RAG不死,只是进化!2026年上下文工程师必备指南,建议收藏学习
RAG技术未死,而是从狂热走向冷静,将演变为"上下文工程"。GraphRAG、AgenticRAG等新技术存在成本高、稳定性问题,长上下文与RAG互补而非替代。2026年RAG将成为AI应用基础设施,智能体RAG、垂直领域RAG等趋势兴起。实际应用中,朴素的RAG配合高质量数据和精细产品设计往往比复杂方案更有效,开发者应从简单开始,持续迭代。
RAG技术未死,而是从狂热走向冷静,将演变为"上下文工程"。GraphRAG、AgenticRAG等新技术存在成本高、稳定性问题,长上下文与RAG互补而非替代。2026年RAG将成为AI应用基础设施,智能体RAG、垂直领域RAG等趋势兴起。实际应用中,朴素的RAG配合高质量数据和精细产品设计往往比复杂方案更有效,开发者应从简单开始,持续迭代。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
2025年RAG已死?2026年做上下文工程?
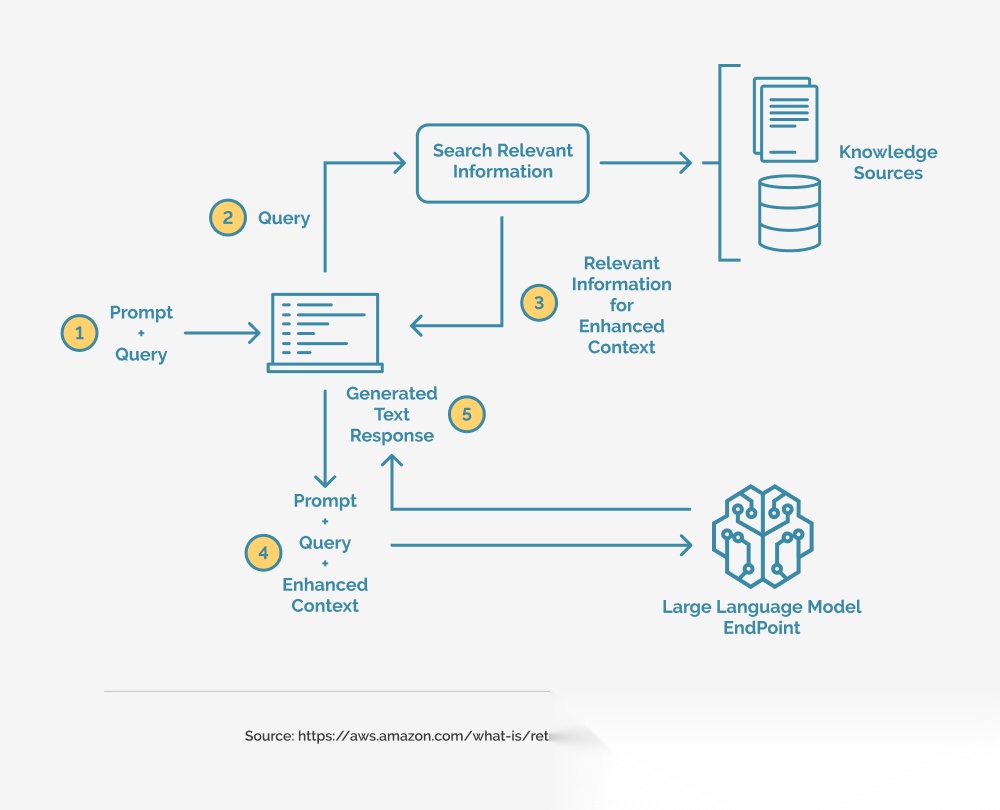
写在前面
2025年即将过去,作为一名深耕RAG技术的算法工程师,我想和大家聊聊这一年RAG技术的真实状态——不是那些震惊体标题下的"RAG已死",也不是各种PPT里的宏大叙事,而是我在实际落地中观察到的技术演进、踩过的坑,以及对2026年的真实判断。
这篇文章,既是对过去一年的复盘,也是给自己和同行的一些提醒:技术本身没有对错,关键在于是否用对了地方。
下期分享: 7 种必须了解的企业落地RAG 架构
一、2025年RAG:从狂热到冷静
1.1 数据会说话
先看一组数据:
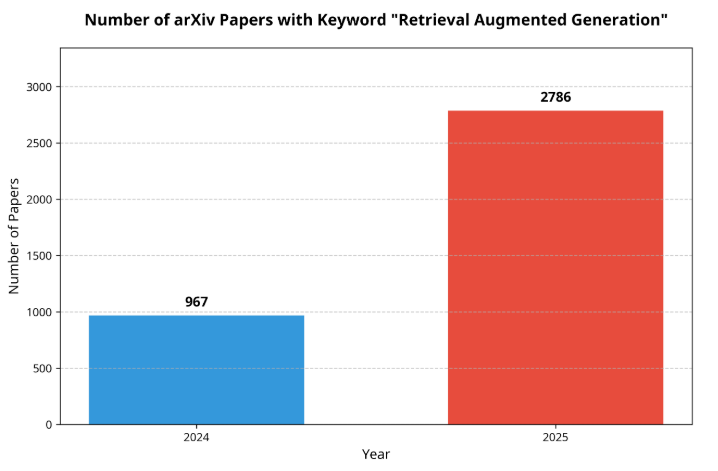
但论文数量的爆发,并不等于技术的成熟。事实上,2025年RAG领域呈现出一种成熟与分化并存的状态——基础设施趋于稳定,技术创新却开始放缓。
1.2 开源框架的大浪淘沙
年初的时候,GitHub上RAG相关的开源项目有35个之多,到年末,真正活跃的不超过10个,而被广泛使用的只有3-5个。

这种收敛形成了一个有趣的三层金字塔:
- 底层(面向开发者): LangChain、AutoGen、等底层框架,灵活但学习成本高
