Large Language Model(LLM)应用开发学习实践(二)
本文总结了部分常用的LLM记忆策略,同时基于通义千问大语言模型和LangChain进行了代码学习实践。
一、LLM记忆存储策略
大语言模型本身是无状态的(stateless),即每次推理都是独立的,不保留历史信息。为了在对话或多轮交互中实现“记忆”能力,开发者通常借助外部记忆存储策略(memory strategies)。以下是常见的五种记忆存储策略:
(一)上下文窗口记忆(In-Context Memory)
实现原理:
- 将历史对话或相关信息直接拼接到当前 prompt 中,作为上下文输入给模型。
(二)摘要总结记忆(Summary Memory)
实现原理:用 LLM 自身或另一个模型对历史对话进行压缩摘要,只保留关键信息。
- 每 N 轮对话后生成一段总结;
- 将总结 + 最近几轮原始对话一起输入。
(三)结构化记忆(Structured Memory)
实现原理:将记忆以结构化形式(如 JSON、数据库表、图谱)存储,例如:
- 用户偏好({"language": "zh", "timezone": "UTC+8"})
- 对话状态(state tracking)
- 实体关系(知识图谱)
(四)向量数据库记忆(Vector-Based / Semantic Memory)
实现原理:
- 将历史对话或知识片段嵌入为向量(使用 embedding 模型);
- 存入向量数据库(如 FAISS、Pinecone、Chroma);
- 每次查询时,用当前问题检索最相关的记忆片段(RAG 思路)。
(五)混合记忆策略(Hybrid Memory)
结合多种记忆策略方式,例如:
- 短期记忆:用上下文窗口保留最近 3 轮;
- 中期记忆:用摘要记录过去 10 轮的核心内容;
- 长期记忆:用向量库存储所有历史,并支持语义检索;
- 结构化记忆:单独存储用户配置或关键实体。
二、开发实践
实现功能:
1. 实现大语言模型的多轮次记忆对话;
2. 学习常用的多种记忆存储策略并尝试LangChain提供的memory模块的API调用。
开发工具及大模型平台:
阿里云大模型服务平台百炼、LangChain、Transformer、anaconda、PyCharm
注意事项:
1. LangChain_v1.0 API文档部分内容不完整或暂时缺失(关键学习文档[3]),若需要查阅旧版本API可以先浏览 LangChain_v0.3 API文档(关键学习文档[4]);
2. InMemoryChatMessageHistory类是memory系列类的基础父类,它直接在内存里完整存储对话消息;
3. 采用ConversationSummaryBufferMemory类进行记忆存储时,会读取Hugging Face Transformers库中的tokenizer_config.json(GPT-2模型仓库中的分词器配置文件);
4. API Key存储于.env文件,采用设置环境变量的方式使用。
详细参考文档:
(一)关键代码与实践结果
1. 在内存中存储完整对话消息并全部输入模型问答
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import HumanMessage,AIMessage
# 解析.env文件并将所有变量设置为环境变量
load_dotenv()
QWEN_API_KEY = os.getenv("QWEN_API_KEY")
# 预定义大语言模型
ChatLLM = ChatTongyi(
model="qwen-plus",
api_key=QWEN_API_KEY,
top_p=0.8
)
# 预定义提示词模板
system_prompt = '''你是一位资深且乐于助人的BIM工程师,熟悉BIM领域相关软件(如Revit、Sketch Up、3Dmax等)的使用,同时也对BIM领域相关技术概念有着深刻理解。
务必严格执行以下特殊要求:
1.你只能回答BIM领域相关的问题;
2.若用户问题与BIM领域无关的问题,请回答"非常抱歉,您的问题可能与BIM领域相关知识无关,无法为您提供一个较为准确的答复!";
3.若用户问题因信息不充分导致无法回答的问题,请回答"非常抱歉,根据当前信息无法为您提供一个较为准确的答复!"。
'''
prompt = ChatPromptTemplate.from_messages([
("system",system_prompt),
("human","{user_prompt}")
])
# 构建对话
UserMessage = ""
while UserMessage != "quit":
UserMessage = input("请输入您的问题:")
if UserMessage == "quit":
break
# chain构建
chain = prompt | ChatLLM
# 消息提交大模型
response = chain.invoke({"user_prompt":UserMessage})
print(response.content)
# 将轮次消息存放到提示词模板的消息列表中
prompt.messages.append(HumanMessage(UserMessage))
