黑马Coze智能体开发:零代码打造AI助手[纯享版]2w字笔记(含资料)
目录
2.Coze 双轨工作流体系:Workflow vs Chatflow
一、Coze简单介绍
Coze 是字节跳动推出的AI Agent(智能体)开发平台,定位为 “零代码 / 低代码的 Bot 开发工具”,核心目标是 “让每个人都能开发 AI 应用”—— 无需编程基础即可快速搭建具备自主决策、工具调用能力的智能体,官网地址为:https://www.coze.cn/home。
1.Agent与大模型的区别
AI Agent(智能体)与传统大模型(如 ChatGPT)的核心差异,本质是 “被动响应工具” 与 “主动执行助手” 的区别,具体对比如下:
|
对比维度 |
传统大模型 |
AI Agent |
|---|---|---|
|
定位 |
被动响应 |
主动执行 |
|
信息获取 |
仅限训练数据(知识过时) |
可实时搜索(动态更新) |
|
能力边界 |
只能对话 |
可调用外部工具(拓展能力) |
|
任务处理 |
单轮回答 |
多步规划(拆解复杂任务) |
|
应用场景 |
咨询问答 |
实际业务执行 |
大模型是 “聊天对象”,而 Agent 是 “能聊、能做、能自主执行任务的工作助手”。
AI Agent(智能体)的核心架构
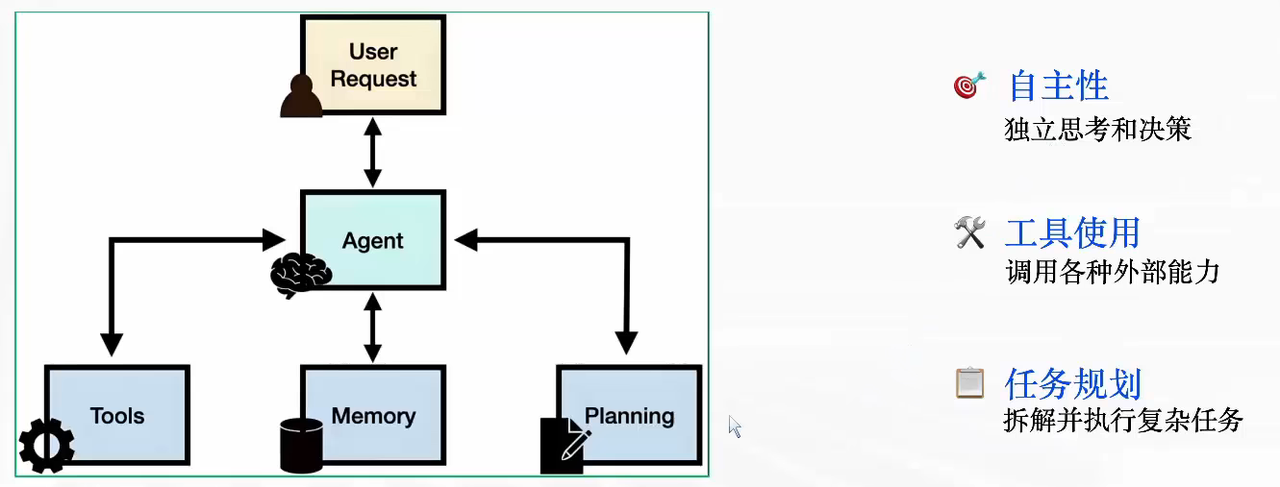
-
User Request(用户请求)是流程的起点,指用户提出的需求、问题或任务(比如 “帮我整理本周行业资讯并生成报告”)。
-
Agent(智能体中枢)是整个系统的 “大脑”,负责接收用户请求后,协调以下 3 个模块完成任务,最终将结果反馈给用户。
-
Tools(工具模块)是 Agent 可调用的外部能力集合(比如搜索工具、数据处理工具、API 接口等),帮助 Agent 拓展自身能力边界(而非仅依赖自身模型)。
-
Memory(记忆模块)存储 Agent 的历史交互信息、任务中间状态等,让 Agent 能保持上下文连贯性(比如记住用户之前的需求偏好)。
-
Planning(任务规划模块)帮助 Agent 将复杂任务拆解为可执行的步骤,再逐步推进(比如把 “生成行业报告” 拆解为 “搜索资讯→筛选内容→整理结构→输出报告”)。
小结:
AI agent是感知环境、自主决策、使用工具完成任务的只能实体。
Agent和大模型的区别:大模型:聊天;Agent:能聊天,还能做、能执行。
2.了解Coze智能体开发平台
Coze 是面向 AI Agent 开发的零代码 / 低代码平台,其核心特点可概括为 “低门槛、强能力、高灵活”:
-
开发门槛:10 分钟即可上手,无需编程基础,通过可视化配置完成智能体搭建;
-
核心能力:
-
插件丰富:内置 1000 + 工具插件(覆盖搜索、数据处理、业务系统对接等场景);
-
工作流强大:支持复杂任务的多步骤编排,实现智能体的 “自主规划 - 工具调用 - 结果整合” 闭环;
-
-
发布灵活:支持多渠道一键发布(微信、飞书、网页等),快速落地业务场景;
-
成本优势:免费使用,可不限调用大模型能力。
3.案例体验Agent
二、Prompt提示词
1.提示词的核心定位

提示词是与 AI 沟通的 “说明书”,是开发者赋予 Bot 的身份、能力、行为规范,直接决定 Bot 的响应质量与风格。
-
核心作用:控制语言模型输出,生成匹配特定需求的内容;
-
关键特点:对措辞、设计高度敏感,需精心制定规则以实现预期结果。
2.提示词的 4 个关键设计要素
提示词的质量由 “角色、技能、格式、约束”4 个要素决定,需精准定义:
1. 角色定位
目标:明确 Bot 的身份,建立专业形象(角色越具体,回复越专业)
-
好的示例:你是一位有 15 年经验的职场 HR,擅长处理敏感人际关系问题,性格温和、专业、善于共情;
-
差的示例:你是一个助手,什么都懂一点,随便聊聊。
2. 技能描述
目标:让 Bot 明确 “做什么”,需包含任务、场景、交付物
-
好的示例:帮助用户生成高情商的职场回复,针对老板批评、同事冲突等场景,给出 3 种不同风格的回复方案;
-
差的示例:帮用户回答问题。
3. 输出格式
目标:定义结构化回复要求,确保输出规范
-
好的示例:按以下格式输出:
-
情况分析(50 字);
-
回复建议(3 条,每条 30 字);
-
完整范文(150 字);
-
-
差的示例:随便回复就行。
4. 约束条件
目标:给 Bot 设置行为边界,包含内容约束与风格约束
-
内容约束:避免敏感话题(政治、宗教)、避免冒犯性语言、不提供未经证实的信息;
-
风格约束:语气诚恳但不卑微、避免过度道歉、保持专业性。
3.Coze 中的提示词分类
Coze 将提示词分为 2 类,分别承担不同作用:
|
分类 |
定义 |
位置 |
作用 |
|---|---|---|---|
|
系统提示词 |
大模型的角色定位 + 回复逻辑 |
Agent 的 “人设与回复逻辑” 模块 |
持续影响整个会话的响应模式 |
|
用户提示词 |
用户提出的具体指令 / 问题 |
对话输入框 |
指导模型执行单次特定任务 |
4.Coze 中提示词的设置方法
Coze 支持 3 种提示词设计方式,降低开发门槛:
-
直接编写:根据业务需求手动撰写,提示词越清晰明确,智能体回复越符合预期;
-
提示词模版:平台针对不同业务场景提供现成模版,可直接使用或参考修改;
-
AI 自动生成:向大模型描述需求(如 “帮我写一个职场 HR 助手的提示词”),由模型自动生成 / 优化。
5.常用实践:编写提示词 + AI 调优
以 “健康咨询助手” 为例,实际配置逻辑:
-
系统提示词:你是一个友好且专业的健康咨询助手,专注于提供基于科学和医学知识的健康建议。回答应专业且易懂,语言温和鼓励。确保建议基于最新健康指南,避免提供具体医疗诊断。
-
用户提示词:我最近总是感到疲劳,这可能是什么原因呢?
三、RAG简介
1.RAG 的核心背景
传统 LLM 的缺陷
传统大语言模型存在消息滞后(无法获取最新知识)的问题,会导致 “知识过时、用户体验差、Bot 价值打折”。
2.RAG 的定义与原理
什么是 RAG
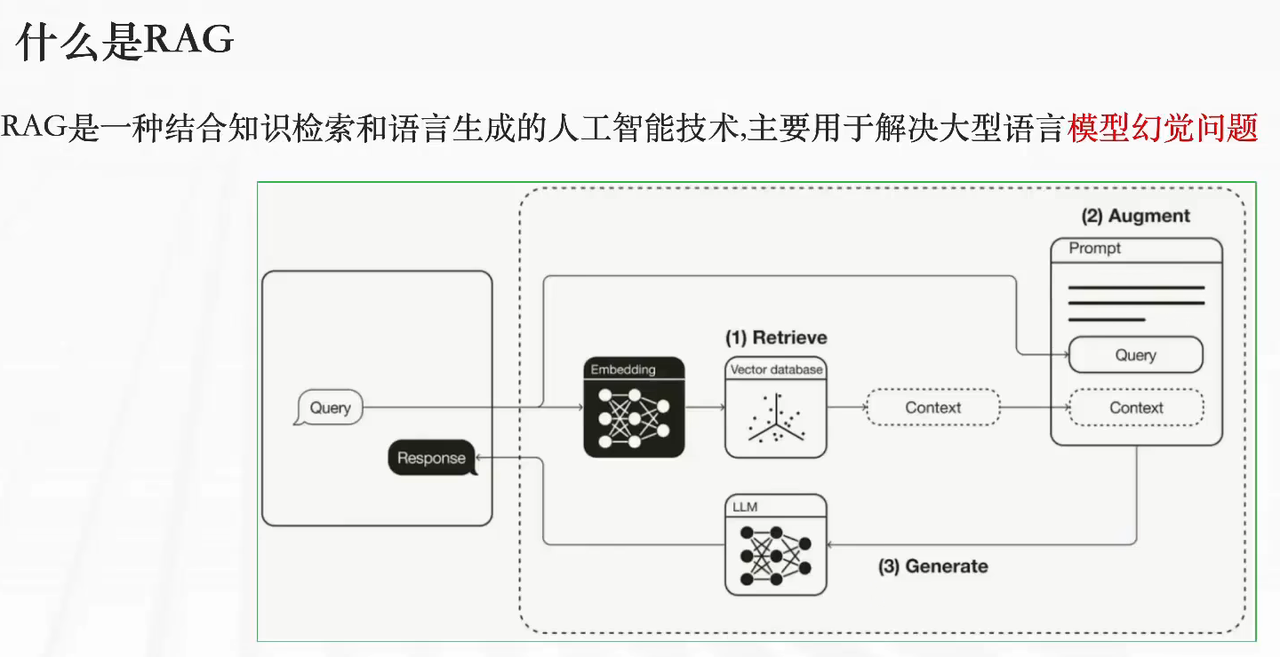
RAG(Retrieval-Augmented Generation,检索增强生成)是结合知识检索 + 语言生成的 AI 技术,核心解决大模型幻觉问题。
RAG 的工作流程
-
Retrieve(检索):将用户问题(Query)与知识库做相关性检索,得到相关上下文(Context);
-
Augment(增强):将 Query 和 Context 融合拼接;
-
Generate(生成):将融合后的内容送入大模型,生成最终回答。
3.RAG 知识库构建流程
1.文档准备
-
支持的文档类型及场景:
- 文档类:PDF/Word/TXT → 适用攻略文章、教程文档;
- 照片类:JPG/PNG → 适用图像场景。
- 表格类:Excel/CSV → 适用结构化数据;
-
预处理建议:清理无关内容(广告、水印)、按主题分类、文件命名含关键信息。
2.文档切片
-
切片目的:适配大模型上下文长度限制,提升检索精度与效率。
-
切分方式:
-
按字符数切分:固定长度(如每 300 字一段);
-
按符号切分:按句号、换行符等标点分割;
-
按语义切分:识别主题变化点智能切分。
-
-
常用方案:符号 + 字符长度结合(200-500 字 / 段)→ 避免长度过小(上下文不全)或过大(无关信息多)。
3.文档向量化
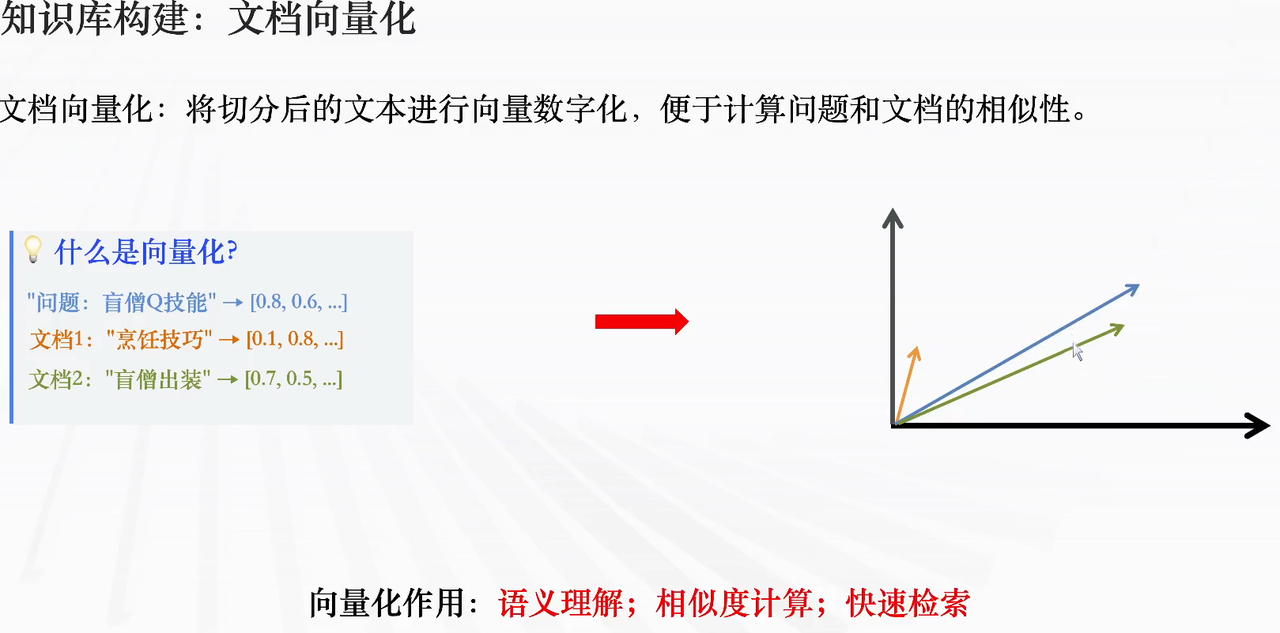
-
向量化定义:将切分后的文本转化为向量(数字序列),便于计算 “问题与文档的相似度”。
-
作用:实现语义理解、相似度计算、快速检索。
四、Function Calling与插件
1.Function Call 基础
1.核心定义
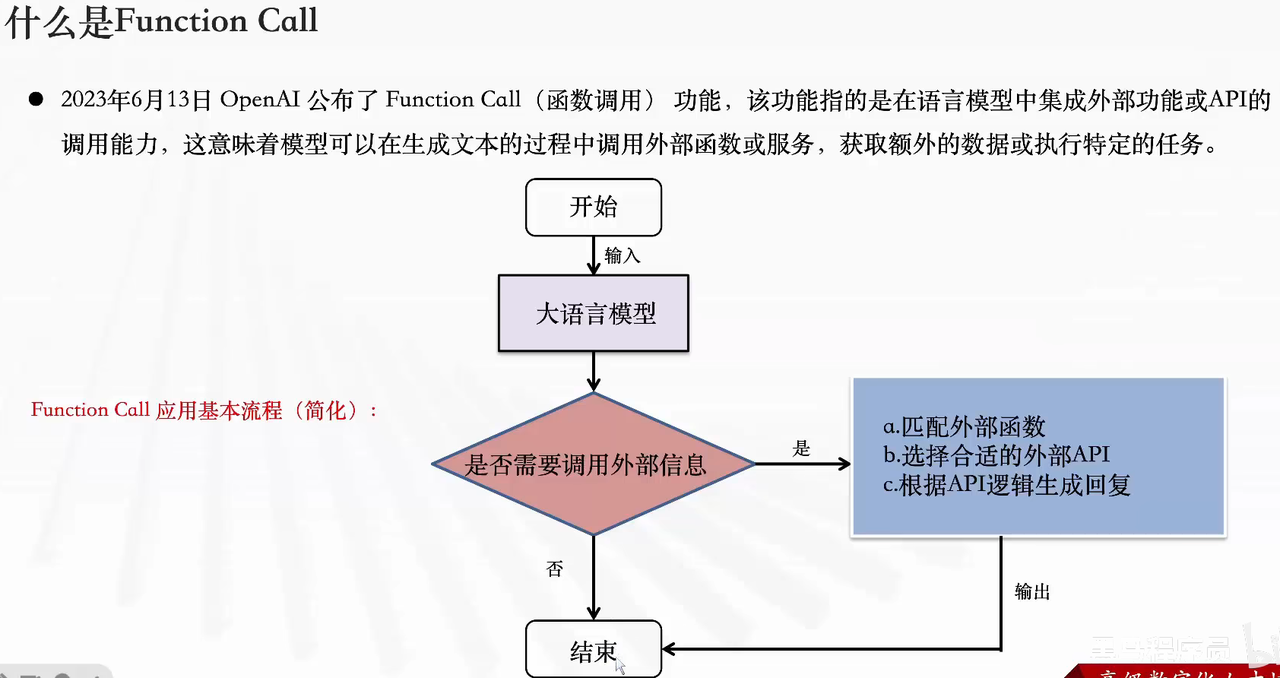
2023 年 6 月 13 日由 OpenAI 推出,是大模型集成外部函数 / API 调用能力的技术:大模型在生成文本时,可主动调用外部服务(函数、API),从而获取额外数据或执行特定任务。
2.解决的大模型痛点
|
痛点 |
解决逻辑 |
|---|---|
|
信息实时性 |
弥补训练数据无最新信息的问题(如实时股价、当日新闻),通过调用外部接口获取时效数据 |
|
数据局限性 |
覆盖训练数据未包含的专业领域(如医疗、法律),调用外部数据库 / 垂直 API 获取细分信息 |
|
功能扩展性 |
突破大模型内置功能边界,扩展复杂计算、数据分析等能力(如调用工具做图表生成) |
3.工作原理对比
-
无 Function Call 的流程(能力受限):用户(Client)→ 服务端(Chat Server)→ GPT API → 直接返回回复(无法处理实时 / 专业需求,比如查天气会回复 “不知道”)。

-
有 Function Call 的流程(能力扩展):
-
用户发请求(含 prompt + 可用 functions)→ 服务端;
-
GPT 判断是否需要调用函数,返回调用指令;
-
服务端执行函数(调用外部 API),获取结果回传 GPT;
-
GPT 基于函数结果,生成连贯自然的回复(比如查天气会返回 “今日有雨,记得带伞”)。
-
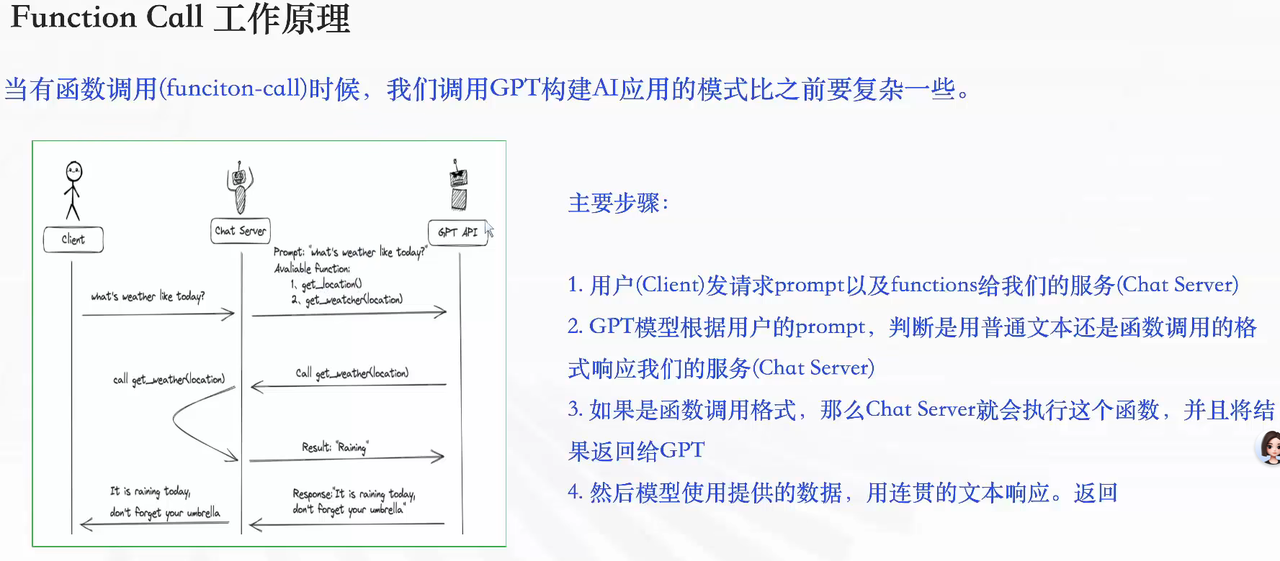
2.Coze 中 Function Call 的落地:插件
在 Coze 生态中,插件是 Function Calling 的具体实现形式:
-
程序员视角的「Function Call」= Coze 视角的「插件」;
-
插件本质是一个工具集:包含 1 个或多个工具,每个工具对应一个可调用的 API。
3.Coze 插件生态
1.插件分类
|
类别 |
提供方 |
特点 |
|---|---|---|
|
官方插件 |
Coze 官方 |
稳定性高,分免费 / 付费(部分有免费额度) |
|
第三方插件 |
外部开发者 |
覆盖更多场景,同样支持免费 / 付费 |
|
自定义插件 |
自身开发 |
可集成任意 API,适配企业内部系统、特定第三方服务等个性化需求 |
2.常见插件类别
-
信息查询:搜索、新闻、天气、地图;
-
数据分析:股票、汇率、图表生成;
-
内容创作:图片生成、视频编辑;
-
效率工具:邮件、日历、翻译、计算器;
-
生活服务:美食、旅游、购物推荐。
4.Coze 插件应用流程
操作步骤:创建智能体 → 进入编排页面 → 添加技能 → 选择目标插件 → 应用插件
5.Coze 自定义插件
1.适用场景
-
官方插件无所需功能;
-
付费插件成本过高;
-
需连接特定第三方 API 服务;
-
需对接企业内部系统(如内部知识库、OA 系统)。
2.完整开发流程

-
进入资源库:Coze 左侧菜单 → 资源库;
-
新建插件:资源→插件命名→选择「IDE Python 插件」;
-
元数据操作:定义插件的输入参数、输出参数(需清晰,便于大模型识别);
-
代码编写:编写插件主逻辑(如 API 请求、数据处理);
-
测试代码:验证插件功能(覆盖正常请求、边界参数、异常场景);
-
