强化学习[chapter8] [page18]Deep Q learning
它开启了深度强化学习的新时代。:通过将“动作选择”(由main network 执行)和“价值评估”(由target network执行)进行解耦,打破了在最大化操作中容易产生的过度乐观估计的循环,使Q值估计更准确。在在线学习中,智能体接收到的是一系列连续、高度相关的状态转移数据。:单批次数据可能包含智能体在不同阶段、不同策略下的多样化经验,这有助于网络学习到更通用、更鲁棒的价值函数,避免对当前局
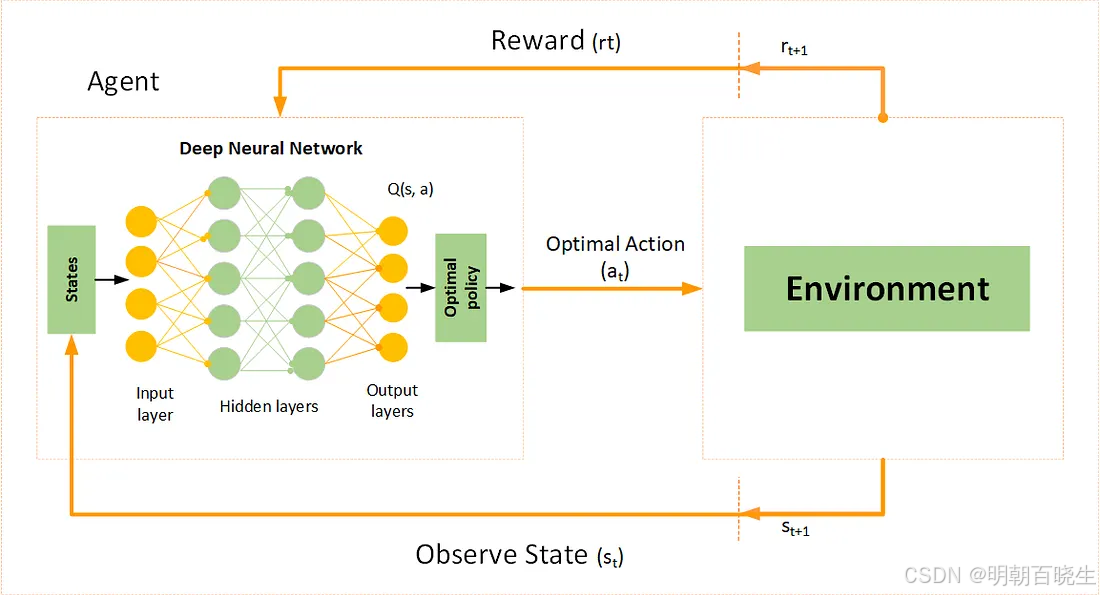
DQN是一种利用深度学习帮助机器在复杂情况下做出决策的方法。它在状态数量非常庞大的环境中尤其有用,例如视频游戏或机器人领域。
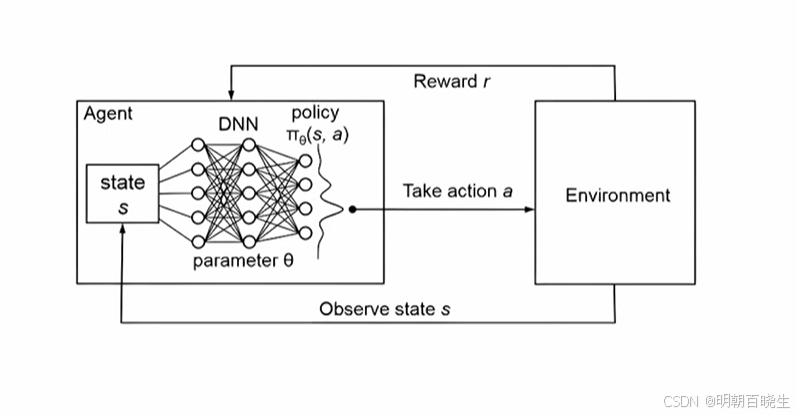
本章主要讲解一下DQN的原理,最后我们给出一个小车自动驾驶躲避障碍物的DQN 例子
目录
引言:从表格型方法到函数逼近
深度Q网络(DQN)原理简介
DQN的核心挑战与稳定化技术
3.1 经验回放机制
3.2 目标网络架构DQN算法训练流程详解
代码实现:基于Python的DQN实例分析
一 引言:从表格型方法到函数逼近

在表格型强化学习的价值函数方法中,我们学习了 Q-learning 和 SARSA 等算法。这些方法在状态空间较小时很有效,但当状态或动作空间较大时,则需要使用函数近似(如神经网络)来拟合价值函数。
问题:
底层的计算神经网络的梯度较为复杂,现代深度学习框架(如 PyTorch、TensorFlow)可以自动进行梯度计算与反向传播。深度 Q 网络(DQN)正是利用了这一特性,通过神经网络自动学习 Q 值的近似表示。
二 深度Q网络(DQN)原理简介
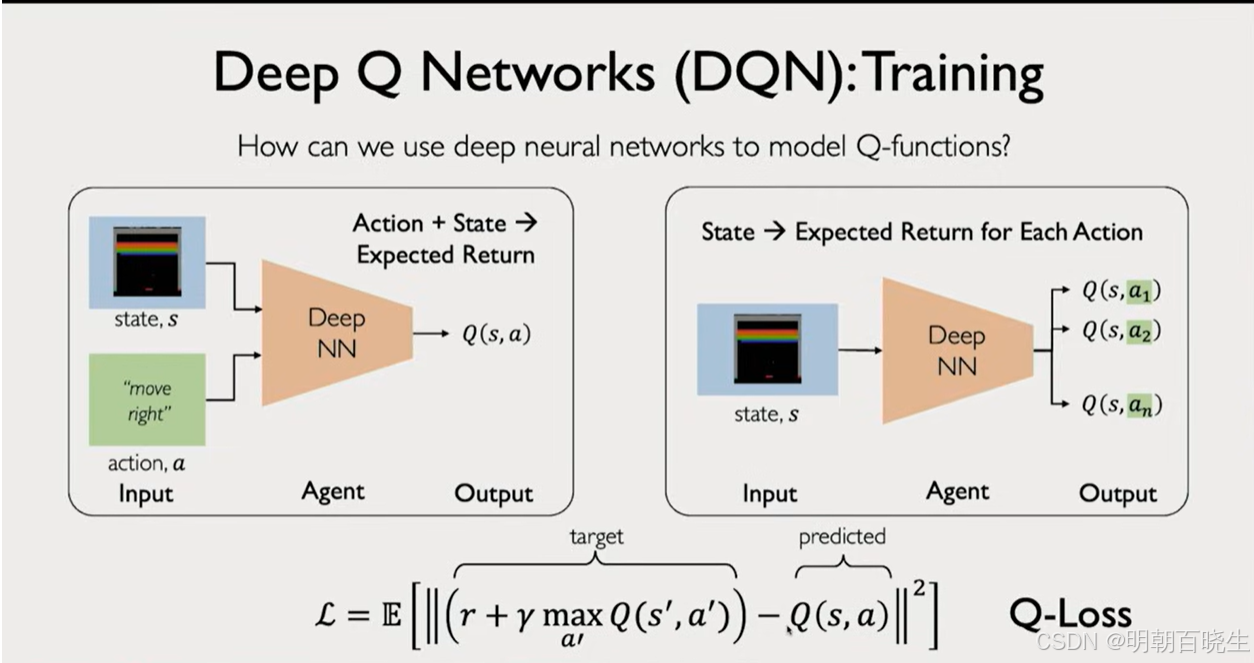
2013年,DeepMind在《自然》杂志上发表了一篇里程碑式的论文,展示了首个能够直接从像素输入学习玩Atari 2600游戏的AI系统。这个系统就是深度Q网络(Deep Q-Network, DQN),它开启了深度强化学习的新时代。与需要手工设计特征的早期游戏AI不同,DQN仅通过观察屏幕像素和游戏得分,就能在多种Atari游戏中达到甚至超越人类水平。今天,让我们深入探索这一开创性算法的内部工作原理。
DQN的目标函数(损失函数)
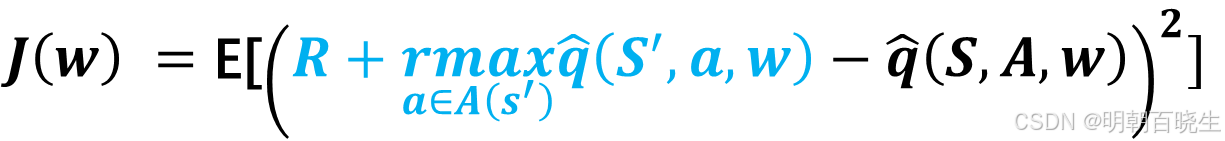
其中 是随机变量, 上面公式实际上是Bellman optimality errror
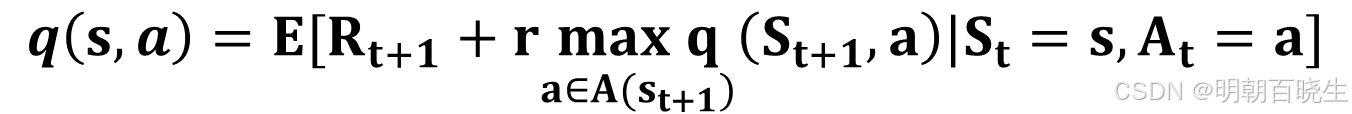
问题: 我们看到目标函数里面有两个w,求解相对复杂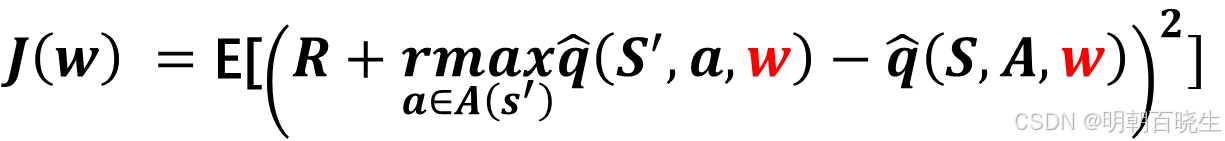
DQN 一个重要的创新点是引入了两个network:main network 和 Target Network
先固定 Target Network(
) 里面的 W ,这里面用
表示 ,
再求导 main Network(
) 的w 梯度
则目标函数可以转换为
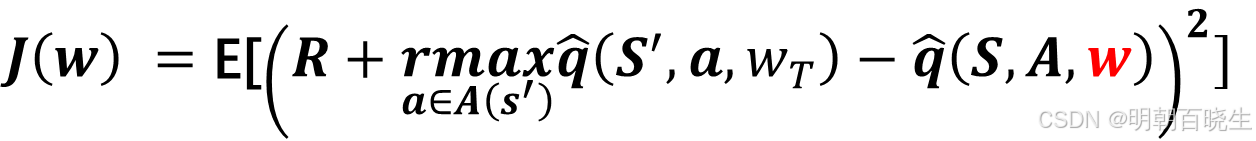
三 DQN的核心挑战与稳定化技术
1. 经验回放
1 原理介绍:
经验回放是一种数据存储与重用机制。智能体将与环境交互的每一步经验(即一个四元组( s, a, r, s‘))存储在一个固定容量的“Replay Buffer”中。在训练时,神经网络不再使用最新的单条经验,而是从这个缓冲区中以uniform distribution 随机采样一批历史经验进行学习2 解决了什么问题:
解决了数据时序相关性和非平稳分布带来的问题。问题阐述:
在在线学习中,智能体接收到的是一系列连续、高度相关的状态转移数据。这类似于让一个学生不停地学习同一章节的习题,而没有机会复习之前学过的章节。
直接后果:
灾难性遗忘:网络权重会快速过拟合到最近的局部经验,并遗忘之前学习到的模式。
训练低效且不稳定:连续相似数据产生的梯度高度相关且方差大,导致参数更新方向剧烈震荡,难以收敛。
3 优点:
打破数据相关性:随机采样使批量数据近似“独立同分布”,满足了监督学习对数据的基本假设,极大稳定了梯度下降过程。
提高数据效率:每一条经验都可以被多次采样和学习,大大提升了样本利用率。
促进知识泛化:单批次数据可能包含智能体在不同阶段、不同策略下的多样化经验,这有助于网络学习到更通用、更鲁棒的价值函数,避免对当前局部轨迹的过拟合。
2. 目标网络
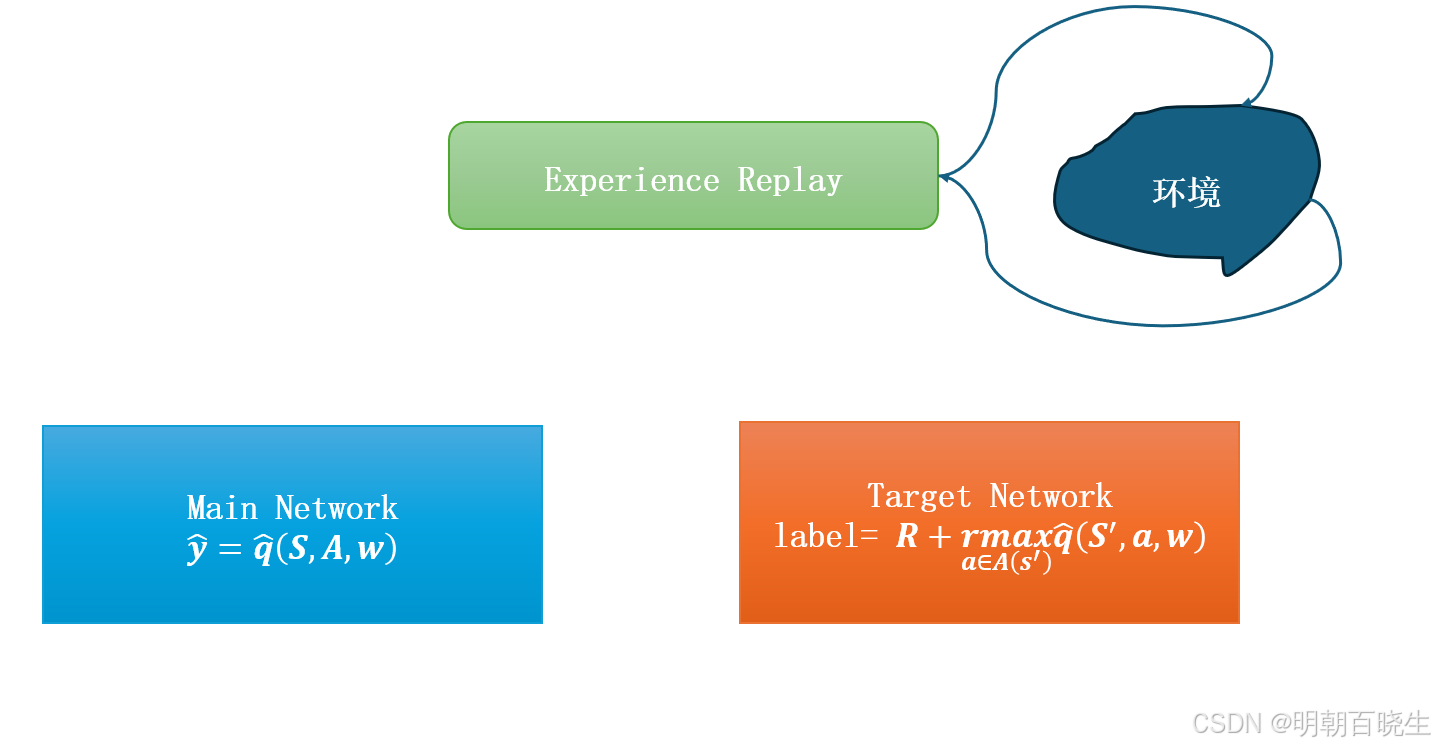
1 主要原理介绍:
目标网络是DQN中引入的第二个神经网络(target Network),其结构与主网络(main network)完全相同,但参数更新不同步。它主要用于计算Q学习中的目标Q值。其参数会定期(例如每N步)从在线网络复制过来,或在每次更新时以极小的比例向在线网络参数靠拢。2 解决了什么问题:
解决了“追逐移动目标”导致的训练不稳定性问题。
问题阐述:在标准Q学习中,我们使用同一个网络(参数为
w)来同时计算当前Q值(预测值)和未来Q值(目标值)。由于w在每一步训练后都会更新,导致我们用于计算损失函数的目标值本身也在不断移动。直接后果: 这类似于用一把时刻在变化的尺子来度量自己的长度。优化过程会陷入剧烈的振荡和反馈循环,导致训练难以收敛,甚至发散。
3 优点:
提供稳定的学习目标:在参数同步间隔期内,目标网络的参数是固定的,因此为目标Q值提供了一个短期稳定的基准。这使得在线网络的更新方向更加一致和可靠。
缓解Q值高估:通过将“动作选择”(由main network 执行)和“价值评估”(由target network执行)进行解耦,打破了在最大化操作中容易产生的过度乐观估计的循环,使Q值估计更准确。
实现平滑收敛:大量实验证明,这种延迟更新或软更新的目标网络机制,是DQN系列算法能够成功收敛并取得优异性能的根本原因之一
四 DQN算法训练流程详解
4.1 算法伪代码

4.2 训练流程
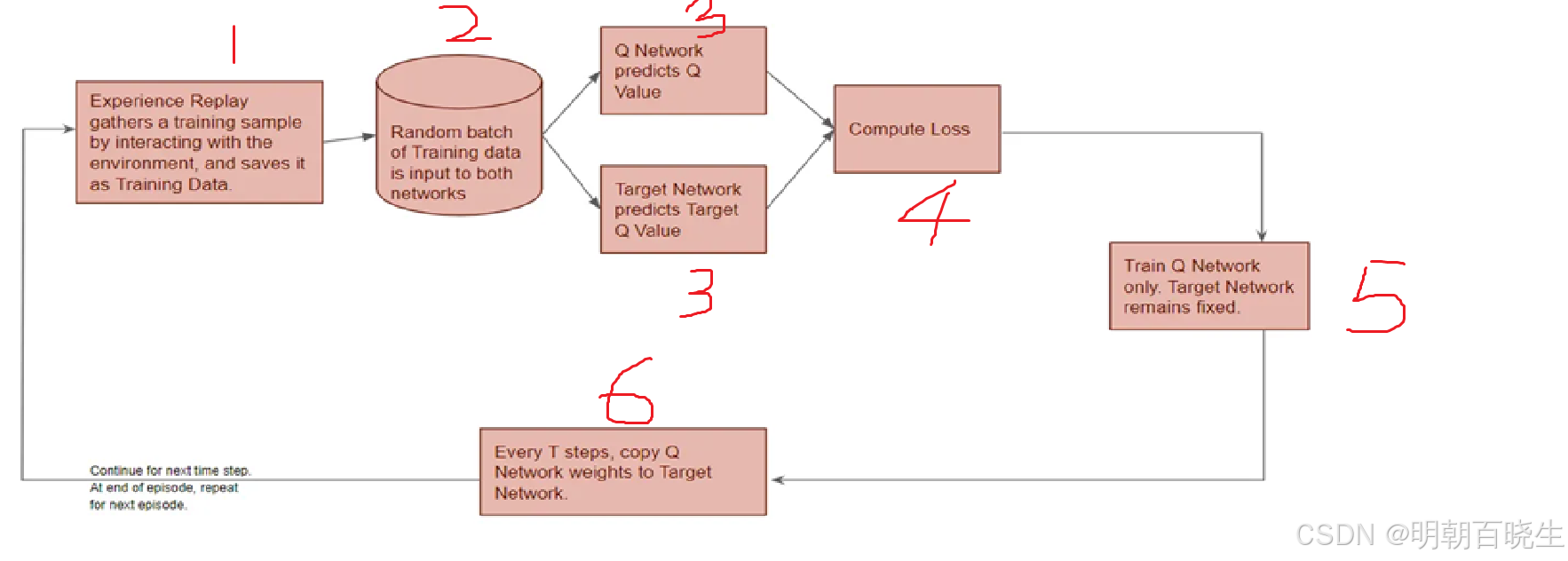
Step 1: 经验收集与存储
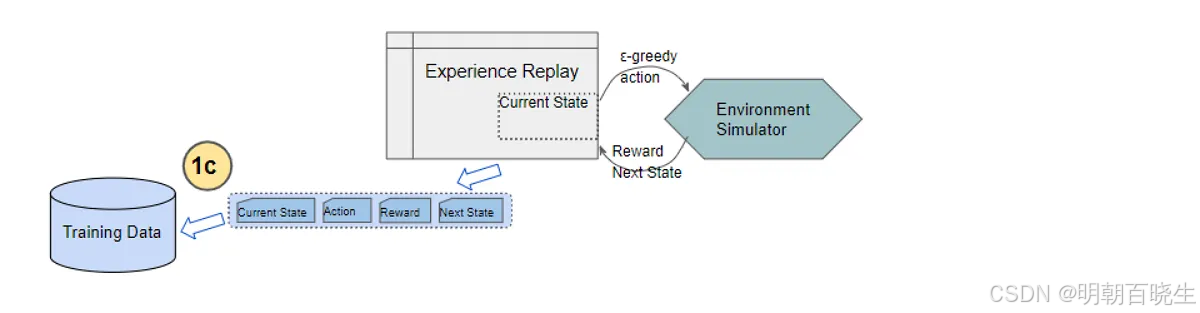
根据当前Q网络(Main Network)及ε-贪婪策略选择并执行动作。
观察环境反馈:获得奖励
r及下一状态s'。将完整转移样本
(s, a, r, s', done)存入经验回放缓冲区(Replay Buffer)
Step 2: 经验采样
当缓冲区中样本数量达到预设阈值后,开始训练。
从缓冲区中均匀随机采样一个小批量(mini-batch)的转移样本。
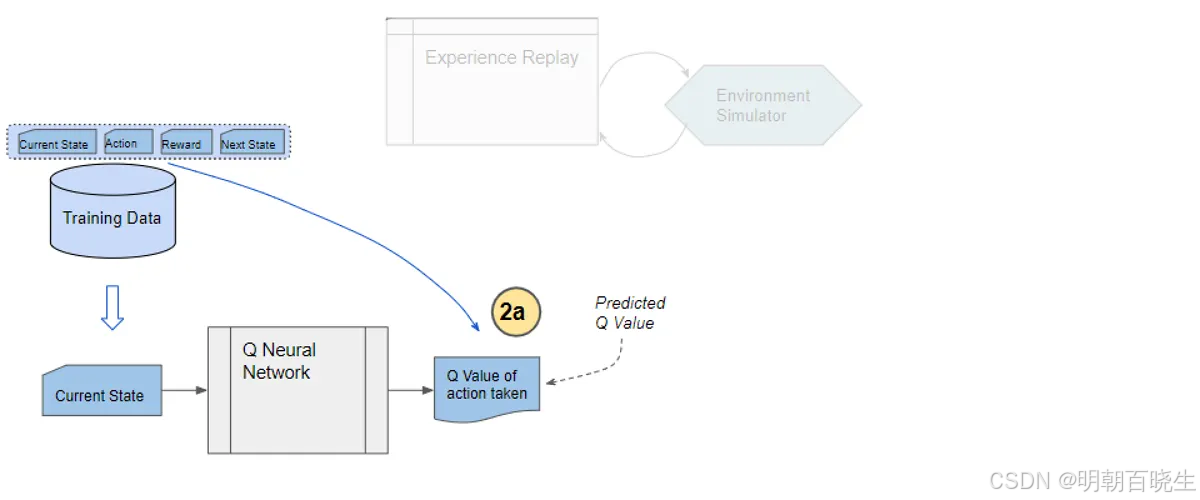
Step 3: 计算当前Q值(预测值)
将采样批次中的状态
s输入在线网络(Main Network)。网络输出该状态下所有动作的Q值
根据批次中实际执行的动作
a,选择对应的Q值作为当前Q值预测
。
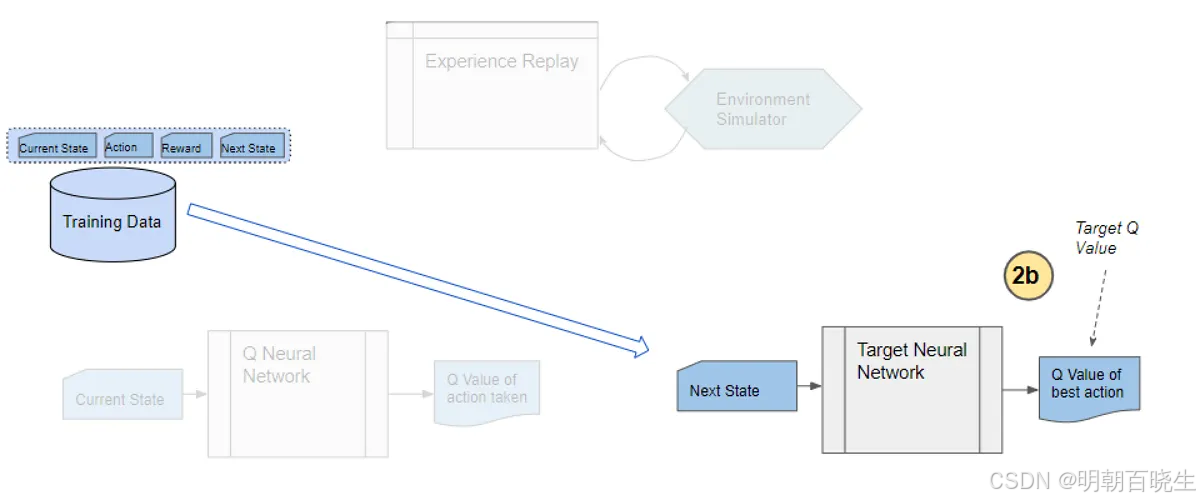
Step 4: 计算目标Q值
对于批次中每个样本的下一状态
s':
输入目标网络(Target Network),得到所有动作的Q值
选择最大Q值:
maxₐ′。计算目标Q值:
,其中
γ为折扣因子。
若
s'为终止状态(done=True),则y = r
Step 5: 计算损失并更新在线网络
计算损失函数(如均方误差MSE):
通过梯度下降法仅更新在线网络的参数w,以最小化损失。
目标网络的参数
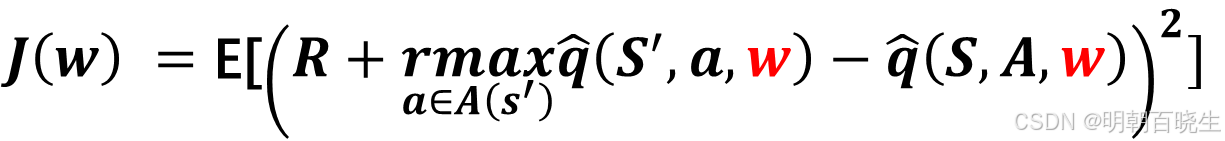
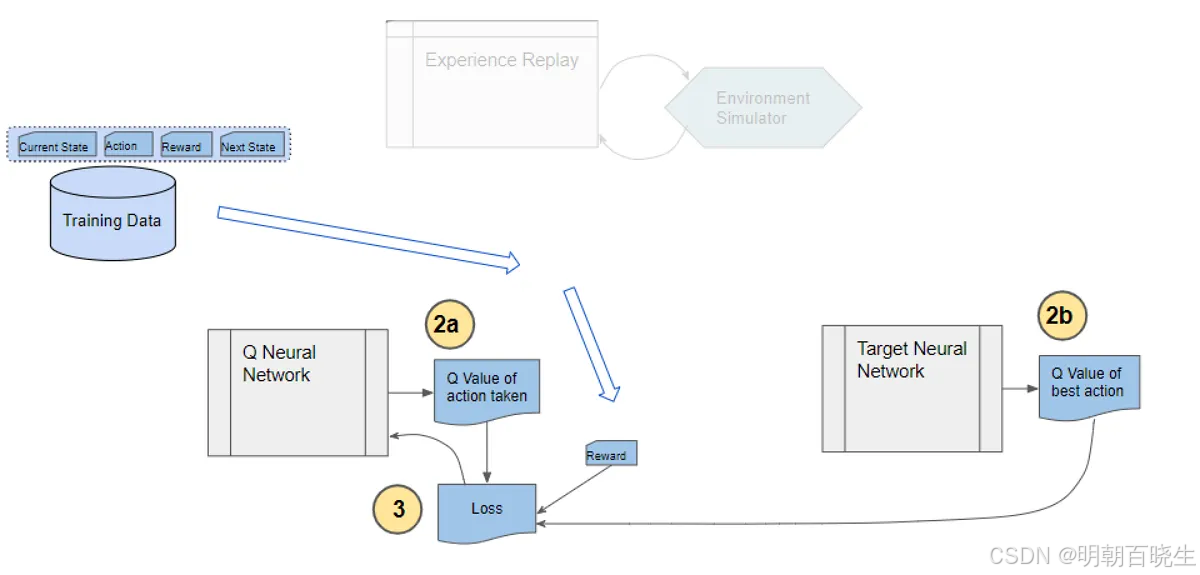
Step 6: 定期同步目标网络
每隔固定的训练步数(如
C=10000步),将在线网络的参数完全复制到目标网络:。
或采用软更新方式,每次训练后以微小系数τ混合参数:
https://www.youtube.com/watch?v=wc-FxNENg9U
五 Python 例子
1:dqn_model.py - 模型部分
# dqn_model.py
"""
深度Q网络(DQN)模型
"""
import torch
import torch.nn as nn
class DeepQNetwork(nn.Module):
"""
深度Q网络类
"""
def __init__(self, input_dim: int = 21, fc1_dim: int = 128,
fc2_dim: int = 64, n_actions: int = 7):
super(DeepQNetwork, self).__init__()
self.input_dim = input_dim
self.n_actions = n_actions
# 网络结构
self.layers = nn.Sequential(
nn.Linear(input_dim, fc1_dim),
nn.ReLU(),
nn.Linear(fc1_dim, fc2_dim),
nn.ReLU(),
nn.Linear(fc2_dim, n_actions)
)
# 初始化权重
for layer in self.layers:
if isinstance(layer, nn.Linear):
nn.init.kaiming_normal_(layer.weight, nonlinearity='relu')
nn.init.zeros_(layer.bias)
def forward(self, state: torch.Tensor) -> torch.Tensor:
if state.dim() == 1:
state = state.unsqueeze(0)
q_values = self.layers(state)
return q_values
def create_dqn_model(input_dim: int = 21, **kwargs) -> DeepQNetwork:
"""
创建DQN模型
"""
default_kwargs = {
'fc1_dim': 128,
'fc2_dim': 64,
'n_actions': 7
}
default_kwargs.update(kwargs)
model = DeepQNetwork(input_dim=input_dim, **default_kwargs)
print(f"创建DQN模型: "
f"输入维度={input_dim}, "
f"动作数={default_kwargs['n_actions']}")
return model
if __name__ == "__main__":
# 测试模型
model = create_dqn_model()
test_input = torch.randn(2, 21)
output = model(test_input)
print(f"测试输入形状: {test_input.shape}")
print(f"输出形状: {output.shape}")2 enviroment.py
"""
智能小车避障环境 - 优化版(带碰撞提示延时)
创建于:2025年12月30日
作者:chengxf2
"""
import numpy as np
import pygame
import math
import random
import os
from typing import Tuple, List, Optional
from dataclasses import dataclass
@dataclass
class EnvironmentConfig:
"""
环境配置参数类
"""
# 屏幕尺寸参数
screen_width: int = 800
screen_height: int = 800
grid_cols = 5
grid_rows = 5
# 每个网格单元格的宽度和高度
cell_width = screen_width // grid_cols
cell_height = screen_height // grid_rows
# 小车尺寸参数
car_width: int = 40
car_height: int = 40
# 目标参数
goal_radius: int = 40
# 小车运动参数
car_speed: float = 6.0
turn_angle: float = 2.0
# 障碍物参数
num_obstacles: int = 4
obstacle_radius: int = 30
# 训练/仿真参数
max_steps: int = 512
max_perception_distance: float = 256
# 渲染参数
frames_per_second: int = 10
# 碰撞提示参数(新增)
collision_prompt_delay_frames: int = 20 # 碰撞提示显示的帧数
# 图片路径参数
car_image_path: str = "car.png"
obstacle_image_path: str = "obstacles.png"
goal_image_path: str = "goal.png"
# 奖励参数
reward_goal: float = 10.0
reward_collision: float = -100.0
reward_step: float = -0.01
reward_distance_scale: float = 0.1
reward_boundary: float = -10.0
# 固定位置参数
car_start_x: float = None
car_start_y: float = None
goal_x: float = None
goal_y: float = None
def __post_init__(self):
