我用AI做的2/100件事之公募基金持仓明细获取
这里我存了两个格式csv和excel,我们实际需要的是csv格式,比较方便后续的处理,那为啥还需要excel呢,因为我们提取持仓信息后还得校验一下,如果靠人工眼睛去核对,那眼睛看瞎了2000个文档不知道能不能比对的过来。所以最终我是借助AI的能力将需求进行拆解,最终我再来组装一下。跑代码比如下载、识别、提取什么的都还好,人工比对真的太耗精神了,我目前做了50个pdf的提取和比对,花了约60分钟,一
一、前言
1. 突发奇想
最近股市又火了,所以我也在琢磨买基金的事情,但根据以往的经验,其实大家都是稀里糊涂在买。比如人工智能火,可能就找名字跟人工智能靠边的,但实际上可能只是做些边角料的供应商。主要痛点在于,某一只基金我们很难通过名字就能确定它的投资标的。所以我们要看一下它的持仓对吧,然后根据持仓来分析这个基金的真实投资情况。然后一家家看肯定不行的,所以得找API接口或者csv文件的形式。这样我拿到持仓数据之后,还可以做进一步的分析,比如说我想找人工智能相关的基金,我可以对全量股票做一个含量评估(这个可以交给AI或者再讨论),再根据人工智能含量来评估各基金的人工智能综合含量。对吧,挺有想象空间的。
2. 不好弄
我先是找有没有csv文件,自然是没有的,然后豆包告诉我有一些接口可以API的形式提供,比如tushare,我也找了,还花了点钱试用一下。结果发现数据很多错误,有点难顶。所以我对其他接口也持怀疑态度了,那就只能自己搞!
经过摸排发现,公募基金的持仓数据其实会定期公布的,有一个公布的平台,还能下载下来(PDF格式)。
3. 尝试AI
我最开始的方案是将pdf文件上传给AI,让AI直接将持仓数据输出成文件,尝试了市面上所有主流的AI,最后豆包全面获胜(国外的也试了,真的不太行)。一个个文件太麻烦对吧,所以我又改成文件链接的形式喂给豆包,也成功了。但仅季度报可行,年报、半年报不可行,因为免费的太慢甚至会卡死,收费的太贵(我用coze实现了链接投喂直接返回持仓数据,但每次要消耗3万-9万token,搞不起)!
4. 不太完美的解决方案
世事往往如此,优美的方案总是需要花很多钱,而苟的方案不花钱但是很丑。所以我将任务进行了拆解:
1)爬链接并下载全量PDF文件
2)获取持仓数据的页码
3)根据页码对PDF文件进行裁剪
4)将裁剪后的PDF文件转成txt格式
5)从txt里提取需要的持仓信息并保存成csv和excel格式的文件
6)将excel格式的持仓信息文件转存成PDF
7)转存的持仓信息PDF文件与原始的PDF文件进行比对
上述步骤除最后一步是人工操作外,其他步骤全都是依靠豆包提供的python代码实现的,当然并不是光提需求豆包就会给你完美的代码,中间也花费了不少时间去调试。执行的代码也是拆解成了很多份:

二、实施步骤
1. 爬链接并下载PDF文件
爬链接比较简单,我用的八爪鱼,咔咔一会就爬了2000多个链接,接着就根据链接去下载,就是“0_downPDF.py”,代码概览。
全部代码都是豆包写的,需要的话可以留言我给你发。
这里我是分批下载和处理的,第一批先弄50个链接试试水。下载到SPDF1目录,结果是这样的PDF文件:
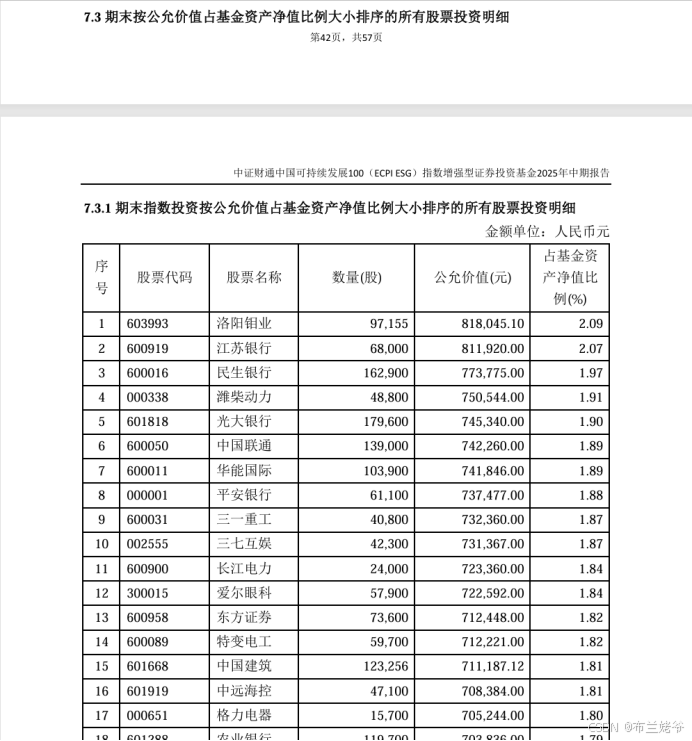
7.3这里就是全量的持仓信息了。
2. 获取持仓数据的页码
可以看到持仓数据都放在7.3这个章节下一个章节是7.4,所以我可以先找到7.3、7.4的页码,后面再根据这两个页面去做PDF的裁剪。
依旧是豆包给的代码:
实践发现,7.3这个章节名,有些基金公司给的文件可能会有出入,比如漏了空格、少几个字,所以还得做模糊识别。将识别结果放到“文件路径及页面1.csv”,将能找到章节的PDF放到“OKPDF1”目录,找不到章节或有任何其他异常的PDF文件放到“NOPDF1”目录。结果如下:
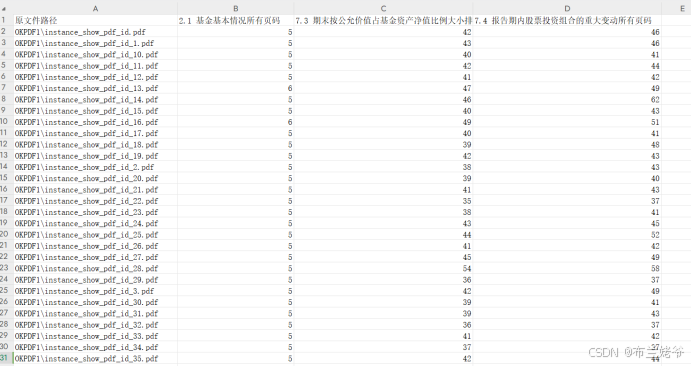
实际上这是我微调后的,在识别章节标题时总是会有一些问题,需要调整下。这样我们就得到了PDF路径和重要章节的页码。
3. 根据页面进行PDF裁剪
读取前面落的文件,我们知道文件路径和页码,直接用python代码进行文件裁剪,自然还是豆包提供的代码。裁剪逻辑是保留2.1这一页,因为有基金的基本信息,保留7.3至7.4的页码,因为持仓信息就在这中间,其他页码全部删除。裁剪后的结果放到“CUTPDF1”,代码概览:

4. 裁剪后的PDF转txt
这一步的目的是为了方便后续信息的提取,那有人要问了,pdf不能直接提取数据吗?可以是可以的,但PDF里带了一些格式信息(比如表格),可能会影响解析(没验证,后面试下)。所以最稳妥还是先转成txt文本,把格式信息都去掉,只对纯文本处理感觉更简单一些。代码概览:
结果存放到“TXT1”目录,结果示例:

5. 提取持仓信息
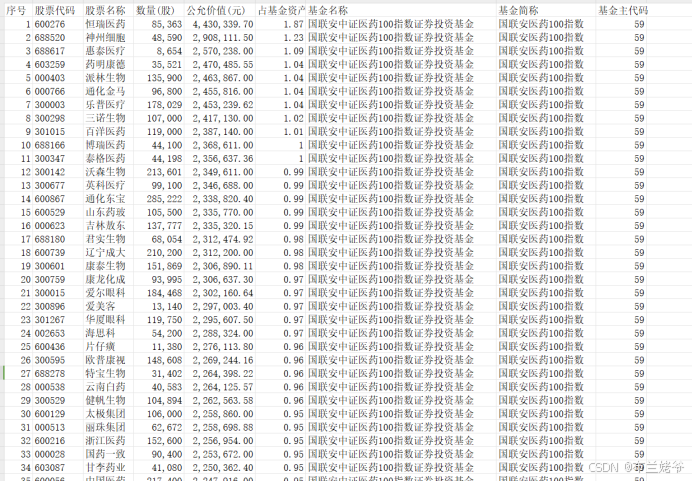
这里我存了两个格式csv和excel,我们实际需要的是csv格式,比较方便后续的处理,那为啥还需要excel呢,因为我们提取持仓信息后还得校验一下,如果靠人工眼睛去核对,那眼睛看瞎了2000个文档不知道能不能比对的过来。所以势必要用自动识别,正好WPS就有这样的功能,但仅限同格式文件,比如pdf和pdf进行对比,所以我们又需要将提取的持仓数据转成pdf格式。在csv文件转pdf时总是会有各种问题最终发现excel可以完美转pdf,所以这里我们分别存csv格式和excel。代码概览:


结果:
6. Excel格式的结果转pdf
比较简单,代码示例:
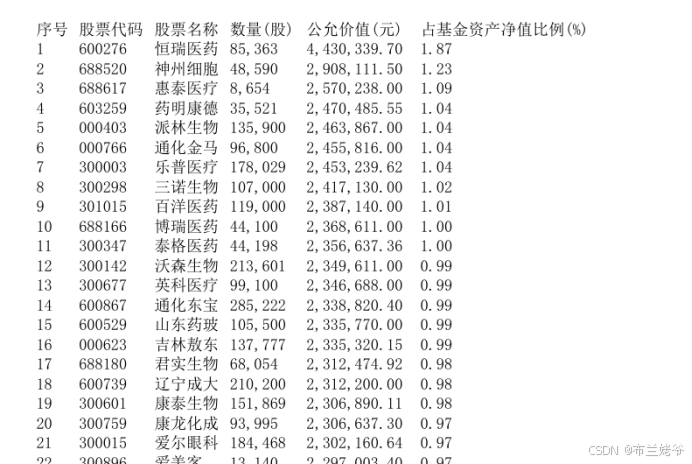
结果示例:
7. 比较核对
怎么知道我们提取的持仓数据都是对的呢,自然是需要做校对的,人工一行行看数据眼睛会瞎,所幸我们有wps。虽然也有脚本可以实现批量比对,但比对结果太乱了根本看不明白,还是我们肉眼看一遍稳妥:

有一说一,这个功能还是很强的,要知道我是拿最终结果和包含了大量冗余信息的原始文档进行比对。我还试过将某个数字特意改了一下,没想到能精确识别出来。所以只要比对结果中数据没有被圈起来,就是没问题的,它可以自动略过冗余信息做特定数据的比对。
三、总结
本文篇幅很长,代码因为篇幅原因就不全部po出来了,需要的可以留言我给你发。
整个过程虽然都是依靠豆包实现的,但还是踩了很多坑,最早从12月中旬就开始弄了,一直到现在1月底才搞定。
跑代码比如下载、识别、提取什么的都还好,人工比对真的太耗精神了,我目前做了50个pdf的提取和比对,花了约60分钟,一共有2300个pdf,那单2025年的中报就需要最少46个小时,每天花2个小时也得一个月才搞得完,我滴天。马上又是2025年年终报了,我滴天。请有同样需求的友友立即联系我,我免费提供全套解决方案,手把手给你教会,你把结果跟我共享就行了。
其次说下我这个系列,从名字就能看出来,我准备靠AI来做100个小项目,AI改变生活嘛。一方面通过这个系列来熟悉AI,其次也是完成一下我年轻时的梦想(瞎折腾的梦想),现在有了AI真的好多疯狂的想法都可以实现了!你要是有什么想法也可以留言,我们一起来研究。
最后给大家汇报一下我目前的体会:AI目前还是“强大的小脑”,举例来说,它可以提升你单项能力,但最终产出还得靠你来组合,如果你想让它咔咔直接实现你的需求可能还没那么厉害。以本篇为例,一开始的解决方案其实就是让AI直接读取pdf文件把持仓信息提取出来,直接落文件,也真的可以实现。但我们终端用户能够使用的资源太有限,一次处理不了太多信息,一旦PDF太大就玩不动了。所以最终我是借助AI的能力将需求进行拆解,最终我再来组装一下。
OVER,如果对后续其他AI实践项目有兴趣的话,欢迎关注我!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)