卷积神经网络(CNN)深度解析:从“像素侦探”到AI视觉革命
摘要:卷积神经网络(CNN)是计算机视觉的核心技术,通过模拟人类视觉系统实现高效图像识别。其核心机制包括局部连接、权值共享和层级特征提取,显著降低了参数数量。CNN由卷积层、激活函数、池化层和全连接层构成,通过反向传播不断优化特征提取能力。从LeNet到ResNet,CNN架构持续演进,解决了深层网络训练难题。尽管存在数据依赖和可解释性等局限,CNN仍通过与注意力机制融合、轻量化设计等方向持续发展
在当今人工智能的浪潮中,卷积神经网络(CNN)无疑是计算机视觉领域的“王牌选手”。当你用手机相册的“以图搜图”功能瞬间找到旧照片,或是惊叹于自动驾驶汽车精准识别行人时,背后都有CNN在默默工作。它就像一位训练有素的“像素侦探”,教会了计算机如何“看懂”世界。本文将带你深入CNN的奇妙世界,用最通俗的语言,揭开其从基础原理到现代演进的神秘面纱。
一、 为什么是CNN?传统神经网络的“致命缺陷”
在CNN出现之前,计算机“看”图片的方式非常笨拙。想象一下,你要让计算机识别一张1000×1000像素的彩色图片。传统全连接神经网络(MLP)会把这300万个像素点(1000×1000×3)直接拉成一长串数字作为输入。如果第一个隐藏层有1000个神经元,仅这一层的连接权重就高达30亿个(3×10⁹)!这导致了参数爆炸、计算资源灾难和极高的过拟合风险。
CNN的革命性在于,它借鉴了人类视觉系统的工作方式。生物学家发现,大脑视觉皮层处理信息是分区域、分层级的:先看边缘和线条,再组合成形状,最后认出整体物体。CNN完美地模拟了这一过程,其核心设计思想解决了传统网络的困境:
- 局部连接:每个神经元只关注图像的一小块局部区域(如3×3像素),而非整张图,大幅减少了参数数量。
- 权值共享:同一个“特征探测器”(卷积核)在整个图像上滑动使用,参数重复利用,进一步降低了参数量并赋予了模型平移不变性——即无论猫在图片左边还是右边,都能被识别。
- 层级特征提取:通过多层堆叠,从简单的边缘、纹理逐步提取出复杂的物体部件乃至完整物体。
二、 CNN核心组件:一条高效的特征精炼流水线
一个典型的CNN网络,就像一条高效的信息精炼流水线,由几个核心车间(层)顺序构成。
1. 卷积层:手持“特征滤片”的侦探
这是CNN的核心引擎,承担着特征提取的关键任务。你可以把卷积核(Kernel或Filter)想象成侦探手中各种功能的“特征滤片”:
- 滤片A:专门检测“垂直边缘”(如建筑轮廓)。
- 滤片B:专门检测“水平边缘”(如地平线)。
- 滤片C:专门检测“红色区域”。
卷积操作就是拿着这些滤片,从图像左上角开始,一步步滑动,计算滤片与对应图像区域的重合程度(进行点乘求和)。其数学表达为:
$$(I * K)(i,j) = \sum_{m}\sum_{n} I(i+m, j+n)K(m,n)$$
其中 $I$ 是输入图像,$K$ 是卷积核,$(i,j)$ 是输出位置坐标。如果某个区域和“边缘滤片”高度重合,就会输出一个高值,表示“这里检测到了边缘”。
这个过程由三个关键参数控制:
- 步长(Stride):滤片每次滑动的像素数。步长越大,输出特征图尺寸越小。
- 填充(Padding):在图像边缘补一圈0,以控制输出尺寸或避免边缘信息丢失。
- 输出尺寸公式:$W_{out} = \frac{W_{in} - K + 2P}{S} + 1$,其中 $W_{in}$ 是输入宽度,$K$ 是卷积核大小,$P$ 是填充数,$S$ 是步长。
2. 激活函数:引入非线性的“质检员”
卷积层提取的是线性特征,但真实世界的关系是非线性的。激活函数就像一个“质检员”,决定哪些特征重要并向后传递。最常用的是ReLU函数:$f(x) = max(0, x)$。它的规则极其简单:如果是正数就原样通过,是负数就变成0(过滤掉)。ReLU计算高效,能有效缓解深层网络中的梯度消失问题,大大加快了训练速度。
3. 池化层:降维抗噪的“信息压缩员”
卷积后得到的特征图可能还很大。池化层的作用是进行下采样,压缩信息。最常见的是最大池化(Max Pooling),它在一个小区域(如2×2)里只保留数值最大的那个特征。这相当于在说:“这附近有个很明显的边缘,具体位置有点偏差没关系,只要知道这附近有就行。” 池化层能降低特征图尺寸、减少计算量、增强模型对微小位移的鲁棒性,并有助于防止过拟合。
4. 全连接层:综合研判的“决策委员会”
经过多次“卷积-激活-池化”的循环,特征已经从简单的“边缘”组合成了复杂的“车轮”、“眼睛”。全连接层位于流水线末端,它把前面提取的所有高级特征“展平”并综合起来,进行全局分析,就像“决策委员会”一样,最终投票得出结论(例如:这是猫的概率是98%)。输出层通常使用Softmax函数将结果转化为各类别的概率分布。
三、 CNN如何学习?从“瞎猜”到“专家”的训练之旅
CNN并非生来就是专家。初始时,它的“滤片”(卷积核)里的数字是随机设定的,提取的特征毫无意义。其学习过程是一个不断“猜错-调整”的循环:
- 前向传播:输入一张标有“猫”的图片,网络根据当前滤片输出一个预测(比如“狗”)。
