【AI Agent开发】小白也能上手!PDF文档智能拆分+向量存储+相似性检索,代码超详细!
本文是AI Agent系列第17篇,详细介绍了PDF文档解析、拆分和向量存储的完整实现流程。文章首先解释了文档拆分的必要性和策略,然后通过代码演示了如何使用RecursiveCharacterTextSplitter将PDF拆分为语义连贯的chunks,并利用AlibabaTongyiEmbeddings进行向量化,最后存储到ChromaDB中实现相似性检索功能。整个过程为构建RAG系统提供了基础
AI Agent 系列文章17, 后续会更新 MCP、监控等内容,最后全栈开发一个 Agent 智能体并部署上线。
本篇介绍内容:
1)为啥要拆分?
2)pdf 文件解析,并生成拆分每一页为一个文档对象
3)拆分文档为更细的 chunk,向量化,存入 chromaDB,相似性检索
一些代码细节无需深究,主要是熟悉整个相似性检索的过程。
- 为啥要拆分?
既然是 rag,那肯定是大文件,不然就直接预置 prompt 就行了。
那为啥要拆分为 chunk 呢?
简单理解:如果整个文件是一个向量,那肯定会包含很多冗余信息,语义不一致的信息,那就失去向量检索的意义了。
给LLM注入大量无关上下文 ==》 答案不准确或产生幻觉
怎么拆分?
没有一种策略适用于所有场景,需根据文档类型和需求选择
更先进的方法,利用模型计算句子或段落间的语义相似度,在语义发生显著变化的位置进行切块。这种方法能最好地保持语义连贯性,但计算成本较高。
或者递归拆分,
一种“先大后小”的层级式拆分法。优先按最大自然边界(如\n\n段落)切割,
如果切出的块仍然太大,再按下一级边界(如\n句子)递归切割,直到满足大小要求。
这种方法能较好地平衡块大小与语义完整性,是处理通用长文档的稳健选择。
下面用这种方法进行 pdf 的文本拆分。
- 编码部分
import { RecursiveCharacterTextSplitter } from '@langchain/textsplitters'
import { AlibabaTongyiEmbeddings } from '@langchain/community/embeddings/alibaba_tongyi'
import { Chroma } from '@langchain/community/vectorstores/chroma'
import { ChromaClient } from 'chromadb'
import { Document } from '@langchain/core/documents'
import dotenv from 'dotenv'
import PDFParser from 'pdf2json'
import path from 'path'
import { fileURLToPath } from 'url'
dotenv.config();
// 获取当前文件目录
// import.meta.url: file:///D:/360MoveData/Users/56801/Desktop/chunk/src/index.mjs
// __filename: D:\360MoveData\Users\56801\Desktop\chunk\src\index.mjs
// __dirname: D:\360MoveData\Users\56801\Desktop\chunk\src
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
// 清理文本内容,移除多余空格等
function cleanText(text) {
let cleaned = text.replace(/(\w)\s+(?=\w)/g, '$1') // 移除单词间多余的空格
cleaned = cleaned.replace(/\s+/g, ' ').trim() // 合并多余的空白字符
return cleaned
}
/**
* 使用 pdf2json 加载 PDF 文件
*/
async function loadPDF(pdfPath) {
return new Promise((resolve, reject) => {
const pdfParser = new PDFParser() // 创建 PDF 解析器实例
pdfParser.loadPDF(pdfPath) // 开始加载 PDF 文件
// 监听解析错误事件
pdfParser.on('pdfParser_dataError', (errData) => {
reject(errData.parserError)
})
// 监听解析完成事件
pdfParser.on('pdfParser_dataReady', (pdfData) => {
try {
const pages = pdfData.Pages || [] // 获取所有页面
const documents = []
// 遍历每一页,提取文本内容
pages.forEach((page, pageIndex) => {
let pageText = ''
const texts = page.Texts || [] // 获取页面中的文本对象
// 遍历文本对象,解码并拼接文本
texts.forEach((text) => {
try {
const decodedText = decodeURIComponent(text.R[0].T) // 解码文本
pageText += decodedText + ' '
} catch (e) {
// 如果解码失败,使用原始文本
pageText += text.R[0].T + ' '
}
})
// 创建 Document 实例并添加到数组
if (pageText.trim()) {
documents.push(
new Document({
pageContent: cleanText(pageText), // 清理后的文本内容
// 配置页码等元数据
metadata: {
source: pdfPath, // 来源文件路径
pageNumber: pageIndex + 1, // 页码(从 1 开始)
},
})
)
}
})
// 解析完成,返回文档数组,每一页就是一个 Document
resolve(documents)
} catch (error) {
reject(error)
}
})
})
}
/**
* RAG 检索
* 1. 加载 PDF 文件
* 2. 拆分文档为 chunks
* 3. 转换为 embedding 向量
* 4. 存储到 ChromaDB
* 5. 执行检索并展示结果
*/
async function ragDemo() {
try {
console.log('=== RAG 检索功能演示 ===\n')
// 1. 加载 PDF 文件
console.log('📄 步骤 1: 加载 PDF 文件...')