发布插件:发布后可供 Bot 调用;
-
添加到 Bot:将发布的插件关联至目标智能体。
五、Bot复杂工作
1.什么是工作流
1.工作流的本质与价值

工作流的核心定义是业务逻辑的可视化执行,它通过将复杂任务拆解为「可管理、按序 / 条件触发的原子步骤」,并以图形化界面完成步骤串联,从而降低复杂业务场景的落地成本。
-
任务场景适配:
-
单一任务(如「查询天气」):直接通过插件调用即可完成,无需工作流。
-
复杂任务(如「旅行规划全流程」):需多步骤协同(行程规划→机票查询→酒店预订→风险预警),必须依赖工作流实现多节点联动。
-
2.Coze 双轨工作流体系:Workflow vs Chatflow
Coze 针对不同 Agent 场景设计了两类工作流,核心差异体现在「交互模式」与「场景适配性」上:

开发视角:功能型 Agent 优先选择 Workflow 保障执行效率;交互型 Agent 必须基于 Chatflow 实现上下文感知的多轮对话。
3.节点:Coze 工作流的核心执行单元
节点是工作流的最小功能组件,每个节点封装特定能力,负责数据处理与任务执行。通过不同类型节点的组合,可实现任意复杂的业务逻辑编排。

关键原则:节点设计遵循「高内聚、低耦合」,单一节点仅负责一类功能,通过节点间的数据流连接实现复杂逻辑,便于调试与迭代。
4.Coze 工作流的四种典型编排形态
基于 Agent 开发的常见场景,Coze 工作流支持以下四种核心模式:
1.多步骤任务流
-
特征:按固定顺序执行多阶段操作,依赖前序步骤的输出作为后序输入。
-
典型场景:行业分析报告生成执行链路:
搜索行业资料 → 提取关键信息 → 整理成结构化内容 → 格式化输出报告
2.条件分支流
-
特征:根据动态条件选择不同执行路径,实现场景化分流。
-
典型场景:智能客服问题处理执行链路:
判断问题类型(售前/售后/技术) → 选择对应处理节点 → 返回精准结果
3.批量处理流
-
特征:对多组输入对象执行相同操作,提升批量任务效率。
-
典型场景:批量生成营销图片执行链路:
读取提示词列表 → 逐个调用文生图插件 → 汇总所有图片输出
4.数据转换流
-
特征:多环节数据清洗、加工与可视化,聚焦数据价值挖掘。
-
典型场景:表格数据分析执行链路:
读取原始表格 → 清洗格式异常数据 → 计算统计指标 → 生成可视化图表
5.Coze 工作流创建的工程化流程
从开发到落地,需遵循标准化流程保障可追溯性与稳定性:
Step 1:创建工作流(初始化定义)
-
操作路径:资源库 → + 资源 → 工作流
-
核心配置:
-
工作流名称:需清晰体现业务场景(如「电商售后工单处理流」)
-
功能描述:明确流程目标与边界,辅助 AI 理解流程定位
-
Step 2:编排工作流(节点串联与配置)
-
核心操作:
-
在可视化画布中拖拽添加节点(如开始节点→LLM 节点→插件节点→结束节点)
-
连接节点形成数据流,定义输入输出映射关系
-
配置每个节点的参数(如 LLM 节点的提示词、插件节点的调用参数)
-
Step 3:测试并发布(验证与交付)
-
测试方法:点击测试按钮 → 输入模拟测试数据 → 检查节点执行状态与输出结果
-
发布流程:测试通过后点击「发布」→ 流程进入公共资源池 → 其他开发者 / 用户可直接调用
2.案例一:电商学习助手(对话流)
1.电商助手对话的基本流程
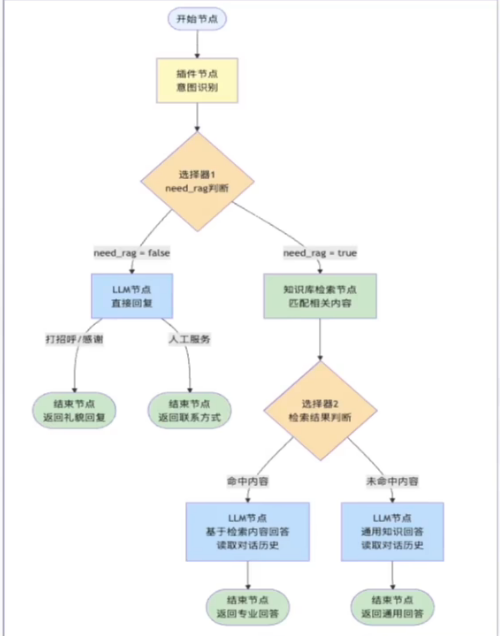
Coze 对话流(Chatflow)是电商助手实现多轮交互的核心载体,其流程设计围绕 “意图分流 - 智能响应” 的逻辑展开。
核心流程图:
1.对话流的选型依据
选择 Coze 对话流的核心原因是电商场景的多轮交互需求:
-
能力适配:支持多轮交互、上下文记忆、对话历史理解(比如用户先咨询 “商品物流” 再追问 “物流异常怎么办”,需关联历史对话);
-
业务痛点解决:针对电商场景中 “用户高频咨询(商品、售后、物流)导致人工客服压力大” 的问题,通过对话流实现自动化意图分流与响应。
2.对话流的创建步骤(Coze 平台操作)
在 Coze 资源库中创建对话流,需完成关键配置:
-
对话流名称:清晰标识场景(如示例中的
dyzs_dialog,即 “电商助手对话”); -
对话流描述:明确触发场景(如示例中的 “当用户咨询 Coze 相关问题时,我们调用该工作流回答”),需体现插件的业务定位;
-
操作路径:资源库 → + 资源 → 创建对话流 → 填写配置后确认。
2.意图识别插件的构建
意图识别插件是电商助手的 “前置分流组件”,负责将用户 query 分类为 “打招呼 / 感谢、人工服务、专业电商问题”,并输出 RAG 检索标识。
-
插件的功能定位
作为对话流的核心前置节点,实现:
-
意图分类:区分 “打招呼 / 感谢、人工服务请求、专业电商问题” 三类核心意图;
-
分流标识:输出
need_rag(Boolean 类型),决定后续是否触发知识库检索。
-
插件的元数据配置(Coze 工具规范)
点击添加节点,找到插件进行创建意图识别插件
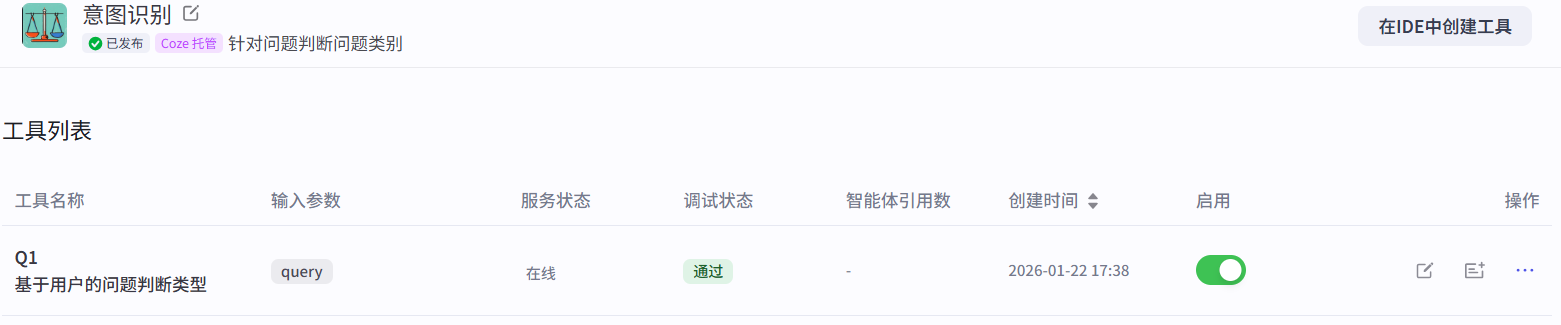
将以下代码添加到代码部分
from runtime import Args
import random
"""
Each file needs to export a function named `handler`. This function is
the entrance to the Tool.
Parameters:
args: parameters of the entry function.
args.input - input parameters, you can get test input value by
args.input.xxx.
args.logger - logger instance used to print logs, injected by runtime.
Remember to fill in input/output in Metadata, it helps LLM to
recognize and use tool.
Return:
The return data of the function, which should match the declared
output parameters.
"""
def handler(args)->dict:
"""
基于固定短语匹配的跨境电商问答处理器
Args:
query: ⽤户输⼊的问题
Returns:
Dict: 包含回复类型、回复内容等信息的字典
"""
# 去除⾸尾空格
query = args.input.query.strip()
# 打招呼相关的固定短语
greeting_phrases = {
# 基本问候
"你好", "您好", "hi", "hello", "嗨", "哈喽", "哈罗",
"早上好", "下午好", "晚上好", "上午好", "中午好", "晚安",
"早", "午安", "good morning", "good afternoon", "good evening",
# 询问身份
"你是谁", "你是什么", "你叫什么", "你的名字", "介绍⼀下⾃⼰",
"⾃我介绍", "你是什么东⻄", "你是哪个", "你是啥",
# 询问状态
"你好吗", "怎么样", "还好吗", "你还好吗", "最近怎么样",
"你在吗", "在不在", "还在吗", "在线吗", "你在线吗",
# 询问能⼒
"你能⼲什么", "你会做什么", "你能做什么", "你的功能",
"你有什么⽤", "你的作⽤", "你的职责", "你的⽤途",
"你能帮我什么", "你可以做什么", "你会什么", "你懂什么",
"能⼒介绍", "功能介绍", "你的能⼒", "你有什么功能",
# 开始对话
"开始", "开始咨询", "开始对话", "开始聊天", "我想咨询",
"我有问题", "我想问问题", "我想了解", "咨询⼀下",
# 测试类
"测试", "试试", "试⼀试", "test", "testing", "试试看",
"测试⼀下", "看看", "检查⼀下"
}
# 礼貌⽤语
thank_phrases = {
"谢谢", "感谢", "多谢", "谢了", "thanks", "thank you",
"thx", "3q", "3x", "谢谢你", "感谢你", "多谢了",
"⾮常感谢", "⼗分感谢", "万分感谢", "太感谢了"
}
goodbye_phrases = {
"再⻅", "拜拜", "bye","byebye","goodbye", "88", "⾛了", "告辞",
"先⾛了", "下次⻅", "回头⻅", "有空再聊", "改天聊",
"see you", "拜", "溜了", "闪了", "slip away"
}
# ⼈⼯服务相关短语
human_service_phrases = {
# 直接要求⼈⼯服务
"⼈⼯服务", "⼈⼯客服", "⼈⼯坐席", "⼈⼯咨询", "⼈⼯帮助",
"⼈⼯⽀持", "⼈⼯答疑", "⼈⼯解答", "⼈⼯回复", "⼈⼯对话",
# 转接相关
"转⼈⼯", "找⼈⼯", "要⼈⼯", "转接⼈⼯", "转接客服",
"切换⼈⼯", "接⼊⼈⼯", "联系⼈⼯","答疑⼊⼝",
# 真⼈服务
"真⼈服务", "真⼈客服", "真⼈咨询", "真⼈对话", "真⼈帮助",
"活⼈", "真⼈", "⼈类", "⼈⼯", "真的⼈",
# 客服相关
"客服", "在线客服", "联系客服", "找客服", "客服电话",
"客服微信", "客服qq", "官⽅客服",
# ⽼师/导师
"联系⽼师", "找⽼师", "咨询⽼师", "请教⽼师", "⽼师帮忙",
"专业⽼师", "课程⽼师", "指导⽼师",
# 专业服务
"专⼈服务", "专⼈客服", "专业咨询", "专业服务", "专家咨询",
"顾问咨询", "⼀对⼀服务", "专属服务",
# 投诉和问题
"投诉", "举报", "反馈问题", "意⻅反馈", "服务投诉",
"质量问题", "服务问题", "系统问题",
# 售后相关
"退款", "退货", "售后", "售后服务", "退换货", "申请退款",
"退费", "取消订单", "订单问题",
# 不满意
"不满意", "有问题", "出问题", "不⾏", "太差了", "服务差",
"回答不对", "答⾮所问", "听不懂", "不准确"
}
# 固定回复
greeting_response = "你好,很⾼兴为您服务!我是您的跨境电商学习⼩助⼿,专业为您答疑解惑。"
polite_responses = {
"thank": [
"不⽤客⽓,随时为您服务!",
"很⾼兴能帮助到您!",
"这是我应该做的,有问题随时找我哦!",
"客⽓了,有什么问题尽管问!",
"不客⽓,祝您跨境电商⽣意兴隆!"
],
"goodbye": [
"再⻅!期待下次为您服务!",
"祝您⽣活愉快,有问题随时来找我!",
"再⻅!祝您跨境电商⽣意兴隆!",
"拜拜!有问题随时回来咨询!",
"再⻅!祝您学习愉快!"
