让大模型真正“干活“:LangChain与Python MCP集成深度解析,解决开发者6大痛点
本文分析了LangChain与Python MCP集成的六大核心挑战:接口抽象冲突、状态管理不一致、性能损耗、版本兼容性问题、调试困难及安全管控缺口。提出标准化适配、统一状态管理、性能优化等解决方案,强调需平衡灵活性与标准化,根据场景取舍适配层设计。
本文分析了LangChain与Python MCP集成的六大核心挑战:接口抽象冲突、状态管理不一致、性能损耗、版本兼容性问题、调试困难及安全管控缺口。提出标准化适配、统一状态管理、性能优化等解决方案,强调需平衡灵活性与标准化,根据场景取舍适配层设计。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
今年以来 mcp实在太火了,有个比喻挺贴切的,当大模型有了 mcp就相当于有了手和脚,真正可以替用户干活了。甚至,有预言 mcp会是未来专属大模型的 app。
而 Anthropic 模型上下文协议(MCP)则为模型与外部工具之间的交互提供了一种标准化的方式。langchain-mcp-adapters 库的出现,使得 MCP 工具能够无缝集成到 LangChain 和 LangGraph 中,为开发者提供了更多的工具选择和更灵活的应用开发方式。
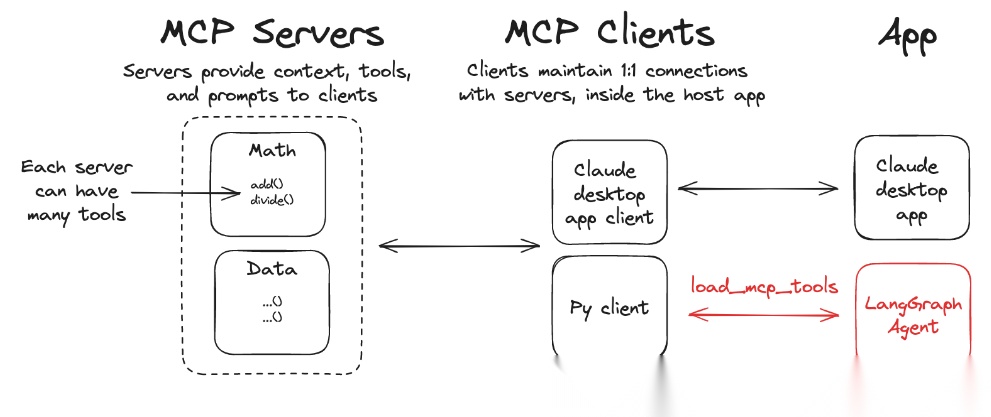
但是LangChain 与 Python MCP 的集成本质是「灵活的组件化框架」与「强标准化的交互协议」的融合,问题集中在接口抽象不兼容、状态管理不同步、多层抽象性能损耗、版本与生态适配脱节等维度,这些问题直接影响集成后的稳定性、性能和可维护性。
以下是具体问题拆解及对应的核心应对思路。
本文将针对以下问题进行探讨:
| 问题类型 | 核心应对原则 |
|---|---|
| 接口抽象冲突 | 优先标准化适配,减少自定义扩展,基于双方核心抽象而非具体实现开发适配层 |
| 状态同步不一致 | 单数据源(如 LangGraph State)+ 自动同步钩子,统一生命周期与序列化规则 |
| 性能损耗 | 全异步 + 精简中间层 + 二进制协议,高并发场景跳过非必要封装 |
| 版本兼容性 | 版本锁定 + 抽象解耦 + 自动化测试,降低版本迭代的维护成本 |
| 调试与可观测性 | 全链路 trace_id + 统一日志 + Mock 测试,打破多层黑盒 |
| 安全管控 | 鉴权托管 + TLS 加密 + 数据脱敏,对齐企业级安全规范 |
一、核心问题 1:接口抽象层的本质冲突
LangChain 的组件抽象(Tool/Memory/LLM)与 Python MCP 的协议抽象(标准化请求 / 上下文 / 错误)并非天然对齐,适配层需解决 “灵活度” 与 “标准化” 的矛盾,具体表现为:
1. 工具接口的适配断层
- 具体问题
- LangChain Tool 的核心抽象是「同步 / 异步执行方法(_run/_arun)+ 自由参数格式」,而 MCP 要求严格的 JSON-RPC 请求格式(固定 method/params/context_id 字段),参数类型仅支持 JSON 原生类型(字符串 / 数字等),但 LangChain 常使用自定义对象(如
Document、pandas.DataFrame)作为参数 / 返回值,直接转换会丢失信息; - LangChain Tool 的描述格式(
description字段)是自然语言,而 MCP 工具需提供标准化 Schema(参数名 / 类型 / 值域),Agent 基于 LangChain 的 Prompt 决策时,可能无法正确解析 MCP 工具的 Schema 约束; - MCP 支持异步 / 双向流调用,但 LangChain 部分老旧 Tool 仅支持同步调用,适配时需额外封装异步层,增加复杂度。
- 应对思路
- 开发统一的「数据转换中间层」:将 LangChain 的自定义对象(如
Document)序列化为 MCP 兼容的 JSON 格式(如{"page_content": "...", "metadata": {...}}),返回时再反序列化; - 自动生成适配层:基于 MCP 的工具 Schema 自动生成 LangChain Tool 类(包含
name/description/ 参数校验),确保 Tool 描述与 MCP Schema 一致; - 强制异步优先:适配层统一实现
_arun()异步方法,LangChain 调用时优先使用异步模式,避免同步阻塞。
2. 错误体系的不兼容
- 具体问题
- LangChain 的工具调用异常是 Python 原生异常(如
ValueError/ConnectionError),而 MCP 定义了标准化错误码体系(如 - 32601 方法不存在、-32000 工具执行失败),异常透传时会出现 “错误语义丢失”(如 MCP 的 - 32100 权限错误被 LangChain 捕获为通用MCPError,无法区分具体原因); - LangChain Agent 的错误重试逻辑(如
max_iterations)仅识别特定异常,无法适配 MCP 的标准化错误码,导致重试策略失效(如 MCP 返回 “工具执行超时” 错误,LangChain 未触发重试)。
- 应对思路
- 封装异常映射层:将 MCP 错误码转换为 LangChain 可识别的自定义异常(如
