LangChain智能文档助手【4】-向量存储与嵌入
这是一个基于 LangChain 框架和(Qwen)大语言模型构建的检索增强生成(RAG)智能问答系统的教程。该系统是基于最基础的功能点,如大语言模型调用,文档处理,嵌入模型向量化,向量存储和检索,智能对话构建而成,最后用streamlit生成一个web界面,将功能可视化。
这是一个基于 LangChain 框架和通义千问(Qwen)大语言模型构建的检索增强生成(RAG)智能问答系统的教程。该系统是基于最基础的功能点,如大语言模型调用,文档处理,嵌入模型向量化,向量存储和检索,智能对话构建而成,最后用streamlit生成一个web界面,将功能可视化。本篇为教程第四章,之前章节请参考:
https://blog.csdn.net/zx79122564/article/details/157181513?spm=1011.2124.3001.6209
https://blog.csdn.net/zx79122564/article/details/157181554?spm=1011.2124.3001.6209
https://blog.csdn.net/zx79122564/article/details/157257012?spm=1011.2124.3001.6209
————————————————
版权声明:本文为CSDN博主「小驴乖乖」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zx79122564/article/details/157257012
第四章 向量存储与嵌入
本节是整个 RAG 系统的向量存储核心,负责将文本转换为向量并构建可搜索的索引,按如下层级创建文件vector_store.py。

vector_store.py文件的完整代码如下:
# 文件: vector_store.py
import os
import pickle
from typing import List
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
import numpy as np
from openai import OpenAI
# 封装阿里云 DashScope 的嵌入服务,提供与 LangChain 兼容的接口
class DashScopeEmbeddings:
"""DashScope兼容的嵌入模型"""
def __init__(self, api_key: str = None):
self.api_key = api_key or os.getenv("DASHSCOPE_API_KEY")
self.client = OpenAI(
api_key=self.api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
self.model = "text-embedding-v2"
def __call__(self, text: str) -> List[float]:
"""使对象可调用,用于FAISS向量存储"""
return self.embed_query(text)
# 查询单个文本的嵌入
def embed_query(self, text: str) -> List[float]:
"""嵌入单个查询文本"""
try:
response = self.client.embeddings.create(
model=self.model,
input=text
)
return response.data[0].embedding
except Exception as e:
print(f"嵌入查询失败: {e}")
raise
# 查询批量文本的嵌入(效率更高)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""嵌入多个文档"""
try:
response = self.client.embeddings.create(
model=self.model,
input=texts
)
return [item.embedding for item in response.data]
except Exception as e:
print(f"嵌入文档失败: {e}")
raise
class QwenVectorStore:
"""通义千问向量存储管理器"""
def __init__(self, persist_dir: str = "./faiss_db_qwen"):
self.persist_dir = persist_dir
self.vectorstore = None
self.embeddings = None
self.qwen_client = None
def get_qwen_embeddings(self):
"""获取Qwen兼容的嵌入模型"""
try:
# 使用兼容DashScope的嵌入模型
embeddings = DashScopeEmbeddings()
print("✅ 使用DashScope兼容的嵌入模型")
self.embeddings = embeddings
return embeddings
except Exception as e:
print(f"❌ 加载嵌入模型失败: {e}")
return None
def create_vector_store(self, chunks: List[Document]):
"""创建向量存储"""
print(f"🛠️ 正在创建Qwen向量存储...")
# 获取嵌入模型
embeddings = self.get_qwen_embeddings()
if not embeddings:
return None
# 测试嵌入模型
print("🧪 测试嵌入模型...")
