别再写代码调 AI 了:让 AI 来调用你的代码
如果你需要稳定的流水线 -> 选范式一。如果你需要灵活的个人助手 -> 选范式二。如果你要构建复杂、安全、高性能的智能系统 -> 请拥抱范式三。在 AI 落地深水区的今天,学会设计“让 AI 好用,让代码好写”的协作界面,是每一位全栈工程师的新必修课。
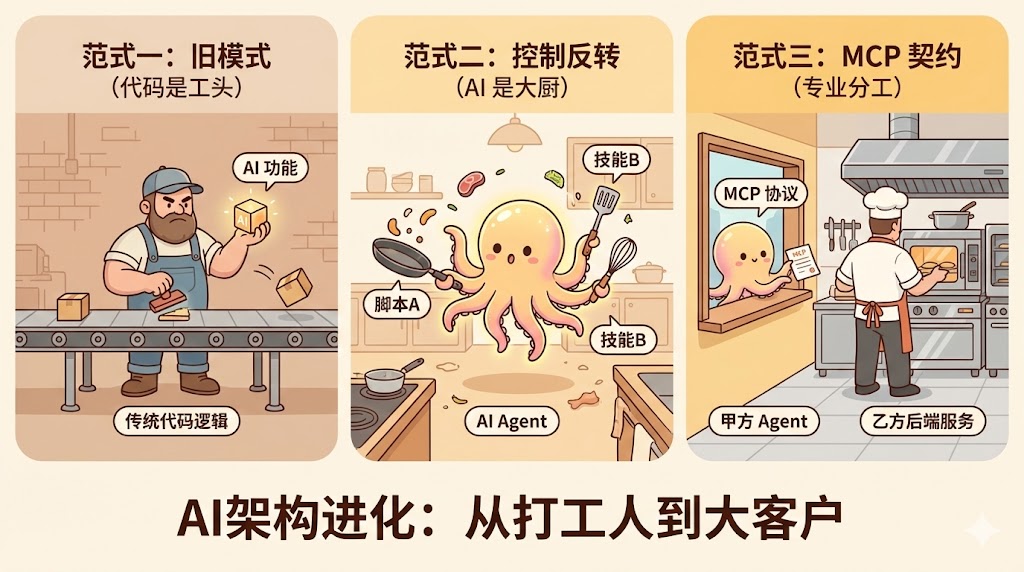
最近在深度使用 Claude Code 时,我获得了一个有趣的顿悟。
以前开发 AI 应用,我习惯写一堆 Python 或 Go 代码,把 LLM 当作一个普通的 API 函数来调用,所有的业务逻辑(循环、判断、数据处理)都写死在代码里。
但现在,我发现完全可以反过来——直接让 Claude Code (Agent) 作为主控,通过 MCP 协议调用我预先封装好的工具。
这种“Agent 主导”的模式,不仅代码量更少,而且逻辑更灵活,完全替代了过去“专门写个程序去调 LLM”的做法。这引发了我对 AI 应用架构设计的思考:在构建复杂系统时,“大脑” (LLM) 与 “手脚” (传统代码逻辑) 的控制权,究竟该如何交接?
