Cursor辅助数据仓库开发实战指南与开发规范
《AI辅助数据仓库开发指南》摘要:本指南详细介绍如何利用Cursor工具提升数据仓库开发效率100%以上。核心内容包括:环境配置(安装、初始化)、人机协作规范(AI负责标准代码生成,人类把控业务逻辑)、数据仓库开发标准(分层架构、命名规范、SQL编码),以及实战案例演示(经营数据看板构建)。重点强调质量保障措施,如代码审查清单、数据质量监控和文档同步机制,同时提供常见问题解决方案和团队协作规范。通
·
一、前言:为什么选择Cursor?
1.1 我们的目标
通过AI辅助开发,实现数据仓库开发效率提升100%以上,同时保证代码质量和一致性。
1.2 Cursor核心价值
| 传统开发 | Cursor辅助开发 | 收益 |
|---|---|---|
| 60%时间写重复代码 | AI生成80%标准代码 | 释放创造力 |
| 手动维护文档 | 自动同步文档 | 知识永不丢失 |
| 新人学习成本高 | 项目自解释,快速上手 | 降低团队门槛 |
| 重构风险大 | 智能影响分析 | 安全演进 |
1.3 本指南适用对象
-
数据开发工程师
-
数据分析师
-
数据产品经理
-
技术负责人
二、环境准备与基础配置
2.1 Cursor安装与设置
bash
# 1. 安装Cursor(团队统一版本) # 下载地址:https://cursor.sh # 2. 配置项目快捷键(推荐) File > Preferences > Keyboard Shortcuts 常用快捷键: - Cmd/Ctrl+K:打开Cursor对话 - Cmd/Ctrl+L:选择代码块并对话 - Cmd/Ctrl+I:内联编辑 # 3. 安装必备插件 - GitLens(代码历史查看) - Database Client(数据库连接) - Markdown All in One(文档编写)
2.2 项目初始化配置
bash
# 标准项目结构初始化脚本
#!/bin/bash
# init_project.sh
# 创建标准目录
mkdir -p {src,docs,config,tests,scripts,.cursor}
# 复制规范文档
cp templates/*.md docs/
# 初始化Cursor配置
cat > .cursor/rules/project_rules.yaml << EOF
project_name: "电商数据仓库"
team: "数据平台部"
coding_standard: "阿里OneData+内部规范"
version: "1.0"
EOF
echo "项目初始化完成!"
2.3 必要配置检查清单
yaml
# .cursorconfig
{
"model": "claude-3.5-sonnet", # 推荐模型
"autocomplete": true,
"inlineChat": true,
"context": {
"include": [
"**/*.sql",
"**/*.md",
"**/*.yaml",
"**/*.py"
],
"exclude": [
"node_modules",
".git",
"*.log",
"tmp/"
]
}
}
三、人机协作开发规范
3.1 核心原则:人机分工明确
AI(Cursor)负责: - 生成标准代码模板 - 自动补充注释 - 代码优化建议 - 文档自动生成 - 重复性工作 人类工程师负责: - 业务逻辑设计 - 架构决策 - 复杂算法实现 - 代码审查 - 质量把关
3.2 开发流程规范
流程1:新需求开发
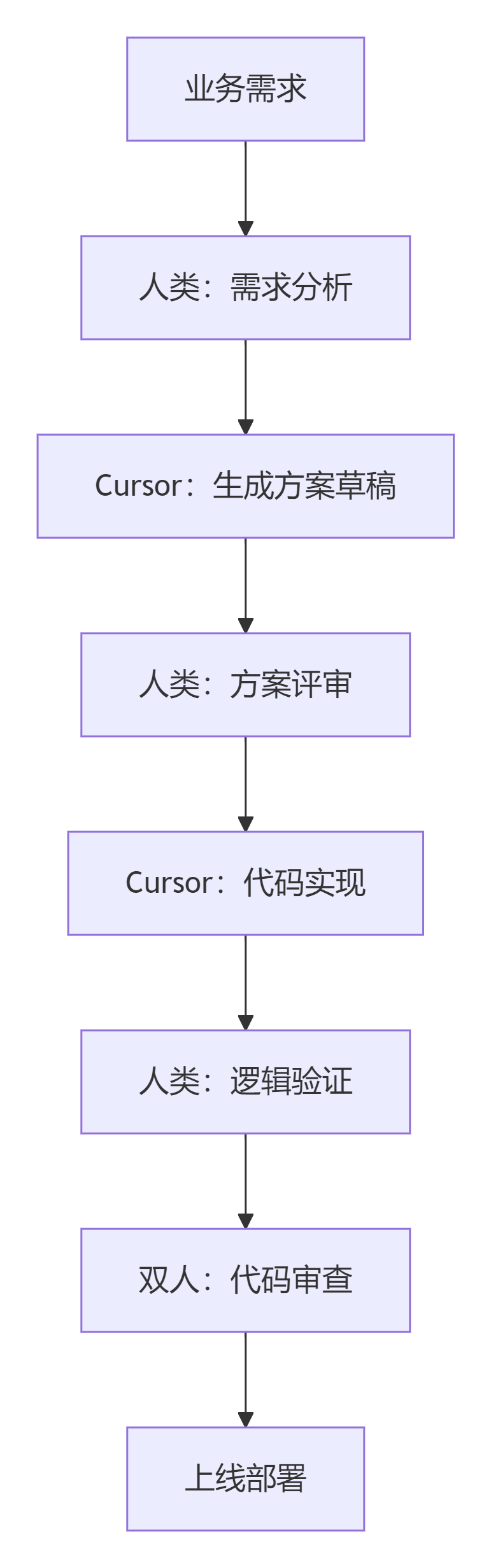
流程2:代码修改/重构
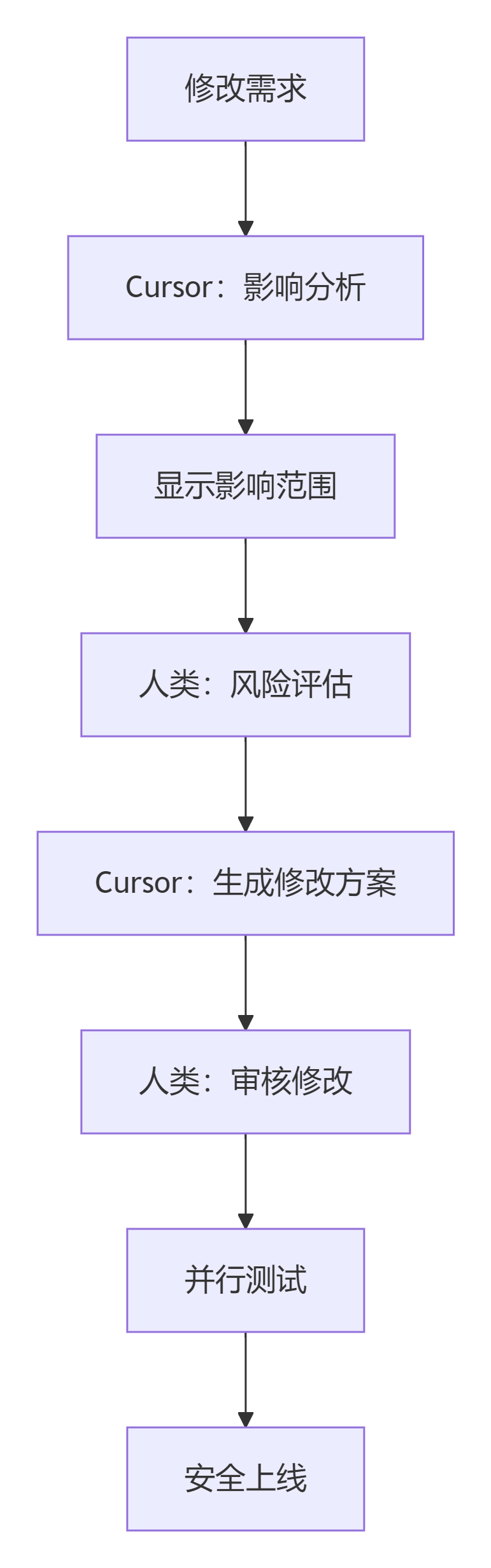
3.3 会话规范(如何与Cursor对话)
好的提示词示例
# 结构清晰的提示词模板 ## 上下文提供 @src/sql/dwd/fact_order.sql @docs/business/order_metrics.md ## 明确指令 请基于现有订单事实表,创建一个用户维度表。 ## 具体要求 1. 表名:dim_user 2. 包含字段:user_id, user_name, register_time, last_login, vip_level 3. 使用SCD Type 2处理历史变化 4. 添加完整注释 5. 生成对应的ETL脚本 ## 输出格式 - 建表DDL - 数据插入SQL - 数据质量检查规则
避免的提示词
