AI 手势识别系统:踩坑与实现全记录 (PyTorch + MediaPipe)
第一步:环境配置
MediaPipe 最新版与 Protobuf 新版在 Windows + Python 3.9 环境下存在极大的兼容性问题。经过反复测试,以下是“黄金兼容组合”:
-
Python: 3.9
-
Torch: 2.4.1+cu121 (根据显卡适配)
-
MediaPipe:
0.10.9(必须锁定此版本) -
Protobuf:
3.20.3(必须降级到 3.20.x)
安装 PyTorch (GPU版)
针对 NVIDIA RTX 30/40 系列显卡,推荐使用 CUDA 12.1 版本的 PyTorch,性能释放最充分。
# 安装 Torch 2.4.1 + CUDA 12.1
python -m pip install torch==2.4.1+cu121 torchvision==0.19.1+cu121 torchaudio==2.4.1+cu121 --index-url https://download.pytorch.org/whl/cu121注:如果你没有 NVIDIA 显卡,可以直接运行
pip install torch torchvision torchaudio 安装 CPU 版本,但训练速度会慢很多。
安装 MediaPipe 黄金组合
# 锁定 MediaPipe 和 Protobuf 的版本,确保兼容性
python -m pip install mediapipe==0.10.9 protobuf==3.20.3安装其他工具库
安装 OpenCV(用于摄像头图像处理)和其他必要的数学计算库。
# 安装 OpenCV 和 NumPy
python -m pip install opencv-python opencv-contrib-python numpyMediaPipe 0.10.9
-
它的作用: Google 开发的超强视觉库。
-
神经网络看不懂原始的图片(一堆像素点)。
-
MediaPipe 负责看图片,精准地把手上的 21 个关节坐标 提取出来。它不负责判断是“石头”还是“剪刀”,它只负责告诉你:“食指指尖在坐标 (0.5, 0.8) 的位置”。
-
-
为什么要锁定 0.10.9?
-
MediaPipe 的更新非常激进。最新版有时会修改函数名,或者引入不兼容的依赖。
-
0.10.9是在 Python 3.9 环境下经过大量开发者验证的**“无 Bug 稳定版”**。
-
(我的显卡为4060)
Protobuf 3.20.3
-
它的作用: 全称 Protocol Buffers,也是 Google 开发的一种数据存储格式。
-
它在后台工作: MediaPipe 极其依赖它。MediaPipe 里的模型结构、数据传输,底层都是用 Protobuf 格式打包的。
-
-
为什么要降级到 3.20.x? (这是最关键的知识点)
-
版本大断层:Protobuf 从 3.x 升级到 4.x (甚至 5.x) 时,修改了底层的 Python 接口生成逻辑。
-
冲突爆发:MediaPipe 0.10.9 是基于 Protobuf 3.x 的逻辑编写的。
-
如果你的环境乱了,请按以下顺序“重置”:
# 1. 卸载冲突包
pip uninstall -y mediapipe protobuf
# 2. 安装
pip install mediapipe==0.10.9 protobuf==3.20.3第二步:无干扰数据采集 (Auto Mode)
采用 “倒计时自动录制” 模式。
核心逻辑
-
程序自动倒计时 5 秒。
-
提示当前需要做的手势(如“数字 1”)。
-
自动连续采集 300 帧骨架坐标(x, y)。
-
存入 CSV 文件。
数据格式 (number_gesture_data.csv):
-
label: 0~9 (代表数字) -
x0, y0 ... x20, y20: 21个关键点的归一化坐标。
第三步:搭建神经网络 (SimpleGestureNet)
数据量不大,不需要复杂的卷积网络(CNN)。直接使用全连接网络 (FCN/MLP) 处理坐标数据即可,速度极快。
模型结构 (PyTorch)
-
输入层: 42 (21个点 × 2个坐标 x,y)
-
隐藏层1: 64 (ReLU激活 + Dropout防止过拟合)
-
隐藏层2: 32 (ReLU激活)
-
输出层: N (取决于你要识别几种手势,例如识别 0-5 则为 6)
训练效果
-
优化器: Adam (lr=0.001)
-
损失函数: CrossEntropyLoss
-
耗时: 1000个 Epoch 仅需几秒钟 (GPU RTX 4060)。
第四步:实时推理与展示
训练好模型保存为 .pth 文件后,在主程序中加载。
关键技巧:
-
OpenCV DSHOW 模式:
cv2.VideoCapture(0, cv2.CAP_DSHOW),在 Windows 上开启摄像头速度更快。 -
镜像处理:
cv2.flip(frame, 1),让画面符合人类照镜子的直觉。 -
置信度微调:设置
min_detection_confidence=0.7,减少误识别。
总体代码:
main.py
import cv2
import mediapipe as mp
import torch
import torch.nn as nn
import numpy as np
import os
import json
from collections import deque, Counter
# ==========================================
# 1. 定义模型(必须和 train.py 一致)
# ==========================================
class SimpleGestureNet(nn.Module):
def __init__(self, input_size=63, num_classes=7):
super(SimpleGestureNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, num_classes)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
