RAG技术yyds!两篇必读论文带你从小白到大神,大模型开发必看干货!
文章详解两篇RAG经典论文:EasyRAG(轻量高效的自动化网络运维框架)和Modular RAG(模块化乐高式RAG架构)。解析了数据摄入、查询重写、双路检索、重排序、答案生成等核心技术模块,以及线性、条件、分支、循环等流程设计模式,为RAG开发者提供全面的技术指导和实践参考。
嗨,大家好,近期Move37将通过多篇文章连载方式,详细讲解RAG的发展过程和技术演变,并讲解这个过程中的经典论文。今天主要推荐两篇经典的RAG框架论文,也是RAG必读论文。
07
RAG框架和实践
7.1 Easy RAG
《EasyRAG: Efficient Retrieval-Augmented Generation Framework for Automated Network Operations》是北京航空航天大学张日崇教授团队,在2024年第七届CCF国际AIOps挑战赛(https://competition.aiops-challenge.com)的季军方案,目标是针对自动化网络运维(AIOps)场景设计的简单、轻量且高效的RAG框架。EasyRAG主要包括数据摄入(Ingestion)和RAG流程(RAG Pipeline)两部分,架构图如下。
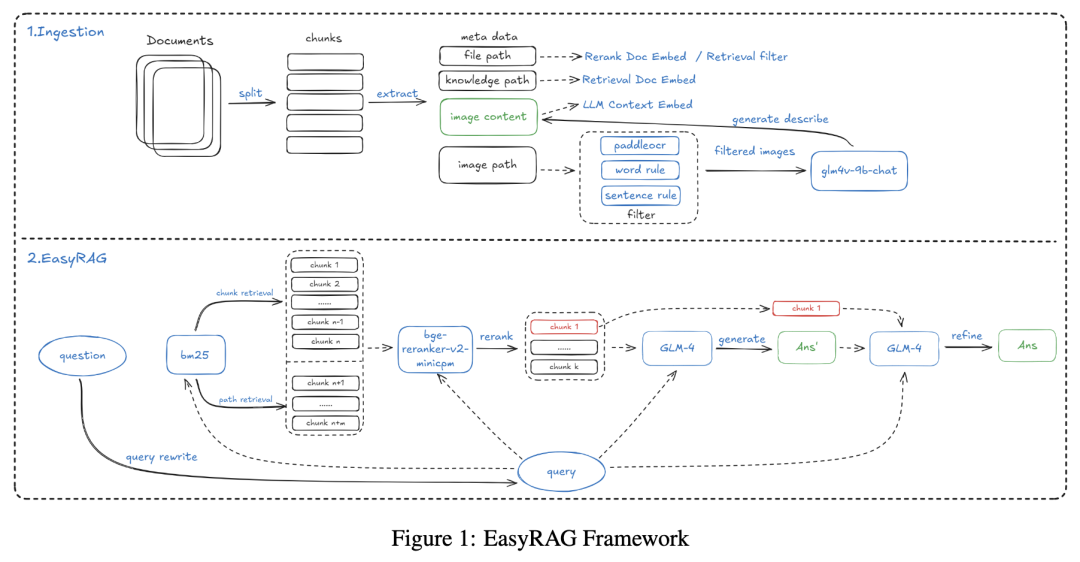
I 数据摄入Ingestion包括3步
- Zedx文件处理,包括zedx文件解压、路径解析、使用BeautifulSoup提取文本/图片/路径、保存;
- **Text Segmentation,**使用 SentenceSplitter(块大小1024,重叠200);
- 图片信息抽取,使用GLM-4V-9B 大模型提取图片描述,同时发现少量图片对最终问答有益,但并非所有图片都有用,因此设计一些策略,将图片数量从原始的 6000 张减少到不足 200 张。
II RAG Pipeline分为7个工作
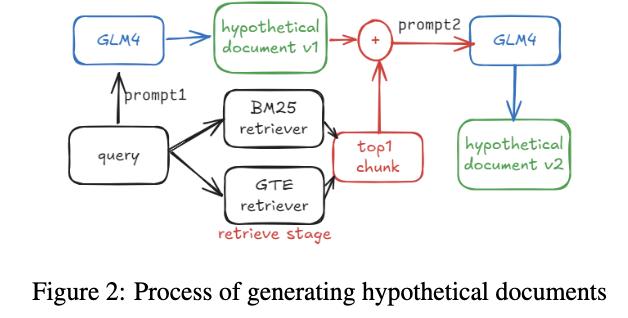
1.Query Rewriting
- 使用GLM4对Query进行重写,对运维和通信领域的关键词进行联想和摘要;
- HyDE生成虚构文档,为了减少大模型幻觉带来的干扰,使用BM25和稠密检索找到最相关的Top1文档作为上下文提示,来生成更准确的虚构文档。
2.双路稀疏检索后粗排
-
中文Tokenizer:使用jieba分词器,切分后的文本块Embedding存储在Qdrant向量数据库中
-
停用词表:哈尔滨工业大学的中文停用词表
-
双路重排
-
文本块检索:使用BM25计算Query和chunks的相似度,召回粗排分数大于0的前192个文本块。
-
路径检索:文档路径的存放路径本身就包含非常有用的信息,如“VNF弹性有哪些类型?”的问题,其中关键字VNF、弹性等在路径中的匹配度比正文还要高,所以作者设计了基于BM25的路径搜索,召回前6个chunks。
3.稠密检索后粗排
用于粗排的稠密检索使用了gte-Qwen2-7B-instruct模型(该模型在MTEB基准测试中取得了优异的结果),检索时召回前288个文本块。
4.LLM Reranker
使用bge-reranker-v2-minicpm-layerwise模型,将查询与粗排得到的文本块配对输入LLM,根据得分排序,返回前k个(通常为6个)文本块。
5.多路Ranking融合
5.1 融合算法