- 中层(面向工程师): RAGFlow、MaxKB等,平衡了易用性和可定制性
- 顶层(面向业务): Dify、Coze等低代码平台,上手快但容易遇到性能瓶颈
我的观察是:大部分团队选择了Dify/Coze,但80%的团队会在3个月内遇到性能瓶颈。为什么?因为RAG的优化高度依赖具体业务场景,而这些平台的抽象层限制了你深入优化的能力。
1.3 一个经典的问题:二开还是重写?
这是我今年被问得最多的问题。我的答案很简单:
如果你只是做demo或简单场景,用开源框架。如果你要做生产级系统,认真考虑从头开发核心模块。
原因有三:
- RAG本质上是模块化的 - 文档解析、分块、检索、重排、生成,每个模块都可以独立优化
- 业务差异巨大 - 金融文档、法律合同、技术手册,每种场景的最优方案完全不同
- LLM代码能力飞跃 - 2025年,Claude 4.5、GPT-5等模型已经能生成很高质量的RAG代码,从头开发的成本大幅降低
当然,这需要你对RAG的原理有深入理解。但如果你打算长期做这个方向,这个投入是值得的。
二、技术演进:从暴力堆叠到理性回归
2.1 技术发展的三个阶段
回顾RAG的发展,可以清晰地划分为三个阶段:
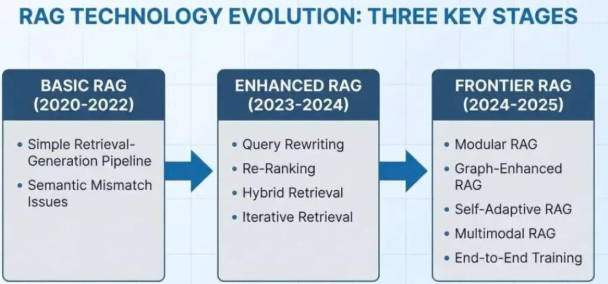
第一阶段(2020-2022):基础RAG时代
最简单的"检索+生成"流水线:向量检索Top-K文档,拼接后扔给LLM。问题很明显:检索和生成完全解耦,检索到的内容不一定是LLM真正需要的。
第二阶段(2023-2024):增强RAG时代
各种tricks层出不穷:Query改写、HyDE、混合检索、重排序、迭代检索…这个阶段产生了LangChain、LlamaIndex等框架,降低了开发门槛。
第三阶段(2024-2025):前沿探索期 出现了四大方向:
出现了四大方向:
- 模块化RAG - 乐高式组装各种组件
- GraphRAG - 引入图结构建立实体关系
- AgenticRAG - 让LLM自主决策检索策略
- 多模态RAG - 处理图像、视频等非文本数据
2.2 GraphRAG:高开低走的典型案例
今年最热的概念之一就是GraphRAG。微软发布后,各种论文、开源项目井喷。但用下来发现,ROI真的不高。
为什么GraphRAG没火起来?
