RAG系统调试神器大揭秘!小白也能看懂的大模型可视化分析工具,一键定位系统Bug!
RAGExplorer是一款专为RAG系统设计的可视化分析工具,通过组件配置、性能概览、故障归因和实例诊断四大视图,帮助开发者直观对比不同配置效果。该工具支持自定义数据集上传,提供多种可视化图表展示性能指标,并能通过自动化算法进行分层故障归因分析,精准定位RAG系统失效环节,为优化提供明确方向,让大模型调试不再难!
今天写第二篇,来看一个工作,RAG系统可视化分析工具,这个是有意义的,用于选型的debug,有些用处,因此,看一个系统性的开源工作。
实际上,放到这个LLM的可观测性上,目前有一些开源工具,例如langfuse,地址在https://github.com/langfuse/langfuse。
技术总是有趣的,从基本问题出发,多总结,多归纳,**多从底层实现分析逻辑,**会有收获。
一、RAG系统可视化分析工具RAGExplorer
先看一个工作,RAGExplorer,RAG系统比较诊断设计的可视化分析系统,通过组件配置视图、性能概览视图、故障归因视图和实例诊断视图四个视图做分析,用于帮助用户探索和对比不同的 RAG 配置、模型及参数,为 RAG 系统的评估与优化提供直观支持,属于面向研究场景的工具。《RAGExplorer: A Visual Analytics System for the Comparative Diagnosis of RAG Systems》,https://arxiv.org/pdf/2601.12991,https://github.com/Thymezzz/RAGExplorer
1、看设计思路