test_text = "通义千问大语言模型"
try:
test_vector = embeddings.embed_query(test_text)
print(f"✅ 嵌入模型测试成功,向量维度: {len(test_vector)}")
except Exception as e:
print(f"❌ 嵌入测试失败: {e}")
return None
# 创建FAISS向量存储
try:
self.vectorstore = FAISS.from_documents(
documents=chunks,
embedding=embeddings,
distance_strategy=DistanceStrategy.COSINE # 使用余弦相似度
)
# 保存到本地
self.vectorstore.save_local(self.persist_dir)
count = len(self.vectorstore.index_to_docstore_id)
print(f"✅ 向量存储创建成功")
print(f" 存储位置: {self.persist_dir}")
print(f" 文档数量: {count}")
print(f" 嵌入维度: {len(test_vector)}")
return self.vectorstore
except Exception as e:
print(f"❌ 创建向量存储失败: {e}")
return None
def load_existing_store(self):
"""加载已存在的向量存储"""
if not os.path.exists(self.persist_dir):
print(f"❌ 向量存储目录不存在: {self.persist_dir}")
return None
embeddings = self.get_qwen_embeddings()
if not embeddings:
return None
try:
self.vectorstore = FAISS.load_local(
folder_path=self.persist_dir,
embeddings=embeddings,
allow_dangerous_deserialization=True # 注意:加载本地文件需要这个参数
)
count = len(self.vectorstore.index_to_docstore_id)
print(f"✅ 加载现有向量存储成功")
print(f" 文档数量: {count}")
return self.vectorstore
except Exception as e:
print(f"❌ 加载向量存储失败: {e}")
return None
def similarity_search_with_qwen(self, query: str, k: int = 3):
"""使用Qwen增强的相似性搜索"""
if not self.vectorstore:
print("❌ 向量存储未初始化")
return []
print(f"🔍 搜索查询: '{query}'")
# 1. 基本相似度搜索
results = self.vectorstore.similarity_search(query, k=k)
print(f"✅ 找到 {len(results)} 个相关文档")
# 2. 使用Qwen重新排序(可选)
if len(results) > 1:
print("🧠 使用Qwen进行相关性重排序...")
try:
# 构建重排序提示
docs_text = "\n\n".join([
f"[文档{i+1}]: {doc.page_content[:200]}..."
for i, doc in enumerate(results)
])
prompt = f"""请根据查询的相关性对以下文档进行排序:
查询:{query}
文档列表:
{docs_text}
请返回最相关的3个文档的编号(如:2,1,3):"""
# 调用Qwen进行重排序
response = self.qwen_client.chat_completion([
{"role": "user", "content": prompt}
])
print(f"🤖 Qwen重排序建议: {response}")
except Exception as e:
print(f"⚠️ 重排序失败: {e}")
return results
def analyze_vector_space(self):
"""分析向量空间"""
if not self.vectorstore or not hasattr(self.vectorstore, 'index'):
return
try:
count = len(self.vectorstore.index_to_docstore_id)
print(f"\n📈 向量空间分析:")
print(f" 总向量数: {count}")
if count > 0:
# 获取向量维度
if hasattr(self.vectorstore.index, 'd'):
print(f" 向量维度: {self.vectorstore.index.d}")
# 获取索引类型
print(f" 索引类型: {type(self.vectorstore.index).__name__}")
# 如果是Flat索引,显示配置
if hasattr(self.vectorstore.index, 'metric_type'):
print(f" 距离度量: {self.vectorstore.index.metric_type}")
except Exception as e:
print(f"⚠️ 空间分析失败: {e}")
def similarity_search_with_score(self, query: str, k: int = 3):
"""带分数的相似度搜索"""
if not self.vectorstore:
return []
docs_with_scores = self.vectorstore.similarity_search_with_score(query, k=k)
return docs_with_scores
def main():
print("🎯 第4章:Qwen向量存储(使用FAISS)")
print("=" * 50)
from qwen_client import QwenClient
# 初始化Qwen客户端
qwenClient= QwenClient()
if not qwenClient.test_connection():
return
# 加载分割后的文档
print("\n📂 加载文档块...")
try:
with open("data/document_chunks.pkl", "rb") as f:
chunks = pickle.load(f)
print(f"✅ 加载 {len(chunks)} 个文档块")
except FileNotFoundError:
print("❌ 请先运行第3章代码")
return
# 创建向量存储管理器
vector_manager = QwenVectorStore(persist_dir="./faiss_db_qwen")
# 检查是否已存在向量存储
if os.path.exists("./faiss_db_qwen"):
use_existing = input("检测到现有向量存储,是否重新创建?(y/n): ").lower()
if use_existing == 'n':
vectorstore = vector_manager.load_existing_store()
else:
vectorstore = vector_manager.create_vector_store(chunks)
else:
vectorstore = vector_manager.create_vector_store(chunks)
if not vectorstore:
print("❌ 向量存储创建失败")
return
# 分析向量空间
vector_manager.analyze_vector_space()
# 测试搜索功能
print("\n🔍 测试语义搜索...")
test_queries = [
"通义千问是什么?",
"LangChain如何集成Qwen?",
"什么是检索增强生成?"