# 避免这样提问 "做个用户表" # 太模糊 "优化这个SQL" # 缺少上下文 "出错了,怎么办" # 没有错误信息
专用指令前缀
#check - 检查代码问题 #optimize - 优化性能 #document - 生成文档 #test - 生成测试用例 #review - 代码审查 #refactor - 重构建议
四、数据仓库开发规范
4.1 分层规范(强制遵守)
# 标准五层架构
src/
├── 00_staging/ # ODS层(原始数据)
│ ├── mysql/ # 业务数据库
│ ├── log/ # 日志数据
│ └── external/ # 外部数据
├── 01_standard/ # DWD层(明细数据)
│ ├── dimensions/ # 维度表
│ └── facts/ # 事实表
├── 02_summary/ # DWS层(汇总数据)
│ ├── daily/ # 日粒度
│ ├── weekly/ # 周粒度
│ └── monthly/ # 月粒度
├── 03_application/ # ADS层(应用数据)
│ ├── dashboard/ # 看板数据
│ ├── report/ # 报表数据
│ └── api/ # API数据
└── 04_bi/ # BI层(查询视图)
└── views/ # 直接查询视图
4.2 命名规范(强制遵守)
表命名规则
-- 格式:{层级}_{主题}_{粒度}_{修饰}
-- 示例:
ods_order_mysql_daily -- ODS层订单表,来自MySQL,日粒度
dwd_fact_order -- DWD层订单事实表
dws_user_daily -- DWS层用户日汇总
ads_sales_dashboard -- ADS层销售看板数据
dim_user_scd2 -- 用户维度表,SCD类型2
字段命名规则
-- 使用下划线分隔,全小写 user_id -- 正确 userID -- 错误 user-name -- 错误 -- 常用后缀约定 _id -- 标识符 _time -- 时间戳 _date -- 日期 _cnt -- 计数 _amt -- 金额 _rate -- 比率 _flag -- 标志位 _status -- 状态
4.3 SQL编码规范
文件头部模板(Cursor自动生成)
-- ============================================
-- 文件名:dwd_fact_order.sql
-- 所属层级:DWD层
-- 业务主题:交易
-- 创建人:{你的姓名}
-- 创建时间:{YYYY-MM-DD}
-- 最后修改:{YYYY-MM-DD}
--
-- 功能描述:
-- 订单事实表,记录所有订单的明细信息
--
-- 更新频率:每日增量
-- SLA时间:凌晨3:00前
--
-- 数据来源:
-- - ods_order_mysql_daily (订单主表)
-- - ods_order_item_mysql_daily (订单商品表)
--
-- 下游依赖:
-- - dws_sales_daily (销售日汇总)
-- - ads_order_dashboard (订单看板)
--
-- 变更记录:
-- 2024-05-20 创建表结构
-- 2024-05-25 增加退款金额字段
-- ============================================
代码结构规范
-- 1. WITH子句优先(可读性好)
WITH order_base AS (
SELECT
order_id,
user_id,
order_time,
total_amount,
shipping_fee,
coupon_amount
FROM ods_order_mysql_daily
WHERE pt_date = '${bizdate}'
AND order_status NOT IN ('cancelled', 'refunded')