设计思路如下图所示: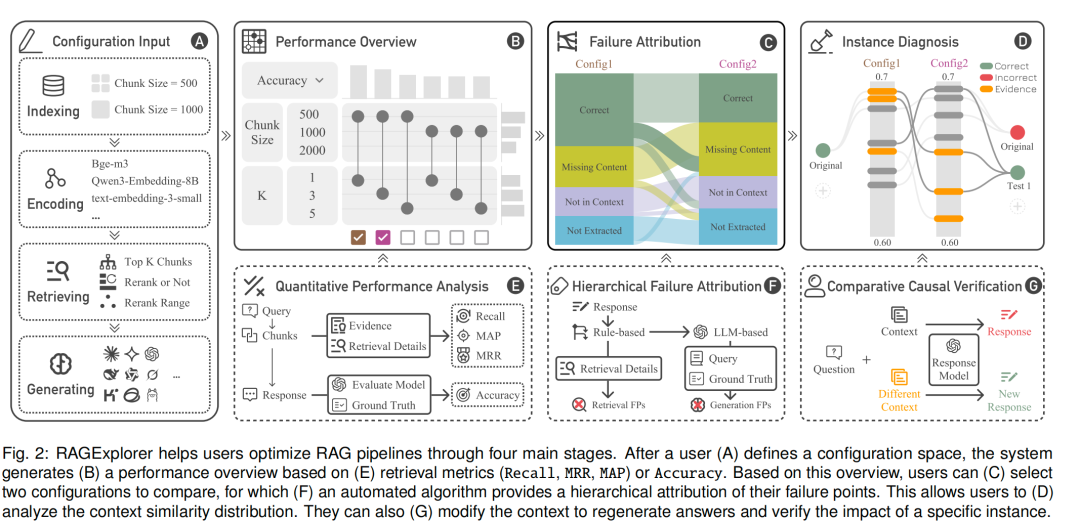 通过四个主要阶段帮助用户优化RAG流水线。用户(A)定义配置空间后,系统会基于(E)检索指标(召回率Recall、平均倒数排名MRR、平均精度均值MAP)或准确率(Accuracy)生成(B)性能总览。基于该总览,用户可(C)选择两个配置进行对比,系统会通过(F)自动化算法对这两个配置的故障点进行分层归因分析。借此,用户能够(D)分析上下文相似度分布,还可(G)修改上下文以重新生成答案,验证特定实例的影响。
通过四个主要阶段帮助用户优化RAG流水线。用户(A)定义配置空间后,系统会基于(E)检索指标(召回率Recall、平均倒数排名MRR、平均精度均值MAP)或准确率(Accuracy)生成(B)性能总览。基于该总览,用户可(C)选择两个配置进行对比,系统会通过(F)自动化算法对这两个配置的故障点进行分层归因分析。借此,用户能够(D)分析上下文相似度分布,还可(G)修改上下文以重新生成答案,验证特定实例的影响。
2、看主要功能
主要功能如下如图所示:

其中,重要的还是数据上的支持,支持上传和管理自定义问题数据集(需包含 query、answer、evidence_list 字段)与语料库数据集(需包含 body 字段,可选 title、url 字段),并提供示例数据集参考。
组件配置视图(A):用于定义实验空间,支持用户为每个RAG组件选择配置选项,比如可自定义嵌入模型、大模型、分块策略、重排模型等核心 RAG 组件参数。
性能总览视图(B):通过矩阵和条形图展示所有配置的排名性能,助力识别最优配置及各组件选择的平均影响,提供矩阵、协调条形图、桑基图、双轨视图等多种可视化形式。指标侧也有**准确率(Accuracy)、召回率(Recall)、平均倒数排名(MRR)、平均精度均值(MAP)**等核心评估指标。
故障归因视图(C):利用桑基图可视化两个RAG配置间的问题故障流向,明确设计变更对故障点的作用。
实例诊断视图(D):采用三面板布局,支持选择问题、对比上下文、验证假设及查看完整文本细节。
