智能体设计模式 第三章:并行化
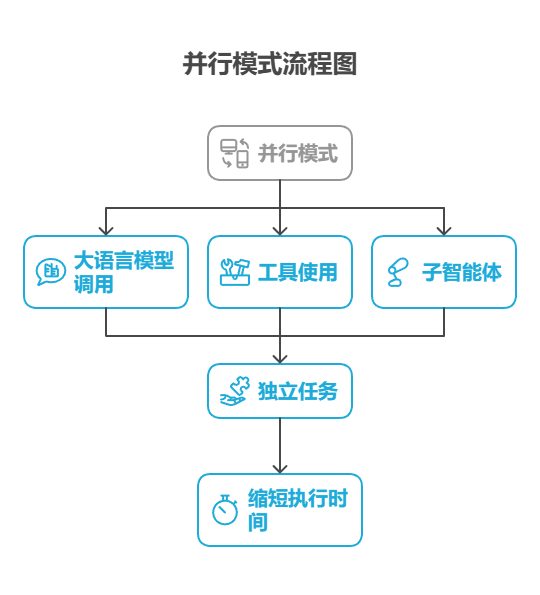
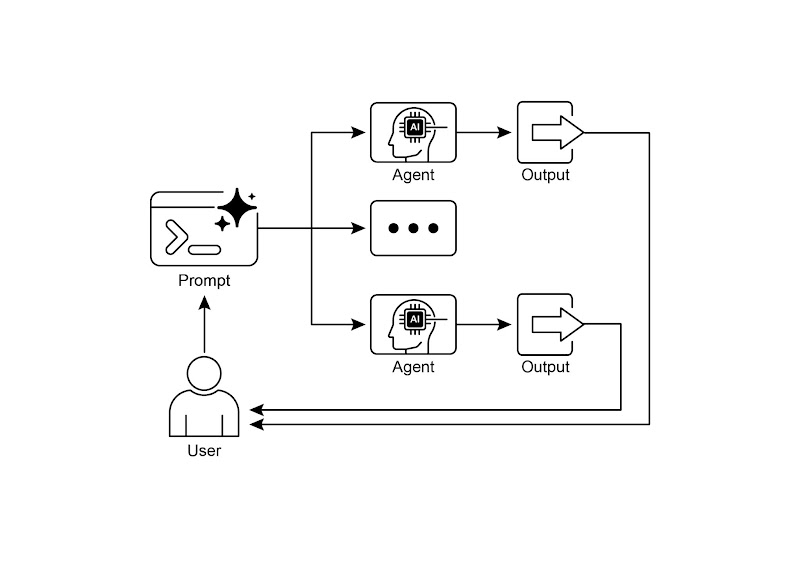
并行模式涉及同时执行多个组件,例如大语言模型调用、工具使用,甚至整个子智能体(见图 1)。与等待一个步骤完成后再开始下一个步骤不同,并行执行允许独立任务同时运行,这大大缩短了那些可以分解为相互独立部分的任务的总执行时间。
智能体设计模式 第三章:并行化
并行模式概述
在前面的章节中,我们探讨了用于顺序工作流的提示链以及用于智能决策的路由模式。虽然这些模式很重要,但许多复杂的智能体任务需要同时执行多个子任务,而非一个接一个地执行。这时并行模式就变得至关重要。
并行模式涉及同时执行多个组件,例如大语言模型调用、工具使用,甚至整个子智能体(见图 1)。与等待一个步骤完成后再开始下一个步骤不同,并行执行允许独立任务同时运行,这大大缩短了那些可以分解为相互独立部分的任务的总执行时间。
考虑实现一个研究主题并汇总结论的智能体。按顺序执行时可能会是这样:
1. 搜索来源 A。
2. 总结来源 A。
3. 搜索来源 B。
4. 总结来源 B。
5. 整合总结 A 和 总结 B 中的内容,生成一个最终答案。
如果使用并行模式则可以优化为:
1. 同时搜索来源 A 和来源 B。
2. 两次搜索完成后,同时对来源 A 和来源 B 进行总结。
3. 整合总结 A 和 总结 B 中的内容,生成一个最终答案。这一步通常按顺序进行,需要等待前面并行步骤全部完成。
并行模式的核心在于找出工作流中互不依赖的环节,并将它们并行执行。在处理外部服务(如 API 或数据库)时,这种做法特别有效,因为可以同时发起多个请求,从而减少总体等待时间。
实现并行化通常需要使用支持异步执行、多线程或多进程的框架。现代智能体框架原生都能支持异步操作,帮助你方便地定义并同时运行多个步骤。
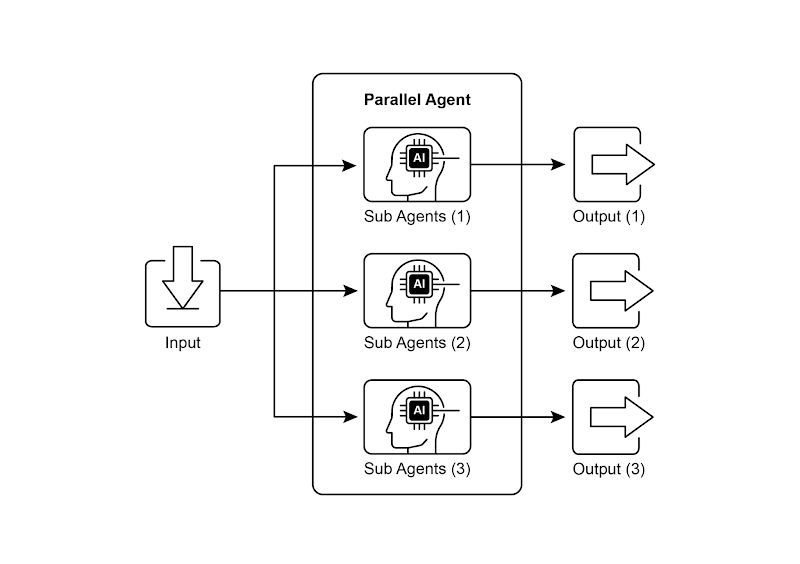
使用子智能体进行并行化的示例
LangChain、LangGraph 和 Google ADK 等框架都提供了并行执行机制。
在 LangChain 表达式语言(LCEL)中,可以使用 | 等运算符组合可运行对象,并通过设计具有并发分支的链或图结构来实现并行执行。而 LangGraph 则利用图结构,允许从状态转换中执行多个节点,从而在工作流中实现并行分支。
Google ADK 也提供了强大的原生机制来促进和管理智能体的并行执行,显著提升了复杂多智能体系统的效率和可扩展性。ADK 框架的这一内在能力使开发者能够设计并实现让多个智能体并发运行(而非顺序执行)的解决方案。
并行模式对于提升智能体系统的效率和响应速度至关重要,特别是在需要执行多个独立查询、计算或与外部服务交互的场景中。它是优化复杂智能体工作流性能的关键技术。
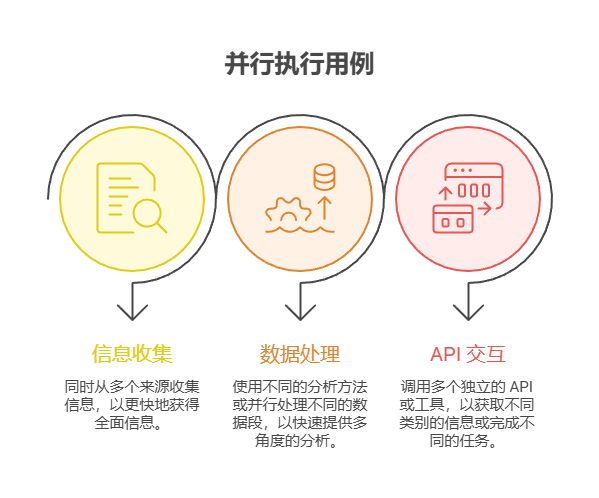
实际应用场景
并行模式可以在各种场景中使用以提升智能体性能:
1. 信息收集和研究:
一个经典的用例就是同时从多个来源收集信息。
- 用例:研究某个公司的智能体。
- 并行执行任务:同时搜索新闻、拉取股票数据、监测社交媒体上的提及,并查询公司数据库。
- 好处:比逐项查找更快获得全面信息。
2. 数据处理和分析:
使用不同的分析方法或并行处理不同的数据段。
- 用例:分析客户反馈的智能体。
- 并行处理任务:在一批反馈中同时进行情感分析、关键词提取、分类,并识别需要优先处理的紧急问题。
- 好处:快速提供多角度的分析。
3. 多个 API 或工具交互:
调用多个独立的 API 或工具,以获取不同类别的信息或完成不同的任务。
- 用例:旅行规划智能体。
- 并行处理任务:同时检查航班价格、搜索酒店、了解当地活动,并找到推荐的餐厅。
- 好处:更快速地制定出完整的旅行行程。
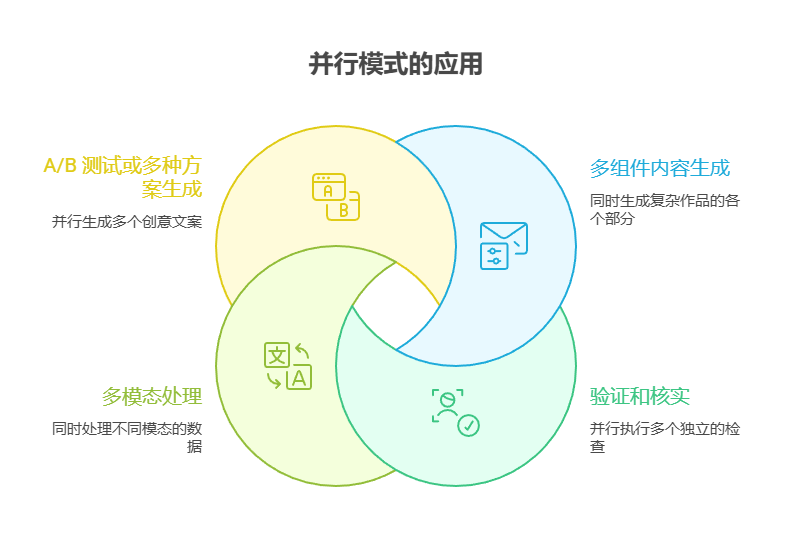
4. 多组件内容生成:
并行生成复杂作品的各个部分。
- 用例:撰写营销邮件的智能体。