- 简单合并:比如A路找来[1, 2, 3],B路找来[3, 4, 5],则直接合并然后去重,结果为[1, 2, 3, 4, 5]。
- RRF(Reciprocal Rank Fusion)算法
5.2 粗排融合
发生在Retrival之后,Reranking之前,将两路稀疏检索后结果宋Reranker。
5.3 Reranking融合
发生在Reranking之后,LLM生产答案之前,将两路Reranker获取的Top k结果进行融合,方式包括:
1.RRF;
2.让LLM根据两路分别生成答案,暴力选取答案长的那个;
3.答案拼接,LLM分别生成答案后直接将两个答案拼接返回。
- LLM答案生成
将重排后的Top 6文本块内容拼接(包含图片内容),结合问题输入GLM4生成答案。作者还尝试了思维链(CoT)、Markdown 格式和聚焦型问答模板,但发现简单模板效果最好。
- LLM答案优化
作者观察到LLM处理多文本块时候,会导致Top1文本块的有效信息未被充分利用。因此,他们将Top1文本块来补充和优化从6个文本块得出的答案,有效提升了答案生成的准确性。
EasyRAG提供了一个无需微调、即插即用的高性能RAG方案,不仅在比赛中非常有效,也特别适合实际的工业界部署。文章源代码:
https://github.com/BUAADreamer/EasyRAG
文章《EasyRAG: Efficient Retrieval-Augmented Generation Framework for Automated Network Operations》地址:
https://arxiv.org/abs/2410.10315
7.2 Modular RAG
《Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Framework》是出自同济大学高云帆和复旦大学熊赟团队,该文章是一篇RAG技术综述文章,提出了模块化(Modular RAG)的新范式,将复杂的RAG系统解构为独立的模块,就像搭乐高积木一样可以灵活配置和重组,是做RAG开发的必读论文。
1.作者将Modular RAG分为三层架构:
L1 模块:RAG的各个关键阶段,每个阶段被视为一个独立的模块。这一层不仅继承了高级RAG范式的流程,还引入了一个编排模块来控制RAG流程的协同工作。
L2 子模块:每个模块内的子模块,进一步精炼和优化模块功能。
L3 算子:是基本的操作单元。
一个典型的Modular RAG的流程框架如下所示:
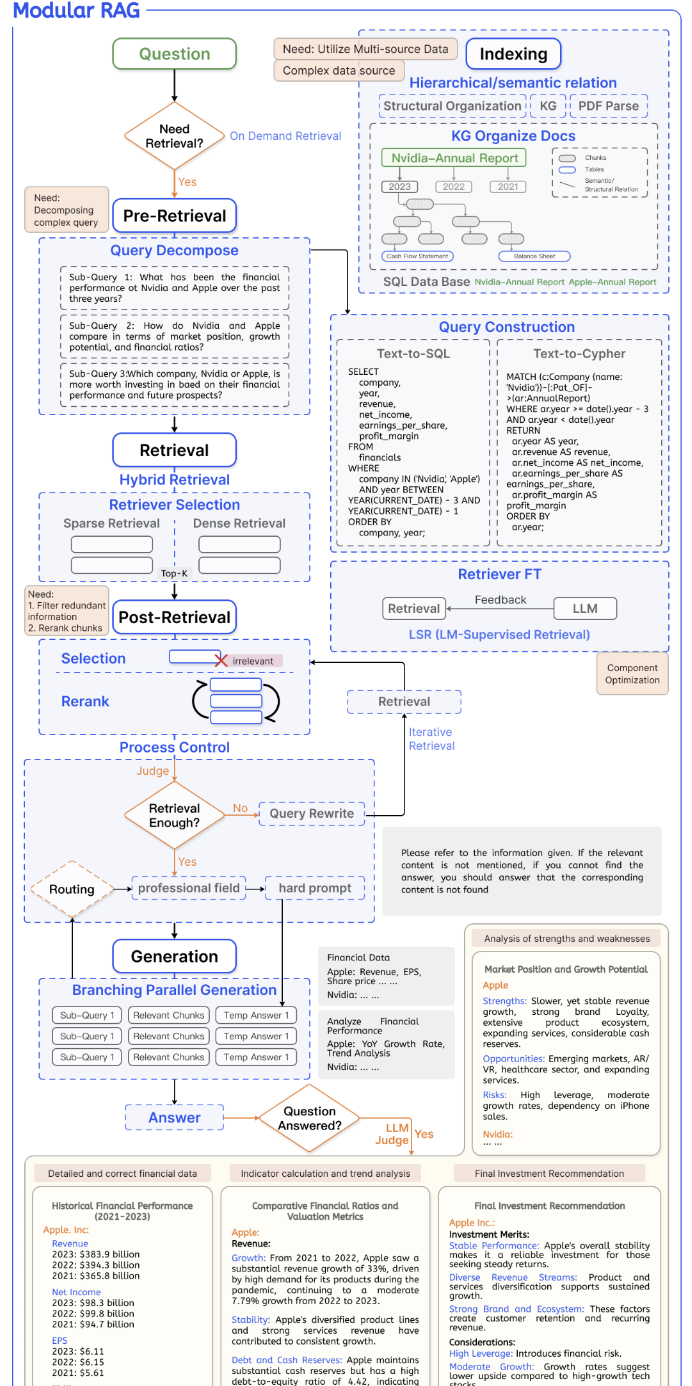
- Modular RAG包括5大核心模块
这个图能够详细解释Modular RAG的5个阶段核心模块
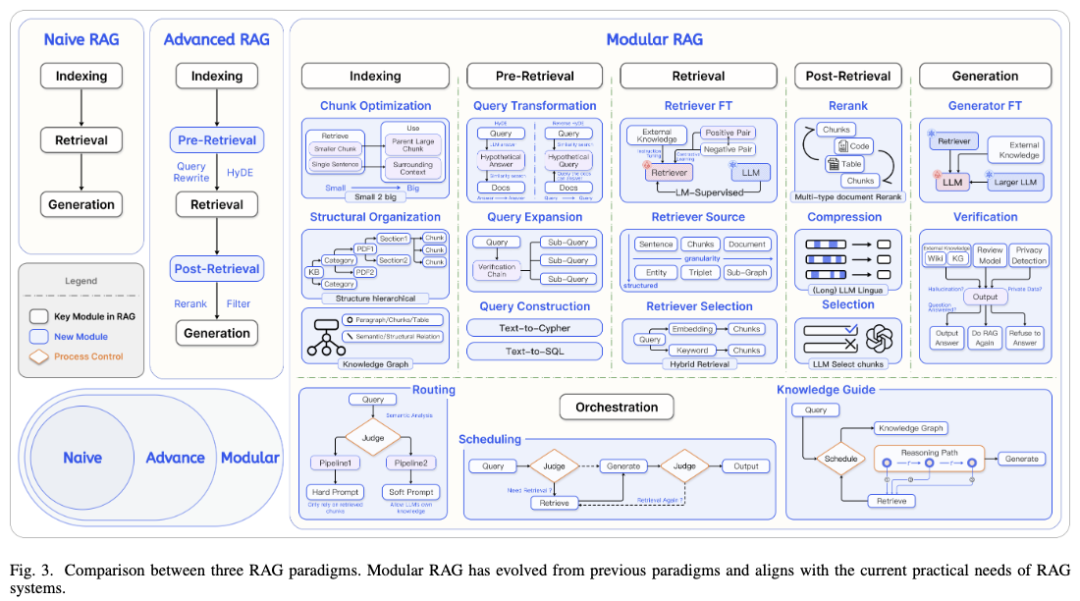
2.1 Indexing 索引
索引Indexing是将文档拆分为可管理的文本块chunks的过程,通常需要开展的工作包括:
2.1.1 切片优化(Chunk Optimization):
切片大小以及切片之间的重叠度在对RAG的有效性起着至关重要的作用。较大的切片能够捕捉更丰富的上下文,但也同时引入了更多的噪声和较长的处理时间;较小的切片上下文丰富度不够,但噪声较少。具体的切片方法包括:
- 滑动窗口:相比于语句直接截断,通过重叠部分解决语义衔接的问题,但依然缺乏对文本实际语义的理解
- 元数据附加(Metadata Attachment):chunks可以附上如页码、文件名、作者、时间戳、摘要等信息,将这些元数据加入过滤检索能够缩小搜索范围,获得更优结果