),
order_items AS (
SELECT
order_id,
product_id,
quantity,
price
FROM ods_order_item_mysql_daily
WHERE pt_date = '${bizdate}'
)
-- 2. 主查询逻辑清晰
SELECT
-- 代理键
ROW_NUMBER() OVER (ORDER BY o.order_time) + 1000000 AS order_sk,
-- 业务主键
o.order_id,
o.user_id,
-- 时间维度
DATE(o.order_time) AS order_date,
o.order_time,
-- 金额字段(统一单位为元)
o.total_amount / 100.0 AS order_amount,
o.shipping_fee / 100.0 AS shipping_fee,
o.coupon_amount / 100.0 AS coupon_amount,
-- 计算字段
(o.total_amount - o.coupon_amount) / 100.0 AS paid_amount,
-- 技术字段
CURRENT_TIMESTAMP AS etl_time,
'mysql' AS data_source
FROM order_base o
LEFT JOIN order_items oi ON o.order_id = oi.order_id
WHERE o.order_time IS NOT NULL -- 数据质量检查
AND o.total_amount >= 0 -- 业务规则检查
QUALIFY ROW_NUMBER() OVER (PARTITION BY o.order_id ORDER BY o.order_time) = 1
;
-- 3. 数据质量检查(Cursor自动生成)
/* 数据质量规则:
1. order_id 不能为空,不能重复
2. total_amount 必须 >= 0
3. order_time 不能为未来时间
4. 与源表数据量差异 < 0.1%
*/
4.4 注释规范
字段注释模板
CREATE TABLE dwd_fact_order (
order_sk BIGINT COMMENT '订单代理键,唯一标识',
order_id BIGINT COMMENT '订单业务ID,源系统传递',
user_id BIGINT COMMENT '用户ID,关联dim_user',
order_time TIMESTAMP COMMENT '订单创建时间,用户提交订单的时间',
order_amount DECIMAL(18,2) COMMENT '订单金额(元),计算公式:total_amount/100.0',
-- 状态字段注释示例
order_status STRING COMMENT '''
订单状态枚举:
- pending: 待支付
- paid: 已支付
- shipped: 已发货
- completed: 已完成
- cancelled: 已取消
''',
-- 计算字段注释示例
is_first_order BOOLEAN COMMENT '''
是否首单:根据用户历史订单判断
业务规则:用户在所有渠道的第一次购买
计算逻辑:ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time) = 1
'''
) COMMENT '订单事实表:记录所有订单的明细信息,用于交易分析';
复杂逻辑注释
-- 业务规则:用户等级计算
-- 规则来源:运营部2024年Q2政策
-- 生效时间:2024-04-01
-- 计算公式:
-- L1普通会员:累计消费<1000
-- L2白银会员:1000≤累计消费<5000
-- L3黄金会员:5000≤累计消费<20000
-- L4铂金会员:累计消费≥20000
CASE
WHEN total_spent < 1000 THEN 'L1'
WHEN total_spent < 5000 THEN 'L2'
WHEN total_spent < 20000 THEN 'L3'
ELSE 'L4'