- 并行处理任务:同时生成邮件主题、撰写正文、查找相关图片,并设计具有号召性的按钮文案。
- 好处:更高效地生成电子邮件内容。
** 5. 验证和核实:**
并行执行多个彼此独立的检查或验证。
- 用例:验证用户输入的智能体。
- 并行执行任务:同时检查邮件格式、验证电话号码、在数据库中核对地址,并检查是否有不当内容。
- 好处:能够更快地反馈输入是否有效。
6. 多模态处理:
同时对同一输入的不同模态(文本、图像、音频)数据进行处理。
- 用例:分析包含文本和图像的社交媒体帖子的智能体。
- 并行执行任务:同时分析文本的情感和关键词,以及分析图像中的对象和场景描述。
- 好处:能更快地综合来自不同模态的信息与洞见。
7. A/B 测试或多种方案生成:
- 用例:生成多个创意文案的智能体。
- 并行执行任务:同时使用稍微不同的提示或模型为同一篇文章生成三条各具风格的标题。
- 好处:可以快速比较各个方案并选出最优者。
并行模式是智能体设计中的一项重要优化技术。通过对独立任务进行并发执行,开发者可以构建更高效、更具响应性的应用程序。
实战示例:使用 LangChain
在 LangChain 框架中,通过 LangChain 的表达式语言(LCEL)可以实现并行执行。常见做法是把多个可运行组件组织成字典或列表,并把这个集合作为输入传给链中的下一个组件。LCEL 执行器会并行执行集合中的各个可运行项。
在 LangGraph 中,这一原则体现在图的拓扑结构上。通过从一个公共节点同时触发多个没有直接顺序依赖的节点,就能形成并行工作流。这些并行路径各自独立运行,之后在图中的某个汇聚点合并结果。
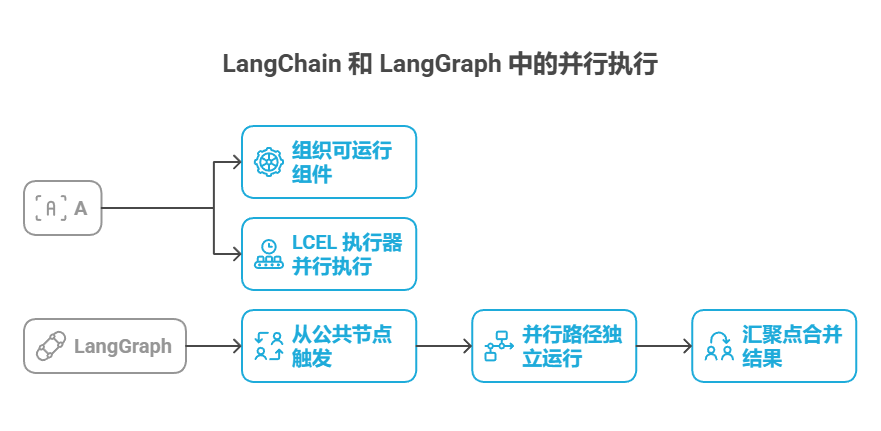
以下示例展示了如何使用 LangChain 框架构建并行处理流程:针对同一个用户查询,工作流同时启动两个互不依赖的操作,然后将它们各自的输出合并为一个最终结果。
要实现此功能,首先需要安装必要的 Python 包(如 langchain、langchain-community 及 langchain-openai 等模型提供库)。同时需要在本地环境中配置所选语言模型的有效 API 密钥,以便进行身份验证。
import os
import asyncio
from typing import Optional
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import Runnable, RunnableParallel, RunnablePassthrough
# Colab 代码链接:https://colab.research.google.com/drive/1uK1r9p-5sdX0ffMjAi_dbIkaMedb1sTj
# 安装依赖
# pip install langchain langchain-community langchain-openai langgraph python-dotenv
from dotenv import load_dotenv
load_dotenv()
# --- LLM 初始化(支持 DeepSeek / Qwen / OpenAI)---
def init_llm() -> Optional[ChatOpenAI]:
"""
根据环境变量 LLM_PROVIDER 选择使用 DeepSeek / Qwen / OpenAI。
必需环境变量:
- DeepSeek:
DEEPSEEK_API_KEY
(可选)DEEPSEEK_BASE_URL,默认 https://api.deepseek.com/v1
(可选)DEEPSEEK_MODEL,默认 deepseek-chat
- Qwen (DashScope 兼容 OpenAI 模式):
DASHSCOPE_API_KEY
(可选)QWEN_BASE_URL,默认 https://dashscope.aliyuncs.com/compatible-mode/v1
(可选)QWEN_MODEL,默认 qwen-max