"""设置默认固定位置"""
if self.car_start_x is None:
self.car_start_x = self.screen_width//2
if self.car_start_y is None:
self.car_start_y = self.screen_height-self.car_height
#目标位置
self.goal_x = self.cell_width*3+ self.cell_width // 2 # 网格中心的x坐标
self.goal_y = self.cell_height*2 +self.cell_height // 2 # 网格中心的y坐标
def validate(self) -> bool:
"""验证配置参数的有效性"""
errors = []
if self.screen_width <= 0 or self.screen_height <= 0:
errors.append("屏幕尺寸必须大于0")
if self.car_width <= 0 or self.car_height <= 0:
errors.append("小车尺寸必须大于0")
if self.car_speed <= 0:
errors.append("小车速度必须大于0")
if self.num_obstacles < 0:
errors.append("障碍物数量不能为负数")
if self.max_steps <= 0:
errors.append("最大步数必须大于0")
if self.frames_per_second <= 0:
errors.append("帧率必须大于0")
if self.collision_prompt_delay_frames <= 0:
errors.append("碰撞提示延时帧数必须大于0")
# 验证固定位置在屏幕内
if not (0 <= self.car_start_x <= self.screen_width):
errors.append(f"小车X位置必须在0到{self.screen_width}之间")
if not (0 <= self.car_start_y <= self.screen_height):
errors.append(f"小车Y位置必须在0到{self.screen_height}之间")
if not (0 <= self.goal_x <= self.screen_width):
errors.append(f"目标X位置必须在0到{self.screen_width}之间")
if not (0 <= self.goal_y <= self.screen_height):
errors.append(f"目标Y位置必须在0到{self.screen_height}之间")
if errors:
print(f"配置验证失败: {errors}")
return False
return True
class CarEnvironment:
"""
智能小车避障环境
"""
# === 动作定义 ===
ACTION_TURN_LEFT = 0
ACTION_TURN_RIGHT = 1
ACTION_MOVE_FORWARD = 2
ACTION_MOVE_BACKWARD = 3
ACTION_TURN_LEFT_FORWARD = 4
ACTION_TURN_RIGHT_FORWARD = 5
ACTION_STAY = 6
actions = [ACTION_TURN_LEFT, ACTION_TURN_RIGHT, ACTION_MOVE_FORWARD,
ACTION_MOVE_BACKWARD, ACTION_TURN_LEFT_FORWARD,
ACTION_TURN_RIGHT_FORWARD, ACTION_STAY]
# 动作名称映射
ACTION_NAMES = {
ACTION_TURN_LEFT: "左转",
ACTION_TURN_RIGHT: "右转",
ACTION_MOVE_FORWARD: "前进",
ACTION_MOVE_BACKWARD: "后退",
ACTION_TURN_LEFT_FORWARD: "左转前进",
ACTION_TURN_RIGHT_FORWARD: "右转前进",
ACTION_STAY: "保持"
}
# === 颜色定义 ===
COLOR_WHITE = (255, 255, 255)
COLOR_BLACK = (0, 0, 0)
COLOR_RED = (255, 0, 0)
COLOR_GREEN = (0, 255, 0)
COLOR_BLUE = (0, 0, 255)
COLOR_YELLOW = (255, 255, 0)
COLOR_ORANGE = (255, 165, 0)
COLOR_PURPLE = (128, 0, 128)
COLOR_CYAN = (0, 255, 255)
# === 奖励函数常量 ===
REWARD_GOAL_REACHED = 100.0
REWARD_COLLISION_PENALTY = -20.0
REWARD_STEP_PENALTY = -0.01
REWARD_DISTANCE_IMPROVED = 1.0
REWARD_DISTANCE_WORSE = -0.5
REWARD_DIRECTION_ALIGNED = 0.5
REWARD_MOVING_TOWARD_GOAL = 0.2
REWARD_TIME_PENALTY = -0.1
REWARD_BOUNDARY_PENALTY = -10.0
# === 碰撞状态常量 ===
COLLISION_NONE = 0
COLLISION_OBSTACLE = 1
COLLISION_GOAL = 2
COLLISION_BOUNDARY = 3
def __init__(self, render: bool = False, config: Optional[EnvironmentConfig] = None):
"""
初始化小车避障环境 - 优化版
参数:
render: 是否启用可视化渲染
config: 环境配置参数
"""
# 环境配置管理
self.config = config if config is not None else EnvironmentConfig()
# 渲染模式
self.render_mode = render
# 状态变量初始化
self._initialize_state_variables()
# 渲染系统初始化
if self.render_mode:
self._initialize_pygame()
self._load_images()
# 环境状态重置
self.reset()
self.collision_times = 0
#print(f"小车避障环境初始化完成: {self.get_environment_info()}")
def _initialize_state_variables(self):
"""初始化状态变量"""
self._car_position = np.zeros(2, dtype=np.float32)
self._car_angle = 0.0
self._goal_position = np.zeros(2, dtype=np.float32)
self._obstacle_positions = []
self._current_step = 0
self._last_position = None
self._last_goal_distance = None
# 碰撞状态变量
self._collision_state = self.COLLISION_NONE
self._collision_timer = 0
self._collision_message = ""
self._boundary_collision_count = 0
# 渲染系统变量
self.screen = None
self.clock = None
self.font = None
# 图片资源
self.car_image = None
self.obstacle_image = None
self.goal_image = None
# 状态追踪变量
self.current_state = None
self.new_state = None
# 空间维度定义
self.state_dimension = self._calculate_state_dimension()
self.action_dimension = 7
def _initialize_pygame(self):
"""初始化 Pygame 渲染系统"""
try:
pygame.init()
self.screen = pygame.display.set_mode((self.config.screen_width, self.config.screen_height))
pygame.display.set_caption("智能小车避障环境 - 固定位置版")
self.clock = pygame.time.Clock()
# 加载字体
self._load_fonts()
print("Pygame 渲染系统初始化成功")
except Exception as e:
print(f"Pygame 初始化失败: {e}")
self.render_mode = False
def _load_fonts(self):
"""加载字体"""
try:
font_path = "C:/Windows/Fonts/simhei.ttf"
self.font = pygame.font.Font(font_path, 24)
self.message_font = pygame.font.Font(font_path, 28)
except:
self.font = pygame.font.SysFont(None, 24)
self.message_font = pygame.font.SysFont(None, 28)
def _load_images(self):
"""加载图片资源"""
try:
# 小车图片
if os.path.exists(self.config.car_image_path):
car_img = pygame.image.load(self.config.car_image_path)
self.car_image = pygame.transform.scale(car_img,
(self.config.car_width, self.config.car_height))
# 障碍物图片
if os.path.exists(self.config.obstacle_image_path):
obs_img = pygame.image.load(self.config.obstacle_image_path)
self.obstacle_image = pygame.transform.scale(obs_img,
(self.config.obstacle_radius * 2,
self.config.obstacle_radius * 2))
# 目标图片
if os.path.exists(self.config.goal_image_path):
goal_img = pygame.image.load(self.config.goal_image_path)
self.goal_image = pygame.transform.scale(goal_img,
(self.config.goal_radius * 2,
self.config.goal_radius * 2))
print("图片资源加载成功")
except Exception as e:
print(f"图片资源加载失败: {e}")
def get_environment_info(self) -> str:
"""获取环境信息字符串"""
return (f"状态维度: {self.state_dimension}, "
f"动作维度: {self.action_dimension}, "
f"屏幕尺寸: {self.config.screen_width}x{self.config.screen_height}, "
f"碰撞提示延时: {self.config.collision_prompt_delay_frames}帧")
def _calculate_state_dimension(self) -> int:
"""
计算状态向量的维度 - 增强版
状态向量包含:
1. 小车位置 (x, y) - 2维
2. 目标方向向量 (dx, dy) - 2维
3. 小车方向向量 (dx, dy) - 2维
4. 到目标的距离 - 1维
5. 最近的5个障碍物信息 (距离, dx, dy) * 5 - 15维
6. 上一帧到目标的距离 - 1维
总计: 23维
"""
return 20
def reset(self) -> np.ndarray:
"""
重置环境到初始状态 - 固定位置版
所有位置固定:
1. 小车位置:屏幕底部中央
2. 目标位置:屏幕右上角
3. 障碍物位置:屏幕中间区域固定位置
"""
# 重置小车初始位置(固定位置)
self._car_position[0] = self.config.car_start_x
self._car_position[1] = self.config.car_start_y
# 重置小车方向(朝上,指向目标方向)
self._car_angle = 0.0
# 目标位置(固定位置)
self._goal_position[0] = self.config.goal_x