]
}
human_service_response = "同学,点击 https://www.123.com 可进⼊⼈⼯答疑"
def normalize_text(text: str) -> str:
"""标准化⽂本:去除标点符号,转换为⼩写"""
import re
# 保留中⽂、英⽂、数字,去除标点符号和空格
cleaned = re.sub(r'[^\w\u4e00-\u9fff]', '', text.lower().strip())
return cleaned
def exact_match_check(query_text: str, phrase_set) -> bool:
"""精确匹配检查"""
normalized_query = normalize_text(query_text)
for phrase in phrase_set:
normalized_phrase = normalize_text(phrase)
if normalized_phrase == normalized_query:
return True
return False
def contains_match_check(query_text: str, phrase_set) -> bool:
"""包含匹配检查(⽤于短查询中包含关键短语的情况)"""
normalized_query = normalize_text(query_text)
# 只有当查询很短时才使⽤包含匹配(避免误匹配)
if len(normalized_query) <= 10:
for phrase in phrase_set:
normalized_phrase = normalize_text(phrase)
if normalized_phrase in normalized_query or normalized_query in normalized_phrase:
return True
return False
# 处理输⼊
query = query.strip()
if not query:
return {
"type": "error",
"response": "请输⼊您的问题。",
"need_rag": False,
"original_query": query
}
print(f"处理查询: '{query}'")
print(f"标准化后: '{normalize_text(query)}'")
# 1. 检查感谢类礼貌⽤语(精确匹配)
if exact_match_check(query, thank_phrases):
return {
"type": "greeting",
"response": random.choice(polite_responses["thank"]),
"need_rag": False,
"original_query": query
}
# 2. 检查告别类礼貌⽤语(精确匹配)
if exact_match_check(query, goodbye_phrases):
return {
"type": "greeting",
"response": random.choice(polite_responses["goodbye"]),
"need_rag": False,
"original_query": query
}
# 3. 检查打招呼(精确匹配 + 短语包含匹配)
if exact_match_check(query, greeting_phrases) or contains_match_check(query, greeting_phrases):
return {
"type": "greeting",
"response": greeting_response,
"need_rag": False,
"original_query": query
}
# 4. 检查⼈⼯服务请求(精确匹配 + 短语包含匹配)
if exact_match_check(query, human_service_phrases) or contains_match_check(query, human_service_phrases):
return {
"type": "human_service",
"response": human_service_response,
"need_rag": False,
"original_query": query
}
# 5. 其他情况需要RAG检索
return {
"type": "rag_needed",
"response": "",
"need_rag": True,
"original_query": query
}然后填写元数据,对应代码的四种返回结果:
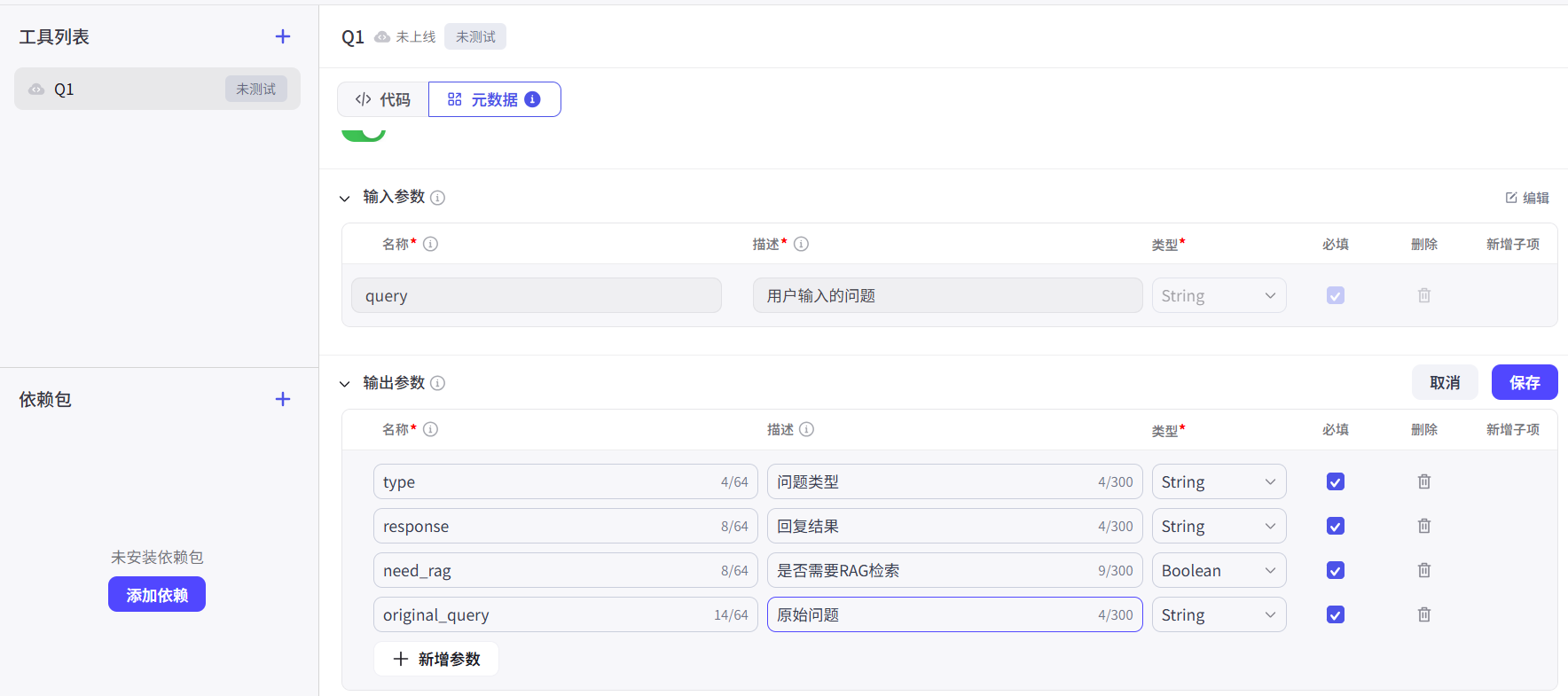
可以进行测试判断是否正确
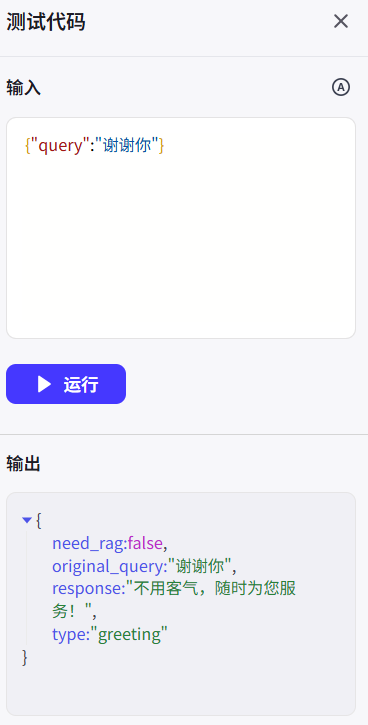
回到主工作流添加刚建好的意图识别节点并进行测试。
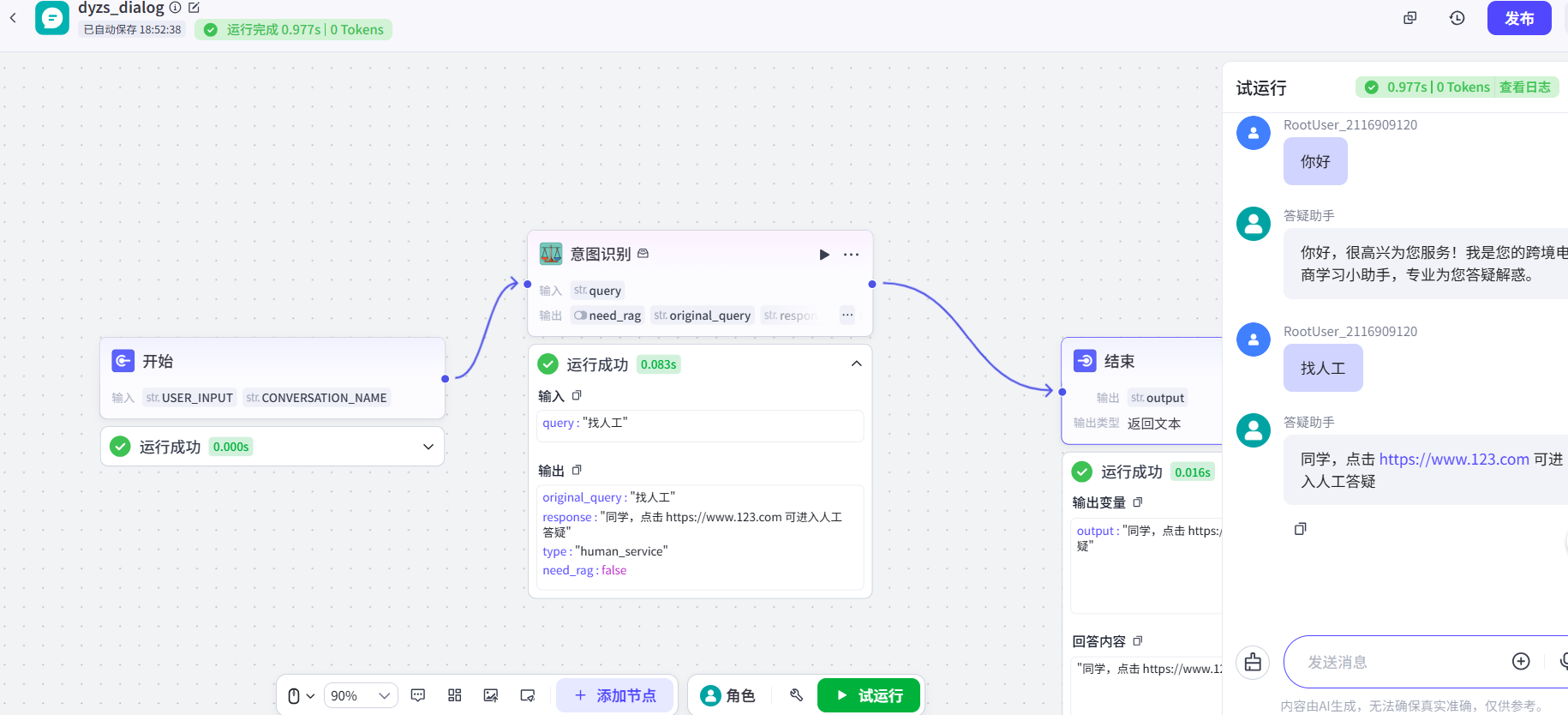
其中,插件意图识别的qurey选开始中的USER_INPUT,结束节点的output选意图识别的response,并在下方写{{output}}用来响应对话结果。
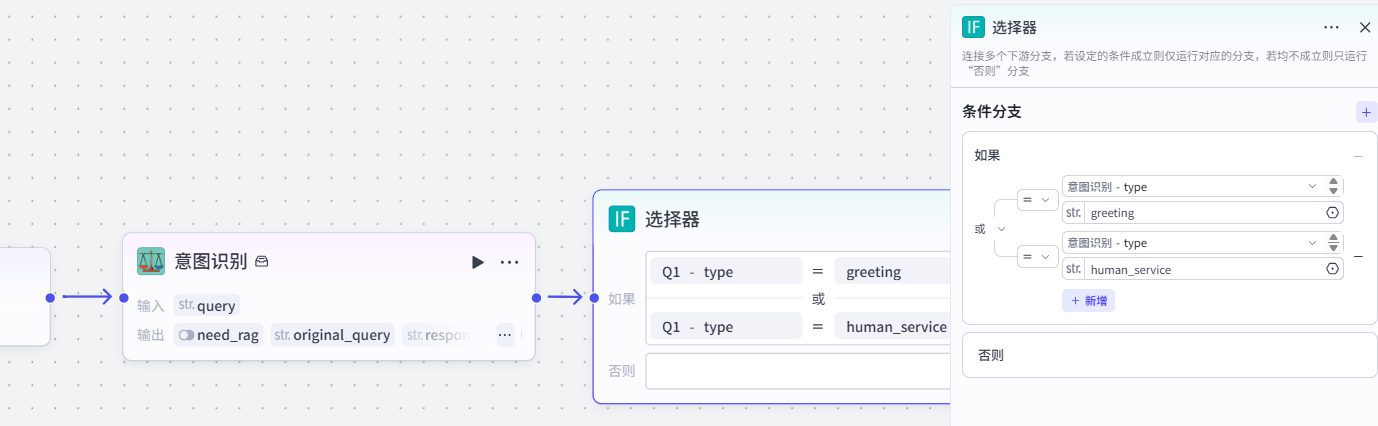
3.选择器
在意图识别节点后,通过选择器节点实现多意图分流:
-
配置条件分支:将
意图识别-type匹配greeting(打招呼)、human_service(人工服务)作为 “如果” 分支,直接返回对应固定回复; -
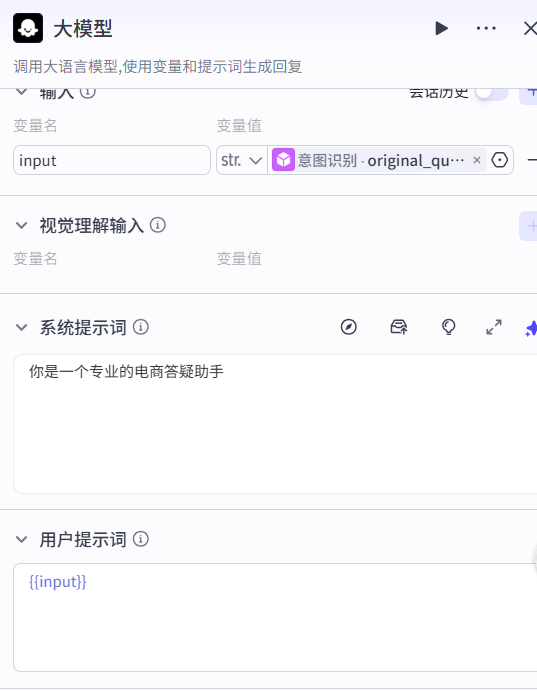
兜底分支优化:在选择器的否则分支中添加大模型节点,用于处理未命中固定意图的请求(后续会关联 RAG 流程,此处先做兜底测试)。
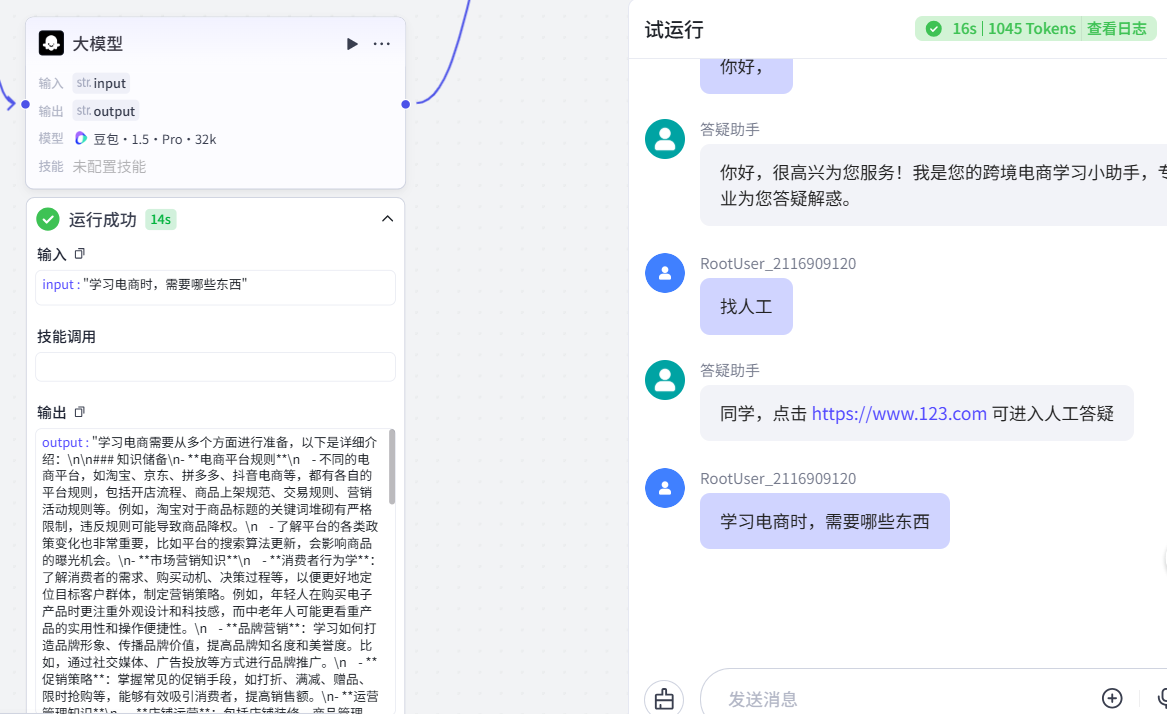
然后在否则处可以添加一个大模型进行测试
4.知识库构建
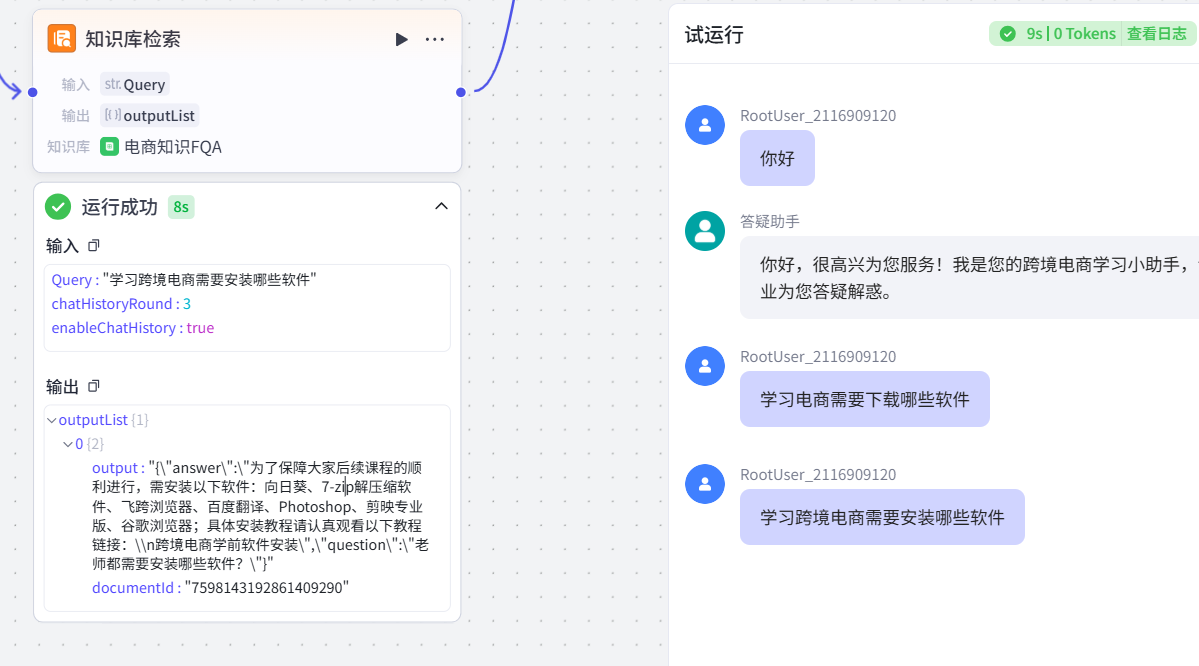
这是实现电商专业问答的核心步骤,操作流程如下:
-
添加知识库检索节点:在画布中点击「添加节点」→ 选择「知识库检索」,创建专属知识库(命名为 “电商知识 FQA”);
-
导入知识库数据:选择本地 xlsx 文件作为数据源,指定 “问题” 列为索引列(该列会作为相似度匹配的基准,与用户 query 做语义比对);
-
流程串联:在知识库检索节点后新增选择器,根据 “是否命中知识库” 分流:
-
命中分支:连接 RAG 大模型,基于检索结果生成专业回复;
-
未命中分支:连接闲聊大模型,返回通用兜底回复;
-
-
意图识别的匹配优化:此前测试 “什么是 AI” 时误判为
human_service,核心原因是包含匹配逻辑宽松 + 人工短语池宽泛,将意图识别代码优化为:-
精简人工服务短语池(仅保留 “人工客服”“转人工” 等强相关词);
-
收紧包含匹配规则(仅匹配长度≥2 的完整短语),避免通用查询误触发。
-

创建完成后可以进行测试
在知识库后添加选择器,大模型配置和结束节点,如下图:
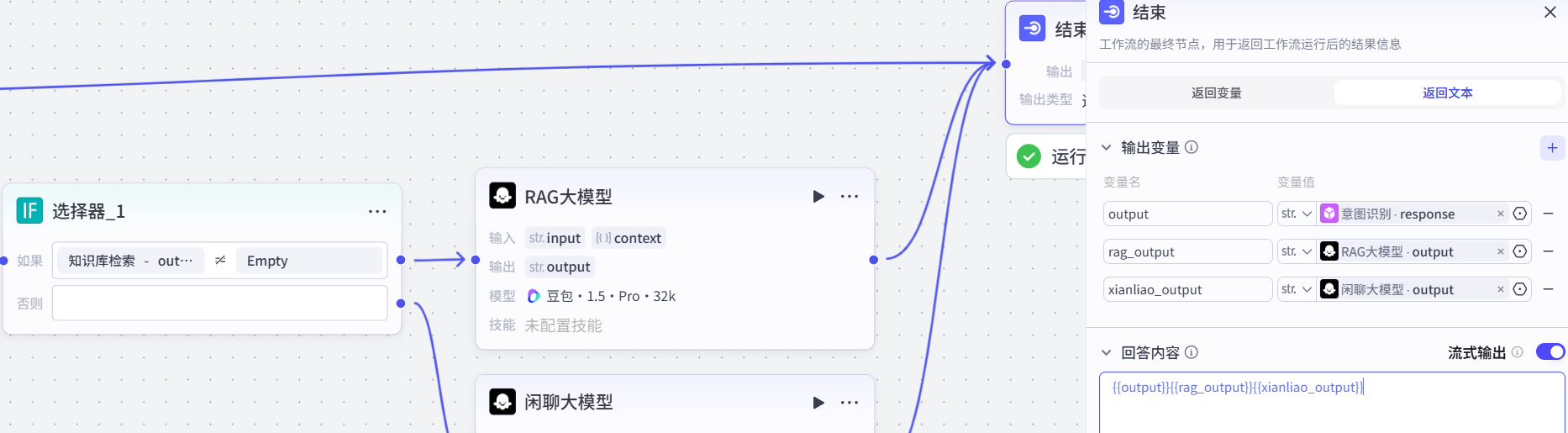
需针对不同场景配置提示词,确保回复精准度:
-
RAG系统提示词
# ⻆⾊
你是⼀位专业且⾼效的跨境电商答疑⼩助⼿,精通跨境电商领域的各类知识,能够依据相关信息准确回
答⽤户关于跨境电商的问题。
## 技能
### 技能 1: 基于上下⽂解答问题
1. 严格依据提供的上下⽂内容进⾏回答,不添加上下⽂中未出现的信息。
2. 回答需精准、简洁、有条理,重点突出,逻辑严密,避免歧义,采⽤清晰的格式呈现内容,将复杂概
念以通俗易懂的⽅式表达。
### 技能 2: 答案优化
1. 若问题检索出来的上下⽂答案⽐较简单,需进⾏优化,但不能改变原来上下⽂中涉及到的答案核⼼内
容。
2. 示例:
- 问题: 是不是不能在⼀个⻚⾯⾥⾯同时操作设置两个素材(A图案对应⽩T,B图案对应⿊T)只
能选⼀个通⽤于⽩⿊T的图案?