# ==========================================
# 2. 和训练时一致的归一化函数
# 输入: 63维 [x0,y0,z0,...,x20,y20,z20]
# ==========================================
def normalize_landmarks(features_63):
arr = np.array(features_63, dtype=np.float32).reshape(21, 3)
# 以 wrist(0号点) 为原点
wrist = arr[0].copy()
arr = arr - wrist
# 按最大欧氏距离缩放
dist = np.linalg.norm(arr, axis=1)
max_dist = np.max(dist)
if max_dist > 1e-6:
arr = arr / max_dist
return arr.reshape(-1)
# ==========================================
# 3. 配置与加载模型
# ==========================================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"🚀 使用设备: {device}")
model_path = "my_hand_model.pth"
label_map_path = "label_map.json"
if not os.path.exists(model_path):
print(f"❌ 找不到模型文件: {model_path}")
print("请先运行 train.py 训练模型。")
exit()
try:
checkpoint = torch.load(model_path, map_location=device)
except Exception as e:
print(f"❌ 模型加载失败: {e}")
exit()
input_size = checkpoint["input_size"]
num_classes = checkpoint["num_classes"]
label_map = checkpoint["label_map"]
# 某些情况下 json / torch 保存后 key 可能变成字符串,这里统一转 int
label_map = {int(k): v for k, v in label_map.items()}
model = SimpleGestureNet(input_size=input_size, num_classes=num_classes).to(device)
model.load_state_dict(checkpoint["model_state_dict"])
model.eval()
print(f"✅ 成功加载模型: {model_path}")
print("📋 标签映射:")
for k in sorted(label_map.keys()):
print(f" {k} -> {label_map[k]}")
# 显示名映射
command_text_map = {
"photo_v": "Take Photo",
"video_o": "Start Recording",
"stop_fist": "Stop Recording",
"move_up": "Moving Up",
"move_down": "Moving Down",
"move_left": "Moving Left",
"move_right": "Moving Right",
}
# ==========================================
# 4. 初始化 MediaPipe
# ==========================================
mp_hands = mp.solutions.hands
mp_draw = mp.solutions.drawing_utils
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.6
)
# ==========================================
# 5. 摄像头
# ==========================================
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
print("❌ 摄像头打开失败。")
exit()
# 为了减少抖动,做一个滑动窗口投票
history_size = 7
pred_history = deque(maxlen=history_size)
print("\n✨ 系统准备就绪,请对着摄像头做手势。")
print("按 Q 键退出。")
while True:
ret, frame = cap.read()
if not ret:
print("❌ 摄像头读取失败。")
break
frame = cv2.flip(frame, 1)
img_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(img_rgb)
result_text = "No Hand"
conf_text = ""
raw_label_text = ""
# 顶部说明
cv2.putText(frame, "Gesture Control Demo", (20, 40),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 255, 255), 2)
cv2.putText(frame, "PHOTO: V | VIDEO: O | STOP: FIST | MOVE: UP/DOWN/LEFT/RIGHT", (20, 75),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (200, 200, 200), 2)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_draw.draw_landmarks(
frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS
)
# 提取 63 维特征
landmark_list = []
for lm in hand_landmarks.landmark:
landmark_list.extend([lm.x, lm.y, lm.z])
