端侧模型是什么意思?
本文介绍了端侧模型的概念及其与云端模型的核心区别。端侧模型指直接在终端设备本地运行的AI模型,具有低延迟、隐私性好、可离线使用等优势,适用于手机、可穿戴设备、车载系统等场景。文章对比了端侧模型与云端模型在运行位置、延迟、隐私等方面的差异,并列举了典型应用案例。同时分析了端侧模型的技术特点,包括模型压缩、硬件依赖等特点。最后探讨了端侧模型与端侧大模型的区别,指出前者侧重单一任务优化,后者具备通用理解
端侧模型(On-device / Edge Model),指的是不依赖云端服务器、直接在“终端设备本地”运行的机器学习 / 深度学习模型。
端侧模型 = 模型跑在你的设备上,而不是跑在云服务器上。
比如:
-
手机
-
智能手表
-
摄像头
-
车载系统
-
IoT 设备
这些都叫“端”。
一、端侧模型和云端模型的核心区别
| 维度 | 端侧模型 | 云端模型 |
|---|---|---|
| 运行位置 | 本地设备(端) | 云服务器 |
| 是否联网 | 不必须 | 通常需要 |
| 延迟 | 极低(毫秒级) | 较高(网络+计算) |
| 隐私 | 数据不出设备 | 数据需上传 |
| 算力 | 有限 | 很强 |
| 模型规模 | 小模型 / 压缩模型 | 大模型 |
| 成本 | 前期高,长期低 | 持续服务器成本 |
二、典型的端侧模型例子
📱 手机端
-
人脸解锁
-
输入法联想
-
拍照场景识别
-
离线翻译


⌚ 可穿戴设备
-
心率 / 睡眠分析
-
跌倒检测
-
健康异常预警

🚗 车载与工业设备
-
自动驾驶感知模型
-
工业缺陷检测
-
边缘摄像头目标识别
三、为什么要做端侧模型?
1、低延迟(实时性)
-
自动刹车
-
手势控制
-
语音唤醒(“嘿 Siri”)
云端根本来不及
2、隐私与安全
-
生物特征(脸、指纹)
-
医疗数据
-
家庭摄像头
数据不上云,更安全
3、离线可用
-
飞机上
-
地下室
-
工厂车间
4、省钱(规模化)
-
上亿设备 × 云推理 = 天价
-
端侧 = 一次部署,长期运行
四、端侧模型有什么技术特点?
🔹 模型必须“瘦”
常见技术:
-
模型剪枝(Pruning)
-
量化(INT8 / INT4)
-
知识蒸馏
-
小模型结构(MobileNet、EfficientNet)
🔹 强依赖硬件
端侧芯片:
-
手机:NPU / DSP / GPU
-
MCU:TinyML
-
AI 芯片:Edge TPU / Ascend / RK NPU
🔹 推理优先,训练在云端
端侧 ≠ 训练
-
训练:云端
-
推理:端侧
-
更新:OTA
五、端侧模型 vs 边缘模型 vs 本地模型
| 名称 | 是否一样 | 说明 |
|---|---|---|
| 端侧模型 | ✅ | 强调“设备端” |
| 边缘模型 | ⚠️ 接近 | 可能在边缘服务器 |
| 本地模型 | ⚠️ 泛称 | PC / 本地部署 |
| On-device AI | ✅ | 英文说法 |
六、工程化经典架构
云端训练 & 评测
↓
模型压缩 / 量化
↓
端侧部署(NPU)
↓
实时推理
↓
日志回传(可选)
端侧模型 = 为“真实世界设备”而生的 AI,是 AI 工程落地的核心形态之一。
端侧模型 vs 端侧大模型
端侧模型:
👉 为“单一明确任务”优化的小模型,追求快、省、电低、稳定端侧大模型:
👉 能“理解 + 推理 + 多任务”的通用模型,追求智能上限与泛化能力
二、核心定义对比
| 维度 | 端侧模型 | 端侧大模型 |
|---|---|---|
| 模型规模 | KB ~ 几十 MB | 几百 MB ~ 数 GB |
| 参数量 | 10⁵ ~ 10⁷ | 10⁸ ~ 10⁹+ |
| 典型结构 | CNN / 小 Transformer | LLM / 多模态 Transformer |
| 是否通用 | ❌ 否 | ✅ 是 |
| 推理频率 | 高(持续运行) | 低 / 按需 |
| 工程目标 | 稳定、可控、极致效率 | 智能、理解、推理 |
三、能力本质差异
1️⃣ 端侧模型:“感知器官”
-
看:目标检测、OCR
-
听:关键词唤醒
-
判:异常 / 缺陷 / 风险
-
算:回归、分类
特点:
-
输入 → 输出
-
不“理解上下文”
-
不会“推理”
像:眼睛、耳朵、反射神经
2️⃣ 端侧大模型:“大脑”
-
自然语言理解
-
多轮对话
-
规划与推理
-
多任务泛化
特点:
-
有上下文
-
能规划
-
能迁移
像:人类的大脑皮层
四、典型应用对比
📱 手机 / IoT
端侧模型
-
人脸解锁
-
拍照自动对焦
-
语音唤醒
-
手势识别

