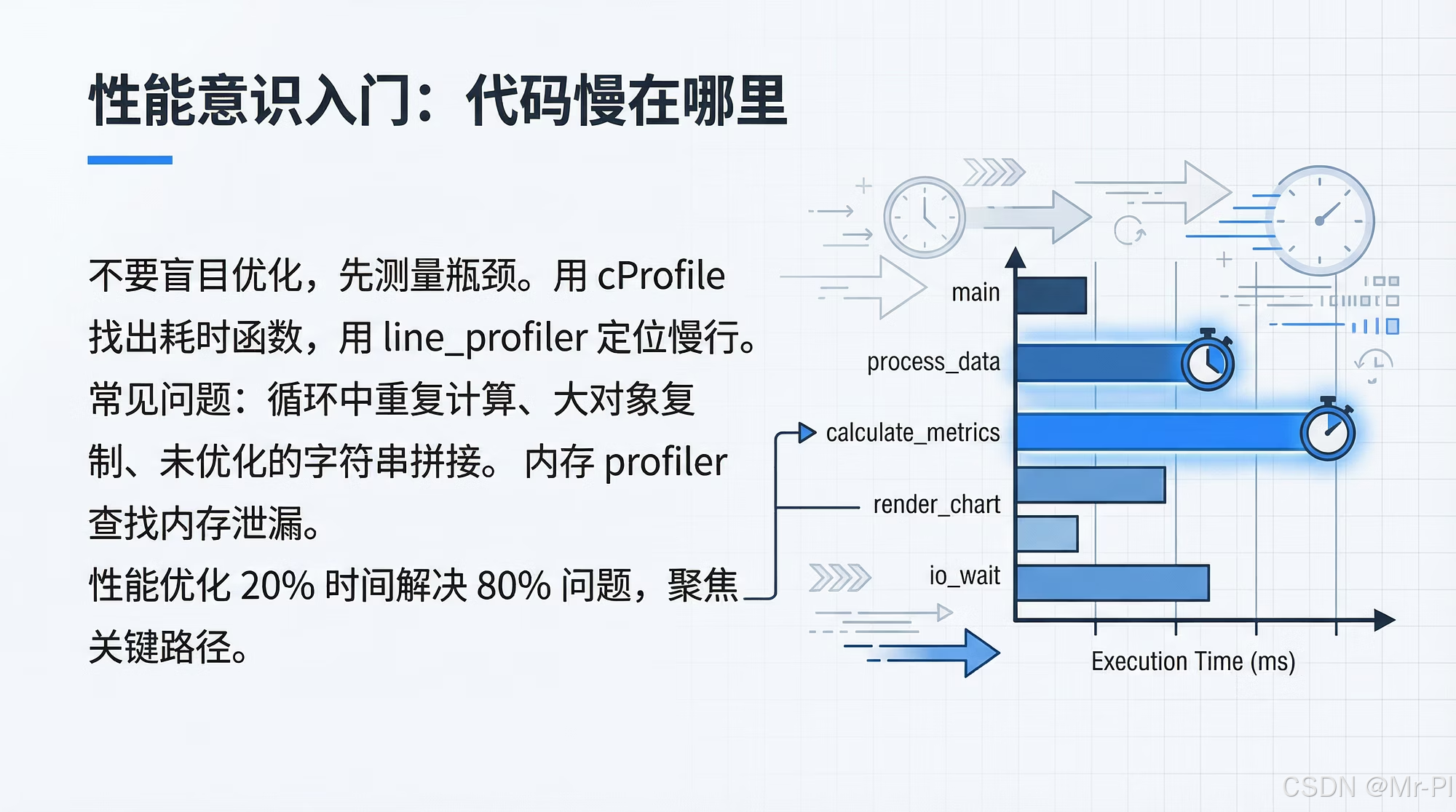
第十三章 性能意识入门:你代码慢在哪?profiling 的工程化思路
第十三章 性能意识入门:你代码慢在哪?profiling 的工程化思路
你有没有这种体验:
- 同样一段数据处理脚本,在你电脑上 2 分钟,到了服务器上 30 分钟;
- 明明“只是多加了一个特征”,训练时间翻倍;
- 你以为瓶颈在模型,结果慢在
groupby、慢在 IO、慢在一个不经意的apply。
数据分析与 AI 工程里,性能问题往往不是“写得不够快”,而是没有性能意识:
你不知道时间花在哪里,于是你只能靠猜。
本章目标很明确:
建立一套 profiling 的思维框架,让你每次遇到“变慢”,都能快速定位:慢在 CPU?慢在 IO?慢在内存?慢在算法复杂度?慢在数据结构?
0. 本章目标与适用场景
学完你应该能做到:
- 能用 30 秒判断:CPU-bound / IO-bound / Memory-bound
- 会用最小工具链:
time、cProfile、line_profiler、memory_profiler - 知道数据工程最常见的“性能坑”在哪里(Pandas / Python 原生 / 序列化)
- 能把优化过程变成“可复现实验”:基线 → 证据 → 优化 → 回归
- 初步掌握“性能预算”的写法:让项目可长期扩展
1. 性能优化的底层逻辑:先度量,再优化
如果只记一句话:
Never optimize what you haven’t measured.
