智能体平台Dify的 分布式调度与系统吞吐优化
本文解析了基于Celery和Redis的异步任务分发完整链路,适用于GitHub Webhook触发代码审查工作流的场景。流程分为三个阶段:1) 同步接收请求并验证入队(毫秒级),包括配额检查、队列选择和任务存储;2) Worker异步处理(秒/分钟级),通过阻塞式拉取任务、执行LLM调用等耗时操作;3) 可选的结果查询阶段。关键实现包括非阻塞设计、状态追踪机制和基于订阅等级的队列路由策略,通过F
Celery + Redis 异步任务分发完整链路解析
实战场景:用户通过 Webhook 触发 Workflow
假设用户配置了 GitHub Webhook,当有新 Pull Request 时自动执行工作流进行代码审查。
完整链路时序图
API 入口 - 任务入队
文件位置:api/services/async_workflow_service.py
Step 1: 方法入口
@classmethod
def trigger_workflow_async(
cls, session: Session, user: Union[Account, EndUser], trigger_data: TriggerData
) -> AsyncTriggerResponse:
"""
Universal entry point for async workflow execution - THIS METHOD WILL NOT BLOCK
通用异步工作流执行入口 - 此方法不会阻塞
Creates a trigger log and dispatches to appropriate queue based on subscription tier.
创建触发日志并根据订阅等级分发到相应队列。
The workflow execution happens asynchronously in the background via Celery workers.
工作流执行通过 Celery Worker 在后台异步进行。
This method returns immediately after queuing the task, not after execution completion.
此方法在任务入队后立即返回,而不是等待执行完成。
Args:
session: Database session to use for operations
user: User (Account or EndUser) who initiated the workflow trigger
trigger_data: Validated Pydantic model containing trigger information
Returns:
AsyncTriggerResponse with workflow_trigger_log_id, task_id, status="queued", and queue
Note: The actual workflow execution status must be checked separately via workflow_trigger_log_id
Raises:
WorkflowNotFoundError: If app or workflow not found
InvokeDailyRateLimitError: If daily rate limit exceeded
"""
关键点:
- ✅ 非阻塞:立即返回,不等待 LLM 调用完成
- ✅ 状态追踪:返回
workflow_trigger_log_id用于后续查询 - ✅ 队列路由:根据订阅等级选择队列
Step 2: 验证与创建触发日志
trigger_log_repo = SQLAlchemyWorkflowTriggerLogRepository(session)
dispatcher_manager = QueueDispatcherManager()
workflow_service = WorkflowService()
# 🔍 1. 验证 App 存在
# 1. Validate app exists
app_model = session.scalar(select(App).where(App.id == trigger_data.app_id))
if not app_model:
raise WorkflowNotFoundError(f"App not found: {trigger_data.app_id}")
# 🔍 2. 获取 Workflow
# 2. Get workflow
workflow = cls._get_workflow(workflow_service, app_model, trigger_data.workflow_id)
# 🔍 3. 根据租户订阅获取队列调度器
# 3. Get dispatcher based on tenant subscription
dispatcher = dispatcher_manager.get_dispatcher(trigger_data.tenant_id)
# 4. Rate limiting check will be done without timezone first
# 🔍 5. 确定用户角色和 ID
# 5. Determine user role and ID
if isinstance(user, Account):
created_by_role = CreatorUserRole.ACCOUNT
created_by = user.id
else: # EndUser
created_by_role = CreatorUserRole.END_USER
created_by = user.id
# 🔍 6. 先创建触发日志(用于追踪)
# 6. Create trigger log entry first (for tracking)
trigger_log = WorkflowTriggerLog(
tenant_id=trigger_data.tenant_id,
app_id=trigger_data.app_id,
workflow_id=workflow.id,
root_node_id=trigger_data.root_node_id,
trigger_metadata=(
trigger_data.trigger_metadata.model_dump_json() if trigger_data.trigger_metadata else "{}"
),
trigger_type=trigger_data.trigger_type,
workflow_run_id=None,
outputs=None,
trigger_data=trigger_data.model_dump_json(),
inputs=json.dumps(dict(trigger_data.inputs)),
status=WorkflowTriggerStatus.PENDING, # 🔍 初始状态:PENDING
queue_name=dispatcher.get_queue_name(),
retry_count=0,
created_by_role=created_by_role,
created_by=created_by,
celery_task_id=None, # 🔍 此时还未创建 Celery 任务
error=None,
elapsed_time=None,
total_tokens=None,
)
trigger_log = trigger_log_repo.create(trigger_log)
session.commit()
数据库记录示例:
-- WorkflowTriggerLog 表
INSERT INTO workflow_trigger_logs (
id, tenant_id, app_id, workflow_id,
status, queue_name, trigger_data, inputs,
created_at
) VALUES (
'trigger_log_123',
'tenant_456',
'app_789',
'workflow_abc',
'pending', -- 初始状态
'workflow_professional',
'{"app_id": "app_789", ...}',
'{"pr_number": 123}',
'2024-01-20 10:30:00'
);
Step 3: 配额检查
# 🔍 7. 检查并消耗配额
# 7. Check and consume quota
try:
QuotaType.WORKFLOW.consume(trigger_data.tenant_id)
except QuotaExceededError as e:
# 🔍 更新触发日志状态
# Update trigger log status
trigger_log.status = WorkflowTriggerStatus.RATE_LIMITED
trigger_log.error = f"Quota limit reached: {e}"
trigger_log_repo.update(trigger_log)
session.commit()
raise WorkflowQuotaLimitError(
f"Workflow execution quota limit reached for tenant {trigger_data.tenant_id}"
) from e
配额机制(伪代码示例):
# enums/quota_type.py
class QuotaType:
WORKFLOW = QuotaConfig(
daily_limit=1000, # 免费版每天1000次
redis_key_template="quota:workflow:{tenant_id}:daily"
)
def consume(self, tenant_id: str):
key = f"quota:workflow:{tenant_id}:daily"
current = redis.incr(key) # 原子递增
if current == 1:
# 首次调用,设置24小时过期
redis.expire(key, 86400)
if current > self.daily_limit:
raise QuotaExceededError()
Step 4: 任务入队(核心)
# 🔍 8. 创建任务数据
# 8. Create task data
queue_name = dispatcher.get_queue_name()
task_data = WorkflowTaskData(workflow_trigger_log_id=trigger_log.id)
# ⭐⭐⭐⭐ ⭐9. 分发到相应队列
# 9. Dispatch to appropriate queue
task_data_dict = task_data.model_dump(mode="json")
task: AsyncResult[Any] | None = None
if queue_name == QueuePriority.PROFESSIONAL:
task = execute_workflow_professional.delay(task_data_dict) # type: ignore
elif queue_name == QueuePriority.TEAM:
task = execute_workflow_team.delay(task_data_dict) # type: ignore
else: # SANDBOX
task = execute_workflow_sandbox.delay(task_data_dict) # type: ignore
# 🔍 10. 更新触发日志,添加任务信息
# 10. Update trigger log with task info
trigger_log.status = WorkflowTriggerStatus.QUEUED # 🔍 状态变更:PENDING -> QUEUED
trigger_log.celery_task_id = task.id # 🔍 记录 Celery 任务 ID
trigger_log.triggered_at = datetime.now(UTC)
trigger_log_repo.update(trigger_log)
session.commit()
return AsyncTriggerResponse(
workflow_trigger_log_id=trigger_log.id,
task_id=task.id, # type: ignore
status="queued",
queue=queue_name,
)
execute_workflow_professional.delay()
这一行代码触发了整个异步机制:
# tasks/async_workflow_tasks.py
@shared_task(queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE)
def execute_workflow_professional(task_data_dict: dict[str, Any]):
# ... 任务执行逻辑
.delay()** 方法做了什么**:

底层 Redis 操作(简化):
# Celery 内部逻辑(简化)
def delay(self, *args, **kwargs):
# 1. 序列化任务数据
task_id = str(uuid.uuid4())
message = {
"id": task_id,
"task": "tasks.async_workflow_tasks.execute_workflow_professional",
"args": [task_data_dict],
"kwargs": {},
"retries": 0,
"eta": None,
}
# 2. 推送到 Redis
redis.lpush(
"workflow_professional", # 队列名
json.dumps(message)
)
# 3. 返回 AsyncResult 对象
return AsyncResult(task_id)
Redis 中的数据结构:
# Redis CLI 查看
127.0.0.1:6379> LLEN workflow_professional
(integer) 5 # 队列中有5个待处理任务
127.0.0.1:6379> LRANGE workflow_professional 0 0
1) '{"id":"abc-123","task":"tasks.async_workflow_tasks.execute_workflow_professional","args":[{"workflow_trigger_log_id":"trigger_log_123"}],"kwargs":{},"retries":0}'
Celery Worker 拉取与执行
文件位置:api/tasks/async_workflow_tasks.py
Worker 启动命令
# 启动专业版队列的 Worker
celery -A celery worker \
-Q workflow_professional \
-c 8 \
--loglevel=info \
--prefetch-multiplier=1
参数说明:
-Q workflow_professional:只监听此队列<font style="color:#DF2A3F;">-c 8</font>:并发8个任务(使用 Gevent 协程池)--prefetch-multiplier=1:每次只预取1个任务,避免任务积压
Worker 监听循环
# Celery Worker 内部伪代码
def worker_main_loop():
while True:
# 阻塞式拉取任务(BRPOP 命令)
task_message = redis.brpop("workflow_professional", timeout=1)
if task_message:
# 反序列化任务
task = deserialize(task_message)
# 执行任务函数
try:
result = execute_task(task)
# 存储结果到 backend
redis.set(f"celery-task-meta-{task.id}", result)
except Exception as e:
# 重试或标记失败
handle_failure(task, e)
任务执行函数
@shared_task(queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE)
def execute_workflow_professional(task_data_dict: dict[str, Any]):
"""Execute workflow for professional tier with highest priority
执行专业版工作流,最高优先级"""
# 🔍 1. 反序列化任务数据
task_data = WorkflowTaskData.model_validate(task_data_dict)
# 🔍 2. 创建调度计划实体
cfs_plan_scheduler_entity = AsyncWorkflowCFSPlanEntity(
queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE,
schedule_strategy=AsyncWorkflowSystemStrategy,
granularity=dify_config.ASYNC_WORKFLOW_SCHEDULER_GRANULARITY,
)
# ⭐⭐⭐⭐ 3. 执行通用工作流逻辑
_execute_workflow_common(
task_data,
AsyncWorkflowCFSPlanScheduler(plan=cfs_plan_scheduler_entity),
cfs_plan_scheduler_entity,
)
**通用执行逻辑 **_execute_workflow_common
def _execute_workflow_common(
task_data: WorkflowTaskData,
cfs_plan_scheduler: AsyncWorkflowCFSPlanScheduler,
cfs_plan_scheduler_entity: AsyncWorkflowCFSPlanEntity,
):
"""Execute workflow with common logic and trigger log updates.
执行工作流的通用逻辑并更新触发日志。"""
# 🔍 1. 创建新的数据库会话(与 API 进程隔离)
# Create a new session for this task
session_factory = sessionmaker(bind=db.engine, expire_on_commit=False)
with session_factory() as session:
trigger_log_repo = SQLAlchemyWorkflowTriggerLogRepository(session)
# 🔍 2. 获取触发日志
# Get trigger log
trigger_log = trigger_log_repo.get_by_id(task_data.workflow_trigger_log_id)
if not trigger_log:
# This should not happen, but handle gracefully
return
# 🔍 3. 从触发日志重建执行数据
# Reconstruct execution data from trigger log
trigger_data = TriggerData.model_validate_json(trigger_log.trigger_data)
# 🔍 4. 更新状态为运行中
# Update status to running
trigger_log.status = WorkflowTriggerStatus.RUNNING
trigger_log_repo.update(trigger_log)
session.commit()
start_time = datetime.now(UTC)
try:
# 🔍 5. 获取 App 和 Workflow 模型
# Get app and workflow models
app_model = session.scalar(select(App).where(App.id == trigger_log.app_id))
if not app_model:
raise WorkflowNotFoundError(f"App not found: {trigger_log.app_id}")
workflow = session.scalar(select(Workflow).where(Workflow.id == trigger_log.workflow_id))
if not workflow:
raise WorkflowNotFoundError(f"Workflow not found: {trigger_log.workflow_id}")
user = _get_user(session, trigger_log)
# 🔍 6. 执行工作流(核心)
# Execute workflow using WorkflowAppGenerator
generator = WorkflowAppGenerator()
# Prepare args matching AppGenerateService.generate format
args = _build_generator_args(trigger_data)
# If workflow_id was specified, add it to args
if trigger_data.workflow_id:
args["workflow_id"] = str(trigger_data.workflow_id)
# ⭐⭐⭐⭐⭐ 7. 执行工作流(这里会调用 LLM)
# Execute the workflow with the trigger type
generator.generate(
app_model=app_model,
workflow=workflow,
user=user,
args=args,
invoke_from=InvokeFrom.SERVICE_API,
streaming=False,
call_depth=0,
triggered_from=trigger_data.trigger_from,
root_node_id=trigger_data.root_node_id,
graph_engine_layers=[
# TODO: Re-enable TimeSliceLayer after the HITL release.
TriggerPostLayer(cfs_plan_scheduler_entity, start_time, trigger_log.id, session_factory),
],
)
except Exception as e:
# 🔍 8. 异常处理:更新触发日志为失败状态
# Calculate elapsed time for failed execution
elapsed_time = (datetime.now(UTC) - start_time).total_seconds()
# Update trigger log with failure
trigger_log.status = WorkflowTriggerStatus.FAILED
trigger_log.error = str(e)
trigger_log.finished_at = datetime.now(UTC)
trigger_log.elapsed_time = elapsed_time
trigger_log_repo.update(trigger_log)
# Final failure - no retry logic (simplified like RAG tasks)
session.commit()
关键点注释:
- 独立会话:Worker 创建新的数据库会话,与 API 进程隔离,避免长事务
- 状态追踪:PENDING → QUEUED → RUNNING → SUCCESS/FAILED
- 异常安全:即使执行失败,也会更新数据库状态
- 工作流执行:
<font style="color:#DF2A3F;">WorkflowAppGenerator.generate()</font>是实际执行 Workflow 的地方
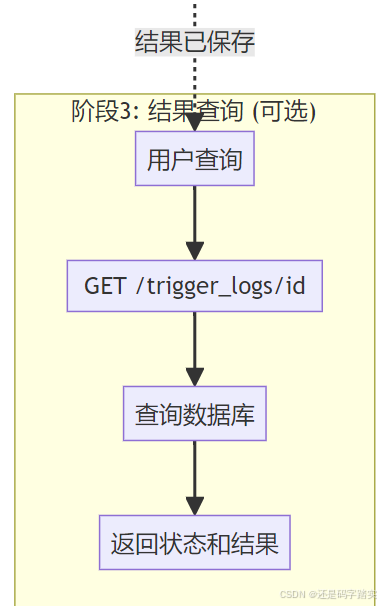
结果查询(可选)
用户可以通过 workflow_trigger_log_id 查询执行状态:
# API 端点
@app.route("/trigger_logs/<trigger_log_id>")
def get_trigger_log(trigger_log_id: str):
result = AsyncWorkflowService.get_trigger_log(trigger_log_id)
return jsonify(result)
返回数据示例:
{
"id": "trigger_log_123",
"status": "success",
"triggered_at": "2024-01-20T10:30:00Z",
"finished_at": "2024-01-20T10:30:25Z",
"elapsed_time": 25.3,
"outputs": {
"code_review": "代码质量良好,建议优化第23行..."