self._goal_position[1] = self.config.goal_y
# 生成固定障碍物位置
self._obstacle_positions = self._generate_fixed_obstacle_positions()
# 重置步数计数器
self._current_step = 0
# 重置碰撞状态
self._collision_state = self.COLLISION_NONE
self._collision_timer = 0
self._collision_message = ""
self._boundary_collision_count = 0
# 获取归一化初始状态
self.current_state = self.get_normalized_state()
self.new_state = None
self._last_position = self._car_position.copy()
self.collision_times = 0
# 计算初始到目标的距离
self._last_goal_distance = self._calculate_goal_distance()
'''
print(f"环境重置完成:")
print(f" 小车位置: ({self._car_position[0]:.1f}, {self._car_position[1]:.1f})")
print(f" 目标位置: ({self._goal_position[0]:.1f}, {self._goal_position[1]:.1f})")
print(f" 障碍物数量: {len(self._obstacle_positions)}")
print(f" 碰撞提示延时: {self.config.collision_prompt_delay_frames}帧")
'''
return self.current_state
def _generate_fixed_obstacle_positions(self) -> List[Tuple[float, float]]:
"""生成固定障碍物位置"""
obstacle_positions = []
#print("\n ---generate")
# 根据障碍物数量生成固定位置
if self.config.num_obstacles >= 1:
x = self.config.cell_width + self.config.cell_width // 2 # 网格中心的x坐标
y = self.config.cell_height +self.config.cell_height // 2 # 网格中心的y坐标
obstacle_positions.append((x, y))
if self.config.num_obstacles >= 2:
x = self.config.cell_width * 3 + self.config.cell_width // 2 # 网格中心的x坐标
y = self.config.cell_height +self.config.cell_height // 2 # 网格中心的y坐标
obstacle_positions.append((x, y))
if self.config.num_obstacles >= 3:
x = self.config.cell_width + self.config.cell_width // 2 # 网格中心的x坐标
y = self.config.cell_height * 3 +self.config.cell_height // 2 # 网格中心的y坐标
obstacle_positions.append((x, y))
if self.config.num_obstacles >= 4:
x = self.config.cell_width*3 + self.config.cell_width // 2 # 网格中心的x坐标
y = self.config.cell_height * 3 +self.config.cell_height // 2 # 网格中心的y坐标
obstacle_positions.append((x, y))
# 验证障碍物位置有效性
valid_positions = []
for pos in obstacle_positions:
if self._is_valid_obstacle_position(pos, valid_positions):
valid_positions.append(pos)
else:
print("---------------")
adjusted_pos = self._adjust_obstacle_position(pos, valid_positions)
valid_positions.append(adjusted_pos)
return valid_positions
def _adjust_obstacle_position(self, position: Tuple[float, float],
existing_positions: List[Tuple[float, float]]) -> Tuple[float, float]:
"""调整障碍物位置以避免重叠"""
x, y = position
attempts = 0
max_attempts = 10
while attempts < max_attempts:
# 在周围小范围内随机调整位置
offset_x = random.uniform(-50, 50)
offset_y = random.uniform(-50, 50)
new_position = (x + offset_x, y + offset_y)
# 确保在屏幕内
new_position = (
max(self.config.obstacle_radius,
min(new_position[0], self.config.screen_width - self.config.obstacle_radius)),
max(self.config.obstacle_radius,
min(new_position[1], self.config.screen_height - self.config.obstacle_radius))
)
if self._is_valid_obstacle_position(new_position, existing_positions):
return new_position
attempts += 1
# 如果无法找到合适位置,返回原始位置
return position
def _is_valid_obstacle_position(self, new_position: Tuple[float, float],
existing_positions: List[Tuple[float, float]]) -> bool:
"""检查障碍物位置是否有效"""
# 确保不与其他障碍物重叠
for existing_pos in existing_positions:
distance = math.hypot(existing_pos[0] - new_position[0],
existing_pos[1] - new_position[1])
if distance < self.config.obstacle_radius * 3:
return False
# 确保不在小车初始位置附近
distance_to_car = math.hypot(self._car_position[0] - new_position[0],
self._car_position[1] - new_position[1])
if distance_to_car < self.config.obstacle_radius * 3 + self.config.car_width:
return False
# 确保不在目标位置附近
distance_to_goal = math.hypot(self._goal_position[0] - new_position[0],
self._goal_position[1] - new_position[1])
if distance_to_goal < self.config.obstacle_radius * 3 + self.config.goal_radius:
return False
return True
def _calculate_goal_distance(self) -> float:
"""计算小车到目标的欧几里得距离"""
return math.hypot(
self._car_position[0] - self._goal_position[0],
self._car_position[1] - self._goal_position[1]
)
def _get_state_vector(self) -> np.ndarray:
"""获取当前环境的原始状态向量表示 - 增强版"""
state_components = []
# 1. 小车原始位置
state_components.append(self._car_position[0])
state_components.append(self._car_position[1])
# 2. 目标方向向量
goal_direction = self._calculate_direction_vector(self._car_position, self._goal_position)
state_components.extend(goal_direction)
# 3. 小车方向向量
car_direction = self._calculate_car_direction()
state_components.extend(car_direction)
# 4. 到目标的距离
goal_distance = self._calculate_goal_distance()
state_components.append(goal_distance)
# 5. 障碍物信息(最近的5个障碍物)
obstacle_info = self._get_obstacle_information(
max_obstacles=self.config.num_obstacles)
state_components.extend(obstacle_info)
# 6. 上一帧到目标的距离
if self._last_goal_distance is not None:
state_components.append(self._last_goal_distance)
else:
state_components.append(goal_distance)
# 转换为numpy数组并验证维度
state = np.array(state_components, dtype=np.float32)
expected_dim = self._calculate_state_dimension()
if len(state) != expected_dim:
print(f"状态维度错误: 期望 {expected_dim}, 实际 {len(state)}")
state = self._adjust_state_dimension(state, expected_dim)
return state
def _adjust_state_dimension(self, state: np.ndarray, expected_dim: int) -> np.ndarray:
"""调整状态向量维度"""
if len(state) < expected_dim:
return np.pad(state, (0, expected_dim - len(state)), mode='constant')
else:
return state[:expected_dim]
def _calculate_direction_vector(self, from_pos: np.ndarray, to_pos: np.ndarray) -> List[float]:
"""计算从from_pos到to_pos的方向向量"""
return [to_pos[0] - from_pos[0], to_pos[1] - from_pos[1]]
def _calculate_car_direction(self) -> List[float]:
"""计算小车当前方向的单位向量"""
angle_rad = math.radians(self._car_angle)
return [math.sin(angle_rad), -math.cos(angle_rad)]
def _get_obstacle_information(self, max_obstacles: int = 5) -> List[float]:
"""获取最近的障碍物信息"""
obstacle_info = []
# 计算到每个障碍物的距离
obstacle_distances = []
for obstacle in self._obstacle_positions:
distance = math.hypot(obstacle[0] - self._car_position[0],
obstacle[1] - self._car_position[1])
obstacle_distances.append((distance, obstacle))
# 按距离排序并获取最近的障碍物
obstacle_distances.sort(key=lambda x: x[0])
for i in range(min(max_obstacles, len(obstacle_distances))):