# 归一化(必须和训练一致)
norm_landmarks = normalize_landmarks(landmark_list)
# 转 Tensor
input_tensor = torch.tensor([norm_landmarks], dtype=torch.float32).to(device)
# 模型预测
with torch.no_grad():
output = model(input_tensor)
probs = torch.softmax(output, dim=1)
pred_class = torch.argmax(probs, dim=1).item()
confidence = probs[0, pred_class].item()
# 滑动窗口投票
pred_history.append(pred_class)
voted_class = Counter(pred_history).most_common(1)[0][0]
raw_label = label_map.get(voted_class, f"class_{voted_class}")
result_text = command_text_map.get(raw_label, raw_label)
raw_label_text = raw_label
conf_text = f"Confidence: {confidence:.2f}"
break # 只处理一只手
else:
pred_history.clear()
# 显示识别结果
cv2.putText(frame, f"Result: {result_text}", (20, 130),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 0), 3)
if raw_label_text:
cv2.putText(frame, f"Class: {raw_label_text}", (20, 170),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
if conf_text:
cv2.putText(frame, conf_text, (20, 205),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
# 底部提示
cv2.putText(frame, "Press Q to quit", (20, 680),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (180, 180, 180), 2)
cv2.imshow("Final Hand Gesture Recognition", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
hands.close()实际上代码并不复杂,但是环境配置需要花点时间
train.py
训练的代码:
import os
import csv
import json
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader, random_split
# ==========================================
# 1. 配置
# ==========================================
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
data_file = os.path.join(desktop_path, "custom_gesture_data.csv")
save_model_path = "my_hand_model.pth"
save_label_map_path = "label_map.json"
BATCH_SIZE = 32
EPOCHS = 300
LEARNING_RATE = 0.001
VAL_RATIO = 0.2
RANDOM_SEED = 42
print(f"📂 正在读取数据: {data_file}")
# 固定随机种子
torch.manual_seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
# ==========================================
# 2. 读取 CSV
# CSV 格式:
# label_id,label_name,handedness,x0,y0,z0,...,x20,y20,z20
# ==========================================
if not os.path.exists(data_file):
print("❌ 数据文件不存在,请先完成采集。")
exit()
x_list = []
y_list = []
label_map = {} # {0: "photo_v", 1: "video_o", ...}
try:
with open(data_file, "r", encoding="utf-8-sig") as f:
reader = csv.DictReader(f)
for row in reader:
label_id = int(row["label_id"])
label_name = row["label_name"].strip()
label_map[label_id] = label_name
features = []
for i in range(21):
features.append(float(row[f"x{i}"]))
features.append(float(row[f"y{i}"]))
features.append(float(row[f"z{i}"]))
x_list.append(features)
y_list.append(label_id)
except Exception as e:
print(f"❌ 读取 CSV 失败: {e}")
exit()
if len(x_list) == 0:
print("❌ 数据文件为空,请重新采集。")
exit()
X = np.array(x_list, dtype=np.float32)
Y = np.array(y_list, dtype=np.int64)
num_samples = len(X)