},
"total_tokens": 3500,
"error": null
}
完整架构流程图
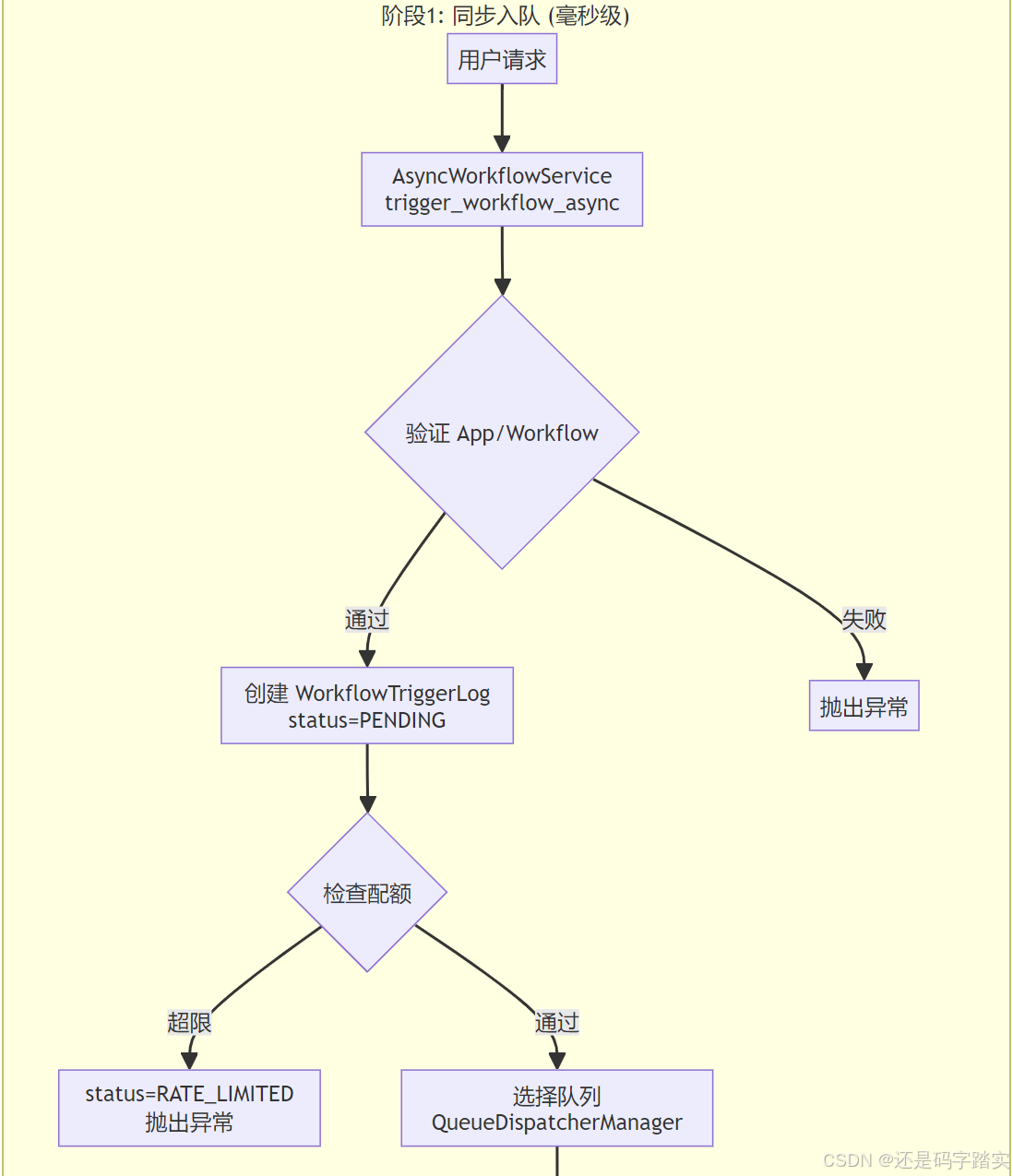
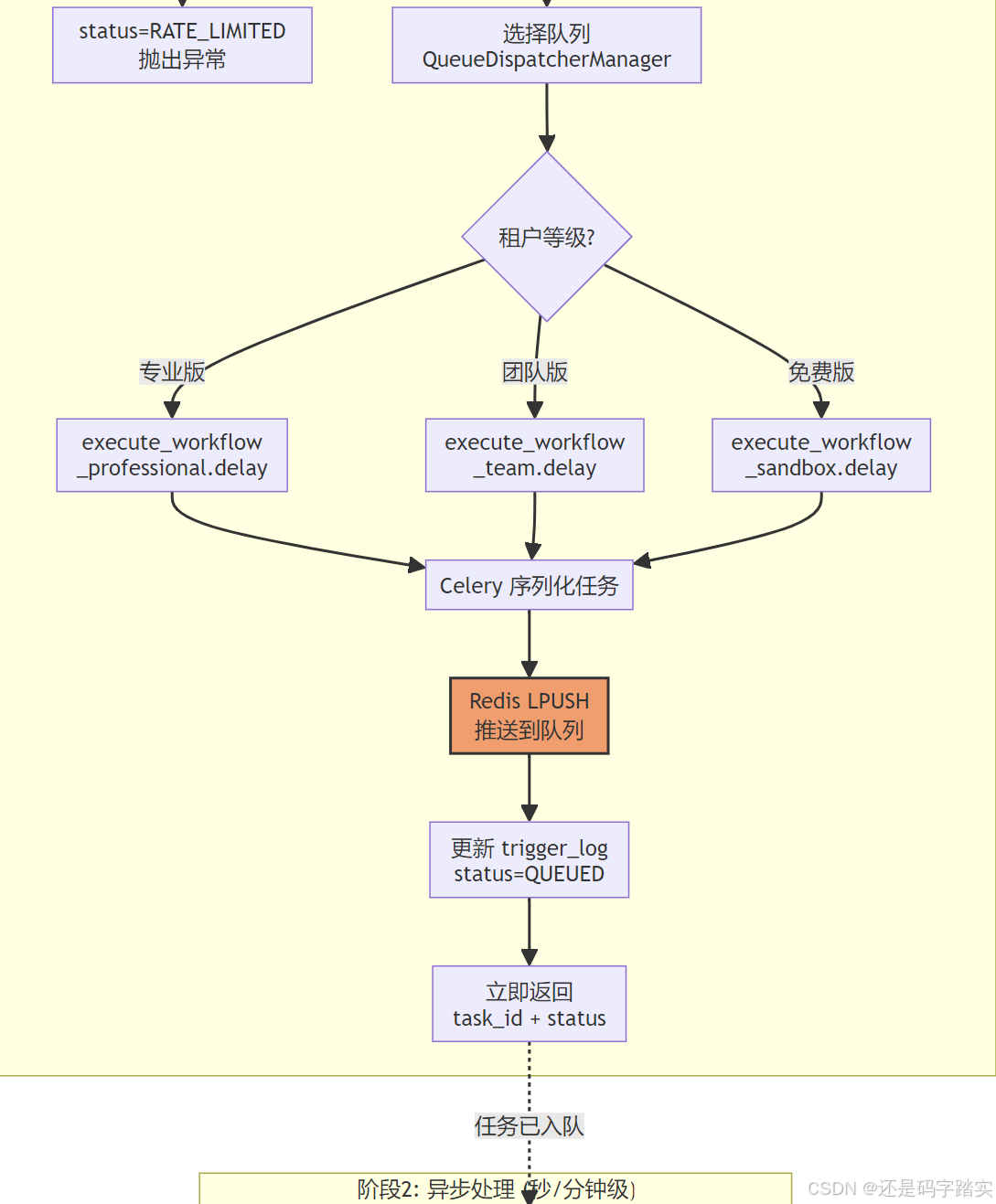
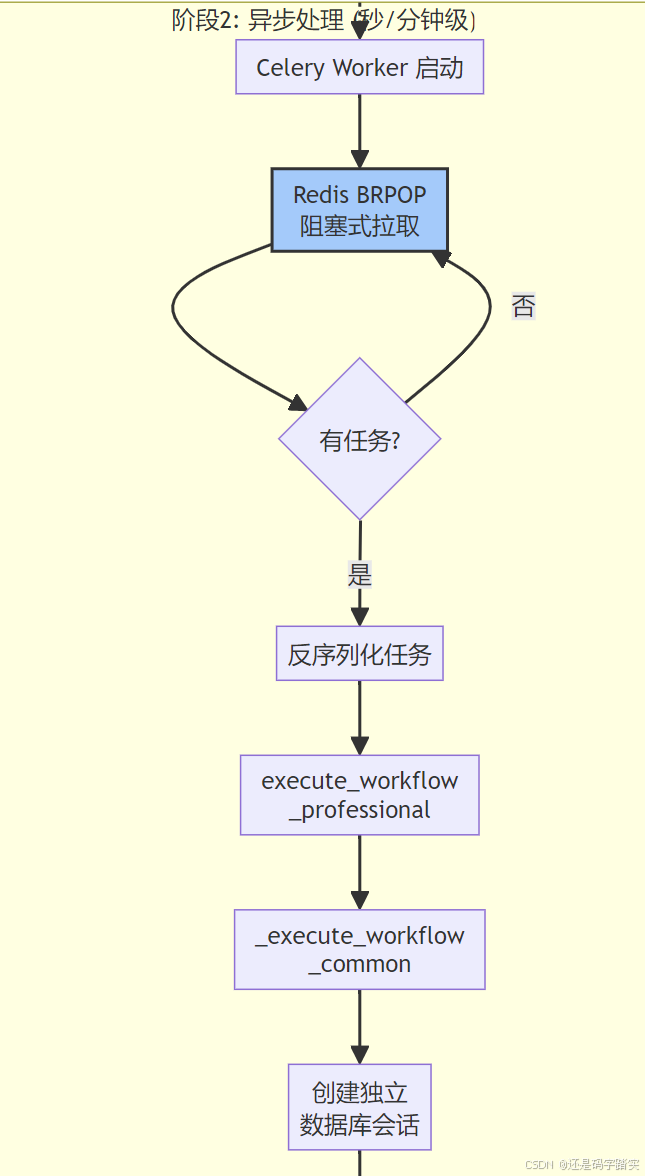
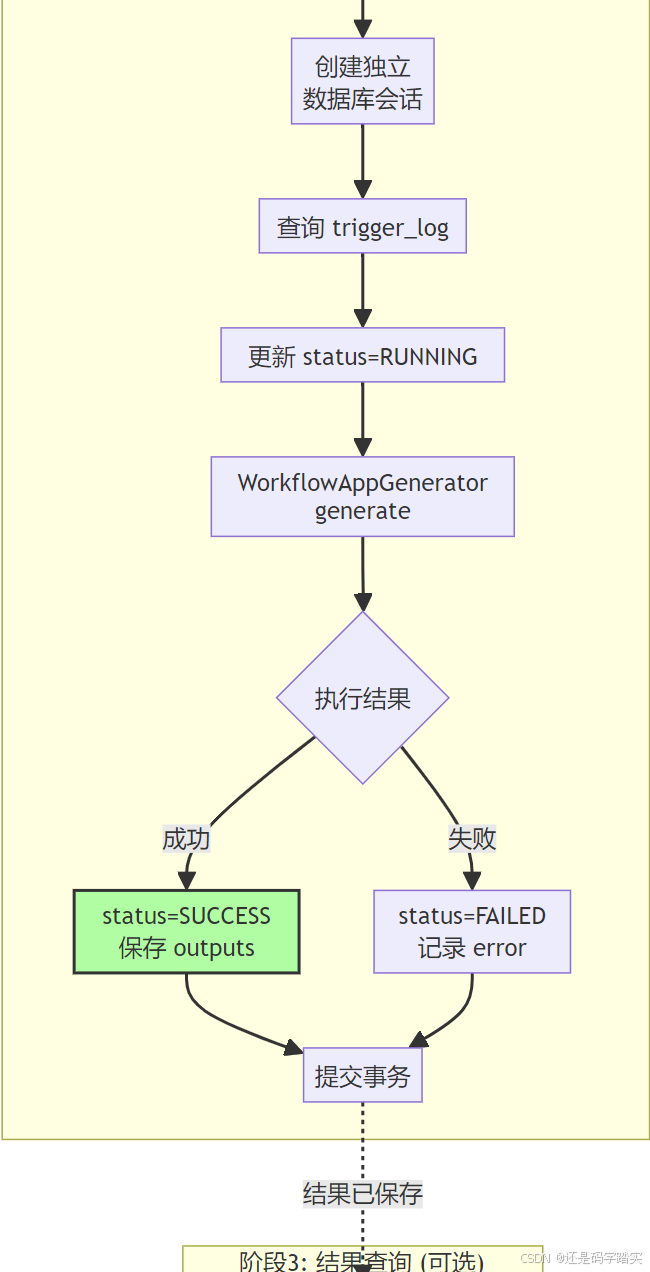
关键函数递归解析
execute_workflow_professional.delay()
# 位置:tasks/async_workflow_tasks.py:35
@shared_task(queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE)
def execute_workflow_professional(task_data_dict: dict[str, Any]):
"""
装饰器 @shared_task 的作用:
1. 将函数注册为 Celery 任务
2. 自动序列化/反序列化参数
3. 提供 .delay() 和 .apply_async() 方法
"""
pass
# 调用 .delay() 时:
task = execute_workflow_professional.delay({"workflow_trigger_log_id": "xxx"})
# 等价于:
task = execute_workflow_professional.apply_async(
args=[{"workflow_trigger_log_id": "xxx"}],
queue="workflow_professional",
retry=False
)
底层 Redis 操作:
# Celery 内部实现(简化)
def apply_async(self, args, kwargs, queue):
# 1. 生成唯一任务 ID
task_id = self._gen_task_id()
# 2. 构造消息体
message = {
"id": task_id,
"task": self.name, # "tasks.async_workflow_tasks.execute_workflow_professional"
"args": args,
"kwargs": kwargs,
"retries": 0,
"eta": None,
"expires": None,
}
# 3. 序列化(默认使用 JSON)
serialized = json.dumps(message)
# 4. 推送到 Redis 队列
redis_client.lpush(queue, serialized)
# 5. 返回 AsyncResult 对象
return AsyncResult(task_id)
WorkflowAppGenerator.generate()
# 位置:core/app/apps/workflow/app_generator.py
class WorkflowAppGenerator:
def generate(
self,
app_model: App,
workflow: Workflow,
user: Account | EndUser,
args: dict,
invoke_from: InvokeFrom,
streaming: bool,
call_depth: int,
triggered_from: WorkflowRunTriggeredFrom | None = None,
root_node_id: str | None = None,
graph_engine_layers: list | None = None,
):
"""
核心工作流执行引擎
执行流程:
1. 解析 Workflow Graph(节点和连接)
2. 初始化执行上下文
3. 按拓扑顺序执行节点
4. 处理节点间的数据流
5. 收集输出结果
"""
# 1. 构建执行图
graph = self._build_graph(workflow)
# 2. 初始化变量池
variable_pool = VariablePool()
variable_pool.add_variables(args["inputs"])
# 3. 执行节点
for node in graph.topological_sort():
if node.type == NodeType.LLM:
# 调用 LLM
result = self._execute_llm_node(node, variable_pool)
elif node.type == NodeType.CODE:
# 执行代码
result = self._execute_code_node(node, variable_pool)
elif node.type == NodeType.TOOL:
# 调用工具
result = self._execute_tool_node(node, variable_pool)
# 更新变量池
variable_pool.add_variable(node.id, result)
# 4. 返回结果
return variable_pool.get_outputs()
TriggerPostLayer —— 结果回写
# 位置:core/app/layers/trigger_post_layer.py(推测)
class TriggerPostLayer:
"""
工作流执行完成后的回调层
负责将结果写回 WorkflowTriggerLog
"""
def __init__(self, cfs_plan_entity, start_time, trigger_log_id, session_factory):
self.start_time = start_time
self.trigger_log_id = trigger_log_id
self.session_factory = session_factory
def on_workflow_completed(self, outputs, total_tokens):
"""工作流完成时调用"""
with self.session_factory() as session:
trigger_log = session.get(WorkflowTriggerLog, self.trigger_log_id)
# 更新结果
trigger_log.status = WorkflowTriggerStatus.SUCCESS
trigger_log.outputs = json.dumps(outputs)
trigger_log.total_tokens = total_tokens
trigger_log.elapsed_time = (datetime.now(UTC) - self.start_time).total_seconds()
trigger_log.finished_at = datetime.now(UTC)
session.commit()
实战示例:完整数据流
场景:GitHub PR 触发代码审查
时间线分析
| 时刻 | 事件 | 耗时 | 说明 |
|---|---|---|---|
| T+0ms | GitHub 发送 Webhook | - | 用户创建 PR |
| T+50ms | API 创建 trigger_log | 10ms | 数据库写入 |
| T+55ms | API 推送到 Redis | 5ms | LPUSH 操作 |
| T+60ms | API 返回响应 | 5ms | HTTP 200 |
| T+100ms | Worker 拉取任务 | - | BRPOP 返回 |
| T+150ms | Worker 查询数据库 | 50ms | SELECT |
| T+15.2s | GPT-4 返回结果 | 15s | LLM 调用 |
| T+15.3s | Worker 更新数据库 | 100ms | UPDATE |
| T+20s | 用户查询结果 | - | GET API |
关键指标:
- ✅ API 响应时间:60ms(用户无感知)
- ✅ 实际执行时间:15.3s(异步完成)
- ✅ 并发能力:API 可同时处理 上千 请求
关键配置文件
Celery 配置 (extensions/ext_celery.py)
Dify 使用 Celery 作为分布式任务队列,配置文件位于 ext_celery.py:
celery_app.conf.update(
# Broker 配置
broker=dify_config.CELERY_BROKER_URL, # redis://localhost:6379/0