prompt.messages.append(AIMessage(response.content))
# 测试
# for message in prompt.messages:
# print("!!!!!!!{0}".format(message))
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
from langchain_core.chat_history import InMemoryChatMessageHistory
# 解析.env文件并将所有变量设置为环境变量
load_dotenv()
QWEN_API_KEY = os.getenv("QWEN_API_KEY")
# 预定义大语言模型
ChatLLM = ChatTongyi(
model="qwen-plus",
api_key=QWEN_API_KEY,
top_p=0.8
)
# 预定义提示词模板
system_prompt = '''你是一位资深且乐于助人的BIM工程师,熟悉BIM领域相关软件(如Revit、Sketch Up、3Dmax等)的使用,同时也对BIM领域相关技术概念有着深刻理解。
务必严格执行以下特殊要求:
1.你只能回答BIM领域相关的问题;
2.若用户问题与BIM领域无关的问题,请回答"非常抱歉,您的问题可能与BIM领域相关知识无关,无法为您提供一个较为准确的答复!";
3.若用户问题因信息不充分导致无法回答的问题,请回答"非常抱歉,根据当前信息无法为您提供一个较为准确的答复!"。
'''
# 预定义内存记忆
memory = InMemoryChatMessageHistory()
memory.add_user_message(system_prompt)
# 构建对话
UserMessage = ""
while UserMessage != "quit":
UserMessage = input("请输入您的问题:")
if UserMessage == "quit":
break
#print(memory.messages)
# 消息提交大模型
memory.add_user_message(UserMessage)
response = ChatLLM.invoke(memory.messages)
print(response.content)
# 存储对话消息
memory.add_ai_message(response.content)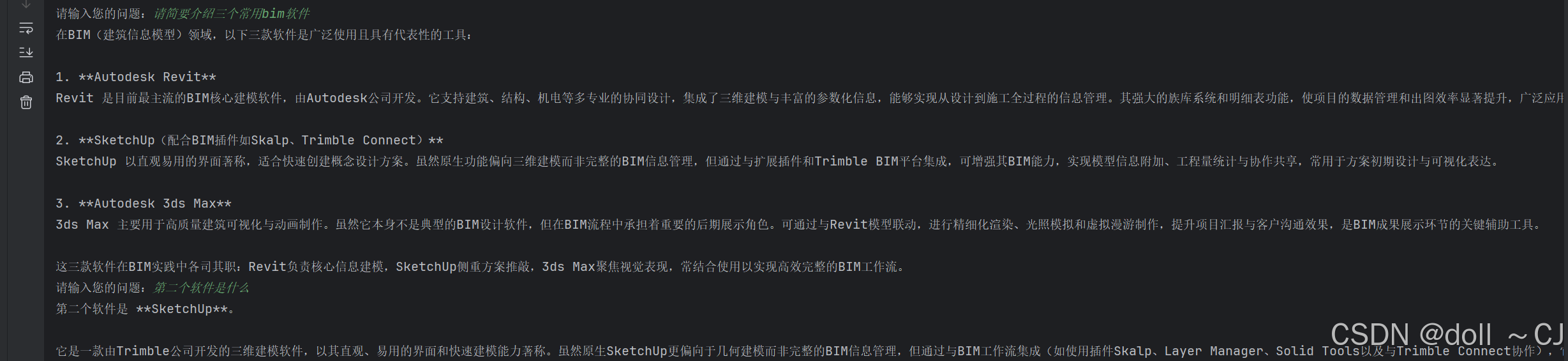
2. 实体与知识图谱总结提取关键记忆信息
import os
from dotenv import load_dotenv
from langchain_classic.chains.llm import LLMChain
from langchain_community.chat_models import ChatTongyi
from langchain_classic.memory import ConversationEntityMemory
from langchain_classic.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
# 解析.env文件并将所有变量设置为环境变量
load_dotenv()
QWEN_API_KEY = os.getenv("QWEN_API_KEY")
# 预定义大语言模型
ChatLLM = ChatTongyi(
model="qwen-plus",
api_key=QWEN_API_KEY,
top_p=0.8
)
# 使用LangChain为实体记忆设计的预定义模板
prompt = ENTITY_MEMORY_CONVERSATION_TEMPLATE
# 初始化实体记忆
memory_t = ConversationEntityMemory(llm=ChatLLM)
# 构建对话链
chain = LLMChain(
llm=ChatLLM,
prompt=prompt,
memory=memory_t
)
# 构建对话
UserMessage = ""
while UserMessage != "quit":
UserMessage = input("请输入您的问题:")
if UserMessage == "quit":
break
# 消息提交大模型
response = chain.invoke(UserMessage)
print(response)
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
from langchain_classic.memory import ConversationKGMemory
# 解析.env文件并将所有变量设置为环境变量
load_dotenv()
QWEN_API_KEY = os.getenv("QWEN_API_KEY")
# 预定义大语言模型
ChatLLM = ChatTongyi(
model="qwen-plus",
api_key=QWEN_API_KEY,
top_p=0.8
)
# 定义ConversationKGMemory对象
memory_KG = ConversationKGMemory(llm=ChatLLM)