]
for query in test_queries:
print(f"\n📝 查询: '{query}'")
results = vector_manager.similarity_search_with_qwen(query, k=2)
for i, doc in enumerate(results):
print(f" [{i+1}] {doc.page_content[:100]}...")
# 测试带分数的搜索
print("\n📊 测试带分数的搜索...")
query = "通义千问的主要功能"
results_with_scores = vector_manager.similarity_search_with_score(query, k=2)
for i, (doc, score) in enumerate(results_with_scores):
print(f" [{i+1}] 相似度: {score:.4f} - {doc.page_content[:80]}...")
print("\n" + "=" * 50)
print("✅ 第4章完成!Qwen向量存储(FAISS)已准备就绪")
if __name__ == "__main__":
main()
运行代码
python src/vector_store.py代码解析
- 本节功能的流程图
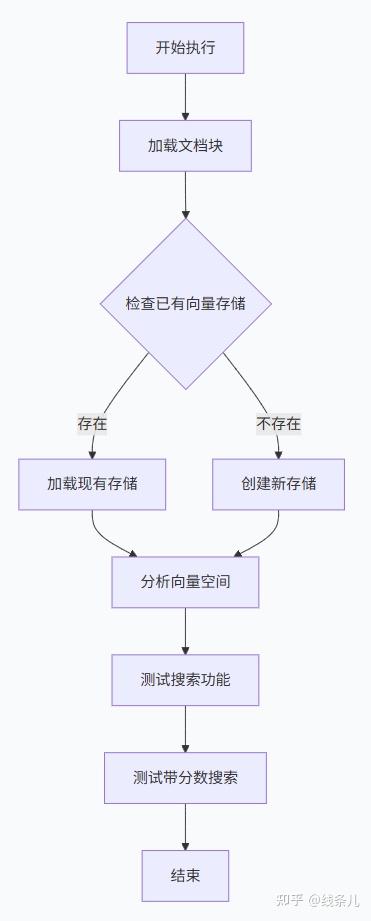
数据流
用户文档
↓
文档分割 (chunks)
↓
嵌入模型 → (调用 text-embedding-v2) 转换为向量 [v1, v2, ..., v1536]
↓(存储到 FAISS)
FAISS索引构建
↓
保存到磁盘 (index.faiss + .pkl)
↓
--- 使用阶段 ---
用户查询
↓
查询嵌入(同样的嵌入模型) → 查询向量
↓
FAISS相似度搜索 (注意,一般rag检索流程中,用户的查询向量不会被持久化存储到向量数据库中),
↓
返回最相似的文档块
↓
(可选) Qwen重排序
↓
最终结果主要功能点

2. 核心类的功能分解
(1)DashScopeEmbeddings 类(嵌入模型层)
用户查询/文本输入
↓
┌──────────────────┐
│ DashScopeEmbeddings │
├──────────────────┤
│ • init(): 初始化 │
│ • __call__(): 调用 │
│ • embed_query(): 单文本│
│ • embed_documents(): 批量│
└──────────────────┘
↓
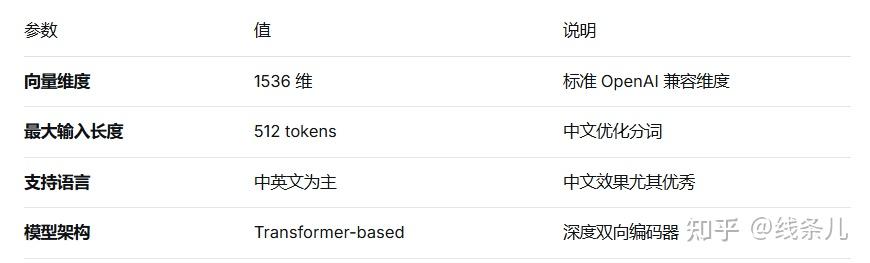
生成向量 (List[float])本节使用的嵌入模型是阿里云的text-embedding-v2模型,它的部署平台为阿里云灵积平台(DashScope),我们采用OpenAI兼容接口接入。
text-embedding-v2模型基础参数
(2)QwenVectorStore 类(向量存储管理层)
初始化 QwenVectorStore
│
├──▶ get_qwen_embeddings()
│ └──▶ DashScopeEmbeddings()