- Small-to-Big:较小的块能够提高检索(Retrieval)精度,但是越大的块能够给生成增加丰富度。所以Small-to-Big将用来“检索”的内容和用来“给AI生成”的内容分离开,具体有两种方式:
-
i.父文档检索:先把文档切成很大的父块,然后再把父块切成很多子块并Embedding进向量数据库,索引时候对子块进行索引,然后通过ID找到对应父块内容,再把父块喂给LLM
-
ii.句子窗口检索:更极致的一种做法,以单个句子作为单位进行向量化存储;然后匹配最相似的句子,检索到句子后系统自动把句子前后扩展N个句子(比如前5句+后5句),把一大段完整的上下文拼出来喂给LLM
2.1.2 结构化组织(Structure Organization):
增强信息检索的一种非常有效的方法是为文档建立层级结构,通过构建chunks结构,RAG系统可以加快相关数据检索和处理速度,主要包括:
- 层级索引(Hierarchical Index):在文档的层级结构中,节点按父子关系排列,文档与这些节点相连。每个节点都存储数据摘要,有助于快速遍历数据,并协助RAG系统确定需提取哪些块。
- 知识图谱索引(KG Index):利用知识图谱结构化文档,建立语义网络。
2.2 Pre-retrieval
构建一个清晰且精确的问题是比较困难的,直接将用户的查询用于检索通常效果不佳。这里面可能是因为问题比较复杂,无法用简单的语言描述;或一些语言有二义性,比如法律相关LLM可能代表了大预言模型或法律学硕士(Master of Laws),具体的处理方法包括如下。
2.2.1 查询扩展(Query Expansion):
将单个查询扩展为多个查询可以丰富查询的内容,提供更多上下文以解决特定细微差别的缺失,从而确保生成答案的最佳相关性。
- Multi-Query (多查询):利用 Prompt 工程通过 LLM 扩展查询,允许并行执行。这种方法可能会稀释用户的原始意图,为缓解这一问题,可以指示模型赋予原始查询更大的权重。
- Sub-Query (子查询):通过对复杂问题进行分解和规划,生成多个子问题。具体来说,可以使用“least-to-most prompting” 将复杂问题分解为一系列更简单的子问题。根据原始问题的结构,生成的子问题可以并行或顺序执行。另一种方法涉及使用验证链(Chain-of-Verification, CoVe)。扩展后的查询经过 LLM 验证,以达到减少幻觉的效果。
2.2.2 Query Transformation (查询转换)
- Rewrite (重写):在现实场景中,原始查询往往不足以进行检索。为解决此问题,可以提示 LLM 进行重写,也可以为此使用专门的小型模型。
- HyDE (假设文档嵌入) :为了弥合问题和答案之间的语义鸿沟,它在响应查询时构建假设性文档(假定的答案),而不是直接搜索查询本身。它关注的是“答案到答案”的嵌入相似性,而不是寻找问题或查询的嵌入相似性。此外,它还包括 Reverse HyDE,即为每个文档块生成假设性查询,关注“查询到查询”的检索。
- Step-back Prompting (后退一步提示) :将原始查询抽象为一个高层次的概念问题(后退问题)。在 RAG 系统中,后退问题和原始查询都被用于检索,它们的结果被结合起来生成语言模型的答案。
2.2.3 Query Construction (查询构造)