端侧大模型
-
离线智能助手
-
本地 AI Copilot
-
复杂指令理解
🚗 自动驾驶 / 工业
端侧模型
-
车道线检测
-
行人识别
-
缺陷检测

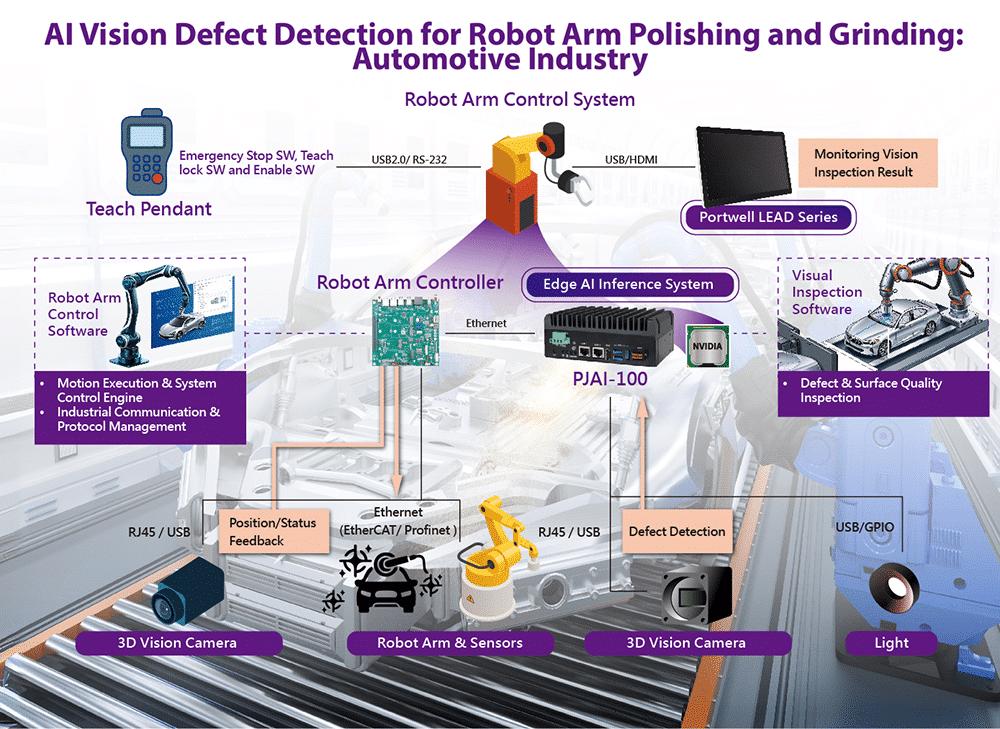
端侧大模型
-
语义场景理解
-
驾驶策略推理
-
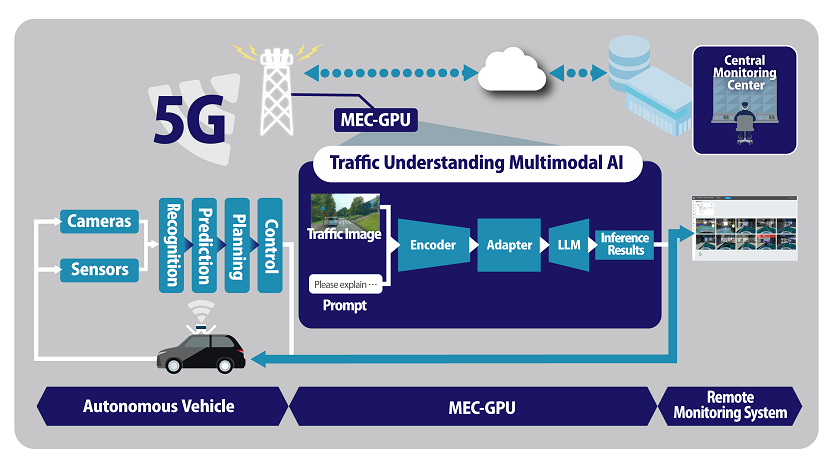
多模态决策

五、工程代价对比
| 维度 | 端侧模型 | 端侧大模型 |
|---|---|---|
| 推理延迟 | 毫秒级 | 100ms ~ 秒级 |
| 功耗 | 极低 | 高 |
| 内存占用 | 小 | 大 |
| 部署难度 | 低 | 高 |
| 稳定性 | 高 | 需防幻觉 |
| 可解释性 | 强 | 弱 |
现实中:99% 的设备都必须依赖端侧模型
六、为什么端侧大模型现在“很火但很难”
技术难点
-
模型太大(显存 / RAM)
-
功耗不可控
-
长时间推理发热
-
幻觉风险(端上更危险)
工程手段
-
INT4 / INT8 量化
-
分层加载
-
KV cache 管理
-
MoE-lite
-
Prompt 限制
七、真正的产业形态:端侧模型 + 端侧大模型
这是行业共识架构:
传感器
↓
端侧小模型(实时感知)
↓
端侧大模型(理解 / 推理)
↓
执行 / 交互
小模型兜底,大模型升智
端侧模型解决“实时感知与控制”,端侧大模型解决“理解、推理与多任务”。
工程上通常采用小模型兜底 + 大模型增强的混合架构。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)