X For You Feed Algorithm
近期开源的X的“For you”(为你推荐) tab推荐框架GitHub地址:https://github.com/xai-org/x-algorithm?
近期开源的X的“For you”(为你推荐) tab推荐框架
GitHub地址:https://github.com/xai-org/x-algorithm?tab=readme-ov-file#x-for-you-feed-algorithm
整体架构
For you feed流的内容来源包括两个部分:
- In-Network (Thunder):用户关注的账号发布的内容
- Out-of-Network(Phoenix召回): X内容的全集
在这两部分内容召回之后会把它们混在一起排序,使用的是Phoenix,一个Grok-based transformer模型,模型会对上一步的每条内容的各维度指标进行预测,最终的分数是这些预测结果的加权组合
目前的架构已经去掉了所有人工设计的特征和大部分启发式(的特征工程?),Grok-based transformer通过理解用户行为序列(点赞、回复、分享等)来决定哪些内容与用户相关。
下图是推荐系统的整体架构: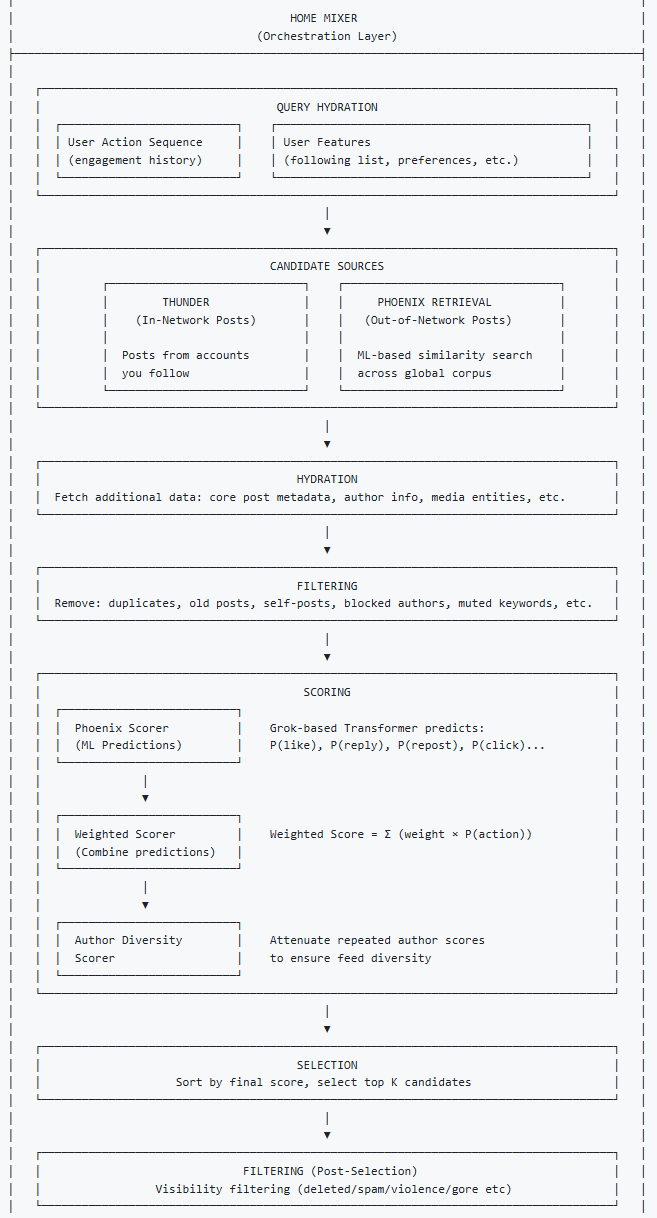
组件细节
Home Mixer
通过 C a n d i d a t e P i p e l i n e CandidatePipeline CandidatePipeline框架来组装推荐过程,主要负责组装下面这些部分: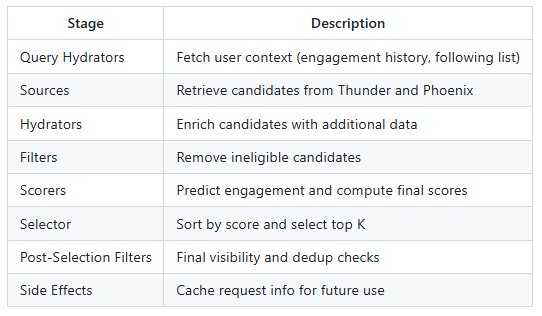
Thunder
一个in-memory存储内容并实时加工的pipeline,用来追踪全部用户近期发布的内容:
- 从Kafka中消费内容创建/删除事件
- 为每个用户存储他的发布、回复/转发和上传的视频
- 为当前请求的用户返回“in-network”的candidate,也就是他们关注的账号发布的内容
- 自动清除过期内容
Phoenix
ML组件,主要有两个功能:
1.双塔召回:在内容全集中寻找与请求用户相关的内容
- 用户塔:将用户特征和行为序列编码为embedding
- candidate(内容)塔:将内容编码为embedding
- 相似检索:通过点积召回top-K内容
2.排序:Candidate Isolation (?) 的Transformer,为每个candidate预测各维度概率
- 输入是用户上下文(行为历史)和候选内容(所有candidate也是排成一个序列)
- 引入仅利用用户行为attention的mask机制,确保candidate看不到彼此
- 为每个candidate x 每一种行为打分
下图是排序阶段的架构: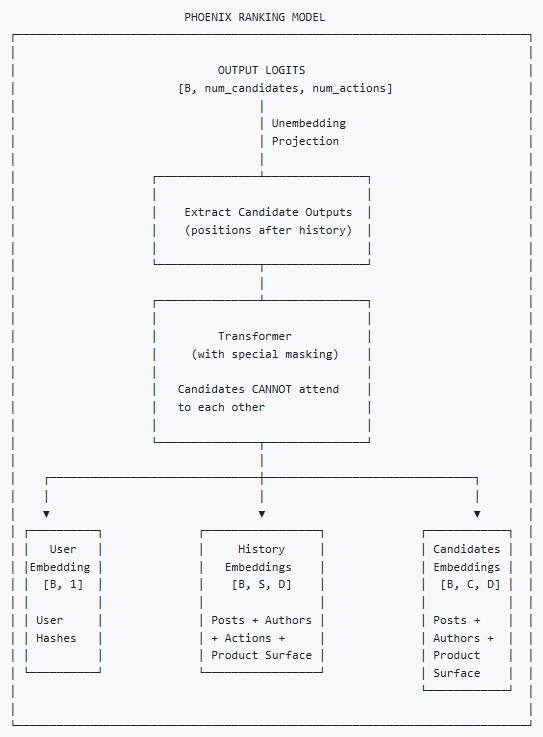
其中embedding由以下几个部分concat得到:
- post本身的embedding
- 作者embedding
- 用户行为(点赞/回复/…)
- Product Surface: 大意是内容所属模块,例如为你推荐、搜索、关注列表等
比较值得注意的是,在排序阶段为候选物品打分的时候,X的做法是把所有候选物品排成一个序列,跟用户序列一起输入transformer,也就是一个用户请求(理论上)只生成一个样本,这样做的好处包括:
- 所有candidate的分数可以通过一个样本输出,节省算力
- 从pointwise到listwise,在训练阶段或许就可以增加一些和排序相关的辅助目标(虽然训练阶段的细节目前还没有开源)
同时局限性包括:
- candidate数量会受到序列长度(也就是模型性能)的限制,目前召回阶段选出的candidate数量没有公布
以上推断还需要等X开源更多实现细节
其他组件
和现在工业界一般的推荐流程中的组件并没有什么区别

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)