- Token消耗巨大 - 实体抽取、关系建立、社区摘要,Token成本是普通RAG的5-10倍
- 图谱质量堪忧 - 自动抽取的实体关系充满噪声,远不如人工构建的知识图谱
- 维护成本高 - 文档一更新,图谱就要重建,这个成本在生产环境难以接受
我的判断:GraphRAG适合那些需要跨文档、多跳推理的复杂场景,但对于80%的常规问答,朴素RAG+好的文档解析就够了。
不过GraphRAG的思想是对的——预先建立关联,降低检索时的认知负担。只是当前的实现方式太粗暴了。
2.3 AgenticRAG:理想很丰满,现实很骨感
AgenticRAG的思路是:让LLM自己决策什么时候检索、检索什么、如何利用检索结果。听起来很美好,但有两个大问题:
- Token成本 - 每次决策都要调用LLM,成本是传统RAG的3-5倍
- 稳定性 - LLM的决策能力还不够可靠,经常做出错误判断
我的建议:对于复杂任务,Agentic思路是对的,但可以用简化版——预定义几种检索策略,用轻量级分类器选择,而不是每次都让LLM深度思考。
2.4 长上下文会取代RAG吗?
这是今年另一个热门争论。Claude 3支持200K上下文,GPT-4 Turbo支持128K,很多人说RAG要死了。
我的答案:长上下文和RAG不是替代关系,而是互补。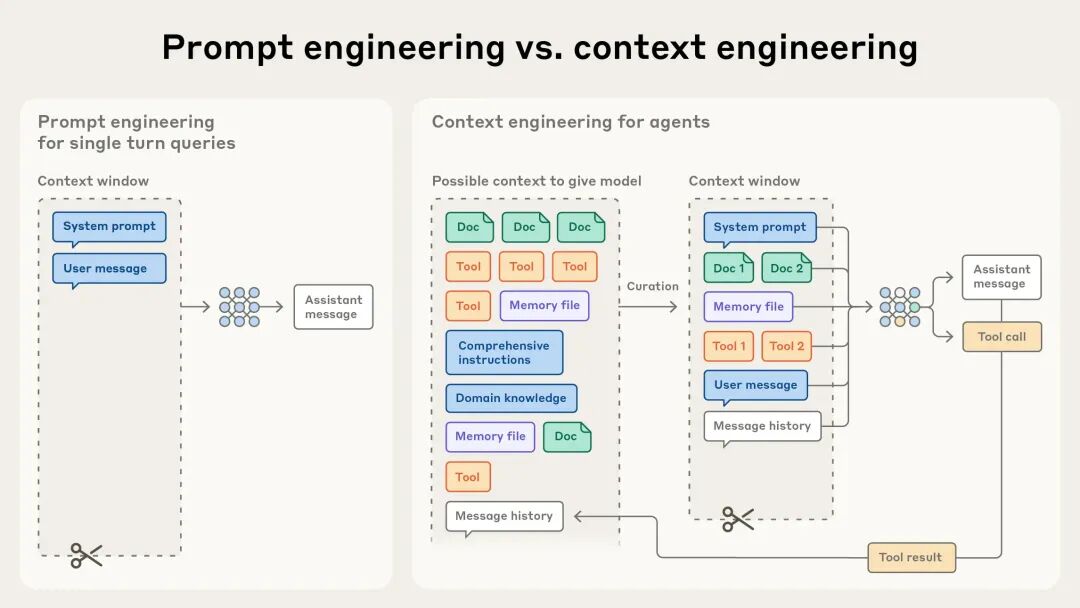
长上下文的问题:
- 成本 - 处理100K上下文的成本是RAG的20-100倍
- Lost in the Middle - 信息太多,模型注意力会分散,答案质量反而下降
- 实时性 - 每次都处理全量文档,延迟不可接受
最佳实践:
- 文档<1000页 + 深度理解场景 → 长上下文
- 文档>10000页 + 精准检索场景 → RAG
- 混合场景 → RAG初筛 + 长上下文精读
三、从RAG到Context Engine:定位的转变
3.1 2025年最重要的认知升级
如果说2025年RAG领域有什么最重要的认知升级,那就是:**RAG的本质不是"检索增强生成",而是"上下文工程"**。
这个认知的转变,源于AI Agent的兴起。
