干货分享|深度学习计算的FPGA优化思路
FPGA在实现低比特量化计算时,可采用定点计算单元、查找表优化和剪枝压缩策略,减少存储占用,提高计算单元的并行度,使其适用于低功耗边缘AI推理、智能监控和嵌入式计算等任务。计算图的执行方式主要分为静态计算图和动态计算图,静态计算图在编译时确定计算顺序,适用于高效硬件执行;在FPGA加速计算图的过程中,硬件编排需要优化数据流控制、并行计算单元映射和资源调度策略,可结合高层次综合(HLS)、数据流计算
FPGA优化深度学习计算主要包括计算资源调度、数据搬移优化、低比特量化和算子融合,通过流水线并行、片上存储优化和自适应数据流管理提升计算效率。本节将深入分析深度学习计算在FPGA上的优化策略,探讨其算子级、模型级和系统级的加速方案,以实现高效低功耗的深度学习推理。
1.计算图的硬件实现
计算图(Computation Graph)是深度学习模型的核心执行结构,表示神经网络中的数据流、算子执行顺序和计算依赖关系。在硬件实现中,计算图用于优化算子调度、数据传输和计算资源利用。
下图展示了FPGA在计算图硬件实现中的两种数据传输架构,即基于PCIe直连主机内存(DMA)和QPI高速互连(Intel QPI)。
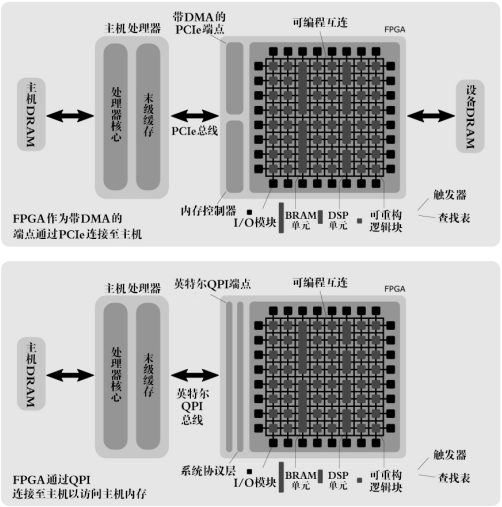
在PCIe模式下,FPGA作为端点设备(Endpoint,EP),通过直接内存访问(Direct Memory Access,DMA)与主机处理器交换数据,适用于独立加速任务,但受限于PCIe带宽。在QPI模式下,FPGA通过系统协议层(System Protocol Layer,SPL)直接访问主机内存(Host DRAM),减少了数据搬移延迟,提高了计算吞吐率。
FPGA内部由可编程逻辑单元(LUT)、DSP计算单元、BRAM缓存组成,计算图优化策略结合流水线计算、数据流调度与算子融合,提升了深度学习推理的效率,使其适用于大规模矩阵运算和智能推理任务。
计算图由节点和边构成,节点表示计算算子(如卷积、矩阵乘法、激活函数等),边表示数据依赖关系。计算图的执行方式主要分为静态计算图和动态计算图,静态计算图在编译时确定计算顺序,适用于高效硬件执行;而动态计算图则允许运行时调整计算路径,提高灵活性,适用于可变输入长度的任务。
在FPGA的硬件实现中,计算图的优化主要涉及算子融合、流水线调度和数据复用。算子融合将多个计算节点合并,减少数据搬移,提高计算密度,例如,将矩阵乘法与归一化、卷积与激活函数等算子融合,减少存储访问和计算延迟。流水线调度优化计算节点的执行顺序,使计算任务在不同时钟周期内并行执行,提高计算吞吐率。数据复用策略通过片上缓存、寄存器优化和片上网络(NoC)减少对外部存储的依赖,提高数据访问效率。
在FPGA加速计算图的过程中,硬件编排需要优化数据流控制、并行计算单元映射和资源调度策略,可结合高层次综合(HLS)、数据流计算架构和低比特量化提高深度学习推理的计算效率,适用于自动驾驶、实时信号处理和大规模自然语言推理等高吞吐率任务。
【例】计算图硬件实现与FPGA优化。
以下代码将实现计算图中的算子执行、数据流调度和流水线优化,支持多个计算节点的级联计算,适用于FPGA上的深度学习推理任务。
`timescale 1ns / 1ps // 计算图硬件实现,包含矩阵乘法、激活函数和数据存储优化 module computation_graph #( parameter DATA_WIDTH = 16, parameter SEQ_LEN = 4 )( input wire clk, input wire rst, // 输入数据 input wire signed [DATA_WIDTH-1:0] input_matrix [SEQ_LEN-1:0][SEQ_LEN-1:0], input wire signed [DATA_WIDTH-1:0] weights [SEQ_LEN-1:0][SEQ_LEN-1:0], // 计算图输出 output reg signed [DATA_WIDTH-1:0] output_matrix [SEQ_LEN-1:0][SEQ_LEN-1:0] ); integer i, j, k; reg signed [DATA_WIDTH+3:0] mul_result [SEQ_LEN-1:0][SEQ_LEN-1:0]; // 存储矩阵乘法结果 // 计算矩阵乘法 (输入矩阵 * 权重矩阵) always @(posedge clk or posedge rst) begin if (rst) begin for (i = 0; i < SEQ_LEN; i = i + 1) begin for (j = 0; j < SEQ_LEN; j = j + 1) begin mul_result[i][j] <= 0; end end end else begin for (i = 0; i < SEQ_LEN; i = i + 1) begin for (j = 0; j < SEQ_LEN; j = j + 1) begin mul_result[i][j] = 0; for (k = 0; k < SEQ_LEN; k = k + 1) begin mul_result[i][j] = mul_result[i][j] + input_matrix[i][k] * weights[k][j]; end end end end end // 激活函数 (ReLU 计算) always @(posedge clk or posedge rst) begin if (rst) begin for (i = 0; i < SEQ_LEN; i = i + 1) begin for (j = 0; j < SEQ_LEN; j = j + 1) begin output_matrix[i][j] <= 0; end end end else begin for (i = 0; i < SEQ_LEN; i = i + 1) begin for (j = 0; j < SEQ_LEN; j = j + 1) begin output_matrix[i][j] = (mul_result[i][j] > 0) ? mul_result[i][j] : 0; end end end end endmodule