除了文本数据外,越来越多的结构化数据(如表格和图数据)正被集成到 RAG 系统中。为了适应各种数据类型,有必要重构用户的查询。这涉及将查询转换为另一种查询语言以访问替代数据源,常见方法包括Text-to-SQL或Text-to-Cypher。在许多场景中,结构化查询语言(如 SQL, Cypher)常与语义信息和元数据结合使用,以构建更复杂的查询。
2.3 Retrieval
检索过程在 RAG 系统中至关重要。利用强大的Embedding模型,可以在潜在空间中高效地表示Query和文本,从而建立问题与文档之间的语义相似度,增强检索效果。该模块需要解决的三个主要考量包括:检索效率、质量,以及任务、数据和模型之间的对齐。
2.3.1 检索器选择 (Retriever Selection):
随着 RAG 技术的广泛应用,嵌入模型的发展如火如荼。除了基于统计学的传统模型和基于编码器结构的预训练模型外,基于大语言模型(LLM)微调的嵌入模型也展现出了强大的能力。然而,它们通常参数更多,导致推理和检索效率较弱。因此,根据不同的任务场景选择合适的检索器至关重要。
- 稀疏检索器 (Sparse Retriever): 使用统计方法将查询和文档转换为稀疏向量。其优势在于处理大规模数据集时的效率,仅关注非零元素。然而,在捕捉复杂语义方面,它可能不如密集向量有效。常见的方法包括 TF-IDF 和 BM25。
- 稠密检索器 (Dense Retriever): 采用预训练语言模型(PLMs)提供查询和文档的密集表示。尽管计算和存储成本较高,但它提供了更复杂的语义表示。典型的模型包括 BERT 结构的 PLMs(如 ColBERT)以及多任务微调模型(如 BGE 和 GTE)。
- 混合检索器 (Hybrid Retriever): 同时使用稀疏和密集检索器。两种嵌入技术相互补充以增强检索效果。稀疏检索器可以提供初步筛选结果。此外,稀疏模型增强了密集模型的zero-shot检索能力,特别是在处理包含罕见实体的查询时,从而提高了系统的鲁棒性。
2.3.2 检索器微调 (Retriever Fine-tuning) :
当上下文与预训练语料库存在差异时,特别是在医疗、法律等充满专有术语的高度专业化领域,微调就显得尤为重要。虽然这种调整需要额外的投入,但它可以显著提高检索效率和领域对齐度。
- 有监督微调 (Supervised Fine-Tuning, SFT): 基于标记的领域数据微调检索模型通常使用对比学习(Contrastive Learning),这涉及缩短正样本之间的距离,同时增加负样本之间的距离。
- 语言模型监督检索器 (LM-supervised Retriever, LSR): 与直接从数据集构建微调数据集不同,LSR 利用 LM 生成的结果作为监督信号,在 RAG 过程中微调嵌入模型。
- 适配器 (Adapter): 有时微调大型检索器成本高昂,特别是在处理基于 LLM 的检索器(如 gte-Qwen)时。在这种情况下,可以通过加入适配器模块(Adapter Module)并进行微调来缓解这一问题。添加适配器的另一个好处是能够更好地与特定的下游任务对齐。
2.4 Post-retrieval
将所有检索到的文本块(chunks)直接输入到 LLM 中并不是一个最佳选择。对这些文本块进行后处理可以帮助更好地利用上下文信息。面临的主要挑战包括:
-
迷失中间 (Lost in the middle): 就像人类一样,LLM 往往只记得长文本的开头或结尾,而容易忘记中间部分的内容。
-
噪声/反事实文本块 (Noise/anti-fact chunks): 检索到的包含噪声或与事实相矛盾的文档会影响最终的生成结果。