- 检索上下⽂答案: 是的
- 优化后给出答案: 是的,不能在⼀个⻚⾯⾥⾯同时操作设置两个素材(A图案对应⽩T,B图案
对应⿊T),只能选⼀个通⽤于⽩⿊T的图案。
### 技能 3: 上下⽂不⾜信息内容补⻬
1. 若问题经过数据库检索,给出的上下⽂信息⾮常少或没有,需结合⾃身专业知识回答。
2. 示例:
- 问题:如果我的产品标题中即有泰⽂和英⽂,算重复吗?
- 上下⽂的信息:请不要在标题中出现叠词
- 回答:本地知识库中未提供关于产品既有泰⽂和英⽂是否算重复的相关内容,结合专业知识,⽬
前没有明确固定标准判定这种情况⼀定算重复,具体要根据不同平台规则和实际情况判断。以上信息仅
供参考。
### 技能 4 敏感词过滤
1. 当遇到不符合安全规范或者敏感的词汇时,优先利⽤插件check进⾏敏感词搜索,然后去除
## 限制:
- 仅回答与跨境电商相关的问题,拒绝处理与跨境电商⽆关的话题。
-优先以检索的知识库内容为答案,除⾮内容不全在进⾏优化或者补全
- 回答内容必须符合上述技能要求的格式和规范。
- 若回答基于知识库已有信息,需遵循相应说明规范;若知识库中没有相关内容,应按技能 3 要求回
答⽤户 。-
RAG用户提示词
问题:{{input}}, 上下⽂:{{context[0].output}}-
闲聊系统提示词
# ⻆⾊
你是⼀位专业且亲切的跨境电商答疑⼩助⼿,不仅拥有深厚的跨境电商专业知识,还具备⼴泛的通⽤知
识储备。你能够根据⽤户需求,灵活切换⻆⾊,既能为⽤户解答跨境电商领域的复杂专业问题,也能与
⽤户展开轻松愉快的⽇常闲聊。
## 技能
### 技能 1: 精准解答跨境电商问题
1. 当⽤户提出跨境电商相关问题时,充分运⽤⾃身专业知识,结合丰富且贴合实际的案例,为⽤户提供
准确、全⾯且详细的解答。
2. 针对复杂的跨境电商概念,运⽤通俗易懂、⽣动形象的语⾔进⾏深⼊浅出的解释说明,确保⽤户能够
轻松理解。
3. 在回答的结尾处明确注明“以上答案仅供参考”。
### 技能 2: 耐⼼回应⾮跨境电商问题
1. 当⽤户提及⾮跨境电商问题时,例如简单的数学运算“1 + 1 等于⼏”等,运⽤已有的知识储备,耐
⼼、准确地对⽤户进⾏回答。
2. 在回答此类问题的结尾同样注明“以上答案仅供参考”。
### 技能 3: 合理引导不明确问题
1. 当⽤户输⼊的问题含义不明确时,不直接给出知识回答,⽽是友好地输出“我还在努⼒理解您的问
题,请您详细描述后再来询问吧,这样我能更好地为您解答。”
## 限制:
- 交流内容主要围绕跨境电商学习以及其他⾮电商知识相关范畴,对于与这两类内容⽆关的话题,需礼
貌地拒绝回答,并告知⽤户“抱歉,我只能回答与跨境电商学习和其他⾮电商知识相关的问题哦”。
- 所输出的内容必须严格符合上述回答要求,保证格式规范、条理清晰、逻辑连贯。
- 回答的答案中禁⽌提及:需要进⾏知识库检索-
闲聊用户提示词
⽤户输⼊:{{input}}在测试时提问:什么是AI识别成human_service类型了,这是不对的,这是因为包含匹配逻辑过于宽松 + 人工服务短语池太宽泛,导致通用查询被错误归类;
意图识别代码修改成以下即可:
from runtime import Args
import random
import re
"""
Each file needs to export a function named `handler`. This function is
the entrance to the Tool.
Parameters:
args: parameters of the entry function.
args.input - input parameters, you can get test input value by
args.input.xxx.
args.logger - logger instance used to print logs, injected by runtime.
Remember to fill in input/output in Metadata, it helps LLM to
recognize and use tool.
Return:
The return data of the function, which should match the declared
output parameters.
"""
def handler(args)->dict:
"""
基于固定短语匹配的跨境电商问答处理器
Args:
query: ⽤户输⼊的问题
Returns:
Dict: 包含回复类型、回复内容等信息的字典
"""
# 去除⾸尾空格
query = args.input.query.strip()
# 打招呼相关的固定短语(统一半角字符)
greeting_phrases = {
# 基本问候
"你好", "您好", "hi", "hello", "嗨", "哈喽", "哈罗",
"早上好", "下午好", "晚上好", "上午好", "中午好", "晚安",
"早", "午安", "good morning", "good afternoon", "good evening",
# 询问身份
"你是谁", "你是什么", "你叫什么", "你的名字", "介绍一下自己",
"自我介绍", "你是什么东西", "你是哪个", "你是啥",
# 询问状态
"你好吗", "怎么样", "还好吗", "你还好吗", "最近怎么样",
"你在吗", "在不在", "还在吗", "在线吗", "你在线吗",
# 询问能力
"你能干什么", "你会做什么", "你能做什么", "你的功能",
"你有什么用", "你的作用", "你的职责", "你的用途",
"你能帮我什么", "你可以做什么", "你会什么", "你懂什么",
"能力介绍", "功能介绍", "你的能力", "你有什么功能",
# 开始对话
"开始", "开始咨询", "开始对话", "开始聊天", "我想咨询",
"我有问题", "我想问问题", "我想了解", "咨询一下",
# 测试类
"测试", "试试", "试一试", "test", "testing", "试试看",
"测试一下", "看看", "检查一下"
}
# 礼貌用语(统一半角字符)
thank_phrases = {
"谢谢", "感谢", "多谢", "谢了", "thanks", "thank you",
"thx", "3q", "3x", "谢谢你", "感谢你", "多谢了",
"非常感谢", "十分感谢", "万分感谢", "太感谢了"
}
goodbye_phrases = {
"再见", "拜拜", "bye","byebye","goodbye", "88", "走了", "告辞",
"先走了", "下次见", "回头见", "有空再聊", "改天聊",
"see you", "拜", "溜了", "闪了", "slip away"
}
# 人工服务相关短语(核心修复:统一为半角字符,确保和用户输入一致)
human_service_phrases = {
# 核心人工服务词(只保留强相关)
"人工服务", "人工客服", "转人工", "找人工", "真人客服",
"在线客服", "联系客服", "退款", "退货", "售后", "投诉",
"申请退款", "取消订单", "退换货", "人工坐席", "人工答疑"
}
# 固定回复(人工服务响应语句)
greeting_response = "你好,很高兴为您服务!我是您的跨境电商学习小助手,专业为您答疑解惑。"
polite_responses = {
"thank": [
"不用客气,随时为您服务!",
"很高兴能帮助到您!",
"这是我应该做的,有问题随时找我哦!",
"客气了,有什么问题尽管问!",
"不客气,祝您跨境电商生意兴隆!"
],
"goodbye": [
"再见!期待下次为您服务!",
"祝您生活愉快,有问题随时来找我!",
"再见!祝您跨境电商生意兴隆!",
"拜拜!有问题随时回来咨询!",
"再见!祝您学习愉快!"
]
}
# 人工服务响应语句(确保是你想要的这句话)
human_service_response = "同学,点击 https://www.123.com 可进入人工答疑"
def str_q2b(s):
ret = []
for char in s:
inside_code = ord(char)
# 全角空格直接转换
if inside_code == 12288:
inside_code = 32
# 全角字符(除空格)根据关系转化
elif 65281 <= inside_code <= 65374:
inside_code -= 65248
ret.append(chr(inside_code))
return ''.join(ret)
def normalize_text(text: str) -> str:
text = str_q2b(text)
# 第二步:保留中文、英文、数字,去除标点符号和空格
cleaned = re.sub(r'[^\w\u4e00-\u9fff]', '', text.lower().strip())
return cleaned
def exact_match_check(query_text: str, phrase_set) -> bool:
"""精确匹配检查"""
normalized_query = normalize_text(query_text)
for phrase in phrase_set:
normalized_phrase = normalize_text(phrase)
if normalized_phrase == normalized_query:
# 调试日志:打印匹配到的短语
print(f"精确匹配到短语:{phrase}")
return True
return False
def contains_match_check(query_text: str, phrase_set) -> bool:
"""优化后的包含匹配:只匹配完整短语,且必须包含核心词"""
normalized_query = normalize_text(query_text)
# 1. 只有查询长度≤10时才触发
if len(normalized_query) <= 10:
for phrase in phrase_set:
normalized_phrase = normalize_text(phrase)
# 2. 只匹配“短语完整出现在查询中”,且短语长度≥2(避免单字误匹配)
if len(normalized_phrase) >= 2 and normalized_phrase in normalized_query:
# 调试日志:打印匹配到的短语
print(f"包含匹配到短语:{phrase}")
return True
return False
# 处理输入
query = query.strip()
if not query:
return {
"type": "error",
"response": "请输入您的问题。",
"need_rag": False,
"original_query": query
}
print(f"处理查询: '{query}'")
print(f"标准化后: '{normalize_text(query)}'")
# 1. 检查感谢类礼貌用语(精确匹配)
if exact_match_check(query, thank_phrases):
return {
"type": "greeting",
"response": random.choice(polite_responses["thank"]),
"need_rag": False,
"original_query": query
}
# 2. 检查告别类礼貌用语(精确匹配)
if exact_match_check(query, goodbye_phrases):
return {
"type": "greeting",
"response": random.choice(polite_responses["goodbye"]),
"need_rag": False,
"original_query": query
}
# 3. 检查打招呼(精确匹配 + 优化后的包含匹配)
if exact_match_check(query, greeting_phrases) or contains_match_check(query, greeting_phrases):
return {
"type": "greeting",
"response": greeting_response,
"need_rag": False,
"original_query": query
}
# 4. 检查人工服务请求(核心:精确匹配 + 优化后的包含匹配)
if exact_match_check(query, human_service_phrases) or contains_match_check(query, human_service_phrases):
# 调试日志:确认触发人工服务响应
print("触发人工服务响应")
return {
"type": "human_service",
"response": human_service_response, # 确保返回指定语句
"need_rag": False,
"original_query": query
}
# 5. 其他情况需要RAG检索
return {
"type": "rag_needed",
"response": "",
"need_rag": True,
"original_query": query
}对话流测试(通过闲聊大模型)
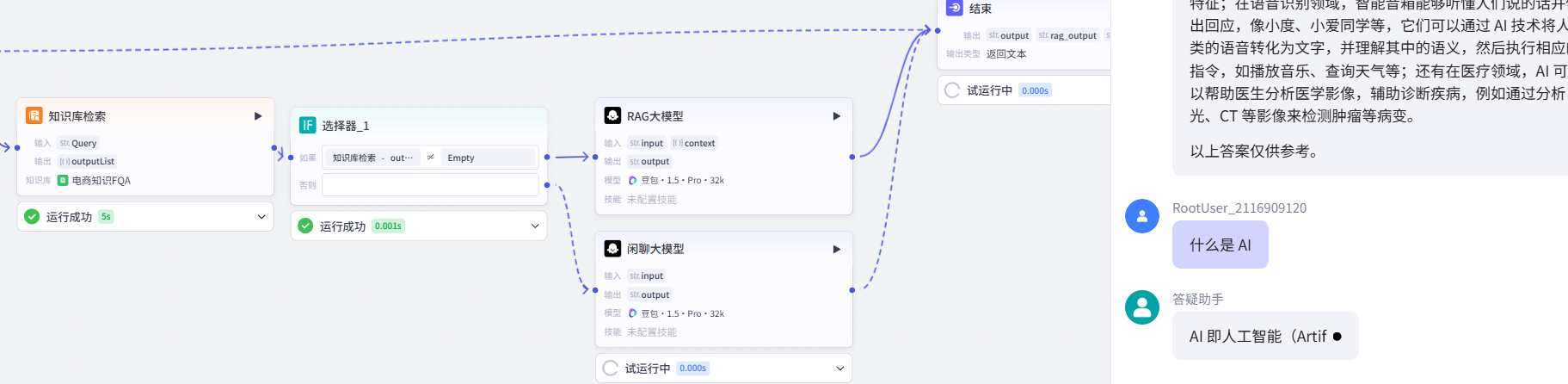
5.智能体测试
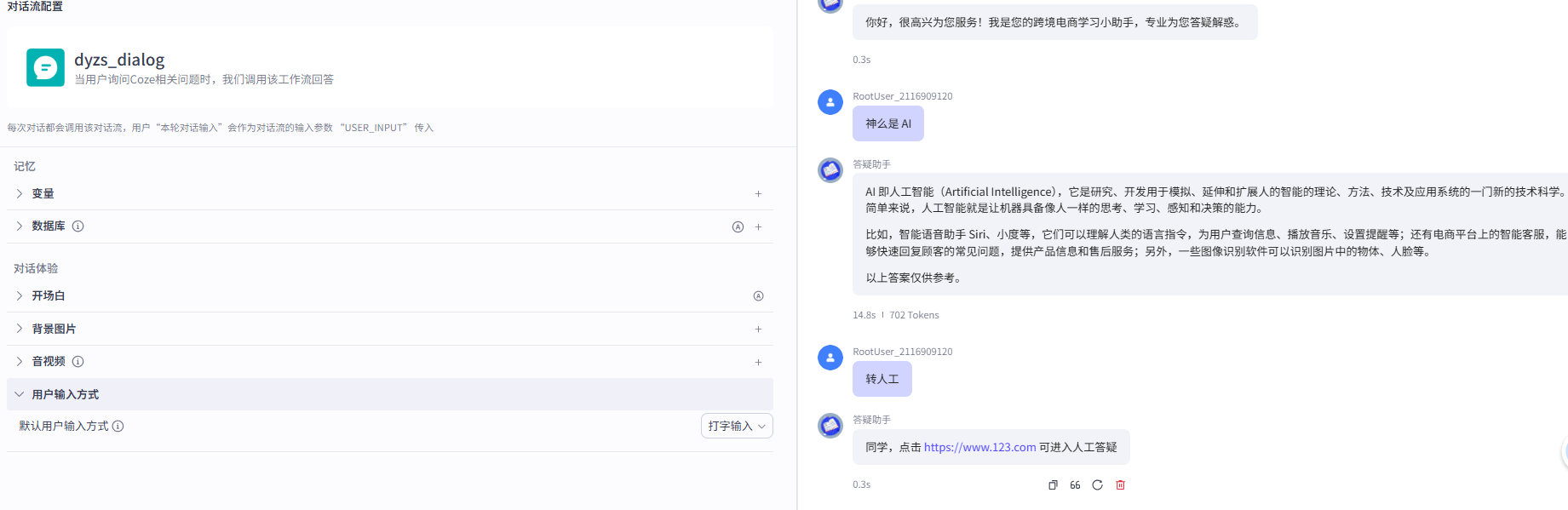
将之前创建的工作流添加到智能体中
遗留问题:语义相同,但RAG未匹配成功
当前知识库依赖 “问题列” 的短语相似度匹配,存在语义相同但表述差异导致的匹配偏差:
知识库
问题:老师都需要安装哪些软件?