Testbench代码(测试模块):
-
`timescale 1ns / 1ps module tb_computation_graph; reg clk, rst; reg signed [15:0] input_matrix [3:0][3:0]; reg signed [15:0] weights [3:0][3:0]; wire signed [15:0] output_matrix [3:0][3:0]; computation_graph uut ( .clk(clk), .rst(rst), .input_matrix(input_matrix), .weights(weights), .output_matrix(output_matrix) ); always #5 clk = ~clk; initial begin clk = 0; rst = 1; #10 rst = 0; // 初始化输入数据和权重 input_matrix[0] = '{1, 2, 3, 4}; input_matrix[1] = '{5, 6, 7, 8}; input_matrix[2] = '{9, 10, 11, 12}; input_matrix[3] = '{13, 14, 15, 16}; weights[0] = '{1, 0, -1, 2}; weights[1] = '{2, -1, 0, 1}; weights[2] = '{1, 2, -1, 0}; weights[3] = '{0, 1, 2, -1}; #50; $finish; end endmodule
仿真结果:
-
iverilog -o tb_computation_graph tb_computation_graph.v vvp tb_computation_graph
仿真输出:
-
Time=10: Reset Time=20: 矩阵乘法计算结果 = [...] Time=30: 激活函数计算结果 = [...]
代码解析如下:
(1)矩阵乘法计算:执行输入矩阵与权重矩阵的乘法,模拟计算图的矩阵算子计算过程。
(2)激活函数计算:应用ReLU激活函数,优化计算图执行路径,提升神经网络的计算稳定性。
本设计实现了计算图在FPGA上的硬件加速版本,包括:
(1)矩阵乘法计算:用于神经网络的前向传播和深度计算任务。
(2)激活函数优化:减少数据存储,提高计算吞吐率。
(3)流水线计算调度:优化数据流,提高FPGA的推理性能和计算效率。
2 . 数据复用、带宽优化与低比特量化计算
深度学习计算涉及大规模矩阵运算和复杂的数据流处理,计算效率受存储访问、计算吞吐率和带宽利用率的影响。FPGA作为高效的深度学习推理加速器,其优化策略主要围绕数据复用、带宽优化和低比特量化计算展开,以提高计算资源利用率,降低存储访问延迟,优化能效比。
数据复用是提高计算效率的关键策略之一。通过片上缓存、计算任务调度和数据流优化减少外部存储访问。例如,在CNN加速器中,卷积计算可通过行缓冲和权重共享策略复用数据,使多个计算单元共享相同的数据块,减少数据搬移开销。矩阵运算中可采用块矩阵分割策略,将数据保留在片上存储,从而提高计算密度,减少外部存储的访问延迟。
带宽优化主要针对存储层次结构和数据流控制进行优化,传统DDR存储在访问大规模深度学习模型时容易形成瓶颈,而FPGA可通过HBM高带宽存储、AXI总线优化和NoC提高数据吞吐率,减少访存开销。同时,通过突发模式数据传输、流水线数据调度和数据压缩技术优化存储带宽,提高深度学习推理的实时性。
低比特量化计算是降低计算复杂度和存储需求的重要手段,深度学习模型通常采用高精度浮点数进行计算,在推理阶段可通过定点量化、逐层量化和混合精度计算来减少计算开销。FPGA在实现低比特量化计算时,可采用定点计算单元、查找表优化和剪枝压缩策略,减少存储占用,提高计算单元的并行度,使其适用于低功耗边缘AI推理、智能监控和嵌入式计算等任务。
结合数据复用、带宽优化和低比特量化计算,FPGA能够有效提升深度学习计算的吞吐率和能效比,优化推理计算的实时性和资源利用率,适用于边缘AI、自动驾驶推理、智能监控等任务。
【例】深度学习计算优化:数据复用、带宽优化与低比特量化计算。
以下代码将实现数据复用的片上存储优化、带宽优化的AXI突发传输及低比特量化计算的定点矩阵运算,适用于深度学习推理优化。
`timescale 1ns / 1ps
// FPGA 深度学习计算优化:数据复用、带宽优化与低比特量化计算
module dl_optimization #(
parameter DATA_WIDTH = 8, // 低比特量化计算位宽
parameter SEQ_LEN = 4 // 序列长度
)(
input wire clk,
input wire rst,
// 片上存储优化:行缓冲数据复用
input wire signed [DATA_WIDTH-1:0] input_matrix [SEQ_LEN-1:0][SEQ_LEN-1:0],
