LangChain 1.x 全景解析:从 LCEL 到 LangGraph 的工程化 Agent 实战
本文系统解析 LangChain 1.x 生态,将其视为 AI 操作系统,深入讲解 LCEL 链式编排、LangGraph 状态机与人工中断机制,完整展示生产级 Agent 的工程化落地路径。
一、 重新定义 LangChain:它不再是一个库,而是一套 AI 操作系统
很多教程会告诉你:“LangChain 是一个开发 LLM 应用的框架”。这句话太抽象了。
通俗点说,如果 DeepSeek 或 GPT-4 是一个强大的 CPU,那么 LangChain 就是那个操作系统(OS)。它不生产智力,但它负责:
- 连接硬件:对接各种模型(OpenAI, Ollama, SiliconFlow)。
- 驱动外设:让模型能上网搜谷歌、读 SQL 数据库。
- 管理内存:记住你 10 分钟前说的话。
- 流程编排:规定模型先做什么,后做什么。
二、 揭秘 LangChain 1.x 生态架构
在 1.x 时代,LangChain 已经完成了从“大杂烩”到“模块化”的华丽转型。根据官方最新的全栈视图,我们可以将其拆解为以下结构:
1.x 的里程碑式变化(相比 0.x 旧版本):
- LCEL (LangChain Expression Language):引入了像 Linux 管道符一样的
|语法,让代码从“面条式”变成“声明式”。 - 从 Chain 到 Graph:废弃了笨重的
AgentExecutor,全面转向 LangGraph。这让 AI 不再只会“一条路走到黑”,而是学会了“循环、回溯、反思”。 - 生产力优先:以前 LangChain 被吐槽只能写 Demo,现在有了 LangSmith,你终于可以像监控微服务一样监控 AI 的每一张 Token 消耗。
三、 快速安装:搭建你的 AI 实验室
我们推荐使用 Python 3.9+ 环境。建议直接安装核心库以及常用集成:
# 安装基础框架
pip install -U langchain langchain-openai
# 安装 LangGraph (1.x 时代的 Agent 必选)
pip install -U langgraph
# 安装常用工具集成 (比如 Tavily 搜索)
pip install tavily-python
四、 进阶之路:从 Hello World 到 链式调用 (LCEL)
第一步:最简单的调用 (The “Hello World”)
这是最基础的语法,用于测试模型连通性。
from langchain_openai import ChatOpenAI
### 1. 初始化模型 (以 SiliconFlow 为例)
llm = ChatOpenAI(
api_key="sk-xxx",
base_url="https://api.siliconflow.cn/v1",
model="deepseek-ai/DeepSeek-V3"
)
### 2. 直接对话
response = llm.invoke("你好,你是谁?")
print(response.content)
第二步:掌握 LCEL (表达式语言) —— LangChain 的灵魂
在 1.x 中,我们不鼓励散乱地调用模型,而是通过管道符 | 把 Prompt + Model + OutputParser 串成一条线。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
### 1. 定义提示词模版
prompt = ChatPromptTemplate.from_template("请给我讲一个关于 {topic} 的冷笑话")
### 2. 使用管道符组合 (LCEL 语法)
# 逻辑流:输入变量 -> 填充模版 -> 发给模型 -> 解析成纯文本
chain = prompt | llm | StrOutputParser()
### 3. 运行
print(chain.invoke({"topic": "程序员"}))