你需要把性能问题当成一个实验问题:
这套流程能避免你在“拍脑袋优化”里浪费时间。
2. 三类瓶颈:CPU / IO / 内存(先做分类)
2.1 快速判断:看现象
- CPU-bound(算不动):CPU 长期 100%,风扇起飞;加线程不见得快
- IO-bound(读写慢):CPU 很闲,但一直在等磁盘/网络;加缓存可能立竿见影
- Memory-bound(内存/GC):内存飙升、swap、频繁 GC、甚至 OOM
你可以把“总耗时”粗略拆成:
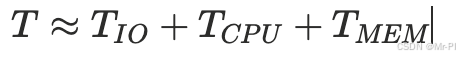
这不是严格公式,但足够指导你先从哪类工具入手。
3. 最小 profiling 工具链(够用就行)
3.1 先用最朴素的 time
很多时候你只需要知道“哪一步最慢”。
import time
t0 = time.perf_counter()
# step 1
t1 = time.perf_counter()
# step 2
t2 = time.perf_counter()
print("step1:", t1 - t0)
print("step2:", t2 - t1)
print("total:", t2 - t0)
工程建议:把 pipeline 拆成 5~10 个粗粒度步骤,先做“宏观定位”。
3.2 cProfile:找函数级热点(CPU)
适用:你不知道慢在哪个函数。
python -m cProfile -o out.prof your_script.py
再用 pstats 查看 Top N:
import pstats
p = pstats.Stats("out.prof")
p.sort_stats("cumtime").print_stats(20)
你要关注两个指标:
- tottime:函数自身耗时
- cumtime:包含子调用的累计耗时
很多数据工程瓶颈,都会在 cumtime 里露头。
3.3 line_profiler:精确到行(定位“那一行”)
适用:你已经锁定函数,但想知道慢在函数内部哪里。
安装:
pip install line_profiler
写法:
from line_profiler import profile
@profile
def build_features(df):
df["a"] = df["x"].fillna(0)
df["b"] = df.groupby("user")["a"].transform("mean")
return df
运行:
kernprof -l -v your_script.py
你会得到逐行耗时,这对定位 Pandas 的“隐形慢点”非常有效。
3.4 memory_profiler:看内存峰值(爆内存必备)
安装:
pip install memory_profiler
写法:
from memory_profiler import profile
@profile
def load_big():
import pandas as pd
df = pd.read_parquet("big.parquet")
return df
运行:
python -m memory_profiler your_script.py
你会看到每行代码内存变化,常用于发现“复制太多”“中间变量太大”。
4. 数据/AI工程最常见的性能坑(高频清单)
下面这几类,基本占了 80% 的慢。
4.1 Pandas 的 apply:最经典的性能陷阱
很多人写:
df["y"] = df["text"].apply(lambda s: s.lower().strip())
这会把向量化计算退化成 Python 循环。
更好的方式(优先用向量化):
df["y"] = df["text"].str.lower().str.strip()
经验法则:
能用 str.*、dt.*、numpy 就不要 apply。
4.2 groupby + transform / merge:隐性大杀器
groupby、merge 很强,但很贵。你要关注:
- key 的基数(cardinality)是否过大
- 是否发生了意外的笛卡尔积
- 是否在循环里做
merge
建议先用 profiling + 样本数据估算复杂度。
4.3 Python 循环处理大数组:算法复杂度不变,再快也没用
当你对 N=1e7 的数据做 Python for 循环:
for x in arr:
...
你本质是在赌解释器速度。
如果复杂度是 (O(N)) 且 N 很大,你要尽快迁移到:
- numpy 向量化
- numba
- Cython
- 或下沉到数据库/分布式计算引擎
4.4 IO:读 CSV 比读 Parquet 慢得多
很多 pipeline 慢在“格式选择”:
- CSV:解析成本高、类型推断慢
- Parquet:列式存储,读取需要的列更快
- Feather/Arrow:中间缓存非常友好
工程建议:训练/特征中间层尽量用 Parquet,并且显式指定 dtype,减少推断。
5. 一个可落地的 profiling 框架:把性能当成回归测试
你写单元测试是为了防 bug;你写性能测试是为了防“悄悄变慢”。
5.1 基线与对比:固定输入 + 固定指标
建议给核心函数做一个最小性能基线:
- 输入:固定 1 万行样本(可脱敏)
- 指标:耗时、内存峰值、P95 延迟(按场景选)
这会让你的项目从“功能能跑”升级到“性能可控”。
6. 优化策略的优先级:先做“收益最大”的
下面是我在数据/AI工程里常用的优化顺序:
- 删掉不必要的工作(减少读取列、减少中间表、减少重复计算)
- 改变数据格式与 IO(Parquet、缓存、批处理)
- 用向量化替代 Python 循环(Pandas/Numpy)
- 降低算法复杂度(从 (O(N^2)) 到 (O(N \log N)))
- 并行/分布式(最后再上,多线程/多进程/Ray/Spark)
为什么并行放最后?
因为你没定位热点,盲目并行只会把复杂度放大,并引入更多不可控因素。
7. 小结:性能意识=可解释、可复现、可持续
你不需要一开始就写出“极致快”的代码。
你需要的是一套方法,让你遇到性能问题时:
- 不猜
- 不拍脑袋
- 不靠运气
而是用 profiling 讲清楚:
“慢在这里,因为这个函数占了 60% cumtime;
我把它从 apply 改成向量化后,耗时从 12s 降到 2.8s;
回归数据集下指标不变,性能基线更新为 3s。”
这就是数据/AI工程里真正的“可维护”。
你可以直接拿来用的行动清单
如果你今天就要开始做 profiling,按这个顺序:
- 把 pipeline 切成 5~10 步,先
time粗定位 - 用
cProfile找 Top 20 热点函数 - 对 Top 1~3 函数上
line_profiler - 如果有 OOM/卡顿,上
memory_profiler - 固定样本数据,建立性能基线(写到 README)
下一章:
《第14章 代码质量清单:从“能跑”到“可交付”》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)