基于GPT-2通用文本模型全量微调训练
本课程介绍如何基于HuggingFace Transformers进行GPT-2中文模型的全量微调训练。使用60万条对联数据集,通过自定义Dataset类加载数据,利用AutoTokenizer进行文本编码。采用AutoModelForCausalLM加载预训练模型,在3轮训练中优化模型参数,实现对联生成功能。训练过程中监控损失和准确率,每1000批次保存模型权重。测试结果显示模型已初步具备对联生
大家好,我是python222_小锋老师,最近更新《AI大模型应用开发入门-拥抱Hugging Face与Transformers生态》专辑,感谢大家支持。
本课程主要介绍和讲解Hugging Face和Transformers,包括加载预训练模型,自定义数据集,模型推理,模型微调,模型性能评估等。是AI大模型应用开发的入门必备知识。

基于GPT-2通用文本模型全量微调训练
我们使用中文通用文本模型gpt2-chinese-cluecorpussmall,因为这个模型不具备对联文本生成能力,所以我们使用自己的对联数据集去完整训练模型,全量微调训练,最终训练出一个能实现对联文本生成的模型。
1,自定义数据集
首先我们准备下训练数据。
![]()
60多万条训练集数据。
我们之所以要自定义数据集,是因为需要去适配训练模型需要的数据格式。
自定义数据集示例代码:
from datasets import load_dataset
from torch.utils.data import Dataset
# 自定义数据集
class MyDataset(Dataset):
def __init__(self, split):
# 加载训练集
train_dataset = load_dataset(path="csv", data_files="./couplet_train_600k.csv")
self.data = train_dataset['train']
# 获取数据集大小
def __len__(self):
return len(self.data)
# 获取数据集的某个元素
def __getitem__(self, index):
return self.data[index]['text1']
if __name__ == '__main__':
train_dataset = MyDataset('train')
# print(train_dataset[0])
for data in train_dataset:
print(data)运行结果:

2,对训练输入文本进行编码
对传入的数据进行训练之前,我们需要对数据进行编码。
我们通过分词器的batch_encode_plus方法进行批量编码;
实例代码:
from transformers import AutoTokenizer
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('../gpt2-chinese-cluecorpussmall')
# 准备测试文本
sents = ['东风揉碎西江月 金惢染浓玉堂春', '涤净尘埃真境界 修成正果雅风光', '青史应同久 紫书倘可传']
# 批量编码句子
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents, # 输入的文本
add_special_tokens=True, # 添加特殊标记
max_length=50, # 最大长度
padding='max_length', # 填充
truncation=True, # 截断
return_tensors='pt' # 返回pytorch张量
)
print(out)
for k, v in out.items():
print(k, v)
# 解码文本数据
for i in range(len(sents)):
print(sents[i] + "--编码后:", tokenizer.decode(out['input_ids'][i]))运行结果:

3,定义全量微调,实现模型训练任务
我们使用中文通用文本模型gpt2-chinese-cluecorpussmall,因为这个模型不具备对联文本生成能力,所以我们使用自己的对联数据集去完整训练模型,全量微调训练,最终训练出一个能实现对联文本生成的模型。
示例代码:
import torch
from datasets import load_dataset
from torch.utils.data import DataLoader, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
# 自定义数据集
class MyDataset(Dataset):
def __init__(self, split):
# 加载训练集
train_dataset = load_dataset(path="csv", data_files="./couplet_train_600k.csv")
self.data = train_dataset['train']
# 获取数据集大小
def __len__(self):
return len(self.data)
# 获取数据集的某个元素
def __getitem__(self, index):
return self.data[index]['text1']
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('../gpt2-chinese-cluecorpussmall')
# 使用设备(GPU/CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型
model = AutoModelForCausalLM.from_pretrained('../gpt2-chinese-cluecorpussmall').to(device)
# 对传入数据进行编码
def collate_fn(data):
# 批量编码句子
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=data, # 输入的文本