END AS user_level,
4.5 性能规范
查询优化要求
-- 正确:使用分区过滤 SELECT * FROM dwd_fact_order WHERE pt_date = '2024-05-20' -- 分区字段 AND order_date = '2024-05-20'; -- 错误:全表扫描 SELECT * FROM dwd_fact_order WHERE order_date = '2024-05-20'; -- 非分区字段 -- 正确:限制返回数量 SELECT * FROM large_table WHERE pt_date = '2024-05-20' LIMIT 1000; -- 正确:明确字段列表 SELECT order_id, user_id, order_amount FROM dwd_fact_order WHERE pt_date = '2024-05-20'; -- 错误:SELECT * SELECT * FROM dwd_fact_order WHERE pt_date = '2024-05-20';
JOIN优化规范
-- 1. 大表JOIN小表:小表放右边
SELECT /*+ MAPJOIN(small_table) */
a.*, b.name
FROM large_table a
JOIN small_table b ON a.id = b.id;
-- 2. 相同JOIN键合并
SELECT
a.*, b.name, c.category
FROM fact_table a
JOIN dim_user b ON a.user_id = b.user_id
JOIN dim_product c ON a.product_id = c.product_id;
-- 3. 避免笛卡尔积
-- 明确JOIN条件
SELECT a.*, b.*
FROM table_a a
JOIN table_b b ON a.key = b.key;
-- 避免隐式JOIN
SELECT a.*, b.*
FROM table_a a, table_b b
WHERE a.key = b.key; -- 容易遗漏条件
五、Cursor实战操作指南
5.1 常用操作指令库
数据建模指令
# 创建维度表指令模板 @docs/standards/dimensional_modeling.md @examples/dim_product.sql 请创建商品维度表(dim_product): - 业务主键:product_id - 核心属性:product_name, category_id, brand, price - 使用SCD Type 2跟踪价格变化 - 来源表:ods_product_mysql_daily - 生成完整DDL和初始加载SQL
ETL开发指令
# ETL任务开发指令 @src/sql/00_staging/ods_order_mysql_daily.sql @src/sql/01_standard/dim_user.sql 请开发订单事实表(dwd_fact_order)的ETL任务: - 来源:ods_order_mysql_daily, ods_order_item_mysql_daily - 目标:dwd_fact_order - 业务逻辑: 1. 关联订单主表和商品表 2. 计算实付金额:total_amount - coupon_amount 3. 标记首单用户 4. 排除测试订单(user_id以'test_'开头) - 输出:完整的INSERT语句和异常处理
数据质量检查指令
# 数据质量规则生成 @src/sql/01_standard/dwd_fact_order.sql 请为订单事实表生成数据质量检查规则: - 完整性:关键字段非空 - 一致性:金额字段逻辑关系 - 准确性:枚举值验证 - 及时性:数据新鲜度检查 - 输出:可执行的验证SQL和告警阈值
文档生成指令
# 自动生成文档 @src/sql/01_standard/dwd_fact_order.sql @src/sql/02_summary/dws_sales_daily.sql 请基于以上SQL文件生成: 1. 数据字典(字段说明、业务含义) 2. 血缘关系图(上游依赖、下游使用) 3. 业务指标说明(计算逻辑、更新频率) 4. 数据质量报告(空值率、枚举分布)
5.2 代码审查与优化