│
├──▶ create_vector_store(chunks)
│ ├──▶ 测试嵌入模型
│ ├──▶ FAISS.from_documents()
│ ├──▶ vectorstore.save_local()
│ └──▶ 返回向量存储
│
├──▶ load_existing_store()
│ ├──▶ os.path.exists() 检查
│ ├──▶ FAISS.load_local()
│ └──▶ 返回向量存储
│
├──▶ similarity_search_with_qwen(query)
│ ├──▶ vectorstore.similarity_search()
│ ├──▶ (可选)Qwen重排序
│ └──▶ 返回结果
│
├──▶ similarity_search_with_score(query)
│ └──▶ vectorstore.similarity_search_with_score()
│
└──▶ analyze_vector_space()
└──▶ 分析向量维度/数量等a. FAISS的使用:
本项目中相关代码
# 从你的代码中提取的FAISS使用
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
# 创建FAISS向量库
vectorstore = FAISS.from_documents(
documents=chunks, # Document对象列表
embedding=embeddings, # 嵌入模型
distance_strategy=DistanceStrategy.COSINE # 距离度量
)
# 保存到磁盘
vectorstore.save_local(folder_path="./faiss_db")
# 从磁盘加载
vectorstore = FAISS.load_local(
folder_path="./faiss_db",
embeddings=embeddings,
allow_dangerous_deserialization=True # 注意安全风险
)b. similarity_search_with_qwen(query)
这个方法功能为增强版语义搜索方法,结合了FAISS向量搜索和Qwen大模型的重排序能力。
完整的执行流程:
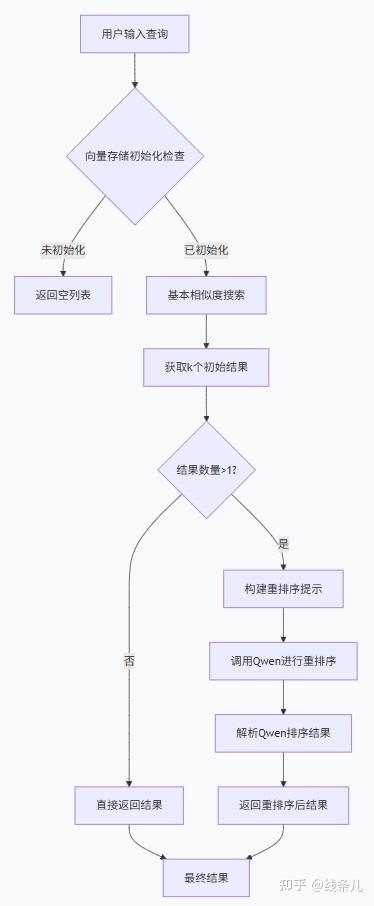
基础向量搜索:
相关代码
# 1. 基本相似度搜索
results = self.vectorstore.similarity_search(query, k=k)
print(f"✅ 找到 {len(results)} 个相关文档")
底层逻辑:
查询文本 → 嵌入模型 → 查询向量 → FAISS索引 → 余弦相似度计算 → 返回top-k文档使用Qwen语言模型重新排序:
相关代码
# 2. 使用Qwen重新排序(可选)
if len(results) > 1:
print("🧠 使用Qwen进行相关性重排序...")
try:
# 构建重排序提示
docs_text = "\n\n".join([
f"[文档{i+1}]: {doc.page_content[:200]}..."