# 构建对话
memory_KG.save_context({"input":"小明喜欢吃西瓜"},{"output":"小明和小黄是好朋友"})
memory_KG.save_context({"input":"小黄喜欢吃好朋友喜欢吃的水果"},{"output":"小智喜欢吃香蕉"})
print(memory_KG.load_memory_variables({"input":"小黄喜欢吃西瓜吗?"}))
print(memory_KG.get_knowledge_triplets("小白喜欢吃芒果"))
3. 在max_token_limit限制下总结早期对话并存储为history内容,保留其余的对话消息
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
from langchain_classic.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_classic.chains.llm import LLMChain
from langchain_classic.memory import ConversationSummaryMemory,ConversationSummaryBufferMemory,ChatMessageHistory
# 解析.env文件并将所有变量设置为环境变量
load_dotenv()
QWEN_API_KEY = os.getenv("QWEN_API_KEY")
# 预定义大语言模型
ChatLLM = ChatTongyi(
model="qwen-plus",
api_key=QWEN_API_KEY,
top_p=0.8,
)
# 定义提示词模板
prompt = ChatPromptTemplate.from_messages([
("system","你是一位BIM领域的资深工程师,请用中文友好回复用户问题,与BIM领域无关的问题请回复‘该问题暂时无法回答!’"),
MessagesPlaceholder(variable_name="chat_history"),
("human","{input}")
])
# 创建带摘要缓冲的记忆系统(无需手动控制消息存储)
memory = ConversationSummaryBufferMemory(
llm=ChatLLM,
max_token_limit=50,
memory_key="chat_history",
return_messages=True # 设置为True,从memory中读取历史聊天记录时,返回的是BaseMessage类型的对象列表(如HumanMessage等);设置为False,则把历史对话内容以字符串形式返回。兼容chain和agent使用的聊天模型输入
)
# 创建对话链
chain = LLMChain(
llm=ChatLLM,
prompt=prompt,
memory=memory
)
# 模拟用户多轮对话历史
User_dialogue = [
"请推荐BIM领域较好的三款软件",
"Revit是哪个公司生产的?",
"Revit主要功能是什么?",
]
for d in User_dialogue:
response = chain.invoke({"input":d})
# 查阅记忆内容
print(memory.load_memory_variables({}))
# # 假定消息历史(需要手动控制消息存储)
# history_s = ChatMessageHistory()
# history_s.add_user_message("您好,我是BIM大师。")
# history_s.add_ai_message("BIM大师,您好。有什么能够为你服务的吗?")
# history_s.add_user_message("请问常用的BIM软件有什么?")
# history_s.add_ai_message("Revit")
#
# # 定义ConversationKGMemory对象
# memory_s = ConversationSummaryMemory.from_messages(
# llm=ChatLLM,
# chat_memory=history_s
# )
#
# # 读取消息(总结后)
# print(memory_s.load_memory_variables({}))
(二)提取知识图谱(实体-关系)的提示词
_DEFAULT_ENTITY_SUMMARIZATION_TEMPLATE = """You are an AI assistant helping a human keep track of facts about relevant people, places, and concepts in their life. Update the summary of the provided entity in the "Entity" section based on the last line of your conversation with the human. If you are writing the summary for the first time, return a single sentence.