为什么要学这个? 因为 LCEL 自动支持了:异步调用、流式输出、中间步骤监控。这是你从初级开发迈向高级开发的必经之路。
五、终极奥义:从 Chain 进化到 Graph (Agent 实战)
当你的业务逻辑包含:“如果 A 报错了就执行 B,如果 B 没搜到就回过头再试一次 A”这种循环逻辑时,传统的 Chain 就力不从心了。
这就是 LangGraph 登场的时候。
核心思维转变:
- Chain:像一条传送带,东西只能往前走。
- Graph:像一个十字路口,有红绿灯(条件判断),有环岛(循环),甚至可以有交警(人工审批)。
我们在之前的章节中展示过“调研助理”的代码,其背后的逻辑就是:
- 定义 State:给 Agent 一个记事本。
- 定义 Node:把“搜索”、“写作”写成函数。
- 定义 Edge:连线。
- 编译 Checkpoint:让 Agent 具备随时暂停、随时复活的能力。
六、 实战演示:构建一个“全能调研助理”
6.1 环境准备与模型配置
我们将使用 DeepSeek-V3 作为核心大脑。得益于 LangChain 的标准化接口,我们只需修改 ChatOpenAI 的 base_url 即可无缝切换模型。
import os
from typing import Annotated, TypedDict, List
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, HumanMessage, SystemMessage
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# 配置 DeepSeek-V3 (通过 SiliconFlow 接入)
llm = ChatOpenAI(
api_key="sk-xxx", # <--- 替换为你的真实 Key
base_url="https://api.siliconflow.cn/v1",
model="deepseek-ai/DeepSeek-V3",
temperature=0
)
6.2 核心逻辑实现
这个示例演示了如何构建一个具有“自动化调研 -> 生成草稿 -> 人工审批 -> 正式发布”流程的智能体。
# 1. 定义状态结构:这是 Agent 在各节点间传递的“记忆盒”
class AgentState(TypedDict):
topic: str
content: str
report: str
approved: bool
# 2. 定义节点 (Nodes)
def researcher(state: AgentState):
"""调研节点:模拟信息搜集"""
# 在实际场景中,这里可以接入 Tavily 或搜索工具
topic = state['topic']
search_prompt = [
SystemMessage(content="你是一个资深情报分析师。"),
HumanMessage(content=f"请为我搜集关于 '{topic}' 的核心观点和最新事实。")
]
response = llm.invoke(search_prompt)
return {"content": response.content}
def writer(state: AgentState):
"""撰写节点:根据搜集的信息生成报告草案"""
prompt = [
SystemMessage(content="你是一个专业的报告撰写专家。"),
HumanMessage(content=f"基于以下素材撰写一份深度调研报告:\n\n{state['content']}")
]
response = llm.invoke(prompt)
return {"report": response.content}
def human_approval(state: AgentState):
"""人工审批节点:占位符,执行逻辑将由 interrupt 挂起"""
