英伟达三大AI法宝:CUDA、NVLink、InfiniBand——构筑AI时代的算力基石
英伟达凭借CUDA、NVLink和InfiniBand三大核心技术构筑AI算力基石。CUDA突破GPU图形专用限制,建立庞大开发者生态;NVLink以900GB/s带宽实现多GPU高速互联,支持大模型训练;InfiniBand提供超低延迟网络连接,实现万卡集群高效协同。这三大技术形成从芯片到数据中心的完整AI加速闭环,使英伟达从GPU厂商转型为AI基础设施核心提供商。它们共同定义了AI时代的计算范
英伟达三大AI法宝:CUDA、NVLink、InfiniBand——构筑AI时代的算力基石
在人工智能迅猛发展的今天,英伟达(NVIDIA)已从一家图形处理器(GPU)厂商跃升为全球AI基础设施的核心引擎。其成功并非偶然,而是源于一套高度协同、层层递进的技术生态体系。其中,CUDA、NVLink 和 InfiniBand 被誉为英伟达驱动AI革命的“三大法宝”。它们分别作用于编程层、芯片互连层和系统互连层,共同构建了一个从单卡到万卡规模的高效AI计算闭环。
一、CUDA:让GPU成为通用计算的“操作系统”
是什么?
CUDA(Compute Unified Device Architecture)是英伟达于2006年推出的并行计算平台与编程模型。它允许开发者使用C/C++、Python等高级语言直接调用GPU的数千个核心进行通用计算(GPGPU)。
为何是“法宝”?
- 打破图形专用壁垒:在CUDA之前,GPU仅用于图形渲染;CUDA首次将GPU变为可编程的通用加速器。
- 生态护城河:十余年积累,形成数百万开发者、数十万应用的庞大生态。PyTorch、TensorFlow等主流AI框架底层均依赖CUDA。
- 性能与易用性平衡:提供cuBLAS、cuDNN、NCCL等高度优化的库,让AI训练/推理效率倍增。
💡 没有CUDA,就没有现代深度学习的爆发。它让GPU从“显卡”变成了“AI芯片”。
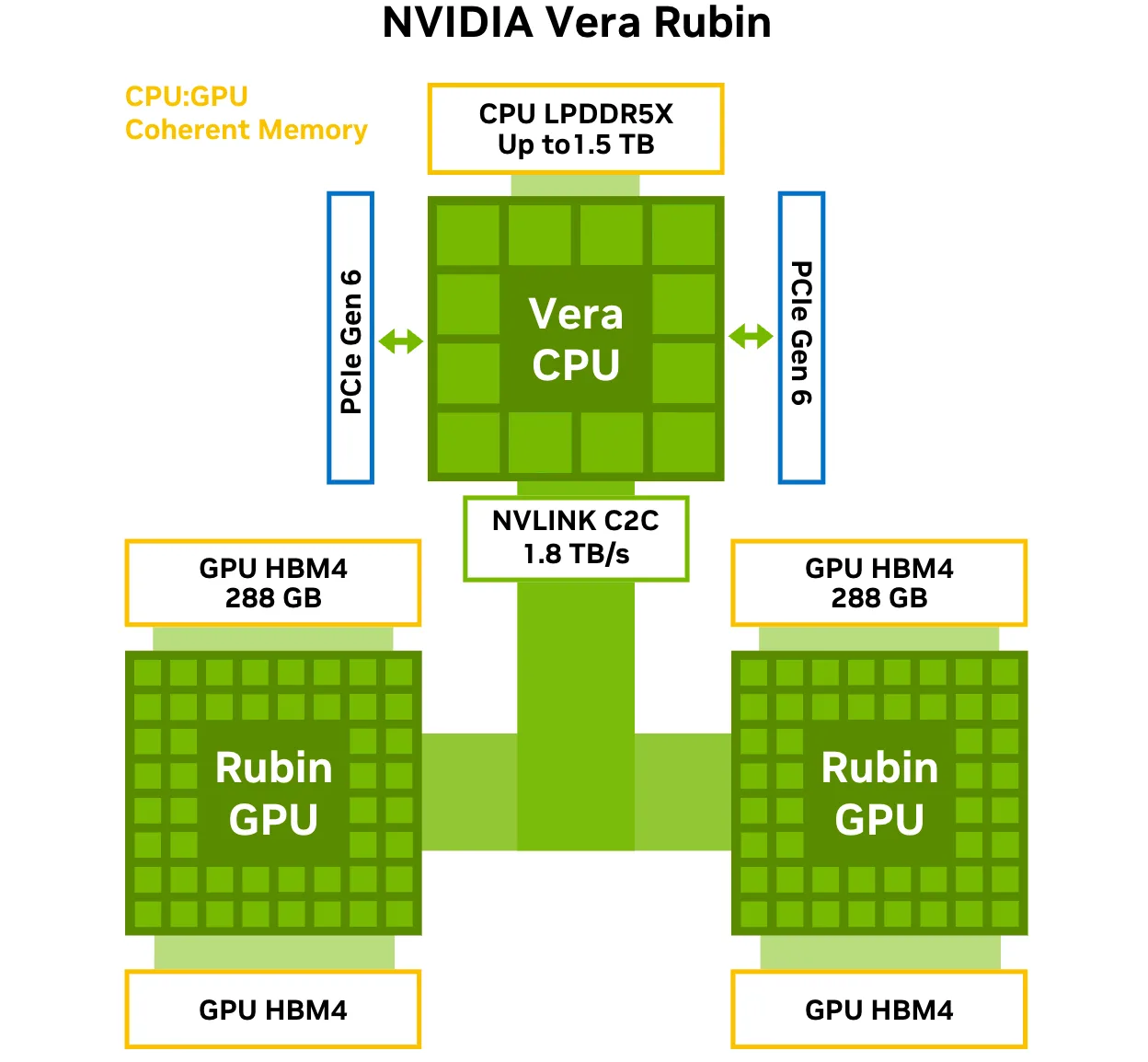
二、NVLink:打通多GPU之间的“高速公路”
是什么?