add_special_tokens=True, # 添加特殊标记
max_length=50, # 最大长度
padding='max_length', # 填充
truncation=True, # 截断
return_tensors='pt' # 返回pytorch张量
)
out['labels'] = out['input_ids'].clone() # 创建标签 克隆一份
return out
# 创建数据集
train_dataset = MyDataset('train') # 训练集
train_loader = DataLoader(
dataset=train_dataset, # 数据集
batch_size=10, # 批次大小
shuffle=True, # 是否打乱数据
drop_last=True, # 丢弃最后一个批次数据
collate_fn=collate_fn # 对加载的数据进行编码
)
if __name__ == '__main__':
EPOCH = 3 # 训练轮数
optimizer = torch.optim.AdamW(model.parameters()) # 优化器
model.train() # 设置成训练模式
for epoch in range(EPOCH):
for i, data in enumerate(train_loader):
for j in data.keys(): # 遍历数据
data[j] = data[j].to(device) # 移动数据到设备
out = model(**data) # 前向传播
loss = out.loss # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
optimizer.zero_grad() # 清空梯度
if i % 30 == 0: # 每隔30个批次输出训练结果
labels = data['labels'][:, 1:] # 获取真实标签,移除第一个特殊标记
out = out['logits'].argmax(dim=2)[:, :-1] # 获取预测结果,移除最后一个特殊标记
acc = (out == labels).sum().item() / labels.numel()
print("EPOCH:{}--第{}批次--损失:{}--准确率:{}".format(epoch + 1, i + 1, loss.item(), acc))
if i % 1000 == 0:
torch.save(model.state_dict(), "best_model.pth")
print("训练完成")
torch.save(model.state_dict(), "last_model.pth")运行结果:
EPOCH:1--第42721批次--损失:1.6447025537490845--准确率:0.7306122448979592
EPOCH:1--第42751批次--损失:1.6567798852920532--准确率:0.7224489795918367
EPOCH:1--第42781批次--损失:1.7314213514328003--准确率:0.7122448979591837
EPOCH:1--第42811批次--损失:1.4304875135421753--准确率:0.7489795918367347
EPOCH:1--第42841批次--损失:1.7530544996261597--准确率:0.7
EPOCH:1--第42871批次--损失:1.4136962890625--准确率:0.7489795918367347
EPOCH:1--第42901批次--损失:1.335880160331726--准确率:0.7877551020408163
EPOCH:1--第42931批次--损失:1.6236571073532104--准确率:0.7448979591836735
EPOCH:1--第42961批次--损失:1.5450268983840942--准确率:0.7326530612244898
EPOCH:1--第42991批次--损失:1.1529603004455566--准确率:0.8
EPOCH:1--第43021批次--损失:1.5731669664382935--准确率:0.7163265306122449
EPOCH:1--第43051批次--损失:1.4738476276397705--准确率:0.7408163265306122
EPOCH:1--第43081批次--损失:1.4993581771850586--准确率:0.736734693877551
EPOCH:1--第43111批次--损失:1.4280855655670166--准确率:0.7591836734693878
EPOCH:1--第43141批次--损失:1.8130102157592773--准确率:0.689795918367347
EPOCH:1--第43171批次--损失:1.3389391899108887--准确率:0.7693877551020408
EPOCH:1--第43201批次--损失:1.27996027469635--准确率:0.7591836734693878
EPOCH:1--第43231批次--损失:1.3075250387191772--准确率:0.7653061224489796
EPOCH:1--第43261批次--损失:1.2324328422546387--准确率:0.7816326530612245
EPOCH:1--第43291批次--损失:1.4553524255752563--准确率:0.7591836734693878
EPOCH:1--第43321批次--损失:1.3804436922073364--准确率:0.7653061224489796
EPOCH:1--第43351批次--损失:1.5597093105316162--准确率:0.7489795918367347
EPOCH:1--第43381批次--损失:1.602893352508545--准确率:0.7142857142857143
EPOCH:1--第43411批次--损失:1.3732272386550903--准确率:0.773469387755102