本文将分享这一思考过程中的三种设计范式。
范式一:LLM-as-a-Function (大模型只是一个函数)
“传统程序是主宰,AI 是被调用的 API。”
这是最早期,也是目前商业软件中集成 AI 最稳妥的模式。
想象一下,你写了一个 Python 脚本来生成周报。
- 代码执行:程序先去数据库里把这一周的 Git Commit 记录抓出来。
- AI 介入:程序把这些记录拼成一段文字,传给 LLM 说:“帮我总结一下”。
- 流程继续:LLM 返回一段话,程序把它存进数据库,渲染到前端。
它的本质:
整个系统的控制流(Control Flow)是由程序员写死的(If-Else/While)。LLM 在这里极其被动,它不知道自己在一个庞大的系统里,它只是完成了一个文本处理任务,就像调用了一个 JSON.parse() 函数一样。
- 优点:极其稳定、可预测、高性能。
- 缺点:毫无灵活性。如果用户突发奇想:“把含有 Bug 修复的提交单独列出来”,原本写死的代码逻辑就得重写。
范式二:Agent-Centric Script (控制权反转)
“AI 是指挥官,代码是它手边的原子技能。”
这是 Agent 开发的分水岭。在这里,控制权发生了彻底的反转。
不再是代码调用 LLM,而是 LLM 决定调用哪段代码。我们将传统的业务逻辑(如“查询数据库”、“发送邮件”、“计算图表”)封装成一个个原子化的 Skills (技能) 或 Scripts (脚本)。
- 工作流:
- 用户指令:“分析一下我上个月的社交活跃度,并生成图表。”
- Agent 思考:它分析手头有哪些工具,决定先执行
get_monthly_stats.py,拿到数据后再执行plot_chart.py。 - 调用技能:Agent 动态调度这些预置的代码逻辑。
它的本质:
Agent 成为了 runtime 的主导者。传统的代码逻辑退化为被调用的“工具箱”。这种模式极大地释放了 AI 的潜力,因为它允许 AI 组合原子能力来解决未知的复杂问题。
- 优点:极度灵活。用有限的技能,组合出无限的解决方案。
- 适用:自动化运维、本地文件批处理、数据探索。
范式三:The Decoupled Pattern (MCP / 契约模式)
“AI 是甲方,后端是乙方的专业服务。”
这看起来和范式二很像(都是 AI 调用工具),但它们在架构上有本质的区别:解耦 (Decoupling) 与 契约 (Contract)。这是 Model Context Protocol (MCP) 提倡的方向。
在范式二中,Agent 往往和脚本运行在同一个进程或环境中,Agent 甚至可能直接生成代码去跑。
而在范式三中,Agent 和 业务逻辑是完全隔离的。
- 架构:
Agent (Client) <-> MCP 协议 <-> Backend Service (Server) - 工作流:
- Agent (甲方):通过 MCP 协议发送一个请求:“我要查一下 ID 为 123 的用户状态。”
- Backend (乙方):这是一个用 Go/Rust/Java 写的高性能后端。它收到请求,执行严格、复杂的业务逻辑(解密、跨库查询、鉴权),然后只把最终结果通过协议返回给 Agent。
- Agent (决策):拿到结果,决定下一步通过协议请求什么。
它的本质:
Agent 不需要知道“查询数据库”到底涉及多少个分表、用了什么加密算法。它只管通过标准协议(MCP)下达意图。后端负责把“脏活累活”干得又快又安全。
- 优点:
- 安全与性能:复杂的逻辑跑在编译型语言里,而不是让 LLM 现场写 Python。
- 架构清晰:后端代码可以独立升级,只要 MCP 接口不变,Agent 就不受影响。
- 适用:企业级应用、复杂业务流、需要严格数据一致性的系统(比如我们的微信聊天记录分析)。
案例复盘:述职报告生成器
我们在开发“聊天记录 -> 自动述职报告”这个功能时,架构的选择决定了成败:
- 若用范式一:我们需要手写代码去判断“哪句话是工作相关的”。这太难了,因为“工作”的定义很主观。
- 若用范式二 (Code Interpreter):让 Agent 现场写 Python 脚本去解析聊天记录的
.db数据库。但是,这么做相当不稳定,Agent 生成的代码根本跑不通,或者跑得极慢。 - 最终选择范式三 (MCP):
- 我们用 Go 写了一个高性能后端,负责读取数据库、提取消息、清洗数据——这是Backend Service。
- Go 暴露出了简单的 MCP 工具:
get_messages_by_date。 - Claude (Agent) 只需要调用这个工具拿到干净的文本,然后专注于它的强项:语义分析和报告撰写。
结语
- 如果你需要稳定的流水线 -> 选 范式一。
- 如果你需要灵活的个人助手 -> 选 范式二。
- 如果你要构建复杂、安全、高性能的智能系统 -> 请拥抱 范式三。
在 AI 落地深水区的今天,学会设计 “让 AI 好用,让代码好写” 的协作界面,是每一位全栈工程师的新必修课。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)