return state
def publisher(state: AgentState):
"""发布节点:将报告持久化"""
with open("final_report.txt", "w", encoding="utf-8") as f:
f.write(state["report"])
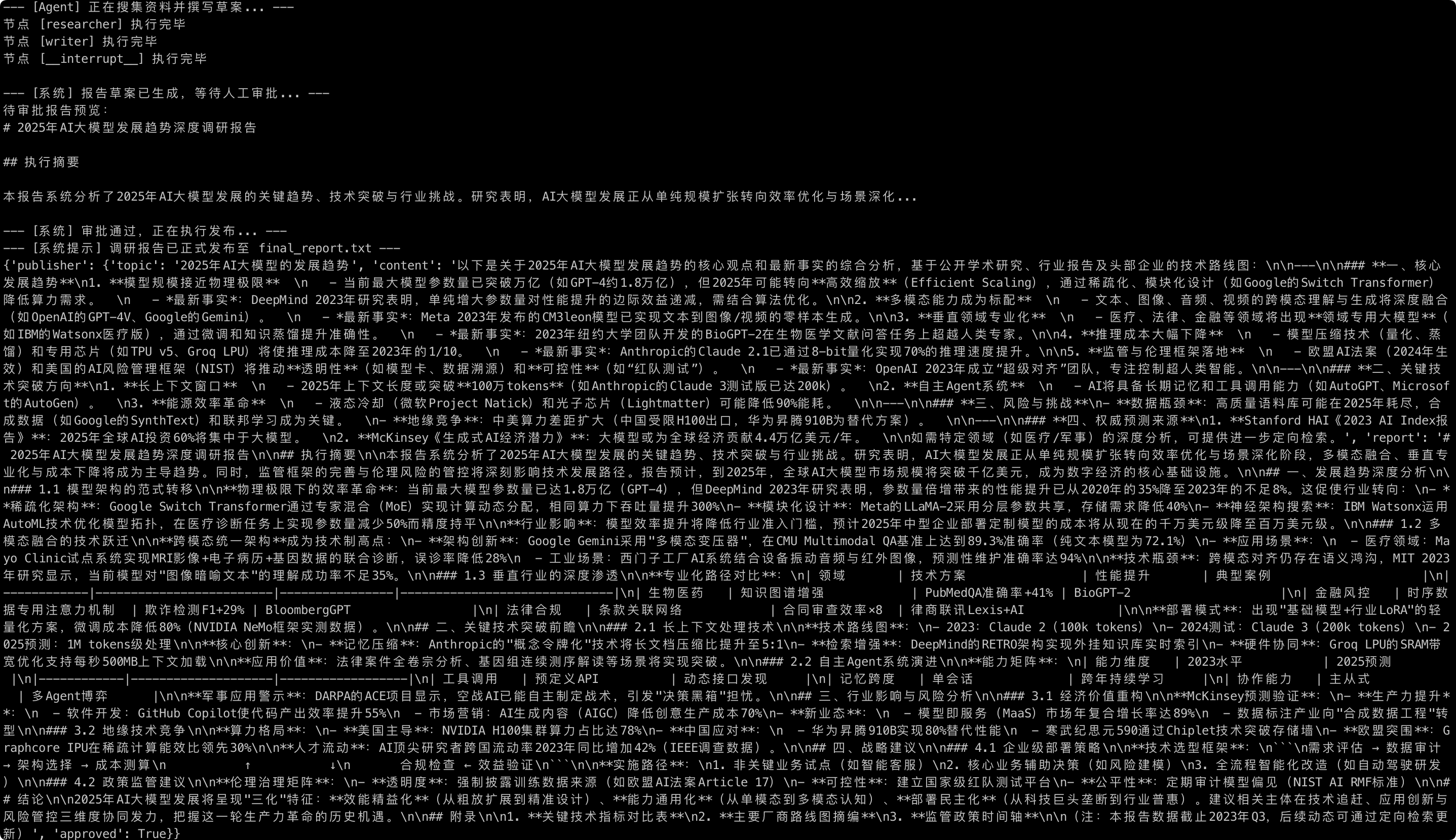
print("--- [系统提示] 调研报告已正式发布至 final_report.txt ---")
return state
# 3. 编排工作流 (Graph)
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("researcher", researcher)
workflow.add_node("writer", writer)
workflow.add_node("human_approval", human_approval)
workflow.add_node("publisher", publisher)
# 设定执行连线
workflow.add_edge(START, "researcher")
workflow.add_edge("researcher", "writer")
workflow.add_edge("writer", "human_approval")
# 定义审批分支逻辑
def should_publish(state: AgentState):
# 根据 state 中的 approved 字段决定去向
if state.get("approved"):
return "publisher"
return END
workflow.add_conditional_edges("human_approval", should_publish)
workflow.add_edge("publisher", END)
# 4. 编译图并开启“人工干预”功能
# 使用 MemorySaver 来在内存中保存执行状态(以便在中断后恢复)
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer, interrupt_before=["human_approval"])
# 5. 执行流程
config = {"configurable": {"thread_id": "research_001"}} # 线程 ID 用于标记单次任务
# 第一阶段:运行到审批节点前停止
print("--- [Agent] 正在搜集资料并撰写草案... ---")
initial_input = {"topic": "2025年AI大模型的发展趋势", "approved": False}
for event in app.stream(initial_input, config):
for node_name, state_update in event.items():
print(f"节点 [{node_name}] 执行完毕")
# 此时程序自动挂起
print("\n--- [系统] 报告草案已生成,等待人工审批... ---")
state = app.get_state(config)
print(f"待审批报告预览:\n{state.values['report'][:100]}...")
# 第二阶段:模拟人工操作,修改状态并继续
# 用户检查后发送“审批通过”指令
app.update_state(config, {"approved": True}, as_node="human_approval")
print("\n--- [系统] 审批通过,正在执行发布... ---")
for event in app.stream(None, config): # 传入 None 表示从断点继续
print(event)
6.3 关键点解析:为什么这是 Agent 的工程化解法?