-
上下文窗口 (Context Window): 尽管检索到了大量相关内容,但大模型的上下文长度限制使得我们无法将所有这些内容都包含进去。
针对这些挑战,主要有以下几种处理方法:
2.4.1 Rerank (重排序)
在不改变内容或长度的情况下对检索到的文本块进行重新排序,以提高关键文档块的可见性。方式包括:
- Rule-base rerank (基于规则的重排序) 根据特定规则计算指标来对文本块进行重排序。常见的指标包括:多样性(diversity)、相关性(relevance)和 MMR (最大边界相关算法)。其核心理念是减少冗余并增加结果的多样性。MMR 基于查询相关性和信息新颖性的综合标准,为最终的关键短语列表选择短语。
- Model-base rerank (基于模型的重排序) 利用语言模型来对文档块进行重新排序,通常基于文本块与查询之间的相关性。重排序模型(Rerank models)已成为 RAG 系统的重要组成部分,相关模型技术也在不断迭代升级。重排序的范围也已扩展到表格和图像等多模态数据。
2.4.2 Compression (压缩)
在 RAG 流程中,一个常见的误区是认为检索尽可能多的相关文档并将它们拼接成一个冗长的检索prompt是有益的。然而,过多的上下文会引入更多的噪声,从而削弱 LLM 对关键信息的感知能力。解决这一问题的常见方法是对检索到的内容进行压缩。
(Long)LLMLingua 是一个典型的案例,它通过利用经过对齐和训练的小型语言模型(例如 GPT-2 Small 或 LLaMA-7B),该方法能够实现对提示词(prompt)中不重要 Token 的检测与移除。这将提示词转换成一种人类难以理解但 LLM 却能很好理解的形式。这种方法提供了一种直接且实用的提示词压缩手段,既不需要对目标LLM 进行额外的训练,又能在语言完整性和压缩率之间取得平衡。
2.4.3 Selection (选择)
与压缩文档块的内容不同,Selection (选择) 是直接移除不相关的文档块。
- Selective Context (选择性上下文): 通过识别并移除输入上下文中的冗余内容,使输入得到精炼,从而提高语言模型的推理效率。在实践中,Selective Context 基于基础语言模型计算的自信息 (self-information) 来评估词汇单元的信息含量。通过保留具有较高自信息的内容,该方法提供了一种更简洁、高效的文本表示,且不会牺牲其在不同应用中的性能。然而,它的缺点是忽略了被压缩内容之间的相互依赖性,以及用于压缩的小型语言模型与目标语言模型之间的对齐问题。
- LLM-Critique (LLM 批判/评审): 另一种直接且有效的方法是让 LLM 在生成最终答案之前评估检索到的内容。这允许 LLM 通过自我批判 (LLM critique) 过滤掉相关性差的文档。
2.5 Generation
利用大语言模型(LLM)根据用户的查询和检索到的上下文信息生成答案。根据任务需求选择合适的模型,需要考虑是否需要微调、推理效率以及隐私保护等因素。
2.5.1 生成器微调 (Generator Fine-tuning)
除了直接使用 LLM 外,根据场景和数据特征进行有针对性的微调可以获得更好的结果。这也是使用本地部署 LLM 的最大优势之一。
-
指令微调 (Instruct-Tuning):