# Result Backend
result_backend=dify_config.CELERY_RESULT_BACKEND,
# 任务忽略结果(减轻 Redis 负载)
task_ignore_result=True,
# 连接重试
broker_connection_retry_on_startup=True,
# 时区
timezone=pytz.timezone("UTC"),
# 任务序列化
task_serializer='json',
accept_content=['json'],
result_serializer='json',
)
celery_app = Celery(
app.name,
task_cls=FlaskTask,
broker=dify_config.CELERY_BROKER_URL,
backend=dify_config.CELERY_BACKEND,
)
celery_app.conf.update(
result_backend=dify_config.CELERY_RESULT_BACKEND,
broker_transport_options=broker_transport_options,
broker_connection_retry_on_startup=True,
worker_log_format=dify_config.LOG_FORMAT,
worker_task_log_format=dify_config.LOG_FORMAT,
worker_hijack_root_logger=False,
timezone=pytz.timezone(dify_config.LOG_TZ or "UTC"),
task_ignore_result=True,
)
# Apply SSL configuration if enabled
ssl_options = _get_celery_ssl_options()
if ssl_options:
celery_app.conf.update(
broker_use_ssl=ssl_options,
# Also apply SSL to the backend if it's Redis
redis_backend_use_ssl=ssl_options if dify_config.CELERY_BACKEND == "redis" else None,
)
if dify_config.LOG_FILE:
celery_app.conf.update(
worker_logfile=dify_config.LOG_FILE,
)
celery_app.set_default()
app.extensions["celery"] = celery_app
核心配置解读:
- broker: Redis 作为消息代理(Broker),存储待执行任务
- backend: 任务结果存储,可选 Redis/Database/RabbitMQ
- broker_connection_retry_on_startup: 启动时自动重连,防止 Redis 临时不可用导致服务崩溃
- task_ignore_result: 忽略结果存储,减轻 Redis 负载(适用于不需要获取任务结果的场景)
Redis Sentinel 高可用配置
if dify_config.CELERY_USE_SENTINEL:
broker_transport_options = {
"master_name": dify_config.CELERY_SENTINEL_MASTER_NAME,
"sentinel_kwargs": {
"socket_timeout": dify_config.CELERY_SENTINEL_SOCKET_TIMEOUT,
"password": dify_config.CELERY_SENTINEL_PASSWORD,
},
}
高可用保障:
- 支持 Redis Sentinel 模式,实现主从切换
- 当 Master 节点故障时,Sentinel 自动选举新 Master
- 防止 Redis 单点故障导致任务队列不可用
队列定义 (tasks/workflow_cfs_scheduler/entities.py)
if dify_config.EDITION == "CLOUD":
# 云版:三个队列
_professional_queue = "workflow_professional"
_team_queue = "workflow_team"
_sandbox_queue = "workflow_sandbox"
else:
# 社区版:单队列
_professional_queue = "workflow"
_team_queue = "workflow"
_sandbox_queue = "workflow"
Worker 启动脚本
#!/bin/bash
# start_workers.sh
# 启动专业版队列 Worker(8个并发)
celery -A celery worker \
-Q workflow_professional \
-c 8 \
--pool=gevent \
--loglevel=info \
--logfile=/var/log/celery/professional.log &
# 启动团队版队列 Worker(4个并发)
celery -A celery worker \
-Q workflow_team \
-c 4 \
--pool=gevent \
--loglevel=info \
--logfile=/var/log/celery/team.log &
# 启动免费版队列 Worker(2个并发)
celery -A celery worker \
-Q workflow_sandbox \
-c 2 \
--pool=gevent \
--loglevel=info \
--logfile=/var/log/celery/sandbox.log &
总结:异步架构的核心优势
对比同步 vs 异步
| 维度 | 同步架构 | 异步架构(Celery + Redis) |
|---|---|---|
| API 响应时间 | 10-30秒 | 50-100ms |
| 并发能力 | 40(连接池限制) | 1000+(瞬时入队) |
| 失败处理 | 用户感知超时 | 后台重试,用户无感 |
| 资源利用 | API Worker 阻塞 | API/Worker 解耦,独立扩展 |
| 监控追踪 | 困难 | 通过 trigger_log_id 完整追踪 |
关键设计原则
- 非阻塞入队:API 只负责验证和入队,立即返回
- 状态追踪:通过
WorkflowTriggerLog全程记录 - 队列隔离:按租户等级分流,防止资源滥用
- 独立会话:Worker 使用独立数据库会话,避免长事务
- 异常安全:即使失败也更新状态,不丢失追踪
这套架构让 Dify 能够支撑每秒数千并发请求,同时保持 API 响应速度在毫秒级!
轻重任务队列分离 —— 按租户等级分流
整体架构流程图
场景示例
假设三个用户同时触发工作流:
- Alice(专业版):生成市场分析报告
- Bob(团队版):批量处理客户数据
- Charlie(免费版):测试简单工作流
API 入口 - 接收请求
文件位置: api/services/async_workflow_service.py
# 第52-80行:AsyncWorkflowService.trigger_workflow_async
@classmethod
def trigger_workflow_async(
cls, session: Session, user: Union[Account, EndUser], trigger_data: TriggerData
) -> AsyncTriggerResponse:
"""
Universal entry point for async workflow execution - THIS METHOD WILL NOT BLOCK
Creates a trigger log and dispatches to appropriate queue based on subscription tier.
The workflow execution happens asynchronously in the background via Celery workers.
This method returns immediately after queuing the task, not after execution completion.