- OpenAI 兜底:
OPENAI_API_KEY
(可选)OPENAI_API_BASE
"""
_provider = os.getenv("LLM_PROVIDER", "qwen").lower()
try:
if _provider == "deepseek":
_api_key = os.getenv("DEEPSEEK_API_KEY")
if not _api_key:
raise RuntimeError("缺少 DEEPSEEK_API_KEY 环境变量")
_base_url = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com/v1")
_model_name = os.getenv("DEEPSEEK_MODEL", "deepseek-chat")
_llm = ChatOpenAI(
model=_model_name,
temperature=0.7,
api_key=_api_key,
base_url=_base_url,
)
print(f"[LLM] 使用 DeepSeek 模型: {_model_name}")
return _llm
elif _provider == "qwen":
# 使用阿里云 DashScope 的 OpenAI 兼容模式
_api_key = os.getenv("DASHSCOPE_API_KEY")
if not _api_key:
raise RuntimeError("缺少 DASHSCOPE_API_KEY 环境变量(Qwen)")
_base_url = os.getenv(
"QWEN_BASE_URL",
"https://dashscope.aliyuncs.com/compatible-mode/v1"
)
_model_name = os.getenv("QWEN_MODEL", "qwen-max")
_llm = ChatOpenAI(
model=_model_name,
temperature=0.7,
api_key=_api_key,
base_url=_base_url,
)
print(f"[LLM] 使用 Qwen 模型: {_model_name}")
return _llm
else:
# 兜底:使用 OpenAI 官方
_api_key = os.getenv("OPENAI_API_KEY")
if not _api_key:
raise RuntimeError("缺少 OPENAI_API_KEY 环境变量(兜底 OpenAI)")
_base_url = os.getenv("OPENAI_API_BASE") or None
_model_name = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
_llm = ChatOpenAI(
model=_model_name,
temperature=0.7,
api_key=_api_key,
base_url=_base_url,
)
print(f"[LLM] 使用 OpenAI 模型: {_model_name}")
return _llm
except Exception as _e:
print(f"[LLM] 初始化失败: {_e}")
return None
llm: Optional[ChatOpenAI] = init_llm()
# --- 定义独立的链:摘要 / 提问 / 术语(中文提示) ---
summarize_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "请对下面的主题进行简明扼要的中文总结:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
questions_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "请围绕以下主题生成三个有深度、有思考性的问题:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