num_classes = len(sorted(label_map.keys()))
input_size = X.shape[1]
print(f"📊 数据加载成功!共 {num_samples} 条样本")
print(f"📐 输入维度: {input_size}")
print(f"🏷️ 类别数: {num_classes}")
print("📋 类别映射:")
for k in sorted(label_map.keys()):
print(f" {k} -> {label_map[k]}")
# ==========================================
# 3. 特征归一化
# 思路:
# 1) 以 wrist(0号点) 为原点
# 2) 再按整只手的最大距离做缩放
# 这样能减弱“手离摄像头远近不同”的影响
# ==========================================
def normalize_landmarks(features_63):
arr = np.array(features_63, dtype=np.float32).reshape(21, 3)
# 以手腕为中心
wrist = arr[0].copy()
arr = arr - wrist
# 按最大欧氏距离缩放
dist = np.linalg.norm(arr, axis=1)
max_dist = np.max(dist)
if max_dist > 1e-6:
arr = arr / max_dist
return arr.reshape(-1)
X_norm = np.array([normalize_landmarks(sample) for sample in X], dtype=np.float32)
# 转换为张量
X_tensor = torch.tensor(X_norm, dtype=torch.float32)
Y_tensor = torch.tensor(Y, dtype=torch.long)
# ==========================================
# 4. 划分训练集 / 验证集
# ==========================================
dataset = TensorDataset(X_tensor, Y_tensor)
val_size = int(len(dataset) * VAL_RATIO)
train_size = len(dataset) - val_size
train_dataset, val_dataset = random_split(
dataset,
[train_size, val_size],
generator=torch.Generator().manual_seed(RANDOM_SEED)
)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
print(f"🧪 训练集: {train_size}")
print(f"🧪 验证集: {val_size}")
# ==========================================
# 5. 定义模型
# ==========================================
class SimpleGestureNet(nn.Module):
def __init__(self, input_size=63, num_classes=7):
super(SimpleGestureNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, num_classes)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleGestureNet(input_size=input_size, num_classes=num_classes).to(device)
print(f"💻 训练设备: {device}")
# ==========================================
# 6. 训练配置
# ==========================================
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# ==========================================
# 7. 训练
# ==========================================
def evaluate(model, loader, criterion, device):
model.eval()
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item() * inputs.size(0)
preds = torch.argmax(outputs, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
avg_loss = total_loss / total
acc = correct / total
return avg_loss, acc
print("\n🚀 开始训练...")
best_val_acc = 0.0
for epoch in range(EPOCHS):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
preds = torch.argmax(outputs, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
train_loss = running_loss / total
train_acc = correct / total
val_loss, val_acc = evaluate(model, val_loader, criterion, device)
if val_acc > best_val_acc:
best_val_acc = val_acc
# 保存最佳模型
torch.save({
"model_state_dict": model.state_dict(),
"input_size": input_size,
"num_classes": num_classes,
