AI大模型检索黑科技:一文搞懂多模态RAG,让程序猿秒变跨模态检索大神
本文系统介绍了多模态RAG技术的四种主流方案:CLIP双编码器通过对比学习实现跨模态语义对齐;VLM Captioning将图像转为文本描述进行检索;Qwen3-VL黄金架构采用Embedding+Reranker两阶段检索提升精度;Agentic RAG引入智能Agent动态选择检索策略。文章详细分析了各方案的原理、实现方法、优缺点及适用场景,并提供了技术选型指南和渐进式演进建议,帮助开发者根据
引言
在传统的RAG系统中,我们主要处理文本到文本的检索场景。然而,现实世界的知识库往往包含大量图片、图表等视觉信息。如何让用户通过自然语言查询找到相关图片(文搜图),或者通过一张图片找到相似图片(图搜图),成为多模态RAG需要解决的核心问题。
核心挑战
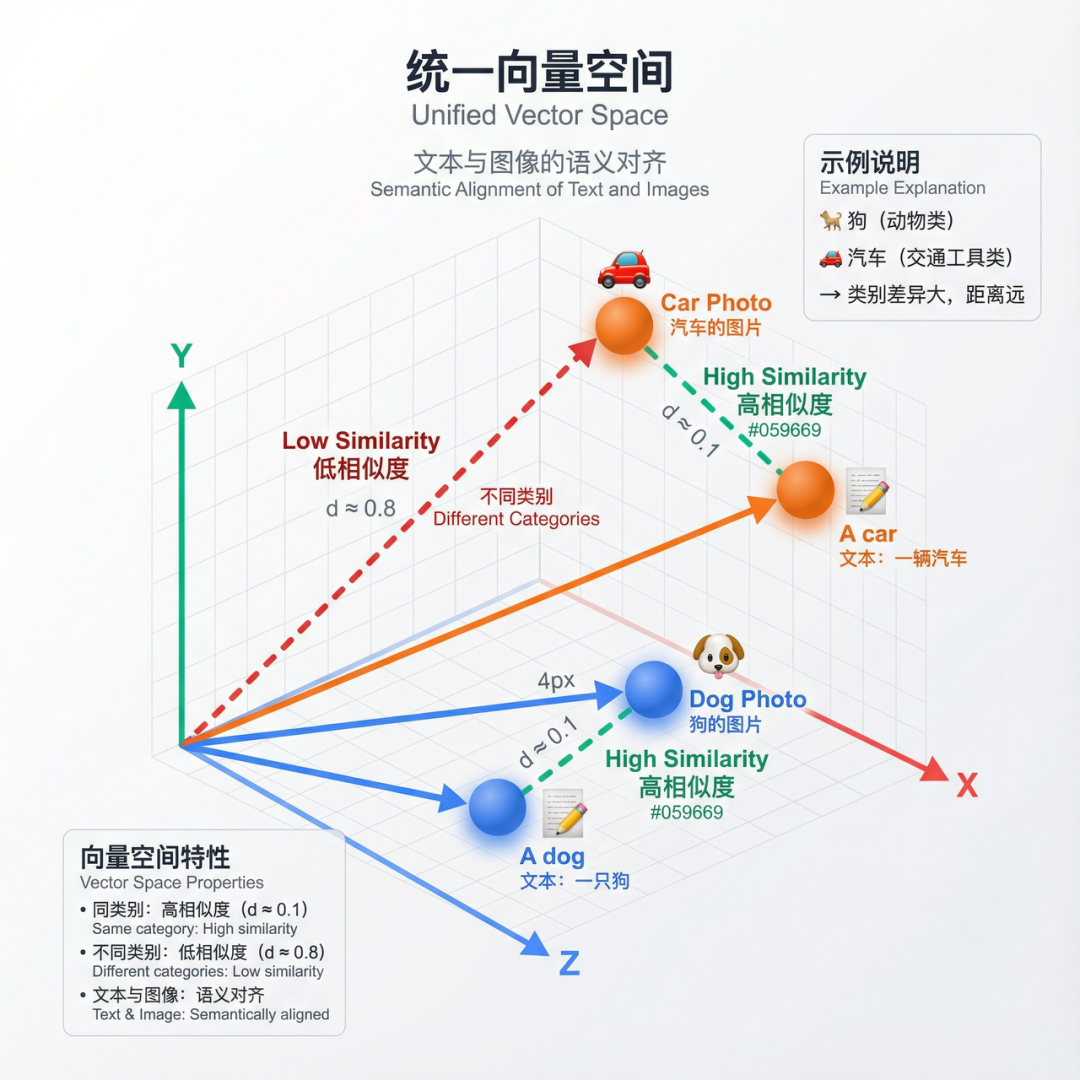
多模态检索面临的根本挑战是:如何让文本和图像在同一个语义空间中进行比较?
