ICML: PiD_ Generalized AI-Generated Images Detection with Pixelwise Decomposition_Residuals
提出了一种名为PiD的、基于像素级分解残差的AI生成图像通用检测方法。
·
| 书名 | PiD: Generalized AI-Generated Images Detection with Pixelwise Decomposition Residuals |
|---|---|
| 作者 | Xinghe Fu 1 Zhiyuan Yan 2 Zheng Yang 1 Taiping Yao 2 Yandan Zhao 2 Shouhong Ding 2 Xi Li 1 |
| 简介 | 提出了一种名为PiD的、基于像素级分解残差的AI生成图像通用检测方法。 |
一、现有方法的局限性(动机)
- 基于重建的方法(如DIRE):虽然泛化性能好,但依赖于笨重的自重建生成器,计算成本高,且可能因模型特定伪影而导致过拟合,难以泛化到未见过的生成器。
- 基于预训练视觉语言模型的方法(如UnivFD、FatFormer):利用CLIP等模型中的语义知识进行检测,但随着生成模型越来越逼真和语义一致,这类方法有过时的风险。
解决方案:PiD
该方法专注于图像内的像素级残差信号,其基本原理是:生成模型旨在优化高层语义内容(主成分),而通常会忽略低层信号(残差成分)。PiD通过将像素向量映射到其他色彩空间(如YUV)然后进行量化,再将量化后的向量映射回RGB空间,并将量化损失作为残差用于检测,从而解耦出独立于语义内容的、更底层和通用的伪造线索。
二、贡献
-
提出了一种计算高效、无需生成器且高效的方法:作者团队提出了一种基于像素级分解残差的新检测方法。该方法不依赖于任何生成模型进行图像重建,从而避免了相关计算开销和模型偏差,同时在广泛使用的基准测试上实现了卓越的泛化性能 。

-
提出了一种分解残差信号的新视角:该方法的核心创新在于分解残差信号的思路。具体而言,它首先在像素级别进行操作,将像素向量映射到另一个色彩空间(如YUV),然后对该向量进行量化以产生用于检测的残差信号 。

-
进行了广泛的实验验证:作者在多个现有且广泛使用的基准数据集上进行了大量实验。结果证明,他们提出的方法相比其他最先进的检测器,展现出了惊人的高泛化性能 。

三、方法
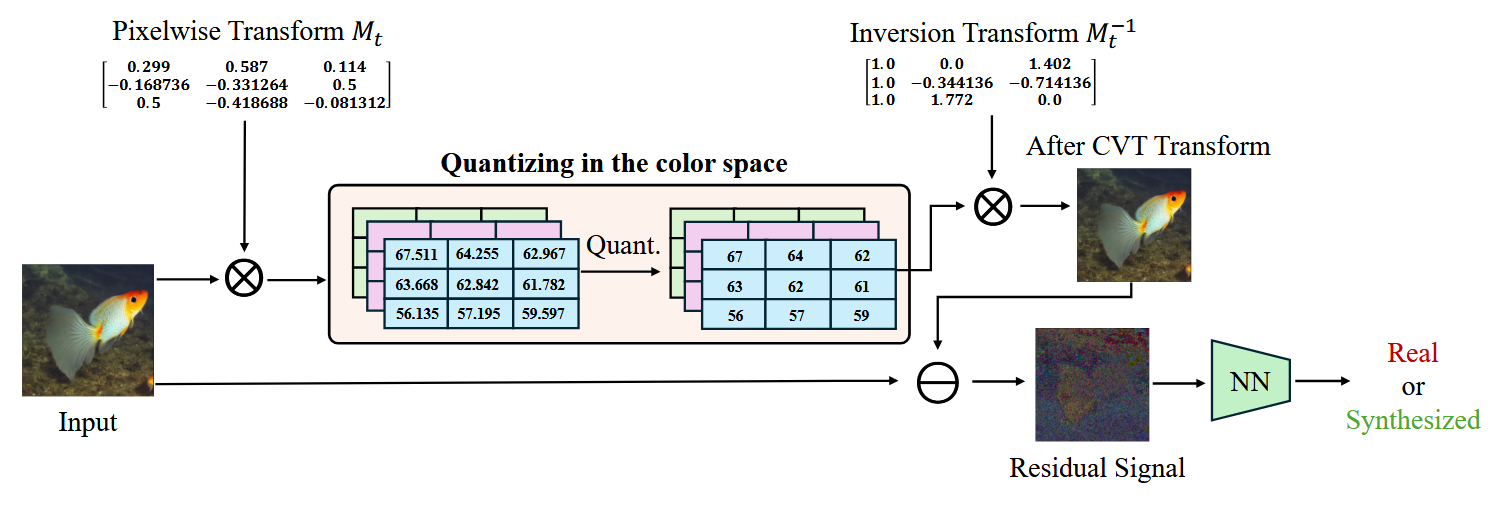
- 操作:对每个像素,把它从RGB颜色值转换到另一个空间(如YUV),然后对转换后的数值进行取整,再转换回RGB。
- 得到残差:用原始图片减去上面这个“取整并来回转换”后得到的图片,差值就是“像素级分解残差”。
给定一张图像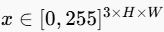
其像素级分解残差定义为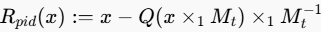
其中X1是张量-矩阵的模式-1乘积运算。【这个就代表颜色转换了】 - 检测:训练一个神经网络不看原图,而是专门看这个残差图,来学习分辨真假。