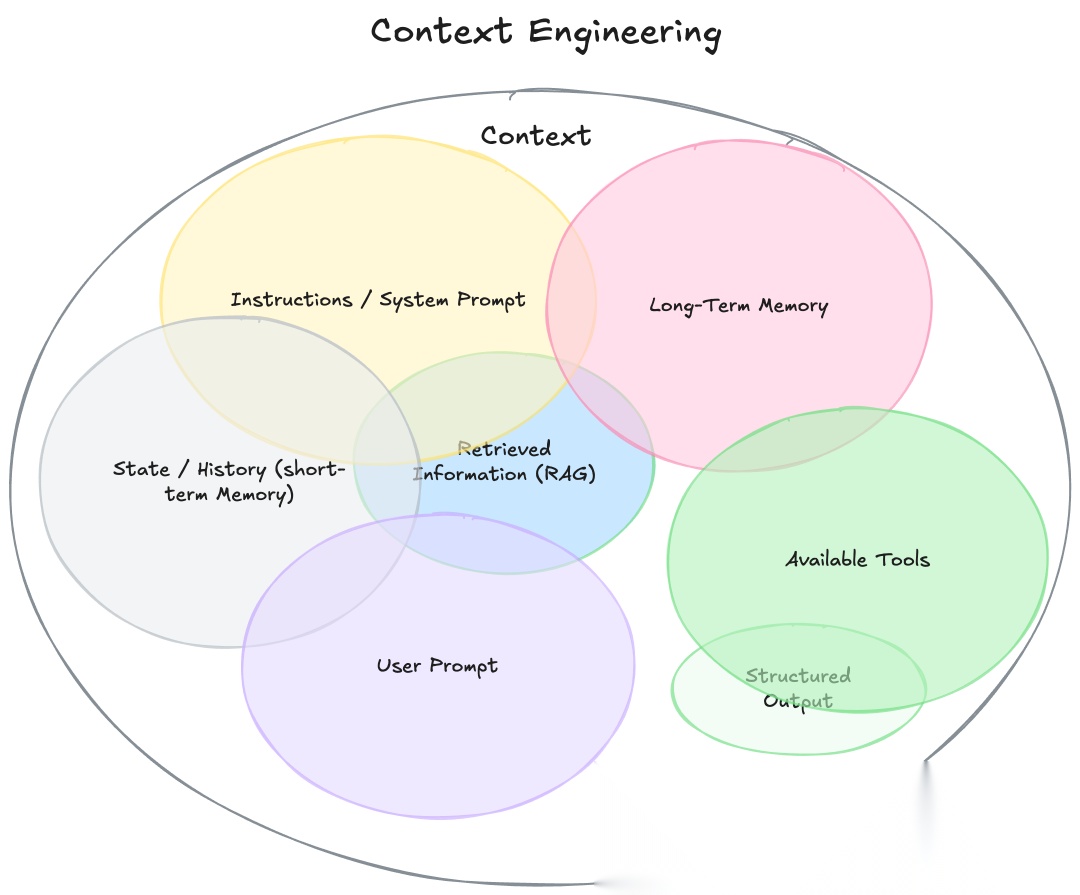
3.2 Agent需要的三类上下文
一个能干活的Agent,需要精心组装三类上下文:
1. 领域知识(Knowledge)
- 企业内部文档、产品手册、历史案例
- 这就是传统RAG的强项
2. 工具描述(Tools)
- API文档、函数说明、调用示例
- 当工具数量>100个,如何选择成为大问题
3. 交互历史(Memory)
- 对话历史、用户偏好、任务状态
- 本质也是一种检索问题
关键洞察:这三类数据的管理,本质上都是检索问题。RAG的技术栈(向量索引、混合检索、重排序)可以完美复用。
3.3 MCP只是开始,真正的挑战是检索
2024年底Anthropic推出MCP(Model Context Protocol),今年很多人在喊"MCP凉了"。其实是搞错了对象。
MCP解决的是"如何调用"的连通性问题,但没有解决"调用哪个"的决策问题。
当企业有500个API可以调用时,你不可能把500个工具的描述都塞进prompt。这时候你需要什么?工具检索(Tool Retrieval)[10]。
根据当前任务,动态检索最相关的3-5个工具,这才是实用的方案。
3.4 Memory就是特殊的RAG
今年Memory也火了一把,很多人把它和RAG对立起来。但本质上:Memory就是对会话历史的RAG。
上下文工程概念图
- 数据来源不同 - RAG处理静态文档,Memory处理动态对话
- 技术栈相同 - 都是存储、索引、检索
- 目标互补 - 一个提供领域知识,一个提供个性化上下文
所以不要纠结用RAG还是Memory,统一到"Context Engine"的框架下思考。
3.5 Context Platform:下一个基础设施
Theory Ventures的投资人早在2024年就提出了"Context Platform"的概念[13][14][15]。
核心思想:上下文的创建、管理、交付应该是一个平台化的能力,而不是每个应用各自实现。
这个判断我深度认同。2026年,谁能把Context做成平台级产品,谁就占据了AI应用的核心基础设施。
四、多模态RAG:雷声大,雨点小
4.1 为什么多模态RAG还没起来?