传统的文本Embedding模型只能处理文本,图像特征提取模型只能处理图像,两者产生的向量处于完全不同的向量空间,无法直接计算相似度。
技术演进路线
多模态RAG技术经历了从简单到复杂、从单一到融合的演进过程:
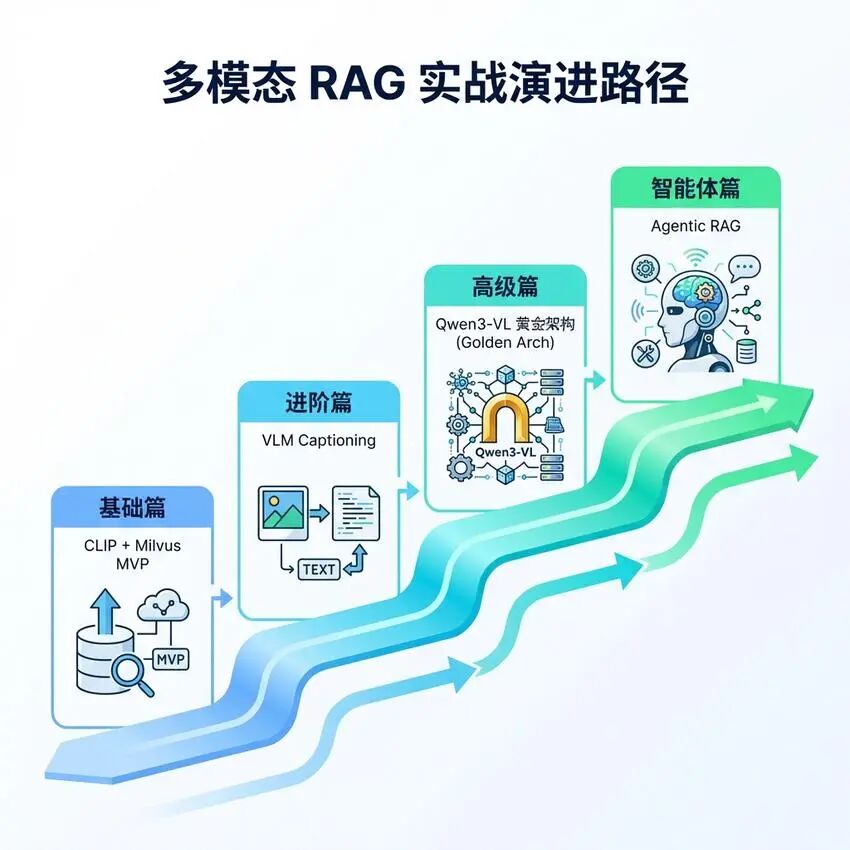
- CLIP双编码器方案:通过对比学习将文本和图像映射到统一向量空间
- VLM Captioning方案:利用视觉语言模型为图像生成文本描述,转化为文本检索问题
- Qwen3-VL黄金架构:结合Embedding和Reranker的两阶段检索方案
- Agentic RAG:引入智能Agent,根据查询意图动态选择检索策略
接下来,我们将逐一深入探讨每种方案的实现思路。
第一章:CLIP双编码器方案
1.1 CLIP模型原理
CLIP(Contrastive Language-Image Pre-training)是OpenAI在2021年发布的多模态模型,其核心思想是通过对比学习,让文本和图像在同一个512维向量空间中表示。
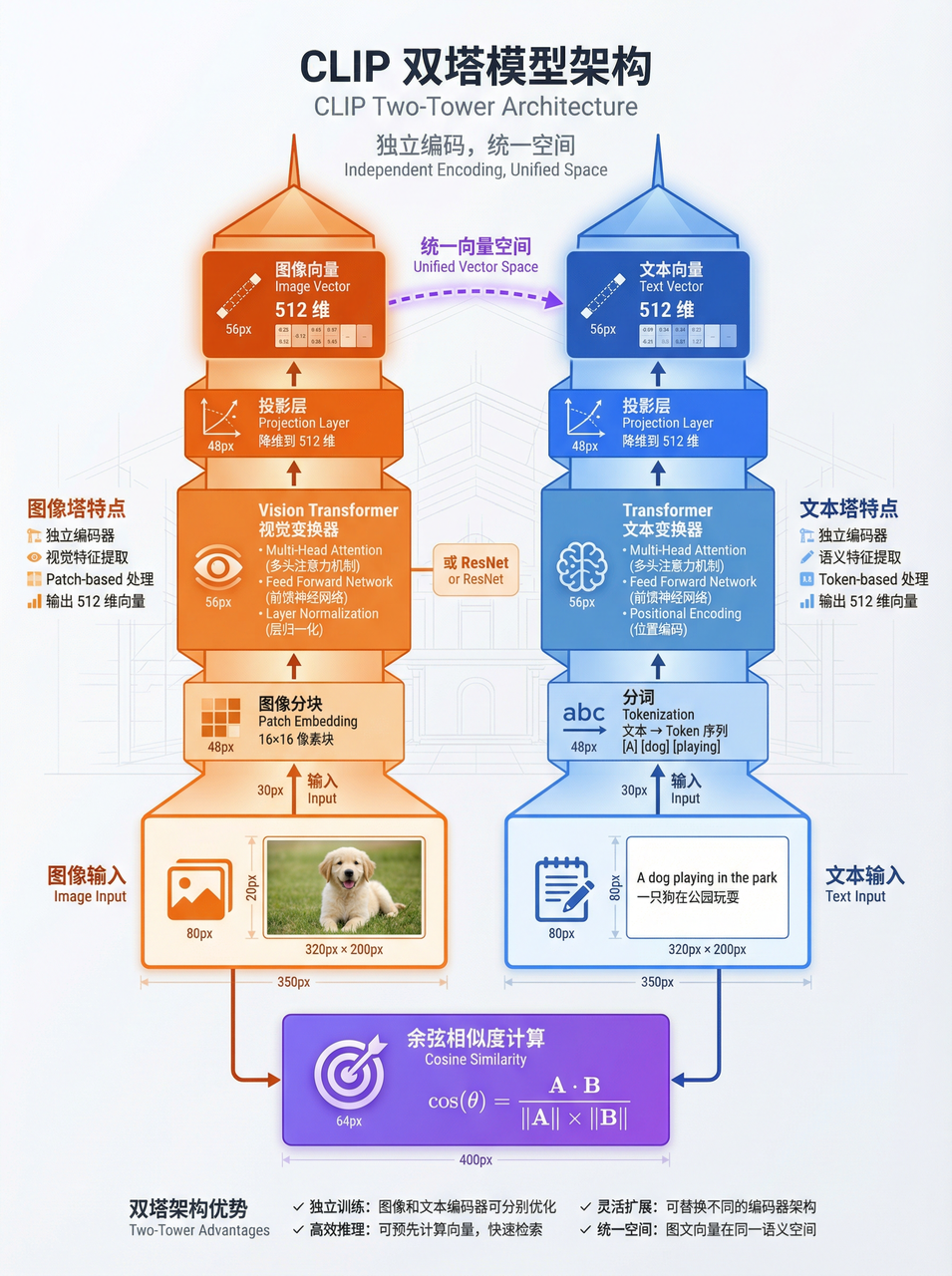
双编码器架构
CLIP采用双编码器架构:
- 文本编码器(Text Encoder):将文本转换为512维向量
- 图像编码器(Image Encoder):将图像转换为512维向量
两个编码器通过对比学习进行联合训练,使得语义相关的文本和图像在向量空间中距离更近。
对比学习训练
训练过程中,CLIP使用了4亿个图文对数据。对于每个batch:
- 正样本:匹配的图文对,目标是拉近它们的向量距离
- 负样本:不匹配的图文对,目标是推远它们的向量距离
这种训练方式使得CLIP学会了跨模态的语义对齐能力。
1.2 基于CLIP的检索实现思路
文搜图(Text-to-Image)
实现文搜图的核心流程:
- 离线索引阶段:
- 遍历图片库中的所有图片
- 使用CLIP的图像编码器将每张图片转换为512维向量
- 将向量存入向量数据库(如Milvus)
- 在线检索阶段:
- 接收用户的文本查询
- 使用CLIP的文本编码器将查询转换为512维向量
- 在向量数据库中进行相似度搜索
- 返回最相似的图片
图搜图(Image-to-Image)
图搜图的实现更加直接:
- 离线索引阶段:与文搜图相同
- 在线检索阶段:
- 接收用户上传的查询图片
- 使用CLIP的图像编码器将查询图片转换为向量
- 在向量数据库中搜索相似向量
- 返回最相似的图片
1.3 LlamaIndex中的MultiModalVectorStoreIndex
LlamaIndex提供了MultiModalVectorStoreIndex类,专门用于构建多模态检索系统。其核心设计思想是:
- 双索引架构:分别为文本和图像建立独立的向量索引
- 统一查询接口:通过统一的API同时检索文本和图像
- 灵活的Embedding配置:支持配置不同的文本和图像Embedding模型
索引构建流程
- 加载文档和图像数据
- 配置文本Embedding模型和图像Embedding模型(如CLIP)
- 创建MultiModalVectorStoreIndex实例
- 系统自动将文本和图像分别编码并存储
检索流程
- 创建MultiModalRetriever
- 输入查询(文本或图像)
- 系统自动选择对应的编码器处理查询
- 返回相关的文本节点和图像节点
1.4 向量持久化:Milvus集成
在生产环境中,向量数据需要持久化存储。Milvus是一个专门为向量检索设计的数据库,具有以下优势:
- 高性能:支持十亿级向量的毫秒级检索
- 多种索引类型:IVF_FLAT、HNSW等,可根据场景选择
- 分布式架构:支持水平扩展
与LlamaIndex集成
LlamaIndex提供了MilvusVectorStore类,可以无缝对接Milvus:
- 配置Milvus连接参数(URI、collection名称等)
- 创建MilvusVectorStore实例
- 将其作为存储后端传入MultiModalVectorStoreIndex
- 索引数据自动持久化到Milvus
双Collection设计
对于多模态场景,推荐使用双Collection设计:
- 文本Collection:存储文本向量,维度由文本Embedding模型决定
- 图像Collection:存储图像向量,维度为512(CLIP标准输出)
这种设计的好处是可以独立管理和优化文本与图像的检索性能。
1.5 CLIP方案的优缺点
优点
- 端到端简洁:无需额外的图像描述生成步骤
- 真正的跨模态理解:直接学习图文语义对齐
- 检索速度快:向量检索复杂度低
缺点
- 语义理解深度有限:CLIP的训练数据以简短描述为主,对复杂语义理解不足
- 细粒度检索能力弱:难以处理"图片中红色物体的左边是什么"这类细节查询
- 向量维度固定:512维可能无法充分表达复杂图像的全部信息
📦 想动手实践本章内容? CLIP模型加载、Milvus向量库配置、LlamaIndex实战教程可扫码加入赋范空间咨询

第二章:VLM Captioning方案
2.1 核心思想
VLM Captioning方案采用了一种"曲线救国"的策略:既然跨模态检索困难,那就把图像转换为文本,将问题转化为成熟的文本检索问题。
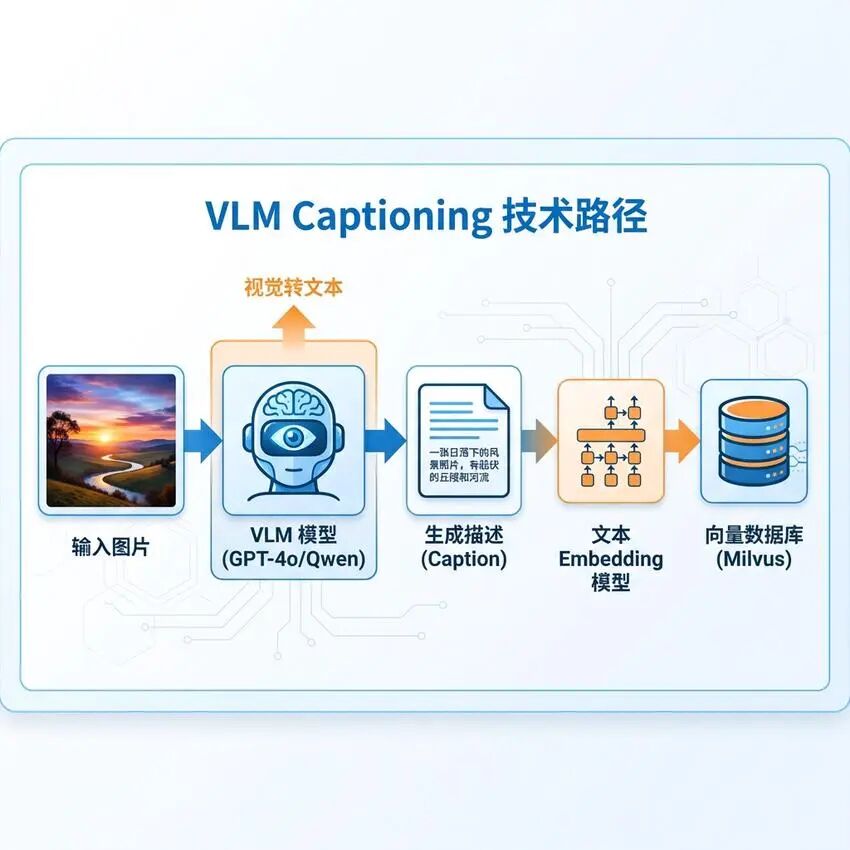
基本流程
- 图像描述生成:使用视觉语言模型(如GPT-4o、Qwen-VL-Max)为每张图片生成详细的文本描述
- 文本索引构建:将生成的描述文本进行Embedding,存入向量数据库