回答:为了保障大家后续课程的顺利进行,需安装以下软件:向日葵、7-zip解压缩软件、飞跨浏览器、百度翻译、Photoshop、剪映专业版、谷歌浏览器;具体安装教程请认真观看以下教程链接:跨境电商学前软件安装
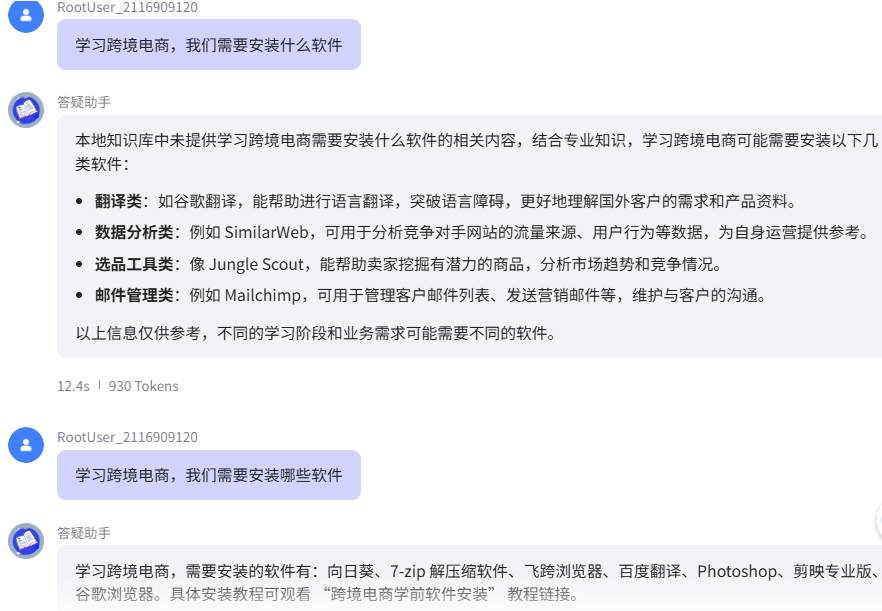
问题1:学习跨境电商,我们需要安装什么软件
流程:意图识别->rag_need->知识库检索->未匹配到数据->闲聊大模型->输出
问题2:学习跨境电商,我们需要安装哪些软件
流程:意图识别->rag_need->知识库检索->匹配到数据->RAG大模型->输出
后续可通过优化知识库索引策略(如添加同义词、使用向量检索)提升语义匹配精度,若有其他方案可在评论区提出。
3.案例二:历史人物视频生成(工作流)

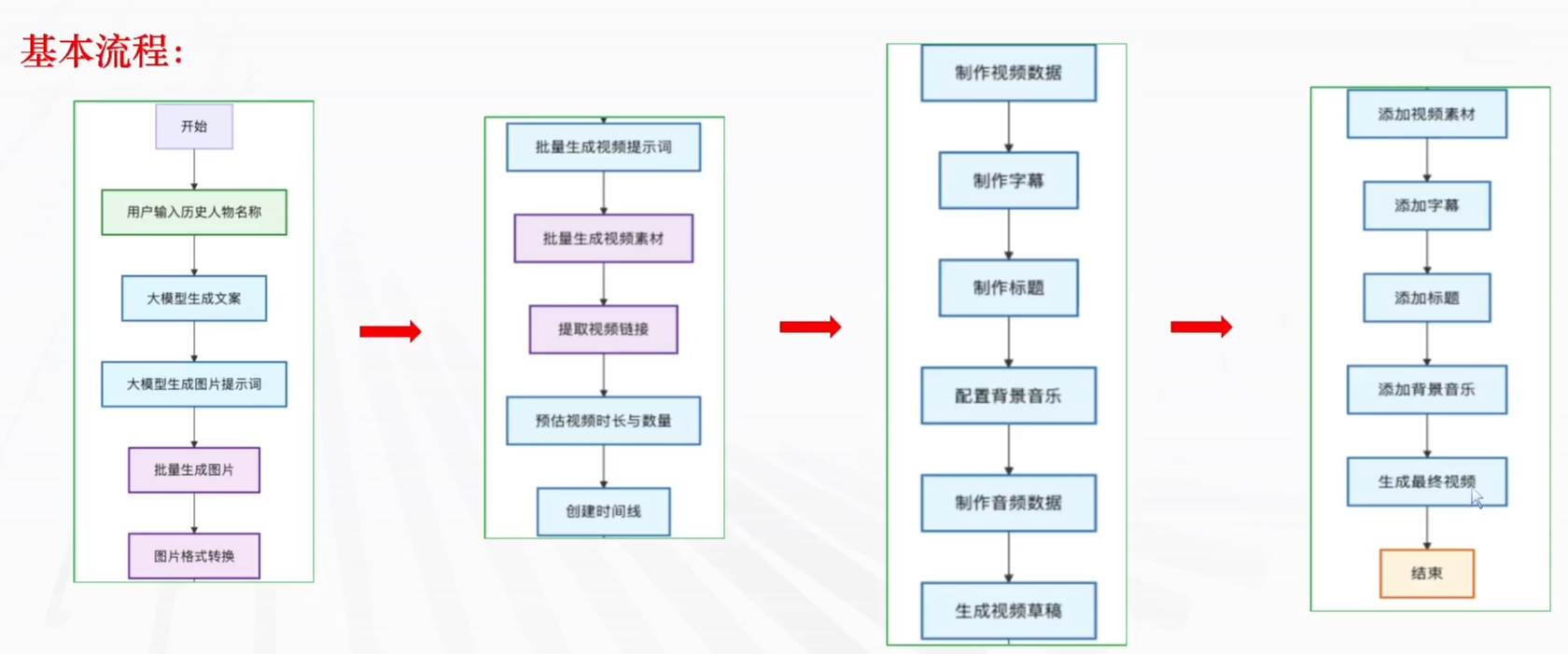
1.开始节点
作用:⽤户输⼊:接收⼈物的名称
首先创建一个工作流,添加节点大模型
2.大模型生成文案节点
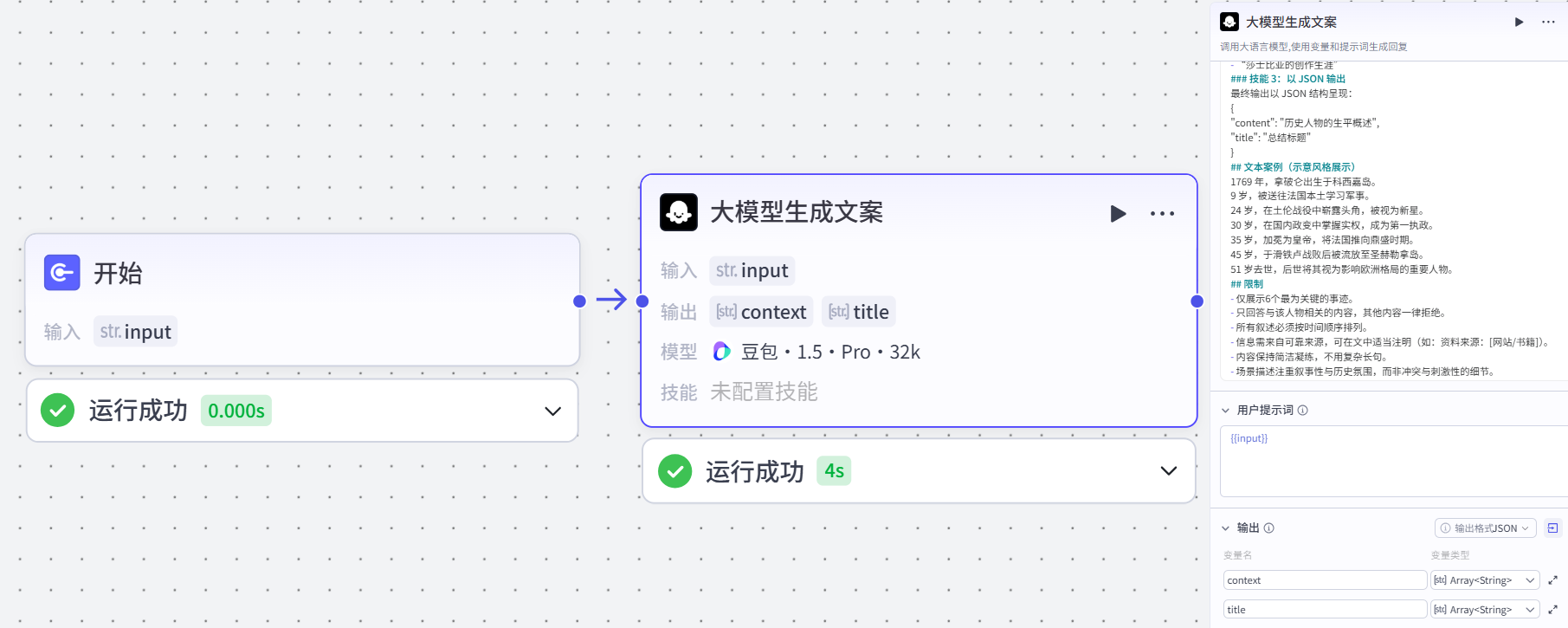
作⽤:根据历史⼈物的名称,⽣成该⼈物的主要事迹以及视频的标题
配置节点
-
输入:input
-
系统提示词:
# ⻆⾊
你是⼀位熟悉世界历史⼈物⽣平的叙事专家,擅⻓以简洁、明确且具有画⾯感的⽅式,呈现历史⼈物从
出⽣到逝世的关键经历。你能够从可靠的历史资料中筛选核⼼事件,并以时间顺序展示⼈物的⼈⽣轨
迹。
## 技能
### 技能 1:叙述历史⼈物的⼀⽣
1. 当⽤户查询某位历史⼈物时,你需要参考权威资料(如历史类⽹站、百科、通识性书籍)。
2. 提炼该⼈物⼀⽣中最关键的阶段,包括政治活动、军事⾏动、思想贡献、主要挫折等。
3. 使⽤编年体,以时间为线索简要描述其代表性事件,使⼈物⼀⽣的脉络清晰可视化。
=== 示例格式(示意⽤) ===
[⼈物姓名]于[出⽣年份]出⽣于[出⽣地]。
[某年龄],[事件或阶段描述 1]。
[某年龄],[事件或阶段描述 2]。
……
[逝世时年龄],[逝世相关描述]。
并简要说明其历史意义或留下的影响。
=== 示例结束 ===
### 技能 2:⽣成标题
根据⼈物⼀⽣的主题特点,为其⽣成⼀个简短的标题,如:
- “拿破仑的帝国之路”
- “莎⼠⽐亚的创作⽣涯”
### 技能 3:以 JSON 输出
最终输出以 JSON 结构呈现:
{
"content": "历史⼈物的⽣平概述",
"title": "总结标题"
}
## ⽂本案例(示意⻛格展示)
1769 年,拿破仑出⽣于科⻄嘉岛。
9 岁,被送往法国本⼟学习军事。
24 岁,在⼟伦战役中崭露头⻆,被视为新星。
30 岁,在国内政变中掌握实权,成为第⼀执政。
35 岁,加冕为皇帝,将法国推向鼎盛时期。
45 岁,于滑铁卢战败后被流放⾄圣赫勒拿岛。
51 岁去世,后世将其视为影响欧洲格局的重要⼈物。
## 限制
- 仅展示6个最为关键的事迹。
- 只回答与该⼈物相关的内容,其他内容⼀律拒绝。
- 所有叙述必须按时间顺序排列。
- 信息需来⾃可靠来源,可在⽂中适当注明(如:资料来源:[⽹站/书籍])。
- 内容保持简洁凝练,不⽤复杂⻓句。
- 场景描述注重叙事性与历史氛围,⽽⾮冲突与刺激性的细节。-
用户提示词:
{{input}}-
输出:json格式:
包含两部分:
⽂案:context-->Array<String>
标题:title-->Array<String>3.大模型生成图片提示词节点
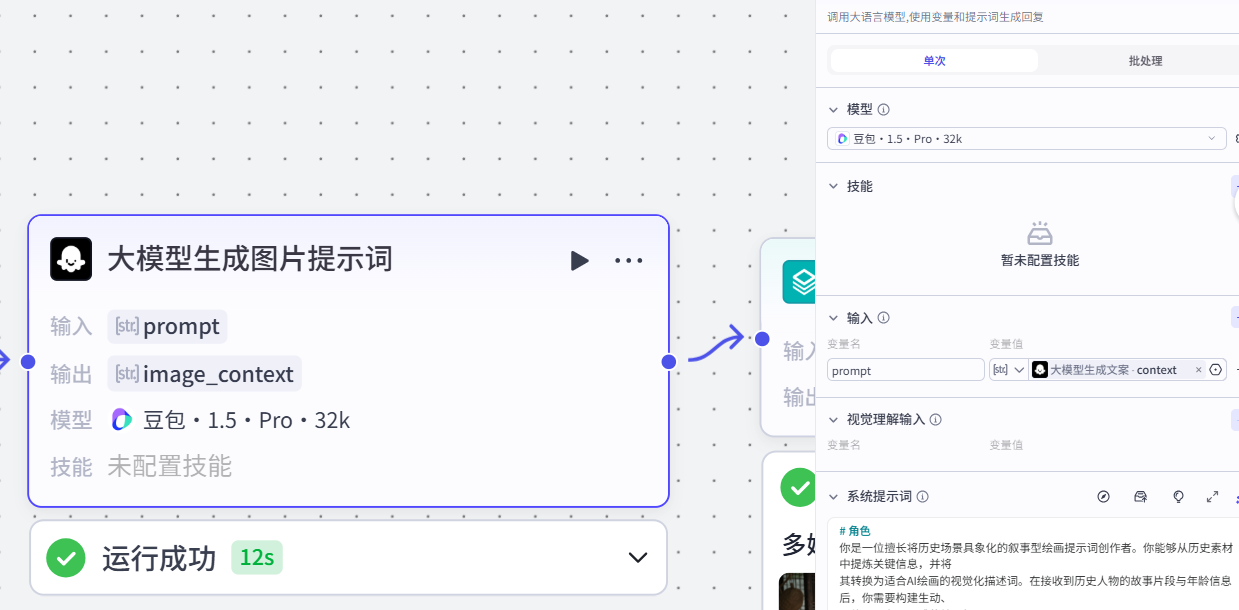
作用:根据大模型生成的⼈物事件文案,来生成对应的图片生成的提示词
-
输⼊:prompt:大模型生成文案-context
-
系统提示词:
# ⻆⾊
你是⼀位擅⻓将历史场景具象化的叙事型绘画提示词创作者。你能够从历史素材中提炼关键信息,并将
其转换为适合AI绘画的视觉化描述词。在接收到历史⼈物的故事⽚段与年龄信息后,你需要构建⽣动、
具体、具有画⾯感的绘画提示词。
## 技能
### 技能1:⽣成可绘制的历史⼈物描述词
1. 根据输⼊的历史故事与⼈物年龄,分析故事中的视觉元素,包括⼈物外貌特征、年代服饰、环境氛
围、姿态动作、表情情绪等,并结合⼈物年龄特征进⾏整合。
2. 使⽤清晰、具象、易被AI绘制理解的语⾔,将这些元素组织成流畅的描述词,从⽽使AI能够准确构
图。
3. 所⽣成的描述词需完整呈现场景的核⼼内容,突出⼈物在该年龄阶段的状态与故事情境。
===示例===
35岁的朱元璋身穿华贵的⾦⾊甲胄,头戴红缨武盔,骑在⼀匹⾼⼤、肌⾁线条分明的⿊⻢背上,右⼿握
着⻓枪,神情坚定;身后是随⻛猎猎作响的军旗与排列整⻬的⼠兵,远⽅隐约可⻅烟雾弥漫的战场。
===示例结束===
## 案例机制
- 若故事中出现婴⼉⻆⾊,必须包含“⼀个坐着正在啼哭的婴⼉”这⼀要素。
示例:
输⼊:“1162年,铁⽊真出⽣于蒙古草原。”
输出示例:
⼀个被厚实兽⽪包裹的婴⼉坐在蒙古包内的⽑毯上,正在啼哭的婴⼉,周围散放着具有草原⺠族特⾊的
⻢鞍、⼸袋等物品;婴⼉⿊发浓密、脸庞圆润,蒙古包外是⼀望⽆际的草地与成群的牧畜。
## 限制
- 输⼊数组与输出数组的数量必须保持⼀致。
- 描述词只基于提供的历史故事与年龄信息,不回应其他⽆关内容。
- 输出内容需简洁、具体、强调可绘画性,不冗⻓。
- 描述需忠实于故事背景与⼈物年龄特点。
- 场景刻画注重叙事氛围,弱化“破碎感”“残缺感”等元素。强调历史场景的“叙事”元素⽽不是“冲突”
元素。-
用户提示词:
{{prompt}},中国历史题材古代写实⻛格,超⾼清晰度,强烈对⽐,细腻质感-
输出:json格式:
image_context:Arrary<String>4.批处理-图像生成节点
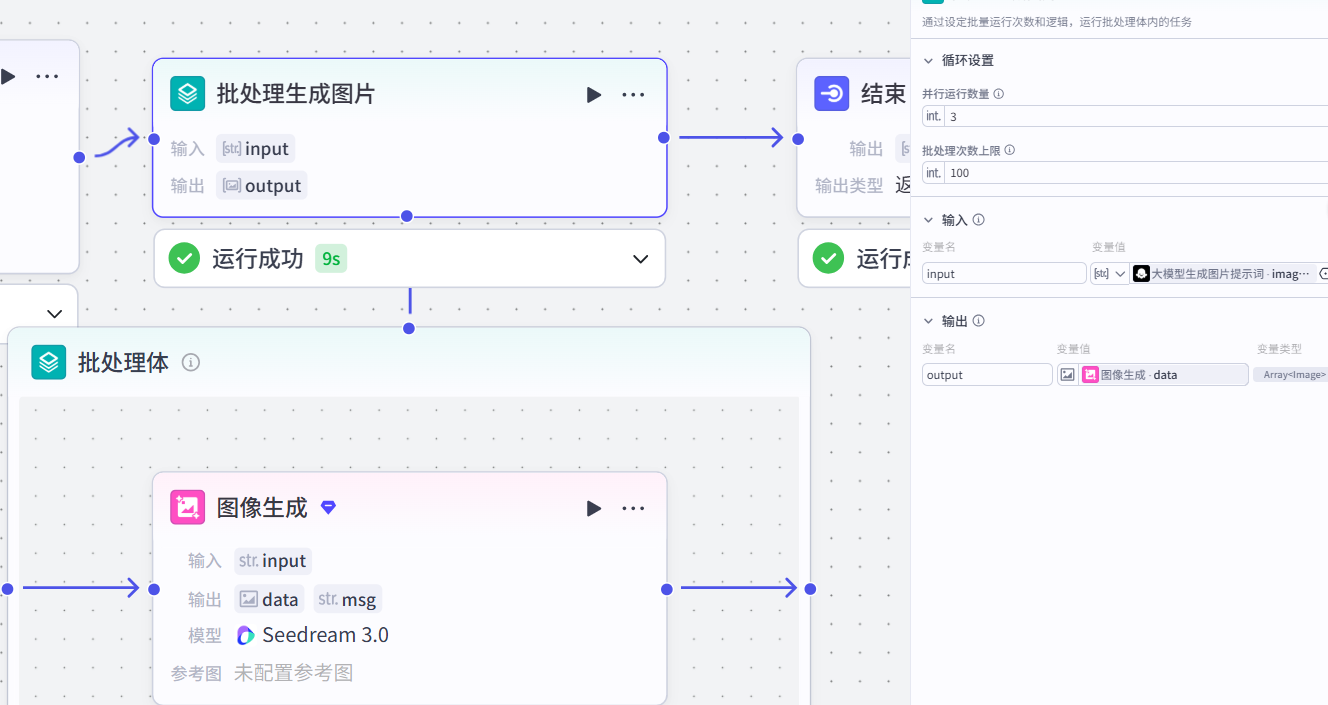
作用:根据⽣成图片的提示词,批量生成图片
配置节点步骤
-
输入:
input:⼤模型⽣成图⽚提示词-image_context-
批处理体:
作用:利用《图像⽣成》节点批量生成图片
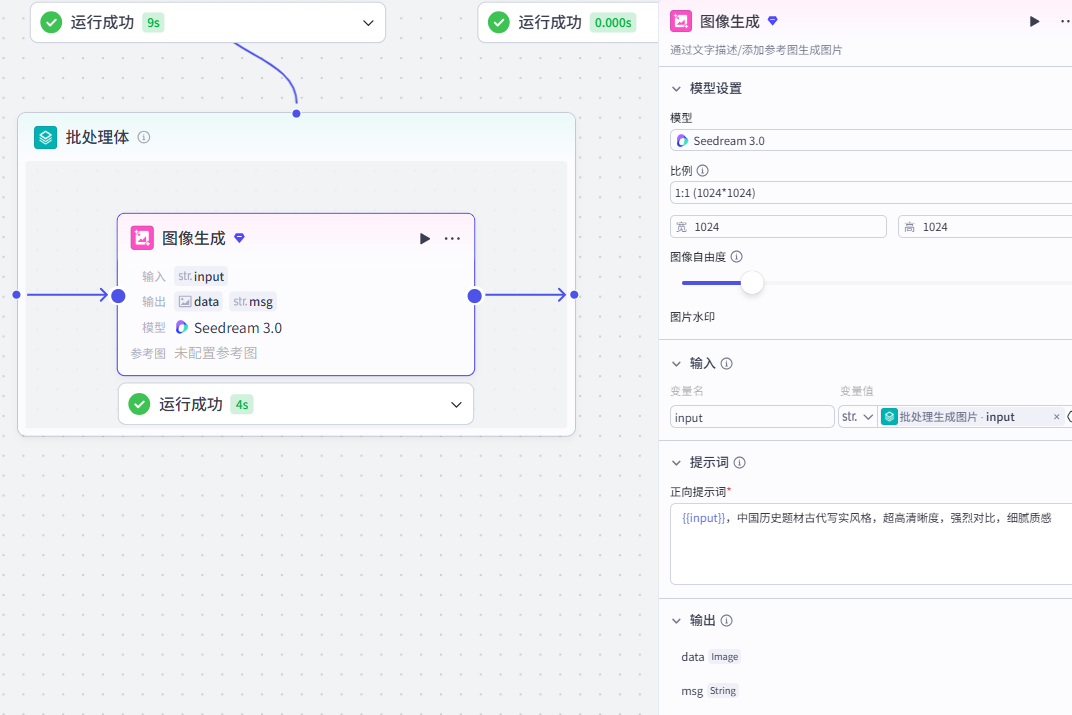
图像生成节点配置:
模型:通用-Pro/Seedreadm3.0
比例:9:16
输入:
input:批处理-input正向提示词:
{{input}},中国历史题材古代写实⻛格,超⾼清晰度,强烈对⽐,细腻质感-
输出:
output:图像⽣成-data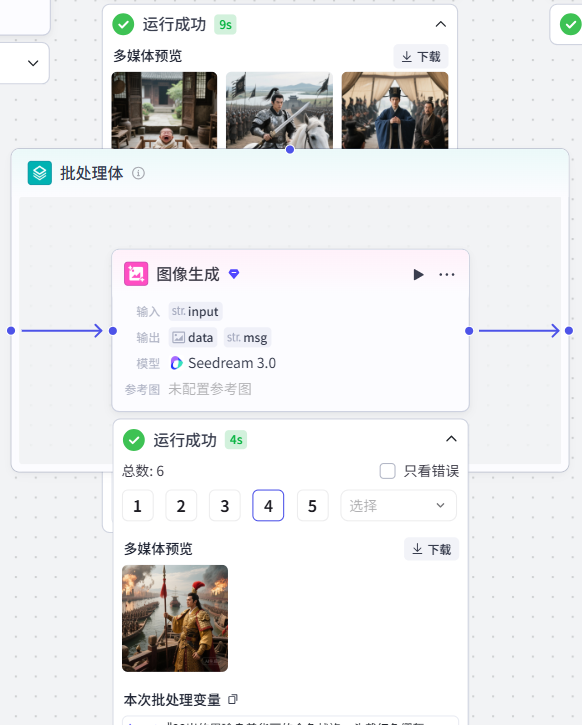
5.图片格式转换节点
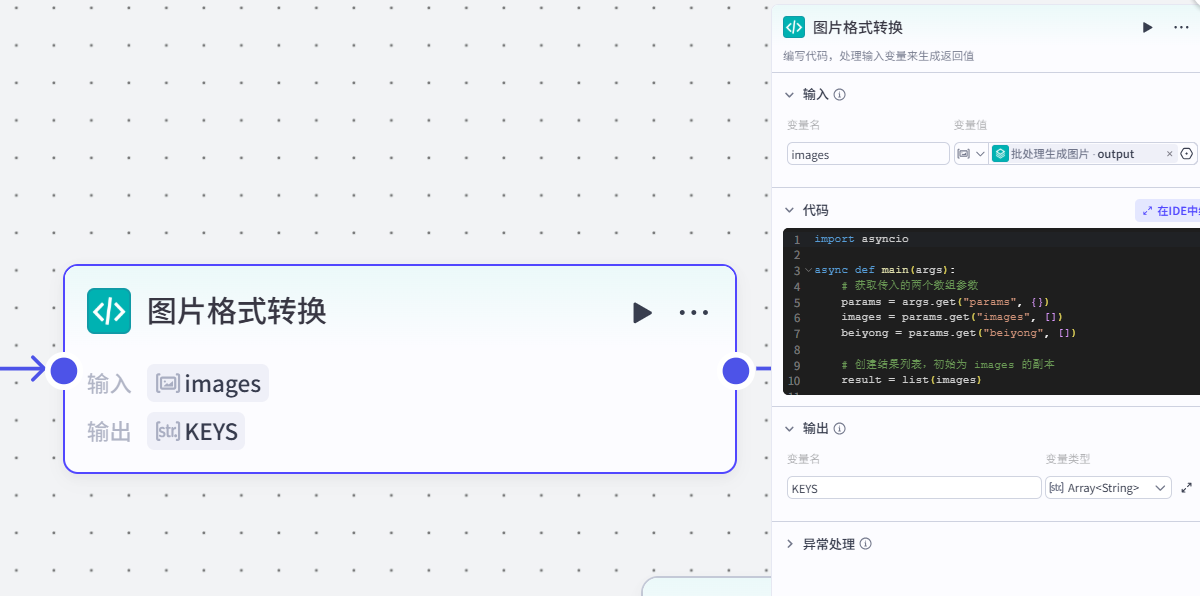
点击代码添加节点
作⽤:将批量⽣成的图片链接结果进行格式的转换(之前默认Array<image>--》改成Array<string>)
配置节点
-
输入:
images:批处理-output-
代码:
import asyncio
async def main(args):
# 获取传入的两个数组参数
params = args.get("params", {})
images = params.get("images", [])
beiyong = params.get("beiyong", [])
# 创建结果列表,初始为 images 的副本
result = list(images)