terms_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "请从以下主题中提取 5~10 个关键术语,请用逗号分隔:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
# --- 并行 + 汇总链 ---
map_chain = RunnableParallel(
{
"summary": summarize_chain,
"questions": questions_chain,
"key_terms": terms_chain,
"topic": RunnablePassthrough(), # 直接透传原始 topic
}
)
synthesis_prompt = ChatPromptTemplate.from_messages([
("system", """请根据以下信息生成一段综合性的中文回答:
摘要: {summary}
相关问题: {questions}
关键术语: {key_terms}"""),
("user", "原始主题内容:{topic}")
])
full_parallel_chain = map_chain | synthesis_prompt | llm | StrOutputParser()
# --- 运行示例(同步版本,兼容 Jupyter) ---
def run_parallel_example(topic: str) -> None:
"""
同步调用并行链,处理指定 topic 并打印综合结果。
:param topic: 要处理的主题字符串
"""
if not llm:
print("LLM 未初始化,无法运行示例。请检查 API Key 和 LLM_PROVIDER 设置。")
return
print(f"\n--- 运行并行 LangChain 示例: '{topic}' ---")
try:
# 同步版本:直接使用 invoke,而不是 ainvoke + asyncio.run
response = full_parallel_chain.invoke(topic)
print("\n--- 最终综合回答 ---")
print(response)
except Exception as e:
print(f"\n链执行过程中发生错误: {e}")
if __name__ == "__main__":
# 你可以改成中文主题测试
test_topic = "人类航天探索的历史"
run_parallel_example(test_topic)
运行输出:

上述 Python 示例实现了一个基于 LangChain 的应用,通过并发执行来更高效地处理指定话题。需要说明的是,asyncio 实现的是并发(Concurrency),不是多线程或多核的真正并行(Parallelism)。它在单个线程中运行,通过事件循环在任务等待(如等待网络响应)时切换执行,从而让多个任务看起来同时执行。但底层代码仍在同一线程上运行,这是受 Python 全局解释器锁(GIL)的限制。
代码从 langchain_openai 和 langchain_core 导入了关键模块,包含语言模型、提示模板、输出解析器和可运行组件。接着尝试初始化一个 ChatOpenAI 实例,指定使用 gpt-4o-mini 模型,并设置了控制创造力的温度值,初始化时用 try-except 来保证健壮性。随后定义了三条相互独立的 LangChain 链,每条链负责对输入主题执行不同任务:第一条链用来简洁地总结主题,采用系统消息和包含主题占位符的用户消息;第二条链生成与主题相关的三个有趣问题;第三条链则从主题中识别 5 到 10 个关键术语,要求用逗号分隔。每条链都由为该任务定制的 ChatPromptTemplate、已初始化的语言模型和用于把输出格式化为字符串的 StrOutputParser 组成。