- 文本检索:用户查询与图片描述进行文本相似度匹配
- 结果映射:将匹配的描述映射回对应的图片
2.2 VLM选择与Prompt设计
VLM模型选择
常用的视觉语言模型包括:
- GPT-4o:OpenAI的多模态旗舰模型,描述质量高但成本较高
- Qwen-VL-Max:阿里云的视觉语言模型,性价比较高
- Claude 3.5 Sonnet:Anthropic的多模态模型,理解能力强
Prompt设计要点
生成高质量图片描述的Prompt应包含:
- 全面性要求:描述图片中的所有重要元素
- 结构化输出:按照主体、背景、细节等层次组织
- 语义丰富性:包含颜色、位置、动作、情感等多维度信息
- 检索友好性:使用用户可能搜索的关键词
2.3 混合检索:向量 + BM25
单纯的向量检索可能会遗漏一些关键词精确匹配的场景。例如,用户搜索"iPhone 15 Pro Max",向量检索可能返回各种手机图片,但BM25关键词检索能精确匹配包含这个型号的描述。
BM25算法简介
BM25是一种经典的关键词检索算法,其核心思想是:
- 词频(TF):关键词在文档中出现的次数越多,相关性越高
- 逆文档频率(IDF):在越少文档中出现的词,区分度越高
- 文档长度归一化:避免长文档获得不公平的优势
QueryFusionRetriever
LlamaIndex提供了QueryFusionRetriever,可以融合多种检索方式:
- 向量检索器:基于语义相似度检索
- BM25检索器:基于关键词匹配检索
- RRF融合算法:使用Reciprocal Rank Fusion合并两路结果
混合检索的优势
- 语义理解:向量检索捕捉语义相似性
- 精确匹配:BM25确保关键词不被遗漏
- 互补增强:两种方法的优势互补,提升整体召回率
2.4 VLM Captioning方案的优缺点
优点
- 语义理解深度:VLM可以生成非常详细的图片描述,包含丰富的语义信息
- 复用成熟技术:可以直接使用成熟的文本检索技术栈
- 可解释性强:检索结果可以通过描述文本解释为什么匹配
缺点
- 信息损失:图像转文本过程中不可避免地丢失部分视觉信息
- 成本较高:需要为每张图片调用VLM生成描述
- 不支持图搜图:用户上传图片后,需要先生成描述再检索,体验不够直接
第三章:Qwen3-VL黄金架构
3.1 两阶段检索思想
前面介绍的CLIP和VLM Captioning方案各有优缺点。Qwen3-VL黄金架构结合了两者的优势,采用"粗筛 + 精排"的两阶段检索策略。
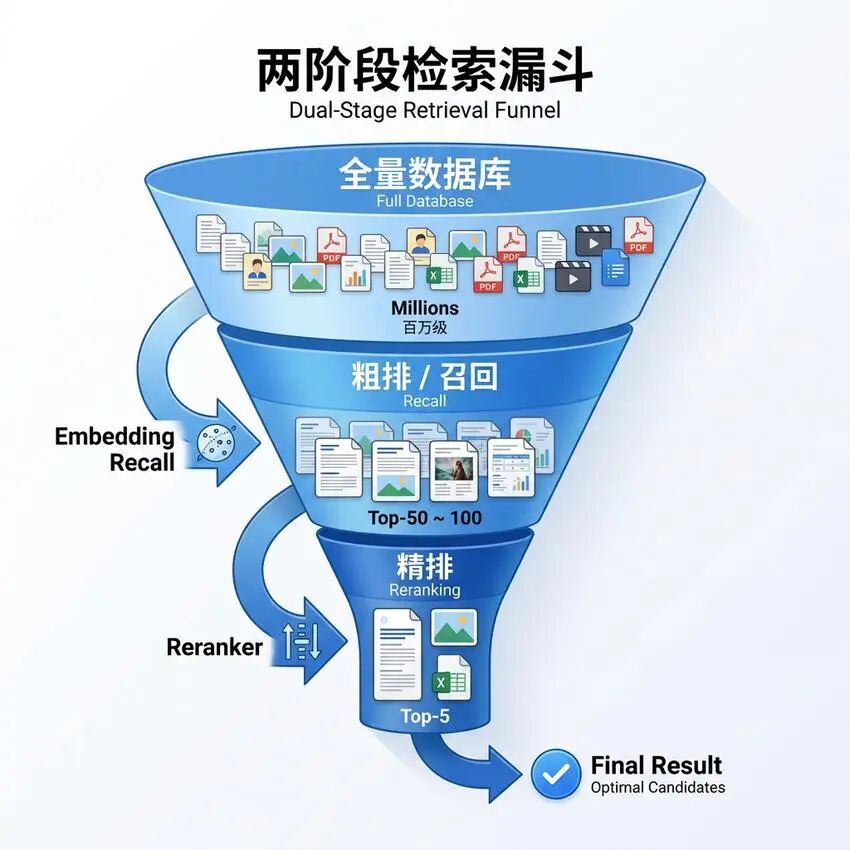
第一阶段:Embedding粗筛
使用Embedding模型快速从海量数据中召回候选集:
- 速度快:向量检索复杂度低
- 召回量大:通常召回Top-K(如100条)候选