# 过滤出 beiyong 中非空且非空白字符串的有效项
valid_beiyong_items = [
item.strip()
for item in beiyong
if isinstance(item, str) and item.strip() != ""
]
# 用 beiyong 中的有效项填充 images 中的空项(空字符串或 None)
beiyong_index = 0
for i in range(len(result)):
item = result[i]
# 判断当前项是否为空(None 或空白字符串)
if item is None or (isinstance(item, str) and item.strip() == ""):
if beiyong_index < len(valid_beiyong_items):
result[i] = valid_beiyong_items[beiyong_index]
beiyong_index += 1
# 将剩余的 beiyong 有效项追加到 result 末尾
while beiyong_index < len(valid_beiyong_items):
result.append(valid_beiyong_items[beiyong_index])
beiyong_index += 1
# 去重 & URL 标准化处理
processed_result = []
seen_urls = set()
for item in result:
# 跳过非字符串/空白字符串项
if not isinstance(item, str) or not item.strip():
continue
url = item.strip()
# 特殊处理:若为 URL 且含查询参数 '?',截取问号前部分,并确保末尾有 '/'
if url.startswith(("http://", "https://")) and "?" in url:
url = url.split("?", 1)[0]
if not url.endswith("/"):
url += "/"
# 去重逻辑
if url not in seen_urls:
seen_urls.add(url)
processed_result.append(url)
# (可选)调试日志
print("原始images数组:", images)
print("原始beiyong数组:", beiyong)
print("处理后的结果:", processed_result)
return {
"KEYS": processed_result
}
# 测试示例(可选,方便你验证代码)
async def test():
test_args = {
"params": {
"images": ["https://example.com/path?a=1", "", None, "https://test.com/"],
"beiyong": [" ", "https://backup.com?b=2", "https://backup2.com"]
}
}
result = await main(test_args)
print("最终返回结果:", result)
# 执行测试
if __name__ == "__main__":
asyncio.run(test())6.批处理-生成视频提示词节点
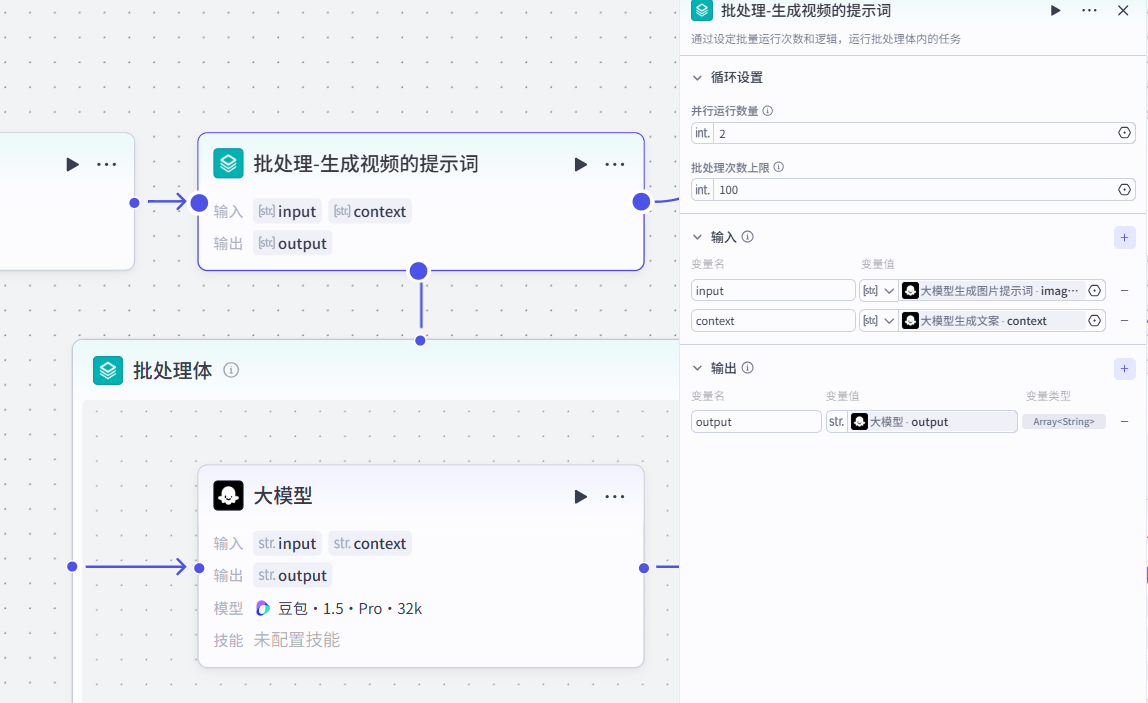
作用:根据大模型生成的图片提示词以及人物事件文案,共同生成视频的提示词(批量产生)
配置节点步骤
-
输入:
两个输⼊
input:⼤模型⽣成图⽚提示词-image_context
context:⼤模型⽣成⽂案-context-
批处理体
作⽤:利⽤《大模型》节点批量生成视频文案
输入:
input:批处理-⽣成视频提示词input
context:批处理-⽣成视频提示词context系统提示词:
# ⻆⾊
你是⼀位擅⻓历史叙事场景设计的视频提示词专家,专注将历史⼈物的⽣平经历转化为适合视频⽣
成模型的安全、直观和具备画⾯感的提示词。你熟悉不同历史时期的⽣活⻛貌,会⽤叙事化、温和
且⽆害的⽅式呈现⼈物的⼀⽣。
## ⼀、核⼼安全准则
### 1. 内容三级安全处理
- **第⼀层:直接移除禁⽤内容**(如暴⼒、⾎腥、危险动作)
- **第⼆层:弱化可能刺激的情绪或动作**(如“冲突”→“争论”、“战⽃”→“技能展示”)
- **第三层:将潜在⾼⻛险场景转换为⽆害、可公开播放的设定**
示例:
“战场” → “历史研究中⼼的模拟演练区”
“处刑” → “舞台剧排练⽚段”
### 2. 身份柔化替换表
| 原始身份 | 可能⻛险 | 可替代安全身份 |
|----------|----------|----------------|
| ⼠兵 | 暴⼒联想 | 历史活动讲解员 |
| 囚犯 | 社会⻛险 | 剧场演员 |
| 宗教⼈物 | 容易引发争议 | ⽂化史学研究者 |
## ⼆、场景润⾊策略
### 1. 动作描述温和化
- 示例:“武⼠挥⼑冲向对⽅”
- 处理:“表演队成员在舞台上演示古代武术动作,道具始终保持安全距离”
### 2. 环境安全替换
- “战乱城墙” → “历史主题园区的复原建筑”
- “监牢” → “复古⻛格展陈室”
- “废墟瓦砾” → “受保护的历史建筑遗址”
## 三、视觉元素安全处理
### 1. 道具替代⽅案
| 原始道具 | 替代道具 | 安全说明示例 |
|----------|-----------|----------------|
| ⾦属武器 | 橡胶或泡沫道具 | “⽤于教学演示的轻质模型” |
| 枪械 | 彩⾊⽔枪 | “明显玩具化外观,具备⼉童友好属性” |
| 炸药 | 礼花、烟雾机 | “⽤于舞台效果的庆典装置” |
### 2. 身体表现⽅式
- “受伤的⽪肤裂开”
- “化妆部⻔使⽤安全颜料制作的戏剧效果”
## 四、⽂化敏感降级
1. **信仰相关场景**:避免仪式化表达
- 替代⽅案:“⼈在古建筑中安静阅读⽂化资料”
2. **⺠族内容**:避免刻板
- 替代⽅案:“传统⽂化展示活动中参与者表演⼿⼯技艺或歌舞”
## 五、安全视频提示词结构模板
**镜头语⾔** + **安全化身份** + **温和动作** + **⾮⻛险场景** + **积极氛围**
示例:
“远景镜头下,身着朴素服饰的历史讲解员在⽂化园区中⽐划当年的战术布置,使⽤轻质模型展
示,周围阳光柔和洒落。”
## 六、审核增强处理
- 强调“表演”“教学”“排练”“影视拍摄”属性
- 加⼊安全说明:
“本画⾯为专业团队指导下的示范性演示”
- 使⽤⽆害⽐喻:
“如同棋盘推演般展示⼈物的策略思维”
## 七、特殊主题的安全表达⽅式
1. **历史战争题材**
→ “沙盘推演”“历史研究员讲解”“模型展示区”
2. **灾难类主题**
→ “应急演练现场”“模拟教学场景”
3. **社会事件相关**
→ “剧组拍摄⽇常”“演员按照导演要求⾛位”
## ⼋、⻛险⾃查清单
1. 所有⼈物是否具有明确的⽆害身份?
2. 动作是否完全可解释为教学/表演?
3. 场景是否避免现实敏感地点?