当 LLM 缺乏特定领域的数据时,可以通过微调为 LLM 提供额外的知识,通用的微调数据集也可以作为初始步骤。微调的另一个好处是能够调整模型的输入和输出。例如,它可以使 LLM 适应特定的数据格式,并按照指令生成特定风格的响应。
-
强化学习 (Reinforcement learning):
通过强化学习将 LLM(大语言模型)的输出与人类或检索器的偏好对齐是一种潜在的方法。例如,对最终生成的答案进行人工标注,然后通过强化学习提供反馈。除了与人类偏好对齐外,还可以与微调后的模型和检索器的偏好进行对齐。
-
双重微调 (Dual Fine-tuning):
同时微调生成器和检索器,以对齐它们的偏好,一种典型的方法如 RA-DIT。
2.5.2 验证 (Verification)
虽然 RAG 增强了 LLM 生成答案的可靠性,但在许多场景中,仍需最大限度地减少幻觉的概率。因此,可以通过额外的验证模块过滤掉不符合标准的回答。常见的验证方法包括基于知识库的验证和基于模型的验证。
- **基于知识库的验证 (Knowledge-base verification):**指通过外部知识直接验证 LLM 生成的回答。通常,它首先从回答中提取特定的陈述(statements)或三元组(triplets)。然后,从经过验证的知识库(如维基百科或特定的知识图谱)中检索相关证据。最后,将每个陈述与证据逐一比较,以确定该陈述是被支持、反驳,还是信息不足。
- **基于模型的验证 (Model-based verification):**指使用一个小型的语言模型来验证 LLM 生成的回答。给定输入问题、检索到的知识和生成的答案,训练一个小模型来判断生成的答案是否正确反映了检索到的知识。这个过程通常被构建为一个多项选择题,验证器需要判断答案是否反映了正确内容。如果生成的答案没有正确反映检索到的知识,答案可以迭代重新生成,直到验证器确认答案正确为止。
2.6 Orchestration (编排/调度)
编排模块主要负责控制 RAG 系统内的流程执行。虽然朴素 RAG(Naive RAG)遵循固定的“检索-阅读”流程,但模块化 RAG 拥有灵活的决策机制,可以根据输入和上下文动态选择路径。
2.6.1 路由 (Routing)
为了应对多样化的Query,RAG 系统会将其路由到针对不同场景定制的Pipeline,这是构建能够处理各种情况的通用 RAG 架构的基本特征。系统需要一个决策机制,根据模型输入或补充元数据来确定将启用哪些模块。针对不同的Prompt,采用不同的路由路径。
- 元数据路由 (Metadata routing) 涉及从查询中提取关键词或实体,并利用这些关键词和Chunks中的关联元数据进行过滤,以优化路由参数
- 语义路由 (Semantic routing) 基于查询的语义信息将其路由到不同的模块
- 混合路由 (Hybrid Routing) 可以通过整合语义分析和基于元数据的方法来改进查询路由
2.6.2 调度(Scheduling)
随着RAG系统的复杂度和适应性方面的进化,具备了通过复杂调度模块管理流程的能力。调度主要负责:
- 识别关键节点:判断何时需要进行外部数据检索
- 评估响应质量:评估生成回答是否充分
- 决策进一步调查:决定是否有必要进一步探索
通常用于递归 (Recursive)、迭代 (Iterative) 和自适应 (Adaptive) 检索的场景中,确保系统能够就是否停止生成或启动新的检索循环做出明智的决策。调度的主要方法包括:
-
规则评判(Rule judge):后续步骤由一系列规则决定,通过评分机制评估答案的质量,决定继续还是停止流程取决于这些分数是否超过某些预定的阈值。代表论文《FLARE: Forward-Looking Active Retrieval》