- 容错性高:宁可多召回,不可漏掉相关结果
第二阶段:Reranker精排
使用Reranker模型对候选集进行精细排序:
- 理解深度:Reranker可以同时看到查询和候选,进行交叉注意力计算
- 排序精准:输出精确的相关性分数
- 计算量可控:只处理第一阶段召回的少量候选
3.2 Qwen3-VL Embedding
Qwen3-VL是阿里云推出的多模态大模型,其Embedding版本专门针对检索场景优化。
核心特点
- 原生多模态:同一个模型可以处理文本和图像
- 统一向量空间:文本和图像编码到同一个高维空间
- 指令感知:支持通过指令控制Embedding的生成方式
与LlamaIndex集成
要在LlamaIndex中使用Qwen3-VL Embedding,需要实现自定义的Embedding适配器:
- 继承LlamaIndex的BaseEmbedding类
- 实现文本编码方法:调用Qwen3-VL处理文本
- 实现图像编码方法:调用Qwen3-VL处理图像
- 确保输出向量维度一致
3.3 Qwen3-VL Reranker
Reranker是两阶段检索的关键组件,负责对候选集进行精细排序。
Reranker vs Embedding的区别
| 特性 | Embedding | Reranker |
| 输入 | 单个文本/图像 | 查询 + 候选对 |
| 输出 | 向量 | 相关性分数 |
| 计算方式 | 独立编码 | 交叉注意力 |
| 适用场景 | 大规模召回 | 小规模精排 |
实现思路
Qwen3-VL Reranker的实现需要:
- 将查询和候选拼接成特定格式的输入
- 调用Qwen3-VL模型进行推理
- 从模型输出中提取相关性分数
- 根据分数对候选进行排序
3.4 黄金架构:Embedding + Reranker
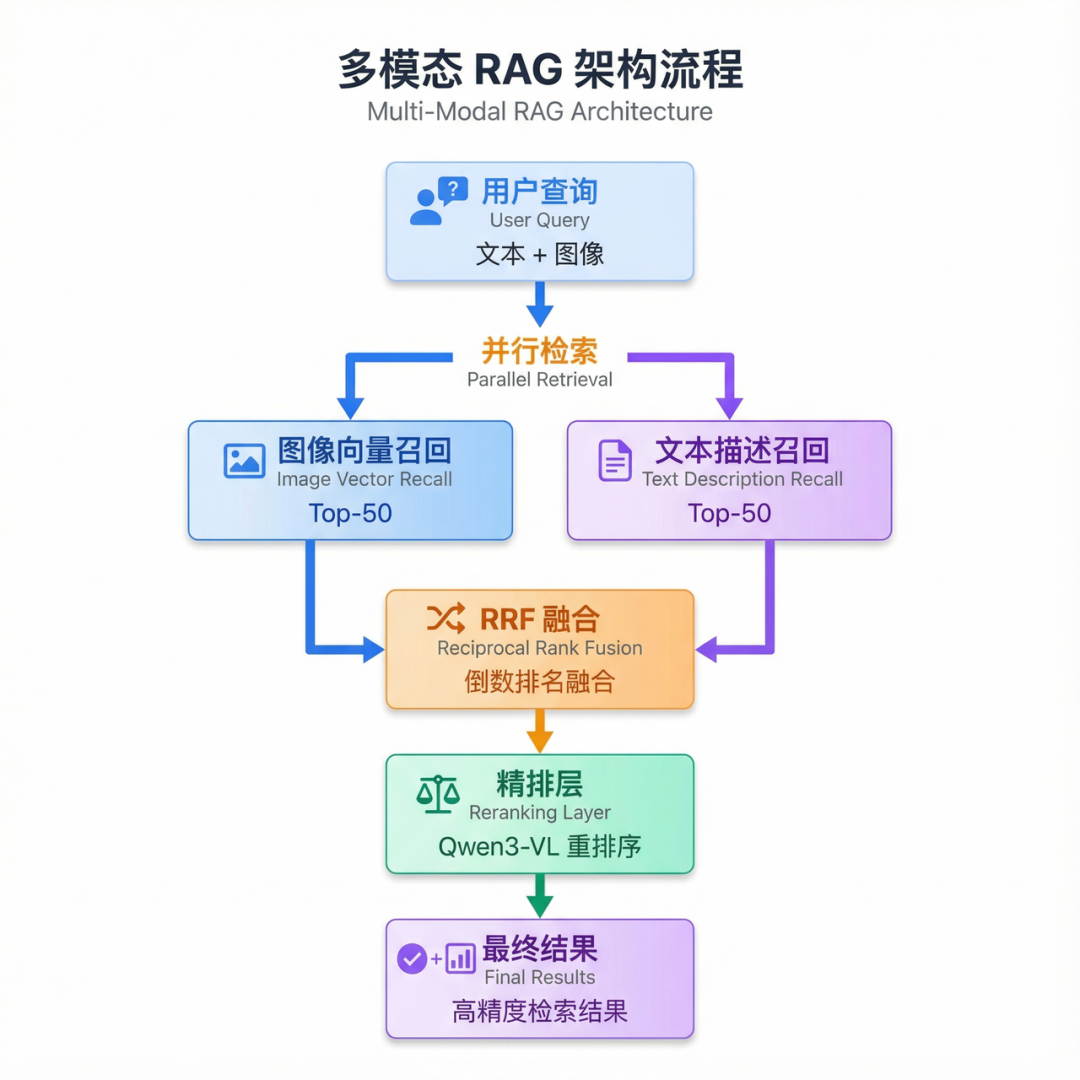
将Embedding和Reranker组合,形成完整的两阶段检索流程:
完整流程
- 查询处理:接收用户的文本或图像查询
- Embedding编码:将查询编码为向量
- 向量检索:在向量数据库中检索Top-K候选(如100条)
- Reranker精排:对候选集进行精细排序
- 结果返回:返回Top-N最相关结果(如10条)
性能与效果的平衡
- 召回阶段:追求高召回率,宁可多召回
- 精排阶段:追求高精度,确保排序准确
- 参数调优:K和N的选择需要根据实际场景调整
3.5 三路检索融合
为了进一步提升检索效果,可以将向量检索、BM25检索和Reranker结合,形成三路检索融合架构。
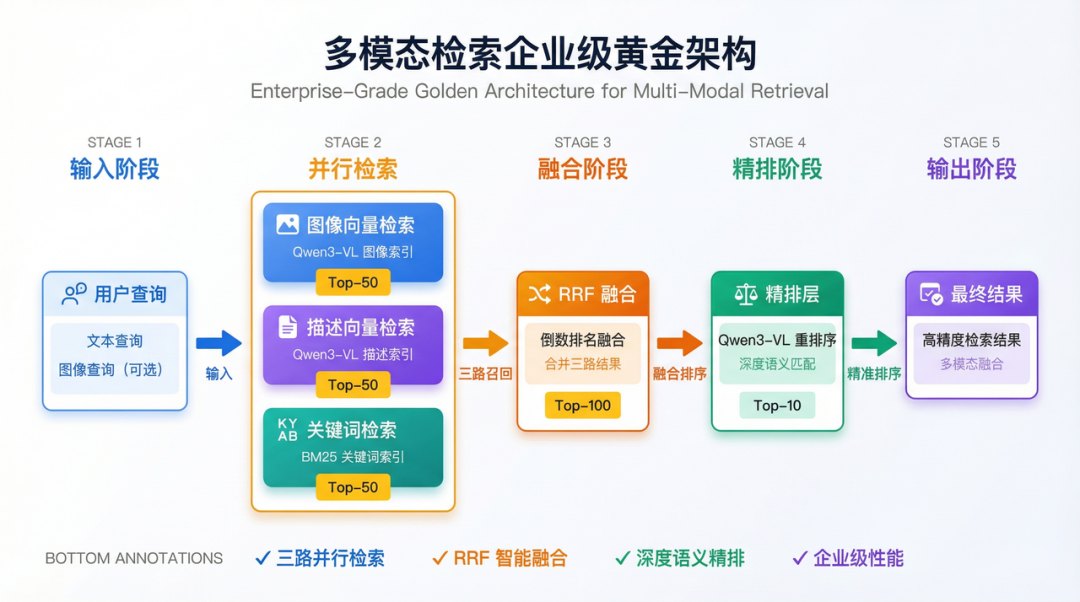
架构设计