我在去年的总结中预测多模态RAG会在2025年爆发,但现实是:雷声大,雨点小。
理论上,多模态RAG很有价值:
- 医疗文献中的图表
- 设计文档中的示意图
- 视频中的关键帧
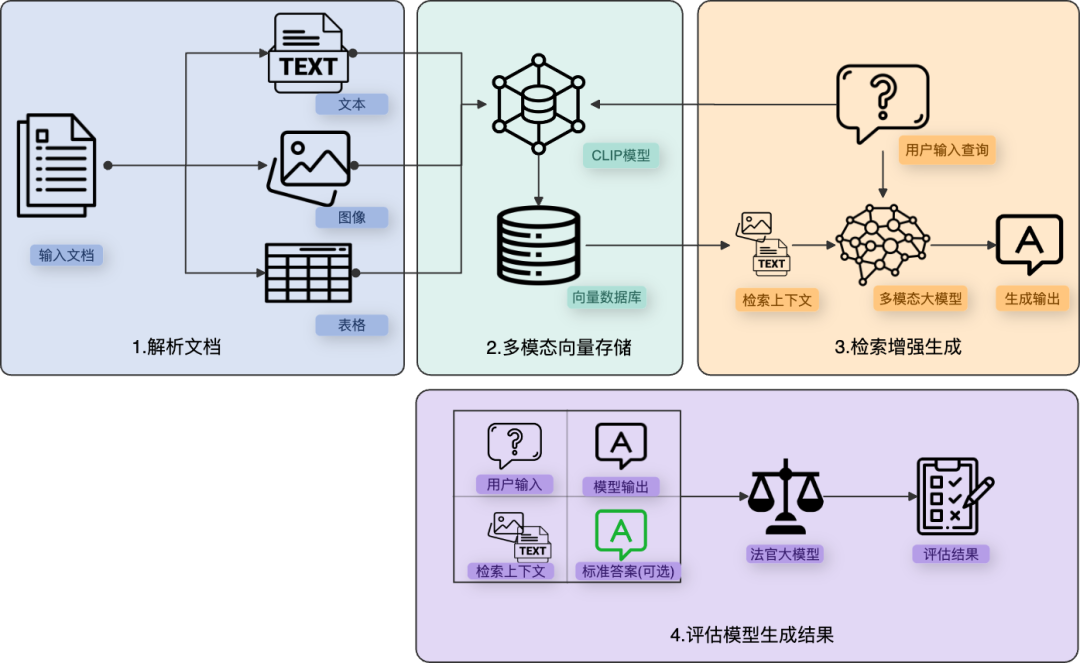
工程上,有两大拦路虎:
- Token爆炸 - 用ColPali处理一页PDF,生成1024个token,每个token 128维,一页就要500KB存储。百万页文档库需要TB级索引。
- 检索效果 - 纯文本向量检索已经很成熟,但图文混合检索的效果还不够稳定。
4.2 两条可行的路径
要突破这个瓶颈,有两条路:
路径1:量化压缩
- 把float32降到int4甚至二值化,存储压缩32倍
- 关键是要训练对量化鲁棒的embedding模型
路径2:Token剪枝
- 从1024个token降到128个
- 用attention机制自动选择最重要的token
4.3 我的判断
2026年多模态RAG会有突破,但真正大规模应用要到2027年。
原因:
- 基础设施(向量数据库、检索引擎)对张量的支持还在完善
- 专门为检索优化的多模态模型还在研发阶段
- 成本需要继续降低
但方向是对的,值得持续关注。
五、真实案例:企业怎么用RAG?