NVLink是英伟达开发的高速GPU-to-GPU互连技术,用于替代传统PCIe总线在多GPU通信中的瓶颈。
关键优势:
| 指标 | PCIe 4.0 x16 | NVLink 4.0(H100) |
|---|---|---|
| 带宽(双向) | ~64 GB/s | 900 GB/s |
| 延迟 | 较高 | 极低 |
| 拓扑灵活性 | 点对点受限 | 支持全互联(如NVSwitch) |
在AI中的价值:
- 大模型训练必需:千亿参数模型需跨多GPU共享梯度与激活值,NVLink极大减少通信等待时间。
- 显存池化:通过NVLink + NVSwitch,8颗H100 GPU可组成640GB统一显存空间,突破单卡显存限制。
- 提升MFU(Model FLOPs Utilization):减少通信空闲,让GPU算力持续满载。
🚀 NVLink让多GPU不再是“各自为战”,而是一个协同作战的超级计算单元。
三、InfiniBand:连接万卡集群的“神经中枢”
是什么?
InfiniBand(IB)是一种高性能、低延迟的网络互连标准。英伟达在2019年收购Mellanox后,全面掌控了InfiniBand技术栈,并将其深度集成到AI数据中心方案中。
为何AI离不开InfiniBand?
- 超低延迟:端到端延迟可低至1微秒级,远优于以太网(通常10+微秒)。
- 超高吞吐:NDR InfiniBand单链路带宽达400 Gb/s(50 GB/s),支持大规模横向扩展。
- 智能卸载:支持GPUDirect RDMA,GPU显存可直接通过网络读写,绕过CPU,避免内存拷贝瓶颈。
- 拥塞控制与可靠性:自适应路由、前向纠错(FEC)等机制保障万卡训练稳定性。
实战意义:
- 训练万亿参数模型(如GPT、Claude)需数千甚至上万GPU协同;
- 若使用普通以太网,通信开销可能占训练时间70%以上;
- InfiniBand + NCCL + GPUDirect 技术栈,可将通信效率提升3–5倍。
🌐 InfiniBand是AI超算中心的“血管系统”,确保海量GPU像一个整体般高效运转。
三位一体:构建端到端AI加速闭环
这三大技术并非孤立存在,而是纵向深度协同:
[开发者]
↓ 编写代码
[CUDA] → 调用cuDNN/NCCL → 利用GPU算力
↓ 多GPU通信
[NVLink] → 高速互联本地GPU(单服务器内)
↓ 跨服务器通信
[InfiniBand] → 连接千台服务器(集群级)
- CUDA 解决“如何编程GPU”;
- NVLink 解决“多GPU如何高效协作”;
- InfiniBand 解决“万卡集群如何同步训练”。
三者共同构成了英伟达从芯片→服务器→数据中心的全栈AI优势,形成极高的技术与生态壁垒。
结语:不是硬件,而是“AI操作系统”
英伟达真正的护城河,从来不只是GPU芯片本身,而是这套软硬一体、层层优化的计算范式。CUDA定义了AI编程标准,NVLink重塑了计算单元边界,InfiniBand扩展了集群规模极限。
正如黄仁勋所言:“我们正在构建AI时代的‘操作系统’。”
而CUDA、NVLink、InfiniBand,正是这个操作系统的三大核心模块——
一个让算力可用,一个让算力可扩,一个让算力可联。
在AI竞赛进入“万卡时代”的今天,这三大法宝,依然是通往智能未来最坚实的阶梯。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)