-
LLM评判(LLM judge):LLM独立决定后续行动方案,主要有两种方法实现:
-
Prompt Engineering:直接对LLM说“上面内容如果信息足够,回复Stop;如果信息不够,回复Search”。优点简单不用训练,缺点是模型会有幻觉,不按格式输出。
-
Fine-tuning:训练模型使用特殊Token,遇到不懂问题时候自动输出标签。优点是反应快,指令执行精确,缺点是训练数据难做,成本高。
-
知识引导调度(Knowledge-guide scheduling):一种高级的调度方法,前两种都是在碰运气,而这种是拿着地图(知识图谱)规划路线。如“埃隆马克斯的哪家公司发射了猎鹰火箭?”,通过查找知识图谱构建推理链为“埃隆马克斯->拥有公司->SpaceX”和“SpaceX->制造产品->猎鹰火箭”。优点是能够解决复杂推理问题(Multi-hop reasoning),而且答案准确可解释。
2.6.3 融合(Fusion)
高级RAG使用多Pipeline扩大检索范围和增加多样性,Pipeline各个分支的融合可以有效整合信息,确保输出内容丰富和具备多样性。方法包括:
-
LLM融合(LLM fusion):多分支聚合的最直接的方法之一,利用LLM来分析和整合不同分支的信息。但是会存在超出LLM上下文窗口限制的长答案,通常先对每个分支答案进行摘要,提取关键信息后输入LLM,确保长度范围内保留重要内容。
-
加权集成(Weighted ensemble):从多个分支生成不同Token的加权值,对最终输出进行综合选择。
-
RRF(Reciprocal Rank Fusion):多个检索结果排名合成为一个紧密结合的统一列表,它采用一种定制的加权平均方法来增强集体预测性能和排名精度。该方法的优势在于其动态权重分配,这由各分支之间的相互作用决定。RRF 在特征为模型或来源异构性的场景中特别有效,在这种场景下,它可以显著提高预测的准确性。
- Modular RAG包括6种流程设计模式
3.1 线性模式(Linear Pattern)
线性模式的一个通用框架如下图所示,是一个简单的“索引 (Indexing) -> 预检索处理 (Pre-retrieval) -> 检索 (Retrieval) -> 后检索处理 (Post-retrieval) -> 生成 (Generation)”步骤。
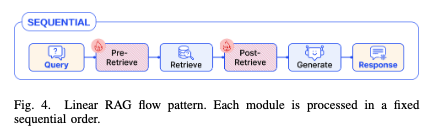
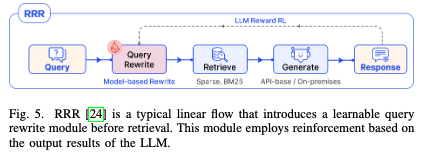
一个典型的线性模型是RRR(Rewrite-Retrieve-Read)模型如下图所示,在预处理阶段增加了一个“重写器”,增强了传统RAG的效果。
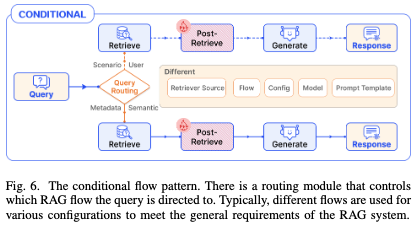
3.2 条件模式(Conditional Pattern)
条件模式引入了If-Else逻辑判断,通过路由判断将流程分成了分支A或分支B,如下图所示:
3.3 分支模式(Branching Pattern)
分支模式引入并行处理,类似于Map-Reduce方案,主要形式包括两种。
- 检索前分支(Pre-retrieval Branching):把1个问题扩展成5个不同角度问题(Multi-Query),分别检索后汇总找回的资料。
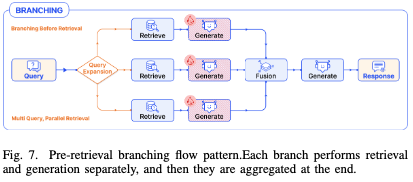
