技能。

3
Fast-ThinkAct
论文题目:Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
研究团队:英伟达
查看论文:https://go.hyper.ai/q1h7j
研究简介:
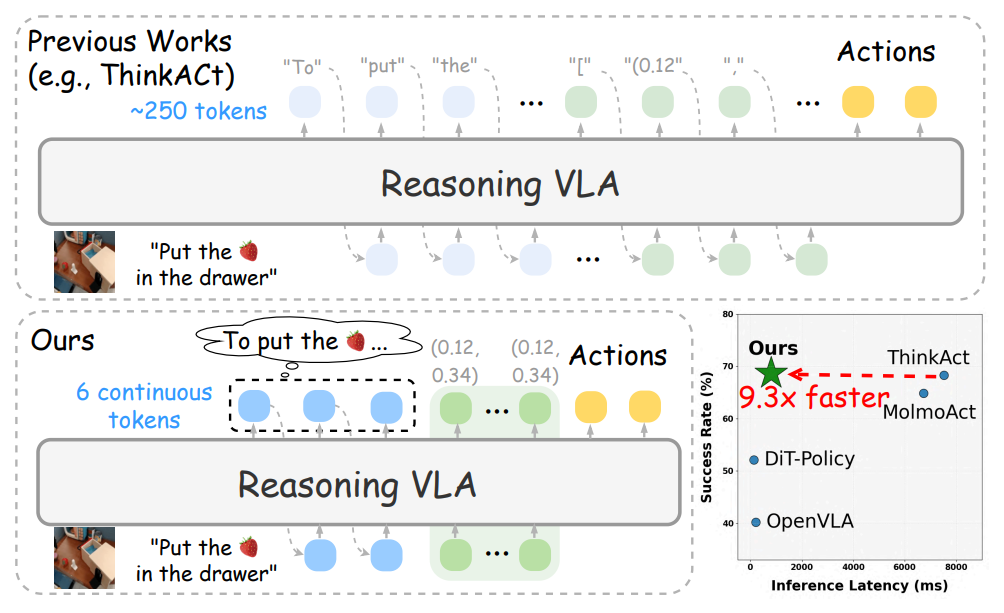
该团队提出了一种高效的推理框架 Fast-ThinkAct,通过可语言化的潜在推理机制,在保证性能的同时实现更加紧凑的规划过程。Fast-ThinkAct 通过从教师模型中蒸馏潜在 CoT,学习高效推理能力,并在偏好引导目标函数的驱动下,对操作轨迹进行对齐,从而将语言层面的规划能力与视觉层面的规划能力共同迁移到具身控制中。
大量覆盖多种具身操作与推理任务的实验结果表明,Fast-ThinkAct 在保持长时序规划能力、少样本适应能力以及失败恢复能力的同时,相较于当前最先进的推理型 VLA 模型,推理延迟最高可降低 89.3%,并取得了显著的性能表现。
4
JudgeRLVR
论文题目:JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
研究团队:北京大学、小米
查看论文:https://go.hyper.ai/2yCxp
研究简介:
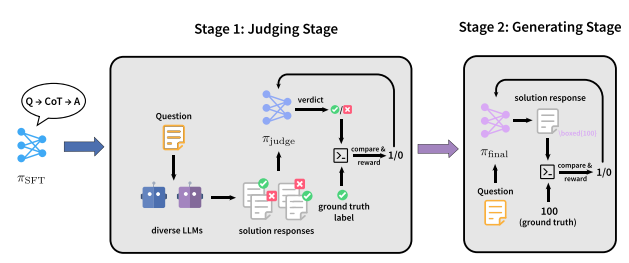
该团队提出了一种「先判别、再生成」的两阶段训练范式 JudgeRLVR,在第一阶段,团队训练模型对具有可验证答案的解题响应进行判别与评估;在第二阶段,以该判别模型为初始化,使用标准的生成式 RLVR 对同一模型进行微调。
与在相同数学领域训练数据上使用的 Vanilla RLVR 相比,JudgeRLVR 在 Qwen3-30B-A3B 上实现了更优的质量–效率权衡:在域内数学任务上,平均准确率提升约 3.7 个百分点,同时平均生成长度减少 42%;在域外基准测试中,平均准确率提升约 4.5 个百分点,显示出更强的泛化能力。
5
ACoT-VLA
论文题目:ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
研究团队:北京航空航天大学、AgiBot
查看论文:https://go.hyper.ai/2jMmY
研究简介:
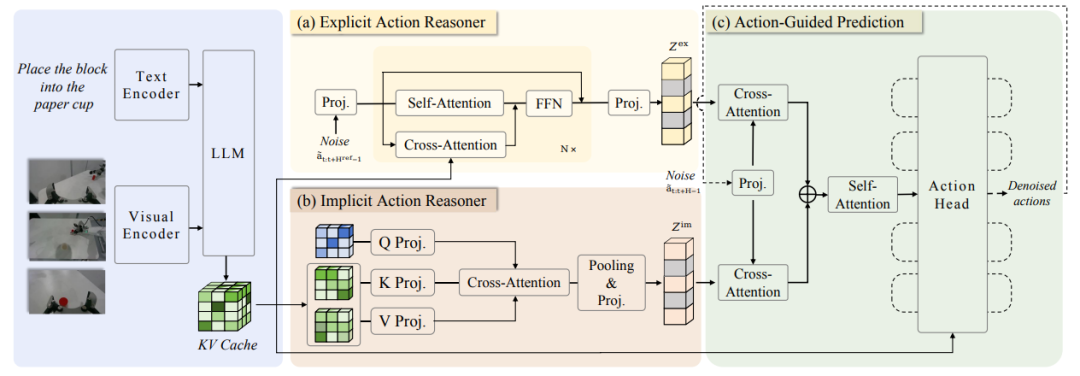
该团队首先提出了 Action Chain-of-Thought(ACoT,动作思维链),将推理过程本身建模为一系列结构化的粗粒度动作意图,用于引导最终的策略生成,随后进一步提出 ACoT-VLA,一种将 ACoT 范式具体化的新型模型架构。
在具体设计上,其引入了两个互补的核心组件:显式动作推理器(Explicit Action Reasoner,EAR) 与 隐式动作推理器(Implicit Action Reasoner,IAR)。其中,EAR 以显式的动作级推理步骤形式,提出粗粒度的参考轨迹;而 IAR 则从多模态输入的内部表示中提取潜在的动作先验。二者共同构成 ACoT,并作为条件输入作用于下游动作头,从而实现具备落地约束的策略学习。
在真实世界与仿真环境中的大量实验结果表明,该方法展现出显著优势,在 LIBERO、LIBEROPlus 和 VLABench 基准上分别取得了 98.5%、84.1% 和 47.4% 的成绩。
查看最新论文:https://hyper.ai/papers

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)