MCPMethodNotFoundError/MCPPermissionError),保留 MCP 原始错误数据; - 扩展 LangChain 重试逻辑:基于 MCP 错误码配置重试规则(如仅重试 - 32000 工具执行失败,不重试 - 32601 方法不存在)。
二、核心问题 2:状态管理的同步一致性问题
LangChain 的 Memory(会话记忆)与 Python MCP 的 Context(标准化上下文)是两套独立的状态体系,集成时易出现 “数据孤岛” 或 “状态不一致”,具体表现为:
1. 双状态体系的同步延迟
- 具体问题
- LangChain Memory 默认存储在本地内存(如
ConversationBufferMemory),而 MCP Context 支持持久化(Redis / 数据库),多轮交互时可能出现 “LangChain Memory 更新了但 MCP Context 未同步”(如 Agent 调用工具后,Memory 记录了结果,但 MCP Context 仍为旧数据); - 上下文生命周期不一致:LangChain Memory 的生命周期绑定 Agent 会话,而 MCP Context 可独立配置过期时间(如 1 小时),若生命周期不匹配,会出现 “Agent 会话未结束但 MCP Context 已过期”,导致工具调用失败。
- 应对思路
- 单向数据流设计:将 LangGraph 的 State(若集成 LangGraph)作为唯一数据源,LangChain Memory 和 MCP Context 均从 State 读写数据,避免双写;
- 上下文同步钩子:在 LangChain Memory 的
save_context()方法中添加钩子,自动将新数据同步到 MCP Context; - 统一生命周期配置:将 LangChain Memory 的过期逻辑与 MCP Context 的 TTL(生存时间)对齐,通过配置中心统一管理。
2. 复杂上下文的序列化损耗
- 具体问题
- LangChain Memory 常存储复杂结构(如多轮对话的
HumanMessage/AIMessage对象),转换为 MCP Context 的 JSON 格式时,需额外序列化(如将 Message 对象转为{"role": "...", "content": "..."}),增加 CPU 开销; - MCP Context 的 JSON 格式无法保留 LangChain Message 的元数据(如
tool_calls字段),导致上下文恢复时丢失关键信息。
- 应对思路
- 精简上下文数据:仅同步核心字段(role/content/tool_calls)到 MCP Context,非核心元数据保留在 LangChain Memory 中;
- 自定义序列化规则:基于 MCP 的扩展字段(
context.metadata)存储 LangChain 特有的元数据,确保信息完整。
三、核心问题 3:多层抽象导致的性能损耗
LangChain + MCP 的集成引入了多轮封装和协议转换,在高并发 / 低延迟场景下性能问题突出,具体表现为:
1. 序列化 / 反序列化的额外开销
- 具体问题
- 数据流转链路:
LangChain Agent → MCPLangChainTool → MCP Client(序列化JSON) → MCP Server(反序列化) → 外部系统 → MCP Server(序列化) → MCP Client(反序列化) → LangChain Agent,每轮工具调用需至少 2 次 JSON 序列化 / 反序列化,大参数(如长文本、结构化数据)场景下耗时显著; - LangChain 的
Runnable接口与 MCP Client 的调用接口之间的参数转换(如 Dict → JSON 字符串 → Dict),进一步增加开销。
- 应对思路
- 精简参数传输:仅传输必要参数,避免大文本 / 二进制数据通过 MCP 协议传输(可改用文件存储 + URL 引用);
- 采用二进制协议:部分 MCP 实现支持 MessagePack(二进制 JSON)替代纯 JSON,降低序列化开销;
- 直接调用优化:高并发场景下,跳过 LangChain Tool 封装,直接在 LangGraph Node 中调用 MCP Client,减少中间层。
2. 同步调用的阻塞问题
- 具体问题
- LangChain Agent 默认同步调用工具,而 MCP Client 的同步
call_method()方法会阻塞整个 Agent 流程,高并发下(如每秒 100 + 工具调用)会导致线程池耗尽,吞吐量下降; - LangChain 的异步 Runnable 与 MCP Client 的异步
acall_method()适配不完整,易出现 “异步嵌套阻塞”(如 LangChain 异步链中调用同步 MCP Client 方法)。
- 应对思路
- 全异步改造:适配层统一使用 MCP Client 的异步方法,LangChain Agent/Chain 采用异步模式(如
AsyncAgentExecutor); - 引入协程池:使用
asyncio协程池管理 MCP 异步调用,避免单线程阻塞; - 批量调用优化:对批量工具调用场景(如批量查询多个城市天气),封装 MCP 批量调用方法,减少网络往返次数。
四、核心问题 4:版本兼容性的持续维护成本
LangChain 和 MCP 的版本迭代特性导致适配层频繁失效,是集成后维护的核心痛点:
1. LangChain API 的高频变更
- 具体问题
- LangChain 的核心抽象(如
Chain→Runnable、Memory接口变更)在 v0.1→v0.2 等版本中大幅调整,基于旧版本开发的MCPLangChainTool/MCPMemory会直接失效; - LangChain 第三方集成(如向量数据库、LLM)的 API 变更,会间接影响 MCP 适配层的依赖(如 LangChain 的 OpenAI 接口变更,导致
MCPChatModel无法调用)。
- 应对思路
- 版本锁定:集成时固定 LangChain 版本(如
langchain==0.2.10),避免自动升级; - 适配层抽象解耦:将适配层与 LangChain 的具体 API 解耦,基于 LangChain 的核心抽象(如
Runnable)而非具体实现开发,降低版本变更影响; - 自动化测试:为适配层编写全量单元测试,LangChain 版本更新后自动验证适配层可用性。
2. MCP 协议版本的迭代
- 具体问题
- MCP 协议的小版本更新(如 v1.0→v1.1)可能调整请求 / 响应字段(如新增
timeout参数),导致旧版 MCP Client 与新版 MCP Server 不兼容; - 不同厂商的 MCP 实现(如官方 MCP、企业自研 MCP)对协议的扩展不同,适配层需兼容多版本协议。
- 应对思路
- 协议版本校验:在适配层添加 MCP 协议版本检测逻辑,不兼容时返回明确错误;
- 向后兼容设计:适配层支持多版本 MCP 协议,根据服务端返回的版本自动切换请求格式;
- 避免依赖扩展字段:仅使用 MCP 核心协议字段(method/params/context_id),不依赖厂商自定义扩展。
五、核心问题 5:调试与可观测性的黑盒化
多层集成导致问题定位困难,调试成本远高于单独使用 LangChain 或 MCP:
1. 链路追踪的断层
- 具体问题
- LangChain 的日志(如 Tool 调用日志)与 MCP 的日志(如请求 / 响应日志)分散在不同组件中,无统一的 trace_id 关联,难以追踪 “Agent 决策→MCP 请求→外部系统执行” 的完整链路;
- MCP 的错误日志仅输出协议层面信息,无法关联到 LangChain 的具体 Agent 步骤(如哪个 Node 触发的 MCP 调用)。
- 应对思路
- 全链路 trace_id:在 MCP 请求的
context.metadata中添加 LangChain 的 trace_id,贯穿 Agent→适配层→MCP Client→MCP Server; - 统一日志格式:将 LangChain 和 MCP 的日志标准化(如 JSON 格式,包含 trace_id / 组件名 / 耗时),接入 ELK 等日志平台;
- 可视化调试:使用 LangChain Studio 或 MCP 的调试面板,关联两者的调用链路。
2. 工具调用的黑盒问题
- 具体问题
- LangChain Agent 的 “思考 - 工具调用” 链路是黑盒,无法直接看到转换后的 MCP 请求格式是否正确;
- MCP Server 的工具执行结果返回后,LangChain Agent 的处理逻辑(如是否正确解析结果)难以监控。
- 应对思路
- 适配层日志增强:在
MCPLangChainTool中打印 MCP 请求 / 响应的完整内容; - 中间结果存储:将 MCP 调用的中间结果写入 LangGraph State,便于调试时查看;
- 模拟测试:开发 MCP Mock Server,模拟外部系统响应,验证 LangChain Agent 的工具调用逻辑是否正确。
六、核心问题 6:安全与管控的适配缺口
企业级场景中,LangChain 的轻量化管控能力与 MCP 的安全机制易脱节:
1. 鉴权逻辑的脱节
- 具体问题
- MCP Server 通常通过中间件实现 API Key 鉴权、IP 白名单,但 LangChain Agent 调用 MCP 工具时,易出现 “鉴权信息泄露”(如 API Key 硬编码在 Tool 配置中);
- LangChain 无统一的鉴权框架,无法基于角色控制 Agent 调用 MCP 工具的权限(如普通 Agent 只能调用查询类工具,管理员 Agent 可调用修改类工具)。
- 应对思路
- 鉴权信息托管:将 MCP API Key 存储在环境变量 / 密钥管理系统(如 Vault),而非硬编码;
- 适配层添加鉴权钩子:在
MCPLangChainTool中自动注入鉴权信息(如请求头中的X-MCP-API-Key); - 权限映射:将 LangChain Agent 的角色(如
user_role)传递到 MCP Context,MCP Server 基于角色鉴权。
2. 数据传输的安全风险
- 具体问题
- LangChain 与 MCP Client 之间的参数传输默认是明文,敏感数据(如用户 ID、财务数据)易泄露;
- MCP 的 HTTP 调用未启用 TLS 时,整个链路存在数据篡改风险。
- 应对思路
- 启用 TLS 加密:MCP Server 配置 HTTPS,MCP Client 使用
https协议调用; - 参数加密:对敏感参数(如用户手机号)在 LangChain 侧加密,MCP Server 侧解密;
- 数据脱敏:适配层对 MCP 请求中的敏感字段(如身份证号)自动脱敏,仅传输脱敏后的数据。