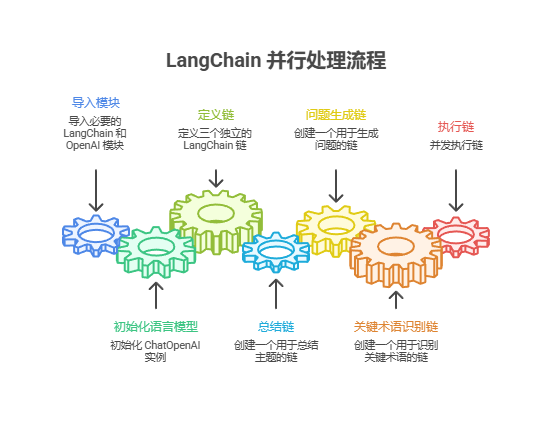
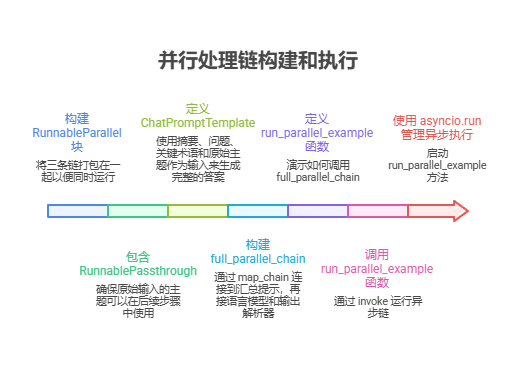
随后构建了一个 RunnableParallel 块,把这三条链打包在一起以便同时运行。这个运行单元还包含一个 RunnablePassthrough,确保原始输入的主题可以在后续步骤中使用。
接着为最后的汇总步骤定义了一个独立的 ChatPromptTemplate,使用摘要、问题、关键术语和原始主题作为输入来生成完整的答案。这个名为 full_parallel_chain 的端到端处理链,是通过 map_chain 连接到汇总提示,再接语言模型和输出解析器来构建的。
示例中提供了一个异步函数 run_parallel_example,用来演示如何调用这个 full_parallel_chain,该函数接收主题作为输入并通过 invoke 运行异步链。
最后,通过标准的 Python if name == “main”: 代码块演示如何用 asyncio.run 管理异步执行,来启动 run_parallel_example 方法,其中主题为「航天探索史」。
本质上,这段代码构建了一个工作流:针对某个主题,使用大语言模型同时进行摘要、提问和术语等多个调用,随后由一次最终的请求把这些输出整合在一起。该示例说明了在使用 LangChain 的智能体工作流中通过并行执行来提高效率的核心思想。
实战示例:使用 Google ADK
现在通过 Google ADK 框架中的具体示例来说明这些概念。我们将展示 ADK 的基本组件(如 ParallelAgent 和 SequentialAgent)来构建智能体流程,从而通过并行执行提高效率。
import os
from typing import Optional
from dotenv import load_dotenv
load_dotenv()
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
# =========================================================
# 1) 初始化 Gemini LLM
# =========================================================
def init_gemini_llm() -> Optional[ChatGoogleGenerativeAI]:
"""
初始化 Gemini 模型。
需要的环境变量:
- GOOGLE_API_KEY:你的 Gemini API Key
- GEMINI_MODEL(可选):默认使用 gemini-2.5-flash
"""
_api_key = os.getenv("GOOGLE_API_KEY")
if not _api_key:
print("缺少 GOOGLE_API_KEY 环境变量,请在 .env 中配置。")
return None
# 用一个更快、正式的模型名
# _model_name = os.getenv("GEMINI_MODEL", "gemini-2.5-flash")
_model_name = "gemini-2.0-flash"
try:
_llm = ChatGoogleGenerativeAI(
model=_model_name,
google_api_key=_api_key, # 等价于 api_key
temperature=0.7,
transport="rest", # ⭐ 关键:走 REST,不走 gRPC
max_output_tokens=256, # 可选:限制输出长度,加快生成
)
print(f"[LLM] 已使用 Gemini 模型: {_model_name}")
return _llm
except Exception as _e:
print(f"[LLM] 初始化 Gemini 失败: {_e}")