distance, obstacle = obstacle_distances[i]
obstacle_info.append(distance)
obstacle_info.append(obstacle[0] - self._car_position[0])
obstacle_info.append(obstacle[1] - self._car_position[1])
# 如果障碍物不足,填充零值
while len(obstacle_info) < max_obstacles * 3:
obstacle_info.append(0.0)
return obstacle_info
def get_normalized_state(self) -> np.ndarray:
"""获取归一化状态向量 - 优化版"""
raw_state = self._get_state_vector()
normalized_state = []
# 1. 小车位置归一化到[0, 1]
normalized_state.append(raw_state[0] / self.config.screen_width)
normalized_state.append(raw_state[1] / self.config.screen_height)
# 2. 目标方向向量归一化到[-1, 1]
max_dim = max(self.config.screen_width, self.config.screen_height)
normalized_state.append(raw_state[2] / max_dim)
normalized_state.append(raw_state[3] / max_dim)
# 3. 小车方向向量已经在[-1, 1]范围内
normalized_state.append(raw_state[4])
normalized_state.append(raw_state[5])
# 4. 到目标的距离归一化到[0, 1]
max_distance = math.hypot(self.config.screen_width, self.config.screen_height)
normalized_state.append(min(raw_state[6] / max_distance, 1.0))
# 5. 障碍物信息归一化
for i in range(7, len(raw_state) - 1, 3):
distance = raw_state[i]
if distance > 0:
norm_dist = min(distance / self.config.max_perception_distance, 1.0)
normalized_state.append(norm_dist)
else:
normalized_state.append(0.0)
normalized_state.append(raw_state[i + 1] / max_dim)
normalized_state.append(raw_state[i + 2] / max_dim)
# 6. 上一帧距离归一化
normalized_state.append(min(raw_state[-1] / max_distance, 1.0))
# 转换为numpy数组并处理无效值
normalized_state = np.array(normalized_state, dtype=np.float32)
if not np.all(np.isfinite(normalized_state)):
normalized_state = np.nan_to_num(normalized_state)
return normalized_state
def _execute_action(self, action: int) -> None:
"""
根据动作编号执行相应的动作 - 优化版
支持组合动作
"""
turn_angle = self.config.turn_angle
if action == self.ACTION_TURN_LEFT:
# 左转
self._car_angle -= turn_angle
self._car_angle = self._car_angle % 360
elif action == self.ACTION_TURN_RIGHT:
# 右转
self._car_angle += turn_angle
self._car_angle = self._car_angle % 360
elif action == self.ACTION_MOVE_FORWARD:
# 前进
self._move_forward()
elif action == self.ACTION_MOVE_BACKWARD:
# 后退
self._move_backward()
elif action == self.ACTION_TURN_LEFT_FORWARD:
# 左转前进(组合动作)
self._car_angle -= turn_angle
self._car_angle = self._car_angle % 360
self._move_forward()
elif action == self.ACTION_TURN_RIGHT_FORWARD:
# 右转前进(组合动作)
self._car_angle += turn_angle
self._car_angle = self._car_angle % 360
self._move_forward()
elif action == self.ACTION_STAY:
# 保持:不执行任何动作
pass
def _move_forward(self):
"""向前移动小车"""
angle_rad = math.radians(self._car_angle)
self._car_position[0] += self.config.car_speed * math.sin(angle_rad)
self._car_position[1] -= self.config.car_speed * math.cos(angle_rad)
def _move_backward(self):
"""向后移动小车"""
angle_rad = math.radians(self._car_angle)
self._car_position[0] -= self.config.car_speed * math.sin(angle_rad)
self._car_position[1] += self.config.car_speed * math.cos(angle_rad)
def _enforce_boundary_constraints(self) -> Tuple[bool, str]:
"""
确保小车不超出屏幕边界,并检测边界碰撞
返回:
Tuple[bool, str]: (是否发生边界碰撞, 碰撞边界描述)
"""
boundary_collision = False
boundary_description = ""
# X轴边界检测
if self._car_position[0] < 0:
self._car_position[0] = 0
boundary_collision = True
boundary_description = "左边界"
elif self._car_position[0] > self.config.screen_width:
self._car_position[0] = self.config.screen_width
boundary_collision = True
boundary_description = "右边界"
# Y轴边界检测
if self._car_position[1] < 0:
self._car_position[1] = 0
boundary_collision = True
if boundary_description:
boundary_description += "和上边界"
else:
boundary_description = "上边界"
elif self._car_position[1] > self.config.screen_height:
self._car_position[1] = self.config.screen_height
boundary_collision = True
if boundary_description:
boundary_description += "和下边界"
else:
boundary_description = "下边界"
return boundary_collision, boundary_description
def _handle_collision_prompt(self, collision_type: int, collision_details: str = ""):
"""
处理碰撞提示 - 支持延时功能
参数:
collision_type: 碰撞类型
collision_details: 碰撞详细信息
"""
self._collision_state = collision_type
self._collision_timer = self.config.collision_prompt_delay_frames # 使用配置的延时帧数
# 设置碰撞消息
if collision_type == self.COLLISION_OBSTACLE:
self._collision_message = f"⚠️ 小车碰到障碍物!{collision_details}"
elif collision_type == self.COLLISION_GOAL:
self._collision_message = f"🎯 小车到达目标!{collision_details}"
elif collision_type == self.COLLISION_BOUNDARY:
self._boundary_collision_count += 1
self._collision_message = f"🚫 小车碰到边界!{collision_details}"
#print(f"边界碰撞: {collision_details} (累计碰撞次数: {self._boundary_collision_count})")
#print(f"碰撞提示: {self._collision_message},将显示 {self._collision_timer} 帧")
def _update_collision_timer(self):
"""更新碰撞提示计时器"""
if self._collision_timer > 0:
self._collision_timer -= 1
if self._collision_timer == 0:
#print("碰撞提示已消失")
self._collision_message = ""
def step(self, action: int) -> Tuple[np.ndarray, float, bool, dict]:
"""
执行一个时间步的动作 - 优化版
返回:
Tuple: (新状态, 奖励, 终止标志, 信息字典)
"""
# 验证动作有效性
if not 0 <= action < self.action_dimension:
action = self.ACTION_STAY
# 更新碰撞提示计时器
self._update_collision_timer()
# 保存当前状态和距离
self.current_state = self.get_normalized_state()
previous_distance = self._last_goal_distance
# 执行动作
self._execute_action(action)
# 检查边界碰撞并强制执行边界约束
boundary_collision, boundary_description = self._enforce_boundary_constraints()
# 计算奖励和终止标志
reward, terminated, info = self._calculate_reward_and_termination(
previous_distance, boundary_collision, boundary_description
)
# 更新步数计数器
self._current_step += 1
# 检查步数限制
if self._current_step >= self.config.max_steps:
terminated = True
info["termination_reason"] = "max_steps_reached"
#print(f"达到最大步数限制: {self.config.max_steps}")
# 获取新状态
self.new_state = self.get_normalized_state()
# 更新上一帧到目标的距离
self._last_goal_distance = self._calculate_goal_distance()
# 在info字典中添加信息
info.update({
"current_state": self.current_state.copy(),
"new_state": self.new_state.copy(),
"action": action,
"action_name": self.ACTION_NAMES.get(action, "未知"),
"step": self._current_step,