- 计算损失:比较预测“狗”和真实标签“猫”,计算出一个损失值(错误程度分数)。
- 反向传播与优化:这是学习的关键!网络根据损失值,反向推算每个“滤片”对错误贡献了多少,然后通过梯度下降算法,微调滤片中的数字,让下次预测更准。
- 循环往复:用海量图片重复上述过程数百万次。最终,这些滤片自动调整成了能精准提取猫特征的“猫耳朵检测器”、“猫胡须检测器”。
为了训练得更快、更稳,现代CNN还引入了许多关键技术:
- 批标准化(Batch Normalization):对每一层的输入进行归一化,使其均值接近0、方差接近1,能显著加速训练并提高稳定性。其公式为:$\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$,其中 $\mu_B$ 和 $\sigma_B^2$ 是小批次的均值和方差。
- Dropout:在训练时随机“关闭”一部分神经元,是一种有效的正则化手段,能防止模型对特定神经元的过度依赖,从而减轻过拟合。
- 数据增强:通过对训练图像进行随机旋转、裁剪、翻转等操作,人工增加数据多样性,提升模型的泛化能力。
四、 经典架构演进:从LeNet到ResNet的智慧之路
CNN的发展史是一部不断加深、不断创新的历史:
- LeNet-5(1998):由Yann LeCun提出,首个成功应用于手写数字识别的CNN,奠定了卷积、池化、全连接的基本结构。
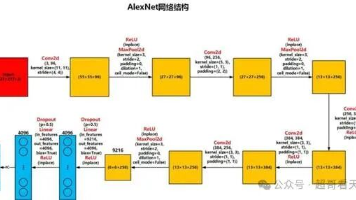
- AlexNet(2012):在ImageNet大赛中以压倒性优势夺冠,真正点燃了深度学习热潮。它首次成功应用了ReLU、Dropout和大规模GPU训练。
- VGGNet(2014):通过反复堆叠3×3的小卷积核来构建深层网络,证明了深度对于提升性能至关重要。
- ResNet(2015):革命性地引入了残差连接(Residual Connection),解决了深层网络的梯度消失和退化问题。其核心单元 $y = F(x) + x$,让网络可以通过恒等映射轻松地学习,使得构建数百甚至上千层的网络成为可能。
五、 CNN的局限与未来:没有“银弹”,只有进化
尽管强大,CNN也并非万能。理解其边界与理解其原理同样重要:
- 缺乏关系理解:CNN能识别物体,但难以理解物体间的空间或逻辑关系(如“骑”这个动作)。
- 非序列数据专家:其天生为空间结构设计,处理文本、语音等强时序依赖的数据并非最擅长。
- 数据饥渴:需要海量标注数据才能成为专家,数据收集成本高。
- “黑箱”特性:决策过程难以精确解释。
面对这些挑战和新的技术浪潮(如Vision Transformer),CNN也在不断进化。现代研究方向包括:
- 与注意力机制融合:如ConvNeXt等混合架构,结合了CNN的效率与Transformer的全局建模能力。
- 轻量化设计:如MobileNet、EfficientNet,专为移动和嵌入式设备优化。
- 自监督学习:减少对海量标注数据的依赖。
六、 动手实践:用PyTorch构建你的第一个CNN
理论离不开实践。下面是一个用PyTorch实现、用于MNIST手写数字识别的简易CNN代码框架,助你快速上手:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 1. 定义模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1) # 输入1通道(灰度),输出8通道
self.pool = nn.MaxPool2d(2, 2) # 2x2最大池化
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.fc1 = nn.Linear(16 * 7 * 7, 128) # 展平后全连接
self.fc2 = nn.Linear(128, 10) # 输出10类
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 7 * 7) # 展平
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 2. 加载数据、定义损失函数和优化器
# 3. 训练循环 (前向传播、计算损失、反向传播、优化)
# ... (具体代码可参考上文[8](@ref)或相关教程)
通过这个简单的框架,你可以直观地感受CNN“局部连接-权值共享-分层抽象”的工作流程。
结语
卷积神经网络,这个受生物视觉启发而诞生的模型,已经深刻地改变了我们与机器交互的方式。它从像素中提炼语义,将冰冷的数字转化为智能的认知。尽管新的架构不断涌现,但CNN所奠定的局部感知、权重共享和层次化提取的核心思想,依然是计算机视觉乃至更广泛深度学习领域的宝贵财富。理解CNN,不仅是掌握了一项工具,更是洞察了AI如何学习“看见”世界的一种思维方式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)