"label_map": label_map
}, save_model_path)
with open(save_label_map_path, "w", encoding="utf-8") as f:
json.dump(label_map, f, ensure_ascii=False, indent=2)
if (epoch + 1) % 20 == 0 or epoch == 0:
print(
f"Epoch [{epoch+1:03d}/{EPOCHS}] | "
f"Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.4f} | "
f"Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.4f}"
)
print("\n✅ 训练完成!")
print(f"🏆 最佳验证集准确率: {best_val_acc:.4f}")
print(f"💾 最佳模型已保存为: {save_model_path}")
print(f"🗂️ 标签映射已保存为: {save_label_map_path}")
print("👉 下一步需要把 main.py 也改成读取这个新模型格式。")collect代码:
import cv2
import mediapipe as mp
import csv
import os
import time
# ==========================================
# 1. 配置
# ==========================================
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
file_name = os.path.join(desktop_path, "custom_gesture_data.csv")
# 手势类别: (类别ID, 类别名, 屏幕提示, 采集帧数)
TARGET_GESTURES = [
(0, "photo_v", "PHOTO: V", 300), # 拍照:比V
(1, "video_o", "VIDEO: O", 300), # 录像:比O
(2, "stop_fist", "STOP: FIST", 300), # 停止录像:握拳
(3, "move_up", "MOVE: UP", 400), # 向上
(4, "move_down", "MOVE: DOWN", 400), # 向下
(5, "move_left", "MOVE: LEFT", 400), # 向左
(6, "move_right", "MOVE: RIGHT", 400), # 向右
]
PREPARE_SECONDS = 5 # 每个动作开始前倒计时秒数
print(f"📂 数据将保存到: {file_name}")
# ==========================================
# 2. 初始化 CSV
# ==========================================
if not os.path.exists(file_name):
with open(file_name, mode="w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
header = ["label_id", "label_name", "handedness"]
for i in range(21):
header.extend([f"x{i}", f"y{i}", f"z{i}"])
writer.writerow(header)
# ==========================================
# 3. 初始化 MediaPipe
# ==========================================
mp_hands = mp.solutions.hands
mp_draw = mp.solutions.drawing_utils
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.6,
min_tracking_confidence=0.6
)
# Windows 下 DSHOW 一般更稳定
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
print("❌ 摄像头打开失败,请检查设备。")
exit()
cv2.namedWindow("Gesture Collection", cv2.WINDOW_NORMAL)
cv2.resizeWindow("Gesture Collection", 1100, 750)
print("=============================================")
print(" ⏱️ 自动手势采集启动")
print(" Q / ESC 可提前退出")
print("=============================================")
# ==========================================
# 4. 工具函数
# ==========================================
def draw_top_info(frame, lines, start_y=35, color=(255, 255, 255), scale=0.75, thickness=2):
y = start_y
for line in lines:
cv2.putText(
frame, line, (20, y),
cv2.FONT_HERSHEY_SIMPLEX, scale, color, thickness
)
y += 32
def save_landmarks_to_csv(csv_path, label_id, label_name, handedness, hand_landmarks):
row = [label_id, label_name, handedness]
for lm in hand_landmarks.landmark:
row.extend([lm.x, lm.y, lm.z])
with open(csv_path, mode="a", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(row)