"goal_distance": self._last_goal_distance,
"collision_state": self._collision_state,
"collision_message": self._collision_message,
"collision_timer": self._collision_timer,
"boundary_collision_count": self._boundary_collision_count
})
# 只在有变化时打印详细信息
'''
if info['collision_message'] or reward != self.REWARD_STEP_PENALTY:
print(f"步骤 {self._current_step}: "
f"动作={info['action_name']}({action}), "
f"奖励={reward:.2f}, 距离={self._last_goal_distance:.1f}, "
f"终止={terminated}, 碰撞提示剩余={self._collision_timer}帧")
'''
return self.new_state, reward, terminated, info
def _calculate_reward_and_termination(self, previous_distance: float,
boundary_collision: bool = False,
boundary_description: str = "") -> Tuple[float, bool, dict]:
"""
计算当前时间步的奖励和终止条件 - 优化版
"""
reward = self.REWARD_STEP_PENALTY
terminated = False
info = {"termination_reason": "none"}
# 计算到目标的距离
current_goal_distance = self._calculate_goal_distance()
#1 到达目标奖赏
if current_goal_distance < (self.config.goal_radius + self.config.car_width):
reward += self.REWARD_GOAL_REACHED
terminated = True
info["termination_reason"] = "goal_reached"
self._handle_collision_prompt(
self.COLLISION_GOAL,
f"到达目标!距离: {current_goal_distance:.1f},奖励: {self.REWARD_GOAL_REACHED:.2f}"
)
return reward, terminated, info
# 2 障碍物碰撞奖赏
collision_detected, obstacle_index = self._check_collision_with_details()
if collision_detected:
reward += self.REWARD_COLLISION_PENALTY
terminated = True
info["termination_reason"] = "collision"
self._handle_collision_prompt(
self.COLLISION_OBSTACLE,
f"碰撞障碍物 #{obstacle_index + 1}"
)
return reward, terminated, info
# 3 检查是否发生边界碰撞奖赏
if boundary_collision:
reward += self.REWARD_BOUNDARY_PENALTY
self._handle_collision_prompt(
self.COLLISION_BOUNDARY,
f"碰撞{boundary_description},惩罚: {self.REWARD_BOUNDARY_PENALTY:.2f}"
)
# 4. 距离改进奖励
if previous_distance is not None:
distance_change = previous_distance - current_goal_distance
if distance_change > 0:
reward += self.REWARD_DISTANCE_IMPROVED * distance_change
else:
reward += self.REWARD_DISTANCE_WORSE * abs(distance_change)
'''
# 2. 方向对齐奖励
car_direction = self._calculate_car_direction()
goal_vector = self._calculate_direction_vector(self._car_position, self._goal_position)
direction_alignment = self._calculate_alignment(car_direction, goal_vector)
if direction_alignment > 0:
reward += self.REWARD_DIRECTION_ALIGNED * direction_alignment
# 3. 移动奖励
if self._last_position is not None:
move_alignment = self._calculate_movement_alignment()
if move_alignment > 0:
reward += self.REWARD_MOVING_TOWARD_GOAL * move_alignment
# 4. 时间惩罚
time_penalty = self.REWARD_TIME_PENALTY * (self._current_step / self.config.max_steps)
reward += time_penalty
# 5. 接近目标奖励
normalized_distance = current_goal_distance / math.hypot(self.config.screen_width, self.config.screen_height)
if normalized_distance < 0.2:
proximity_reward = self.REWARD_DISTANCE_IMPROVED * (1.0 - normalized_distance) * 2
reward += proximity_reward
'''
# 保存当前位置供下一帧使用
self._last_position = self._car_position.copy()
return reward, terminated, info
def _calculate_alignment(self, vec1: List[float], vec2: List[float]) -> float:
"""计算两个向量的对齐程度"""
norm1 = math.hypot(vec1[0], vec1[1])
norm2 = math.hypot(vec2[0], vec2[1])
if norm1 > 0 and norm2 > 0:
return (vec1[0] / norm1) * (vec2[0] / norm2) + (vec1[1] / norm1) * (vec2[1] / norm2)
return 0.0
def _calculate_movement_alignment(self) -> float:
"""计算移动方向与目标方向的对齐程度"""
if self._last_position is None:
return 0.0
# 计算移动向量
move_vector = [
self._car_position[0] - self._last_position[0],
self._car_position[1] - self._last_position[1]
]
# 计算目标方向向量
goal_vector = self._calculate_direction_vector(self._car_position, self._goal_position)
return self._calculate_alignment(move_vector, goal_vector)
def _check_collision_with_details(self) -> Tuple[bool, int]:
"""
检查小车是否与任何障碍物发生碰撞,并返回详细信息
返回:
Tuple[bool, int]: (是否碰撞, 碰撞的障碍物索引)
"""
car_collision_radius = max(self.config.car_width, self.config.car_height) / 2
for i, obstacle in enumerate(self._obstacle_positions):
distance = math.hypot(
obstacle[0] - self._car_position[0],
obstacle[1] - self._car_position[1]
)
collision_threshold = self.config.obstacle_radius + car_collision_radius
if distance < collision_threshold:
return True, i
return False, -1
def render(self, mode: str = 'human'):
"""
渲染当前环境状态
参数:
mode: 渲染模式 ('human' 或 'rgb_array')
"""
if not self.render_mode or self.screen is None:
return None
# 清除屏幕
self.screen.fill(self.COLOR_WHITE)
# 绘制障碍物
self._draw_obstacles()
# 绘制目标
self._draw_goal()
# 绘制小车
self._draw_car()
# 绘制方向指示器
self._draw_direction_indicator()
# 绘制小车到目标的连线
pygame.draw.line(self.screen, self.COLOR_ORANGE,
(int(self._car_position[0]), int(self._car_position[1])),
(int(self._goal_position[0]), int(self._goal_position[1])), 1)
# 绘制信息面板
self._draw_info_panel()
# 绘制碰撞提示消息
if self._collision_message and self._collision_timer > 0:
self._draw_collision_message()
# 绘制边界
pygame.draw.rect(self.screen, self.COLOR_BLACK,
(0, 0, self.config.screen_width, self.config.screen_height), 3)
# 更新显示
pygame.display.flip()
# 控制帧率
self.clock.tick(self.config.frames_per_second)
# 处理Pygame事件
self._handle_pygame_events()
# 如果模式是rgb_array,返回图像数据
if mode == 'rgb_array':
return pygame.surfarray.array3d(self.screen)
return None
def _draw_obstacles(self):
"""绘制障碍物"""
for i, obstacle in enumerate(self._obstacle_positions):
if self.obstacle_image:
obstacle_rect = self.obstacle_image.get_rect(center=(int(obstacle[0]), int(obstacle[1])))
self.screen.blit(self.obstacle_image, obstacle_rect)
else:
pygame.draw.circle(self.screen, self.COLOR_BLUE,
(int(obstacle[0]), int(obstacle[1])),
self.config.obstacle_radius)
# 绘制障碍物编号
if self.font:
text = self.font.render(f"障碍物{i+1}", True, self.COLOR_WHITE)
text_rect = text.get_rect(center=(int(obstacle[0]), int(obstacle[1])))
self.screen.blit(text, text_rect)
def _draw_goal(self):
"""绘制目标"""
if self.goal_image:
goal_rect = self.goal_image.get_rect(center=(int(self._goal_position[0]), int(self._goal_position[1])))
self.screen.blit(self.goal_image, goal_rect)
else:
pygame.draw.circle(self.screen, self.COLOR_GREEN,