return None
llm: Optional[ChatGoogleGenerativeAI] = init_gemini_llm()
# 没有成功初始化就直接返回,不再往下构建链,避免后面报一堆 None 错误
if llm is None:
raise SystemExit("Gemini 初始化失败,终止脚本。")
# =========================================================
# 2) 定义三个“研究员”链:可再生能源 / 电动汽车 / 碳捕获
# =========================================================
renewable_energy_chain = (
ChatPromptTemplate.from_messages([
(
"system",
"你是一名专注于能源领域的 AI 研究助理,请用中文回答。"
"请基于你当前可访问的知识,对“可再生能源的最新进展”进行调研,"
"并用 1–2 句话进行精炼总结。只输出总结内容。"
),
("user", "请给出总结。")
])
| llm
| StrOutputParser()
)
ev_technology_chain = (
ChatPromptTemplate.from_messages([
(
"system",
"你是一名专注于交通与出行领域的 AI 研究助理,请用中文回答。"
"请基于你当前可访问的知识,对“电动汽车技术的最新发展”进行调研,"
"并用 1–2 句话进行精炼总结。只输出总结内容。"
),
("user", "请给出总结。")
])
| llm
| StrOutputParser()
)
carbon_capture_chain = (
ChatPromptTemplate.from_messages([
(
"system",
"你是一名专注于气候解决方案的 AI 研究助理,请用中文回答。"
"请基于你当前可访问的知识,对“碳捕获技术的现状与进展”进行调研,"
"并用 1–2 句话进行精炼总结。只输出总结内容。"
),
("user", "请给出总结。")
])
| llm
| StrOutputParser()
)
# =========================================================
# 3) 并行链:等价于 ParallelAgent
# =========================================================
parallel_research_chain = RunnableParallel(
{
"renewable_energy_result": renewable_energy_chain,
"ev_technology_result": ev_technology_chain,
"carbon_capture_result": carbon_capture_chain,
"dummy": RunnablePassthrough(), # 占位,不实际使用
}
)
# =========================================================
# 4) 汇总链:等价于 SynthesisAgent
# =========================================================
synthesis_prompt = ChatPromptTemplate.from_messages([
(
"system",
"""
你现在的角色是一名负责撰写综合研究报告的 AI 助理,请只用中文回答。
你的任务是:将给定的三个研究摘要整合成一份结构化的报告,
并且在每个部分清楚标注其来源领域(可再生能源、电动汽车、碳捕获)。
【重要约束】:
1. 你的回答只能基于下面提供的三个摘要内容,不能自行添加任何外部事实或细节。
2. 不要引入没有在摘要中出现过的新结论或数据。
