智能金融客服助手:从大模型API调用到私有化Agent的实战演进
本文探讨了金融领域如何通过RAG+智能体框架构建专属AI客服系统。针对传统客服效率低、通用大模型合规风险高的问题,采用LangChain+Chroma进行知识向量化,结合DeepSeek-V2模型实现动态知识更新和精准回答。系统通过三阶段实施:知识结构化处理、业务流程智能体构建、严格合规提示词设计,最终实现89%首解率和40秒平均响应时间。项目不仅提升效率,更推动了企业知识管理模式变革和人机协作新
引言
金融领域面临一个典型的行业痛点:客户服务中心每天需要处理大量关于理财产品、费率规则、合同条款的咨询。传统的关键词匹配机器人经常答非所问,而人工客服则被重复性问题消耗了大量精力。我们曾尝试接入某通用大模型的API,但它对最新的公司内部产品手册和动态监管政策一无所知,时常“一本正经地胡说八道”,甚至编造不存在的条款,这在高合规要求的金融领域是致命的。
我们意识到,直接调用通用大模型API,在强知识的金融领域、高合规场景下,是远远不够的。 真正的“重塑”,不是把ChatGPT当搜索引擎用,而是将其核心能力与企业自身的“知识大脑”和“业务流程”深度融合。我们的目标从“使用一个AI工具”转变为“构建一个专属的、可控的、懂业务的智能体(Agent)”。
一、解决方案选型:为什么是RAG + 智能体框架?
面对“专业知识时效性”、“回答精准性与合规性”以及“成本可控”三大挑战,我们评估了三条主流路径:
-
全量微调(Fine-tuning):成本极高,且每次知识更新都需重新训练,灵活性差。
-
提示词工程:在提问时拼接大量文本,受限于模型上下文长度,且对长文档理解不佳。
-
检索增强生成(RAG):将企业内部知识库向量化,先检索相关片段,再让大模型基于这些“证据”生成答案。这完美契合了我们的需求——知识可动态更新、答案有据可查、成本相对较低。
技术栈最终确定:
-
知识处理与检索层:
LangChain+Chroma(向量数据库)+Sentence-Transformer嵌入模型。 -
核心智能体层:
LangGraph或AutoGen框架,用于编排多步骤推理和工具调用。 -
大模型基座:综合评估后,选择 DeepSeek-V2 作为基座模型。其混合专家(MoE)架构在保证强大能力的同时,推理成本极具性价比,特别适合我们这种需要高频查询的场景。同时,其128K的上下文窗口,也能更好地处理检索到的长文档片段。
-
后端与部署:
FastAPI+Docker+ 私有化服务器部署。
二、实施过程:从杂乱文档到“业务专家”的蜕变
整个构建过程并非一蹴而就,我们将其分为三个阶段:
阶段一:知识库的“消化”与“结构化”
这是最基础,也最繁琐的一步。我们将分散在各处的PDF产品说明书、Excel费率表、Word版监管文件和内部Q&A文档进行统一处理。
# 示例:基于LangChain的文档处理与向量化核心代码片段
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
# 1. 加载文档
loader = DirectoryLoader('./internal_knowledge/', glob="**/*.pdf", loader_cls=PyPDFLoader)
documents = loader.load()
# 2. 切分文档,确保语义完整性
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# 3. 创建向量存储