LangChain 与 Python MCP 集成的核心矛盾是 “LangChain 的灵活性” 与 “MCP 的标准化” 之间的平衡 —— 过度追求标准化会丧失 LangChain 的组件优势,过度依赖 LangChain 的灵活性则会偏离 MCP 的解耦目标。实践中需根据场景取舍:原型验证场景可容忍适配层的冗余,企业级生产场景需精简适配层、强化标准化与可维护性。
如何学习AI大模型 ?
“最先掌握AI的人,将会晚掌握AI的人有竞争优势,晚掌握AI的人比完全不会AI的人竞争优势更大”。 在这个技术日新月异的时代,不会新技能或者说落后就要挨打。
老蓝我作为一名在一线互联网企业(保密不方便透露)工作十余年,指导过不少同行后辈。帮助很多人得到了学习和成长。
我是非常希望可以把知识和技术分享给大家,但苦于传播途径有限,很多互联网行业的朋友无法获得正确的籽料得到学习的提升,所以也是整理了一份AI大模型籽料包括:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、落地项目实战等 免费分享出来。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集

大模型学习路线
想要学习一门新技术,你最先应该开始看的就是学习路线图,而下方这张超详细的学习路线图,按照这个路线进行学习,学完成为一名大模型算法工程师,拿个20k、15薪那是轻轻松松!

视频教程
首先是建议零基础的小伙伴通过视频教程来学习,其中这里给大家分享一份与上面成长路线&学习计划相对应的视频教程。文末有整合包的领取方式

技术书籍籽料
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,这里也分享一份我学习期间整理的大模型入门书籍籽料。文末有整合包的领取方式

大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。文末有整合包的领取方式

大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。文末有整合包的领取方式

大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。文末有整合包的领取方式

领取方式
这份完整版的 AI大模型学习籽料我已经上传CSDN,需要的同学可以微⭐扫描下方CSDN官方认证二维码免费领取!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)