使用Cursor进行代码审查
# 代码审查指令 @src/sql/02_summary/dws_sales_daily.sql 请审查此SQL代码,检查以下方面: 1. 是否符合项目命名规范 2. 性能问题(全表扫描、数据倾斜) 3. 数据质量风险(空值处理、除零错误) 4. 业务逻辑正确性 5. 文档完整性 请按以下格式输出: - 严重问题(必须修改) - 优化建议(建议修改) - 文档建议(补充说明)
SQL性能优化
# 性能优化指令 @src/sql/02_summary/dws_sales_daily.sql 此查询在production环境执行较慢(约45秒),请分析并优化: 当前执行计划的问题: 1. 缺少分区过滤 2. 大表JOIN未使用索引 3. 窗口函数导致数据膨胀 请提供: 1. 优化后的SQL 2. 预计性能提升 3. 创建索引建议
5.3 错误排查与调试
错误分析指令
# 错误排查指令 @src/python/etl/order_etl.py @logs/error_20240520.log ETL任务失败,错误信息: "MemoryError: Java heap space" 请分析: 1. 根本原因 2. 修复方案 3. 预防措施
数据不一致排查
# 数据不一致分析 @src/sql/03_application/ads_sales_dashboard.sql @src/sql/01_standard/dwd_fact_order.sql 问题:看板中今日GMV与财务系统相差3.2% 请分析可能原因: 1. 数据口径差异 2. 时间范围不同 3. 过滤条件不一致 4. 数据延迟问题 请生成对比验证SQL
六、项目管理与协作规范
6.1 项目文档结构
docs/
├── 📁 business/ # 业务文档
│ ├── glossary.md # 数据字典(自动生成)
│ ├── metrics.md # 指标定义库
│ ├── requirements/ # 需求文档
│ └── rules/ # 业务规则库
├── 📁 technical/ # 技术文档
│ ├── architecture.md # 架构设计
│ ├── etl_specs.md # ETL规范
│ ├── api_docs.md # API文档
│ └── lineage/ # 血缘关系图
├── 📁 operations/ # 运维文档
│ ├── deployment.md # 部署指南
│ ├── monitoring.md # 监控告警
│ └── troubleshooting.md # 故障排查
└── 📁 team/ # 团队文档
├── onboarding.md # 新人指南
├── workflows.md # 工作流程
└── best_practices.md # 最佳实践
6.2 Git协作规范
分支策略
bash
# 分支命名规范 feature/ # 新功能开发 bugfix/ # Bug修复 hotfix/ # 紧急修复 release/ # 发布分支 # 示例 git checkout -b feature/add-user-retention-metrics git checkout -b bugfix/fix-gmv-calculation
提交信息规范
bash
# 提交格式 类型(范围): 简要描述 # 类型说明 feat: 新功能 fix: Bug修复 docs: 文档更新 style: 代码格式 refactor: 代码重构 test: 测试相关 chore: 构建过程或辅助工具 # 示例 git commit -m "feat(dwd): 新增订单事实表,支持退款分析" git commit -m "fix(ads): 修复GMV计算中的除零错误" git commit -m "docs: 更新数据字典,补充字段说明"
6.3 代码审查清单