5.1 我看到的失败案例
今年也看到不少失败案例,典型的有三类:
类型1:过度追求新技术
- 上来就要GraphRAG,结果成本控制不住
- 建议:先把朴素RAG做到80分,再考虑升级
类型2:数据质量差
- 文档解析错误连篇,检索再准也没用
- 建议:投入50%精力在数据清洗和解析上
类型3:缺少产品设计
- 把RAG当黑盒,没有做用户反馈闭环
- 建议:像做产品一样做RAG,持续迭代
六、当前的五大挑战
6.1 成本:大多数团队的第一痛点
现状:
- 向量数据库存储成本高
- LLM调用成本高(特别是多轮对话)
- 多模态更是成本杀手
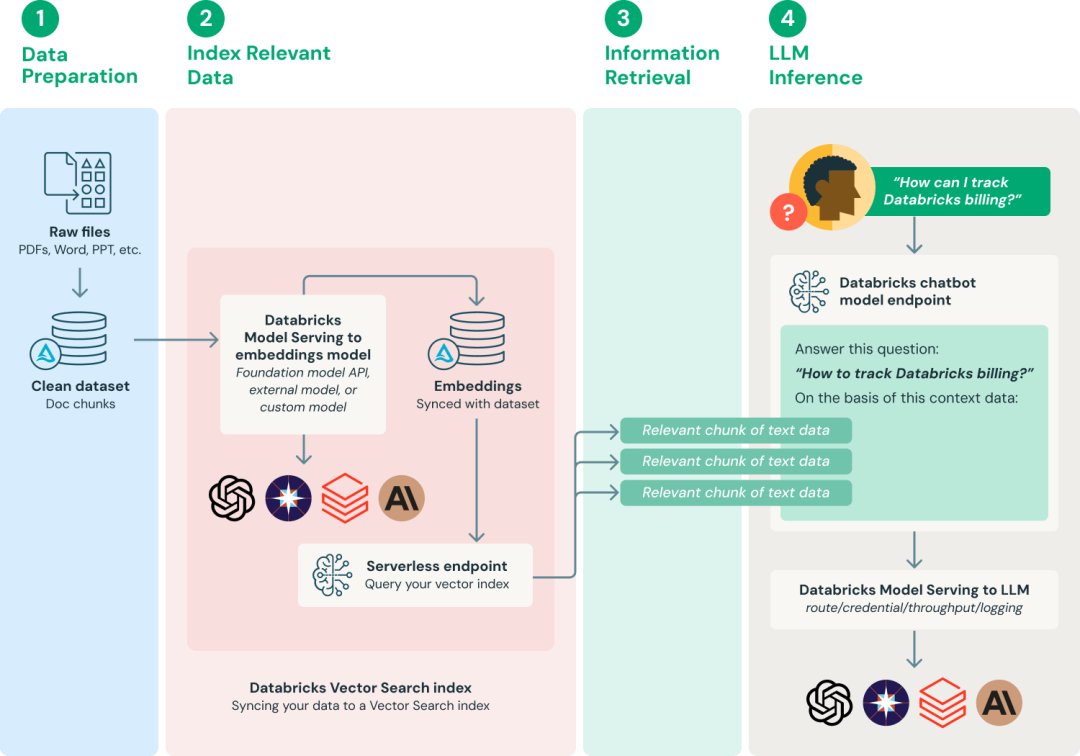
可行的优化:
- 增量索引,不要每次全量重建
- 冷热数据分层存储
- 小模型做初筛,大模型做精排
- 缓存高频query的结果
6.2 实时性:金融/安防场景的硬需求
问题:
- 检索+生成通常需要2-5秒
- 某些场景需要毫秒级响应
解决方案:
- 预检索缓存
- 流式生成(先给部分答案)
- GPU加速向量检索
- HNSW等近似检索算法
6.3 语义鸿沟:多模态的老大难
问题:
- 用户问"悲伤的场景",系统怎么从视频里找?