for i, doc in enumerate(results)
])
构建prompt和调用Qwen:
prompt = f"""请根据查询的相关性对以下文档进行排序:
查询:{query}
文档列表:
{docs_text}
请返回最相关的3个文档的编号(如:2,1,3):"""
# 调用Qwen进行重排序
response = self.qwen_client.chat_completion([
{"role": "user", "content": prompt}
])
print(f"🤖 Qwen重排序建议: {response}")c. similarity_search_with_score(query)
这是标准的带相似度分数的语义搜索方法,返回文档及其与查询的量化相似度分数。
相关代码块:
def similarity_search_with_score(self, query: str, k: int = 3):
"""带分数的相似度搜索"""
if not self.vectorstore:
return []
docs_with_scores = self.vectorstore.similarity_search_with_score(query, k=k)
return docs_with_scores代码底层逻辑
# LangChain FAISS 内部实现模拟
def similarity_search_with_score_implementation(query: str, k: int):
# 1. 查询向量化
query_vector = embeddings.embed_query(query) # 1536维向量
# 2. FAISS 相似度搜索
# distances: 距离分数列表(越小越相似)
# indices: 对应文档的索引
distances, indices = index.search(np.array([query_vector]), k)
# 3. 获取文档内容
docs = []
for idx, distance in zip(indices[0], distances[0]):
doc_id = index_to_docstore_id[idx]
document = docstore.search(doc_id)
# 4. 转换距离为相似度分数
# FAISS返回的是距离,LangChain转换为相似度
similarity_score = self._distance_to_similarity(distance)
docs.append((document, similarity_score))
return docs返回值格式
# 返回类型: List[Tuple[Document, float]]
[
(Document1, 0.95), # 相似度0.95(非常相关)
(Document2, 0.82), # 相似度0.82(比较相关)
(Document3, 0.61), # 相似度0.61(一般相关)
...
]距离度量的类型
# 取决于FAISS索引配置的distance_strategy
class DistanceStrategy:
COSINE = "余弦相似度" # 分数范围: -1到1,通常转换到0-1
EUCLIDEAN = "欧几里得距离" # 分数范围: 0到∞,越小越好
DOT_PRODUCT = "点积" # 分数范围: -∞到∞
# 本文使用的是余弦相似度
vectorstore = FAISS.from_documents(
distance_strategy=DistanceStrategy.COSINE # ← 这里
)
d. analyze_vector_space()
这是我们自定义的向量空间分析方法,用于分析和诊断FAISS向量存储的内部状态和性能指标。
方法输出的空间分析示例:
# 输出示例:
📈 向量空间分析:
总向量数: 1527
向量维度: 1536
索引类型: IndexFlatIP
距离度量: METRIC_INNER_PRODUCT总向量数 (index_to_docstore_id)
# 这个属性存储了索引到文档的映射
count = len(self.vectorstore.index_to_docstore_id)
# 结构示例:
index_to_docstore_id = {
0: "doc_001", # 索引0对应文档ID "doc_001"
1: "doc_002", # 索引1对应文档ID "doc_002"
2: "doc_003", # 索引2对应文档ID "doc_003"
# ...
}
# 重要性:
# - 确认数据是否成功加载
# - 监控数据增长
# - 评估存储需求向量维度 (index.d)
# FAISS索引的维度属性
if hasattr(self.vectorstore.index, 'd'):
dimension = self.vectorstore.index.d # 例如: 1536
# 重要性:
# - 验证嵌入模型一致性
# - 确保查询向量维度匹配
# - 影响搜索性能和内存使用
问题1: 什么是嵌入模型和数据库向量维度一致性?
❌ 不一致的情况:
嵌入模型 text-embedding-v2 → 输出1536维向量
FAISS索引配置 → 期望768维向量
结果:🚨 维度不匹配错误!
✅ 一致的情况:
嵌入模型 text-embedding-v2 → 输出1536维向量
FAISS索引配置 → 期望1536维向量
结果:✅ 正常工作
问题2:text-embedding-v2 输出维度是一个固定值还是一个范围?FAISS索引配置呢?