二、RAG系统可视化分析工具RAGExplorer、几个例子
来看几个实际的例子,看看一些设计想法,如下:
1、参数分析
文中论述如何使用该工具分析chunk-overlap的设置问题,如下:
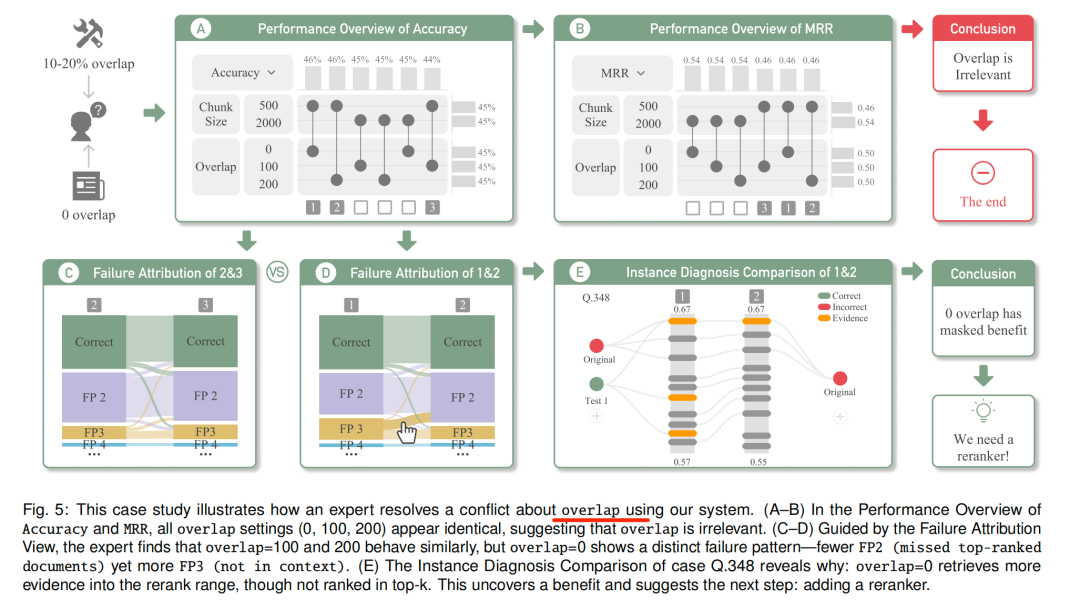
(A–B)在准确率(Accuracy)和平均倒数排名(MRR)的性能总览中,所有重叠度设置(0、100、200)的表现均一致,这表明重叠度与此无关。
(C–D)在故障归因视图(FailureAttributionView)的指引下,专家发现重叠度=100和200的表现相近,但重叠度=0呈现出明显不同的故障模式——FP2(遗漏top-k排名文档)更少,但FP3(不在上下文中)更多。
(E)对案例Q.348的实例诊断对比(InstanceDiagnosisComparison)揭示了背后原因:重叠度=0时,虽有更多证据被纳入重排范围,但并未进入top-k排名,进而为后续优化指明方向:添加重排模型(reranker)。
2、分层故障归因
用于系统诊断RAG系统的失效原因。其核心逻辑是:先筛选正确答案,对错误答案按“从上游到下游、从明确到模糊”的顺序逐步检查,最终为每个错误答案分配唯一的主故障点(FP),分层检查顺序按“基础合规性→检索阶段→生成阶段”逐步推进,前一阶段未捕获的故障,自动进入下一阶段分析,确保故障点归属唯一且准确。
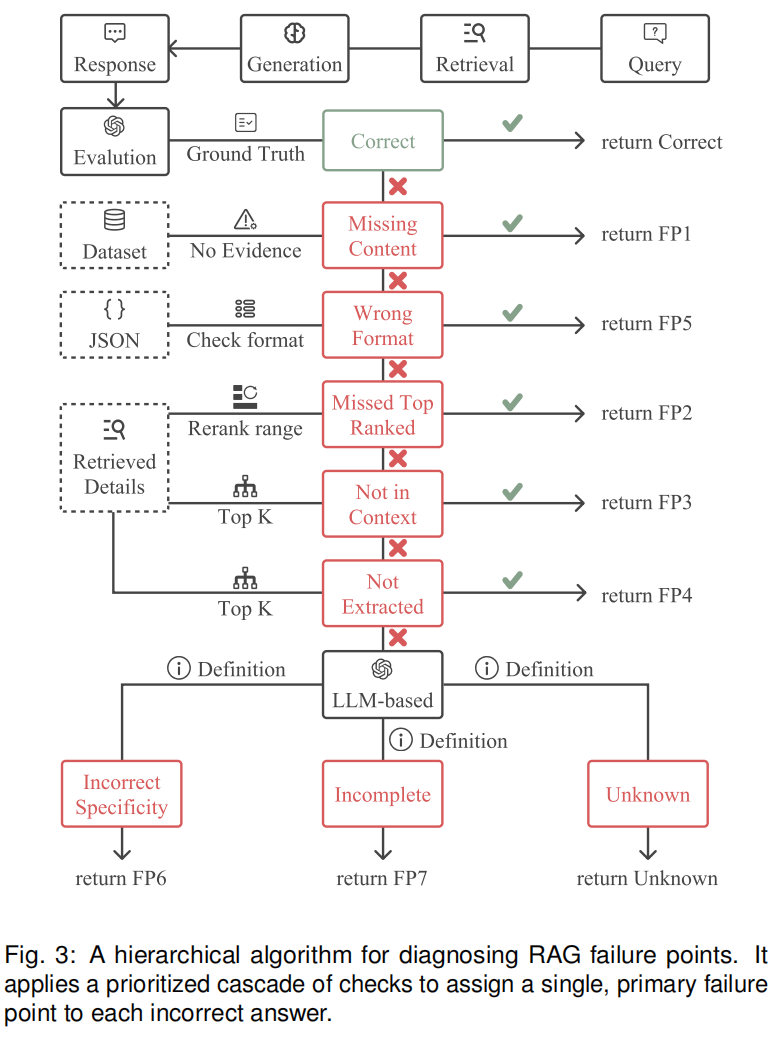
其核心目的还是说,通过标准化、自动化的分层检查,定位RAG系统失效的关键环节(是不可回答问题处理不当、检索漏证、生成推理错误,还是格式违规),为后续优化提供明确方向(如FP2需优化重排模型,FP4需优化生成器的证据识别能力)。
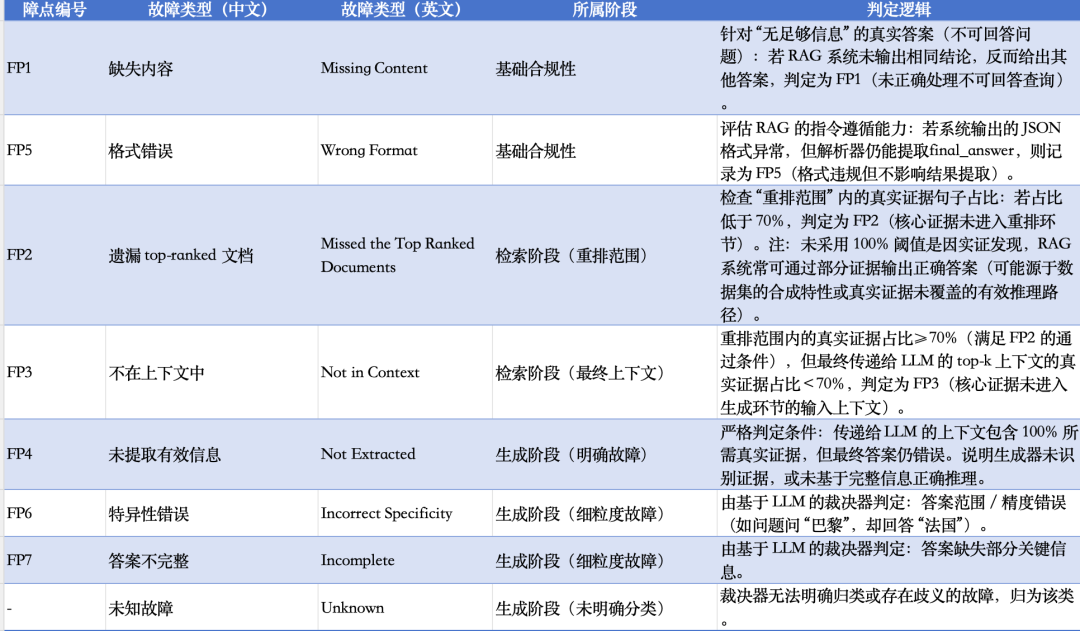
其中,可以重点看下的是这个检查逻辑这些FP都是啥?