const pdfPath = path.join(__dirname, '../files/尚品衣橱知识库.pdf')
console.log('pdfPath: ', pdfPath);
// 加载并解析 PDF, 先获取每一页数据解码,每一页内容作为一个 Document 对象
const docs = await loadPDF(pdfPath)
console.log(`✅ 成功加载 PDF,共 ${docs.length} 页\n`)
// 2. 拆分文档为 chunks
console.log('✂️ 步骤 2: 拆分文档为 chunks...')
// 使用递归字符拆分器进行拆分
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000, // 每个 chunk 包含的最大字符数
chunkOverlap: 200, // chunk 的重叠部分字符数,意思是相邻 chunk 之间会有 200 字符的重叠
})
// 拆分文档
const splitDocs = await textSplitter.splitDocuments(docs)
console.log(`✅ 成功拆分为 ${splitDocs.length} 个 chunks`)
// 为了演示,只使用前 100 个 chunks 以避免配额限制
const limitedDocs = splitDocs.slice(0, 100)
console.log(
`📝 为避免配额限制,本次演示使用前 ${limitedDocs.length} 个 chunks\n`
)
// 3. 初始化 Embedding 模型
console.log('🔢 步骤 3: 初始化 Embedding 模型...')
const embeddings = new AlibabaTongyiEmbeddings({
apiKey: process.env.ALIBABA_API_KEY,
// 降低批处理大小以避免配额限制
batchSize: 10, // 每批处理 10 个文本, 意思是每次请求会发送 10 个文本进行 embedding 计算
})
console.log('✅ Embedding 模型初始化成功\n')
// 4. 存储到 ChromaDB
console.log('💾 步骤 4: 存储到 ChromaDB...')
const collectionName = 'nodejs_env_init_demo'
// 首先清理已存在的集合
try {
const chromaClient = new ChromaClient({
host: 'localhost',
port: 8000,
})
await chromaClient.deleteCollection({ name: collectionName })
console.log('🗑️ 已删除旧的集合')
} catch (error) {
// 集合不存在,忽略错误
}
// 将分割后的文档进行 embedding 并存储到 ChromaDB
const vectorStore = await Chroma.fromDocuments(limitedDocs, embeddings, {
collectionName: collectionName, // 集合名称, 是用来存储和组织向量数据的逻辑单元
url: 'http://localhost:8000', // ChromaDB 服务地址
})
console.log(`✅ 成功存储 ${limitedDocs.length} 个 chunks 到 ChromaDB\n`)
// 5. 执行检索演示
console.log('🔍 步骤 5: 执行检索演示...\n')
console.log('='.repeat(80))
// 检索示例 1:
console.log('\n【检索示例 1】')
const query1 = "尚品衣橱品牌定位是什么?"
console.log(`查询问题: ${query1}`)
console.log('-'.repeat(80))
// 执行相似度搜索,返回 top 3 相关文档片段
const results1 = await vectorStore.similaritySearchWithScore(query1, 3)
console.log(`找到 ${results1.length} 个相关文档片段:\n`)
// 展示检索结果
results1.forEach(([doc, score], index) => {
// 显示相似度分数和文档内容摘要,分数越小表示越相关
console.log(`结果 ${index + 1}: (相似度距离: ${(score * 100).toFixed(2)})`)
console.log(`内容: ${doc.pageContent.substring(0, 400)}...`)
console.log(`来源: 第 ${doc.metadata.pageNumber || '未知'} 页`)
console.log('-'.repeat(80))
})
// 检索示例 2:
console.log('\n【检索示例 2】')
const query2 = "尚品衣橱有什么T恤系列?"