Args:
session: Database session to use for operations
user: User (Account or EndUser) who initiated the workflow trigger
trigger_data: Validated Pydantic model containing trigger information
Returns:
AsyncTriggerResponse with workflow_trigger_log_id, task_id, status="queued", and queue
Note: The actual workflow execution status must be checked separately via workflow_trigger_log_id
Raises:
WorkflowNotFoundError: If app or workflow not found
InvokeDailyRateLimitError: If daily rate limit exceeded
Behavior:
- Non-blocking: Returns immediately after queuing
- Asynchronous: Actual execution happens in background Celery workers
- Status tracking: Use workflow_trigger_log_id to monitor progress
- Queue-based: Routes to different queues based on subscription tier
"""
关键注释解读:
- 🔸 非阻塞:方法立即返回,不等待工作流执行完成
- 🔸 异步执行:实际执行在后台 Celery Worker 中进行
- 🔸 状态追踪:通过
workflow_trigger_log_id监控执行状态
示例调用:
# Alice(专业版用户)触发工作流
trigger_data = TriggerData(
tenant_id="tenant_alice_123",
app_id="app_market_analysis",
workflow_id="workflow_001",
inputs={"topic": "AI市场趋势"},
trigger_type="api"
)
response = AsyncWorkflowService.trigger_workflow_async(
session=db_session,
user=alice_user,
trigger_data=trigger_data
)
# 立即返回: AsyncTriggerResponse(
# workflow_trigger_log_id="log_abc123",
# task_id="celery_task_xyz789",
# status="queued",
# queue="workflow_professional"
# )
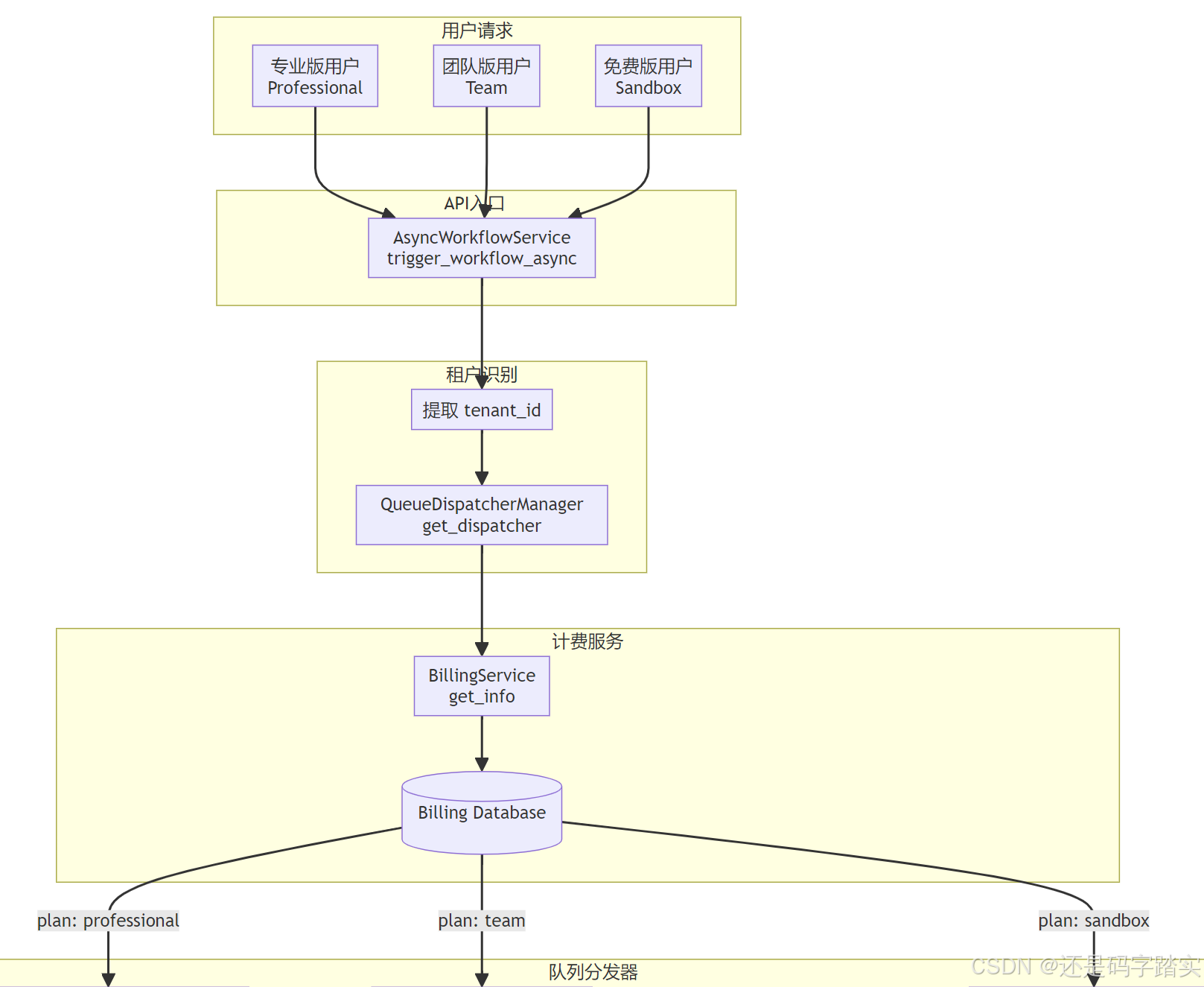
获取队列分发器
文件位置: api/services/async_workflow_service.py:82-94
trigger_log_repo = SQLAlchemyWorkflowTriggerLogRepository(session)
dispatcher_manager = QueueDispatcherManager()
workflow_service = WorkflowService()
# 1. Validate app exists
app_model = session.scalar(select(App).where(App.id == trigger_data.app_id))
if not app_model:
raise WorkflowNotFoundError(f"App not found: {trigger_data.app_id}")
# 2. Get workflow
workflow = cls._get_workflow(workflow_service, app_model, trigger_data.workflow_id)
# 3. Get dispatcher based on tenant subscription
dispatcher = dispatcher_manager.get_dispatcher(trigger_data.tenant_id)
关键步骤注释:
- Step 1: 验证应用是否存在
- Step 2: 获取工作流配置
- Step 3: 🎯 核心 - 根据租户订阅获取分发器
查询租户订阅计划
文件位置: api/services/workflow/queue_dispatcher.py:80-106
def get_dispatcher(cls, tenant_id: str) -> BaseQueueDispatcher:
"""
Get dispatcher based on tenant's subscription plan
Args:
tenant_id: The tenant identifier
Returns:
Appropriate queue dispatcher instance
"""
# 🔸 Step 3.1: 检查是否启用计费
if dify_config.BILLING_ENABLED:
try:
# 🔸 Step 3.2: 从计费服务获取租户信息
billing_info = BillingService.get_info(tenant_id)
plan = billing_info.get("subscription", {}).get("plan", "sandbox")
except Exception:
# 🔸 Step 3.3: 计费服务失败时默认 sandbox
# If billing service fails, default to sandbox
plan = "sandbox"
else:
# 🔸 Step 3.4: 未启用计费时默认 team
# If billing is disabled, use team tier as default
plan = "team"
# 🔸 Step 3.5: 根据计划选择分发器类
dispatcher_class = cls.PLAN_DISPATCHER_MAP.get(
plan,
SandboxQueueDispatcher, # Default to sandbox for unknown plans
)
return dispatcher_class() # type: ignore
分发器映射表:
# Mapping of billing plans to dispatchers
PLAN_DISPATCHER_MAP = {
"professional": ProfessionalQueueDispatcher,
"team": TeamQueueDispatcher,
"sandbox": SandboxQueueDispatcher,
# Add new tiers here as they're created
# For any unknown plan, default to sandbox
}
时序图 - 订阅查询流程:
示例执行:
# Alice 的租户 ID
tenant_id = "tenant_alice_123"
# QueueDispatcherManager.get_dispatcher 执行流程:
# 1. 调用 BillingService.get_info("tenant_alice_123")
# 2. 返回: {"subscription": {"plan": "professional"}}
# 3. plan = "professional"
# 4. dispatcher_class = ProfessionalQueueDispatcher
# 5. 返回: ProfessionalQueueDispatcher() 实例
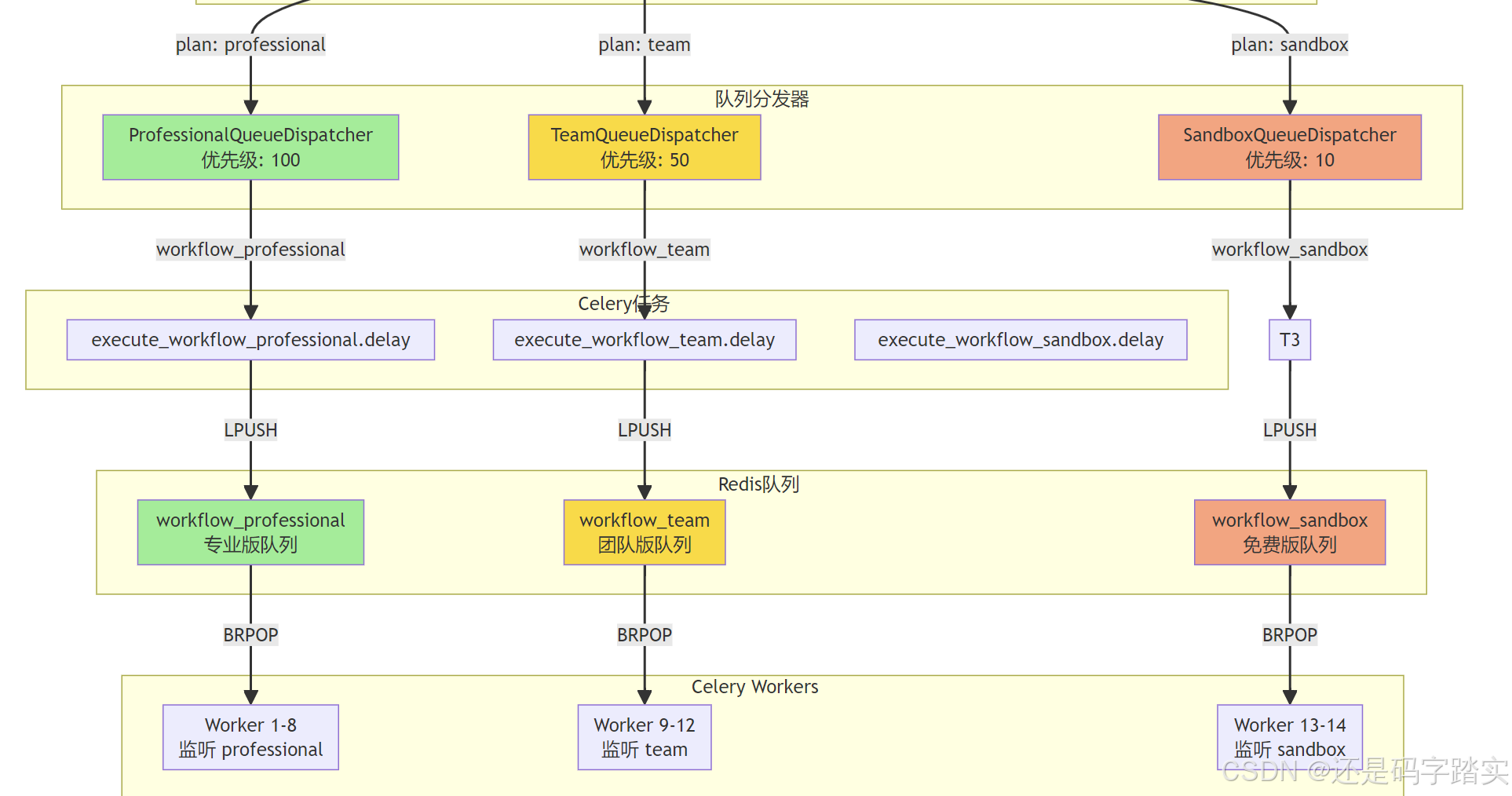
分发器返回队列名称
文件位置: api/services/workflow/queue_dispatcher.py:37-65
专业版分发器
class ProfessionalQueueDispatcher(BaseQueueDispatcher):
"""Dispatcher for professional tier"""
def get_queue_name(self) -> str:
return QueuePriority.PROFESSIONAL
def get_priority(self) -> int:
return 100
团队版分发器
class TeamQueueDispatcher(BaseQueueDispatcher):
"""Dispatcher for team tier"""
def get_queue_name(self) -> str:
return QueuePriority.TEAM
def get_priority(self) -> int:
return 50
免费版分发器
class SandboxQueueDispatcher(BaseQueueDispatcher):
"""Dispatcher for free/sandbox tier"""
def get_queue_name(self) -> str:
return QueuePriority.SANDBOX
def get_priority(self) -> int:
return 10
队列优先级定义:
class QueuePriority(StrEnum):
"""Queue priorities for different subscription tiers"""
PROFESSIONAL = "workflow_professional" # Highest priority
TEAM = "workflow_team"
SANDBOX = "workflow_sandbox" # Free tier
优先级对比表:
| 租户等级 | 队列名称 | 优先级分数 | Worker 数量 | 预期响应时间 |
|---|---|---|---|---|
| Professional | workflow_professional |
100 | 8 | < 5 秒 |
| Team | workflow_team |
50 | 4 | < 30 秒 |
| Sandbox | workflow_sandbox |
10 | 2 | < 5 分钟 |
创建触发日志
文件位置: api/services/async_workflow_service.py:106-132
# 6. Create trigger log entry first (for tracking)
trigger_log = WorkflowTriggerLog(
tenant_id=trigger_data.tenant_id,
app_id=trigger_data.app_id,
workflow_id=workflow.id,
root_node_id=trigger_data.root_node_id,
trigger_metadata=(
trigger_data.trigger_metadata.model_dump_json() if trigger_data.trigger_metadata else "{}"
),
trigger_type=trigger_data.trigger_type,
workflow_run_id=None,
outputs=None,
trigger_data=trigger_data.model_dump_json(),
inputs=json.dumps(dict(trigger_data.inputs)),
status=WorkflowTriggerStatus.PENDING,
queue_name=dispatcher.get_queue_name(), # 🔸 记录队列名称
retry_count=0,
created_by_role=created_by_role,
created_by=created_by,
celery_task_id=None,
error=None,
elapsed_time=None,
total_tokens=None,
)
trigger_log = trigger_log_repo.create(trigger_log)
session.commit()
关键字段解读:
<font style="color:#DF2A3F;">queue_name</font>: 记录任务被分配到哪个队列(用于监控和调试)<font style="color:#DF2A3F;">status</font>: 初始状态为<font style="color:#DF2A3F;">PENDING</font>(待处理)celery_task_id: 稍后会更新为 Celery 任务 ID
示例数据:
# Alice 的触发日志
{
"id": "log_abc123",
"tenant_id": "tenant_alice_123",
"app_id": "app_market_analysis",
"workflow_id": "workflow_001",
"status": "PENDING",
"queue_name": "workflow_professional", # ✅ 专业版队列
"celery_task_id": None, # 待分配
"created_at": "2024-01-20 10:30:00"
}
配额检查
文件位置: api/services/async_workflow_service.py:134-146
# 7. Check and consume quota
try:
QuotaType.WORKFLOW.consume(trigger_data.tenant_id)
except QuotaExceededError as e:
# Update trigger log status
trigger_log.status = WorkflowTriggerStatus.RATE_LIMITED
trigger_log.error = f"Quota limit reached: {e}"
trigger_log_repo.update(trigger_log)
session.commit()
raise WorkflowQuotaLimitError(
f"Workflow execution quota limit reached for tenant {trigger_data.tenant_id}"
) from e
配额机制:
- 专业版:1000 次/天
- 团队版:500 次/天
- 免费版:50 次/天
示例:
# Charlie(免费版)已执行 50 次,再次触发会失败
try:
QuotaType.WORKFLOW.consume("tenant_charlie_456")
except QuotaExceededError:
# 更新状态为 RATE_LIMITED
# 抛出 WorkflowQuotaLimitError
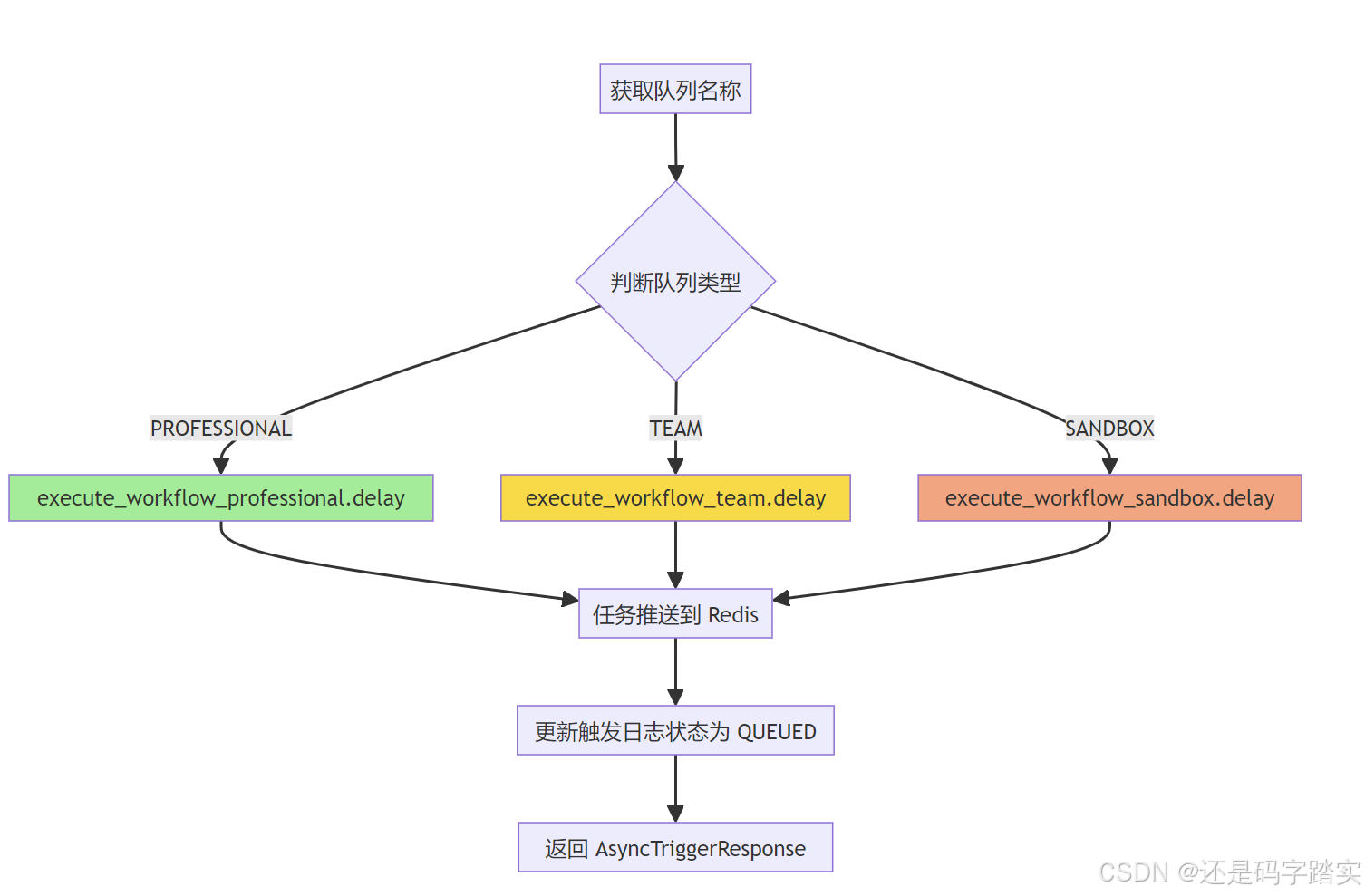