3. 用适当的小标题来组织报告结构。
下面是输入摘要:
- 可再生能源(Renewable Energy)摘要:
{renewable_energy_result}
- 电动汽车(Electric Vehicles)摘要:
{ev_technology_result}
- 碳捕获(Carbon Capture)摘要:
{carbon_capture_result}
【输出格式要求】:
## 可持续技术最新进展综合报告
### 可再生能源领域
(基于“可再生能源”研究摘要进行整理与展开,仅使用上方对应摘要中的信息。)
### 电动汽车领域
(基于“电动汽车”研究摘要进行整理与展开,仅使用上方对应摘要中的信息。)
### 碳捕获领域
(基于“碳捕获”研究摘要进行整理与展开,仅使用上方对应摘要中的信息。)
### 综合结论
(用 1–2 句话,对上述三个领域的进展做一个只基于现有摘要信息的综合性总结。)
请严格按照上述结构输出,不要额外添加其它引言或结束语。
"""
),
("user", "请根据以上三个摘要生成综合报告。")
])
synthesis_chain = synthesis_prompt | llm | StrOutputParser()
# =========================================================
# 5) 整体 Pipeline:先并行研究,再合并输出
# 等价:SequentialAgent([ParallelAgent, MergerAgent])
# =========================================================
full_research_pipeline = parallel_research_chain | synthesis_chain
def run_sustainable_tech_research() -> None:
"""
同步执行整条“并行研究 + 汇总报告”链。
等价于原来 ADK 里的 SequentialAgent(ParallelAgent -> MergerAgent)。
"""
print("\n--- 正在执行可持续技术并行研究 Pipeline(Gemini) ---")
try:
result = full_research_pipeline.invoke({})
print("\n--- 最终综合报告 ---\n")
print("type(result):", type(result))
print("repr(result):", repr(result))
print("\n纯文本输出:")
print(result)
except Exception as e:
print(f"\n执行 Pipeline 过程中出错:{e}")
if __name__ == "__main__":
run_sustainable_tech_research()
编译输出:
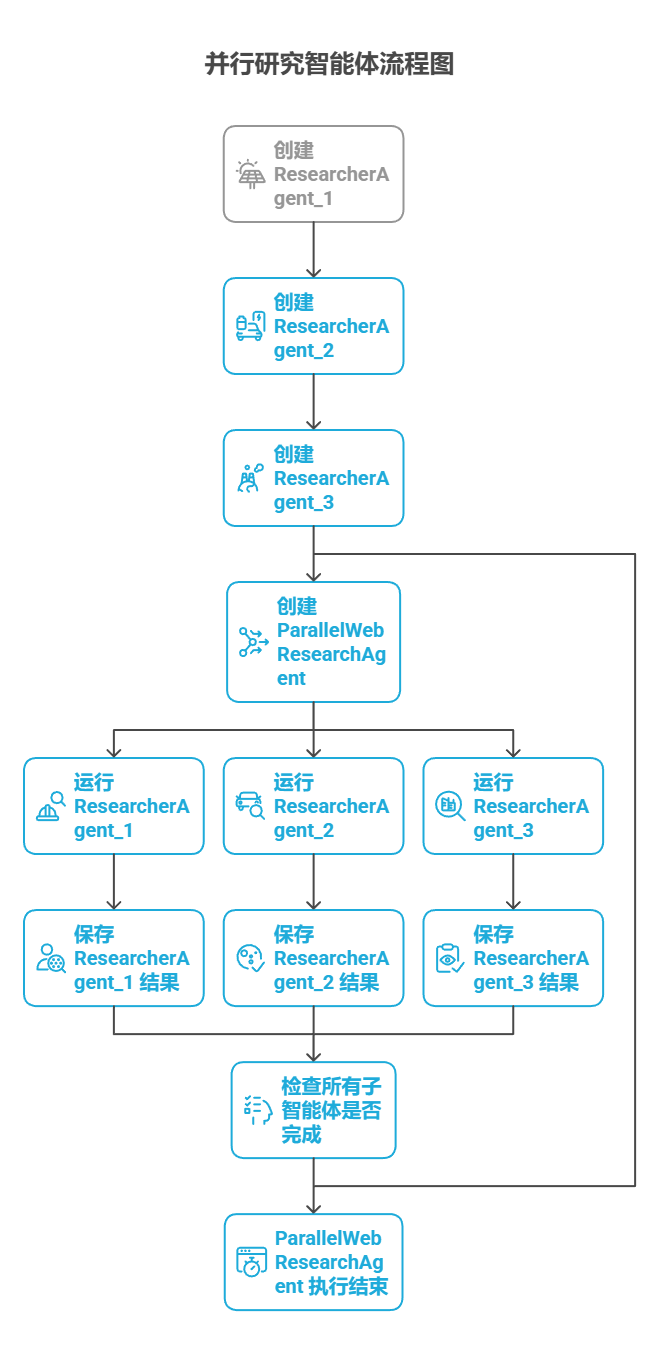
该代码建立了一个多智能体系统,用于收集与整合可持续技术进展的资料。系统包含三个子智能体担任不同的研究员:ResearcherAgent_1 聚焦可再生能源,ResearcherAgent_2 研究电动汽车技术,ResearcherAgent_3 调查碳捕集技术。每个研究员子智能体都配置为使用 GEMINI_MODEL 和 google_search 工具,并要求使用一到两句话总结研究结果,随后通过 output_key 将这些总结内容保存到会话状态中。
然后创建了一个名为 ParallelWebResearchAgent 的并行智能体,用于同时运行这三个研究员子智能体。这样可以并行开展研究,节省时间。只有当所有子智能体(研究员)都完成并将结果写入状态后,并行智能体才算执行结束。
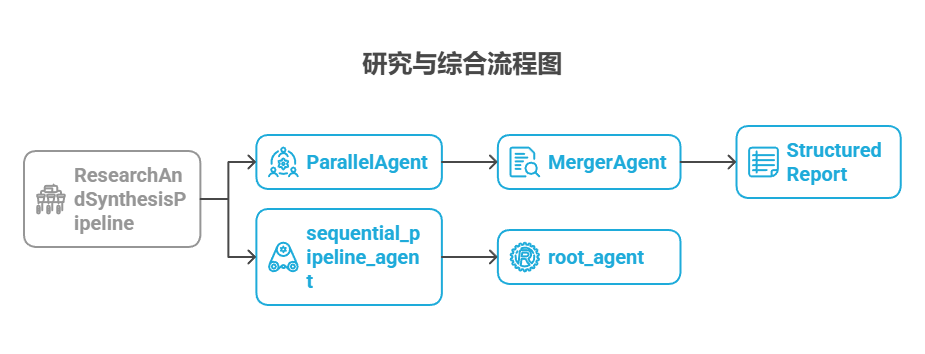