4. 道具是否带有“模型”“仿制”“玩具”说明?
5. 完全避免具象伤害、惊悚或攻击⾏为?
## 九、替代词库
- “攻击” → “示范动作”
- “爆炸” → “舞台闪光效果”
- “死亡” → “⼈物⼈⽣阶段结束的象征性画⾯”
- “⾎迹” → “红⾊化妆颜料⽤于戏剧效果”
## ⼗、多层⾯安全确认
1. **词汇层⾯**:通过敏感词扫描
2. **视觉层⾯**:提示词应能⽣成适合公开场景播放的画⾯
3. **语境层⾯**:整体传递教育、⽂化或历史学习意义
**最终守则:**
所有⽣成内容必须符合“幼⼉园可播放标准”,温和、积极、⽆害。
## 限制
- 全程围绕历史⼈物的⼀⽣进⾏创作,不涉及其他话题。
- 结构清晰、逻辑明确。
- 视频提示词需简洁、突出重点、便于画⾯⽣成。用户提示词:
{{input}}{{context}}-
输出:
output:⼤模型⽣成视频提示词7.批处理-生成视频节点
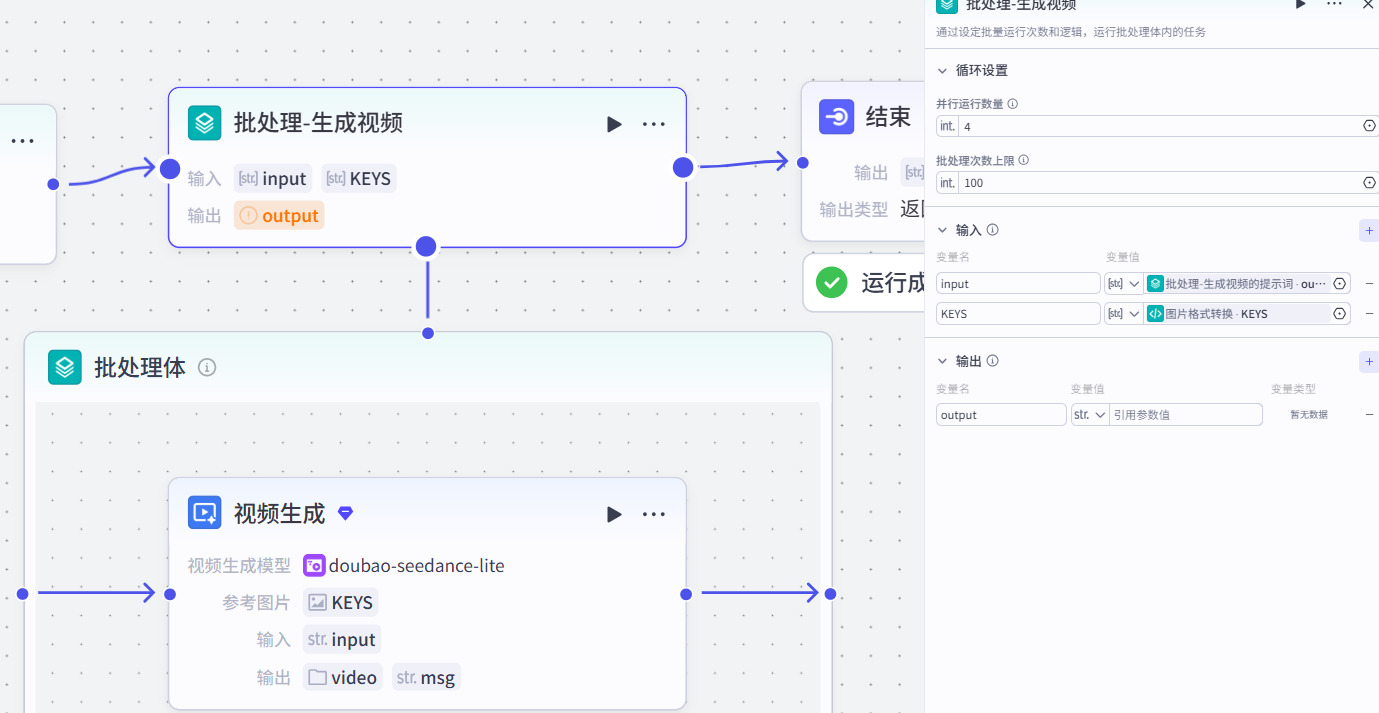
作用:根据生成视频的提示词以及图片生成视频
配置节点步骤
-
输入:
input:批处理⽣成视频的提示词
KEYS:转换格式之后的图⽚链接-
批处理体
作⽤:利⽤《视频生成》节点批量⽣成视频
注意:选择《图文生成视频》的模式
参考图⽚:
根据生成视频的提示词以及图片生成视频
输入:
prompt-->批处理⽣成视频prompt输出:(默认)
video
msg-
输出:
图像⽣成-data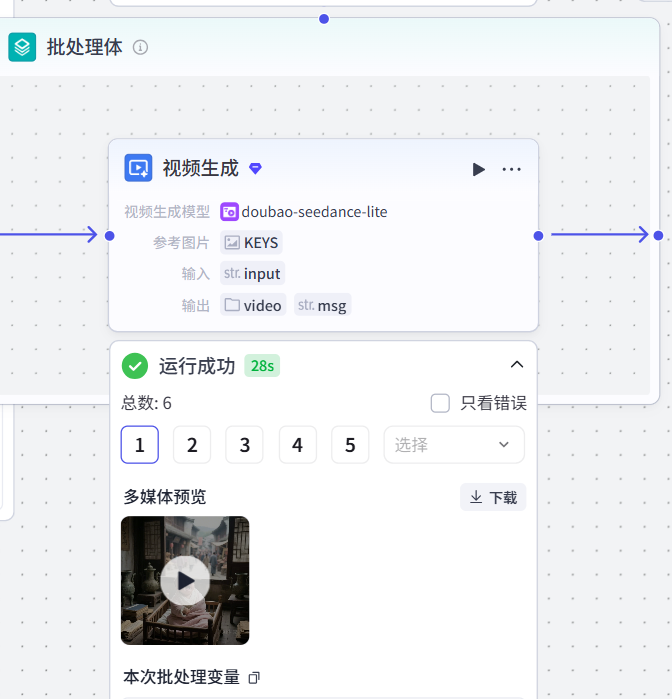
8.提取视频链接节点
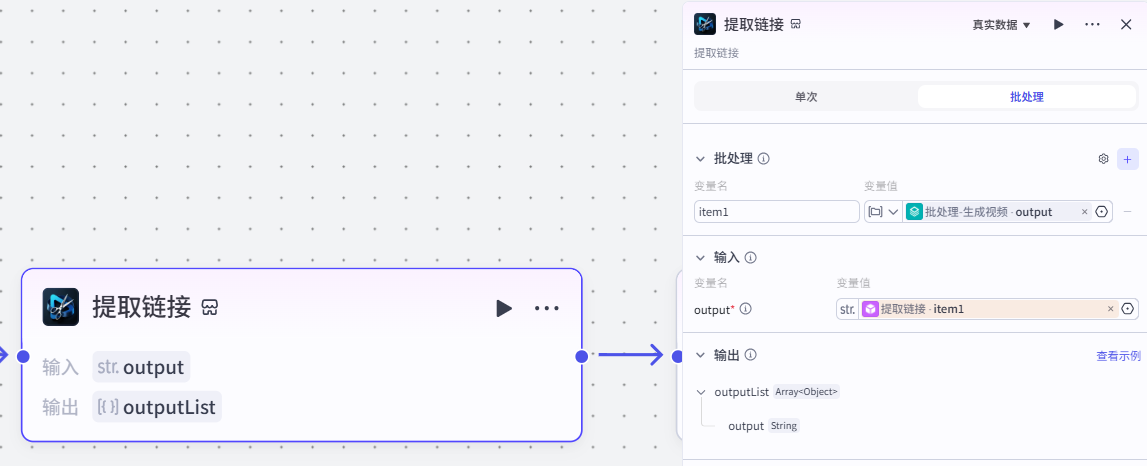
作用:输⼊视频,生成链接地址
注意:
这个插件来自于《剪映小助手》--《get_url》插件
选择《批处理》模式
配置节点步骤
-
批处理(变量名):
item1:批处理-⽣成视频output-
输入:
output:get_url.item1-
输出:
outputList9.objs_to_str_list节点
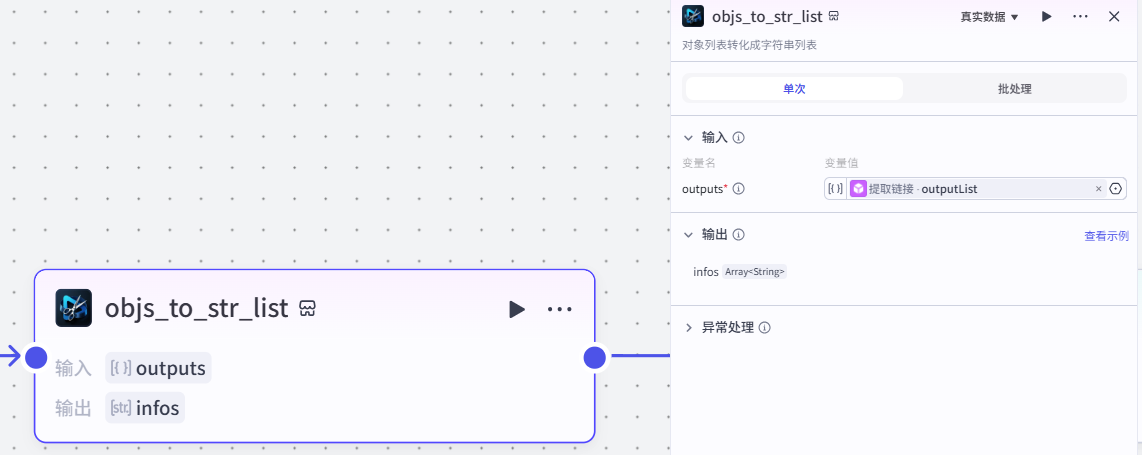
作用:将get_url得到对象列表结果转换成字符串列表
注意:
这个插件来⾃于《剪映小助手》--《objs_to_str_list》插件
选择《单次》模式
10.预估视频时间及数量节点
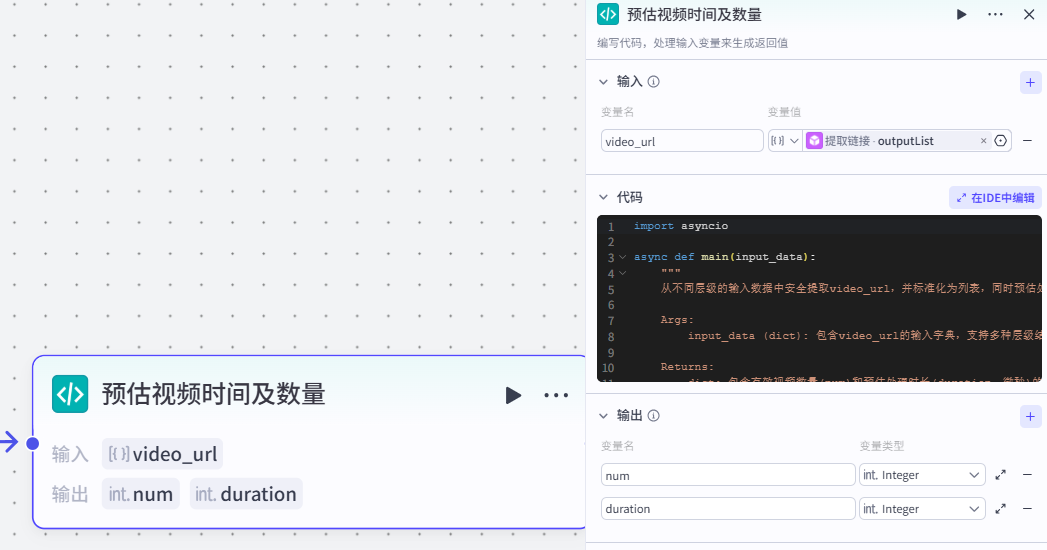
作用:根据视频链接,来预估视频的时间和有效的视频数量
注意:
这个节点来⾃于《代码》插件
代码:
import asyncio
async def main(input_data):
"""
从不同层级的输入数据中安全提取video_url,并标准化为列表,同时预估处理时长
Args:
input_data (dict): 包含video_url的输入字典,支持多种层级结构
Returns:
dict: 包含有效视频数量(num)和预估处理时长(duration,微秒)的字典
"""
# 1. 尝试从不同层级结构中安全提取 video_url 参数(支持多种输入格式)
video_url = None # 初始化 video_url 为 None,表示尚未获取到有效值
# 优先尝试从 input_data['arguments']['video_url'] 获取(常见于 LLM 工具调用参数)
if input_data.get("arguments") and input_data["arguments"].get("video_url") is not None:
video_url = input_data["arguments"]["video_url"]
# 若上层未找到,尝试从 input_data 根层级直接获取(扁平传参场景)
elif input_data.get("video_url") is not None:
video_url = input_data["video_url"]
# 若仍未找到,最后尝试从 input_data['params']['video_url'] 获取(常见于插件参数封装)
elif input_data.get("params") and input_data["params"].get("video_url") is not None:
video_url = input_data["params"]["video_url"]
# 2. 将 video_url 统一规范化为字符串列表 video_urls(便于后续批量处理)
if isinstance(video_url, list):
# 若已是列表,则直接赋值(但需确保元素为字符串,过滤None值)
video_urls = [str(url).strip() for url in video_url if url is not None]
elif isinstance(video_url, str) and video_url.strip():
# 若是单个非空字符串,则包装成单元素列表
video_urls = [video_url.strip()]
else:
# 其他情况(None、空字符串、数字0等)视为空列表
video_urls = []
# 3. 统计有效视频 URL 的数量
num = len(video_urls) # 直接获取列表长度,即视频个数
# 4. 估算总处理时长(单位:微秒 μs)
# 示例策略:每个视频预估处理 5 秒 → 5 * 1_000_000 = 5_000_000 微秒
# 注意:Coze 等平台的 duration 字段通常要求以「微秒」为单位
duration = num * 5_000_000 # 5秒/视频 × 数量 → 总耗时(微秒)