(int(self._goal_position[0]), int(self._goal_position[1])),
self.config.goal_radius)
if self.font:
goal_text = self.font.render("目标", True, self.COLOR_WHITE)
goal_text_rect = goal_text.get_rect(center=(int(self._goal_position[0]), int(self._goal_position[1])))
self.screen.blit(goal_text, goal_text_rect)
def _draw_car(self):
"""绘制小车"""
if self.car_image:
rotated_car = pygame.transform.rotate(self.car_image, -self._car_angle)
car_rect = rotated_car.get_rect(center=(int(self._car_position[0]), int(self._car_position[1])))
self.screen.blit(rotated_car, car_rect)
else:
# 根据碰撞状态选择颜色
car_color = self._get_car_color()
# 绘制小车多边形
car_points = self._get_car_polygon_points()
pygame.draw.polygon(self.screen, car_color, car_points)
pygame.draw.polygon(self.screen, self.COLOR_BLACK, car_points, 2)
if self.font:
car_text = self.font.render("小车", True, self.COLOR_WHITE)
car_text_rect = car_text.get_rect(center=(int(self._car_position[0]), int(self._car_position[1])))
self.screen.blit(car_text, car_text_rect)
def _get_car_color(self):
"""根据碰撞状态获取小车颜色"""
if self._collision_state == self.COLLISION_OBSTACLE:
return self.COLOR_PURPLE
elif self._collision_state == self.COLLISION_GOAL:
return self.COLOR_CYAN
elif self._collision_state == self.COLLISION_BOUNDARY:
return self.COLOR_ORANGE
else:
return self.COLOR_RED
def _draw_direction_indicator(self):
"""绘制方向指示器"""
direction_length = 50
angle_rad = math.radians(self._car_angle)
direction_x = self._car_position[0] + direction_length * math.sin(angle_rad)
direction_y = self._car_position[1] - direction_length * math.cos(angle_rad)
pygame.draw.line(self.screen, self.COLOR_YELLOW,
(int(self._car_position[0]), int(self._car_position[1])),
(int(direction_x), int(direction_y)), 3)
def _draw_info_panel(self):
"""绘制信息面板"""
if not self.font:
return
# 步数信息
steps_text = f"步数: {self._current_step}/{self.config.max_steps}"
self.screen.blit(self.font.render(steps_text, True, self.COLOR_BLACK), (10, 10))
# 距离信息
distance = self._calculate_goal_distance()
distance_text = f"距离目标: {distance:.1f} 像素"
self.screen.blit(self.font.render(distance_text, True, self.COLOR_BLACK), (10, 40))
# 方向信息
direction_text = f"方向: {self._car_angle:.1f}°"
self.screen.blit(self.font.render(direction_text, True, self.COLOR_BLACK), (10, 70))
# 边界碰撞次数
boundary_text = f"边界碰撞: {self._boundary_collision_count} 次"
self.screen.blit(self.font.render(boundary_text, True, self.COLOR_BLACK), (10, 100))
# 碰撞提示剩余时间
if self._collision_timer > 0:
timer_text = f"碰撞提示剩余: {self._collision_timer} 帧"
self.screen.blit(self.font.render(timer_text, True, self.COLOR_RED), (10, 130))
# 位置信息
car_pos_text = f"小车位置: ({self._car_position[0]:.0f}, {self._car_position[1]:.0f})"
self.screen.blit(self.font.render(car_pos_text, True, self.COLOR_BLACK), (10, 160))
def _draw_collision_message(self):
"""绘制碰撞提示消息"""
# 根据碰撞类型选择颜色
message_color = self._get_message_color()
# 渲染消息
message_surface = self.message_font.render(self._collision_message, True, message_color)
message_rect = message_surface.get_rect(center=(self.config.screen_width // 2, 50))
# 绘制背景框
background_rect = message_rect.inflate(20, 10)
pygame.draw.rect(self.screen, (255, 255, 255, 200), background_rect, border_radius=10)
pygame.draw.rect(self.screen, message_color, background_rect, 2, border_radius=10)
self.screen.blit(message_surface, message_rect)
def _get_message_color(self):
"""根据碰撞类型获取消息颜色"""
if self._collision_state == self.COLLISION_OBSTACLE:
return self.COLOR_RED
elif self._collision_state == self.COLLISION_GOAL:
return self.COLOR_GREEN
elif self._collision_state == self.COLLISION_BOUNDARY:
return self.COLOR_ORANGE
else:
return self.COLOR_BLACK
def _get_car_polygon_points(self):
"""获取小车多边形的顶点"""
half_width = self.config.car_width // 2
half_height = self.config.car_height // 2
# 小车四个角点(相对于中心)
base_points = [
(-half_width, -half_height),
(half_width, -half_height),
(half_width, half_height),
(-half_width, half_height)
]
# 旋转和平移到实际位置
angle_rad = math.radians(self._car_angle)
cos_a = math.cos(angle_rad)
sin_a = math.sin(angle_rad)
points = []
for x, y in base_points:
rot_x = x * cos_a - y * sin_a
rot_y = x * sin_a + y * cos_a
px = self._car_position[0] + rot_x
py = self._car_position[1] + rot_y
points.append((int(px), int(py)))
return points
def _handle_pygame_events(self):
"""处理Pygame事件"""
for event in pygame.event.get():
if event.type == pygame.QUIT:
self.close()
def close(self):
"""关闭环境,释放资源"""
if self.render_mode and pygame.get_init():
pygame.quit()
self.render_mode = False
print("环境已关闭")
@property
def action_dim(self):
"""获取动作空间维度"""
return self.action_dimension
@property
def state_dim(self):
"""获取状态空间维度"""
return self.state_dimension
def get_fixed_positions(self) -> dict:
"""获取所有固定位置信息"""
return {
"car": (self.config.car_start_x, self.config.car_start_y),
"goal": (self.config.goal_x, self.config.goal_y),
"obstacles": self._obstacle_positions
}
def environment_example():
"""演示固定位置版环境的使用"""
print("=" * 60)
print("智能小车避障环境演示 - 固定位置版(带碰撞提示延时)")
print("=" * 60)
# 创建环境配置,设置碰撞提示延时为30帧
config = EnvironmentConfig(
screen_width=800,
screen_height=800,
num_obstacles=4,
max_steps=200,
car_speed=6.0,
turn_angle=10.0,
frames_per_second=15,
reward_boundary=-5.0,
collision_prompt_delay_frames=30 # 设置碰撞提示延时为30帧
)
# 创建环境实例(启用渲染)
env = CarEnvironment(render=True, config=config)
# 重置环境并获取固定位置信息
env.reset()
positions = env.get_fixed_positions()
print(f"固定位置: {positions}")
print(f"碰撞提示延时: {config.collision_prompt_delay_frames}帧")
done = False
step_num = 0
while not done :
# 执行随机动作以演示碰撞
action = random.choice(env.actions)
next_state, reward, done, info = env.step(action)
# 渲染
env.render()
step_num +=1
# 检查是否达到最大步数
if info.get("termination_reason") == "max_steps_reached":
#print(f"达到最大步数限制: {config.max_steps}")
done = True
# 显示最终统计
boundary_count = info.get("boundary_collision_count", 0)
print(f"最终边界碰撞次数: {boundary_count}")
#print(f"碰撞提示总显示次数: {config.collision_prompt_delay_frames * (1 if boundary_count > 0 else 0)}帧")
# 关闭环境
env.close()
if __name__ == "__main__":
# 运行环境演示
environment_example()3 agent.py