console.log(`查询问题: ${query2}`)
console.log('-'.repeat(80))
// 执行相似度搜索,返回 top 3 相关文档片段
const results2 = await vectorStore.similaritySearchWithScore(query2, 3)
console.log(`找到 ${results2.length} 个相关文档片段:\n`)
// 展示检索结果
results2.forEach(([doc, score], index) => {
// 显示相似度分数和文档内容摘要,分数越小表示越相关
console.log(`结果 ${index + 1}: (相似度距离: ${(score * 100).toFixed(2)})`)
console.log(`内容: ${doc.pageContent.substring(0, 400)}...`)
console.log(`来源: 第 ${doc.metadata.pageNumber || '未知'} 页`)
console.log('-'.repeat(80))
})
// 完成
console.log('\n✨ RAG 检索演示完成!')
} catch (error) {
console.error('❌ 错误:', error.message)
console.error(error)
}
}
// 运行演示
ragDemo()
执行结果:这个距离是 * 100 了
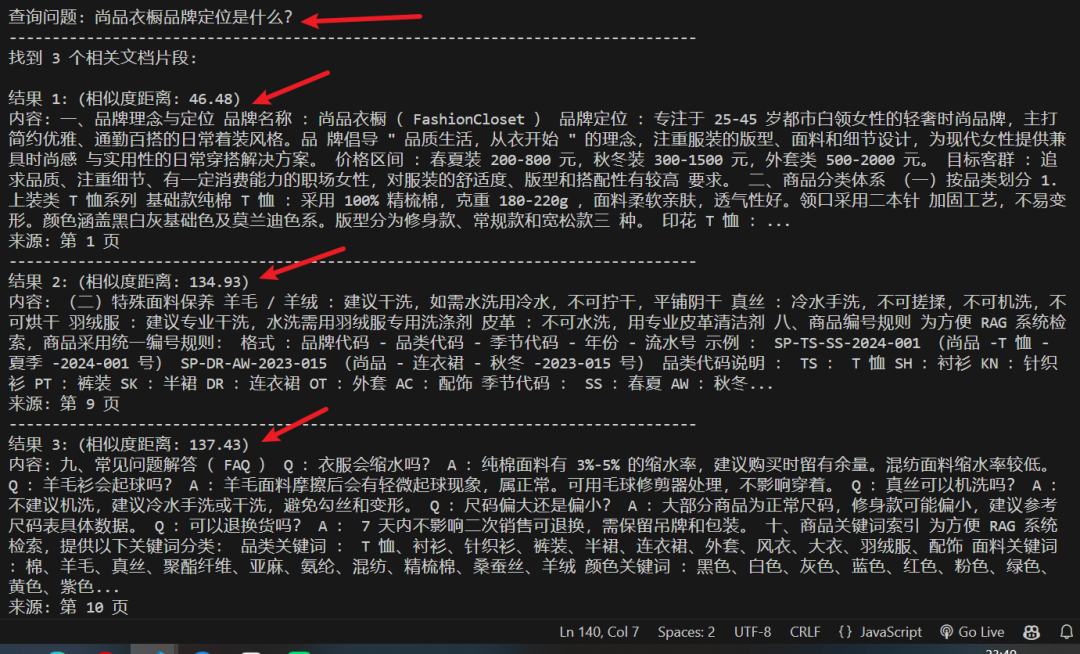
读取本地的一个 “尚品衣橱知识库.pdf” 文件
关键总结:
-
读取 pdf 文件,解析到每一页,遍历每一页的文本,解码,整合后存到一个 Document 对象中
-
通过 langchain 的 RecursiveCharacterTextSplitter 拆分为更细致的chunk,
-
Chroma.fromDocuments 向量化,并存入 chromaDB
-
similaritySearchWithScore 相似性检索
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献627条内容
已为社区贡献627条内容

所有评论(0)