EPOCH:1--第43441批次--损失:1.560001015663147--准确率:0.746938775510204
EPOCH:1--第43471批次--损失:1.5979629755020142--准确率:0.746938775510204
EPOCH:1--第43501批次--损失:1.350143313407898--准确率:0.7714285714285715
EPOCH:1--第43531批次--损失:1.367422342300415--准确率:0.773469387755102
EPOCH:1--第43561批次--损失:1.5746468305587769--准确率:0.7387755102040816训练时间非常长。我们训练到第一个轮次 4万多条数据的时候,来加载模型权重参数测试下;
测试代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
def test_text_generation():
# 使用设备(GPU/CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# print(device)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('../gpt2-chinese-cluecorpussmall')
# 加载模型
model = AutoModelForCausalLM.from_pretrained('../gpt2-chinese-cluecorpussmall')
# print(model)
# 加载保存的模型权重
model.load_state_dict(torch.load('best_model.pth'))
# 设置为评估模式
model.eval()
model.to(device)
# 准备输入数据
input_ids = tokenizer.encode(
text='春满神州花似锦-', # 输入文本
return_tensors='pt' # 返回PyTorch张量
).to(device)
# 生成文本
output_sequences = model.generate(
input_ids=input_ids,
max_length=25, # 生成的文本总长度
num_return_sequences=1, # 返回的生成序列数量
no_repeat_ngram_size=2, # 避免重复的n-gram 防止相同词组重复出现,从而提高生成文本的多样性和自然性。
temperature=0.7, # 温度参数控制随机性
top_k=50, # 仅从前k个概率最高的单词中采样
top_p=0.95, # 只从前95%概率质量的词汇中进行随机采样 核采样策略
do_sample=True # 开启采样
)
# print(output_sequences)
# 解码并打印生成的文本
for sequence in output_sequences:
generated_text = tokenizer.decode(sequence, skip_special_tokens=True)
print(generated_text)
if __name__ == '__main__':
for i in range(3):
test_text_generation()运行结果:
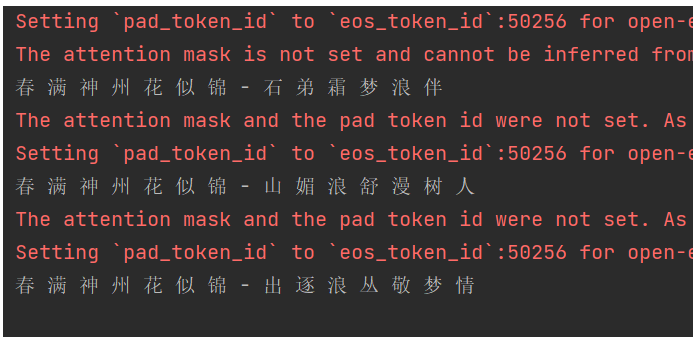
总体看来,还是有点效果的。虽然训练还不足。但是我们发现一个明显的问题,格式有时候不对,原因是一些未识别的生僻词,不在词汇表里,返回了UNK。模型是负责输出,但是格式的话,我们得通过编码进行控制。比如下方判断长度。
# 解码并打印生成的文本
for sequence in output_sequences:
generated_text = tokenizer.decode(sequence, skip_special_tokens=True)
if len(generated_text) == 29:
print(generated_text)4,生成文本模型微调的评估方式
生成式大模型的微调评估是一个多维度、系统性的工程。以下从评估方法论、评估维度和实践流程三个层面进行梳理:
一、评估方法论分类
-
自动化评估
-
基于规则的评估:BLEU、ROUGE、METEOR(适合翻译、摘要等任务)
-
基于模型的评估:
-
BERTScore:使用预训练模型计算语义相似度
-
BLEURT:专门训练的评估模型
-
GPT-as-judge:使用更强大的LLM(如GPT-4)作为评判者
-
FactScore:针对事实性评估的专门指标
-
-
人工评估
-
评分式评估:从1-5分或1-7分评估回复质量
-
比较评估:将多个模型输出进行两两比较
-
维度专项评估:按流畅度、相关性、安全性等维度分别评估
-
任务特定评估
-
代码生成:Pass@k、测试用例通过率
-
数学推理:准确率、步骤正确性
-
对话系统:连贯性、一致性、用户满意度
二、核心评估维度
-
能力维度
-
指令遵循能力:是否理解并执行用户指令
-
任务完成质量:针对下游任务的专业表现
-
泛化能力:对未见过的指令或任务的适应能力
-
安全与对齐维度
-
安全性评估:
-
有害内容生成率
-
偏见与公平性分析
-
越狱攻击抵抗力
-
-
价值观对齐:符合人类价值观的程度
-
效率维度
-
推理速度:生成tokens/秒
-
内存使用:显存占用情况
-
部署成本:吞吐量和延迟的综合考量
三、业界主流评估框架
-
综合性基准测试集
-
MT-Bench:多轮对话评估基准
-
AlpacaEval:基于指令跟随的自动评估
-
HELM:全面的语言模型评估框架
-
Open LLM Leaderboard:Hugging Face的集成评估
-
中文特定评估
-
C-Eval:中文学科知识评估
-
CMMLU:中文多任务语言理解
-
GAOKAO-Bench:高考题目评测
-
专业领域评估
-
MedQA:医学领域评估
-
HumanEval:代码生成评估
-
MathQA:数学推理评估

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)