-
DeepSeek-V3 的角色:
在researcher和writer节点中,我们使用了SystemMessage和HumanMessage的组合,充分利用了 DeepSeek 的长文本理解和指令遵循能力。它的低延迟让 Agent 的多轮循环变得非常丝滑。 -
interrupt_before(断点保护):
在编译app时,我们指定在human_approval节点之前中断。这在真实业务中非常重要——涉及资产操作、公开发布、或重要决策时,Agent 不能“蒙头狂奔”,必须等待人类的反馈。 -
update_state(状态注入):
我们不需要重启程序,而是通过update_state在research_001这个线程的生命周期里注入了{"approved": True}。Agent 就像被拍了一下肩膀,立刻明白可以进入publisher流程了。 -
MemorySaver(持久化):
通过thread_id,Agent 具备了“随时随地复活”的能力。即使你的服务器在审批期间重启了,只要数据库中有这个检查点,Agent 就能接上之前的记忆继续干活。
七、深度解密:如何理解 Graph 的编排逻辑?
很多初学者会问:为什么不能直接写几个 if...else 或者函数调用,非要弄一个 StateGraph?理解了下面这三个核心概念,你就掌握了 LangChain 1.x 的工程精髓。
7.1 StateGraph(AgentState):定义“共享白板”
workflow = StateGraph(AgentState)
- 知其然: 这行代码初始化了一个图。
- 知其所以然: 在传统的程序中,数据是在函数间通过参数传递的(像接力棒)。但在复杂的 Agent 任务中,数据(如搜索结果、用户反馈、Token 消耗)太多,传递起来非常混乱。
- 底层机理:
AgentState就像是一个“共享白板”。无论流程走到哪个节点,所有的“工人们”(节点函数)都可以看到白板上的内容,并把自己的工作成果写在上面。StateGraph的作用就是维护这个白板的实时更新。
7.2 add_node:招募“专职工人”
workflow.add_node("researcher", researcher)
- 知其然: 将你写的 Python 函数注册到图中,并给它起个名字。
- 知其所以然: 节点(Node)是 Agent 的最小执行单元。
- 底层机理: 每一个节点本质上都是一个“输入 State -> 输出 State”的映射函数。LangGraph 会自动把当前的“白板内容”传给函数,并把你函数返回的结果合并(Update)到白板上。通过这种解耦,你可以独立调试每一个节点,比如单独测试
writer节点的文案写得好不好。
7.3 add_edge:铺设“传送带”
workflow.add_edge(START, "researcher")
workflow.add_edge("researcher", "writer")
- 知其然: 规定了任务从哪里开始,接下来该传给谁。
- 知其所以然: 边(Edge)定义了逻辑控制流。
- 底层机理:
START:这是一个特殊的入口标识,告诉程序:当用户输入第一个请求时,第一个去敲哪扇门。- 普通边 (Edge):是确定性的传送带。
researcher活干完了,百分之百要把结果传给writer。 - 条件边 (Conditional Edge):这是 Agent “智能”的体现。它就像流水线上的分拣器,根据白板上的状态(比如
approved是 True 还是 False),动态决定下一步是去“发布”还是“结束”。
7.4 为什么这种思维更高级?
传统的线性代码(Chain)一旦运行起来,你很难在中间停下来。而 Graph 架构 允许你:
- 实现循环:让 Agent 发现结果不对时,自动跳回上一步重新搜索(这是 Chain 做不到的)。
- 断点续传:就像我们在代码里看到的,程序可以在
human_approval节点停住,把状态存进数据库。过了两三天,你审批通过后,它能从数据库里读取状态,精准地从断点处“复活”。
总结: 写 LangGraph 就像在画流程图。你不是在写程序如何“运行”,而是在定义程序运行的“规则”。
八、深度实验:如何真正“体验”人工中断与审批?