分发到对应队列
文件位置: api/services/async_workflow_service.py:148-176
# 8. Create task data
queue_name = dispatcher.get_queue_name()
task_data = WorkflowTaskData(workflow_trigger_log_id=trigger_log.id)
# 9. Dispatch to appropriate queue
task_data_dict = task_data.model_dump(mode="json")
task: AsyncResult[Any] | None = None
# 🔸 根据队列名称选择对应的 Celery 任务
if queue_name == QueuePriority.PROFESSIONAL:
task = execute_workflow_professional.delay(task_data_dict) # type: ignore
elif queue_name == QueuePriority.TEAM:
task = execute_workflow_team.delay(task_data_dict) # type: ignore
else: # SANDBOX
task = execute_workflow_sandbox.delay(task_data_dict) # type: ignore
# 10. Update trigger log with task info
trigger_log.status = WorkflowTriggerStatus.QUEUED
trigger_log.celery_task_id = task.id
trigger_log.triggered_at = datetime.now(UTC)
trigger_log_repo.update(trigger_log)
session.commit()
return AsyncTriggerResponse(
workflow_trigger_log_id=trigger_log.id,
task_id=task.id, # type: ignore
status="queued",
queue=queue_name,
)
任务分发逻辑流程图:
示例执行:
# Alice(专业版)
queue_name = "workflow_professional"
task_data_dict = {"workflow_trigger_log_id": "log_abc123"}
# 执行分支 1
task = execute_workflow_professional.delay(task_data_dict)
# Celery 内部操作:
# Redis LPUSH workflow_professional '{"workflow_trigger_log_id": "log_abc123"}'
# task.id = "celery_task_xyz789"
# 更新日志
trigger_log.status = WorkflowTriggerStatus.QUEUED
trigger_log.celery_task_id = "celery_task_xyz789"
# 返回响应
return AsyncTriggerResponse(
workflow_trigger_log_id="log_abc123",
task_id="celery_task_xyz789",
status="queued",
queue="workflow_professional"
)
Celery 任务定义
文件位置: api/tasks/async_workflow_tasks.py:35-80
专业版任务
@shared_task(queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE)
def execute_workflow_professional(task_data_dict: dict[str, Any]):
"""Execute workflow for professional tier with highest priority"""
task_data = WorkflowTaskData.model_validate(task_data_dict)
cfs_plan_scheduler_entity = AsyncWorkflowCFSPlanEntity(
queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE,
schedule_strategy=AsyncWorkflowSystemStrategy,
granularity=dify_config.ASYNC_WORKFLOW_SCHEDULER_GRANULARITY,
)
_execute_workflow_common(
task_data,
AsyncWorkflowCFSPlanScheduler(plan=cfs_plan_scheduler_entity),
cfs_plan_scheduler_entity,
)
团队版任务
@shared_task(queue=AsyncWorkflowQueue.TEAM_QUEUE)
def execute_workflow_team(task_data_dict: dict[str, Any]):
"""Execute workflow for team tier"""
task_data = WorkflowTaskData.model_validate(task_data_dict)
cfs_plan_scheduler_entity = AsyncWorkflowCFSPlanEntity(
queue=AsyncWorkflowQueue.TEAM_QUEUE,
schedule_strategy=AsyncWorkflowSystemStrategy,
granularity=dify_config.ASYNC_WORKFLOW_SCHEDULER_GRANULARITY,
)
_execute_workflow_common(
task_data,
AsyncWorkflowCFSPlanScheduler(plan=cfs_plan_scheduler_entity),
cfs_plan_scheduler_entity,
)
免费版任务
@shared_task(queue=AsyncWorkflowQueue.SANDBOX_QUEUE)
def execute_workflow_sandbox(task_data_dict: dict[str, Any]):
"""Execute workflow for free tier with lower retry limit"""
task_data = WorkflowTaskData.model_validate(task_data_dict)
cfs_plan_scheduler_entity = AsyncWorkflowCFSPlanEntity(
queue=AsyncWorkflowQueue.SANDBOX_QUEUE,
schedule_strategy=AsyncWorkflowSystemStrategy,
granularity=dify_config.ASYNC_WORKFLOW_SCHEDULER_GRANULARITY,
)
_execute_workflow_common(
task_data,
AsyncWorkflowCFSPlanScheduler(plan=cfs_plan_scheduler_entity),
cfs_plan_scheduler_entity,
)
任务装饰器解读:
@shared_task(queue=AsyncWorkflowQueue.PROFESSIONAL_QUEUE)
# ↑
# 指定任务推送到哪个队列
队列名称映射:
# Determine queue names based on edition
if dify_config.EDITION == "CLOUD":
# Cloud edition: separate queues for different tiers
_professional_queue = "workflow_professional"
_team_queue = "workflow_team"
_sandbox_queue = "workflow_sandbox"
AsyncWorkflowSystemStrategy = WorkflowScheduleCFSPlanEntity.Strategy.TimeSlice
else:
# Community edition: single workflow queue (not dataset)
_professional_queue = "workflow"
_team_queue = "workflow"
_sandbox_queue = "workflow"
AsyncWorkflowSystemStrategy = WorkflowScheduleCFSPlanEntity.Strategy.Nop
class AsyncWorkflowQueue(StrEnum):
# Define constants
PROFESSIONAL_QUEUE = _professional_queue
TEAM_QUEUE = _team_queue
SANDBOX_QUEUE = _sandbox_queue
云版 vs 社区版差异:
| 版本 | 专业版队列 | 团队版队列 | 免费版队列 | 调度策略 |
|---|---|---|---|---|
| CLOUD | <font style="color:#DF2A3F;">workflow_professional</font> |
workflow_team |
workflow_sandbox |
TimeSlice |
| 社区版 | <font style="color:#DF2A3F;">workflow</font> |
workflow |
workflow |
Nop |
Worker 拉取与执行
Celery Worker 启动配置:
# 专业版 Worker(8个进程,高优先级)
celery -A celery worker \
-Q workflow_professional \
-c 8 \
--prefetch-multiplier 1 \
--max-tasks-per-child 1000 \
--loglevel INFO
# 团队版 Worker(4个进程)
celery -A celery worker \
-Q workflow_team \
-c 4 \
--prefetch-multiplier 2 \
--max-tasks-per-child 500
# 免费版 Worker(2个进程,低优先级)
celery -A celery worker \
-Q workflow_sandbox \
-c 2 \
--prefetch-multiplier 4 \
--max-tasks-per-child 100
Worker 拉取流程:
任务执行核心逻辑
文件位置: api/tasks/async_workflow_tasks.py:94-177
def _execute_workflow_common(
task_data: WorkflowTaskData,
cfs_plan_scheduler: AsyncWorkflowCFSPlanScheduler,
cfs_plan_scheduler_entity: AsyncWorkflowCFSPlanEntity,
):
"""Execute workflow with common logic and trigger log updates."""
# 🔸 ⭐⭐⭐Step 10.1: 创建独立的数据库会话
# Create a new session for this task
session_factory = sessionmaker(bind=db.engine, expire_on_commit=False)
with session_factory() as session:
trigger_log_repo = SQLAlchemyWorkflowTriggerLogRepository(session)
# 🔸 Step 10.2: 获取触发日志
# Get trigger log
trigger_log = trigger_log_repo.get_by_id(task_data.workflow_trigger_log_id)
if not trigger_log:
# This should not happen, but handle gracefully
return
# 🔸 Step 10.3: 重建执行数据
# Reconstruct execution data from trigger log
trigger_data = TriggerData.model_validate_json(trigger_log.trigger_data)
# 🔸 Step 10.4: 更新状态为 RUNNING
# Update status to running
trigger_log.status = WorkflowTriggerStatus.RUNNING
trigger_log_repo.update(trigger_log)
session.commit()
start_time = datetime.now(UTC)
try:
# 🔸 Step 10.5: 获取应用和工作流模型
# Get app and workflow models
app_model = session.scalar(select(App).where(App.id == trigger_log.app_id))
if not app_model:
raise WorkflowNotFoundError(f"App not found: {trigger_log.app_id}")
workflow = session.scalar(select(Workflow).where(Workflow.id == trigger_log.workflow_id))
if not workflow:
raise WorkflowNotFoundError(f"Workflow not found: {trigger_log.workflow_id}")
user = _get_user(session, trigger_log)
# 🔸 ⭐⭐⭐⭐⭐Step 10.6: 执行工作流
# Execute workflow using WorkflowAppGenerator
generator = WorkflowAppGenerator()
# Prepare args matching AppGenerateService.generate format
args = _build_generator_args(trigger_data)
# If workflow_id was specified, add it to args
if trigger_data.workflow_id:
args["workflow_id"] = str(trigger_data.workflow_id)