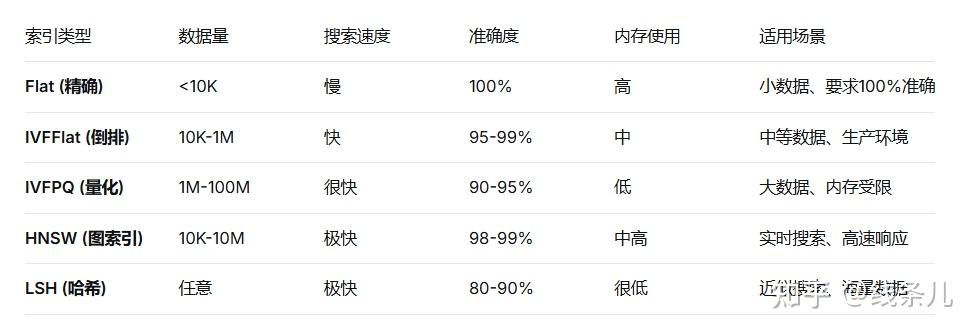
模型输出维度是一个固定值;FAISS索引维度是创建时确定的,创建时要和嵌入模型输出维度保持一致索引类型 (type(index).__name__)
# 获取索引的类名
index_type = type(self.vectorstore.index).__name__
# 常见FAISS索引类型:
# - IndexFlatL2: 精确L2距离搜索
# - IndexFlatIP: 精确内积(余弦)搜索
# - IndexIVFFlat: 倒排文件索引
# - IndexIVFPQ: 乘积量化索引
# - IndexHNSWFlat: 层次可导航小世界图
问题:索引类型有什么重要影响?
距离度量 (index.metric_type)
# FAISS支持的距离度量类型
if hasattr(self.vectorstore.index, 'metric_type'):
metric = self.vectorstore.index.metric_type
# 常见值:
# faiss.METRIC_L2: 欧氏距离
# faiss.METRIC_INNER_PRODUCT: 内积(用于余弦相似度)
metric_names = {
0: "METRIC_L2 (欧氏距离)",
1: "METRIC_INNER_PRODUCT (内积)"
}
print(f"距离度量: {metric_names.get(metric, metric)}")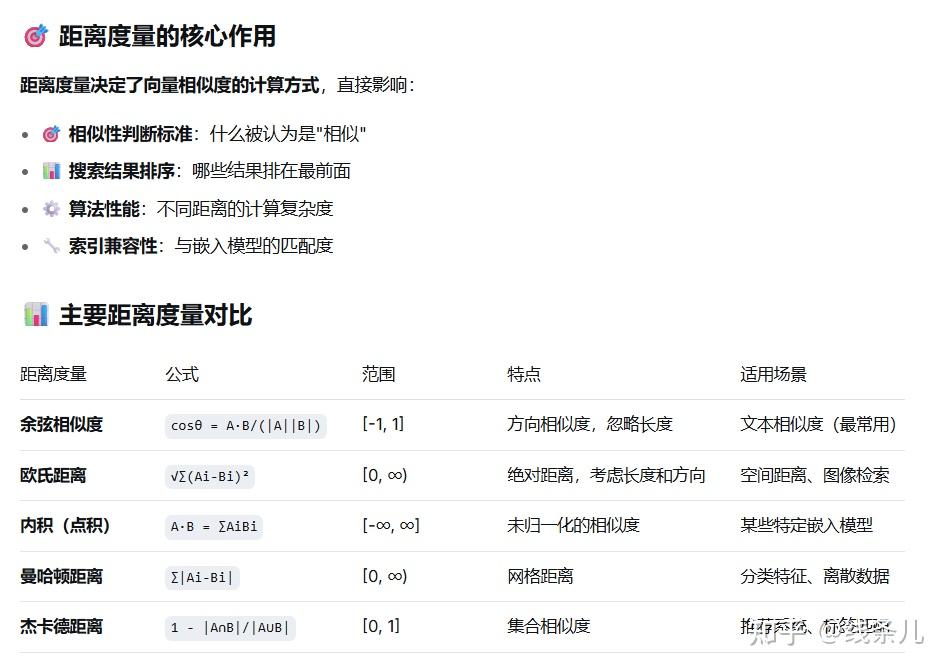
完成本章课程,即完成了向量嵌入和存储,本文也包括了部分索引的内容。下一章会介绍更多索引方法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)