在 LangGraph 中,真正让程序“停下来”的魔力来自于在 compile 时设置的参数。
8.1 魔法参数:interrupt_before
# 这里的 interrupt_before 是关键
app = workflow.compile(checkpointer=memory, interrupt_before=["human_approval"])
当你运行这段代码时,会发生以下极其重要的物理过程:
- 自动暂停:当流程即将进入
human_approval之前,LangGraph 会发现这个节点在“中断名单”里。 - 强制快照:它会立刻把当前所有的
AgentState(搜索到的资料、写的草稿)序列化,存入你提供的MemorySaver(内存或数据库)中。 - 退出执行:当前的 Python 执行流会直接结束(
stream或invoke函数返回)。
此时,Agent 就像是被“按了暂停键”的电影,在等待你按下继续。
8.2 如何手动“调戏”中断中的 Agent?
你可以通过以下代码,在程序停下来时,像“上帝”一样检查并修改它的记忆。
# --- 实验:查看 Agent 被暂停时的状态 ---
# 假设第一阶段已经运行完毕并停在了 human_approval
current_state = app.get_state(config)
print("--- [上帝视角] 检查 Agent 目前的进度 ---")
print(f"当前下一步要执行的节点: {current_state.next}")
# 预期输出: ('human_approval',)
print(f"草稿内容预览: {current_state.values['report'][:50]}...")
8.3 update_state 的精髓:注入“人类意志”
当你执行下面这行代码时,你并不是在调用 human_approval 函数,而是在改写 Agent 的大脑:
app.update_state(
config,
{"approved": True}, # 注入的变量:我同意了!
as_node="human_approval" # 伪装身份:假装是这个节点产生的决策
)
- 为什么要
as_node?
这在审计中非常重要。它告诉 Graph:这个approved: True的状态不是天上掉下来的,也不是researcher节点产生的,而是由human_approval这个环节产生的。 - 如果不满意怎么办?
你甚至可以修改它的报告!例如:app.update_state(config, {"report": "重写:这篇文章太烂了"}, as_node="human_approval")
这样,当 Agent “复活”后,它拿到的就是你修改后的版本。
8.4 复活:app.stream(None, config)
这是最神奇的地方。
# 传入 None,表示:不要开启新任务,从上一个断点继续跑
for event in app.stream(None, config):
print(event)
因为你在 update_state 里已经把 approved 改成了 True,所以当程序从断点恢复运行并进入 human_approval 节点后,它会顺着我们定义的 “条件边” (Conditional Edge) 往下走:
def should_publish(state: AgentState):
if state.get("approved"): # 这里现在是 True 了!
return "publisher" # 走向发布
return END
8.5 完整实验代码:亲手感受“人在回路” (Human-in-the-loop)
你可以直接将以下代码保存为 agent_hitl_demo.py 并运行。请确保你已经安装了 langchain-openai 和 langgraph。
import os
from typing import TypedDict, List
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# =================================================================
# 1. 环境配置
# =================================================================
llm = ChatOpenAI(
api_key="sk-xxx", # <--- 请在此处替换为您真实的 SiliconFlow API Key
base_url="https://api.siliconflow.cn/v1",
model="deepseek-ai/DeepSeek-V3",
temperature=0.7
)
# =================================================================
# 2. 定义状态与节点
# =================================================================
class AgentState(TypedDict):
topic: str
report: str
approved: bool
def researcher(state: AgentState):
print("\n[节点执行] researcher: 正在搜集资料...")
prompt = [
SystemMessage(content="你是一个情报分析专家。"),
HumanMessage(content=f"请简要列出关于 {state['topic']} 的三个核心事实。")
]
response = llm.invoke(prompt)
return {"report": f"【资料搜集完毕】\n{response.content}"}
def writer(state: AgentState):
print("\n[节点执行] writer: 正在撰写报告草案...")
prompt = [
SystemMessage(content="你是一个专业的科技作家。"),
HumanMessage(content=f"请根据以下素材写一段结语:\n{state['report']}")
]
response = llm.invoke(prompt)
# 将原始资料和结语合并
full_report = f"{state['report']}\n\n【专家结语】\n{response.content}"
return {"report": full_report}
def human_approval(state: AgentState):
# 这个节点本身不执行复杂逻辑,它是我们设置“红绿灯”的地方
print("\n[节点执行] human_approval: 进入审批流程节点...")