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vector_db = Chroma.from_documents(documents=chunks, embedding=embeddings, persist_directory="./chroma_db")阶段二:构建具备“业务流程”的智能体
简单的Q&A不足以解决复杂问题。我们利用LangGraph将客服流程图形化。例如,一个用户问“我想申购XX基金,费率是多少?到期如何赎回?”:
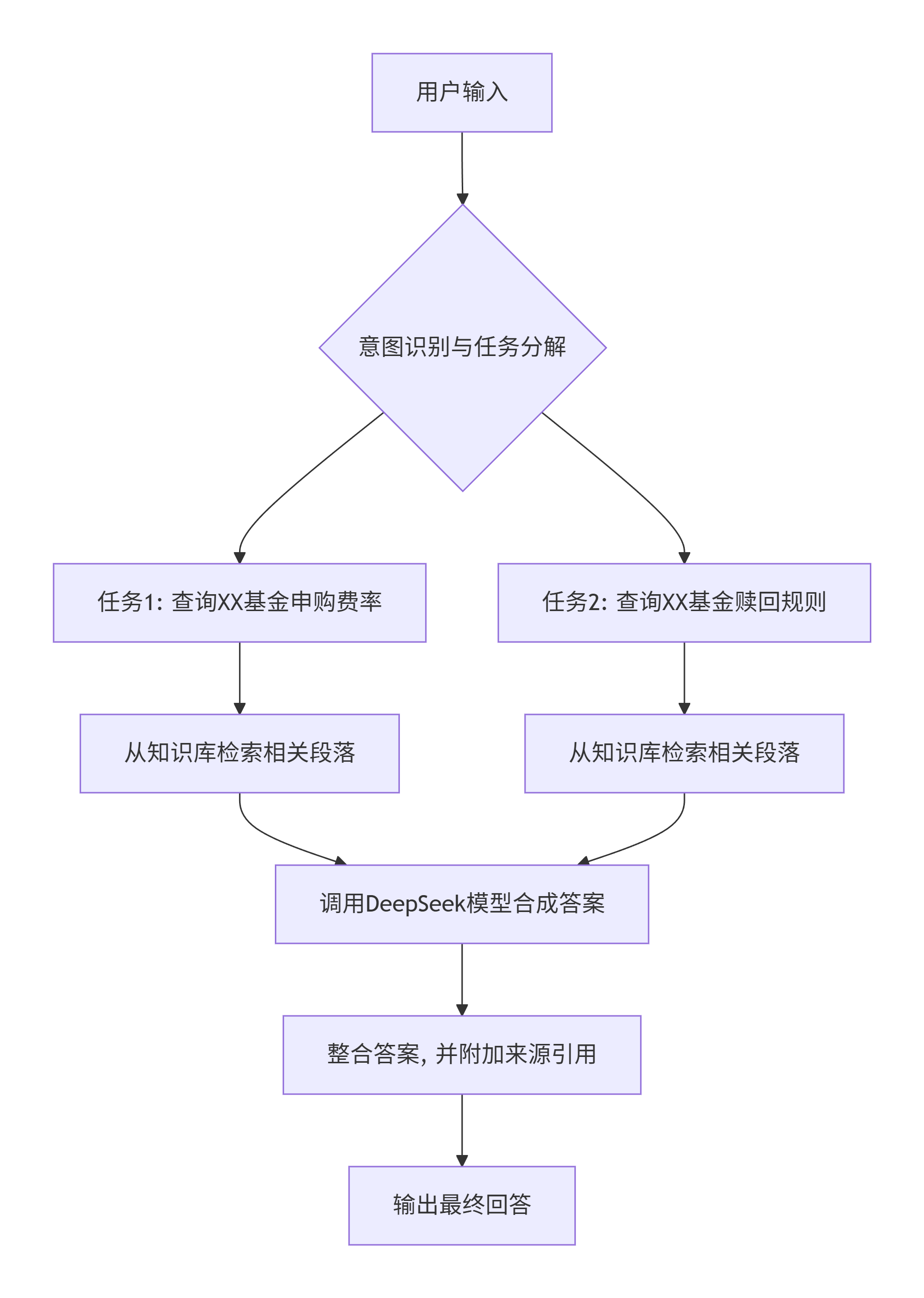
智能体会自动将此复合问题拆解为两个子任务,并行检索,最后合成一个完整、准确的回答,并注明答案依据出自哪份文档第几页。
阶段三:提示词工程与“合规护栏”设计
我们为模型设计了严格的系统提示词(System Prompt),使其角色定位为“严谨的金融客服专家”,并制定了必须遵守的规则:
-
“实事求是”原则:若检索到的知识置信度低或为空,必须回答“根据现有资料,我暂时无法确认该信息,建议您联系人工客服核实”。
-
“引用溯源”原则:答案中关键信息点必须附带来源。
-
“风险提示”原则:涉及收益、风险等,必须自动追加标准风险提示语句。
三、效果评估:不只是效率,更是模式的升级
经过两个月的迭代和上线试运行,效果对比显著:
| 指标 | 传统关键词机器人 | 通用大模型API | 自研RAG智能体 |
|---|---|---|---|
| 问题首解率 | 35% | 65% | 89% |
| 平均处理时间 | 5分钟 | 1分钟 | 40秒 |
| 知识更新周期 | 1周(需手动更新规则) | 无法更新 | 实时(上传文档即可) |
| 合规风险 | 低(但能力有限) | 高(存在幻觉) | 可控(答案有据可查) |
| 月度成本 | 低 | 高(API调用量巨大) | 中等(一次构建,长期复用) |
更深层的“重塑”体现在三个方面:
-
开发团队角色的转变:我们从“业务系统的实现者”变成了“业务知识的架构师和训练师”,需要更深层次地理解业务逻辑并将其“翻译”给AI。
-
知识管理模式的变革:倒逼业务部门将知识从杂乱的文件柜,整理成结构化的、机器可读的数字资产。
-
人机协作的新范式:客服人员从重复应答中解放出来,转而处理智能体移交的复杂、高情感交互的客户问题,并负责对智能体的回答进行审核与优化,形成了“AI处理标准信息,人处理复杂情感与异常”的高效协同。
四、挑战、反思与未来展望
挑战:
即使有RAG,模型在拼接不同来源信息时,偶尔仍会产生细微偏差。我们通过增加“交叉验证”步骤来缓解。对于需要跨多文档、多步骤深度推理的非常规问题,系统仍需人工介入。
反思:
这次实践让我们深刻认识到,大模型落地不是“炼丹”,而是“筑路”。它是一项系统工程,成功的关键“三分在模型,七分在知识工程与业务融合”。选择合适的、性价比高的基座模型(如DeepSeek)是基础,但更核心的是围绕业务场景进行精巧的架构设计和流程编排。
展望:
下一步,我们计划引入多模态能力,让系统能理解用户上传的合同截图并进行分析;同时探索轻量级微调与RAG的结合,让模型更能掌握公司特有的语言风格和专业术语。我们相信,未来每个企业都将在通用大模型的基础之上,生长出自己独特的、有机的“数字业务大脑”。
(本文基于真实项目经验抽象总结,已进行必要脱敏。所有代码与架构均为原创实践,首发于CSDN,遵守活动规则。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)