- 文本和图像的语义对齐很难
解决方案:
- 用VLM(如GPT-4V)做细粒度理解
- 离线时给视觉内容打丰富的标签
- 收集反馈,持续优化匹配模型
6.4 幻觉:信任度的致命伤
问题:
- 即使检索到正确文档,LLM也可能胡说八道
- 用户一旦发现错误,信任度归零
解决方案:
- 强制引用来源(带文档位置和页码)
- 用小模型验证答案和文档的一致性
- 训练时用检索文档做监督信号
6.5 隐私:企业的红线
问题:
- 敏感数据不能上云
- 需要细粒度权限控制
解决方案:
- 本地化部署
- 数据脱敏+全程加密
- 完整的审计日志
七、2026年:我看到的六大趋势
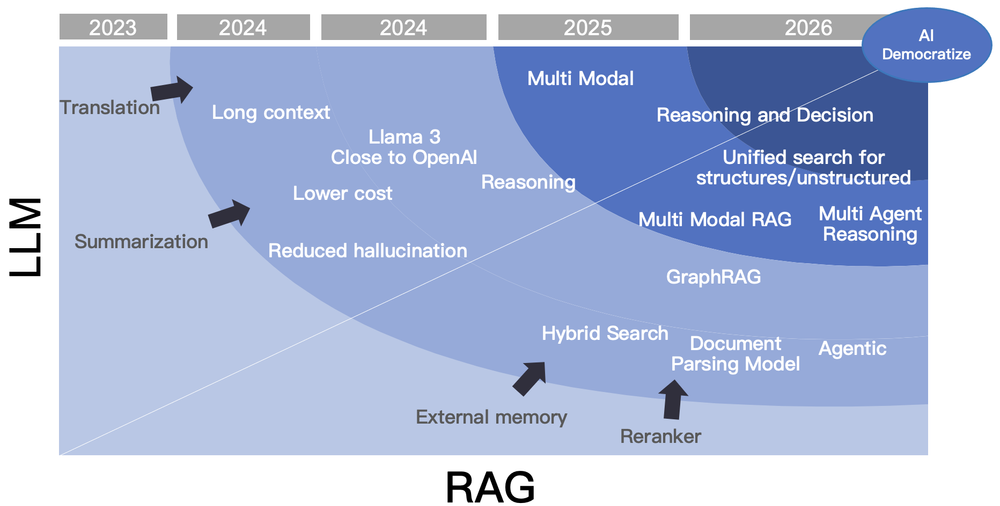
7.1 智能体RAG成为标配
判断依据:
- LangChain已经all in Agentic
- 复杂任务确实需要多步规划
但要注意:
- 不是所有场景都需要Agentic
- 简单场景用规则+轻量级LLM就够了
7.2 长上下文和RAG深度融合
不是替代,而是协同:
- RAG做粗筛(从10万文档筛到10篇)
- 长上下文做精读(深度理解这10篇)
7.3 垂直领域RAG涌现
通用RAG的问题:
- 无法处理领域特有的逻辑
- 评估指标不适配具体场景
垂直化的价值:
- 医疗RAG:集成医学知识图谱,理解诊断逻辑
- 法律RAG:内置法条检索和案例分析
- 金融RAG:实时接入市场数据
**我的建议:**如果你的领域文档有明显特征(如法律条文的层级结构),不要用通用方案,定制开发ROI更高。
7.4 端到端训练进入工程实践
现状:
- 检索器和生成器分别训练,可能目标不一致
RAG 2.0的思路:
- 联合训练,直接优化最终答案质量
- 检索器学习"生成器喜欢什么样的文档"
2026年的突破点:
- 更多开源的端到端训练框架
- 小数据量下也能有效训练的方法
7.5 Context Platform成为基础设施
我最看好的方向:
- 不是某个RAG框架,而是统一的上下文管理平台
- 就像数据仓库之于BI,Context Platform之于AI应用
谁有机会:
- RAGFlow这类深耕底层引擎的
- 云厂商(如AWS、阿里云)推的托管服务
- 新兴的专注Context的创业公司
7.6 标准化和互操作性提升
当前的痛点:
- 向量数据库格式不兼容
- Embedding模型互相替换困难
- 评估指标各说各话
2026年的进展:
- OpenAI、Anthropic等大厂会推动标准
- 更多benchmark的出现
- 框架间的互操作性增强
八、给开发者的七条建议
建议1:拥抱模块化
不要把RAG当黑盒,理解每个模块的作用:
- Parser(文档解析)
- Chunker(分块策略)
- Retriever(检索器)
- Reranker(重排序)
- Generator(生成器)
这样你才能针对性优化。
建议2:从简单开始
反对一上来就上GraphRAG/AgenticRAG的冲动。
正确的路径:
- 基础RAG(Faiss + Llama 3.1)
- 加入重排序(BGE Reranker)
- 优化chunking策略
- 根据场景决定是否升级
建议3:重视数据质量
好的RAG = 30%技术 + 70%数据
时间分配建议:
- 50%: 文档清洗和解析
- 30%: 评估和调优
- 20%: 技术选型和开发
建议4:建立评估体系
不只是demo能跑就行,要有系统的评估:
检索层面:
- Precision@K / Recall@K
- MRR(Mean Reciprocal Rank)
生成层面:
- 答案准确性(人工评估)
- 引用质量(是否引用了正确文档)
- 幻觉率
业务层面:
- 响应时间
- 用户满意度
- 人工介入率
建议5:做好监控和迭代
RAG不是一次性工程,是持续迭代的系统。
必须的监控:
- 每个query的检索结果
- 生成答案的质量评分
- 用户反馈(点赞/点踩)
- 异常case(答非所问、拒答、幻觉)
每周review一次bad case,找规律,针对性优化。
建议6:不要忽视产品设计
技术只是手段,用户体验才是目的。
产品层面要考虑:
- 什么情况下触发检索?