## 代码审查检查项 ### 业务逻辑 (人类审查) - [ ] 业务规则是否正确实现 - [ ] 计算逻辑是否符合需求 - [ ] 异常场景是否处理 - [ ] 数据口径是否一致 ### 代码质量 (Cursor辅助) - [ ] 符合命名规范 - [ ] 有完整的注释 - [ ] 无明显的性能问题 - [ ] 数据质量检查完整 ### 文档更新 (Cursor自动) - [ ] 数据字典已更新 - [ ] 血缘关系已记录 - [ ] 变更说明已添加 - [ ] 影响评估已完成
七、实战案例:构建经营数据看板
7.1 案例背景
为电商业务构建CEO经营数据看板,核心指标:
-
销售业绩:GMV、订单数、客单价
-
用户分析:新增用户、活跃用户、留存率
-
商品分析:热销商品、库存周转
-
财务指标:毛利率、退款率
7.2 开发步骤演示
步骤1:需求分析与设计
# 向Cursor提供需求 @docs/business/requirements/ceo_dashboard.md @docs/standards/data_modeling.md 请设计经营数据看板的数据模型: 需求要点: 1. 核心指标:日GMV、订单数、活跃用户数、毛利率 2. 分析维度:时间(日/周/月)、渠道、品类、省份 3. 数据时效:T+1,每日7:00前更新 4. 数据质量:与财务系统误差<0.1% 请输出: 1. 数据模型设计图 2. 表结构设计 3. ETL数据处理流程
步骤2:自动生成代码
Cursor生成的核心代码示例:
-- ads_ceo_dashboard_daily.sql
-- 经营看板日粒度数据表
CREATE TABLE ads_ceo_dashboard_daily (
stat_date STRING COMMENT '统计日期',
channel STRING COMMENT '销售渠道',
province_id INT COMMENT '省份ID',
-- 销售指标
gmv DECIMAL(18,2) COMMENT '商品交易总额(元)',
order_cnt BIGINT COMMENT '订单数量',
buyer_cnt BIGINT COMMENT '购买用户数',
avg_order_amount DECIMAL(18,2) COMMENT '平均客单价',
-- 用户指标
new_user_cnt BIGINT COMMENT '新增用户数',
active_user_cnt BIGINT COMMENT '活跃用户数',
retention_rate_7d DECIMAL(5,2) COMMENT '7日留存率(%)',
-- 商品指标
hot_product_cnt BIGINT COMMENT '热销商品数(日销>100件)',
stock_turnover_rate DECIMAL(5,2) COMMENT '库存周转率',
-- 财务指标
gross_margin_rate DECIMAL(5,2) COMMENT '毛利率(%)',
refund_rate DECIMAL(5,2) COMMENT '退款率(%)',
-- 技术字段
etl_time TIMESTAMP COMMENT 'ETL处理时间',
data_version STRING COMMENT '数据版本标识'
)
COMMENT 'CEO经营数据看板-日粒度汇总表'
PARTITIONED BY (pt_year STRING, pt_month STRING)
STORED AS ORC;
步骤3:ETL任务生成
python
# Cursor生成的ETL任务
class CeoDashboardETL:
def process_daily(self, biz_date):
"""处理每日数据"""
sql = f"""
INSERT OVERWRITE TABLE ads_ceo_dashboard_daily
PARTITION (pt_year, pt_month)
SELECT
'{biz_date}' AS stat_date,
channel,
province_id,
-- 销售指标计算
SUM(order_amount) AS gmv,
COUNT(DISTINCT order_id) AS order_cnt,
COUNT(DISTINCT user_id) AS buyer_cnt,
AVG(order_amount) AS avg_order_amount,
-- 数据质量标记