3、原文高亮
如下所示,这是很常规的定位功能,用于可解释性。

问题ID.9及其检索到的336号文本块与7949号文本块。无关文本以灰色显示,支持句以蓝色下划线标注,证据以橙色高亮显示。若文本段落存在重叠,这些样式可叠加呈现。
4、整体性能对比
这个就是各种配置问题的比对,做实验嘛,比对出结论:
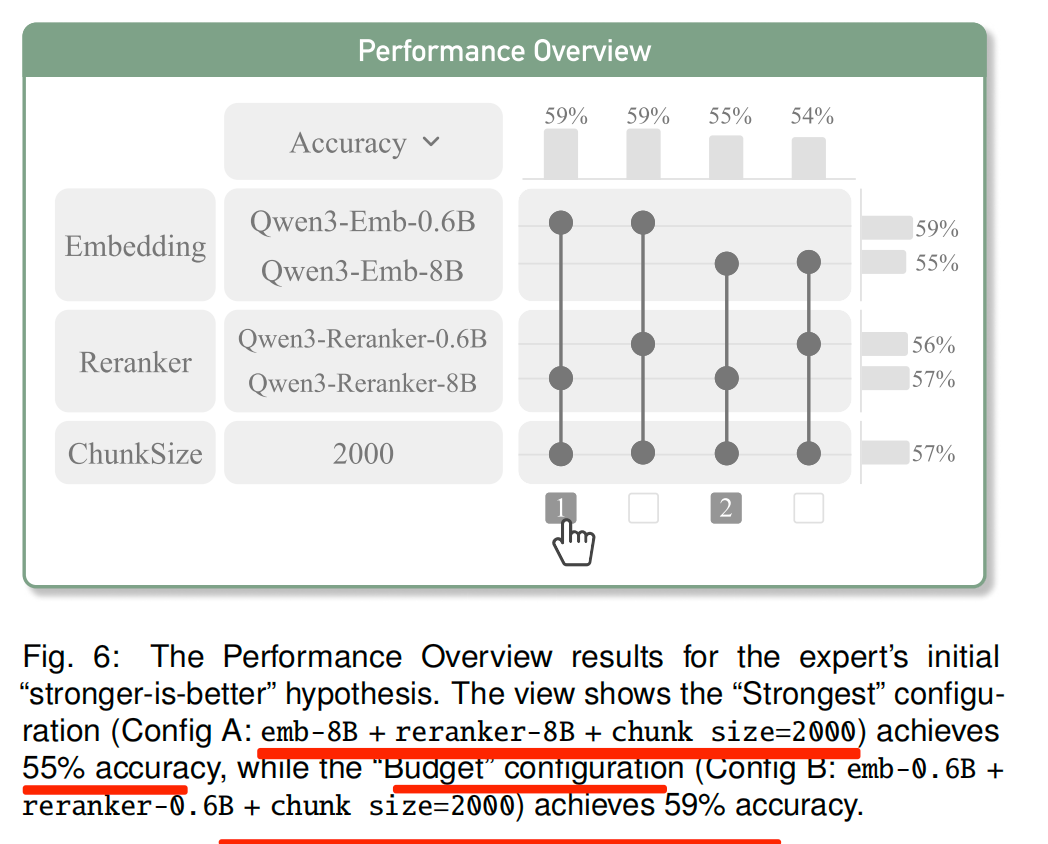
如上图所示:“最强配置”(配置A:80亿参数嵌入模型+80亿参数重排模型+分块大小=2000)的准确率为55%,而“经济型配置”(配置B:0.6亿参数嵌入模型+0.6亿参数重排模型+分块大小=2000)的准确率达59%。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献745条内容
已为社区贡献745条内容

所有评论(0)