# Execute the workflow with the trigger type
generator.generate(
app_model=app_model,
workflow=workflow,
user=user,
args=args,
invoke_from=InvokeFrom.SERVICE_API,
streaming=False,
call_depth=0,
triggered_from=trigger_data.trigger_from,
root_node_id=trigger_data.root_node_id,
graph_engine_layers=[
# TODO: Re-enable TimeSliceLayer after the HITL release.
TriggerPostLayer(cfs_plan_scheduler_entity, start_time, trigger_log.id, session_factory),
],
)
except Exception as e:
# 🔸 Step 10.7: 异常处理
# Calculate elapsed time for failed execution
elapsed_time = (datetime.now(UTC) - start_time).total_seconds()
# Update trigger log with failure
trigger_log.status = WorkflowTriggerStatus.FAILED
trigger_log.error = str(e)
trigger_log.finished_at = datetime.now(UTC)
trigger_log.elapsed_time = elapsed_time
trigger_log_repo.update(trigger_log)
# Final failure - no retry logic (simplified like RAG tasks)
session.commit()
关键步骤注释解读:
- 独立会话:每个任务使用独立的数据库会话,避免事务冲突
- 状态追踪:PENDING → RUNNING → SUCCESS/FAILED
- 异常处理:捕获所有异常并记录到日志,不阻塞队列
- 工作流执行:调用
<font style="color:#DF2A3F;">WorkflowAppGenerator.generate()</font>真正执行业务逻辑
完整时序图 - 三个用户并发场景
实际场景对比
场景 1:高峰期负载
假设:同时有 100 个请求
- 50 个专业版用户
- 30 个团队版用户
- 20 个免费版用户
传统单队列模式:
所有任务混在一起 → 100个任务排队
免费用户的大任务阻塞付费用户 → 付费用户体验差
多队列分离模式:
workflow_professional: 50个任务 → 8个Worker并发处理 → 平均响应 6.25秒
workflow_team: 30个任务 → 4个Worker并发处理 → 平均响应 7.5秒
workflow_sandbox: 20个任务 → 2个Worker并发处理 → 平均响应 10秒
✅ 付费用户不受免费用户影响
场景 2:免费用户滥用
攻击:免费用户发起 1000 个并发请求
单队列模式后果:
所有用户的任务都被阻塞 → 系统瘫痪
多队列模式防护:
workflow_sandbox 队列积压 1000 个任务
workflow_professional 和 workflow_team 队列正常运行
免费用户自己等待,不影响付费用户 ✅
监控与调优
关键监控指标
# 队列长度监控
redis-cli LLEN workflow_professional # 应 < 100
redis-cli LLEN workflow_team # 应 < 200
redis-cli LLEN workflow_sandbox # 可 > 1000
# Worker 状态监控
celery -A celery inspect active
celery -A celery inspect stats
# 任务执行速度
SELECT
queue_name,
AVG(elapsed_time) as avg_time,
COUNT(*) as total_tasks
FROM workflow_trigger_log
WHERE created_at > NOW() - INTERVAL '1 hour'
GROUP BY queue_name;
动态扩缩容策略
# Kubernetes HPA 配置
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: celery-worker-professional
spec:
scaleTargetRef:
name: celery-worker-professional
minReplicas: 8
maxReplicas: 50
metrics:
- type: External
external:
metric:
name: redis_queue_length
selector:
matchLabels:
queue: workflow_professional
target:
type: AverageValue
averageValue: "20" # 队列长度>20自动扩容
总结:轻重任务分离的核心价值
架构优势
- 服务质量保障(QoS)
- 付费用户享受独立资源池
- 响应速度可预测
- 资源隔离
- 免费用户无法消耗付费用户资源
- 单个租户故障不影响其他租户
- 弹性扩展
- 可针对不同队列独立扩容
- 按需分配计算资源
- 成本优化
- 高价值用户获得优先级
- 低价值用户使用共享资源
关键实现要点
- 订阅计划查询 →
BillingService.get_info() - 分发器模式 →
QueueDispatcherManager - 多队列路由 →
@shared_task(queue=...) - Worker 分组 →
celery -Q workflow_professional
数据库连接池管理
整体架构流程图
应用启动 - 连接池初始化
入口:app.py 启动
# api/app.py
from app_factory import create_app
app = create_app()
celery = app.extensions["celery"]
应用工厂创建
文件位置:api/app_factory.py
def create_app() -> DifyApp:
start_time = time.perf_counter()
app = create_flask_app_with_configs()
initialize_extensions(app)
end_time = time.perf_counter()
if dify_config.DEBUG:
logger.info("Finished create_app (%s ms)", round((end_time - start_time) * 1000, 2))
return app
关键步骤注释:
create_flask_app_with_configs():创建 Flask 应用并加载配置<font style="color:#DF2A3F;">initialize_extensions(app)</font>:核心! 初始化所有扩展,包括数据库
扩展初始化顺序
文件位置:api/app_factory.py
def initialize_extensions(app: DifyApp):
from extensions import (
ext_app_metrics,
ext_blueprints,
ext_celery,
ext_code_based_extension,
ext_commands,
ext_compress,
ext_database,
ext_forward_refs,
ext_hosting_provider,
ext_import_modules,
ext_logging,
ext_login,
ext_logstore,
ext_mail,
ext_migrate,
ext_orjson,
ext_otel,
ext_proxy_fix,
ext_redis,
ext_request_logging,
ext_sentry,
ext_session_factory,
ext_set_secretkey,
ext_storage,
ext_timezone,
ext_warnings,
)
extensions = [
ext_timezone,
ext_logging,
ext_warnings,
ext_import_modules,
ext_orjson,
ext_forward_refs,
ext_set_secretkey,
ext_compress,
ext_code_based_extension,
ext_database,
ext_app_metrics,
ext_migrate,
ext_redis,
ext_storage,
ext_logstore, # Initialize logstore after storage, before celery
ext_celery,
ext_login,
ext_mail,
ext_hosting_provider,
ext_sentry,
ext_proxy_fix,
ext_blueprints,
ext_commands,
ext_otel,
ext_request_logging,
ext_session_factory,
]
for ext in extensions:
short_name = ext.__name__.split(".")[-1]
is_enabled = ext.is_enabled() if hasattr(ext, "is_enabled") else True
if not is_enabled:
if dify_config.DEBUG:
logger.info("Skipped %s", short_name)
continue
start_time = time.perf_counter()
ext.init_app(app)
end_time = time.perf_counter()
if dify_config.DEBUG:
logger.info("Loaded %s (%s ms)", short_name, round((end_time - start_time) * 1000, 2))
关键注释:
- ext_database:第10个加载,初始化连接池
- ext_session_factory:最后加载,配置会话工厂
数据库扩展初始化
文件位置:api/extensions/ext_database.py
def init_app(app: DifyApp):
db.init_app(app)
_setup_gevent_compatibility()
# Eagerly build the engine so pool_size/max_overflow/etc. come from config
try:
with app.app_context():
_ = db.engine # triggers engine creation with the configured options
except Exception:
logger.exception("Failed to initialize SQLAlchemy engine during app startup")
关键步骤解析:
- db.init_app(app):
<font style="color:#DF2A3F;">db</font>是<font style="color:#DF2A3F;">Flask-SQLAlchemy</font>实例(定义在<font style="color:#DF2A3F;">models/engine.py</font>)- 从
app.config读取数据库配置 - 创建 SQLAlchemy Engine 和连接池
- _setup_gevent_compatibility():
- 处理 Gevent 协程环境下的连接安全回滚
- 防止连接泄漏
- _ = db.engine:
- 关键! 立即触发 Engine 创建
- 确保连接池参数生效
连接池配置参数
文件位置:api/configs/middleware/__init__.py
SQLALCHEMY_POOL_SIZE: NonNegativeInt = Field(
description="Maximum number of database connections in the pool.",
default=30,
)
SQLALCHEMY_MAX_OVERFLOW: NonNegativeInt = Field(
description="Maximum number of connections that can be created beyond the pool_size.",
default=10,
)
SQLALCHEMY_POOL_RECYCLE: NonNegativeInt = Field(
description="Number of seconds after which a connection is automatically recycled.",
default=3600,
)
SQLALCHEMY_POOL_USE_LIFO: bool = Field(
description="If True, SQLAlchemy will use last-in-first-out way to retrieve connections from pool.",
default=False,
)
SQLALCHEMY_POOL_PRE_PING: bool = Field(
description="If True, enables connection pool pre-ping feature to check connections.",
default=False,
)
SQLALCHEMY_ECHO: bool | str = Field(
description="If True, SQLAlchemy will log all SQL statements.",
default=False,
)
SQLALCHEMY_POOL_TIMEOUT: NonNegativeInt = Field(
description="Number of seconds to wait for a connection from the pool before raising a timeout error.",
default=30,
)
RETRIEVAL_SERVICE_EXECUTORS: NonNegativeInt = Field(
description="Number of processes for the retrieval service, default to CPU cores.",
default=os.cpu_count() or 1,
)
@computed_field # type: ignore[prop-decorator]
@property
def SQLALCHEMY_ENGINE_OPTIONS(self) -> dict[str, Any]:
# Parse DB_EXTRAS for 'options'
db_extras_dict = dict(parse_qsl(self.DB_EXTRAS))
options = db_extras_dict.get("options", "")
connect_args = {}
# Use the dynamic SQLALCHEMY_DATABASE_URI_SCHEME property
if self.SQLALCHEMY_DATABASE_URI_SCHEME.startswith("postgresql"):
timezone_opt = "-c timezone=UTC"
if options:
merged_options = f"{options} {timezone_opt}"
else:
merged_options = timezone_opt
connect_args = {"options": merged_options}
return {
"pool_size": self.SQLALCHEMY_POOL_SIZE,
"max_overflow": self.SQLALCHEMY_MAX_OVERFLOW,
"pool_recycle": self.SQLALCHEMY_POOL_RECYCLE,
"pool_pre_ping": self.SQLALCHEMY_POOL_PRE_PING,
"connect_args": connect_args,
"pool_use_lifo": self.SQLALCHEMY_POOL_USE_LIFO,
"pool_reset_on_return": None,
"pool_timeout": self.SQLALCHEMY_POOL_TIMEOUT,
}
配置参数可视化:
┌─────────────────────────────────────────┐
│ 数据库连接池配置 │
├─────────────────────────────────────────┤
│ pool_size: 30 │ 核心连接数(常驻)
│ max_overflow: 10 │ 溢出连接数(临时)
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 总连接数 = 30 + 10 = 40 │
│ │
│ pool_recycle: 3600秒 (1小时) │ 连接回收时间
│ pool_timeout: 30秒 │ 等待连接超时
│ pool_pre_ping: False │ 使用前不检测连接
│ pool_use_lifo: False (FIFO模式) │ 先进先出
└─────────────────────────────────────────┘
Session Factory 配置
文件位置:api/extensions/ext_session_factory.py
from core.db.session_factory import configure_session_factory
from extensions.ext_database import db
def init_app(app):
with app.app_context():
configure_session_factory(db.engine)
文件位置:api/core/db/session_factory.py
from sqlalchemy import Engine
from sqlalchemy.orm import Session, sessionmaker
_session_maker: sessionmaker[Session] | None = None
def configure_session_factory(engine: Engine, expire_on_commit: bool = False):
"""Configure the global session factory"""
global _session_maker
_session_maker = sessionmaker(bind=engine, expire_on_commit=expire_on_commit)
def get_session_maker() -> sessionmaker[Session]:
if _session_maker is None:
raise RuntimeError("Session factory not configured. Call configure_session_factory() first.")
return _session_maker
def create_session() -> Session:
return get_session_maker()()
# Class wrapper for convenience
class SessionFactory:
@staticmethod
def configure(engine: Engine, expire_on_commit: bool = False):
configure_session_factory(engine, expire_on_commit)
@staticmethod
def get_session_maker() -> sessionmaker[Session]:
return get_session_maker()
@staticmethod
def create_session() -> Session:
return create_session()
session_factory = SessionFactory()
关键注释:
<font style="color:#DF2A3F;">_session_maker</font>:全局单例 sessionmakerexpire_on_commit=False:提交后对象不过期,减少数据库查询bind=engine:绑定到连接池 Engine
API 请求 - 连接获取与使用
完整的 HTTP 请求处理时序图
Controller 层使用 db.session
文件位置:api/controllers/console/app/app.py
# 典型的 Controller 代码片段
from extensions.ext_database import db
from models import App
class AppApi(Resource):
@login_required
@account_initialization_required
def post(self):
# 🔍 Step 1: 解析请求参数
args = request.get_json()
# 🔍 Step 2: 调用 Service 层
app = AppService.create_app(
tenant_id=current_account_with_tenant.current_tenant.id,
args=args,
account=current_account_with_tenant
)
# 🔍 Step 3: Service 内部使用 db.session
# 实际代码在 Service 层:
# app_model = App(...)
# db.session.add(app_model)
# db.session.commit()
return app.to_dict(), 201
db.session 是什么:
# db.session 是 Flask-SQLAlchemy 提供的 scoped_session
# 实际定义:
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy() # 在 models/engine.py
# db.session 的内部实现(简化):
# db.session = scoped_session(
# sessionmaker(bind=engine),
# scopefunc=_app_ctx_stack.__ident_func__
# )
scoped_session 工作原理:
┌────────────────────────────────────────────┐
│ scoped_session │
├────────────────────────────────────────────┤
│ │
│ 线程/请求上下文 A → Session A │
│ 线程/请求上下文 B → Session B │
│ 线程/请求上下文 C → Session C │
│ │
│ 同一请求内多次调用 db.session │
│ 返回同一个 Session 对象 │
│ │
│ 请求结束后自动调用 session.remove() │
│ 归还连接到连接池 │
└────────────────────────────────────────────┘
连接从池中获取的详细过程
连接池内部状态(QueuePool):
# SQLAlchemy QueuePool 内部结构(简化)
class QueuePool:
def __init__(self, pool_size=30, max_overflow=10):
self._pool = Queue() # 可用连接队列
self._overflow = 0 # 当前溢出连接数
self._checked_out = set() # 已借出的连接
# 初始化时创建 pool_size 个连接
for _ in range(pool_size):
conn = self._create_connection()
self._pool.put(conn)
def get_connection(self, timeout=30):
"""
获取连接的逻辑
"""
# 🔍 Step 1: 尝试从队列获取空闲连接
try:
conn = self._pool.get(block=False)
self._checked_out.add(conn)
return conn
except Empty:
pass
# 🔍 Step 2: 队列为空,检查是否可以创建溢出连接
if self._overflow < self.max_overflow:
conn = self._create_connection()
self._overflow += 1
self._checked_out.add(conn)
return conn
# 🔍 Step 3: 达到上限,等待其他连接归还
try:
conn = self._pool.get(timeout=timeout)
self._checked_out.add(conn)
return conn
except Empty:
raise TimeoutError("Pool exhausted")
def return_connection(self, conn):
"""
归还连接
"""
self._checked_out.remove(conn)
# 检查连接是否需要回收(超过 pool_recycle 时间)
if self._should_recycle(conn):
conn.close()
conn = self._create_connection()
# 归还到队列
self._pool.put(conn)
可视化连接获取流程:
请求1到达
↓
从池获取连接
↓
┌─────────────────────────────────────┐
│ 连接池状态 │
│ ┌───┬───┬───┬───┬───┬───┬───┐ │
│ │ 1 │ 2 │ 3 │ 4 │ 5 │...│30 │ │ 空闲连接
│ └─┬─┴───┴───┴───┴───┴───┴───┘ │
│ │ │
│ └──> 借出给请求1 │
│ │
│ 已借出: [conn1] │
│ 空闲: 29个 │
└─────────────────────────────────────┘
请求2-30到达(同时)
↓
全部从池获取连接
↓
┌─────────────────────────────────────┐
│ 已借出: [conn1...conn30] │
│ 空闲: 0个 │
└─────────────────────────────────────┘
请求31到达
↓
池已空,创建溢出连接
↓
┌─────────────────────────────────────┐
│ 已借出: [conn1...conn30, conn31] │
│ 空闲: 0个 │
│ 溢出: 1个 (最多10个) │
└─────────────────────────────────────┘
请求41到达
↓
达到上限40(30+10),等待30秒
↓
超时抛出异常:TimeoutError
Celery 任务 - 独立 Session 管理
Celery Worker 使用 sessionmaker
文件位置:api/tasks/async_workflow_tasks.py
def _execute_workflow_common(
task_data: WorkflowTaskData,
cfs_plan_scheduler: AsyncWorkflowCFSPlanScheduler,
cfs_plan_scheduler_entity: AsyncWorkflowCFSPlanEntity,
):
"""Execute workflow with common logic and trigger log updates."""