- 如何展示来源文档?
- 答案不确定时如何处理?
- 如何收集用户反馈?
我看到的最好的RAG产品,都在这些细节上下了功夫。
建议7:安全和合规前置
不要等上线了再考虑安全问题。
设计阶段就要明确:
- 哪些数据可以索引?
- 如何做权限控制?
- 如何审计访问记录?
- 如何应对数据泄露?
对于金融、医疗等强监管行业,这些是必答题。
九、我的核心观点:回归本质

9.1 技术无罪,用错了才是问题
我经常听到"RAG已死"、"GraphRAG不work"这样的声音。但问题不在技术本身,在于:
- 用错了场景 - 简单问答非要用GraphRAG
- 数据质量差 - 垃圾进垃圾出
- 过度追求新技术 - 基础没打好就想上天
技术只是工具,关键是理解你的业务需求,选择合适的工具。
9.2 不要面向RAG做业务
这是我想强调的最重要的一点:
不要面向RAG做业务,而是面向业务做RAG。
什么意思?
- ❌ 错误:我们有RAG技术,能做什么业务?
- ✅ 正确:我们要解决XX问题,RAG是不是最优解?
很多失败的案例,就是为了用RAG而用RAG。结果发现:
- 简单的FAQ,规则系统就够了
- 复杂的分析任务,RAG解决不了核心问题
9.3 论文和落地是两回事
今年看了大量RAG论文,很多都很fancy。但:论文的意义是探索边界,不是给你直接落地的。
论文的价值:
- 告诉你某个方向是否可行
- 提供一种解决问题的思路
- 帮助你理解技术的上限
但论文通常:
- 只在特定数据集上有效
- 忽略了工程成本
- 没有考虑实际约束
所以看论文要学思路,不要照搬代码。
9.4 简单往往更有效
这是我今年最深的感悟:
在80%的场景下,朴素RAG + 好的数据 + 精细的产品设计,比复杂的技术方案更有效。
为什么?
- 简单系统更稳定 - 环节少,出错的地方就少
- 简单系统更好调试 - 出了问题容易定位
- 简单系统成本更低 - 开发快,维护容易
GraphRAG、AgenticRAG这些,只在你确实遇到瓶颈时才考虑。
十、2026:干中学,在业务中成长
10.1 大势已定:RAG是基础设施
虽然争议不断,但我的判断很明确:
RAG不会死,而是会从"应用"变成"基础设施"。
就像数据库之于应用开发,RAG(或者说Context Engine)会成为所有AI应用的标配。
理由:
- 长上下文不是银弹 - 成本和效果都有天花板
- 私有数据必须管理 - 企业不可能把所有数据都扔给LLM
- 动态性是刚需 - 文档会更新,知识会变化
10.2 机会在垂直领域
通用RAG框架的时代接近尾声,垂直领域RAG的机会才刚开始。
为什么?
- 通用方案的问题 - 无法处理领域特性
- 垂直方案的价值 - 内置领域知识,开箱即用
- 商业模式更清晰 - 可以收更高的价格
如果你在某个领域有深厚积累,做垂直RAG是很好的切入点。
10.3 长期主义:持续迭代才是王道
RAG不是一锤子买卖,而是需要长期运营的系统。
成功的RAG团队都在做什么?
- 持续优化数据 - 新文档的接入,旧文档的更新
- 监控和迭代 - 每周review bad case,针对性优化
- 收集反馈 - 让用户参与,形成闭环
- 技术升级 - 新技术出来就试试,有收益就上
这是一个马拉松,不是百米冲刺。
写在最后:给2026的自己
回看这一年,RAG经历了从狂热到冷静,技术本身在成熟,但大家的心态也在变化。
明年这个时候再回看,我相信:
- 基础框架会更加稳定 - 淘汰期已过,剩下的都是精品
- 垂直应用会涌现 - 通用方案做到极致后,差异化在细分领域
- Context Engine会成为共识 - 不再只谈RAG,而是整个上下文管理
- 工程化会被重视 - 不只是炫技,而是真正能稳定运行的系统
对于我自己:继续深耕业务,在实际场景中打磨技术。不追热点,做长期有价值的事情。
与君共勉。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)