return state
def publisher(state: AgentState):
print("\n[节点执行] publisher: 正在发布最终成果...")
with open("agent_demo_report.txt", "w", encoding="utf-8") as f:
f.write(state["report"])
return state
# =================================================================
# 3. 编排工作流 (Graph)
# =================================================================
workflow = StateGraph(AgentState)
workflow.add_node("researcher", researcher)
workflow.add_node("writer", writer)
workflow.add_node("human_approval", human_approval)
workflow.add_node("publisher", publisher)
workflow.add_edge(START, "researcher")
workflow.add_edge("researcher", "writer")
workflow.add_edge("writer", "human_approval")
# 条件边逻辑
def should_publish(state: AgentState):
if state.get("approved"):
print("--- [逻辑分支] 审批通过,前往发布节点 ---")
return "publisher"
print("--- [逻辑分支] 审批未通过,结束任务 ---")
return END
workflow.add_conditional_edges("human_approval", should_publish)
workflow.add_edge("publisher", END)
# 编译图:重点在于 interrupt_before
memory = MemorySaver()
app = workflow.compile(checkpointer=memory, interrupt_before=["human_approval"])
# =================================================================
# 4. 运行实验
# =================================================================
config = {"configurable": {"thread_id": "test_user_001"}}
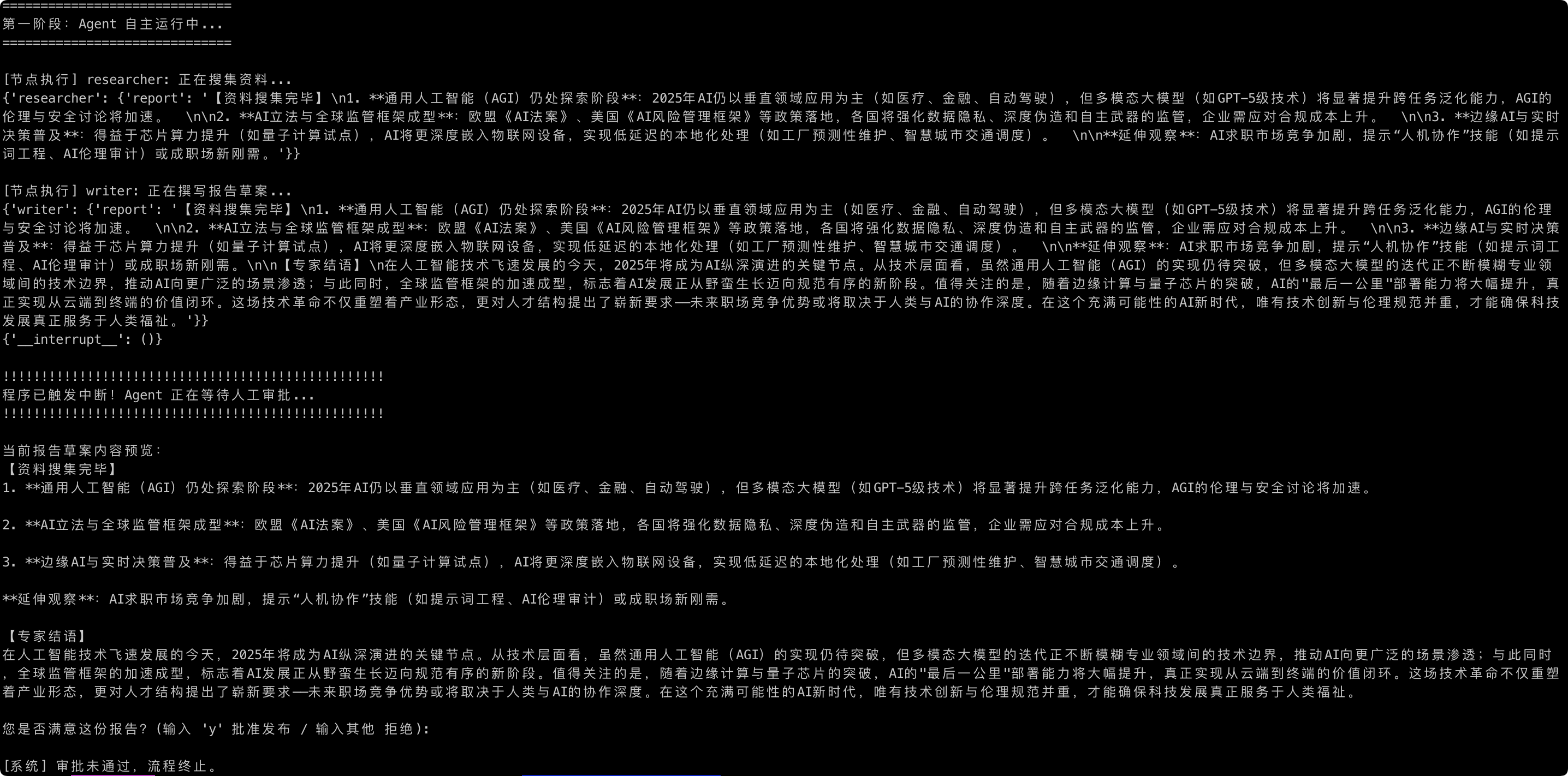
print("="*30)
print("第一阶段:Agent 自主运行中...")
print("="*30)
# 启动任务
initial_input = {"topic": "人工智能在 2025 年的趋势", "approved": False}
for event in app.stream(initial_input, config):
print(event)
# 观察点:你会发现程序执行完 writer 后,并没有打印 publisher 的内容,而是直接停住了
print("\n" + "!"*50)