- 算法接收训练数据集D 、神经网络fθ (·)、变换矩阵Mt和量化函数Q(·),并初始化神经网络的参数θ。
- 迭代训练循环:算法进入一个标准的训练循环,遍历多个训练轮次和批次 。
- 核心残差计算:对于每个批次的图像,依次执行:
- 通过矩阵Mt进行像素级变换:
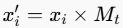 。
。 - 对变换后的值进行量化:
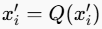 。
。 - 通过逆矩阵 将量化后的值映射回RGB空间:
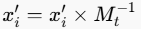 。
。 - 计算残差表示:
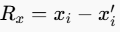 。
。
- 通过矩阵Mt进行像素级变换:
- 网络预测与优化:将计算得到的残差Rx输入神经网络fθ 得到预测概率pi,然后计算交叉熵损失Lce,并利用该损失的梯度更新网络参数θ。
四、思路推导
- 生成模型会忽略图像底层的“噪声”信号,而检测的关键是找到一种方法分离出这种信号
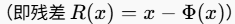
- 从图像压缩(如JPEG)中获得灵感,因为压缩算法就是为了去除人眼不敏感的冗余细节(可视为一种噪声)并保留主要内容。于是,尝试用压缩算法的编解码器作为
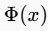 ,计算压缩残差 。
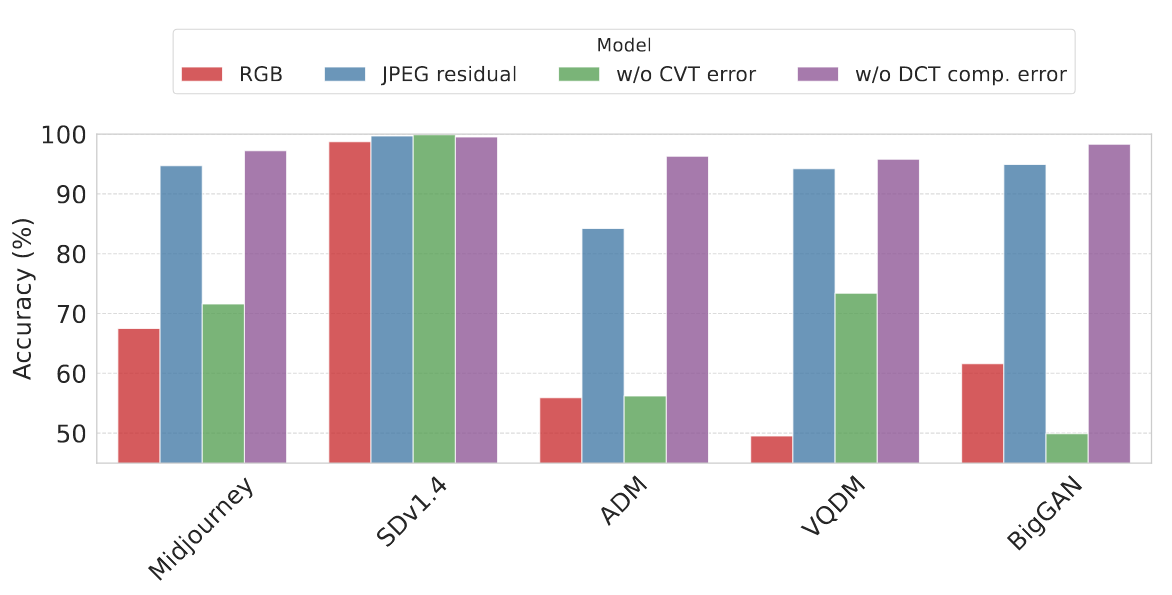
,计算压缩残差 。 - 经过实验发现残差中最重要的部分并非来自复杂的频域压缩(DCT量化),而是来自最初简单的颜色空间转换和量化带来的误差。下图是作者做的实验对比,去除DCT对模型影响最小,CVT是除了RGB最大的。
- 如果直接对RGB的值进行量化的话,太粗糙,会严重破坏图像内容。先变换到另一个色彩空间,可以更符合人眼感知特性,让量化操作集中在相对不敏感的维度上,从而在几乎不改变视觉内容的前提下,提取出细微的量化误差。

此图证明残差模型的注意力则更分散或集中在一些非语义的纹理和边缘区域,这些区域恰好包含了由生成过程引入的细微伪影。这证明了残差模型确实是在分析“噪声”而非“内容”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)