CASE
WHEN COUNT(*) = 0 THEN 'ERROR: no_data'
WHEN SUM(order_amount) < 0 THEN 'ERROR: negative_gmv'
ELSE 'SUCCESS'
END AS data_quality_flag,
CURRENT_TIMESTAMP AS etl_time,
YEAR('{biz_date}') AS pt_year,
MONTH('{biz_date}') AS pt_month
FROM dwd_fact_order
WHERE order_date = '{biz_date}'
AND order_status = 'completed'
GROUP BY channel, province_id
"""
return self.execute_sql(sql)
步骤4:数据质量检查
-- Cursor自动生成的数据质量检查
SELECT
'ads_ceo_dashboard_daily' AS table_name,
stat_date,
-- 完整性检查
COUNT(*) AS total_records,
SUM(CASE WHEN gmv IS NULL THEN 1 ELSE 0 END) AS null_gmv_count,
-- 准确性检查
MIN(gmv) AS min_gmv,
MAX(gmv) AS max_gmv,
AVG(gmv) AS avg_gmv,
-- 一致性检查(与源表对比)
(SELECT COUNT(*) FROM dwd_fact_order
WHERE order_date = stat_date) AS source_count,
-- 及时性检查
MAX(etl_time) AS latest_etl_time,
CURRENT_TIMESTAMP - MAX(etl_time) AS data_freshness,
-- 综合评分
CASE
WHEN null_gmv_count > 0 THEN 'FAIL'
WHEN data_freshness > INTERVAL '2' HOUR THEN 'WARNING'
ELSE 'PASS'
END AS quality_grade
FROM ads_ceo_dashboard_daily
WHERE pt_date = '${bizdate}'
GROUP BY stat_date;
7.3 成果验证
-- 新旧数据对比验证
WITH legacy_data AS (
-- 旧版看板数据(手动维护)
SELECT * FROM manual_ceo_report
WHERE report_date = '2024-05-20'
),
new_data AS (
-- 新版看板数据(Cursor生成)
SELECT * FROM ads_ceo_dashboard_daily
WHERE stat_date = '2024-05-20'
)
SELECT
'GMV对比' AS metric,
l.gmv AS legacy_value,
n.gmv AS new_value,
ROUND(ABS(l.gmv - n.gmv) / l.gmv * 100, 2) AS diff_percent,
CASE WHEN ABS(l.gmv - n.gmv) / l.gmv < 0.001 THEN '1'
ELSE '0' END AS result
FROM legacy_data l
JOIN new_data n ON 1=1;
八、常见问题与解决方案
8.1 Cursor使用问题
问题1:Cursor生成的代码不符合规范
解决方案: 1. 提供更详细的上下文 @docs/standards/sql_style_guide.md @examples/correct_example.sql 2. 明确指定规范要求 "请严格按照项目SQL规范编写,包括: - 表名必须小写,使用下划线分隔 - 每个字段必须有COMMENT - 必须包含分区字段 - 参考示例文件的结构"
问题2:Cursor不理解业务逻辑