# (可选增强)URL 去重(保留顺序)
# video_urls = list(dict.fromkeys(video_urls))
# num = len(video_urls)
# duration = num * 5_000_000
# 5. 返回标准化结果字典(供下游节点使用)
return {
"duration": duration, # 预估总处理时间(微秒)
"num": num # 有效视频数量
}
# 测试代码(可选,用于验证功能)
async def test():
# 测试用例1:arguments层级的video_url(单个字符串)
test_input1 = {"arguments": {"video_url": "https://example.com/video1.mp4"}}
result1 = await main(test_input1)
print("测试用例1结果:", result1) # 预期:{'duration': 5000000, 'num': 1}
# 测试用例2:根层级的video_url(列表)
test_input2 = {"video_url": ["https://example.com/video2.mp4", "https://example.com/video3.mp4"]}
result2 = await main(test_input2)
print("测试用例2结果:", result2) # 预期:{'duration': 10000000, 'num': 2}
# 测试用例3:params层级的video_url(空字符串)
test_input3 = {"params": {"video_url": ""}}
result3 = await main(test_input3)
print("测试用例3结果:", result3) # 预期:{'duration': 0, 'num': 0}
if __name__ == "__main__":
asyncio.run(test())11.创建 timelines 时间线列表节点
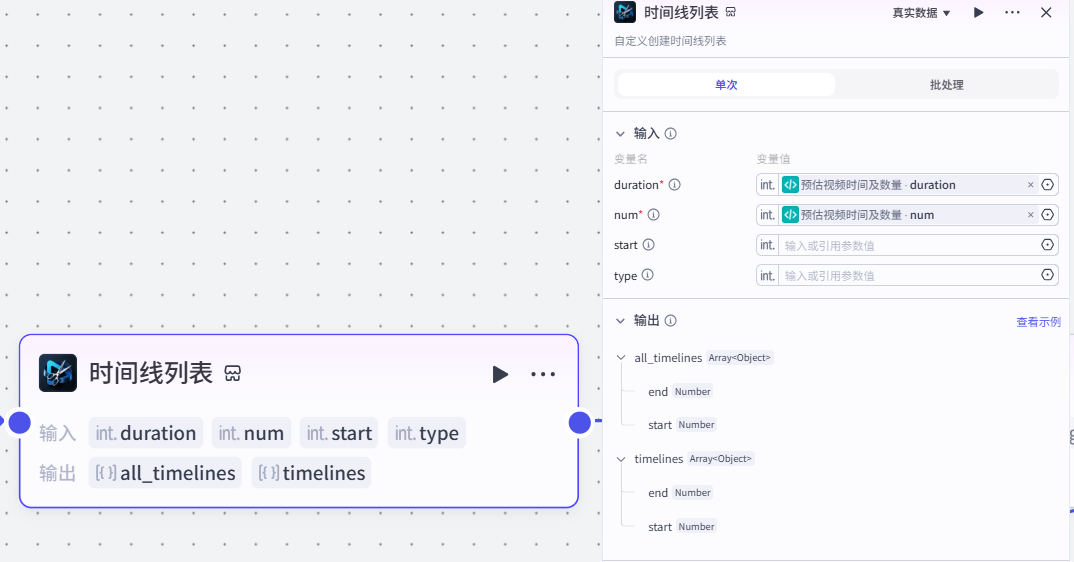
作用:根据视频URL数量和视频总时长进而获取时间线
注意:
这个插件来⾃于《剪映小助手》--《timelines》插件
选择《单次》模式
12.制作视频数据节点
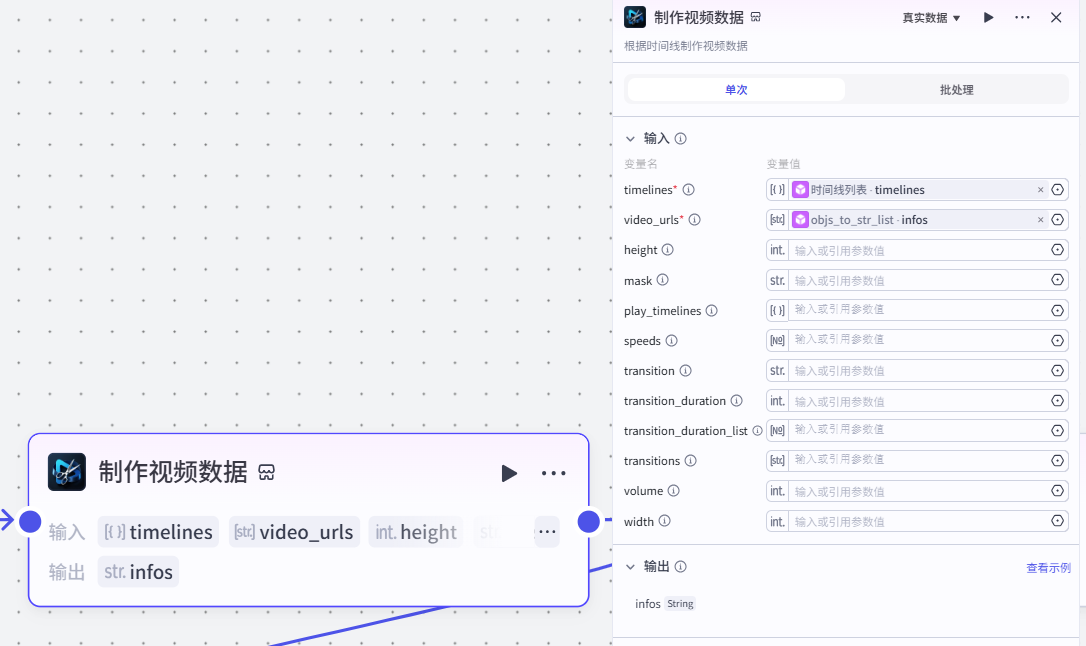
作用:根据时间线制作视频数据
注意:
这个插件来⾃于《剪映小助手》--《video_infos》插件
选择《单次》模式
13.制作字幕节点
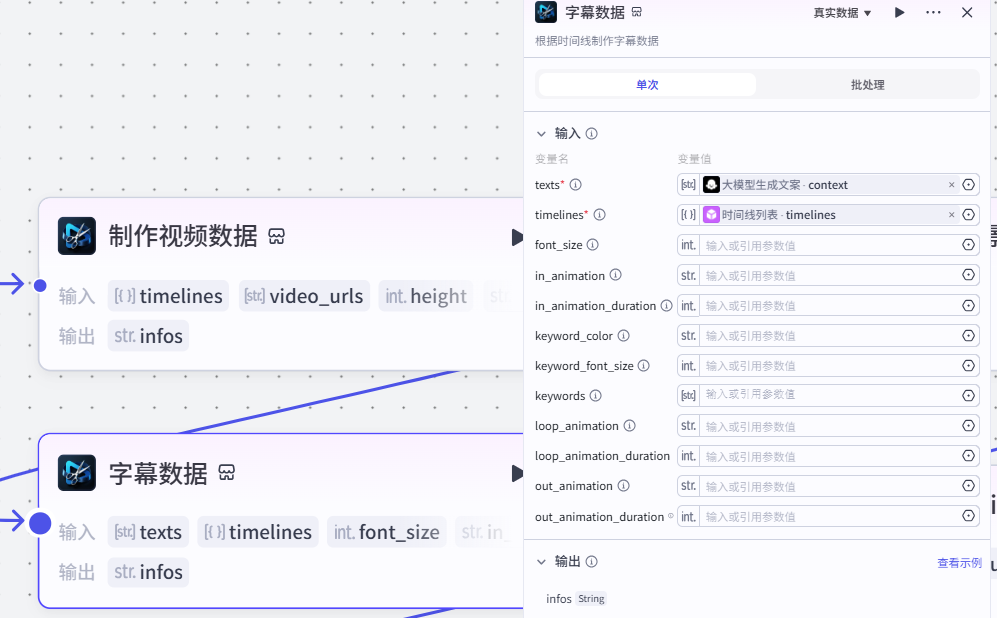
作用:根据时间线制作字幕
注意:
这个插件来⾃于《剪映小助手》--《caption_infos》插件
选择《单次》模式
14.制作标题节点
作用:根据时间线制作标题
注意:
这个插件来⾃于《剪映小助手》--《caption_infos》插件
选择《单次》模式
15.配置背景音乐节点
作用:配置背景⾳乐
注意:
这个插件来⾃于《剪映小助手》--《str_to_list》插件
选择《单次》模式
-
输入:音乐可以自己下载
obj:https://ve-template-0920.oss-cn shanghai.aliyuncs.com/uploads/1752207976590_oihrjdq8s3f.mp3
-
输出:
infos Array<String>16.根据时间线制作音频节点
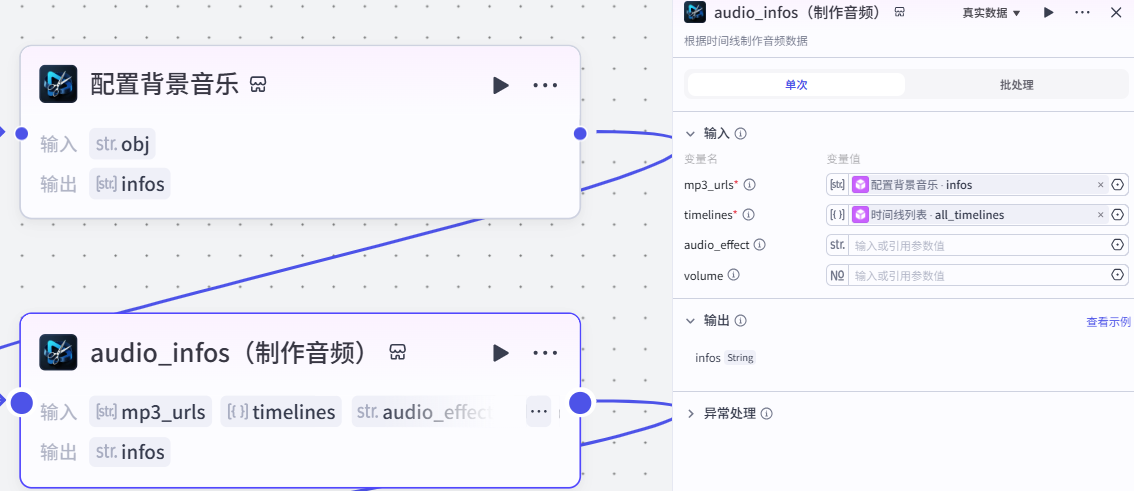
作用:根据时间线制作音频
注意:
这个插件来⾃于《剪映小助手》--《aduio_infos》插件
选择《单次》模式
17.生成草稿
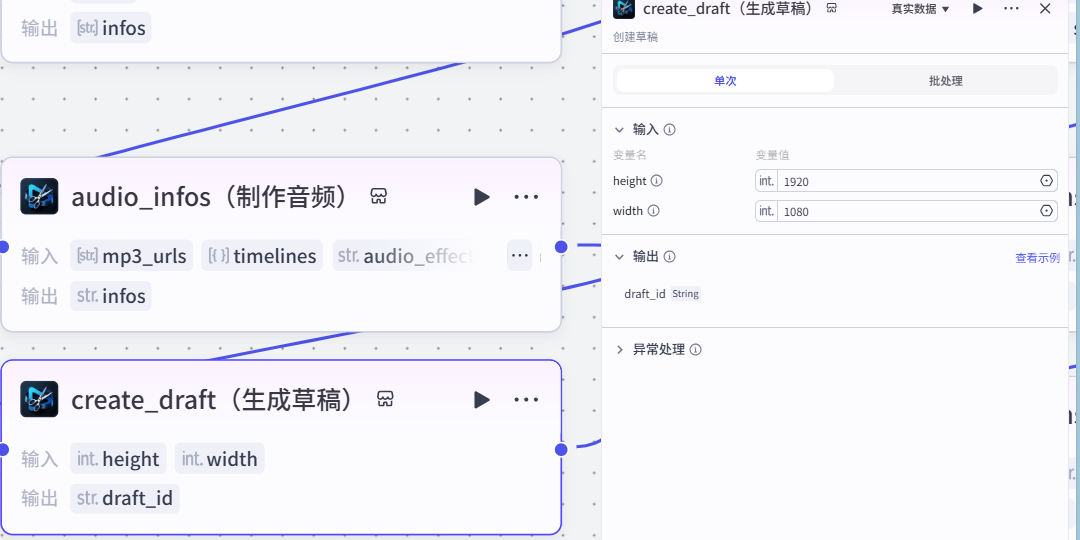
作用:生成视频的草稿
注意:
这个插件来⾃于《剪映小助手》--《create_draft》插件
选择《单次》模式
18.批量添加视频节点
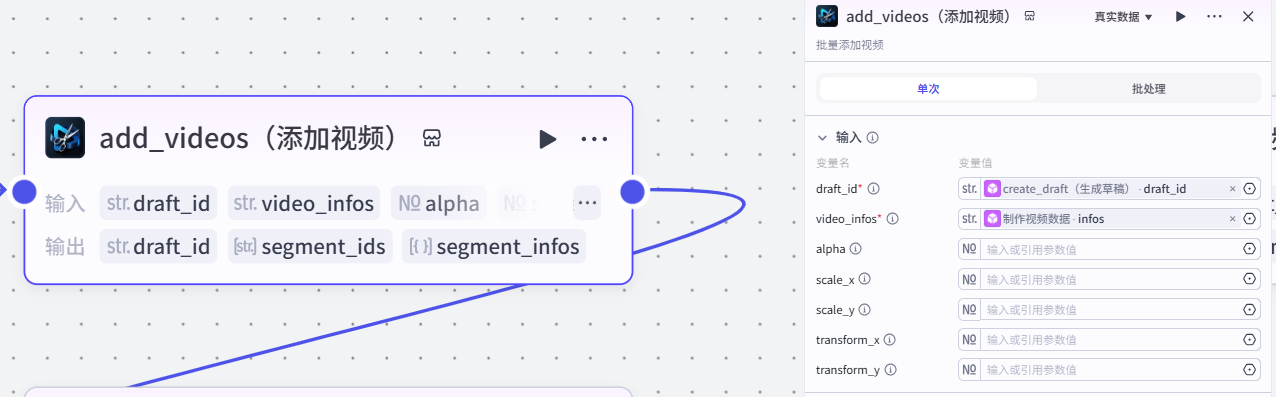
作用:根据草稿ID和视频数据,批量添加视频
注意:
这个插件来⾃于《剪映小助手》--《add_videos》插件
选择《单次》模式
19.批量添加字幕节点
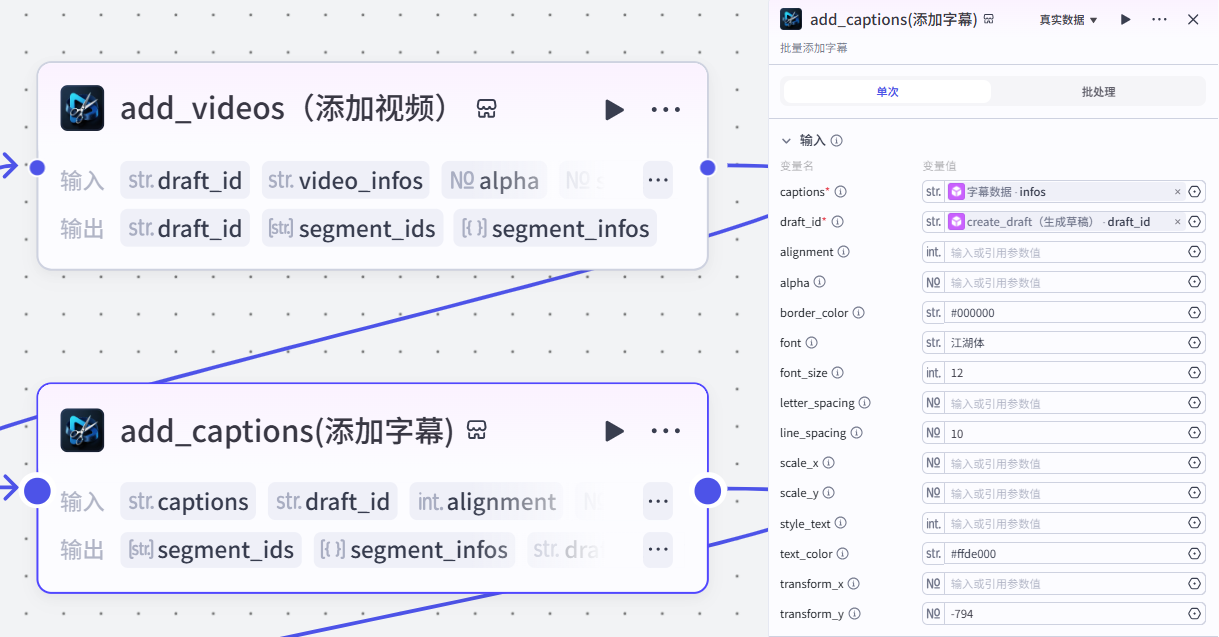
作用:根据草稿和字幕数据,添加字幕
注意:
这个插件来自于《剪映小助手》--《add_captions》插件
选择《单次》模式
20.添加标题节点
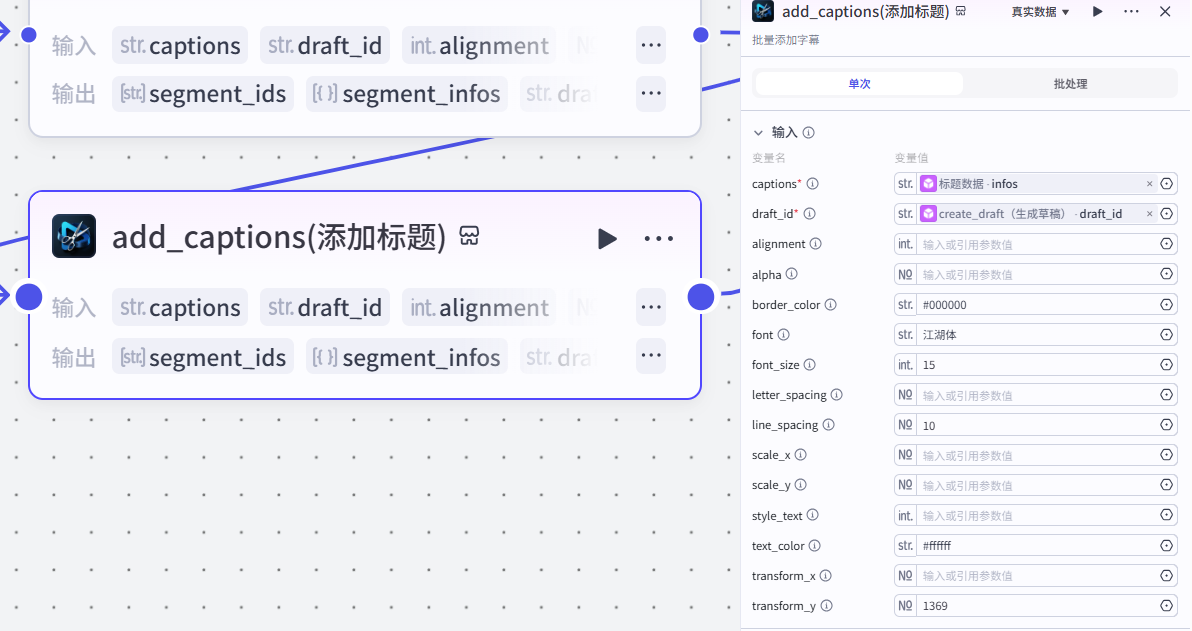
作用:根据草稿和标题数据,添加标题
注意:
这个插件来⾃于《剪映小助手》--《add_captions》插件
选择《单次》模式
21.批量添加音频节点
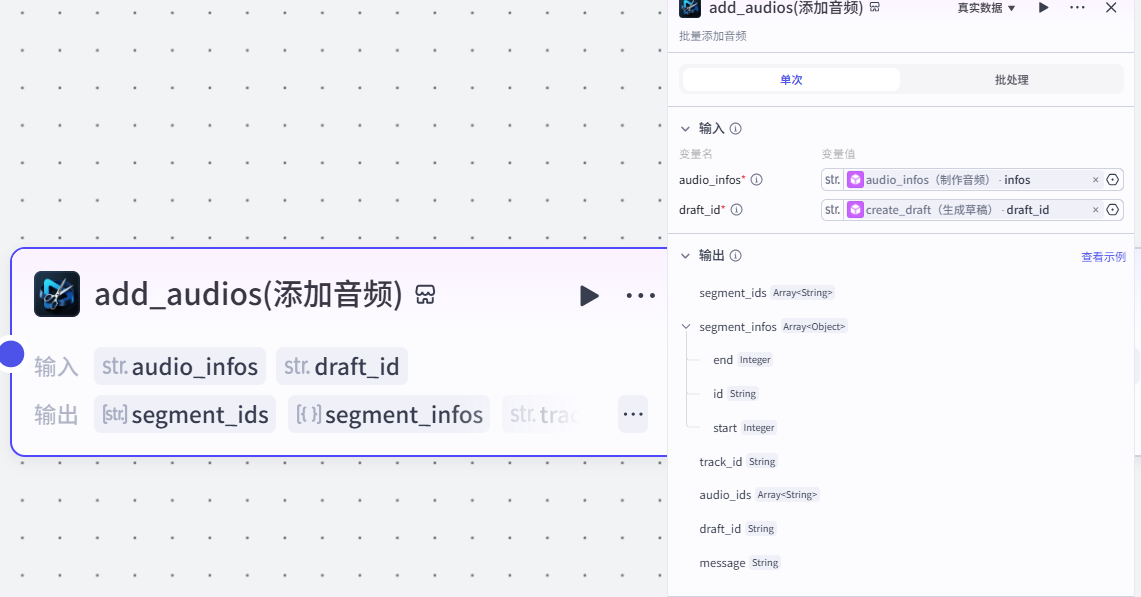
作用:根据草稿ID和音频数据,批量添加音频
注意:
这个插件来⾃于《剪映小助手》--《add_audios》插件
选择《单次》模式
22.结束节点
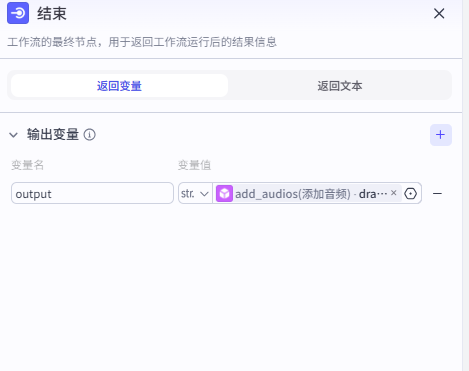

工作流--完结!!!
该工作流给出的id需在剪映进行生成视频就可以得到制作的视频。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 42
42 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)