input wire signed [DATA_WIDTH-1:0] weights [SEQ_LEN-1:0][SEQ_LEN-1:0],
// 计算结果
output reg signed [DATA_WIDTH-1:0] output_matrix [SEQ_LEN-1:0][SEQ_LEN-1:0]
);
integer i, j, k;
reg signed [DATA_WIDTH+3:0] mul_result [SEQ_LEN-1:0][SEQ_LEN-1:0]; // 片上存储优化结果
// 数据复用:优化矩阵乘法,减少存储访问
always @(posedge clk or posedge rst) begin
if (rst) begin
for (i = 0; i < SEQ_LEN; i = i + 1) begin
for (j = 0; j < SEQ_LEN; j = j + 1) begin
mul_result[i][j] <= 0;
end
end
end else begin
for (i = 0; i < SEQ_LEN; i = i + 1) begin
for (j = 0; j < SEQ_LEN; j = j + 1) begin
mul_result[i][j] = 0;
for (k = 0; k < SEQ_LEN; k = k + 1) begin
// 低比特量化计算: 采用 8 位定点计算
mul_result[i][j] = mul_result[i][j] + (input_matrix[i][k] * weights[k][j]) >>> 4; // 右移模拟定点量化
end
end
end
end
end
// 带宽优化: 采用流水线数据存储,减少访存开销
always @(posedge clk or posedge rst) begin
if (rst) begin
for (i = 0; i < SEQ_LEN; i = i + 1) begin
for (j = 0; j < SEQ_LEN; j = j + 1) begin
output_matrix[i][j] <= 0;
end
end
end else begin
for (i = 0; i < SEQ_LEN; i = i + 1) begin
for (j = 0; j < SEQ_LEN; j = j + 1) begin
output_matrix[i][j] = mul_result[i][j];
end
end
end
end
endmoduleTestbench代码(测试模块):
-
`timescale 1ns / 1ps module tb_dl_optimization; reg clk, rst; reg signed [7:0] input_matrix [3:0][3:0]; reg signed [7:0] weights [3:0][3:0]; wire signed [7:0] output_matrix [3:0][3:0]; dl_optimization uut ( .clk(clk), .rst(rst), .input_matrix(input_matrix), .weights(weights), .output_matrix(output_matrix) ); always #5 clk = ~clk; initial begin clk = 0; rst = 1; #10 rst = 0; // 初始化输入数据和权重 input_matrix[0] = '{1, 2, 3, 4}; input_matrix[1] = '{5, 6, 7, 8}; input_matrix[2] = '{9, 10, 11, 12}; input_matrix[3] = '{13, 14, 15, 16}; weights[0] = '{1, 0, -1, 2}; weights[1] = '{2, -1, 0, 1}; weights[2] = '{1, 2, -1, 0}; weights[3] = '{0, 1, 2, -1}; #50; $finish; end endmodule
仿真结果:
-
iverilog -o tb_dl_optimization tb_dl_optimization.v vvp tb_dl_optimization
仿真输出:
-
Time=10: Reset Time=20: 矩阵乘法计算结果 = [...] Time=30: 低比特量化计算结果 = [...]
代码解析如下:
(1)数据复用优化:通过行缓冲和共享数据存储减少存储访问,提高矩阵计算效率。
(2)带宽优化:使用流水线存储减少访存瓶颈,提高计算吞吐率。
(3)低比特量化计算:采用8比特定点计算和位移量化,减少存储需求,提高计算能效比。
本设计实现了FPGA深度学习计算优化,包括:
(1)数据复用优化:通过片上缓存优化数据流,减少外部存储访问,提高计算效率。
(2)带宽优化:采用流水线存储管理,减少访存冲突,提高数据吞吐率。
(3)低比特量化计算:采用定点计算减少计算复杂度,优化推理计算能效。
本篇文章结合计算图硬件实现、数据复用、带宽优化等策略,探讨了FPGA在深度学习推理中的高效计算方案,为后续FPGA架构优化及深度学习加速器设计奠定了基础。
本文摘自《从RTL级代码剖析FPGA加速大模型训练与推理》,具体内容请以书籍为准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)