The update should only include facts that are relayed in the last line of conversation about the provided entity, and should only contain facts about the provided entity.
If there is no new information about the provided entity or the information is not worth noting (not an important or relevant fact to remember long-term), return the existing summary unchanged.
Full conversation history (for context):
{history}
Entity to summarize:
{entity}
Existing summary of {entity}:
{summary}
Last line of conversation:
Human: {input}
Updated summary:""" # noqa: E501_DEFAULT_KNOWLEDGE_TRIPLE_EXTRACTION_TEMPLATE = (
"You are a networked intelligence helping a human track knowledge triples"
" about all relevant people, things, concepts, etc. and integrating"
" them with your knowledge stored within your weights"
" as well as that stored in a knowledge graph."
" Extract all of the knowledge triples from the last line of conversation."
" A knowledge triple is a clause that contains a subject, a predicate,"
" and an object. The subject is the entity being described,"
" the predicate is the property of the subject that is being"
" described, and the object is the value of the property.\n\n"
"EXAMPLE\n"
"Conversation history:\n"
"Person #1: Did you hear aliens landed in Area 51?\n"
"AI: No, I didn't hear that. What do you know about Area 51?\n"
"Person #1: It's a secret military base in Nevada.\n"
"AI: What do you know about Nevada?\n"
"Last line of conversation:\n"
"Person #1: It's a state in the US. It's also the number 1 producer of gold in the US.\n\n" # noqa: E501
f"Output: (Nevada, is a, state){KG_TRIPLE_DELIMITER}(Nevada, is in, US)"
f"{KG_TRIPLE_DELIMITER}(Nevada, is the number 1 producer of, gold)\n"
"END OF EXAMPLE\n\n"
"EXAMPLE\n"
"Conversation history:\n"
"Person #1: Hello.\n"
"AI: Hi! How are you?\n"
"Person #1: I'm good. How are you?\n"
"AI: I'm good too.\n"
"Last line of conversation:\n"
"Person #1: I'm going to the store.\n\n"
"Output: NONE\n"
"END OF EXAMPLE\n\n"
"EXAMPLE\n"
"Conversation history:\n"
"Person #1: What do you know about Descartes?\n"
"AI: Descartes was a French philosopher, mathematician, and scientist who lived in the 17th century.\n" # noqa: E501
"Person #1: The Descartes I'm referring to is a standup comedian and interior designer from Montreal.\n" # noqa: E501
"AI: Oh yes, He is a comedian and an interior designer. He has been in the industry for 30 years. His favorite food is baked bean pie.\n" # noqa: E501
"Last line of conversation:\n"
"Person #1: Oh huh. I know Descartes likes to drive antique scooters and play the mandolin.\n" # noqa: E501
f"Output: (Descartes, likes to drive, antique scooters){KG_TRIPLE_DELIMITER}(Descartes, plays, mandolin)\n" # noqa: E501
"END OF EXAMPLE\n\n"
"Conversation history (for reference only):\n"
"{history}"
"\nLast line of conversation (for extraction):\n"
"Human: {input}\n\n"
"Output:"
)关键学习文档:
[1] Short-term memory - Docs by LangChain
[2] Long-term memory - Docs by LangChain
网络参考资料:
拓展资料:
Genkit — Google推出的一个用于构建生成式AI应用的开源框架
Genkit主要面向JavaScript/TypeScript开发者(Node.js环境),其是为Web/JS生态打造的构建生成式AI应用的开源框架。
官网地址:https://genkit.dev/
Sumers T, Yao S, Narasimhan K R, et al. Cognitive architectures for language agents[J]. Transactions on Machine Learning Research, 2023.
文献地址:https://arxiv.org/abs/2309.02427
视频解读:Building Brain-Like Memory for AI | LLM Agent Memory Systems
Liu B, Li X, Zhang J, et al. Advances and challenges in foundation agents: From brain-inspired intelligence to evolutionary, collaborative, and safe systems[J]. arXiv preprint arXiv:2504.01990, 2025.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)