# Create a new session for this task
session_factory = sessionmaker(bind=db.engine, expire_on_commit=False)
with session_factory() as session:
trigger_log_repo = SQLAlchemyWorkflowTriggerLogRepository(session)
# Get trigger log
trigger_log = trigger_log_repo.get_by_id(task_data.workflow_trigger_log_id)
if not trigger_log:
# This should not happen, but handle gracefully
return
# Reconstruct execution data from trigger log
trigger_data = TriggerData.model_validate_json(trigger_log.trigger_data)
# Update status to running
trigger_log.status = WorkflowTriggerStatus.RUNNING
trigger_log_repo.update(trigger_log)
session.commit()
关键步骤注释:
- session_factory = sessionmaker(…):
- 创建独立的 sessionmaker(不使用 Flask 的 scoped_session)
bind=db.engine:复用同一个连接池expire_on_commit=False:提交后对象不失效
- with session_factory() as session::
- 使用上下文管理器自动管理 Session
- 进入时:从连接池获取连接
- 退出时:自动调用
session.close(),归还连接
- session.commit():
- 提交事务
- 不会关闭连接(仍在 with 块内)
时序图 - Celery 任务的连接生命周期:
连接回收与健康检查
POOL_RECYCLE 自动回收机制
配置:
SQLALCHEMY_POOL_RECYCLE = 3600 # 1小时
工作原理:
# SQLAlchemy 内部逻辑(简化)
class QueuePool:
def get_connection(self):
conn = self._pool.get()
# 🔍 检查连接是否超过回收时间
if time.time() - conn.created_at > self.pool_recycle:
# 关闭旧连接
conn.close()
# 创建新连接
conn = self._create_connection()
return conn
为什么需要回收:
场景:MySQL wait_timeout=28800 (8小时)
时间轴:
00:00 创建连接 conn1
01:00 使用 conn1 查询
02:00 conn1 归还到池
...
10:00 再次使用 conn1
❌ 连接已被 MySQL 服务器关闭(超过8小时未活动)
❌ 抛出异常:MySQL server has gone away
解决方案:
POOL_RECYCLE = 3600 (1小时)
↓
每小时自动关闭并重建连接
↓
连接永远不会在池中超过1小时
↓
避免 MySQL timeout 问题
POOL_PRE_PING 健康检查
配置:
SQLALCHEMY_POOL_PRE_PING = False # 默认关闭
开启后的工作原理:
# 使用连接前先 ping
class QueuePool:
def get_connection(self):
conn = self._pool.get()
if self.pool_pre_ping:
# 🔍 发送 SELECT 1 测试连接
try:
conn.execute("SELECT 1")
except Exception:
# 连接已断开,创建新连接
conn.close()
conn = self._create_connection()
return conn
性能权衡:
开启 POOL_PRE_PING:
✅ 优点:每次使用前检测,避免使用断开的连接
❌ 缺点:每次获取连接都多一次 SELECT 1 查询,增加延迟
关闭 POOL_PRE_PING + 开启 POOL_RECYCLE:
✅ 优点:定期回收,无额外查询开销
⚠️ 注意:需要设置合理的回收时间
Gevent 协程兼容性处理
文件位置:api/extensions/ext_database.py
def _setup_gevent_compatibility():
global _gevent_compatibility_setup # pylint: disable=global-statement
# Avoid duplicate registration
if _gevent_compatibility_setup:
return
@event.listens_for(Pool, "reset")
def _safe_reset(dbapi_connection, connection_record, reset_state): # pyright: ignore[reportUnusedFunction]
if reset_state.terminate_only:
return
# Safe rollback for connection
try:
hub = gevent.get_hub()
if hasattr(hub, "loop") and getattr(hub.loop, "in_callback", False):
gevent.spawn_later(0, lambda: _safe_rollback(dbapi_connection))
else:
_safe_rollback(dbapi_connection)
except (AttributeError, ImportError):
_safe_rollback(dbapi_connection))
_gevent_compatibility_setup = True
为什么需要:事务状态混乱
Celery + Gevent 环境:
协程1: 开始事务 → 协程切换
协程2: 使用同一连接 → ❌ 事务状态混乱
↓
解决:监听 Pool.reset 事件
↓
在协程切换时安全回滚事务
↓
防止事务泄漏和状态污染
完整示例:从 HTTP 请求到数据库连接
# ========================================
# 示例 1:Flask API 处理流程
# ========================================
# Step 1: 客户端发起请求
# POST /v1/apps
# Body: {"name": "My App", "mode": "chat"}
# Step 2: Flask 路由处理
@api.route('/apps', methods=['POST'])
@login_required
def create_app():
# ── 进入请求上下文 ──
# before_request 钩子已执行:init_request_context()
args = request.get_json()
# Step 3: Service 层处理
app = AppService.create_app(
tenant_id=current_tenant.id,
args=args
)
return jsonify(app.to_dict()), 201
# ── 离开请求上下文 ──
# after_request 钩子执行:scoped_session.remove()
# 连接归还到池
# ========================================
# AppService.create_app 内部实现
# ========================================
class AppService:
@staticmethod
def create_app(tenant_id, args):
# 🔍 使用 db.session(scoped_session)
app_model = App(
tenant_id=tenant_id,
name=args['name'],
mode=args['mode']
)
# ── 第一次使用 db.session ──
# 触发连接获取:
# 1. scoped_session 检查当前请求上下文
# 2. 从连接池获取连接
# 3. 创建 Session 对象并绑定连接
db.session.add(app_model)
# ── 执行 SQL ──
# BEGIN TRANSACTION
# INSERT INTO app (tenant_id, name, mode) VALUES (...)
db.session.commit()
# COMMIT
# ── 连接仍然持有,等待请求结束 ──
return app_model
# ========================================
# 示例 2:Celery 任务处理流程
# ========================================
@shared_task(queue="workflow")
def execute_workflow_task(workflow_id, user_id):
# 🔍 创建独立的 sessionmaker
from extensions.ext_database import db
from sqlalchemy.orm import sessionmaker
session_factory = sessionmaker(bind=db.engine, expire_on_commit=False)
# ── 进入 with 块,获取连接 ──
with session_factory() as session:
# 从连接池获取连接
# 1. QueuePool.get_connection()
# 2. 检查池中是否有空闲连接
# 3. 如有:返回;如无且未达上限:创建;达上限:等待
# 执行业务逻辑
workflow = session.query(Workflow).get(workflow_id)
workflow.status = "running"
# ── 提交事务 ──
# BEGIN; UPDATE workflow SET status='running'; COMMIT;
session.commit()
# 继续执行工作流...
result = run_workflow(workflow)
workflow.status = "completed"
session.commit()
# ── 退出 with 块 ──
# __exit__ 自动调用 session.close()
# 连接归还到池:QueuePool.return_connection()
return result
# ========================================
# 连接池内部状态变化(可视化)
# ========================================
# 初始状态(应用启动后)
Pool: [conn1, conn2, ..., conn30] # 30个空闲连接
Checked out: []
Overflow: 0
# ── 请求1到达 ──
db.session.add(app_model)
# 获取 conn1
Pool: [conn2, ..., conn30]
Checked out: [conn1]
# ── 请求2-30同时到达 ──
# 获取 conn2-conn30
Pool: []
Checked out: [conn1, conn2, ..., conn30]
# ── 请求31到达 ──
# 创建溢出连接 conn31
Pool: []
Checked out: [conn1, ..., conn30, conn31]
Overflow: 1
# ── 请求1完成,after_request 执行 ──
scoped_session.remove()
# 归还 conn1
Pool: [conn1]
Checked out: [conn2, ..., conn30, conn31]
Overflow: 1
# ── 1小时后,conn1 被再次使用 ──
db.session.query(...)
# POOL_RECYCLE 检查
if (now - conn1.created_at) > 3600:
conn1.close() # 关闭旧连接
conn1 = create_new_connection() # 创建新连接
# 使用 conn1 执行查询
完整生命周期时序图总览
关键文件与函数总览
| 文件路径 | 关键函数/类 | 作用 |
|---|---|---|
api/app_factory.py |
create_app() |
应用入口,初始化所有扩展 |
api/app_factory.py |
initialize_extensions() |
按顺序加载扩展 |
api/extensions/ext_database.py |
init_app() |
初始化数据库连接池 |
api/extensions/ext_database.py |
_setup_gevent_compatibility() |
Gevent 兼容性处理 |
api/models/engine.py |
db = SQLAlchemy() |
Flask-SQLAlchemy 实例 |
api/configs/middleware/__init__.py |
SQLALCHEMY_ENGINE_OPTIONS |
连接池配置参数 |
api/extensions/ext_session_factory.py |
init_app() |
配置 sessionmaker |
api/core/db/session_factory.py |
configure_session_factory() |
全局 sessionmaker 配置 |
api/core/db/session_factory.py |
create_session() |
创建独立 Session |
api/tasks/async_workflow_tasks.py |
_execute_workflow_common() |
Celery 任务使用 sessionmaker |
最佳实践总结
✅ 推荐做法
- API 层使用 db.session:
# Flask-SQLAlchemy 自动管理生命周期
db.session.add(model)
db.session.commit()
# 请求结束后自动归还连接
- Celery 任务使用独立 sessionmaker:
session_factory = sessionmaker(bind=db.engine, expire_on_commit=False)
with session_factory() as session:
session.add(model)
session.commit()
# with 块结束自动关闭
- 设置合理的连接池参数:
SQLALCHEMY_POOL_SIZE = 30 # 根据并发量调整
SQLALCHEMY_MAX_OVERFLOW = 10 # 允许临时突增
SQLALCHEMY_POOL_RECYCLE = 3600 # 1小时回收
❌ 避免的坑
- 不要在 Celery 任务中使用 db.session:
# ❌ 错误:scoped_session 在非 Flask 上下文中行为不可预测
@shared_task
def my_task():
db.session.add(model) # 危险!
- 不要忘记归还连接:
# ❌ 错误:手动创建 Session 后不关闭
session = Session(bind=db.engine)
session.query(...)
# 忘记 session.close() → 连接泄漏
# ✅ 正确:使用 with 块
with Session(bind=db.engine) as session:
session.query(...)
# 自动关闭
- 不要设置过小的连接池:
# ❌ 错误:pool_size=5 无法应对100并发
# 会导致大量请求等待超时
# ✅ 正确:根据实际并发设置
# 经验公式:pool_size = 预期并发数 * 1.2
工程实战与故障应对 (Failure Mode Analysis)
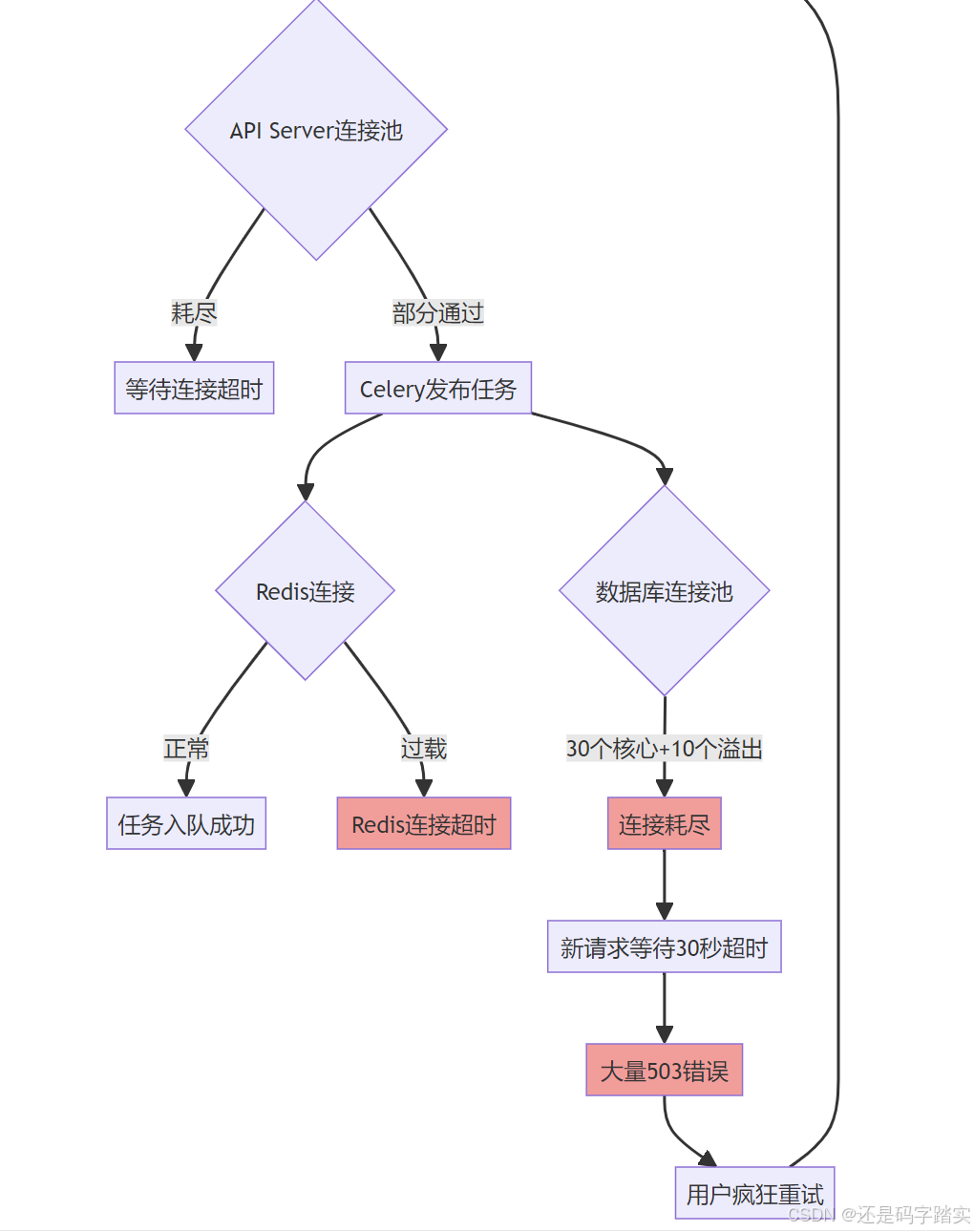
故障模拟 1:连接雪崩 (Connection Avalanche)
场景描述
凌晨 2 点,某大客户的自动化脚本突然发起 10,000 个并发请求:
for i in {1..10000}; do
curl -X POST "https://api.dify.ai/v1/workflows/run" &
done
雪崩链路
代码中的防护机制
1. 连接池超时保护
SQLALCHEMY_POOL_TIMEOUT: NonNegativeInt = Field(
description="Number of seconds to wait for a connection from the pool before raising a timeout error.",
default=30,
)
- 等待 30 秒后抛出
TimeoutError - 防止请求无限期阻塞
2. Celery 任务忽略结果
task_ignore_result=True,
- 不将结果存入 Redis,减轻压力
- 适用于"fire-and-forget"场景
3. 队列分流调度
# 专业版用户走快速队列
execute_workflow_professional.delay(task_data)
# 免费版用户走慢速队列
execute_workflow_sandbox.delay(task_data)
- 付费用户不受免费用户影响
- 核心服务可用性优先保障
缺失的防护(建议增强):
dify中未发现以下机制:
API 层限流:
# 建议在 API 入口添加
from flask_limiter import Limiter
limiter = Limiter(
app,
key_func=lambda: request.headers.get("Authorization"), # 按 API Key 限流
default_limits=["100 per minute", "1000 per hour"]
)
@app.route("/v1/workflows/run")
@limiter.limit("10 per second") # 单个 API Key 每秒最多10次
def run_workflow():
...