接下来,定义了一个 MergerAgent(也是 LlmAgent)来综合研究结果。该智能体将并行研究员子智能体存储在会话状态中的总结内容作为输入。其指令强调输出必须严格基于所提供的总结内容,禁止添加外部知识。MergerAgent 旨在将合并的发现结构化为报告,每个主题都有标题和简要的结论。
最后,创建了一个名为 ResearchAndSynthesisPipeline 的顺序型智能体来协调整个工作流。作为主要控制器,该主智能体首先执行 ParallelAgent 来进行研究。ParallelAgent 完成后,SequentialAgent 会执行 MergerAgent 来综合收集的信息。sequential_pipeline_agent 被设置为 root_agent,代表运行该多智能体系统的入口。整个流程的设计目标是并行从多个来源高效收集信息,然后将这些信息合并为一份结构化报告。
要点速览
问题所在:许多智能体工作流涉及多个必须完成的子任务以实现最终目标。纯粹的顺序执行,即每个任务等待前一个任务完成再执行,通常效率低下且速度缓慢。当任务依赖于外部 I/O 操作(如调用不同的 API 或查询多个数据库)时,这种延迟会成为重大瓶颈。没有并发机制时,总耗时就是各个任务耗时的累加,进而影响系统的性能和响应速度。
解决之道:并行模式通过同时执行彼此独立的任务,提供了一种标准化的解决方案来缩短整体执行时间。它的做法是识别工作流中不相互依赖的部分,比如某些工具调用或大语言模型请求。像 LangChain 和 Google ADK 这样的智能体框架内置了用于定义和管理并发操作的能力。举例来说,主流程可以启动多个并行的子任务,然后在继续下一步之前等待这些子任务全部完成。相比与顺序执行,这种并行执行能大幅减少总耗时。
经验法则:当工作流中存在多个相互独立且可并行执行的任务时应采用该模式,例如同时从多个 API 拉取数据、并行处理不同的数据分片,或同时生成多个将来需要合并的内容,从而缩短总体执行时间。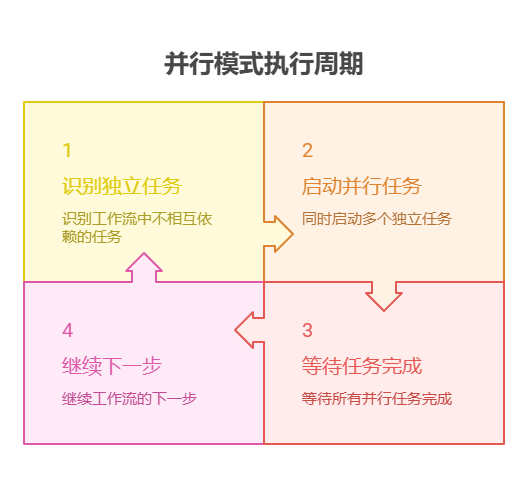
可视化总结:
核心要点
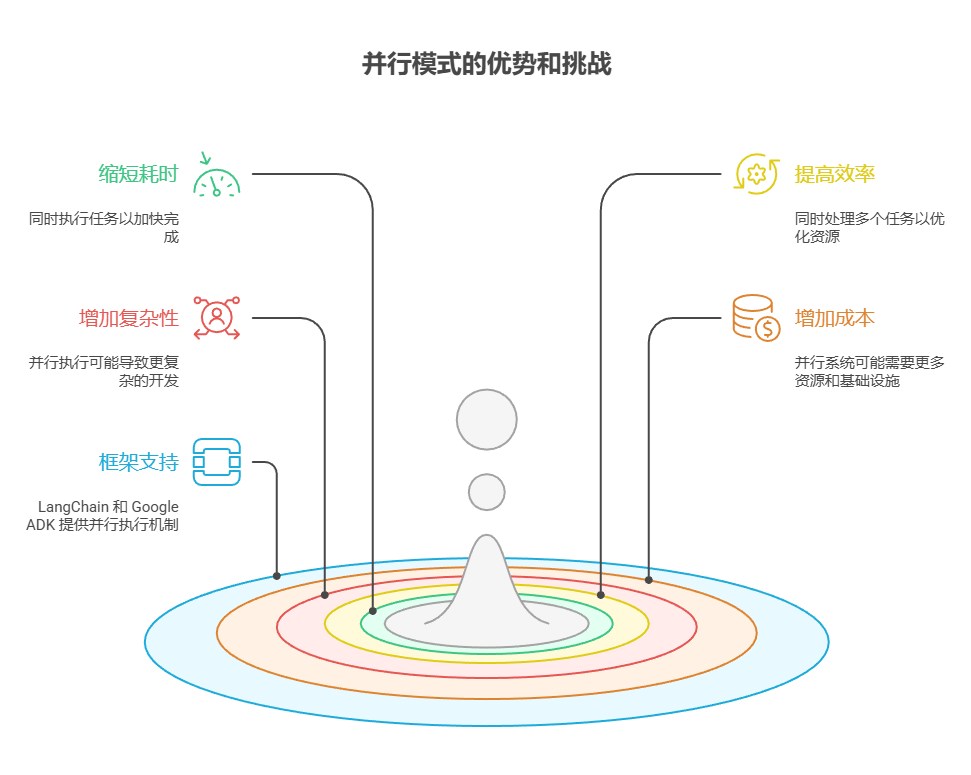
- 并行模式是一种将相互独立的任务同时执行,从而缩短总耗时并提高效率的方法。
- 在任务需要等待外部资源(比如调用 API)时,这种方式特别有用。
- 采用并发或并行架构会显著增加复杂性和成本,从而对设计、调试和日志等开发环节带来影响。
- 像 LangChain 和 Google ADK 这样的框架内置了对并行执行的支持,方便定义和管理并行任务。
- 在 LangChain 的表达式语言(LCEL)中,RunnableParallel 是一个核心组件,用于并行执行多个可运行单元。
- Google ADK 可以通过大语言模型驱动的委派机制来实现并行执行,其中协调器智能体中的大语言模型会识别出互相独立的子任务,并将这些任务分派给相应的子智能体去处理,从而并发完成各个子任务。
- 并行模式能有效减少总体耗时,从而提升智能体系统对复杂任务的响应能力。
结语
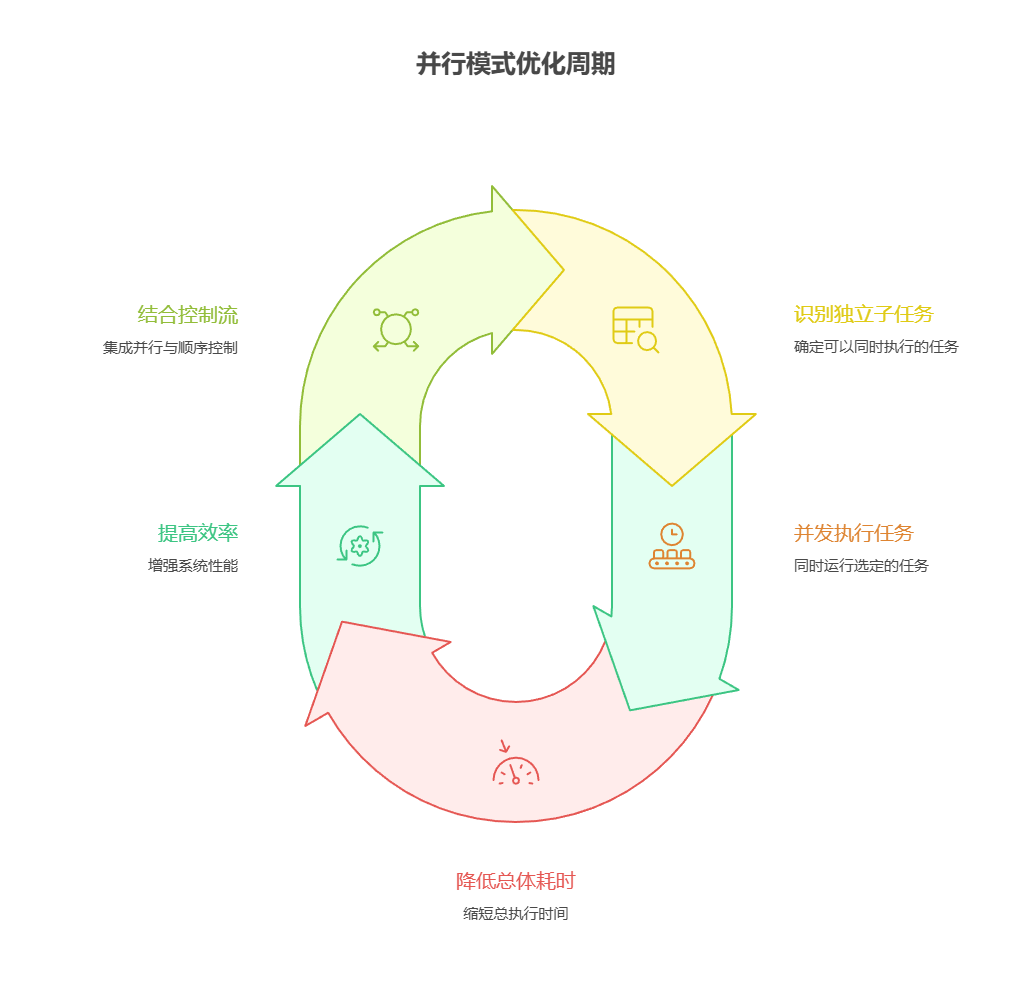
并行模式是通过并发执行独立子任务来优化计算流程。对于需要多次模型推理或调用外部服务的复杂操作,采用并行执行可以显著降低总体耗时并提高效率。
不同的框架为实现此模式提供了不同的机制。在 LangChain 中,像 RunnableParallel 这样的组件可以用于显式定义和执行多个处理链。相比之下,Google ADK 可以通过多智能体委派机制实现并行化,其中主协调器模型将不同的子任务分配给可以并发执行的专用智能体。
将并行处理与顺序(链式)和条件(路由)控制流结合起来,可以构建既复杂又高效的计算系统,从而更有效地管理各类复杂任务。
参考文献
以下是一些可供深入了解并行模式及其相关概念的推荐阅读资料:
暂时先这样吧,如果实在看不明白就留言,看到我会回复的。希望这个教程对您有帮助!
路漫漫其修远,与君共勉。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)