- 向量检索路:基于Qwen3-VL Embedding的语义检索
- BM25检索路:基于图片描述的关键词检索
- 融合层:使用RRF算法合并两路结果
- 精排层:使用Qwen3-VL Reranker对融合结果精排
自定义Milvus检索器
为了实现三路检索,需要自定义Milvus检索器:
- 支持同时查询文本和图像Collection
- 支持配置不同的检索参数
- 支持结果的合并与去重
- 与LlamaIndex的Retriever接口兼容
3.6 Qwen3-VL方案的优缺点
优点
- 检索质量高:两阶段架构兼顾召回率和精度
- 原生多模态:无需图像转文本,保留完整视觉信息
- 灵活可扩展:可以根据需求调整各阶段参数
缺点
- 系统复杂度高:需要维护多个模型和组件
- 计算成本较高:Reranker阶段需要额外的模型推理
- 部署要求高:需要GPU资源支持大模型推理
🚀 进阶学习提示:Qwen3-VL黄金架构涉及自定义Embedding适配器、Reranker集成、三路检索融合等高级技术,相关实战教程和调优技巧可扫码加入赋范空间咨询
第四章:Agentic RAG
4.1 从传统RAG到Agentic RAG
传统RAG系统采用固定的检索-生成流程,无法根据查询的特点动态调整策略。Agentic RAG引入智能Agent,让系统具备自主决策能力。
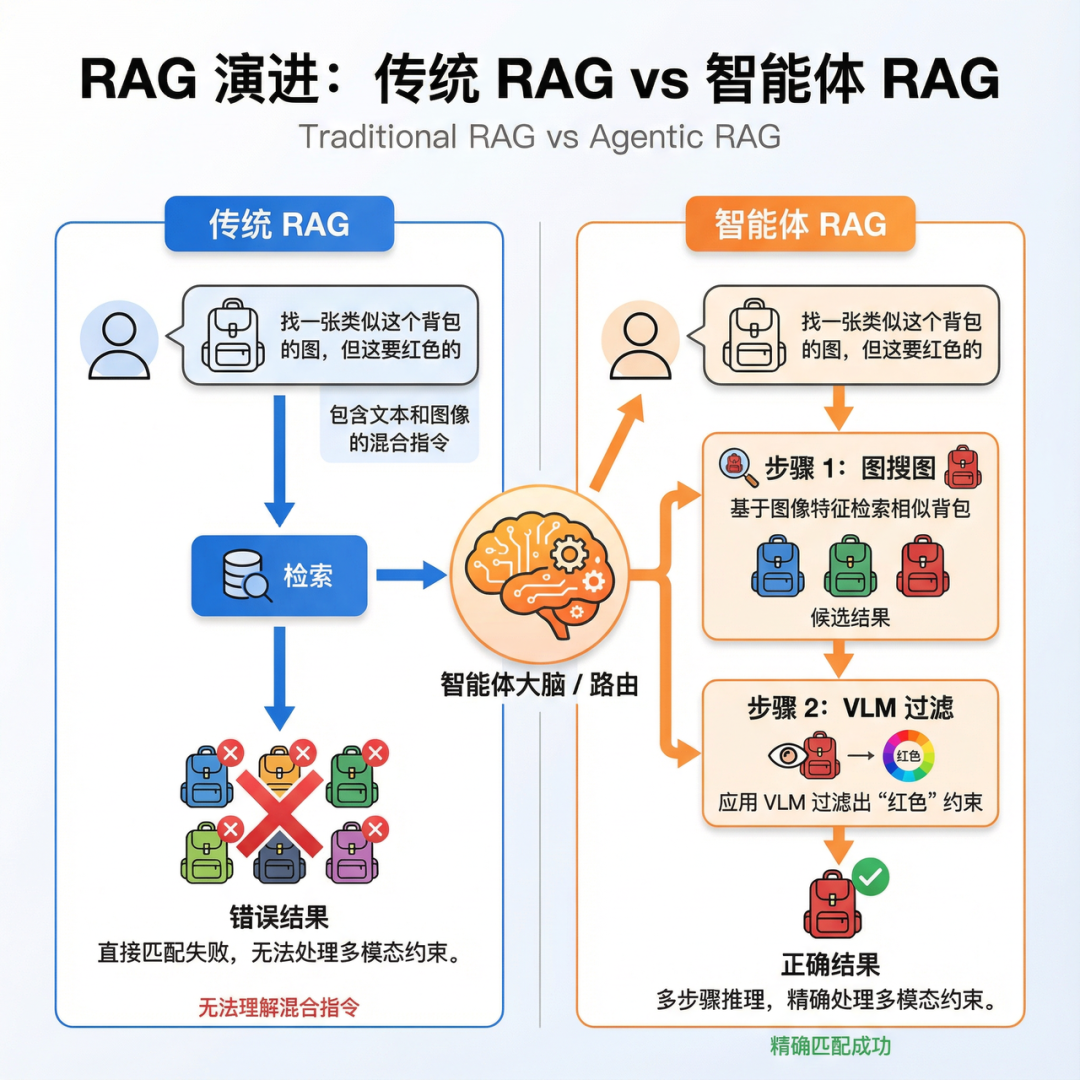
传统RAG的局限
- 流程固定:无论什么查询都走相同的检索流程
- 无法迭代:一次检索不满意无法自动重试
- 缺乏推理:无法根据检索结果进行逻辑推理
Agentic RAG的优势
- 动态决策:根据查询意图选择最合适的检索策略
- 迭代优化:检索结果不满意时自动调整策略重试
- 推理能力:可以对检索结果进行分析和推理
4.2 ReAct循环
Agentic RAG的核心是ReAct(Reasoning + Acting)循环,让Agent在推理和行动之间交替进行。
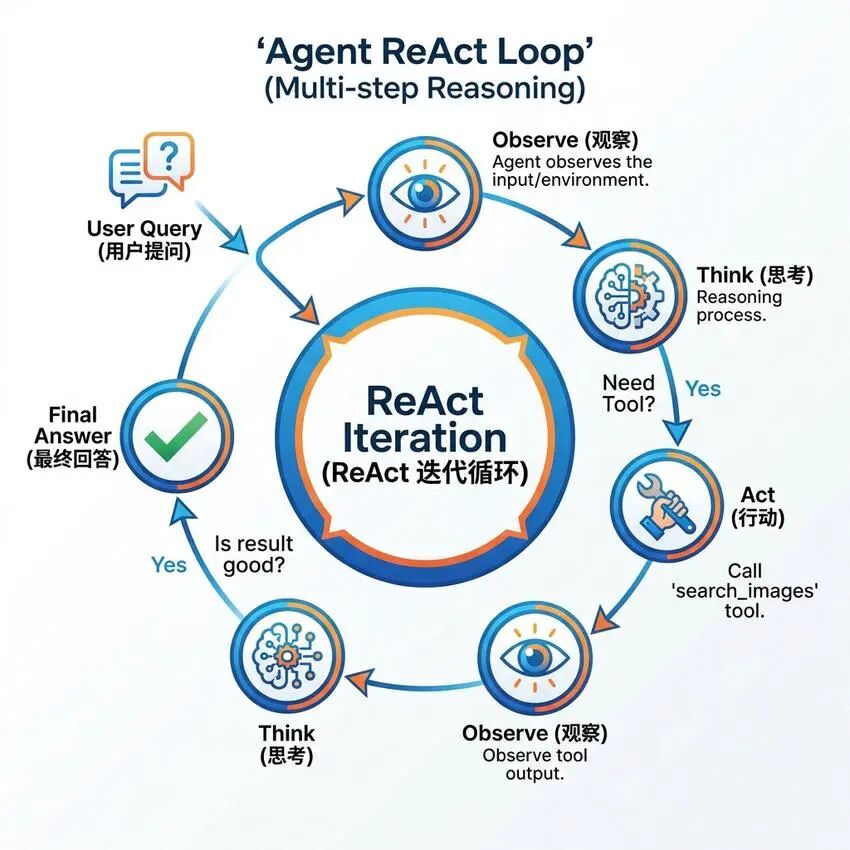
ReAct循环的三个阶段
- Observe(观察):Agent观察当前状态,包括用户查询、已有的检索结果等
- Think(思考):Agent分析当前状态,决定下一步应该采取什么行动
- Act(行动):Agent执行决定的行动,如调用检索工具、生成回答等
循环终止条件
- Agent认为已经收集到足够的信息
- 达到最大迭代次数
- 用户主动终止
4.3 工具设计
在Agentic RAG中,检索能力被封装为工具(Tool),供Agent调用。
多模态检索工具
针对多模态场景,可以设计以下工具:
- 文搜图工具:输入文本查询,返回相关图片
- 图搜图工具:输入图片,返回相似图片
- 混合检索工具:同时使用向量和BM25检索