print("程序已触发中断!Agent 正在等待人工审批...")
print("!"*50)
# 此时我们可以检查当前大脑里的“报告”长什么样
current_snapshot = app.get_state(config)
print(f"\n当前报告草案内容预览:\n{current_snapshot.values['report']}")
# 模拟人工审批操作
user_input = input("\n您是否满意这份报告?(输入 'y' 批准发布 / 输入其他 拒绝): ")
if user_input.lower() == 'y':
# 修改状态,并注入人类的意志
app.update_state(config, {"approved": True}, as_node="human_approval")
print("\n[系统] 已注入人工指令:approved = True")
print("\n" + "="*30)
print("第二阶段:Agent 恢复运行...")
print("="*30)
# 传入 None,让 Agent 从断点继续
for event in app.stream(None, config):
print(event)
else:
print("\n[系统] 审批未通过,流程终止。")
运行此代码你将看到:
- 自动化的前半段:Agent 会自动调用 DeepSeek-V3 完成
researcher和writer的工作。 - 戛然而止的瞬间:由于
interrupt_before=["human_approval"],你会发现控制台打印完writer的日志后,程序并没有结束,也没有去发布,而是跳出了我们的input交互提示。 - 状态的持久化:即使你在这一步强行关闭程序(Ctrl+C),只要你的
thread_id不变,Agent 的进度就已经死死地刻在了MemorySaver里。 - 身份的伪装:通过
update_state(..., as_node="human_approval"),你成功地在“白板”上写下了approved: True,并且让 Graph 认为这是审批节点的输出,从而顺着逻辑流走向了最终的publisher。
这,就是生产级 Agent 开发中,如何平衡 AI 的自主性 与 人类的确定性 的终极答案。
拒绝
同意

8.6 总结:这就是“状态机”的威力
- 知其然:
human_approval是你给节点起的名字。 - 知其所以然:
interrupt_before负责“停”。update_state负责人类“干预”。stream(None, ...)负责人类干预后的“续”。
这种机制让 Agent 不再是一个不可控的“黑盒脚本”,而是一个可以随时被叫停、被人类审查、被人类修正、最后再继续任务的可控工程组件。这在金融、法律、医疗等高风险领域是 LangChain 1.x 能够落地的核心原因。
九、 为什么开发者首选 LangChain?—— 行业地位与竞品博弈
随着 Agent 概念的火爆,开源社区涌现出了一大批各具特色的开发框架,如 AutoGPT、CrewAI、Semantic Kernel 以及 MetaGPT。然而,在繁花簇锦的工具链中,LangChain 依然保持着绝对的统治地位。
9.1 统治力的背后:坚实的数据支撑
这种“统治力”不仅体现在其活跃的 官方社区 建设上,更有权威机构的背书。根据 a16z 发布的生成式 AI 堆栈调研报告 以及 OSS Insight 的 GitHub 实时数据 显示,LangChain 在 GitHub 上的 Star 增长曲线与贡献者规模远超同类框架。
开发者之所以首选 LangChain,主要归功于以下两点:
- 深厚的生态积淀: 它拥有数以千计的组件集成,无论是各种数据加载器 (Loader)、外部工具 (Tool)、主流模型 (Model) 还是向量数据库 (VectorDB),你几乎找不到它无法连接的组件。
- 架构的工程化演进: 在 1.x 版本中,LangChain 完成了从简单的“链(Chain)”向更复杂的“图(Graph)”的华丽转身。特别是 LangGraph 的推出,通过引入“状态机”思维,解决了 Agent 开发中“不可控”与“难以调试”的痛点,让 AI 应用在生产环境下具备了真正的工程化落地能力。
9.2 横向测评:LangChain vs 热门竞品
虽然 LangChain 是全能型选手,但在特定场景下,其他框架也各有所长。以下是主流 Agent 开发框架的对比分析:
| 框架 | 核心优势 | 主要劣势 | 最佳适用场景 |
|---|---|---|---|
| LangChain | 生态无敌,支持 700+ 工具集成;LangGraph 提供的状态控制极其精准。 | 概念较多,初学者学习曲线相对较陡。 | 绝大多数企业级 AI 应用、需要复杂逻辑编排的 Agent 项目。 |
| LlamaIndex | RAG(知识库检索)领域的神,数据索引和查询转换机制极其丰富。 | 在复杂 Agent 逻辑编排和多轮交互上不如 LangGraph 灵活。 | 专门做深度文档问答、搜索增强系统(RAG)。 |
| CrewAI | 简单易用,主打“多角色”扮演(Role-playing),能快速跑通多 Agent 协作。 | 底层控制力较弱,定制化复杂逻辑时难度较大。 | 快速验证多角色协同的 Demo 或自动化内容创作。 |
| Semantic Kernel | 微软“亲儿子”,对 .NET 和 Java 开发者极度友好,企业级整合能力强。 | Python 生态相比之下更新略慢,社区活跃度稍逊于 LangChain。 | 传统大型企业级软件(如 Office 生态)的 AI 功能集成。 |
9.3 开发建议:我该怎么选?
- 如果你追求稳定性与工业化落地:毫不犹豫选择 LangChain + LangGraph。它的断点续传、人工干预和状态管理是目前业内最成熟的工程方案。
- 如果你的需求核心是“海量文档检索”:可以优先考虑 LlamaIndex,或者将 LlamaIndex 的检索能力作为插件集成进 LangChain 中。
- 如果你是初学者且想快速看到“多个 Agent 吵架/协作”的效果:CrewAI 是一个很好的上手起点。
- 如果你在传统的 C# 或 Java 企业环境中工作:Semantic Kernel 是你的不二之选。
十、总结与将来:LangChain 会进化到哪里?
LangChain 的联合创始人哈里森·蔡斯(Harrison Chase) 曾在多次演讲中提到,Agent 的未来是 “Self-Correction”(自我修正)。
- 低代码化:未来你可能不需要写复杂的 Python 代码,而是通过 LangGraph Studio 这样的可视化界面拖拽生成 Agent。
- 标准化:随着 MCP(Model Context Protocol) 等协议的出现,LangChain 将成为连接万物工具的通用适配器。
- Autonomous(自主化):Agent 将从“你指哪它打哪”,进化到“你给它一个目标(如:帮我写个网站并部署),它自己规划路径”。
给初学者的建议:
不要死记硬背 API。LangChain 的 API 经常更新,但 “状态机思维” 和 “LCEL 链式编排” 是永远不变的核心。掌握了这两点,你就掌握了 Agent 时代的生存法则。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)