# ==========================================
# 5. 开始采集
# ==========================================
user_abort = False
for label_id, label_name, show_text, frames_per_gesture in TARGET_GESTURES:
# ---------- 准备阶段 ----------
start_time = time.time()
while True:
ret, frame = cap.read()
if not ret:
print("❌ 读取摄像头画面失败。")
user_abort = True
break
frame = cv2.flip(frame, 1)
elapsed = time.time() - start_time
countdown = PREPARE_SECONDS - int(elapsed)
countdown = max(0, countdown)
draw_top_info(frame, [
"Gesture Mapping:",
"PHOTO -> V",
"VIDEO -> O",
"STOP -> FIST",
"MOVE -> UP / DOWN / LEFT / RIGHT"
], start_y=35, color=(220, 220, 220), scale=0.65, thickness=2)
cv2.putText(
frame, f"NEXT: {show_text}", (90, 260),
cv2.FONT_HERSHEY_SIMPLEX, 1.8, (0, 255, 255), 4
)
cv2.putText(
frame, f"Start in: {countdown}", (220, 360),
cv2.FONT_HERSHEY_SIMPLEX, 2.2, (0, 0, 255), 5
)
cv2.putText(
frame, "Please keep one clear hand in the center", (150, 430),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (255, 255, 255), 2
)
cv2.imshow("Gesture Collection", frame)
key = cv2.waitKey(1) & 0xFF
if key == 27 or key == ord('q'):
user_abort = True
break
if countdown <= 0:
break
if user_abort:
break
# ---------- 录制阶段 ----------
print(f"🔴 开始录制: {label_name}")
count = 0
while count < frames_per_gesture:
ret, frame = cap.read()
if not ret:
print("❌ 读取摄像头画面失败。")
user_abort = True
break
frame = cv2.flip(frame, 1)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb)
draw_top_info(frame, [
f"Recording: {show_text}",
f"Progress : {count}/{frames_per_gesture}",
"Press Q or ESC to quit"
], start_y=40, color=(0, 255, 0), scale=0.9, thickness=2)
detected = False
if results.multi_hand_landmarks:
handedness = "Unknown"
if results.multi_handedness:
handedness = results.multi_handedness[0].classification[0].label
for hand_landmarks in results.multi_hand_landmarks:
mp_draw.draw_landmarks(
frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS
)
save_landmarks_to_csv(
file_name,
label_id,
label_name,
handedness,
hand_landmarks
)
detected = True
count += 1
break # 只存一只手
status_text = "Hand Detected" if detected else "No Hand Detected"
status_color = (0, 255, 0) if detected else (0, 0, 255)
cv2.putText(
frame, status_text, (20, 680),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, status_color, 2
)
cv2.imshow("Gesture Collection", frame)
key = cv2.waitKey(1) & 0xFF
if key == 27 or key == ord('q'):
user_abort = True
break
if user_abort:
break
print(f"✅ 录制完成: {label_name}")
# ==========================================
# 6. 释放资源
# ==========================================
cap.release()
cv2.destroyAllWindows()
hands.close()
if user_abort:
print("⚠️ 采集已中断。")
else:
print("🎉 所有手势数据采集完毕!")代码结果:
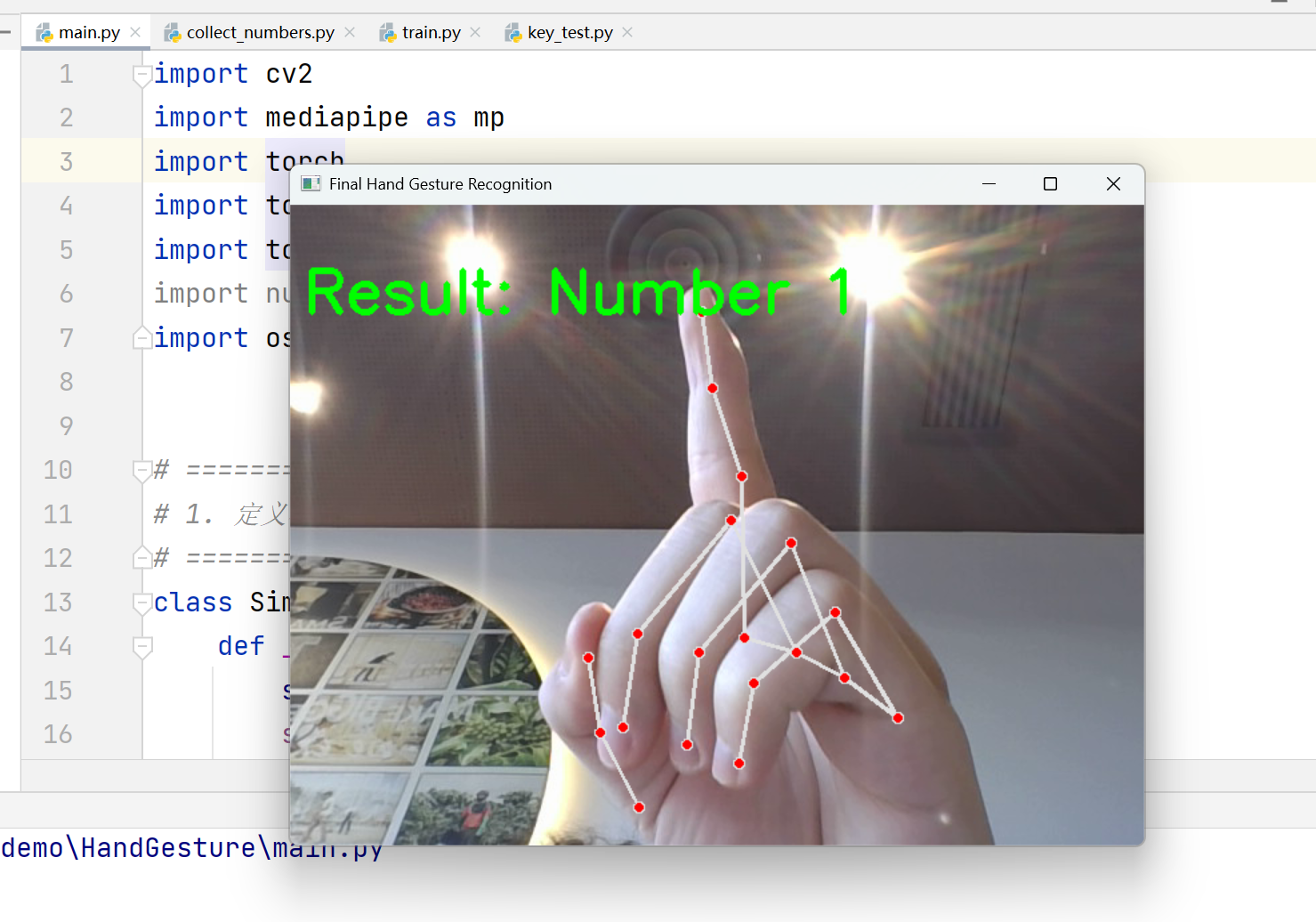
HandGestsure

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)