- 精排工具:对候选结果进行Reranker精排
工具描述的重要性
Agent通过工具描述来理解每个工具的功能和使用场景。好的工具描述应该:
- 清晰说明工具的功能
- 明确输入输出格式
- 给出使用场景示例
- 说明与其他工具的区别
4.4 LangChain Agent实现
LangChain提供了完善的Agent框架,可以快速构建Agentic RAG系统。
核心组件
- LLM:作为Agent的"大脑",负责推理和决策
- Tools:Agent可以调用的工具集合
- Memory:存储对话历史和中间状态
- Prompt:指导Agent行为的提示词
实现流程
- 定义检索工具,封装各种检索能力
- 配置LLM,选择合适的大语言模型
- 创建Agent,绑定工具和LLM
- 运行Agent,处理用户查询
4.5 多Agent协作
对于复杂的多模态检索场景,可以设计多个专门化的Agent协作完成任务。
Agent角色划分
- 路由Agent:分析查询意图,决定调用哪个专门Agent
- 文搜图Agent:专门处理文本到图像的检索
- 图搜图Agent:专门处理图像到图像的检索
- 问答Agent:基于检索结果生成回答
协作模式
- 串行模式:Agent按顺序执行,前一个的输出作为后一个的输入
- 并行模式:多个Agent同时执行,结果合并
- 层级模式:主Agent协调多个子Agent
4.6 Agentic RAG的优缺点
优点
- 智能化程度高:能够理解复杂查询意图
- 自适应能力强:可以根据情况动态调整策略
- 可扩展性好:通过添加工具扩展能力
缺点
- 延迟较高:多轮推理增加响应时间
- 成本较高:每次推理都需要调用LLM
- 可控性降低:Agent的行为不完全可预测
第五章:场景选型指南
5.1 技术方案对比
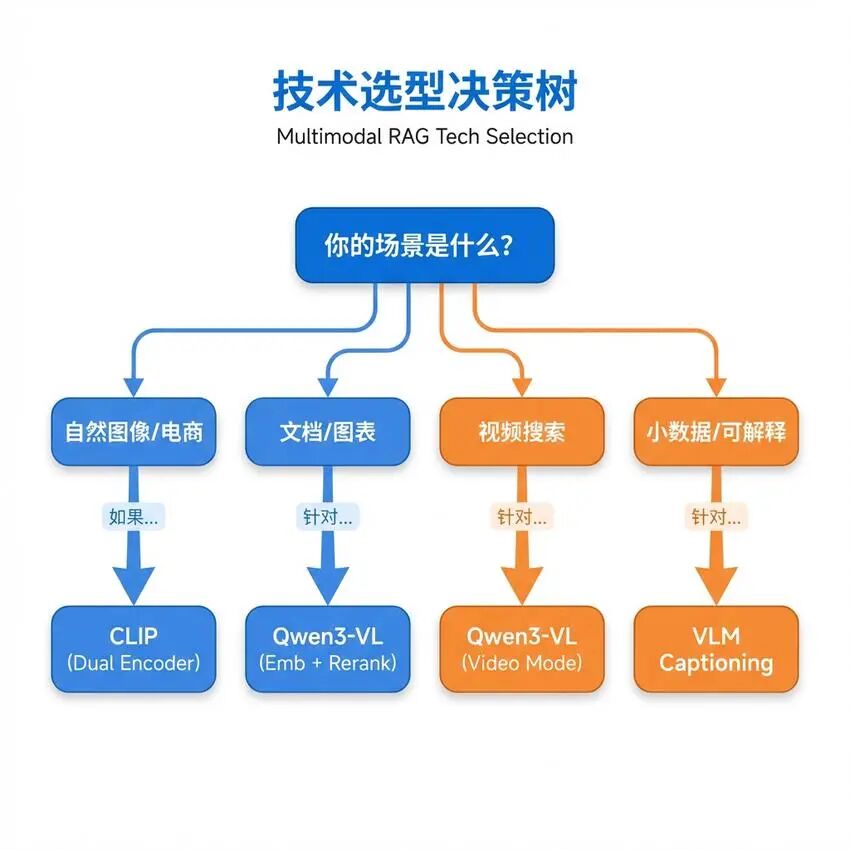
| 方案 | 文搜图 | 图搜图 | 语义理解 | 实现复杂度 | 成本 |
| CLIP | 支持 | 支持 | 中等 | 低 | 低 |
| VLM Captioning | 支持 | 不直接支持 | 高 | 中 | 中 |
| Qwen3-VL黄金架构 | 支持 | 支持 | 高 | 高 | 高 |
| Agentic RAG | 支持 | 支持 | 最高 | 最高 | 最高 |
5.2 场景推荐
场景一:电商商品图片搜索
需求特点:
- 海量商品图片(百万级以上)
- 用户查询相对简单(如"红色连衣裙")
- 对响应速度要求高
推荐方案:CLIP + Milvus
理由:
- CLIP能够处理简单的商品描述查询
- 向量检索速度快,满足高并发需求
- 实现成本低,易于维护
场景二:医学影像检索
需求特点:
- 图片数量中等(万级到十万级)
- 查询涉及专业术语和复杂描述