Celery Worker 动态扩缩容:
# Kubernetes HPA 配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: celery-worker
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: celery-worker
minReplicas: 3
maxReplicas: 20
metrics:
- type: External
external:
metric:
name: redis_queue_length
target:
type: AverageValue
averageValue: "100" # 队列长度超过100自动扩容
故障模拟 2:Redis 过载与脑裂
场景 A:Redis 内存满
# Redis 内存使用率 99.9%
127.0.0.1:6379> INFO memory
used_memory_human:15.99G
maxmemory:16.00G
影响:
- 新任务无法入队(
LPUSH失败) - Celery Broker 不可用
- 所有异步任务停滞
代码中的容错:
broker_connection_retry_on_startup=True,
- 启动时自动重连,但运行时连接断开会导致任务丢失
- 缺失:运行时重连机制
建议增强:
# 任务发布时捕获异常
try:
execute_workflow_professional.delay(task_data)
except Exception as e:
logger.error(f"Failed to publish task to Redis: {e}")
# 降级:直接同步执行或存入数据库待重试
fallback_execute_workflow(task_data)
场景 B:Redis Sentinel 脑裂
Master 与 Sentinel 网络分区:
┌─────────┐ ┌─────────┐
│ Master │ ✗ ✗ ✗│Sentinel │
│ Redis-1 │ │ Group │
└─────────┘ └─────────┘
│ │
✓ ✓
┌─────────┐ ┌─────────┐
│ Client │ │ Slave │
│ (Dify) │ │ Redis-2 │
└─────────┘ └─────────┘
后果:
- Sentinel 选举 Redis-2 为新 Master
- Client 仍连接旧 Master(Redis-1)
- 任务分散到两个 Master,状态不一致
代码中的保护:
if dify_config.CELERY_USE_SENTINEL:
broker_transport_options = {
"master_name": dify_config.CELERY_SENTINEL_MASTER_NAME,
"sentinel_kwargs": {
"socket_timeout": dify_config.CELERY_SENTINEL_SOCKET_TIMEOUT,
"password": dify_config.CELERY_SENTINEL_PASSWORD,
},
}
- Celery 会自动从 Sentinel 获取当前 Master
- 但不保证立即切换(可能有几秒延迟)
任务状态一致性校验:
with session_factory() as session:
trigger_log_repo = SQLAlchemyWorkflowTriggerLogRepository(session)
# Get trigger log
trigger_log = trigger_log_repo.get_by_id(task_data.workflow_trigger_log_id)
if not trigger_log:
# This should not happen, but handle gracefully
return
# Reconstruct execution data from trigger log
trigger_data = TriggerData.model_validate_json(trigger_log.trigger_data)
# Update status to running
trigger_log.status = WorkflowTriggerStatus.RUNNING
trigger_log_repo.update(trigger_log)
session.commit()
start_time = datetime.now(UTC)
try:
- 任务状态存储在数据库(而非 Redis),即使 Redis 脑裂,任务状态仍可靠
- 通过
trigger_log_id保证幂等性
异步 DoS 攻击 —— 虚假长任务耗尽资源
攻击手法
攻击者注册免费账号,上传恶意构造的文档:
# 攻击脚本
import requests
api_key = "免费账号的API Key"
headers = {"Authorization": f"Bearer {api_key}"}
# 上传 10GB 的垃圾PDF文件
files = {"file": open("10gb_junk.pdf", "rb")}
for i in range(1000):
requests.post(
"https://api.dify.ai/v1/datasets/upload",
headers=headers,
files=files
)
攻击效果:
- 触发 1000 个文档索引任务
- 每个任务耗时 1 小时+
- 占满
dataset队列 - 正常用户无法索引文档
代码中的防御机制
批量上传限制
# check document limit
features = FeatureService.get_features(dataset.tenant_id)
try:
if features.billing.enabled:
vector_space = features.vector_space
count = len(document_ids)
batch_upload_limit = int(dify_config.BATCH_UPLOAD_LIMIT)
if features.billing.subscription.plan == CloudPlan.SANDBOX and count > 1:
raise ValueError("Your current plan does not support batch upload, please upgrade your plan.")
if count > batch_upload_limit:
raise ValueError(f"You have reached the batch upload limit of {batch_upload_limit}.")
if 0 < vector_space.limit <= vector_space.size:
raise ValueError(
"Your total number of documents plus the number of uploads have over the limit of "
"your subscription."
)
except Exception as e:
for document_id in document_ids:
document = (
db.session.query(Document).where(Document.id == document_id, Document.dataset_id == dataset_id).first()
)
if document:
document.indexing_status = "error"
document.error = str(e)
document.stopped_at = naive_utc_now()
db.session.add(document)
db.session.commit()
db.session.close()
return
防御要点:
- 免费版禁止批量上传:
count > 1直接拒绝 - 批量上传上限:付费版也有
BATCH_UPLOAD_LIMIT - 向量空间配额:超过
vector_space.limit拒绝
租户隔离并发控制
tenant_isolated_task_queue = TenantIsolatedTaskQueue(tenant_id, "document_indexing")
# Check if there are waiting tasks in the queue
# Use rpop to get the next task from the queue (FIFO order)
next_tasks = tenant_isolated_task_queue.pull_tasks(count=dify_config.TENANT_ISOLATED_TASK_CONCURRENCY)
logger.info("document indexing tenant isolation queue %s next tasks: %s", tenant_id, next_tasks)
if next_tasks:
for next_task in next_tasks:
document_task = DocumentTask(**next_task)
# Process the next waiting task
# Keep the flag set to indicate a task is running
tenant_isolated_task_queue.set_task_waiting_time()
task_func.delay( # type: ignore
tenant_id=document_task.tenant_id,
dataset_id=document_task.dataset_id,
document_ids=document_task.document_ids,
)
else:
# No more waiting tasks, clear the flag
tenant_isolated_task_queue.delete_task_key()
防御要点:
- 单个租户最多同时执行
<font style="color:#DF2A3F;">TENANT_ISOLATED_TASK_CONCURRENCY</font>个任务 - 恶意租户只能占用自己的并发槽位
- 不影响其他租户
优先级队列分离
@shared_task(queue="priority_dataset")
def priority_document_indexing_task(tenant_id: str, dataset_id: str, document_ids: Sequence[str]):
- 付费用户走
priority_dataset队列 - 免费用户攻击只影响
dataset队列 - 付费用户不受影响
缺失的防护(建议增强):
dify 代码中未发现以下机制:
任务执行时长限制:
@shared_task(
queue="dataset",
time_limit=3600, # 任务最多执行1小时
soft_time_limit=3300 # 55分钟时发送警告信号
)
def document_indexing_task(...):
...
恶意文件检测:
# 在任务开始前检测文件
def validate_document(file_path):
# 检查文件大小
if os.path.getsize(file_path) > 100 * 1024 * 1024: # 100MB
raise ValueError("File too large")
# 检查PDF页数
import PyPDF2
with open(file_path, 'rb') as f:
pdf = PyPDF2.PdfReader(f)
if len(pdf.pages) > 1000:
raise ValueError("Too many pages")
4.2 防御机制总结
| 攻击类型 | 防御机制 | 代码位置 |
|---|---|---|
| 批量上传 DoS | 免费版禁止批量、配额限制 | document_indexing_task.py:61 |
| 单租户霸占 | 租户隔离队列 | queue.py:25 |
| 付费用户被拖累 | 多队列分离 | entities.py:7 |
| 数据库连接耗尽 | 连接池大小限制 | middleware/__init__.py:168 |
| Redis 过载 | task_ignore_result=True |
ext_celery.py:82 |
标准化回答话术(300字以内)
如何优化一个大模型应用平台的系统吞吐量并防止连接雪崩?
从任务调度、连接管理、队列分流和安全防护四个维度设计高并发架构:
** Celery + Redis 异步架构解耦**
首先采用 Celery + Redis 实现请求响应与任务执行的解耦:
- 同步场景:用户请求 → API 直接调用 LLM → 阻塞 30 秒 → QPS 仅 1.3
- 异步优化:用户请求 → API 推送到 Redis 队列 → 立即返回任务 ID → Celery Worker 异步执行 → QPS 提升至 1000+
关键配置:
celery_app.conf.update(
broker=redis_url,
task_ignore_result=True, # 不存结果,减轻 Redis 压力
broker_connection_retry_on_startup=True # 自动重连
)
为什么仅增加 CPU 不够:
- 瓶颈在 I/O 等待(LLM API、数据库查询),不是 CPU 计算
- 需要优化任务流转效率:
- 使用连接池复用数据库连接
- 批量操作减少 Redis 往返
- 合理设置 Worker 并发数(基于 I/O 密集型调优)
** PgBouncer 连接池优化防止雪崩**
问题场景:10,000 并发请求瞬间涌入,应用需要 10,000 个数据库连接,但 PostgreSQL 默认最大连接数仅 100,导致连接耗尽。
解决方案 - 两层连接池:
应用层(SQLAlchemy):
SQLALCHEMY_POOL_SIZE = 30 # 核心连接数
SQLALCHEMY_MAX_OVERFLOW = 10 # 临时连接数(总计40)
SQLALCHEMY_POOL_RECYCLE = 3600 # 1小时回收,防止 MySQL wait_timeout
SQLALCHEMY_POOL_TIMEOUT = 30 # 等待连接超时
中间层(PgBouncer):
[databases]
dify = host=postgres port=5432 dbname=dify
[pgbouncer]
pool_mode = transaction # 事务级池化,利用率最高
max_client_conn = 10000 # 接受应用的10000个连接
default_pool_size = 20 # 但只给 PostgreSQL 建立20个真实连接
reserve_pool_size = 5 # 紧急备用连接
工作原理:
- 应用 40 个连接 → PgBouncer 映射到 20 个真实连接
- 事务结束后立即归还连接,避免长时间占用
- 防止连接雪崩:即使应用请求 10,000 连接,数据库只承受 20 个
监控指标:
-- 监控 PgBouncer 等待队列
SHOW POOLS;
-- 若 waiting_clients > 100,说明连接池过小,需扩容
轻重任务队列分离策略
单队列问题:免费用户上传 1GB 文档索引(耗时 1 小时),阻塞付费用户的 100KB 文档(耗时 10 秒)。
多队列架构:
# 按租户等级分流
if user.plan == "professional":
execute_workflow_professional.delay(task) # workflow_professional 队列
elif user.plan == "team":
execute_workflow_team.delay(task) # workflow_team 队列
else:
execute_workflow_sandbox.delay(task) # workflow_sandbox 队列
# 按任务类型分流
if task_type == "quick_query":
quick_task.delay() # 快速队列,秒级响应
elif task_type == "document_indexing":
indexing_task.delay() # dataset 队列,分钟级
Worker 部署策略:
# 专业版队列:8 个 Worker,高优先级
celery -A celery worker -Q workflow_professional -c 8 --prefetch-multiplier 1
# 团队版队列:4 个 Worker
celery -A celery worker -Q workflow_team -c 4
# 免费版队列:2 个 Worker,低优先级
celery -A celery worker -Q workflow_sandbox -c 2 --max-tasks-per-child 100
租户隔离队列(防止单租户霸占):
class TenantIsolatedTaskQueue:
# 每个租户独立队列
queue_key = f"tenant_tasks:{tenant_id}"
# 并发控制
max_concurrent_tasks = 3 # 单租户最多3个任务同时执行
异步 DoS 防御思路
攻击场景:恶意用户发送 1000 个"上传 1GB 文档"请求,耗尽队列资源。
入口限流:
# API 层限流(基于 API Key)
@limiter.limit("10 requests per second")
@limiter.limit("100 requests per hour")
def upload_document():
...
配额校验:
# 免费版禁止批量上传
if user.plan == "sandbox" and len(documents) > 1:
raise PermissionError("Upgrade to batch upload")
# 向量空间配额
if used_vectors >= vector_quota:
raise QuotaExceededError()
任务超时保护:
@shared_task(
time_limit=3600, # 硬超时:1小时
soft_time_limit=3300 # 软超时:55分钟发警告
)
def long_running_task():
...
恶意文件检测:
# 任务执行前验证
def validate_file(file_path):
size = os.path.getsize(file_path)
if size > 100 * 1024 * 1024: # 100MB
raise ValueError("File too large")
监控告警:
# 队列长度超过阈值告警
if redis.llen("workflow_sandbox") > 1000:
alert_ops_team("Queue backlog detected")
进一步优化:性能监控与调优
关键指标:
# 队列积压
redis.llen("workflow_professional") # < 100 正常,> 1000 需扩容
# 连接池使用率
pool.checkedout / (pool.size + pool.overflow) # < 80% 正常
# Worker 任务处理速度
celery inspect stats # tasks_per_second
# 数据库慢查询
SELECT * FROM pg_stat_statements WHERE mean_exec_time > 1000;
自动扩缩容(Kubernetes HPA):
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: celery-worker-pro
spec:
scaleTargetRef:
name: celery-worker-pro
minReplicas: 8
maxReplicas: 50
metrics:
- type: External
external:
metric:
name: redis_queue_length
target:
averageValue: "50" # 队列长度>50自动扩容
总结:高并发架构的核心原则
- 异步解耦:Celery + Redis 让 API 快速响应
- 连接复用:PgBouncer + SQLAlchemy 连接池防止雪崩
- 队列分流:轻重任务隔离、租户隔离、优先级分离
- 安全防护:限流、配额、超时、恶意检测
- 弹性扩展:基于队列长度自动扩缩容 Worker

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)