# agent.py
# -*- coding: utf-8 -*-
"""
DQN Agent 实现 - 修复目标网络问题
创建于:2025年12月30日
作者:chengxf2
修改:2025年12月30日(强化学习专家优化)
修复要点:
1. 修复目标网络更新逻辑
2. 统一探索率衰减策略
3. 调整超参数
4. 增加训练日志
"""
import numpy as np
import random
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
from typing import Tuple, Optional, Dict, Any
import time
import os
from dqn_model import create_dqn_model
from Environment import CarEnvironment, EnvironmentConfig
class ReplayBuffer:
"""经验回放缓冲区"""
def __init__(self, max_size: int):
self.max_size = max_size
self.buffer = deque(maxlen=max_size)
def add(self, state: np.ndarray, action: int, reward: float,
next_state: np.ndarray, done: bool) -> None:
experience = (state, action, reward, next_state, done)
self.buffer.append(experience)
def sample(self, batch_size: int) -> Tuple:
if len(self.buffer) < batch_size:
batch_size = len(self.buffer)
if batch_size == 0:
raise ValueError("经验回放缓冲区为空")
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
samples = [self.buffer[idx] for idx in indices]
states, actions, rewards, next_states, dones = zip(*samples)
return (
np.array(states, dtype=np.float32),
np.array(actions, dtype=np.int64),
np.array(rewards, dtype=np.float32),
np.array(next_states, dtype=np.float32),
np.array(dones, dtype=np.float32)
)
def __len__(self) -> int:
return len(self.buffer)
class DQNAgent:
"""
DQN Agent - 修复目标网络问题
"""
def __init__(self, state_dim: int = 21, action_dim: int = 7,
learning_rate: float = 0.0005, gamma: float = 0.99,
epsilon_start: float = 1.0, epsilon_end: float = 0.01,
epsilon_decay: float = 0.999, buffer_size: int = 10000,
batch_size: int = 64, target_update_freq: int = 100,
hidden_dim: int = 128, use_double_dqn: bool = True):
"""
初始化 DQN Agent
"""
self.state_dim = state_dim
self.action_dim = action_dim
self.learning_rate = learning_rate
self.gamma = gamma
self.epsilon = epsilon_start
self.epsilon_start = epsilon_start
self.epsilon_end = epsilon_end
self.epsilon_decay = epsilon_decay
self.batch_size = batch_size
self.target_update_freq = target_update_freq
self.use_double_dqn = use_double_dqn
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {self.device}")
# 主网络
self.main_network = create_dqn_model(
input_dim=state_dim,
fc1_dim=hidden_dim,
fc2_dim=hidden_dim // 2,
n_actions=action_dim
)
# 目标网络
self.target_network = create_dqn_model(
input_dim=state_dim,
fc1_dim=hidden_dim,
fc2_dim=hidden_dim // 2,
n_actions=action_dim
)
# 初始化目标网络权重
self.target_network.load_state_dict(self.main_network.state_dict())
self.target_network.eval() # 目标网络设为评估模式
# 优化器
self.optimizer = optim.Adam(self.main_network.parameters(), lr=learning_rate)
# 损失函数
self.loss_function = nn.SmoothL1Loss()
# 经验回放缓冲区
self.replay_buffer = ReplayBuffer(buffer_size)
# 训练统计
self.training_steps = 0
self.episode_rewards = []
self.episode_lengths = []
self.loss_history = []
self.success_history = []
self._print_initialization_info()
def _print_initialization_info(self) -> None:
"""打印初始化信息"""
print("=" * 60)
print("DQN Agent 初始化完成")
print("=" * 60)
print(f"状态维度: {self.state_dim}")
print(f"动作维度: {self.action_dim}")
print(f"学习率: {self.learning_rate}")
print(f"折扣因子: {self.gamma}")
print(f"探索率: {self.epsilon_start} -> {self.epsilon_end}")
print(f"探索衰减: {self.epsilon_decay}")
print(f"缓冲区大小: {self.replay_buffer.max_size}")
print(f"批次大小: {self.batch_size}")
print(f"目标网络更新频率: {self.target_update_freq} 步")
print(f"使用Double DQN: {self.use_double_dqn}")
print("=" * 60)
def _update_target_network(self) -> None:
"""硬更新目标网络权重"""
self.target_network.load_state_dict(self.main_network.state_dict())
#print(f"步骤 {self.training_steps}: 目标网络已更新")
def select_action(self, state: np.ndarray, training: bool = True) -> int:
"""
ε-贪婪策略选择动作
"""
if training and random.random() < self.epsilon:
action = random.randint(0, self.action_dim - 1)
return action
else:
with torch.no_grad():
state_tensor = torch.FloatTensor(state).unsqueeze(0).to(self.device)
q_values = self.main_network(state_tensor)
action = torch.argmax(q_values).item()
return action
def decay_epsilon(self) -> None:
"""衰减探索率"""
self.epsilon = max(self.epsilon_end, self.epsilon * self.epsilon_decay)
def store_experience(self, state: np.ndarray, action: int,
reward: float, next_state: np.ndarray,
done: bool) -> None:
"""存储经验"""
self.replay_buffer.add(state, action, reward, next_state, done)
def train_step(self) -> Optional[float]:
"""
执行一次训练步骤
"""
if len(self.replay_buffer) < 2*self.batch_size:
return None
try:
# 从缓冲区采样
states, actions, rewards, next_states, dones = self.replay_buffer.sample(self.batch_size)
# 转换为张量
states_tensor = torch.FloatTensor(states).to(self.device)
actions_tensor = torch.LongTensor(actions).unsqueeze(1).to(self.device)
rewards_tensor = torch.FloatTensor(rewards).unsqueeze(1).to(self.device)
next_states_tensor = torch.FloatTensor(next_states).to(self.device)
dones_tensor = torch.FloatTensor(dones).unsqueeze(1).to(self.device)
# 计算当前 Q 值
current_q_values = self.main_network(states_tensor)
current_q = current_q_values.gather(1, actions_tensor)
# 计算目标 Q 值
with torch.no_grad():
if self.use_double_dqn:
# Double DQN
next_actions = self.main_network(next_states_tensor).argmax(1, keepdim=True)
next_q_values = self.target_network(next_states_tensor)
next_q = next_q_values.gather(1, next_actions)
else:
# 原始DQN
next_q_values = self.target_network(next_states_tensor)
next_q = next_q_values.max(1, keepdim=True)[0]
target_q = rewards_tensor + self.gamma * next_q * (1 - dones_tensor)
# 计算损失
loss = self.loss_function(current_q, target_q)
# 优化步骤
self.optimizer.zero_grad()
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(self.main_network.parameters(), max_norm=1.0)
self.optimizer.step()
# 更新训练步数
self.training_steps += 1
# 定期更新目标网络
if self.training_steps % self.target_update_freq == 0:
self._update_target_network()
# 记录损失
loss_value = loss.item()
self.loss_history.append(loss_value)
return loss_value
except Exception as e:
print(f"训练失败: {e}")
return None
def train_episode(self, env: CarEnvironment, max_steps: int = 200,
render: bool = False, episode_idx: int = None) -> Dict[str, Any]:
"""
训练一个完整的 episode
"""
state = env.reset()
total_reward = 0.0
steps = 0
episode_losses = []
for step in range(max_steps):
action = self.select_action(state, training=True)
next_state, reward, done, info = env.step(action)
self.store_experience(state, action, reward, next_state, done)
loss = self.train_step()
if loss is not None:
episode_losses.append(loss)
state = next_state
total_reward += reward
steps += 1
if render:
env.render()
time.sleep(0.01)
if done:
success = info.get("termination_reason") == "goal_reached"
if success:
print(f"Episode {episode_idx}: 成功到达目标!")
break
# 衰减探索率
self.decay_epsilon()
# 记录统计
self.episode_rewards.append(total_reward)
self.episode_lengths.append(steps)
success = False
if len(self.episode_rewards) > 0:
success = total_reward > 50 # 如果奖励较高则认为成功
self.success_history.append(success)
# 计算统计
avg_loss = np.mean(episode_losses) if episode_losses else 0.0
recent_success = np.mean(self.success_history[-20:]) if len(self.success_history) >= 20 else 0.0
episode_stats = {
"episode": len(self.episode_rewards),
"total_reward": total_reward,
"steps": steps,
"epsilon": self.epsilon,
"avg_loss": avg_loss,
"buffer_size": len(self.replay_buffer),
"training_steps": self.training_steps,
"success": success,
"recent_success": recent_success
}
print(f"Episode {episode_idx}: "
f"奖励={total_reward:6.2f}, "
f"步数={steps:3d}, "
f"ε={self.epsilon:.3f}, "
f"损失={avg_loss:.4f}, "
f"成功率={recent_success:.2%}")
return episode_stats
def evaluate(self, env: CarEnvironment, num_episodes: int = 5,
render: bool = False) -> Dict[str, Any]:
"""
评估智能体性能
"""
episode_rewards = []
success_count = 0
print(f"开始评估 {num_episodes} 个episode")
collision_times=0
for episode_idx in range(num_episodes):
state = env.reset()
total_reward = 0.0
steps = 0
done = False
while not done and steps < env.config.max_steps:
action = self.select_action(state, training=False)
next_state, reward, done, info = env.step(action)
state = next_state
total_reward += reward
steps += 1
if render:
env.render()
time.sleep(0.01)
if done:
break
if info.get("collision_state"):
collision_times +=1
if collision_times>10:
break
if done and info.get("termination_reason") == "goal_reached":
success_count += 1
print(f"Episode {episode_idx + 1}: 成功到达目标")
else:
print(f"Episode {episode_idx + 1}: 未到达目标")
episode_rewards.append(total_reward)
avg_reward = np.mean(episode_rewards)
success_rate = success_count / num_episodes
print(f"评估完成: "
f"平均奖励={avg_reward:.2f}, "
f"成功率={success_rate:.2%}")
return {
"avg_reward": avg_reward,
"success_rate": success_rate,
"episode_rewards": episode_rewards
}
def save_agent(self, filepath: str) -> None:
"""保存智能体状态"""
save_data = {
'main_network_state': self.main_network.state_dict(),
'target_network_state': self.target_network.state_dict(),
'optimizer_state': self.optimizer.state_dict(),
'epsilon': self.epsilon,
'training_steps': self.training_steps,
'episode_rewards': self.episode_rewards
}
torch.save(save_data, filepath)
print(f"模型已保存: {filepath}")
def load_agent(self, filepath: str) -> None:
"""加载智能体状态"""
if not os.path.exists(filepath):
print(f"文件不存在: {filepath}")
return
save_data = torch.load(filepath, map_location=self.device)
self.main_network.load_state_dict(save_data['main_network_state'])
self.target_network.load_state_dict(save_data['target_network_state'])
self.optimizer.load_state_dict(save_data['optimizer_state'])
self.epsilon = save_data['epsilon']
self.training_steps = save_data['training_steps']
self.episode_rewards = save_data['episode_rewards']
print(f"模型已加载: {filepath}")
def train_dqn_agent_simple(total_episodes: int = 500,
evaluation_frequency: int = 50) -> DQNAgent:
"""
简化版训练函数
"""
print("=" * 60)
print("开始 DQN 训练")
print("=" * 60)
# 简单配置
config_params_train = {
"screen_width": 800,
"screen_height": 800,
"num_obstacles": 4,
"max_steps": 1000,
"car_speed": 4.0,
"goal_radius": 50
}
config_params_test = {
"screen_width": 800,
"screen_height": 800,
"num_obstacles": 4,
"max_steps": 100,
"car_speed": 4.0,
"goal_radius": 50
}
config_train = EnvironmentConfig(**config_params_train)
config_test = EnvironmentConfig(**config_params_test)
# 创建环境
train_env = CarEnvironment(render=False, config=config_train)
eval_env = CarEnvironment(render=True, config=config_test)
print(f"环境创建完成: {train_env.get_environment_info()}")
# 创建 DQN Agent
agent = DQNAgent(
state_dim=train_env.state_dim,
action_dim=train_env.action_dim,
learning_rate=0.005,
gamma=0.99,
epsilon_start=1.0,
epsilon_end=0.01,
epsilon_decay=0.999,
buffer_size=10000,
batch_size=64,
target_update_freq=200,
hidden_dim=128,
use_double_dqn=True
)
best_success_rate = 0.0
# 训练循环
for episode in range(1, total_episodes + 1):
# 训练一个 episode
agent.train_episode(
env=train_env,
max_steps=config_train.max_steps,
render=False,
episode_idx=episode
)
# 定期评估
if episode % evaluation_frequency == 0:
print(f"\n{'=' * 40}")
print(f"Episode {episode} - 评估")
print(f"{'=' * 40}")
eval_stats = agent.evaluate(
env=eval_env,
num_episodes=1,
render=True
)
# 保存最佳模型
current_success_rate = eval_stats['success_rate']
if current_success_rate > best_success_rate:
best_success_rate = current_success_rate
best_model_path = f"dqn_best_{best_success_rate:.2f}.pth"
agent.save_agent(best_model_path)
print(f"最佳模型已保存: {best_model_path}")
# 训练完成
print("\n训练完成!")
print("=" * 60)
# 最终评估
print("最终评估:")
agent.evaluate(
env=eval_env,
num_episodes=1,
render=True
)
# 保存最终模型
agent.save_agent("dqn_final.pth")
# 打印训练统计
if agent.episode_rewards:
recent_rewards = agent.episode_rewards[-50:] if len(agent.episode_rewards) >= 50 else agent.episode_rewards
avg_recent = np.mean(recent_rewards)
print(f"最近{len(recent_rewards)}个episode平均奖励: {avg_recent:.2f}")
return agent
if __name__ == "__main__":
# 简化训练
trained_agent = train_dqn_agent_simple(
total_episodes=200,
evaluation_frequency=20
)https://ocw.nthu.edu.tw/ocw/index.php?page=chapter&cid=242&chid=2665
https://medium.com/data-science/rainbow-the-colorful-evolution-of-deep-q-networks-37e662ab99b2

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)