解决方案: 1. 先提供业务背景 @docs/business/rules/order_rules.md 2. 分步指导 "第一步:从订单表获取基础数据 第二步:应用业务规则过滤 第三步:计算指标 第四步:关联维度表" 3. 提供测试用例 "测试数据: - 正常订单:金额100元 - 退款订单:金额-50元 - 测试订单:user_id以test_开头 期望结果:只包含正常订单"
问题3:Cursor修改了不该改的文件
预防措施: 1. 设置只读目录 # .cursor/rules/protected_files.yaml read_only: - "legacy/" - "production/" - "src/sql/00_staging/" # ODS层禁止修改 2. 使用确认机制 "请先告诉我需要修改哪些文件,等我确认后再修改"
8.2 数据质量问题
问题:数据不一致
-- 使用Cursor生成对比分析SQL @src/sql/01_standard/dwd_fact_order.sql @src/sql/03_application/ads_sales_dashboard.sql 请分析以下数据不一致问题: 表A中2024-05-20的GMV为1,234,567元 表B中同一日期的GMV为1,235,000元 请生成对比分析SQL,检查: 1. 数据口径差异 2. 过滤条件不同 3. 计算逻辑区别 4. 数据延迟问题
问题:性能瓶颈
解决方案指令: @src/sql/02_summary/dws_user_behavior_daily.sql 此查询执行时间超过5分钟,请分析性能瓶颈: 请提供: 1. 执行计划分析 2. 性能优化建议 3. 优化后的SQL 4. 预期的性能提升
8.3 团队协作问题
问题:代码合并冲突
预防方案: 1. 使用标准模板(减少差异) 2. 提前沟通变更范围 3. Cursor辅助解决冲突 解决指令: "请帮我解决这两个文件的合并冲突: @file_a.sql @file_b.sql 冲突内容是关于用户等级的计算逻辑。 业务规则:..."
九、最佳实践总结
9.1 每日工作流
早晨检查: 1. 打开Cursor,加载项目上下文 2. 检查昨日ETL任务状态 3. 查看数据质量报告 开发流程: 1. 新需求:先写文档,再让Cursor生成代码 2. 修改需求:先分析影响,再让Cursor生成方案 3. 代码审查:使用Cursor辅助检查 下班前: 1. 提交代码,确保有完整注释 2. 更新相关文档 3. 记录今日工作总结
9.2 效率提升技巧
-
建立个人提示词库:积累高效的提示词模板
-
项目模板标准化:减少重复配置工作
-
定期知识沉淀:把解决方案文档化
-
团队经验共享:建立最佳实践库
9.3 质量保障措施
-
代码规范检查:每次提交前使用Cursor检查
-
数据质量监控:关键指标自动监控
-
文档同步机制:代码变更自动更新文档
-
定期重构计划:每月使用Cursor优化老旧代码
十、附录
10.1 快捷键速查表
| 快捷键 | 功能 | 使用场景 |
|---|---|---|
| Cmd/Ctrl+K | 打开Cursor对话 | 随时提问 |
| Cmd/Ctrl+L | 选择代码对话 | 代码优化 |
| Cmd/Ctrl+I | 内联编辑 | 快速修改 |
| Alt+C | 接受建议 | 代码补全 |
10.2 常用提示词模板库
# 提示词模板库位置 .cursor/prompts/ ├── sql_development.md # SQL开发模板 ├── etl_pipelines.md # ETL任务模板 ├── data_quality.md # 数据质量模板 ├── documentation.md # 文档生成模板 └── troubleshooting.md # 问题排查模板
写在最后
本指南随着团队使用经验的积累会持续更新。每个团队成员都应:
-
遵守规范:确保代码质量和一致性
-
积极贡献:分享高效的提示词和技巧
-
持续学习:探索Cursor的更多可能性
-
质量第一:AI辅助,人类把关
记住:Cursor是我们强大的助手,但不是决策者。最终的代码质量、业务正确性和架构合理性,仍然依赖于我们工程师的专业判断。
祝大家使用愉快,开发高效!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)