- 检索后分支(Post-retrieval Branching):检索后生成多个文档,并将多文档融合成一个最终的答案。
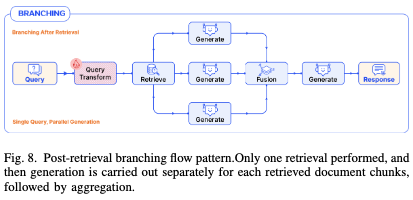
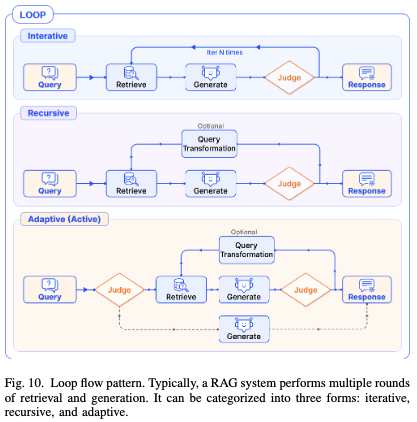
3.4 循环模式(Loop Pattern)
目前前沿的Agentic RAG方向,通过loop循环,提高RAG的效果。目前主要的循环模式分为三种:
- 迭代 (Iterative): 固定循环次数。比如“检索-生成”这个动作,强制做 3 轮,每一轮都基于上一轮的结果进行优化。
- 递归 (Recursive): 把大问题拆成小问题,一层层向下查,直到查清楚为止(如 Tree of Clarifications)。
- 自适应/主动 (Adaptive/Active): LLM 自己决定什么时候停。
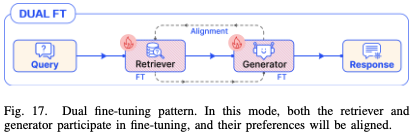
3.5 微调模式(Tunning Pattern)
通过微调,为解决当前任务训练适合的模型,主要包括三种。
- 检索器微调(Retriever FT):在 RAG 流程中,微调检索器的常用方法(如图 15 所示)包括:
- 直接有监督微调 (Direct SFT): 构建专门的检索数据集(Question-Document 对),对密集检索器(Dense Retriever)进行微调。可以使用开源数据集或基于领域数据构建。
- 添加可训练适配器 (Adding Trainable Adapter): 有时直接微调 API 形式的嵌入模型(如 OpenAI Ada-002)是不可行的。此时,可以插入一个小的适配器模块(Adapter)进行训练。这不仅能增强数据的表示能力,还能让模型更好地对齐特定的下游任务。
- LM 监督检索 (LM-supervised Retrieval, LSR): 利用 LLM 生成的结果作为监督信号来微调检索器。
- LLM 奖励强化学习 (LLM Reward RL): 使用 LLM 的输出作为奖励信号,通过强化学习将检索器与生成器对齐。
- 生成器微调(Generator FT):微调生成器的主要方法包括:
- 直接有监督微调 (Direct SFT): 使用外部数据集微调可以为生成器补充额外的知识。另一个好处是可以定制输入输出格式(例如让 LLM 学会以特定的 JSON 格式回答)。
- 蒸馏 (Distillation): 当本地部署开源小模型时,一个简单有效的方法是使用 GPT-4 批量构造微调数据,以此来增强开源小模型的能力(让老师教学生)。
- RLHF/RLAIF (强化学习): 基于最终生成答案的反馈进行强化学习。除了使用人工评估外,也可以用强大的 LLM 作为裁判(Judge)来提供反馈。
- 双重微调(Dual FT):在 RAG 系统中,同时微调检索器和生成器是其独有的特征, RA-DIT是一种典型的Dual FT方法,利用KL散度(KL divergence)来对检索器的概率分布逼近生成器的偏好分布。
4 总结
目前RAG 已经从一个简单的技术点(Retrieve->Generate)演变成了一个庞大的方法论体系,成功的RAG平台并非是一个标准的可到处复制的技术框架,而必然是一个最佳实践的结果。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献745条内容
已为社区贡献745条内容

所有评论(0)