- 对检索精度要求极高
推荐方案:VLM Captioning + 混合检索
理由:
- VLM可以生成专业的医学描述
- 混合检索确保专业术语精确匹配
- 可解释性强,便于医生验证结果
场景三:设计素材库
需求特点:
- 需要同时支持文搜图和图搜图
- 用户可能上传参考图片寻找相似素材
- 对视觉相似度要求高
推荐方案:Qwen3-VL黄金架构
理由:
- 原生支持图搜图,无需额外处理
- 两阶段检索保证检索质量
- Reranker提升视觉相似度排序精度
场景四:智能客服图片问答
需求特点:
- 用户查询复杂多变
- 可能需要多轮交互
- 需要结合图片和文本生成回答
推荐方案:Agentic RAG
理由:
- Agent可以理解复杂查询意图
- 支持多轮交互和迭代检索
- 可以整合多种检索策略
5.3 渐进式演进建议
对于大多数项目,建议采用渐进式演进策略:
第一阶段:快速验证
- 使用CLIP + 简单向量数据库
- 快速搭建MVP验证业务价值
- 收集用户反馈和真实查询数据
第二阶段:效果优化
- 引入VLM Captioning增强语义理解
- 添加BM25混合检索提升召回率
- 根据数据特点调优检索参数
第三阶段:质量提升
- 引入Reranker提升排序精度
- 考虑使用Qwen3-VL等更强的多模态模型
- 建立评估体系持续优化
第四阶段:智能化升级
- 引入Agent实现智能检索
- 支持复杂查询和多轮交互
- 持续迭代优化用户体验
总结
多模态RAG技术正在快速发展,从最初的CLIP双编码器到如今的Agentic RAG,技术方案越来越丰富,能力也越来越强大。
核心要点回顾
- CLIP方案:通过对比学习实现跨模态检索,简单高效,适合入门
- VLM Captioning:将图像转为文本,复用成熟的文本检索技术
- Qwen3-VL黄金架构:Embedding + Reranker两阶段检索,兼顾效率和精度
- Agentic RAG:引入智能Agent,实现动态决策和迭代优化
技术选型原则
- 从简单开始:先用简单方案验证业务价值
- 数据驱动:根据实际数据特点选择方案
- 渐进演进:随着需求增长逐步升级技术栈
- 成本效益:在效果和成本之间找到平衡点
未来展望
随着多模态大模型的持续进步,我们可以期待:
- 更强的跨模态理解:模型能够理解更复杂的图文关系
- 更高效的检索:在保持精度的同时进一步提升速度
- 更智能的Agent:能够处理更复杂的多模态任务
- 更低的使用门槛:框架和工具链的持续完善
希望本文能够帮助读者理解多模态RAG的技术演进脉络,在实际项目中选择合适的技术方案。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献627条内容
已为社区贡献627条内容

所有评论(0)